基于本體和語義距離的DBpedia領(lǐng)域知識抽取方法
2018-07-10 07:20:04張志申王會勇張曉明艾青孟明明
現(xiàn)代電子技術(shù) 2018年13期
關(guān)鍵詞:概念
張志申 王會勇 張曉明 艾青 孟明明


摘 要: 關(guān)聯(lián)開放數(shù)據(jù)(LOD)中蘊(yùn)藏著大量不同領(lǐng)域的知識,但是目前抽取其中特定領(lǐng)域知識的方法大多需要人工參與。為了能自動地抽取領(lǐng)域知識,提出根據(jù)領(lǐng)域本體抽取DBpedia中特定領(lǐng)域知識的方法。使用領(lǐng)域本體、Wikipedia和主題提取算法獲得用于抽取領(lǐng)域知識的種子關(guān)鍵詞集。在直接鏈接子圖語義距離算法中,添加能夠代表邊指向性權(quán)值的參數(shù),用于領(lǐng)域知識的抽取,并基于本體和字符串相似度比較的篩選策略對抽取的知識進(jìn)行篩選。通過實(shí)驗(yàn)表明,該方法不僅能夠獲得較好的抽取效果,而且不需要人為地挑選關(guān)鍵詞和參與篩選過程,極大地節(jié)省了時(shí)間和精力。
關(guān)鍵詞: DBpedia; 領(lǐng)域本體; 直接鏈接子圖語義距離算法; 知識抽取; 抽取策略; 篩選
中圖分類號: TN911.1?34; TP391 文獻(xiàn)標(biāo)識碼: A 文章編號: 1004?373X(2018)13?0128?05
Abstract: The linked open data (LOD) contains huge amounts of different domain knowledge, and most of the approaches to extract the specific domain knowledge require manual intervention. A method of extracting domain specific knowledge from DBpedia based on domain ontology is proposed to extract the domain knowledge automatically. The domain ontology, Wikipedia and topic extraction algorithm are used to obtain the seed keyword set for domain knowledge extraction. The parameter representing the side?directivity weight is added into the direct linked subgraph semantic distance algorithm to extract the domain knowledge. The screening scheme based on ontology and character string similarity comparison is used to screen the extracted knowledge. The experiment results show that the proposed method can obtain perfect extraction performance, and needn′t select keywords or perform manual participation in the screening process artificially, which can greatly save people′s time and effort.
Keywords: DBpedia; domain ontology; direct linked subgraph semantic distance algorithm; knowledge extraction; extraction scheme; screening
0 引 言
