基于MongoDB的鋁合金模板設計軟件數據存儲系統
2018-06-20 08:21:24
土木建筑工程信息技術 2018年2期
(中國建筑科學研究院深圳分院,深圳 518057)
1 引言
我國建筑業正處在大發展、大建設階段。建筑業是資源和能源消耗大戶,其中模板消耗木材的數量非常龐大。據統計,木模板市場占到整個模板市場的3/4之上。而木模板有效利用率只為5%。木模板系統的使用不僅浪費了木材等資源,而且違背了國家產業政策向導,增加了碳排放,也造成了施工成本的大幅提高。
鋁合金模板作為新一代的建筑模板,具有低碳環保,無建筑施工垃圾,重量輕。拆裝靈活、剛度高、使用壽命長,澆筑的混凝土面平整光潔,施工對機械依賴程度低等優勢。隨著建筑行業和科學技術的快速發展,低碳經濟發展模式已經成為全球共識,選擇鋁合金模板系統施工成為必然的發展趨勢。
鋁合金模板加工完成送到現場之后,基本不能修改,不像木模板可以隨便切割。即使模板設計上的小小差錯,都可能需要重新深化設計,加工及制作,再從廠家運至施工現場。所以要求鋁合金模板設計圖紙必須要十分準確。鋁合金模板設計軟件除了處理模板本身的數據信息之外,還需要處理項目的建筑模型信息,結構模型信息以保證模板的對孔,漏漿,碰撞檢查等。因此,如何提升數據存儲和讀取性能同時保證系統服務穩定可靠成為該軟件的焦點。
2 MongoDB概述
MongoDB是一個高性能、開源、模式自由,基于分布式文件存儲的NoSQL數據庫。MongoDb的數據模式是動態的,數據結構非常松散,是類似json的bson格式,在同一集合內的文檔格式可以不一致,單個文檔內部無需考慮數據結構及類型,可動態增加非結構化數據,還可以嵌套文檔或者數組。Mongo最大的特點是它支持的查詢語言非常強大,其語法有點類似于面向對象的查詢語言,幾乎可以實現類似關系數據庫單表查詢的絕大部分功能,而且還支持對數據建立索引。其主要功能特性如下:
1)跨平臺、支持語言眾多;
2)模式自由;
3)支持文件存儲;
4)易于水平擴展;
5)復制集機制;
6)多級索引;
7)面向集合存儲;
8)豐富的查詢語句。
3 數據存儲系統架構
數據存儲系統為獨立的一層,介于業務層與數據庫之間,主要用于提供給業務一個類似內存數據集合的接口進行領域對象的訪問,并負責領域對象的持久化。系統采用Repository模式封裝存儲,讀取和查找行為的機制。如圖1所示,將對領域對象數據公共操作部分提取為IRepository接口,如常見的保存、刪除、查詢等方法,MongoRepository類來具體實現上面的接口的方法。MongoDB并不像關系型數據庫一樣需要定義一個ORM框架。不同的領域對象對數據的處理有著不同的需求,所以對應不同的領域對象定義各自的Repository類。
4 分片集群搭建
結合使用MongoDB的副本集和分片集群技術,使得系統擁有高擴展性、高伸縮性的同時也確保集群的可用性和可靠性。利用Mongo的分片技術,將數據自動的分解成多個塊,存儲在不同的服務器節點上,每個塊都有對應副本集。確保有服務器宕機時,其他的副本可以立即接替壞掉的部分繼續工作。數據分片以后,可以利用多臺服務器構建一個水平可擴展的運算架構,為系統提供強大的處理能力。以確保讓不停增長的數據始終如一的提供初始的訪問性能,而不會隨著數據的增長,系統的訪問速度越來越慢。
