語音特征和情感特征的翻譯系統與實現
2018-07-10 07:20:04曹春香
現代電子技術 2018年13期
曹春香
摘 要: 傳統在線機器翻譯系統存在翻譯效率低、翻譯效果差等問題,因此設計了基于語音特征和情感特征的翻譯系統。系統通過語音情感特征提取模塊將識別出的語音情感特征的具體特征提取出來,在模型庫中進行特征分類,提取出的特征信息在翻譯模塊中進行翻譯處理。翻譯模塊由用戶監視器、內核監視器、CPU模擬器、指令翻譯器、外設模擬器以及翻譯處理器構成,實現翻譯目標的準確翻譯。通過語音特征識別模塊的實現完成系統語音和情感特征的準確識別和檢測,通過翻譯處理器得到準確的翻譯結果。實驗結果表明該系統翻譯準確率高,翻譯效果好,系統響應時間短。
關鍵詞: 語音特征; 情感特征; 翻譯系統; 功能實現; 特征識別; 翻譯模塊; 翻譯處理器; 準確率
中圖分類號: TN911?34; TP391.2 文獻標識碼: A 文章編號: 1004?373X(2018)13?0123?05
Abstract: The traditional online machine translation system has low translation efficiency and poor translation effect, therefore a translation system based on speech feature and emotion feature was designed. The recognized specific features of speech and emotion features are extracted by the system with the speech and emotion features extraction module, and classified in model library. The extracted feature information is translated in translation module. The translation module is composed of user monitor, kernel monitor, CPU simulator, instruction translator, peripheral simulator and translation processor, which can realize the accurate translation of translation target. The speech feature recognition module can realize the accurate identification and detection of the system speech and emotion features. The accurate translation results are obtained with translation processor. The experimental results show that the system has high translation accuracy, perfect translation effect, and short system response time.