隨著科技的發(fā)展,關(guān)聯(lián)開放數(shù)據(jù)(LOD)中的數(shù)據(jù)呈爆炸式增長,如DBpedia[1],Yago[2]等。這為語義網(wǎng)領(lǐng)域提供了大量可用數(shù)據(jù),并且推動了本體技術(shù)的快速發(fā)展。但是正因?yàn)長OD中數(shù)據(jù)的不斷增加,這在為使用者提供強(qiáng)大數(shù)據(jù)來源的同時(shí),也使得從中抽取特定領(lǐng)域數(shù)據(jù)變得困難。目前,針對從LOD中抽取領(lǐng)域數(shù)據(jù)的方式[3?4]大多相似,基本采用人工指定關(guān)鍵詞或者人為篩選關(guān)鍵詞作為抽取LOD知識的入口,并設(shè)計(jì)抽取策略或算法對LOD中的特定領(lǐng)域知識進(jìn)行抽取。但是這些抽取領(lǐng)域知識的方式容易受到關(guān)鍵詞的影響,人為指定的關(guān)鍵詞直接決定了該抽取策略的最后結(jié)果。并且使用者不僅需要對該領(lǐng)域知識有一定的了解,而且還需要進(jìn)行多次實(shí)驗(yàn)來確定關(guān)鍵詞集,從而耗費(fèi)大量的時(shí)間和精力。同時(shí),隨著本體技術(shù)的高速發(fā)展,各個(gè)領(lǐng)域的本體也迅速出現(xiàn),如金屬材料領(lǐng)域的STSM[5],睡眠醫(yī)學(xué)領(lǐng)域的SDO[6]等。由于領(lǐng)域本體中基本都包含著相應(yīng)領(lǐng)域的大部分知識,所以本文根據(jù)領(lǐng)域本體提取用于抽取領(lǐng)域知識的種子關(guān)鍵詞集。
本文提出根據(jù)領(lǐng)域本體提取DBpedia中特定領(lǐng)域知識的方法。該方法首先采用LDA算法[7?8],同時(shí)結(jié)合領(lǐng)域本體和Wikipedia[9]獲得領(lǐng)域本體的種子關(guān)鍵詞集;然后對直接鏈接子圖語義距離算法[3,10](DLSSD)添加邊指向性的權(quán)值參數(shù),使用種子關(guān)鍵詞集和該算法抽取DBpedia中的領(lǐng)域知識,并使用SMOA[11]和最大公共子串算法[12](LCS)結(jié)合當(dāng)前領(lǐng)域本體進(jìn)行篩選;最后得到特定領(lǐng)域知識。本文以STSM抽取DBpedia中金屬材料領(lǐng)域知識為例。通過實(shí)驗(yàn)表明,該方法不僅能獲得相對有效的種子關(guān)鍵詞集和DBpedia中特定的領(lǐng)域知識,而且不需要領(lǐng)域?qū)<业慕槿耄瑯O大地減少了人為工作量。
1 根據(jù)領(lǐng)域本體獲得種子關(guān)鍵詞集
在領(lǐng)域本體中,schema層基本囊括了該領(lǐng)域的知識,但是領(lǐng)域本體中也存在著不屬于該領(lǐng)域的數(shù)據(jù),只是與領(lǐng)域本體中部分?jǐn)?shù)據(jù)存在關(guān)聯(lián),如STSM中的author等。
為了能夠根據(jù)領(lǐng)域本體獲得可以代表該領(lǐng)域的種子關(guān)鍵詞集,本文利用LDA算法提取領(lǐng)域本體schema層,獲得候選關(guān)鍵詞集,并結(jié)合Wikipedia和LDA進(jìn)行擴(kuò)展。然后利用余弦相似度算法結(jié)合本體的schema層進(jìn)行相似度計(jì)算,設(shè)定閾值進(jìn)行篩選。重復(fù)擴(kuò)展和篩選的過程直到結(jié)果中的關(guān)鍵詞集不變?yōu)橹梗传@得能夠代表該本體領(lǐng)域性的種子關(guān)鍵詞集。例如,使用STSM獲得的種子關(guān)鍵詞集為{ iron, carbon, steel, metals, metal, alloys,alloy}。以下展示了通過候選關(guān)鍵詞獲得種子關(guān)鍵詞集的算法描述。
算法:getSK (List listck, Model model)
輸入:listck //候選關(guān)鍵詞集
model //領(lǐng)域本體
輸出:listck //獲得的種子關(guān)鍵詞集
Step:
1 listldaf = createArrayList() //接收初次篩選的關(guān)鍵詞
2 listldas = createArrayList() //接收最后篩選的關(guān)鍵詞
3 calssset←getClassset(model) //獲得領(lǐng)域本體的類名集
4 tostop = true files=null
//用于判停的標(biāo)識tostop,初始值為true,同時(shí)定義文檔files
