企業級大數據平臺框架設計方法研究
2018-07-06 09:18:32尹航謝汶姝劉俊濤喆單崇何楓
計算機與網絡 2018年11期
關鍵詞:數據庫
尹航,謝汶姝,劉俊濤喆,單崇,何楓
(1.北京宇航系統工程研究所,北京100076;2.中國人民解放軍91515部隊,海南三亞572000;3.航天新長征大道科技有限公司,北京100070)
0 引言
大數據技術的發展給企業數據應用和價值提升帶來了前所未有的新局面,越來越多的企業引進大數據技術,在業務戰略指引下,識別業務需求并評估數據分析能力,從現有的和新的數據來源中獲取新的洞察力,挖掘新的價值攀升空間,實現企業發展戰略[1]。本文針對大數據技術在企業級的應用,提出了一種大數據平臺框架設計方案,目的是對企業內部現有的多個應用系統進行整合升級,為企業數據的應用提供新的手段,同時為企業規劃大數據架構設計、關鍵技術攻關、數據處理和分析方法提供一些借鑒。
1 系統組成
大數據平臺的系統組成如圖1所示。大數據平臺包括分布式文件系統、分布式數據庫、關系型數據庫、分布式計算框架、數據服務平臺和平臺管理監控6個部分。大數據平臺的數據源由數據采集平臺提供,同時為企業級上層各業務應用系統提供數據管理、處理與分析手段,提供數據挖掘、數據可視化及數據深度應用的大數據增值服務。

圖1 大數據平臺系統的組成
2 系統功能
系統各部分提供的主要功能如下:
①分布式文件系統:提供穩定可靠的分布式存儲、數據的多冗余備份、不同服務器間負載均衡及存儲空間的水平擴展功能;
②分布式數據庫:實現基于多服務器的分布式數據庫系統,提供分布式數據庫WebService形式的訪問接口及數據庫的水平擴展、負載均衡和故障恢復能力;
③關系型數據庫:提供常用關系型數據庫,支持ODBC/JDBC等接口,提供數據庫備份服務;
④分布式計算框架:提供對大數據量的數據分塊、計算任務調度、數據與任務相互定位功能,實現“分而治之”計算模式,同時提供計算任務優化及故障處理機制,保障分布式計算的有效性;
⑤數據服務平臺:提供分布式算法庫、數據庫基礎接口和WebService形式的數據訪問接口;
⑥平臺管理監控:提供對大數據硬件集群的監控與大數據平臺服務的監控。
3 系統設計
3.1 分布式文件系統
分布式文件系統將文件分布存儲在多臺服務器的存儲空間中,通過統一的接口對外提供文件系統服務,包括文件打開、關閉、讀取及寫入等。分布式文件系統能夠自動實現數據的多冗余備份、虛擬機節點的故障檢測與恢復以及負責均衡和水平擴展。這些功能對用戶完全透明,用戶可以按照訪問本地磁盤的方式來使用分布式文件系統,同時能夠得到高質量的文件服務。分布式文件系統的結構圖如圖2所示,具備以下能力。
(1)具備冗余備份能力
文件系統將文件分塊存儲在多個數據節點中,存儲的同時為每一個文件塊生成2個備份(共3份),3份文件塊分別存儲在不同的數據節點中,即使有2臺服務器同時發生故障也不影響任何文件的完整性和正確性。
(2)具備故障檢測與恢復能力
管理節點通過數據節點發送的心跳數據感知其運行狀態,當某個節點發生故障,管理節點將切斷與該節點的連接關系,不再讓其執行文件訪問操作,并認為其中存儲的數據已經丟失。此外,文件系統會定期檢查文件的備份情況,當由于節點故障而導致備份丟失時,文件系統會再將文件備份到其他節點上,以保持數據同時在3個節點存儲的狀態。
(3)具備負載均衡與水平擴展能力
文件系統定期檢查各節點存儲空間的負載情況,當某些節點負載率過高或過低時,文件系統將自動執行負載均衡,將文件塊移至負載率較低的節點上。當文件系統中有新的數據節點加入時,系統會利用負載均衡機制,將一些文件塊移至新的數據節點,實現存儲空間的水平擴展。

