最小角回歸算法(LAR)結合采樣誤差分布分析(SEPA)建立穩健的近紅外光譜分析模型
2018-08-02 09:17:10張若秋陳萬超杜一平
分析測試學報 2018年7期
熊 芩,張若秋,李 輝,陳萬超,杜一平*
(1.華東理工大學 化學與分子工程學院 上海市功能性材料化學重點實驗室,上海 200237;2.德宏師范高等專科學校 理工系,云南 德宏 678400)
近年來,近紅外光譜(Near infrared spectrum,NIR)技術得到廣泛應用,但由于NIR數據通常存在嚴重的共線性問題,對其進行降維和變量選擇的研究一直是該領域的研究熱點。經典的降維方法,如主成分回歸(PCR)和偏最小二乘回歸(PLS),雖能實現維度的大幅度降低,但模型中仍包括所有變量(波長)的信息,模型缺乏可解釋性。有效解決變量共線性的另一方式為變量選擇,近年提出了很多變量選擇算法,如:無信息變量消除法(UVE)、蒙特卡洛無信息變量消除法(MCUVE)[1]、移動窗口偏最小二乘法(MWPLS)、競爭自適應重加權采樣法(CARS)[2]、穩定性競爭自適應重加權采樣法(SCARS)[3]、遺傳偏最小二乘法(GA-PLS)等,這些方法已被廣泛應用于光譜變量的選擇中。
最小角回歸(Least angle regression,LAR)算法由Efron等[4]提出,常用于回歸分析和高維數據的特征選擇[5-7],在光譜建模中應用較少。該算法在前向梯度算法的基礎上,逐步前進、步長適中,無需進行大量迭代運算,大大降低了計算復雜度,提高了運行速度。Liu等[8]利用LAR對臍橙的近紅外數據集進行了回歸預測,相較于PLS模型具有更好的預測性能和解釋性,同時運行速度快于最小二乘支持向量機(LS-SVM)。顏勝科等[9]通過LAR將系數不為0的變量作為初步篩選的變量,進一步結合GA-PLS再次篩選波長,從光譜數據中提取出信息變量,預測精度優于全光譜模型。