5 While tostop
6 FOR each ck∈listck //遍歷listck中的每個(gè)關(guān)鍵詞
7 destext ← getWebDes(ck)
//獲得該關(guān)鍵詞在Wikipedia中的文本描述
8 similarity ← getWebDes(destext, calssset)
//獲得該文本與類名集的相似度
9 IF similarity >= 0.89
10 files ← write(destext)
11 //將文本描述寫入文檔listldaf.add(ck)
12 listk← getLDA(files) //使用LDA獲得該文檔的關(guān)鍵詞
13 FOR each k∈listk //遍歷listk中的每個(gè)關(guān)鍵詞
14 kdestext ← getWebDes(k)
//獲得該關(guān)鍵詞在Wikipedia中的文本描述
15 ksimilarity ← getWebDes(kdestext, calssset)
//獲得該文本與類名集的相似度
16 IF ksimilarity >= 0.89
17 listldas.add(k) //將關(guān)鍵詞存入listldas
18 IF listck == listldas //如果listck與listldas相等
19 tostop = false //給tostop賦值為false
20 ELSE listck ← listldas
//將listldas中的數(shù)據(jù)賦值給listck,作為下次循環(huán)使用的數(shù)據(jù)
21 listldaf.clear() listldas.clear()
//清空listldaf和listldas
22 RETURN listck
2 基于語義距離抽取DBpedia中的特定領(lǐng)域知識
DBpedia中的數(shù)據(jù)保存在多個(gè)數(shù)據(jù)集中,首先獲得SKOS_Category數(shù)據(jù)集中的特定領(lǐng)域概念,然后將獲得的概念通過字符串匹配的方式獲得其他數(shù)據(jù)集中的相關(guān)知識。本文對DLSSD算法添加能夠代表邊指向性的權(quán)值參數(shù),形成IDLSSD算法,并使用該算法抽取SKOS_Category數(shù)據(jù)集中的特定領(lǐng)域概念。
2.1 IDLSSD算法
在SKOS_Category數(shù)據(jù)集中,各個(gè)數(shù)據(jù)之間存在聯(lián)系,并且是以圖的形式存在。為了能夠獲得SKOS_Category中與領(lǐng)域本體相關(guān)的概念,使用DLSSD算法獲得特定領(lǐng)域的概念。該算法計(jì)算兩個(gè)節(jié)點(diǎn)的直接鏈接子圖語義距離,當(dāng)該直接鏈接子圖語義距離值越接近0時(shí),說明這兩個(gè)節(jié)點(diǎn)越相關(guān)。該算法再根據(jù)人為篩選的關(guān)鍵詞和使用Wikipedia中金屬材料分類作為背景數(shù)據(jù)集獲取DBpedia金屬材料知識,已取得了較好的應(yīng)用[3]。為了更加充分地體現(xiàn)節(jié)點(diǎn)之間的語義關(guān)系,以便更加準(zhǔn)確地獲得相關(guān)領(lǐng)域節(jié)點(diǎn),本文向該算法中添加能夠代表邊指向性的權(quán)值參數(shù),添加參數(shù)后的DLSSD算法(IDLSSD)如下:
在有向圖中,當(dāng)節(jié)點(diǎn)[a]指向節(jié)點(diǎn)[b]時(shí),說明節(jié)點(diǎn)[a]為節(jié)點(diǎn)[b]的子節(jié)點(diǎn)。即如果節(jié)點(diǎn)[b]為已知金屬材料領(lǐng)域的知識,那么節(jié)點(diǎn)[a]必然也為金屬材料知識;但是如果節(jié)點(diǎn)[a]為已知金屬材料知識,節(jié)點(diǎn)[b]有可能不為金屬材料知識。當(dāng)節(jié)點(diǎn)[a]指向節(jié)點(diǎn)[b]的同時(shí),節(jié)點(diǎn)[b]也存在一條指向節(jié)點(diǎn)[a]的線,這基本可以說明,節(jié)點(diǎn)[a]和節(jié)點(diǎn)[b]為相同或相似概念,即它們的領(lǐng)域性基本相同。