基于芯片仿真驗證軟件實現的一種試題庫與試卷庫建設方法
2018-08-01 07:13:10趙鴻昌
中國教育信息化 2018年14期
趙鴻昌
(無錫城市職業技術學院 物聯網工程學院,江蘇 無錫214153)
《國家教育事業發展“十三五”規劃》指出,未來教育信息化的重點是信息技術與教育過程相融合的創新,重點發展教育的效率和質量,并鼓勵社會力量為學校提供信息化課程包和試題庫及試卷庫建設。與此同時,基于移動端的“雨課堂”等軟件與基于PC端的“極域電子教室”等軟件均已實現了課堂習題或試卷的編制和實時發布,國外也有學者研究了試卷中的習題排列順序對學生考試成績的影響[1]。但是,將課程試題庫與試卷庫作為一個整體來設計,并且從整體上提供實用的建設方法仍是國內外研究中尚未論及的,存在諸多難點。
一、試題庫與試卷庫建設的要求
測驗與考試環節作為教學過程中檢測學生學習情況的有效方法,其設計的優劣直接決定了教學質量,因此高效的試題庫和試卷庫歷來是課程建設的重中之重[2]。然而,建設過程存在諸多實現難點。
衡量試題庫優劣的標準主要包括試題能完全覆蓋教學大綱規定的知識點,而且試題的形式和變體足夠豐富從而避免雷同,不要成為令學生厭倦的“題海”。另外,試題庫中覆蓋同一個知識點的相同題型的題目必須標識為互斥題目,以方便后續試卷庫的生成。
衡量試卷庫優劣的標準比較多,很多與試題庫的要求截然不同。盡管各類教育教學的形式千差萬別,核心要求包括:①指定試卷總份數及每份試卷中每類試題的總數;②由經驗豐富的教師指定每份試卷對試題庫中的知識點產生有效覆蓋的要求,表現為必須覆蓋的知識點集合,從而避免必要知識點的遺漏;③試題抽取時要具有一定的隨機性,表現為多套試卷之間試題的重復率要有上限;④能夠使用試題庫中標識的互斥題目的信息,避免相同知識點和類型的試題重復出現于一份試卷中。
衡量試題庫和試卷庫整體建設水平的另一個重要指標就是信息化工具的應用程度,這也是影響實際建設水平的重要指標。一方面,理想情況是試題抽取和試卷的排版工作要盡量自動化,以實現試題庫改動后試卷庫的即時生成,但是當前絕大多數情況下涉及太多的人工操作,出題人疲于應對從而令試卷庫的整體建設常常流于形式。另一方面,試題庫和試卷庫軟件本身的研發效率也是一個重要考量,而能解決上述問題的此類軟件的研發一般是非常困難的,只能考慮借用現有的成熟軟件解決最核心、最難以實現的隨機約束生成問題。
筆者在此背景下提出一種實用的試題庫與試卷庫建設方法,通過分析芯片仿真驗證領域的隨機激勵生成的原理,找到激勵生成與試卷生成之間的共性,然后通過面向對象的仿真驗證語言System Verilog予以抽象建模,將試卷生成問題轉化為基于芯片仿真驗證軟件的隨機約束生成問題。本文詳細闡述了建模機制及實現技巧,在信息化教育教學領域具有很強的實用性及推廣價值。此外,以成熟的芯片仿真驗證軟件為基礎解決試題庫與試卷庫的建設問題,對于教育信息化軟件的研發尤其是快速原型化也提供了很好的借鑒。
二、試卷生成軟件的工作原理
盡管上述對試卷生成的要求繁多復雜,但是經過分析可見試卷生成軟件的核心難點在于試題的約束隨機抽取功能、試題按知識點的覆蓋功能以及試卷的自動排版功能。筆者結合自身在大規模集成電路仿真驗證領域的工作經驗,發現原理上只要將每道試題是否出現于試卷中編碼為1位數字量,則每道試題即可與集成電路仿真驗證時的一個二進制輸入測試激勵相對應。因此,前兩個核心難點完全等同于集成電路仿真驗證時多個位寬為1的測試激勵的隨機生成,采用目前成熟的集成電路仿真驗證軟件實現是完全可行的。