建立NIR模型通常需將樣本集劃分為校正集、交互檢驗集、驗證集等,而不同的劃分會得到完全不同的模型。針對這一問題,本課題組[10]基于模型集群分析(MPA)[11]提出采樣誤差分布分析(Sampling error profile analysis,SEPA)算法。SEPA通過蒙特卡洛采樣(MCS)獲得多個(比如800或2 000)數據劃分,建立多個子模型,對子模型的誤差分布進行統計分析,從而解決了單次劃分導致的偶然性問題,并成功應用于PLS模型優化和評價[10]以及模型傳遞[12]。Zhang等[13]還將SEPA與最小絕對收縮和選擇算子(LASSO)[14]相結合,提出了SEPA-LASSO的變量選擇方法,相較于SCARS、MCUVE、MWPLS等方法,SEPA-LASSO選擇更少的變量,獲得了更優異的預測性能。本文采用SEPA的思路,基于LAR回歸系數提出了一種SEPA-LAR的變量逐步篩選方法,用于建立穩健的近紅外分析模型。通過3套近紅外數據進行建模分析,并與PLS、MCUVE、MWPLS、CARS等方法進行了比較。
1 理論與算法
1.1 最小角回歸
矩陣Xn×p表示NIR光譜矩陣,n為樣本數,p為變量數,yn×1表示指標向量。
最小角回歸算法與經典的前向梯度回歸算法(Forward stepwise regression)類似,首先將所有變量回歸系數的初值賦為0,然后找出與因變量y相關性最大的變量,假設為x1。不同于前向梯度算法,LAR將直接沿x1的方向對y逼近,直至下一個變量x2出現,使得x1、x2與當前殘差具有相同的相關性,再沿x1與x2的角平分線方向找到第3個變量,以此類推。LAR算法的每一步路徑均保持當前殘差與所有入選變量的相關性相同。
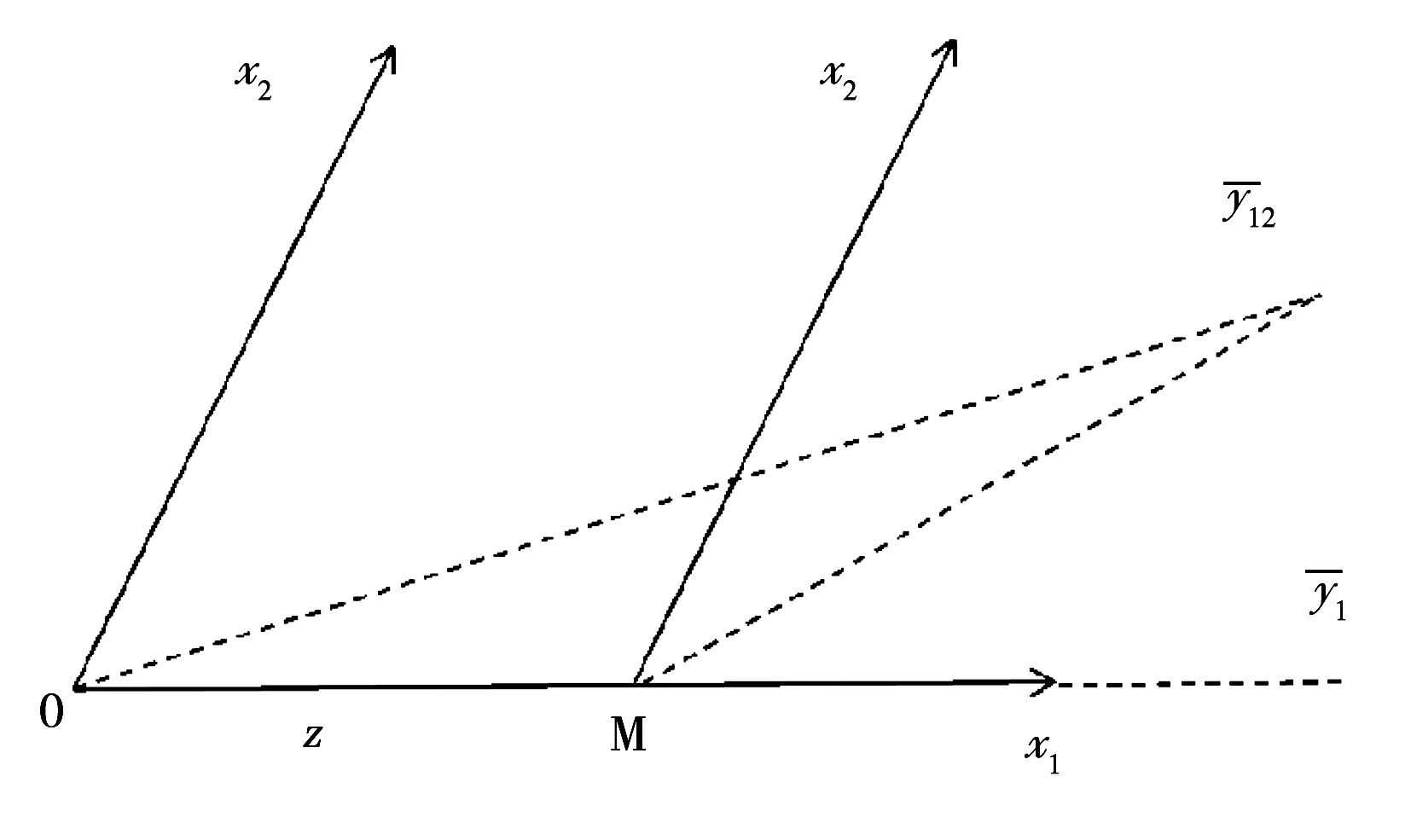
圖1 變量數為2時LAR算法路徑示意圖Fig.1 The path of LAR algorithm in case of 2 variables