如圖2所示,分片集群有四個組件:mongos、config server、shard、replica set。應用請求mongos來操作mongoDB的增刪改查,config server存儲數據庫元信息,并且和mongos做同步,數據最終存入在shard(分片)上,為了防止數據丟失同步在副本集中存儲了一份,Arbiter仲裁在數據存儲到分片的時候決定存儲到哪個節點。
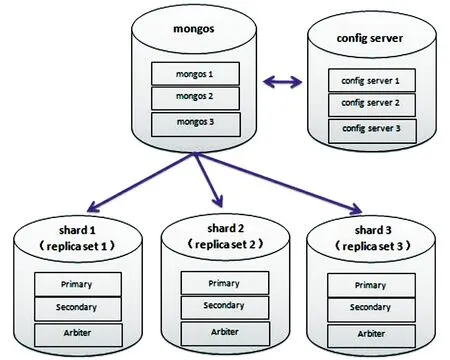
圖2 分片集群
5 海量數據并行運算
隨著系統數據量的不斷增大,對海量數據進行快速運算是該存儲系統必須解決的一個問題。MapReduce模型是解決該問題一個較為成熟的解決方案。該模型將計算任務切割并分發到計算集群的單個計算節點并行計算,在計算完成后,把結果返回給主服務器,主服務器匯總結果,最終完成計算任務的處理。
MongoDB的MapReduce功能是MapReduce編程模式的簡化實現。主要由Map、Shuffle和Reduce組成,使用時Map和Reduce需要顯式定義,shuffle由MongoDB來實現。首先Map將運算映射到文檔,生成Key-Value鍵值對,然后Shuffle按照Key進行分組,并將key相同的Value組合成數組。最后Reduce則把Value數組化簡為單值被返回。
如圖3所示,MapReduce在分片集群進行并行計算時,路由節點mongos將客戶端發出的請求進行暫存,并通過訪問config節點以獲得相關數據的位置。mongos得到數據的分布后,將請求發給相應的分片節點shard,shard節點進行MapReduce處理,并將處理數據返回給mongos,mongos將處理完的數據進行運算之后傳遞給最后的reducer。
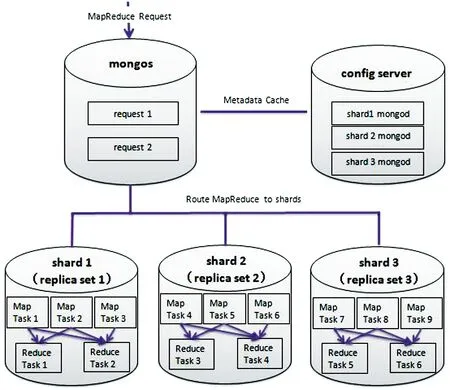
圖3 MapReduce在分片集群并行計算過程
6 性能測試
此次測試共涉及4臺服務器: 1臺Web 服務器和3臺 MongoDB 服務器。機器配置:CPU 為Intel(R)Core(TM)2 Duo CPU T6570 @ 2.10 GHz、內存為16 G DDR2 667、硬盤為SATA 1T、操作系統為Windows Server 2008 R2。編寫程序進行 MongoDB 千萬級數據量的性能測試,分別測試如下幾個項目。
6.1 MongoDb數據庫性能測試
如圖4所示,向MongoDB和MySQL數據庫插入1億條數據,每條數據大小1kb的情況下,MySQL的插入速度高于MongoDB。如圖5所示,在不同大小的數據庫中查詢1 000條數據,每條數據的大小1kb的情況下。MongoDB的查詢速度遠超MySQL,查詢的數據量逐漸增多的時候,MySQL的查詢速度是穩步下降的,而MongoDB的查詢速度卻有些起伏。
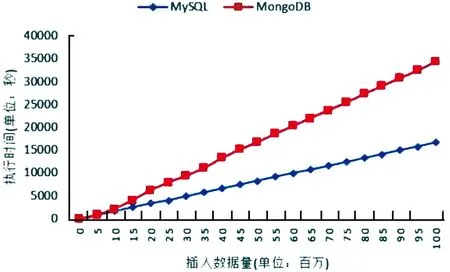
圖4 插入數據對比
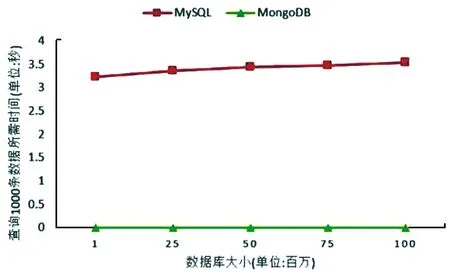
圖5 查詢數據對比
6.2 分片集群性能測試