試卷生成軟件的工作原理如圖1所示。首先準備好試題庫,直接用記事本程序編輯并保存為文本文件即可,每行一道試題。然后在此基礎上按試卷庫的建設要求書寫System Verilog程序并仿真,最后根據仿真結果從試題庫中多次抽取試題組成試卷,并完成試卷的格式排版。需要著重指出的是試卷的自動排版使用成熟的Latex排版軟件實現,生成的PDF文件不但比Word文件格式更穩定從而方便閱讀和打印,而且整個排版過程完全可以一鍵自動運行。可以預見,在素質教育的大背景下,試卷生成的終極目標是按學生定制化,即根據每個學生的知識點掌握情況即時生成最適合個體學習的試卷,因此Latex排版軟件亦是未來試卷庫建設必不可少的工具。
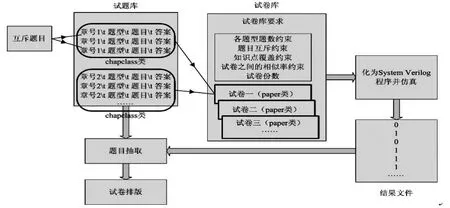
圖1 試卷生成軟件的工作原理圖
三、集成電路System Verilog語言的應用
眾所周知,在描述和處理復雜問題時要用相對復雜的編程語言。System Verilog語言作為一種面向對象的集成電路建模與仿真軟件,輸入激勵的隨機約束生成是其最基本的功能,還提供了靈活的描述硬件行為的類與封裝機制,例如更規范的System Verilog類庫框架是2011年提出的通用驗證方法學 (Universal Verification Methodology,UVM),其應用了集成電路建模與仿真領域最新的面向對象技術[3]。System Verilog對試卷生成問題的適用性表現在以下幾點:
1.問題建模與映射
首先,試題庫中的試題按教材的章號和題型組織,一份試卷中的試題則來自多個章節并具有不同的題型,因此自然地將每章抽象為一個chapclass類。該類的成員變量包括5個隨機數組以對應于5個題型的題目,數組中的元素數目在構造函數中設置,每個元素只能取值0或1,取為1表示此章中此題型的某道題是否出現在試卷中。由此可見,chapclass類中最重要的約束是諸如以下核心代碼中的c0二進制約束,表示每道選擇題是否出現在試卷中。
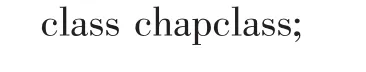

因為試卷中的試題可歸于教材的相應章節,所以將試卷建模為一個名為paper的類,類中的成員變量只有16個實例化的chapclass對象,分別描述課程教材中共15章的題型及相應的試題數量。為理解與設計方便起見,chap[0]不使用,并且每個數組中的0號元素均不使用。試卷paper類的構造函數中設置各章的各類題型及題量,其關鍵代碼如下:

由代碼可見,第二章中的選擇題、填空題、名詞解釋、簡答題以及綜合題依次各有 10、6、3、2、1 道。
至此,試卷生成問題就等效為試卷paper類中的各個對象chapclass的按約束隨機化,每次隨機化的結果是一串取值為0、1的數,1表示需要抽取出的題目。paper類的多次約束隨機化即可生成多份試卷。因為System Verilog語言最顯著的特性正是輸入激勵的約束隨機化,它完全適用于試卷生成問題,其余的建模工作即是在paper類中設定對試卷的各類約束。
2.題目總量約束的實現
生成試卷時首先需要指定各類題型的試題總量,例如,用以下System Verilog功能塊實現對綜合題共有兩道的約束。
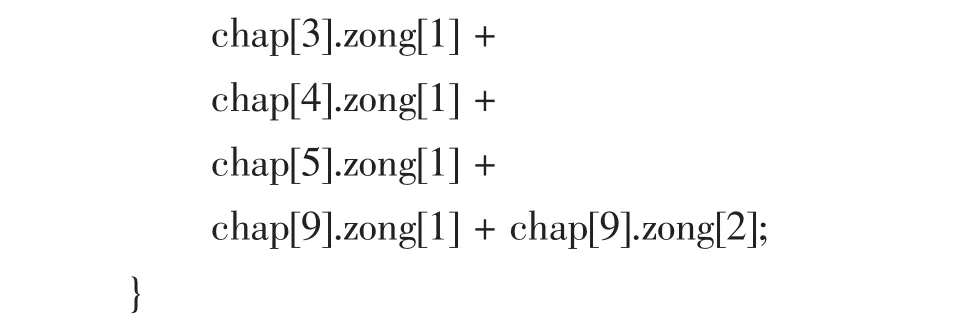
以上約束C5表示第1到第5章各有1道綜合題而第9章則有2道綜合題,需要從中隨機取出共2道生成試卷。
3.互斥題目與知識點覆蓋的實現
約束1==chap[1].xuan[1]+chap[1].xuan[2]+chap[1].xuan[3]就可以限定試題庫中第一章的前三道選擇題只能取一個,從而避免相同知識點的相同類型題目重復出現在一份試卷中。而約束1==chap[1].xuan[1]+chap[1].tian[1]+chap[1].zong[1]則表示第一章中某一知識點對應的不同類型的題目要出現一次,至于是以選擇或填空或綜合題的形式出現則完全由仿真軟件隨機確定。