LAR的具體運算步驟可參考文獻[4]。
1.2 采樣誤差分布分析(SEPA)
以交互檢驗的計算過程為例,按3個步驟對SEPA(SEPA-CV)進行說明:設采樣次數為N,首先通過MCS將樣本集合劃分為校正集和交互驗證集,獲得N個不同的樣本集合劃分;然后分別對各樣本集合建立校正模型,并計算其交互驗證預測均方根誤差(RMSECV),對所有得到的N個RMSECV誤差數據進行統計分析;最終綜合考慮RMSECV中位數及其標準偏差(STD),以及誤差分布輪廓(傾向于正態分布的優先選擇)來選擇隱變量。由于采用隨機選擇樣本集劃分,并多指標綜合考慮誤差分布,因此所選擇的參數和建立的模型更加穩健。
1.3 最小角回歸結合采樣誤差分布分析(SEPA-LAR)建立穩健模型
SEPA-LAR的基本思路是通過N次Monte Carlo采樣得到N個劃分,對每個劃分進行LAR計算獲得不同的變量選擇集合以及各變量集合下的LAR回歸系數,對同一變量數集合,N個劃分將得到N個變量選擇結果。對相同變量數集合下的回歸系數進行統計分析,統計各變量回歸系數的絕對值之和,其值越大說明該變量越重要,因此選擇回歸系數絕對值之和最大的若干個變量作為候選的變量選擇集合。利用這些變量集合建立PLS模型進行交互檢驗,以確定最佳變量集合進行建模。
SEPA-LAR步驟如下:
①通過N次MCS,得到N個不同的樣本子集(校正集和驗證集),其中校正集的樣本數均為n。對每個子集進行LAR計算,得到n-1個變量選擇集合(其變量數i為1~n-1)。N個子集的所有變量選擇集合共計N×(n-1);
②對每一變量數i的所有變量選擇集合(N個),統計每個變量的回歸系數絕對值之和,將該值進行降序排列,選擇前i個變量。可獲得i從1到n-1的n-1個變量子集;
③采用SEPA和PLS進行交互驗證,計算各變量子集下的RMSECV,以RMSECV中位數和STD為依據選擇最佳變量子集;