例如,在DBpedia中,“Alloys broader Metals”表示“Alloys”指向“Metals”,“Metals”為金屬材料領(lǐng)域知識,顯然“Alloys”也為金屬材料知識。然而對于“Metals broader Crystalline_solids”,“Metals”為金屬材料領(lǐng)域知識,但是“Crystalline_solids”表示的是結(jié)晶固體,不為金屬材料領(lǐng)域知識。所以在計(jì)算[a]節(jié)點(diǎn)與[b]節(jié)點(diǎn)的IDLSSD值時(shí),本文也將表示[a]節(jié)點(diǎn)與[b]節(jié)點(diǎn)的指向方向性的權(quán)值[D]考慮在內(nèi),當(dāng)[a]節(jié)點(diǎn)指向[b]節(jié)點(diǎn)時(shí),[D]值設(shè)為1;當(dāng)節(jié)點(diǎn)[b]指向節(jié)點(diǎn)[a]時(shí),[D]值設(shè)為2;當(dāng)[a]節(jié)點(diǎn)與[b]節(jié)點(diǎn)相互指向時(shí),[D]值設(shè)為4。
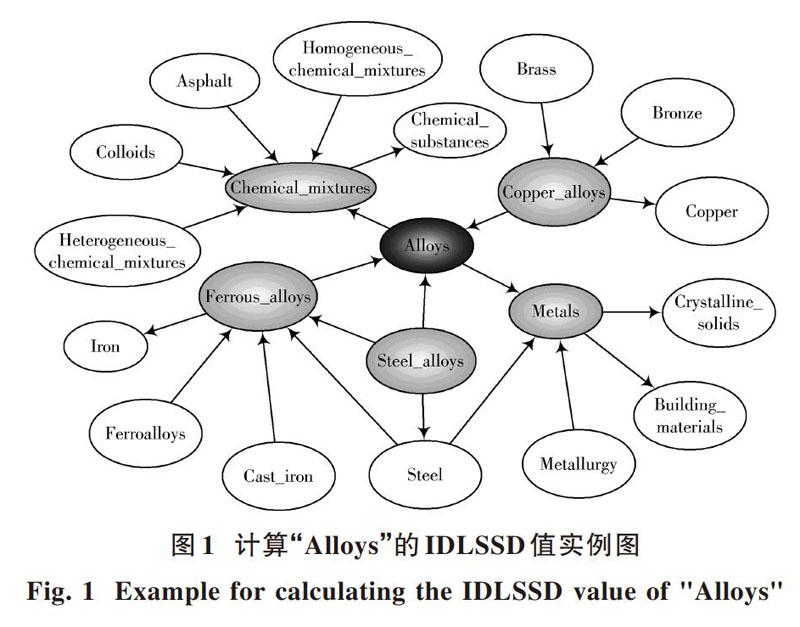
圖1展示了DBpedia中“Alloys”周圍的部分節(jié)點(diǎn)。計(jì)算“Alloys”與周圍節(jié)點(diǎn)的IDLSSD值,通過種子關(guān)鍵詞集中的“Alloys”獲得其直接鏈接子圖的概念{Chemical_mixtures,Copper_alloys,Metals,Steel_alloys, Ferrous_alloys}。以計(jì)算IDLSSD(Alloys, Ferrous_alloys)為例,其中“Alloys”指向“Ferrous_alloys”的邊數(shù)為0,即[E(a,b)]為0。“Ferrous_alloys”指向“Alloys”的邊數(shù)為1,即[E(b,a)]為1。其中,“Alloys”的直接鏈接子圖和“Ferrous_alloys”的直接鏈接子圖中都有相同的元素“Steel_alloys”,所以[N(a,b)]為1。并且已知節(jié)點(diǎn)“Alloys”被“Ferrous_alloys”指向,所以[D]值為2。即IDLSSD(Alloys, Ferrous_alloys)的值為0.20。
2.2 利用IDLSSD算法抽取DBpedia中的特定領(lǐng)域知識
根據(jù)SMOA算法獲得種子關(guān)鍵詞集在SKOS_Category中的對應(yīng)概念,將獲得的對應(yīng)概念作為抽取SKOS_Category數(shù)據(jù)集的入口,使用IDLSSD算法抽取其相關(guān)的概念。為了保障抽取到的概念與當(dāng)前領(lǐng)域本體相關(guān),設(shè)定閾值[T1]和[T2]分段進(jìn)行篩選。當(dāng)IDLSSD值小于[T1]時(shí),視為與當(dāng)前領(lǐng)域本體相關(guān)的概念;當(dāng)IDLSSD值在[T1]~[T2]范圍內(nèi)時(shí),使用SMOA和最大公共子串算法(LCS)結(jié)合領(lǐng)域本體schema層做進(jìn)一步篩選。將滿足篩選條件的概念再次作為SKOS_Category數(shù)據(jù)集的入口進(jìn)行抽取并篩選,一直重復(fù)該過程,直到獲得滿足篩選條件的概念集不再增多為止。最后根據(jù)獲得概念集利用字符串匹配的方式獲得DBpedia其他數(shù)據(jù)集中的相關(guān)知識。
使用SMOA和LCS算法結(jié)合當(dāng)前領(lǐng)域本體進(jìn)行篩選。將領(lǐng)域本體schema層中的概念作為背景數(shù)據(jù)集,對已獲得SKOS_Category中的概念集分別與背景數(shù)據(jù)集中的概念使用SMOA進(jìn)行相似度計(jì)算,當(dāng)最大值大于等于閾值TH1時(shí),視該概念屬于金屬材料領(lǐng)域;當(dāng)最大值小于閾值TH1并大于等于閾值TH2時(shí),使用LCS算法判斷該概念是否包含背景數(shù)據(jù)集中的概念,如果包含,那么該概念屬于金屬材料領(lǐng)域。其他情況都視為該概念不屬于金屬材料領(lǐng)域。