Keywords: speech feature; emotion feature; translation system; function realization; feature recognition; translation module; translation processor; accuracy
0 引 言
語音和情感信息的表達是最直接、有效的交流手段。隨著信息技術和社會的高速發展,各民族之間和國家間的交往越來越緊密,人們對翻譯系統的要求也越來越高。翻譯系統涉及多種學科,翻譯系統的實現能夠引起社會巨大的變革,使得使用不同語言的人們都能無障礙的進行交流[1]。語音特征和情感特征翻譯系統的實現能高效實現人們的無障礙交流,傳統在線機器翻譯系統存在翻譯效率低、翻譯效果差且系統整體運行緩慢等問題。因此,本文設計語音特征和情感特征的翻譯系統,能夠提高翻譯的速率,實現語音情感特征的翻譯。
1 語音特征和情感特征的翻譯系統與實現
1.1 系統總體框架
本文設計的基于語音特征和情感特征的翻譯系統的總體框架如圖1所示。系統采用語音情況特征識別模塊對語音特征和情感特征進行識別,通過語音特征提取模塊以及情感特征提取模塊將識別出的語音情況特征的具體特征提取出來,在模型庫中進行特征分類,提取出的特征信息在翻譯模塊中進行翻譯操作[2],翻譯模塊包括翻譯處理器和翻譯結果檢測,翻譯處理器可將抽象的語音特征和情感特征以具體的形式翻譯出來,加強人們之間的交流和聯系。
1.2 語音情感特征識別模塊設計
語音情感特征識別模塊包括對語音特征和情感特征的提取、模型訓練、模式匹配等。特征的提取主要包括對收集到的語音和情感特征信號的提取,經過計算機模擬數字信號處理后,再通過硬件和軟件組件的操作,對采集到的信號中具有明顯特征信息的信號進行保存[3]。表1是經過計算機的模擬數字信號處理和系統識別模型后的特征分類情況。模型的訓練就是對保存的具有明顯特征信息的信號建立模型的過程。模型的匹配是指識別特征與識別模型進行匹配,計算兩者之間的距離,匹配距離的大小決定語音情感特征識別模型的種類。語音情感特征識別模型按照特征的匹配可分為模板模型、神經網絡模型以及動態貝葉斯模型等。本文系統的語音情感特征識別模塊通過計算機模擬數字信號對識別模型與特征信息進行有效分類,提高了語音和情感特征的識別能力。
1.3 語音情感特征提取模塊設計
分析圖1中的系統結構可以看出,系統通過語音特征提取模塊和情感特征提取模塊,分別提取語音特征和情感特征,因為兩個特征提取模塊的結構一致,則本文設計了語音情感特征提取模塊,實現語音和情感特征的提取。該模塊的設計內容是:將帶有語音情感特征信息的信號進行量化、預加重處理、結果加密和特征的提取[4]。信號量化、預加重處理和結果加密都屬于對特征的預加工處理,具體流程圖如圖2所示。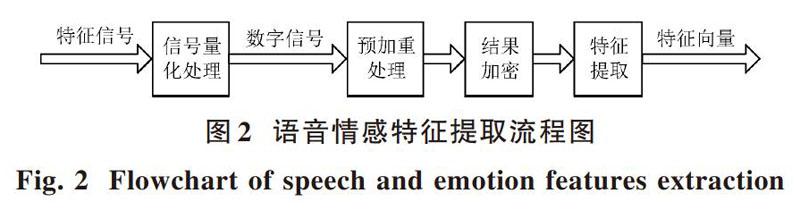
圖2描述的語音情感特征的提取過程中,首先對海量的語音情感數據進行量化處理,提取的結果要能代表語音情感特征的信號數據,整個過程叫語音情感特征提取。將語音情感特征信號轉換成音頻數據,將聲音的不同片段截取[5],投射到多維空間中,得到聲音的特征向量以及情感的特征向量。加密處理是將聲音片段進行時域和頻域分析,得到聲音的特征參數。則語音特征的特征參數就能用截取到的音頻特征參數表示。采用情感特征向量訓練的SVM模型實現情感特征的提取。