④在最佳變量子集下,利用SEPA-PLS選擇最佳隱變量數;
⑤用最終選定的最佳變量子集以及隱變量數建立PLS模型,并用獨立驗證集對模型進行評價。
1.4 計算方法
所有計算在MATLAB(Version 2010a,The MathWork,USA)環境中自編程序完成,所有數據均進行均值中心化處理,以消除光譜的絕對吸收值,突出樣品間差異。對比方法PLS、MWPLS、MCUVE以及CARS的隱變量數目由十折交互檢驗確定,其中,MWPLS窗口大小設為15,MCUVE迭代次數設為100,CARS迭代次數設為100。
對整個數據用Kennard-Stone(K-S)方法[15]劃分出一定數目的樣本組成獨立驗證集,用以評價模型。其余樣本進行SEPA-LAR計算和PLS建模。在SEPA-LAR算法中,MCS采樣次數N均設為2 000,隨機抽取的校正集和驗證集比例設為60∶40應用在“1.3”模型的步驟①和③。
2 數據集
2.1 玉米數據集
數據集下載自http://www.eigenvector.com/data/Corn/index.html,包含80個玉米樣本的近紅外光譜數據,波長范圍1 100~2 498 nm,分辨率為2 nm,共700個波長點。本文采用m5儀器測得的光譜數據和玉米樣品的濕度數據,濕度在9.377%~10.993%之間,獨立驗證集有20個樣本。
2.2 柴油數據集
數據下載自http://www.eigenvector.com/data/SWRI/index.html,為柴油樣本的近紅外光譜數據,波長范圍750~1 550 nm,分辨率2 nm,共401個波長點。本文采用密度數據,密度為0.781 8~0.872 8 g/mL。共395個樣本,獨立驗證集195個樣本。
2.3 奶酪數據集