結(jié)合SMOA和LCS的篩選策略如下:
算法: getSMOAandLCS (List listBD, String con, int TH1, int TH2)
輸入: listDB //背景數(shù)據(jù)集
con //需要進(jìn)行判定的概念名稱
TH1 //設(shè)定的SMOA的閾值其中偏大的
TH2 //設(shè)定的SMOA的閾值其中偏小的
輸出: sc //con是否與背景數(shù)據(jù)集相同領(lǐng)域的標(biāo)識
Step:
1 sc = false //用于返回的標(biāo)識sc,初始值為false
2 simimax ← getSMOAMax(con, listBD)
//獲得最大相似度值
3 IF simimax >= TH1
//判斷最大相似度值是否大于TH1
4 sc = true //將sc的值設(shè)置為true
5 ELSE IF simimax < TH1 && simimax >= TH2
//判斷最大相似度值是否小于閾值TH1并且大于等于TH2
6 lcs ← judgeLCS(con, listBD)
//判斷con是否存在包含背景數(shù)據(jù)集中的概念
7 IF lcs == true //判斷l(xiāng)cs是否為true
8 sc = true //將sc的值設(shè)置為true
9 RETURN sc
3 實(shí)驗(yàn)評估
3.1 評估IDLSSD算法的閾值[T1]和[T2]
本文將[T1]值設(shè)定為0.15,[T2]值設(shè)定為0.34。當(dāng)IDLSSD值小于等于0.15時(shí), IDLSSD算法公式中4個(gè)值的總和必須大于等于6。當(dāng)IDLSSD值在[T1]和[T2]之間時(shí),其公式中4個(gè)值的總和須在6和2之間。由于[E(a,b)],[E(b,a)]表示節(jié)點(diǎn)之間的連線,[D]表示節(jié)點(diǎn)之間指向性的權(quán)值,所以[E(a,b)],[E(b,a)],[N(a,b)]和[D]的取值之間存在一定聯(lián)系。表1展示的是4個(gè)值總和為6和2時(shí),各個(gè)參數(shù)的取值情況。
對于本文,將[T1]值設(shè)定為0.15,即將該4個(gè)值的總和最小設(shè)定為6,因?yàn)樵赟KOS_Category中,節(jié)點(diǎn)之間的連線關(guān)系都為“broader”,并且當(dāng)節(jié)點(diǎn)a和節(jié)點(diǎn)b之間存在相互指向的連線關(guān)系(S6_3)時(shí),說明節(jié)點(diǎn)a和節(jié)點(diǎn)b極為相似或密切關(guān)聯(lián),所以本文視這兩個(gè)節(jié)點(diǎn)的領(lǐng)域性相同。并且在4個(gè)值總和為6時(shí)的其他情況(S6_1和S6_2)中,當(dāng)節(jié)點(diǎn)a的直接鏈接子圖和節(jié)點(diǎn)b的直接鏈接子圖中相同元素個(gè)數(shù)大于等于3時(shí),也可以認(rèn)為這兩個(gè)節(jié)點(diǎn)為相同領(lǐng)域的節(jié)點(diǎn)。
對于其他情況,當(dāng)節(jié)點(diǎn)[a]和節(jié)點(diǎn)[b]至少存在一條連線關(guān)系(S2_1)時(shí),不能肯定地判斷節(jié)點(diǎn)[b]與節(jié)點(diǎn)[a]的領(lǐng)域性是否一致,所以需要對這種情況的節(jié)點(diǎn)進(jìn)行進(jìn)一步的判定篩選,即將[T2]值設(shè)定為0.34。
3.2 評估篩選策略中的閾值TH1和TH2
在對大于等于閾值[T1]并小于閾值[T2]中的節(jié)點(diǎn)進(jìn)行篩選時(shí),本文使用SMOA和LCS算法設(shè)計(jì)分段篩選策略。為了確定篩選過程中TH1和TH2的選擇,從SKOS_Category中選取100個(gè)與當(dāng)前領(lǐng)域本體相關(guān)的節(jié)點(diǎn),900個(gè)與當(dāng)前領(lǐng)域本體不相關(guān)的節(jié)點(diǎn),分別采用不同的閾值對TH1和TH2進(jìn)行實(shí)驗(yàn),并使用準(zhǔn)確率(P),召回率(R)和F值進(jìn)行實(shí)驗(yàn)評估,實(shí)驗(yàn)結(jié)果分別如圖2和圖3所示。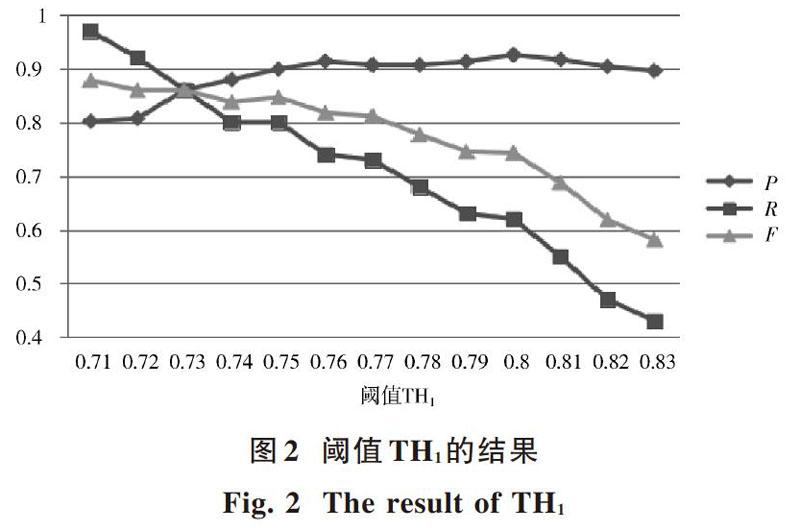