與特征提取方法不同,加密處理分為時域、頻域和小波域。時域的分析方法簡單,運算量小,分析效率高。能夠表示人的語音情感的特征有[6]:短時能量特征、短時過零率特征、短時平均特征、線性預測系數特征和倒譜系數特征等。不同的語音情況特征的描述情況如下:
1) 短時能量。短時能量特征不僅能反應特征語音信號的強度大小,還能反應出語音的間隔和輕重音。短時能量是語音識別的核心技術,短時能量能夠分辨聲音的清晰度,清音的聲音能量將比濁音能量低。假設一段語音信號為[w(n)],采用短時能量分析法對移動的窗口進行加權,得到:

特征的維度數如果過高會產生大量的計算步驟,使系統的存儲空間變小,減少系統的空間利用率[8],現實應用不廣泛。通過對特征的篩選可以減少大量的冗雜信息,降低維度數,提高預測系數,降低系統空間占有率。所以語音情感特征的提取是語音情感特征翻譯實現的關鍵,為翻譯機器對提取特征的翻譯打下基礎。
1.4 翻譯模塊設計
翻譯模塊采用內核動態二進制翻譯模塊,本文的翻譯模塊包括:用戶監視器、內核監視器、CPU模擬器、指令翻譯器、外設模擬器以及翻譯處理器。用戶監視器功能負責加載用戶空間中的應用程序和管理用戶空間與內核空間的交互。內核監視器主要為應用程序中的停留模塊的翻譯指令的執行提供支持。CPU模擬器是整個翻譯模塊的核心組件,負責應用程序CPU運行環境的模擬[9],將需翻譯的信號傳輸給指令翻譯器。指令翻譯器功能包括整個目標機體的指令到宿主機體結構指令的翻譯和保存。外設模擬器是將目標機體的應用程序對硬件設施的指令傳輸到宿主機的硬件當中,翻譯處理器對從外設模擬器中獲取的翻譯指令實施響應,完成指令的翻譯和處理。整個翻譯模塊的設計流程如圖3所示。
2 系統實現
2.1 語音特征識別模塊實現
系統中語音特征識別分為語音信號前端處理、特征提取和情感模式識別。語音模式識別采用分類器進行組合劃分,本文系統采用SVM模型進行語音特征識別,圖4為語音特征識別流程圖。
分析圖4可得,前端的處理包括對帶有特征信號的預處理和端點的檢測,主要工作是獲取有明顯可容易識別的信號,減少過多信息帶來計算量的增加,為后續特征提取提供優質的數據;特征提取與選擇是指提取明顯特征,將其導入到特征模式識別中,特征模式識別包括特征的模型訓練和模型的測試,模型訓練是將已提取出的情感特征劃分為不同類別的SVM模型。情感模型測試包括離線和在線測試:離線測試是對已經訓練好的SVM模型進行測試,即測試SVM模型的可識別能力;在線測試對正在導入的語音特征信號進行在線測試。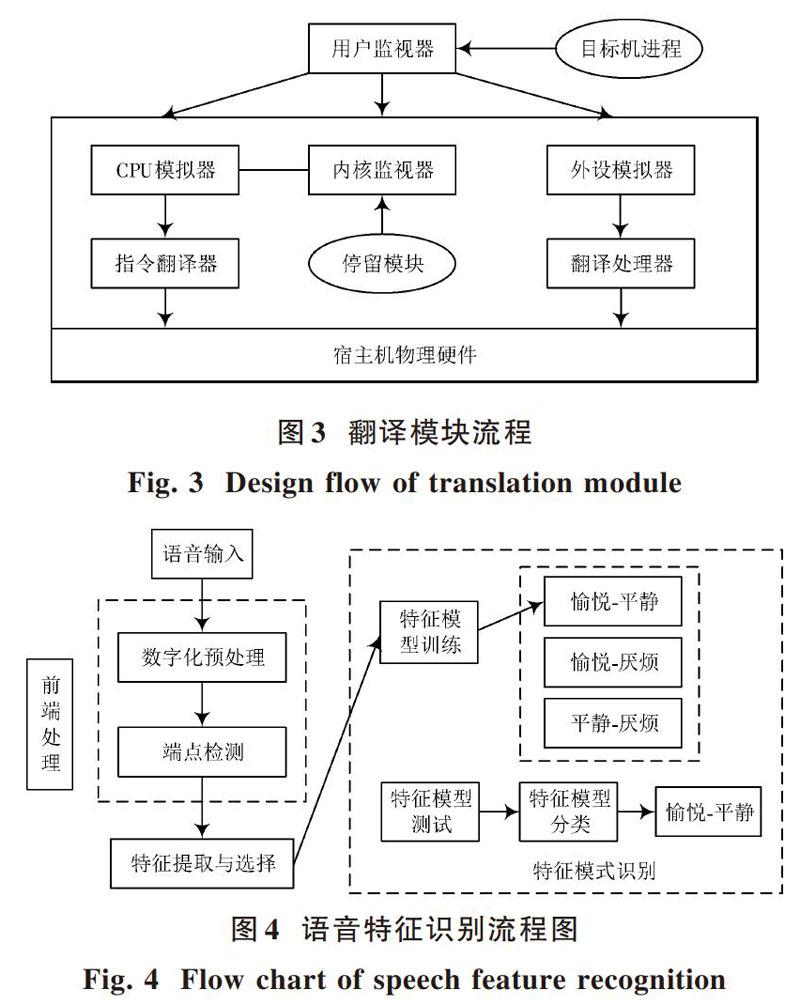
2.2 情感特征識別模塊的實現
對產生的特征需要測試其是否能夠滿足翻譯的條件,情感特征測試是對特征向量訓練的SVM模型分類效果進行測試,圖5為特征檢測流程,特征提取后,經過特征模型訓練分為三種情緒:情感1、情感2和情感3,通過投票判斷特征的識別情況。
2.3 翻譯處理器實現