奶酪樣本購于上海某大型連鎖超市,產自8個不同品牌廠家,共107個樣本。用微型近紅外光譜儀(INSION近紅外檢測器,德國)采集光譜,波長范圍909~1 860 nm,分辨率為8 nm,共116個波長點。奶酪中脂肪含量采用GB 5009.6-2016堿水解法[16]進行測定,含量范圍為8.21~26.65 g/100 g,平均含量為19.51 g/100 g,獨立驗證集37個樣本。
3 結果與討論
3.1 玉米數據集預測
利用K-S方法選擇的60個樣本進行SEPA-LAR以及PLS建模,其余20個樣本為獨立驗證集。
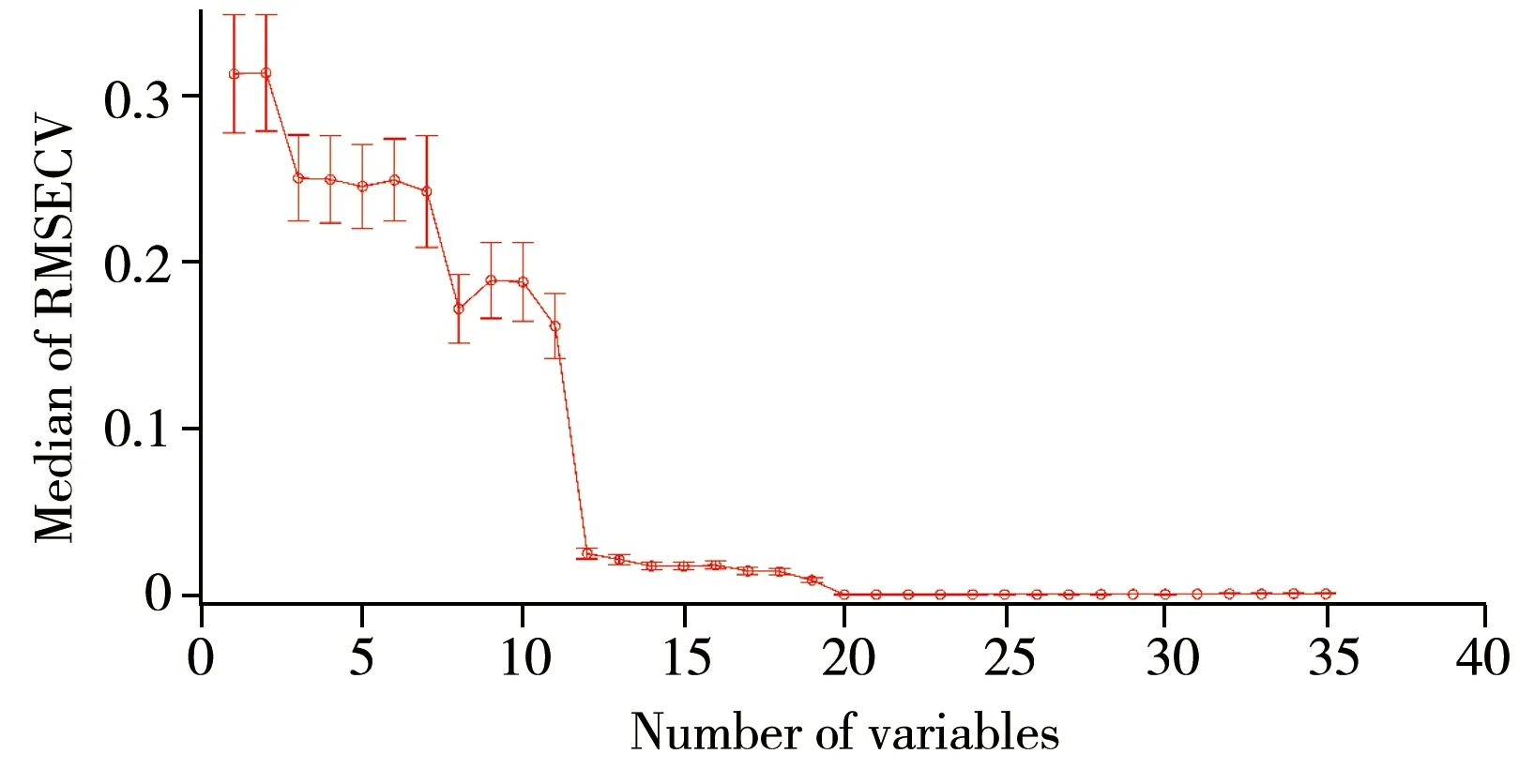
圖2 基于SEPA的不同變量數的交互檢驗結果Fig.2 Variation of RMSECVs with the number of variables based on SEPA
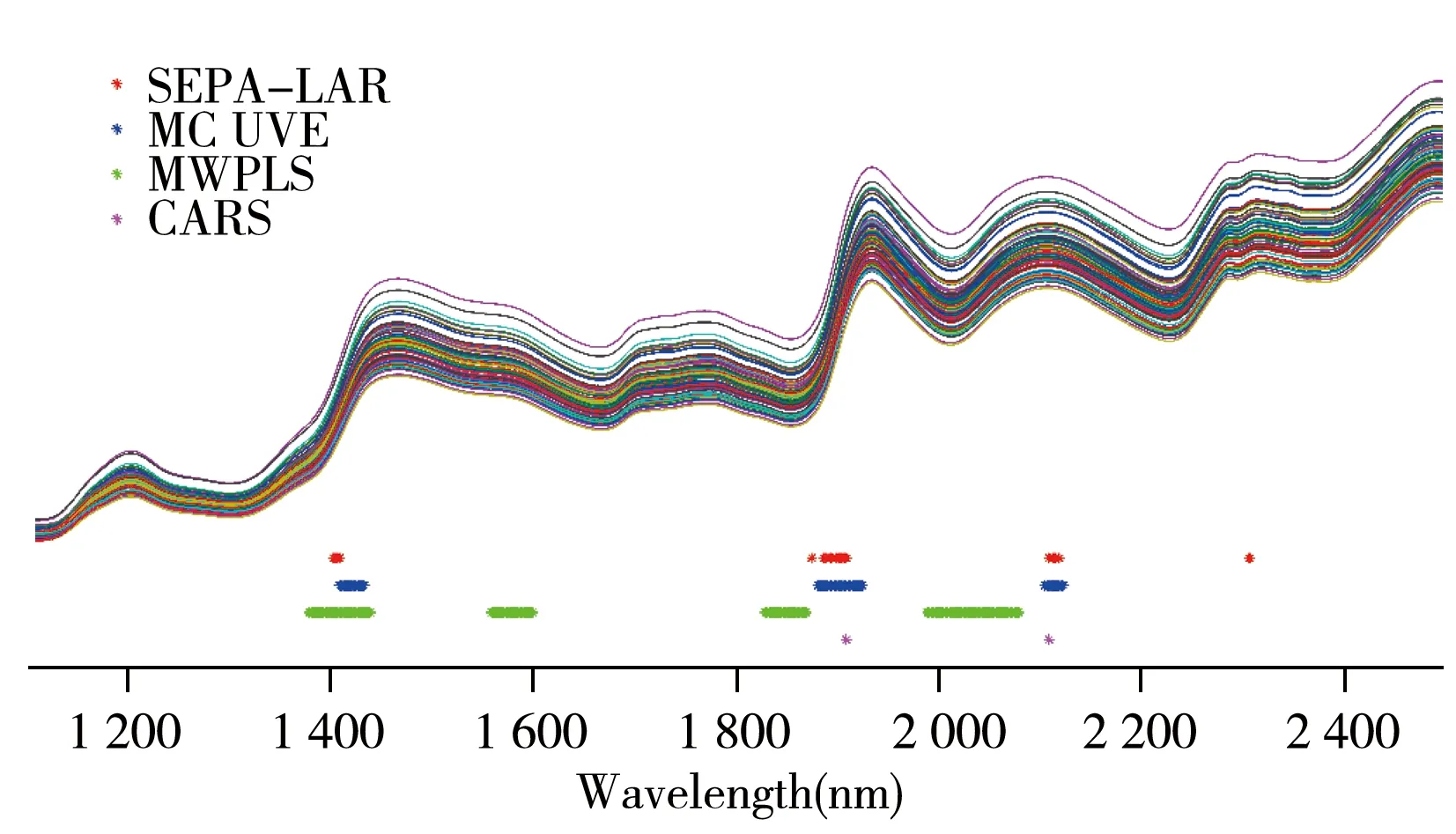
圖3 玉米數據中SEPA-LAR、MCUVE、MWPLS以及CARS選擇的變量Fig.3 The variables selected by SEPA-LAR,MCUVE,MWPLS and CARS on corn dataset
3.1.1變量選擇采用MCS方法從60個樣本中隨機抽取24個樣本作為驗證集,剩余36個樣本組成校正集。經LAR計算得到35個變量子集(變量數i=1,2,…,35)。不同變量選擇下的交互檢驗結果見圖2,其中橫坐標表示變量數。由圖2可見,當選擇的變量數低于20時,RMSECV隨著變量數的增加明顯減小,當變量數達到20之后,RMSECV下降趨于平緩,同時STD(圖2中的誤差棒)很小。由此可見,所選的20個變量對于預測玉米濕度具有重要作用,因此最終選擇20個變量用于PLS建模。當變量數為20時,各變量回歸系數絕對值之和的統計結果表明,大部分的波長變量未被LAR選中,而某些特征變量可被LAR選中。LAR能夠篩選出相關性大的變量并賦予其回歸系數,而將其余變量的回歸系數直接賦值為0。由于集合劃分的不同,不同樣本子集下,LAR并非選中同樣的波長變量,SEPA在建模中充分考慮了集合拆分的影響,最終選擇的特征變量是基于大量重復采樣后的統計結果,使所建模型更合理與可靠。