對TH1值的選擇,在F值可以接受的范圍內(nèi)主要考慮其準(zhǔn)確率,因?yàn)檫@里主要是盡可能多并且準(zhǔn)確地獲得與當(dāng)前領(lǐng)域本體相關(guān)的節(jié)點(diǎn)。對于其余節(jié)點(diǎn),通過LCS算法和TH2進(jìn)行篩選,以保障F值最高。從圖2可以看出,隨著閾值TH1的增加,其準(zhǔn)確率在不斷增長,并在0.76之后基本達(dá)到穩(wěn)定的狀態(tài)。但是,隨著TH1的增加,其召回率一直持續(xù)下降,導(dǎo)致其F值也一直呈現(xiàn)下降的趨勢。TH1在0.78~0.8準(zhǔn)確率出現(xiàn)略微的增長,在0.8時(shí)準(zhǔn)確率達(dá)到最大值,在0.8之后準(zhǔn)確率又開始有輕微下降的趨勢,并且在TH1為0.8時(shí),其F值還保持在一個(gè)可以接受的范圍。所以在本文中,TH1值設(shè)定為0.8。同時(shí)在圖3中,當(dāng)TH2值為0.7時(shí),其F值達(dá)到最高,所以選取TH2值為0.7。
3.3 使用不同的金屬材料領(lǐng)域本體評估抽取方法
為了說明本文所提抽取方法的適用性,使用不同的金屬材料本體提取SKOS_Category數(shù)據(jù)集中的特定領(lǐng)域概念,如使用AMO本體[13](Ashino創(chuàng)建的材料本體)。并且本文提出的抽取方法也適用于同時(shí)根據(jù)兩個(gè)相同領(lǐng)域的本體進(jìn)行抽取DBpedia中的特定領(lǐng)域知識,如使用STSM和AMO本體。在表2中,展示了分別使用AMO,STSM和同時(shí)使用AMO和STSM對SKOS_Category中的概念進(jìn)行抽取的結(jié)果。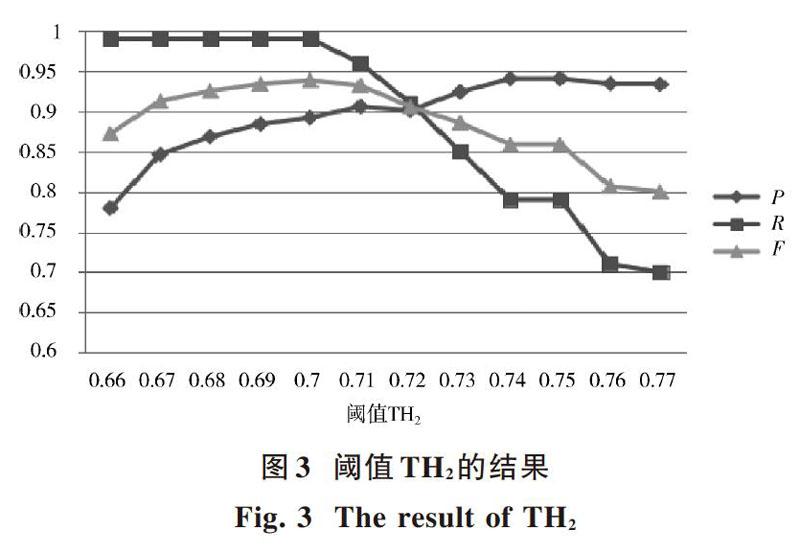
從表2中可以看出,雖然AMO和STSM都為金屬材料領(lǐng)域的領(lǐng)域本體,但是由于本體之間的差異,導(dǎo)致抽取出的候選關(guān)鍵詞集不同,進(jìn)而使得種子關(guān)鍵詞集也不同。并且作為篩選條件的背景數(shù)據(jù)集也存在明顯的差異,所以最后獲得特定領(lǐng)域概念的數(shù)量也不同。
并且從表2中可以看出,隨著背景數(shù)據(jù)集中概念的增加,抽取的SKOS_Category中的特定領(lǐng)域概念的數(shù)量也在增加。在使用AMO抽取SKOS_Category中的特定領(lǐng)域概念時(shí),背景數(shù)據(jù)集中概念的數(shù)量為63個(gè),共抽取SKOS_Category中的概念200個(gè);使用STSM抽取SKOS_Category中的特定領(lǐng)域概念時(shí),背景數(shù)據(jù)集中的概念為146個(gè),抽取到SKOS_Category中的概念338個(gè)。因此可以發(fā)現(xiàn),隨著背景數(shù)據(jù)集中概念數(shù)量的增加,抽取到的SKOS_Category中概念的數(shù)量也在明顯增加。當(dāng)使用STSM和AMO同時(shí)抽取SKOS_Category中的特定領(lǐng)域概念時(shí),背景數(shù)據(jù)集中的概念為209個(gè),但是抽取到的概念只有366個(gè),這是因?yàn)镾TSM和AMO同屬于金屬材料本體。同時(shí),在AMO本體中,“Steel”歸為“Alloy”下的子類,并且基本都是與“Alloy”相關(guān)的概念名稱,關(guān)于“Steel”概念的信息很少,這就導(dǎo)致使用AMO本體抽取的領(lǐng)域概念較少。通過上述分析,說明該抽取方法在根據(jù)該領(lǐng)域其他本體進(jìn)行抽取時(shí),也能獲得相對滿意的效果。
3.4 使用睡眠醫(yī)學(xué)領(lǐng)域本體評估抽取方法