如圖6所示,在插入的數據每條為1 kB 的情況下,正常插入的方式在數據量小于1 000萬條時,性能是比較高效的,但之后急劇降低,通過查看任務管理器,發現此時的內存占用率高于90%以上,說明數據的插入跟內存有著直接的關系,數據量過大時,需要在磁盤和內存間進行大量的數據交換,因此性能下降較快。而在分片的情況下,則相對穩定。批量操作在分片和非分片情況下差別較小。
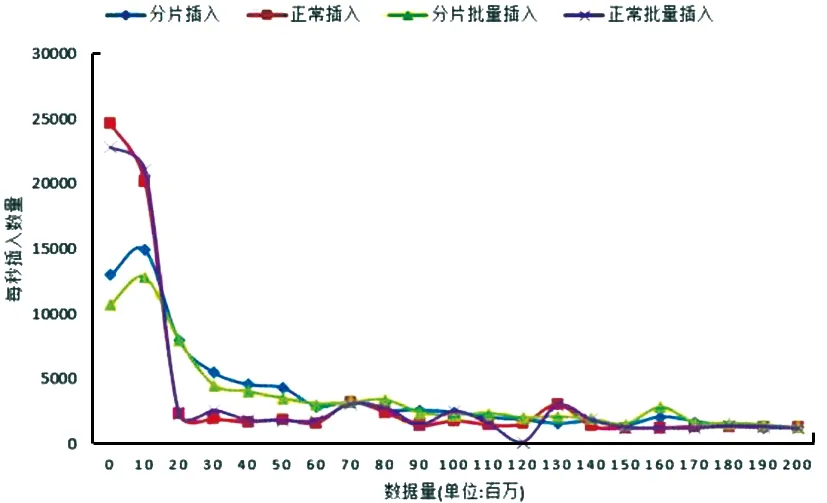
圖6 插入數據對比
如圖7所示,在每次查詢100條記錄,每條數據大小1kb的情況下。分片集群與常規查詢差距不大,但分片集群的穩定性要高于非分片查詢。在加入聚合排序條件之后,兩種情況的速度都有所下降。

圖7 查詢數據對比
7 總結
利用MongoDB的模型自由性、高可用性、高可擴展性等特點,搭建的鋁合金模板設計軟件云端數據存儲系統,可靈活地支持對象屬性字段的擴展,同時MongoDB的Shading技術,為突破單節點數據庫服務器的I/O能力限制,提供了水平擴展的解決方案。使用MapReduce模型搭建的并行計算模型保障了大規模數據運算、分析等處理的高效性與穩定性。數據復制與故障切換功能,為系統的可靠性提供了保障。實踐表明,本系統的靈活度及可擴展性良好,為建筑信息模型數據存儲提供了一種思路。
[1] Heidemann J,Bulusu N.Using geospatial information in sensor networks[C].Proceedings of CSTB workshop on Intersection of Geospatial Information and Information Technology,Arlington,VA,USA, 2001.
[2] MongoDB manual[EB/OL].2012.http://docs.mongodb.org/manual/sharding/.
[3] Chodorow K,Dirolf M.MongoDB 權威指南[M].程顯峰,譯.北京:人民郵電出版社, 2011.
[4] 姚林, 張永庫.NoSQL 的分布式存儲與擴展解決方法[J].計算機工程, 2012, 38(6): 40-42.
[5] Kuznetsov S D,Poskonin A V.NoSQL data management systems[J].Programming & Computer Software, 2014, 40(6): 323-332.
[6] Copeland R.MongoDB 應用設計模式[M].陳新,譯.北京:中國電力出版社, 2015.
[7] 龔健雅. 空間數據庫管理系統的概念與發展趨勢[J].測繪科學, 2001, 26(3): 4-9.
[8] Stonebraker M.SQL databases v.NoSQL databases[J].Communications of the ACM, 2010, 53(4): 10-11.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
光學精密工程(2016年6期)2016-11-07 09:07:19
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
核科學與工程(2015年4期)2015-09-26 11:59:03