圖2 分布式文件系統
3.2 分布式數據庫
分布式數據庫用于存放半結構化的業務數據、數據分析與挖掘的中間數據。分布式數據庫底層基于分布式文件系統構建,繼承其具有的可靠性、高性能和可擴展性。同時,分布式數據庫采用面向列的存儲架構,可以對TB級記錄進行快速隨機查詢與篩選,同時支持異構數據的管理,可靈活適應數據結構的變化。為了使數據便于分析和挖掘,系統需將原始數據進行預處理,以提高特定算法執行速度。利用分布式數據庫可存儲數據預處理的結果,加快分析挖掘算法的數據訪問速度,分布式數據庫結構如圖3所示。
分布式數據庫基于分布式文件系統構建,集成了文件系統的冗余和擴展機制:
①利用分布式文件系統存儲多個復本的元信息,利用Zookeeper選舉機制實現管理節點的多機備份[2];
②利用分布式文件系統存儲數據表的多個副本,實現數據的冗余存儲;
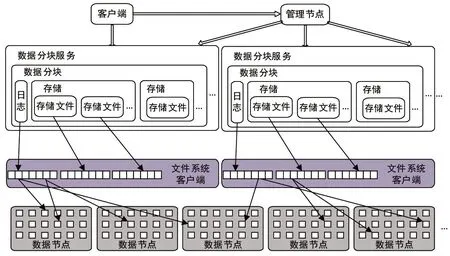
圖3 分布式數據庫
③數據庫表到達一定規模后會根據Key值自動分裂,分布到多個節點,實現負載均衡。
該平臺的分布式數據庫實現數據庫鏡像機制,創建鏡像時,數據庫能夠保存信息的副本,并對元信息指向的全部底層文件進行保護,防止文件在后續操作中被刪除或移動。通過鏡像機制,能夠在數據庫損壞時恢復到某一時刻的狀態。
3.3 關系型數據庫
大數據平臺提供關系型數據庫,用以存儲基礎數據、管理數據及建模數據。該平臺是基于MySQL提供關系數據庫服務的。MySQL是最流行的關系型數據庫管理系統之一,在Web應用方面,MySQL是較好的一款關系數據庫管理系統(Relational Database Management System,RDBMS)應用軟件[3]。MySQL支持ODBC/JDBC等接口,提供數據庫備份服務。在大數據平臺安裝了ODBC/JDBC驅動,在權限控制允許的范圍內,為上層應用信息系統提供讀取、寫入和操作關系型數據庫的接口。
大數據平臺提供的MySQL關系型數據庫實現了數據庫的冗余備份。冗余備份的工作原理是使用2臺服務器,一臺作為主服務器,運行應用系統來提供服務;另一臺作為備機,安裝完全一樣的應用系統,但處于待機狀態。當主服務器出現故障時,通過軟件診測將備份機器激活,保證應用在短時間內恢復正常使用。
作為主服務器Master,會把自己的每一次改動都記錄到二進制日志Binarylog中。作為從服務器Slave,會用主服務器Master上的賬號登陸到Master上,讀取Master的Binarylog,寫入到自己的中繼日志Relaylog中,然后自己的Sql線程會負責讀取這個中繼日志,并執行一遍,主服務器上的更改就同步到從服務器上了。在MySql上可以查看當前服務器的主從狀態。即當前服務器的Binary狀態和位置,以及其RelayLog的復制進度。
3.4 分布式計算框架
分布式計算框架是一種新的編程模式,它主要的思想是“分而治之”。大數據平臺通過Map和Reduce這2步實現任務在大規模計算節點中的調度和分配[4]。分布式計算框架由3個模塊組成,分別是客戶端、主節點和工作結點。客戶端用于將用戶撰寫的并行處理作業提交給主節點,再由主節點自動地將用戶作業分解為Reduce任務和Map任務,并將任務調度到工作結點上,工作結點向主節點請求執行任務,同時多個工作節點組成的分布式文件系統用來存儲輸入和輸出數據,分布式計算框架的結構如圖4所示。

圖4 分布式計算框架
分布式計算框架模型的主要優點就是它的高度抽象性,體現在映射函數Map、聚集函數Reduce和鍵值對<key,value>3個核心概念上。Map函數和Reduce函數對一組輸入的鍵值對(key/value)進行計算,得出另一組輸出鍵值對,即