系統翻譯模塊的翻譯處理器實現過程中,采用TranslateServer.java翻譯程序接收OCR處理器的翻譯請求后,為了實現翻譯系統的多線條處理,將翻譯請求集合成為Thread,并采用run方法,將得到的函數分配到一個端口9874,利用ServerSocket創建新的服務器,打開9874端口,調用accept()監聽服務器端口,當有需要翻譯的數據發送過來時,將數據轉換成socker對象,若沒有需要翻譯的數據,此時翻譯過程處于暫停狀態。新產生的socker對象當作ocrTranslate的構造方法,9874端口的socker不再接收用戶的翻譯請求[10],而是將用戶的翻譯請求傳達給新生成的socker對象,在新的socker對象處于的線程中采用Google TranslateAPI翻譯。同時,9874端口的socker對象接收新用戶發送的翻譯請求,則TranslateServer.java翻譯程序接收用戶的翻譯請求,然后將請求傳輸給socker對象。翻譯處理器的測試結果如圖6,圖7所示。
3 實驗結果與分析
3.1 翻譯效果
實驗對系統翻譯的質量進行量化考核。首先對翻譯質量有一個劃分標準:A?100分,B?80分,C?60分,D?40分,E?20分,F?0分。每一個經過系統翻譯的句子,專家都要根據翻譯的質量進行等級評價,然后將等級轉化成分數,進行加權求值。專家對系統開放性、封閉性和維護性等方面進行評價,將評價結果進行匯總。譯文質量的封閉性測試是從《英漢機器翻譯譯文質量測試大綱》中隨機選取56個句子進行測試。開放性測試由檢測小組設計24個句子進行測試,本文系統的翻譯質量結果用表2描述。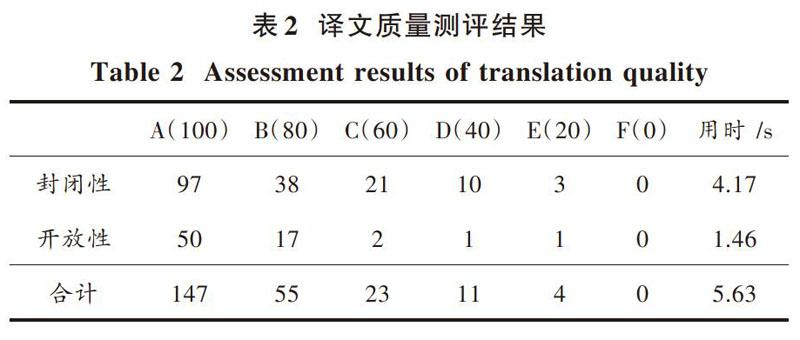
基于表2可得本文系統具有較高的翻譯效果,是有效的。
在Pentium866he 128內存的配置環境下,本文系統在封閉性的測試下共翻譯了169個單詞,用時4.176 s。開放性的測試總共翻譯71個單詞,用時1.467 s,本文系統總體翻譯時間為5.643 s。分析這些結果可得,本文系統質量良好、翻譯速度較快、系統的維護功能良好。
3.2 翻譯系統響應時間
本文系統的翻譯和傳統在線翻譯系統測試后響應的差別如表3所示。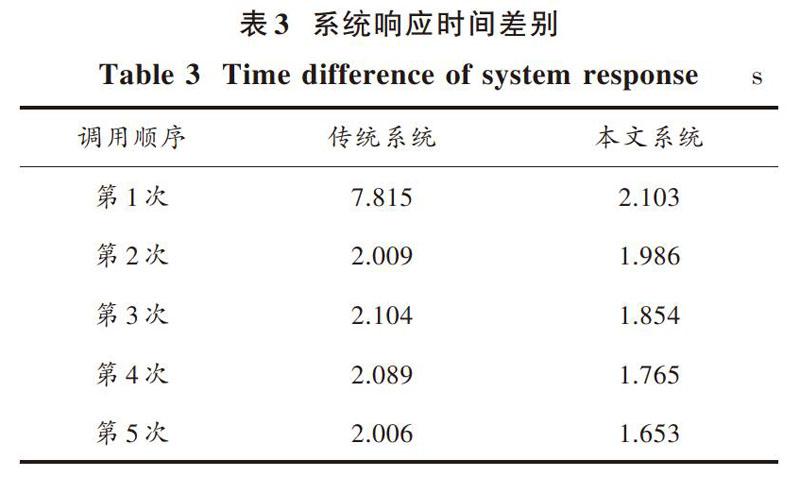
從表3數據可以看出,前兩次兩種系統的響應時間都較長,第一次的調用包括建立信息通道和網絡連接,在接收到翻譯信號后,對一個對象實現實例化,所以第一次調用時間較長,之后的調用都是對這個對象進行實例化。總體響應時間來看,本文系統的響應時間較短,系統的擴展功能較好。
3.3 翻譯準確率
采用本文系統與傳統在線機器翻譯系統對某大學圖書館中的醫學、教育、法律以及數學四種類型的數據庫實施中英文翻譯,來驗證本文系統是否具備較高的翻譯準確率,結果用表4描述。從中能夠看出,對于不同類型數據庫實施翻譯過程中,本文系統的翻譯準確率高于傳統系統,主要是因為本文系統模型庫中的語音合成模塊可以區分文本框中的字符是中文、英文或其他語言,從而對不同類型語音實施準確翻譯。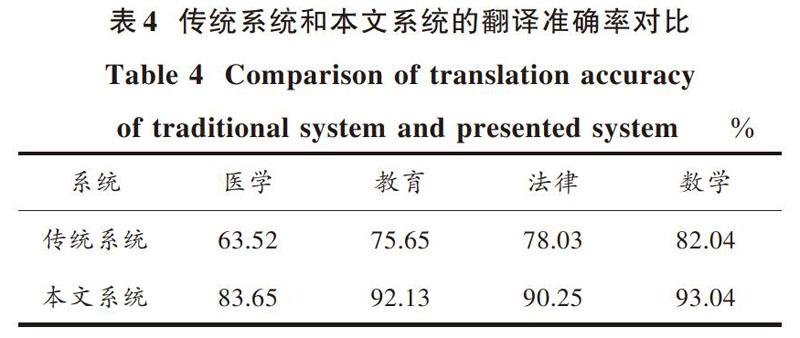
4 結 語
本文設計的語音特征和情感特征的翻譯系統可以提高翻譯的準確率和翻譯效果,實現人與人之間無障礙交流,創建和諧、穩定的交流環境。
參考文獻
[1] 宋鵬,金赟,查誠,等.基于稀疏特征遷移的語音情感識別[J].數據采集與處理,2016,31(2):325?330.