圖3給出了SEPA-LAR、MCUVE、MWPLS以及CARS選擇的波長變量。1 900 nm與2 100 nm左右屬于水分子O—H的組合頻吸收譜帶,1 410 nm左右屬于水分子O—H的一級倍頻吸收譜帶[2],該波長區域對于玉米濕度的預測具有重要作用。CARS選擇了1 908、2 108 nm兩個特征波長,SEPA-LAR和MCUVE均選擇到該重要吸收譜帶內的波長,且兩種方法所選波長基本一致,但SEPA-LAR選中的波長變量更少,其預測精度更高。MWPLS則選擇了更多的波長變量,未選中包含2 100 nm左右的特征波長。
3.1.2模型的評價利用SEPA-LAR選擇的變量以及SEPA-CV確定隱變量數,建立PLS模型,同時分別采用全譜以及MWPLS、MCUVE、CARS波長選擇方法篩選出特征變量建立PLS模型,利用獨立驗證集評價上述模型,表1給出了SEPA-LAR及其他4種方法建模結果的比較。由表1可知,對于獨立驗證集,全譜PLS模型的預測均方根誤差(RMSEP)為0.015 2%,MWPLS-PLS、MCUVE-PLS、CARS-PLS以及SEPA-LAR的RMSEP分別為0.029 0%、0.002 76%、0.000 314%以及0.001 44%。相較于全譜PLS建模,采用MCUVE、CARS和SEPA-LAR方法對變量進行篩選均能提高對玉米濕度的預測性能。相比MCUVE方法,SEPA-LAR通過篩選出更少的變量數,在提高建模效率的同時獲得了更高的預測精度,表明SEPA-LAR對玉米濕度數據具有優異的預測性能。在玉米濕度這類變量特征性強的簡單體系中,CARS方法表現優異,僅篩選出兩個特征變量,預測精度優于本方法及其他對比方法。但當樣品體系復雜時,CARS選擇的波長子集波動較大,建模穩定性變差。而SEPA-LAR通過多指標綜合考慮誤差分布,模型更穩健。