由此可見,各種形式的試題抽取原則上均可以靈活地映射為System Verilog語言中提供的約束功能。
4.多份試卷的生成
生成多份試卷只需要對paper類的多次隨機實例化,可以用System Verilog語言中的循環命令repeat來實現。例如以下代碼段中的repeat(N)表示生成N份試卷,每次生成則只需調用函數randomize()進行一次不同的隨機化。可見,如下System Verilog程序的運行過程包括100次隨機實例化paper對象并將隨機化的結果打印為一串0或1的數字,依次代表試題庫中的相應題目是否要出現在試卷中。

5.試卷的相似率檢測
不同試卷中的題目需要滿足一定的相似率要求,即限制同時出現在兩份試卷中的題目總數。一種實現方法是構建更大的類,例如構建試卷庫repos類并包含100個paper對象作為成員變量,然后將相似率約束寫在repos類中即可,但是仿真實踐表明相似率約束的數目出現了組合爆炸,如此實現的仿真速度大幅降低。另一種簡單的方法是基于每份試卷表現為一串0或1的數字這一特點,用簡單的C語言程序實現多串數字的對比和統計。以本文為例,只要仿真時指定的試卷份數略大于100,就可以用C語言程序快速篩選出相似率符合要求的100份試卷,實現過程簡單,此處不再贅述。
四、試題抽取與試卷排版
以本文為例,試題庫中共有177道題,因此100份試卷對應的仿真結果文件中包括一串共17700個0或1的數字。首先用Linux中的split命令將其分成100個文件,并命名為paperxx.txt,然后按每個文件中所指定的0或1抽取試題,例如抽取選擇題的Linux腳本命令如下:

結合tiku.txt中選擇題的格式“章號 題型 題目 答案”,上述第1行命令表示將第一份試卷的0、1數字號與試題庫內容按列拼接起來,并且按題型排序后只取出以“1”開頭的題目。隨后的 grep“zz.*zz1zz”過濾出所有題型1即選擇題。之后的腳本命令均為Latex排版軟件要求的文件輸入格式,例如使用iconv命令從GBK到UTF-8的轉碼就是因為Latex排版時的中文宏包默認支持UTF-8編碼。
圖2是生成的試卷首頁,試卷答案和試題紙未作展示。試卷頭信息包括試卷名稱、系別專業、姓名、學號以及評分卡等事先作成一個PDF文件,然后用tikz宏包提供的pgfimage命令插入到試卷的開頭。然后將自動抽取出的題目及答案分類組織即可,所有抽取與排版工作全是Linux腳本命令一鍵完成的。
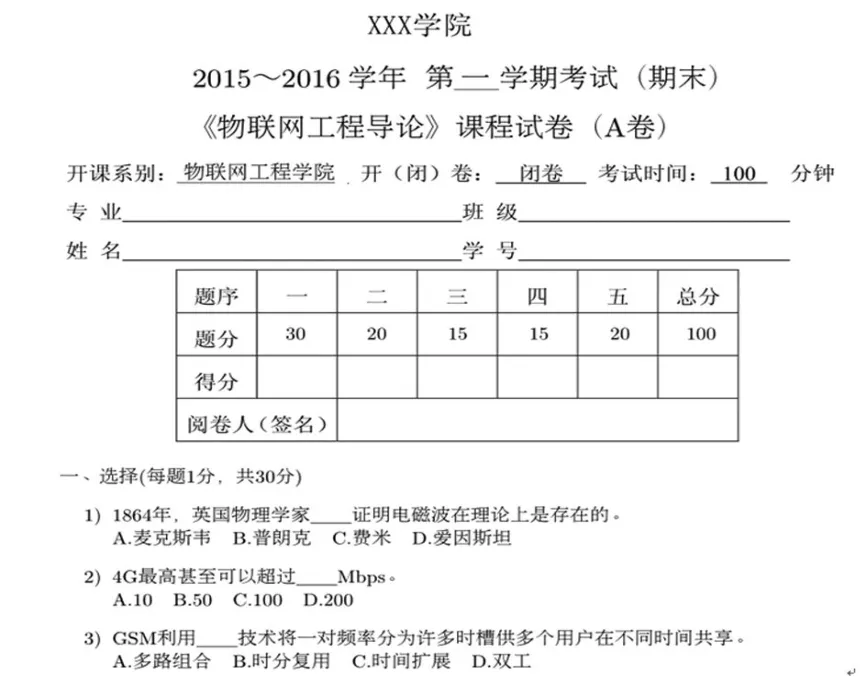
圖2 排版后的試卷樣例
五、結束語
信息技術的運用是無所不在的,本文展示的是絲毫不相關的芯片仿真驗證用到的System Verilog程序解決試卷的自動生成問題。整個項目的實現過程巧妙,具有很強的參考價值。
當前的不足主要包括:①素質教育大背景下,試卷生成的終極目標是學生定制化,即根據每個學生的知識點掌握情況即時生成最適合個體當前發展水平的試卷,每個學生都能實現學習能力的最優發展。這是試卷生成領域很難的研究課題,需要探索學生知識點掌握情況的量化指標。②現有研究與實驗結果大多數都將學生的考試成績作為最終考量點,沒有將學習理論中的知識結構圖作為首要考量點,深入研究知識點網絡的特性與知識點掌握程度之間的關系,給教育信息化帶來了前所未有的挑戰,值得進一步研究和實踐。③試題庫的編輯界面要改進為更易用、更反映知識結構的用戶界面,例如思維導圖界面對于出題者的知識結構理解和調整就大有裨益。最后一點改進是利用芯片時序分析軟件PrimeTime的路徑分析功能,來梳理大規模耦合知識點之間的邏輯關系,以期利用機器學習技術從深層次上為學生挖掘出更利于自主發現新知識的試題,這將加速信息時代學習、應用與創造的融合,為實現未來高效率、高質量的素質教育提供前瞻性的理論研究成果。