為了評估該抽取方法在其他領(lǐng)域的適用性,本文使用不同于金屬材料領(lǐng)域的睡眠醫(yī)學(xué)領(lǐng)域本體SDO[6]抽取SKOS_Category中的領(lǐng)域概念。因?yàn)槭褂玫谋倔w領(lǐng)域不同,所以適當(dāng)?shù)馗某槿》椒ㄖ械南嚓P(guān)閾值。在此次實(shí)驗(yàn)中,將使用SMOA和LCS算法進(jìn)行篩選過程中的TH1設(shè)置為0.88,TH2設(shè)置為0.82,其他閾值不變。其結(jié)果如圖4所示。
圖4展示了使用SDO本體抽取SKOS_Category中領(lǐng)域概念的結(jié)果,一共抽取出156個(gè)與該本體相關(guān)的概念,圖中A區(qū)域和B區(qū)域展示了其中部分抽取結(jié)果。在B區(qū)域中展示了與當(dāng)前SDO本體相同領(lǐng)域的概念,在SDO本體中存在“Sleep function”“Sleep apnea disorder”等關(guān)于睡眠的一些概念,通過本文提出的抽取策略可以獲得SKOS_Category中相同領(lǐng)域的概念,如“Sleep”“Sleep_disorder”“Sleep_medicine”等。并且利用本文的抽取方法還能夠抽取出與當(dāng)前領(lǐng)域本體SDO相關(guān)的領(lǐng)域概念,如A區(qū)域展示的“mind”及其相關(guān)的概念“Thought”“Brain”等。同時(shí),通過調(diào)整TH1和TH2,能夠獲得不同數(shù)量與當(dāng)前領(lǐng)域本體相關(guān)的概念。所以本文提出的抽取策略同樣適用于其他領(lǐng)域,并且能夠得到較好的結(jié)果。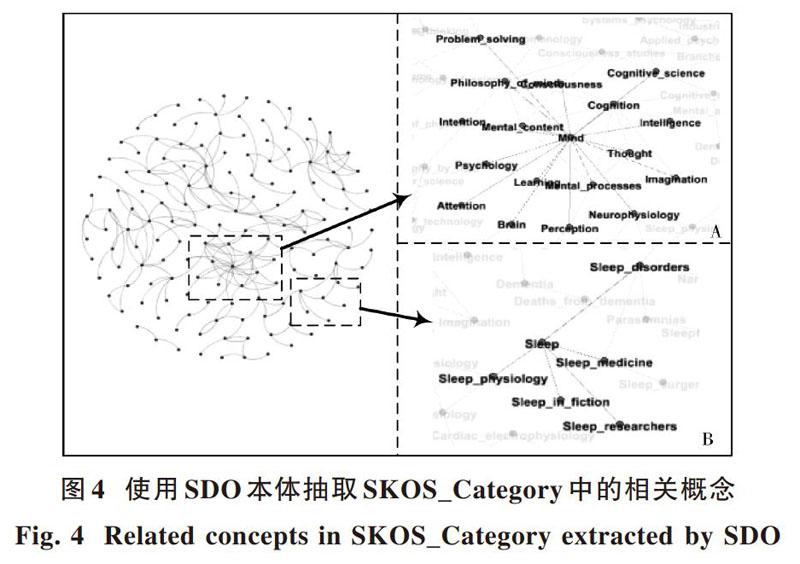
4 結(jié) 論
本文提出根據(jù)領(lǐng)域本體抽取DBpedia中相應(yīng)領(lǐng)域知識的方法。該方法利用領(lǐng)域本體,Wikipedia和LDA算法獲得種子關(guān)鍵詞集,并對種子關(guān)鍵詞集利用IDLSSD算法抽取DBpedia中的領(lǐng)域知識,同時(shí)結(jié)合當(dāng)前領(lǐng)域本體的schema層,使用SMOA和LCS算法進(jìn)行篩選。實(shí)驗(yàn)結(jié)果表明,本文提出的抽取方法能夠相對有效地提取DBpedia中的特定領(lǐng)域知識,并且不需要人為參與。此外,該抽取策略在應(yīng)用于不同領(lǐng)域本體進(jìn)行抽取時(shí),也能獲得較好的結(jié)果。所以本文提出的抽取方法可以在獲得相對有效的特定領(lǐng)域知識的同時(shí),也能極大地減少人為工作量。然而,該抽取方法只是針對抽取DBpedia中特定領(lǐng)域知識,為了能夠比較有效地抽取其他LOD,下一步打算設(shè)計(jì)更具通用性的抽取方法。
參考文獻(xiàn)
[1] LEHMANN J, ISELE R, JAKOB M, et al. DBpedia: a large?scale, multilingual knowledge base extracted from Wikipedia [J]. Semantic Web, 2015, 6(2): 167?195.
[2] BIEGA J, KUZEY E, SUCHANEK F M. Inside YAGO2s: a transparent information extraction architecture [C]// 2013 ACM International Conference on World Wide Web. New York, USA: ACM, 2013: 325?328.
[3] ZHANG X, LIU X, LI X, et al. MMKG: an approach to generate metallic materials knowledge graph based on DBpedia and Wikipedia [J]. Computer physics communications, 2016, 211: 98?112.
[4] ZHANG X, PAN D, ZHAO C, et al. MMOY: towards deriving a metallic materials ontology from Yago [J]. Advanced engineering informatics, 2016, 30(4): 687?702.