表1 5種方法對玉米濕度的預測結果Table 1 Results of five methods on the corn moisture dataset
nVAR represents the number of selected variables;nLV represents the number of latent variables;RMSEC represents the root-mean-square error of calibration;RMSEP represents the root-mean-square error of prediction
3.2 柴油數據集與奶酪數據集的預測
利用SEPA-LAR對柴油數據和奶酪數據進行了變量選擇和模型建立,并與全譜、MWPLS、MCUVE、CARS方法進行比較。表2為柴油密度和奶酪脂肪數據的建模結果。相較于其他4種方法,SEPA-LAR表現出更優異的建模能力,且選擇的變量最少,模型的預測誤差RMSEP最小。對于柴油密度數據,SEPA-LAR僅選擇了28個波長,RMSEP低至0.001 58 g/mL。將SEPA-LAR應用于奶酪脂肪數據進行建模,所建模型僅含有25個波長,RMSEP為1.13 g/100 g。
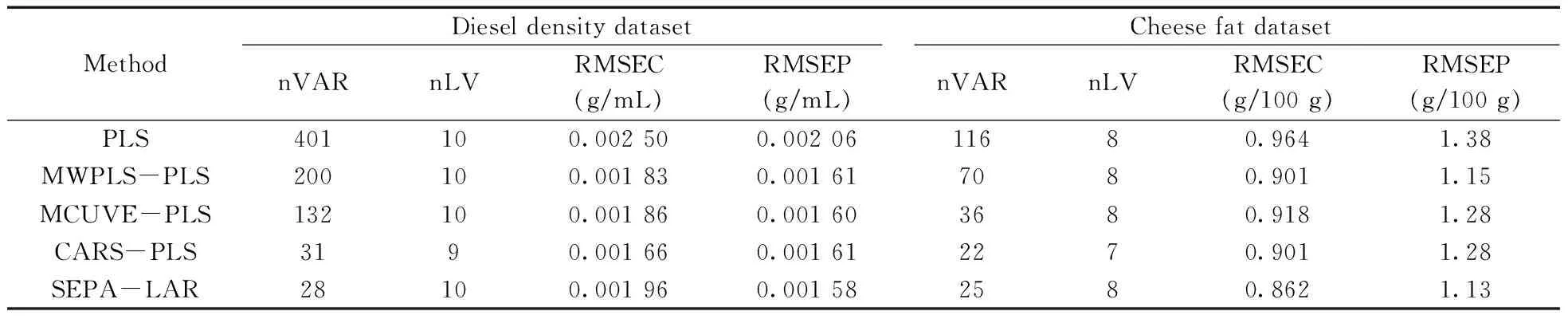
表2 5種方法對柴油密度和奶酪脂肪的預測結果Table 2 Results of five methods on the diesel density dataset and cheese fat dataset