SONG Peng, JIN Yun, CHA Cheng, et al. Speech emotion recognition using sparse feature transfer [J]. Journal of data acquisition and processing, 2016, 31(2): 325?330.
[2] 李強,劉曉峰,賀靜.基于語音特征的情感分類[J].小型微型計算機系統,2016,37(2):385?388.
LI Qiang, LIU Xiaofeng, HE Jing. Sentiment classification based on voice features [J]. Journal of Chinese computer systems, 2016, 37(2): 385?388.
[3] 陳俊,王愛國,王坤俠,等.基于類依賴的語音情感特征選擇[J].微電子學與計算機,2016,33(8):92?96.
CHEN Jun, WANG Aiguo, WANG Kunxia, et al. Speech emotional feature selection based on class dependence [J]. Microelectronics & computer, 2016, 33(8): 92?96.
[4] 唐閨臣,馮月芹,梁瑞宇,等.面向語音情感識別的語譜特征提取算法研究[J].計算機工程與應用,2016,52(21):152?156.
TANG Guichen, FENG Yueqin, LIANG Ruiyu, et al. Research on algorithm of spectral feature extraction for speech emotion recognition [J]. Computer engineering and application, 2016, 52(21): 152?156.
[5] 陶華偉,柳晶晶,梁瑞宇,等.面向語音情感識別的Gabor分塊局部二值模式特征[J].信號處理,2016,32(5):505?511.
TAO Huawei, LIU Jingjing, LIANG Ruiyu, et al. Gabor block spectrum features based on local binary pattern for speech emotion recognition [J]. Journal of signal processing, 2016, 32(5): 505?511.
[6] 劉淼,邵青.基于多譯本平行語料庫的翻譯語言特征研究:對契訶夫小說三譯本的對比分析[J].解放軍外國語學院學報,2015,38(5):126?133.
LIU Miao, SHAO Qing. A study of translation language characteristics based on multi?translation parallel corpus: a comparative analysis of three versions of Chekhov′s novels [J]. Journal of PLA University of Foreign Languages, 2015, 38(5): 126?133.
[7] 劉茂玲,唐友東.英漢互譯中的文化特征與互譯解析[J].中南林業科技大學學報(社會科學版),2014,8(3):117?119.
LIU Maoling, TANG Youdong. Views on the cultural characte?ristics of language and translation [J]. Journal of Central South University of Forestry & Technology (social sciences), 2014, 8(3): 117?119.
[8] 劉宇鵬,馬春光,劉水,等.大規模特征集翻譯系統判別式訓練方法綜述[J].哈爾濱理工大學學報,2014,19(4):100?105.
LIU Yupeng, MA Chunguang, LIU Shui, et al. The summary of discriminative training method of large?scale feature set [J]. Journal of Harbin University of Science and Technology, 2014, 19(4): 100?105.
[9] 毛啟容,白李娟,王麗,等.基于情感上下文的語音情感推理算法[J].模式識別與人工智能,2014,27(9):826?834.
MAO Qirong, BAI Lijuan, WANG Li, et al. Speech emotion reasoning algorithm based on emotional context [J]. Pattern re?cognition and artificial intelligence, 2014, 27(9): 826?834.
[10] 趙小蕾,毛啟容,詹永照.融合功能性副語言的語音情感識別新方法[J].計算機科學與探索,2014,8(2):186?199.
ZHAO Xiaolei, MAO Qirong, ZHAN Yongzhao. New method of speech emotion recognition fusing functional paralanguages [J]. Computer science and exploration, 2014, 8(2): 186?199.
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