由式(1)可知,用戶定義的映射函數Map的功能是接收一組輸入鍵值對 <key,value>,即(K1,V1),經過處理產生一組中間的(K2,V2)鍵值對,分布式計算框架函數庫聚合所有相同的中間鍵K2的相應值,產生關于K2鍵的值集合list(V2),這個處理過程稱為“分組",在形式上可以認為具有相同key值的Value處在同一個組中。接下來再把處理得到的這個新鍵值對發送給由用戶提供的歸并函數Reduce;由式(2)可知,Reduce函數的功能是:讀入新的鍵值對(K2,list(V2)),再進一步處理、合并該中間鍵的值集合,最后形成一個相對較小的鍵值對集合list(K3,V3)。該處理過程稱為“合并”,它不僅是簡單的累加過程,還包含具有很強依賴關系的復雜運算。
3.5 數據服務平臺
數據服務平臺以分布式計算框架為支撐,向上層應用提供數據訪問和處理服務。該平臺采用模塊化組件開發,按功能可分為分布式數據檢索模塊、分布式數據處理模塊、分布式數據分析模塊及分布式數據挖掘模塊等幾方面內容。企業需根據應用系統具體業務需求對該平臺進行功能開發。例如針對運載飛行器測試數據分析與評估應用需求,該數據服務平臺開發了以下功能:
(1)分布式算法庫
提供數據處理、分析、挖掘算法的分布式算法庫,將復雜算法轉化為可由分布式計算框架直接執行的分布式算法。算法主要包括數據轉換算法、多維數據分析算法、關聯分析算法、回歸算法、分類算法及聚類算法等[5]。
(2)任務處理模塊
任務處理模塊將各應用的數據處理請求轉化為實時或后臺處理任務,并對后臺處理任務進行調度和控制。其處理的任務包括生成數據物化視圖、數據預處理、數據挖掘及統計分析等[6]。
(3)數據訪問接口
向上層應用提供基于WebService的數據訪問和服務訪問接口,接口包括測試數據訪問接口、文件訪問接口及業務內容查詢接口等。
3.6 平臺管理監控
平臺管理監控以Web服務方式提供大數據平臺的維護管理功能,在該項目中,平臺管理監控系統提供了2個方面的監控服務:①對大數據硬件集群的監控:包括硬件服務器節點管理、集群運行狀態管理、服務器CPU、內存及網絡運行情況實時監測等;②對大數據平臺服務的監控:包括對Hadoop平臺進程監控、虛擬機運行狀態監控、分布式文件系統對CPU、內存、網絡資源占用率監控以及數據備份、系統擴展和故障恢復情況的監控等。
4 平臺實施部署
以大數據平臺實施途徑和部署方式為例,平臺的整體架構及技術選型如圖5所示。平臺的部署采用10臺云計算服務器搭建集群,具有數據中心管理服務、大數據存儲服務、關系型數據庫服務、數據分析挖掘服務、數據庫備份服務及Web服務等功能。在大數據平臺基礎上,運行了平臺管理監控系統、全壽命周期信息管理系統、測試數據分析系統及大數據分析與挖掘系統等應用。

圖5 大數據平臺整體框架及技術選型
5 結束語
本文從傳統的企業級應用系統向大數據技術背景下多應用系統融合升級需求出發,介紹了企業級大數據平臺框架設計方法,從系統組成、系統功能、系統設計及實施部署等幾個方面進行論述,該方法可實現穩定可靠的分布式存儲、分布式數據檢索、分析、處理與挖掘的數據服務,以及對平臺軟硬件運行的監控。借鑒已有項目實施經驗,基于10臺云計算服務器集群,給出實施部署示例,針對大數據企業級多系統應用底層構架設計提出可行方案,具有一定的應用創新性,為企業級應用系統集成的基礎平臺建設提供借鑒
[1]趙剛.大數據:技術與應用實踐指南[M].北京:電子工業出版社,2013.
[2]Junqueira F.Zookpeeper:Distributed Process Coordi-nation[M].O'Reilly Media,2013:210-333.
[3]盧湘江,李向榮,宴子.MySQL高級配置和管理[M].北京:清華大學出版社,2001:8-9.
[4]Dean J.Ghemawat S.MapReduce:Simplified Data Processing on Large Clusters[J].Communications of the ACM,2008,51(1):107-113.
[5]Han Jiawei,Micheline K.數據挖掘概念與技術[M].范明,孟小峰,譯.北京:機械工業出版社,2007.
[6]Rajaraman A,Ullman J D.大數據:互聯網大規模數據挖掘與分布式處理[M].王斌,譯.北京:人民郵電出版社,2012.
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