圖4給出了柴油數據和奶酪數據的近紅外光譜,以及4種方法所選擇的波長。由圖4A可見,對于柴油數據,4種方法選擇的波段近似,所選波長范圍集中在750~850、1 000~1 100、1 200~1 300、1 400~1 550 nm,這些區域對應柴油的近紅外主要吸收峰位置。與MCUVE和CARS相比,SEPA-LAR選擇的變量大都被MCUVE和CARS選中,但SEPA-LAR最終選擇的變量更少,模型的預測性能更優異。
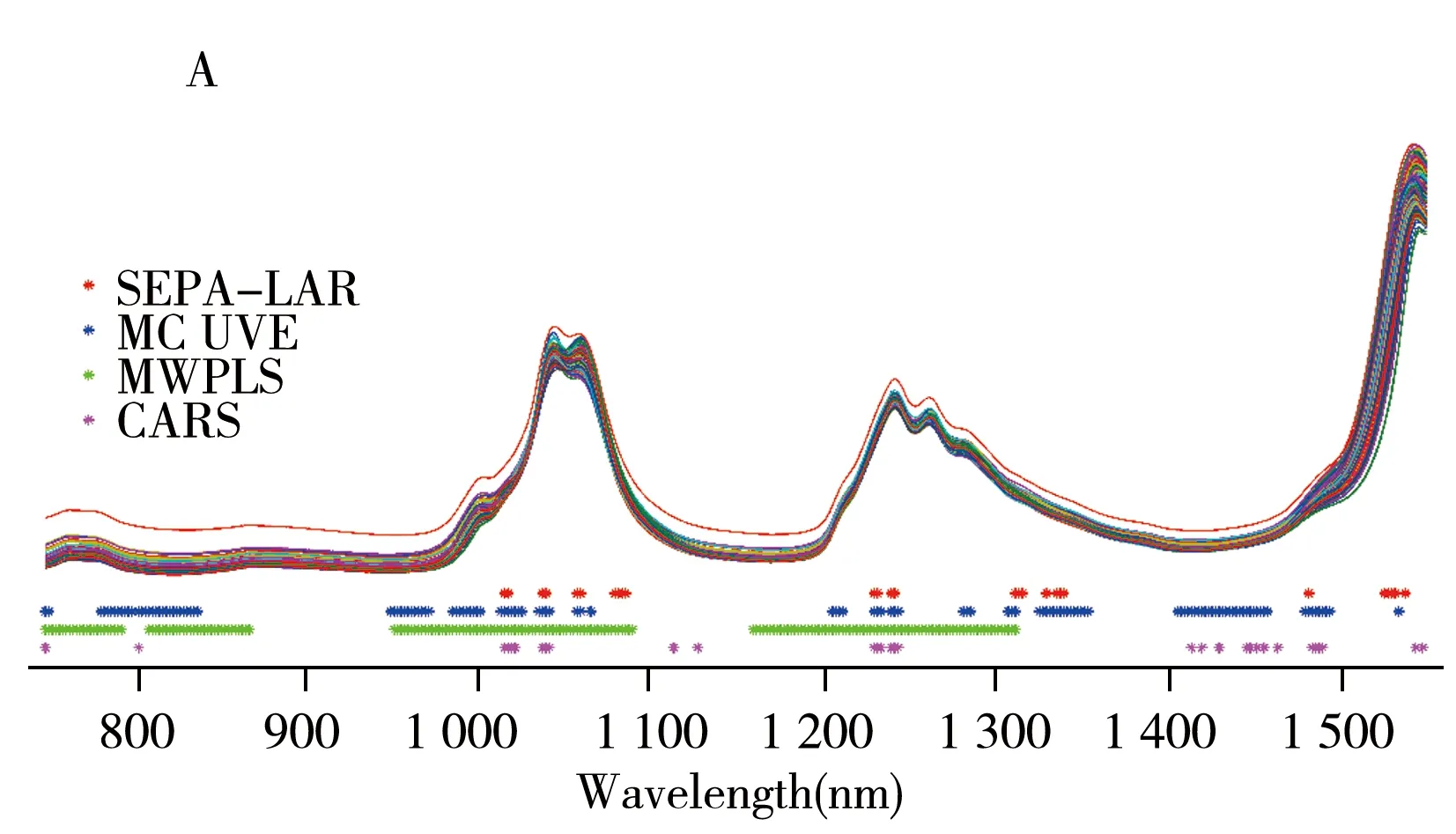
由圖4B可見,4種變量選擇方法選擇了大體相同的波長區域,即900~1 000、1 100~1 350、1 580~1 750 nm。其中SEPA-LAR、MCUVE和CARS選擇的具體波長差別較大,而SEPA-LAR的所選波長幾乎均被MWPLS選中。CARS選擇的波長更少,但其預測性能不如SEPA-LAR。相較于MCUVE,SEPA-LAR則選擇更少的變量,模型的誤差更低。研究結果表明,SEPA-LAR可在選擇較少變量參與建模的同時,提高模型的預測性能。
4 結 論
本文提出了一種基于最小角回歸算法和SEPA算法的變量逐步篩選方法,用于構建穩定的近紅外光譜分析模型。以玉米濕度、柴油密度以及奶酪脂肪數據集為例,首先基于大量的蒙特卡洛采樣計算得到的LAR回歸系數統計結果得出各個變量子集,再采用SEPA框架的思路進行交互檢驗確定最佳變量子集,最后利用得到的最佳變量子集通過SEPA-CV確定PLS模型的隱變量數,從而建立穩健合理的近紅外光譜模型。實驗結果表明,相較于全譜以及MCUVE、MWPLS方法,SEPA-LAR能有效篩選出更少的特征變量,消除原始變量的共線性問題,所建模型具有優異的預測性能,穩定性優于CARS方法,相較于全譜PLS模型擁有更好的可解釋性,有效提高了模型的準確性和穩定性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