[5] ZHANG X, L? P, WANG J. STSM: an infrastructure for unifying steel knowledge and discovering new knowledge [J]. International journal of database theory & application, 2014, 7(6): 175?190.
[6] WHETZEL P L, NOY N F, SHAH N H, et al. Sleep domain ontology [DB/OL]. [2017?04?16]. http://purl.bioontology.org/ontology/SDO.
[7] SANTOSH D T, BABU K S, PRASAD S D V, et al. Opinion mining of online product reviews from traditional LDA topic clusters using feature ontology tree and Sentiwordnet [J]. International journal of education and management, 2016, 6(6): 34?44.
[8] RAMAGE D, HALL D, NALLAPATI R, et al. Labeled LDA: a supervised topic model for credit attribution in multi?labeled corpora [C]// Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing. Stroudsburg: Association for Computational Linguistics, 2009: 248?256.
[9] FREIRE T, LI J. Using Wikipedia to enhance student learning: a case study in economics [J]. Education and information technologies, 2016, 21(5): 1169?1181.
[10] PASSANT A. dbrec: music recommendations using DBpedia [C]// 2010 ISWC. Shanghai: Springer Berlin Heidelberg, 2010: 209?224.
[11] STOILOS G, STAMOU G, KOLLIAS S. A string metric for ontology alignment [J]. Hermochimica acta, 2005, 3729(15): 624?637.
[12] PROZOROV D, YASHINA A. The extended longest common substring algorithm for spoken document retrieval [C]// 2015 International Conference on Application of Information and Communication Technologies. [S.l.]: IEEE, 2015. 88?90.
[13] ASHINO T. Materials ontology: an infrastructure for exchanging materials information and knowledge [J]. Data science journal, 2010, 9(9): 54?61.
猜你喜歡
現(xiàn)代裝飾(2022年1期)2022-04-19 13:47:32
車迷(2022年1期)2022-03-29 00:50:18
紅樓夢學(xué)刊(2020年4期)2020-11-20 05:52:48
現(xiàn)代裝飾(2020年4期)2020-05-20 08:56:10
現(xiàn)代裝飾(2020年2期)2020-03-03 13:37:44
中學(xué)生數(shù)理化·高一版(2018年9期)2018-10-09 06:46:48
中學(xué)生數(shù)理化·高一版(2017年9期)2017-12-19 12:15:14
湘江法律評論(2016年0期)2016-06-15 20:29:32
初中生世界·八年級(2016年8期)2016-05-14 10:10:17
