基于PHOG特征的行人檢測算法研究
2018-08-24 07:50:36,,,,,
計算機測量與控制 2018年8期
,, ,,,
(浙江理工大學 信息學院,杭州 310018)
0 引言
行人檢測技術是智能視頻監控領域一種重要的技術,它是行人跟蹤、行為分析等一系列技術實現的前提。行人檢測技術可以廣泛用于自動駕駛[1]、機器人視覺[2]、智能監控[3]等應用中。行人檢測算法自研究以來,一直是研究熱點,吸引了無數的愛好者研究。其檢測的主要內容是使用計算機識別出對視頻中或者靜態圖像中行人,并輸出相應的位置信息。行人檢測算法的主要內容是在檢測過程中,提取出行人的顯著特征,用于分類器判別,從而輸出行人的判別結果。
近年,涌現了很多行人檢測算法,其中基于機器學習的算法表現較好。這類算法主要涉及到分類器和特征描述子的選擇。2005年,Dalal[4]等人提出HOG(Histogram of oriented gradients)特征,該特征因為很好的穩定性和描述能力而被廣泛的研究與應用。HOG算法的特征描述子是對行人輪廓梯度分布的一種描述,該特征描述對局部形變和光照保持較好的魯棒性。在HOG算法的基礎上,提出了很多改進算法[5-7],典型的有DPM[8]算法。DPM算法是Felzenszwalb等人提出的,該算法將行人分解成好幾部分再基于不同分辨率進行檢測,并增加了HOG特征缺少的顏色信息,一定程度上提高了行人檢測準確率。還有一些行人檢測的改進算法,例如基于積分通道[9]等算法,有效加快了行人檢測的速度。其它使用較多的行人檢測算法有HOG+LBP[10],Haar特征[11],還有基于深度學習的算法[13-14]。這些算法都存在檢測速度較慢或者漏檢率較高等問題。
由于行人的非剛性及環境復雜等原因,使得行人檢測存在漏檢、實時性差等問題。針對HOG特征檢測中速度過慢,漏檢率較高的問題,提出一種基于PHOG特征的行人檢測算法。該算法解決了以下問題:1)降低了漏檢率。通過提出PHOG特征,加強了對局部特征的描述能力,增大了目標和背景的差異;2)減少了檢測時間。通過構建特征圖的金字塔,從而避免了對多層提取特征,減少了計算量。并且進行了PCA降維,降低了特征復雜度。
1 HOG特征原理
HOG特征的提取方法是:先灰度化、歸一化圖像,計算圖像的方向梯度特征,再將圖像劃分成多個cell和block。最后串聯窗口里所有的block的特征向量,就得到了該窗口的HOG特征描述子。用訓練好的行人分類器對該描述子進行判別,再輸出判別結果。特征提取過程中,對cell里的像素梯度進行三線性插值,每個cell提取出一個9維的直方圖。用該9維直方圖代表這個cell的梯度特征,再串聯每個block里cell的直方圖特征,得到一個高維的HOG特征描述子,該描述子就是窗口的HOG特征。基于HOG特征的行人檢測試驗結果如圖1所示。

圖1 基于HOG特征的行人檢測
由圖1可知,基于HOG特征的行人檢測存在漏檢和誤檢的情況。誤檢如圖中細方框,漏檢如圖中未標記出的行人。分析產生誤檢的根本原因,發現是該HOG特征對行人的描述子總體上偏向于直立目標的特征,而忽略了行人特有的一些肢體分布特征。產生漏檢的原因是,在提取HOG特征時,該特征對行人目標的描述子較弱,目標特征與背景的差異不大,故產生漏檢。針對這些問題問題,本文提出PHOG特征。
2 本文算法
2.1 PHOG特征的提取
PHOG特征的主要思想是調整方向梯度直方圖的對比度,即增強對行人梯度分布的描述能力,使背景和行人目標的梯度差異更大,從而減少誤檢和漏檢的產生。PHOG特征主要的具體提取過程如下:
1)先計算圖像里每個像素的梯度信息,包括方向和大小。
2)將圖像劃分成多個cell區域。并用含有9個方向的梯度直方圖來統計每個cell里像素的梯度幅值,生成每個cell的特征描述子(descriptor)。
3)對每個cell的方向梯度直方圖進行調整,得到PHOG特征。根據公式(1)和(2)進行調整,使該cell的梯度直方圖整體對比度增大,如圖2所示。
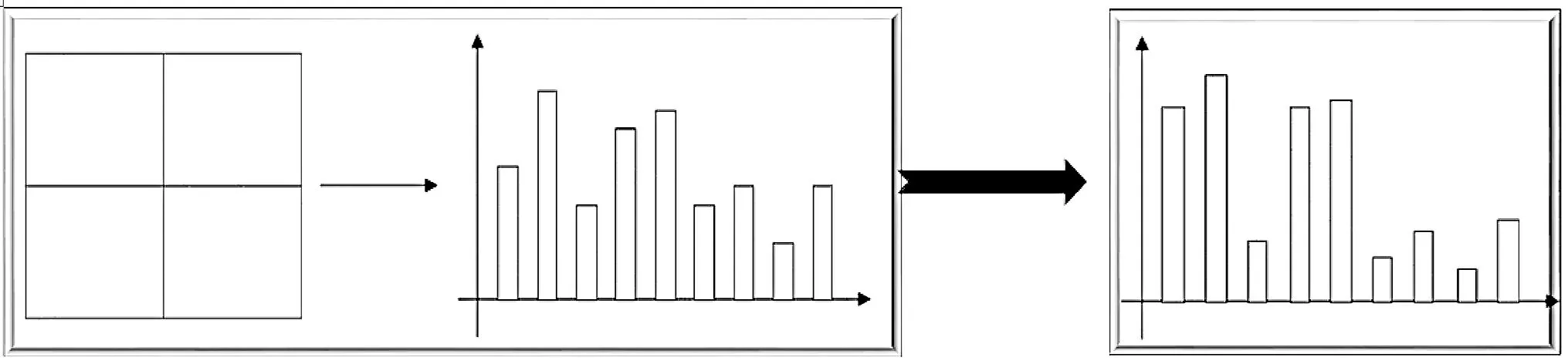
圖2 直方圖對比度增強示意圖
4)將多個cell組合成一個block區域,將block區域內cell的descriptor串聯起來,生成block區域的descriptor。
5)最后將窗口中所有block區域的descriptor串聯起來,得到整個滑動窗口的特征描述子。該特征描述子可用來訓練分類器。
步驟3)中,為了增強特征的局部表現力,對每個cell的方向直方圖進行調整,增大每個cell直方圖的方差(即梯度值大的更大,梯度值小的更小)。根據判別函數來調整cell的直方圖特征,具體的判別函數如式(1)、(2)所示:
(1)
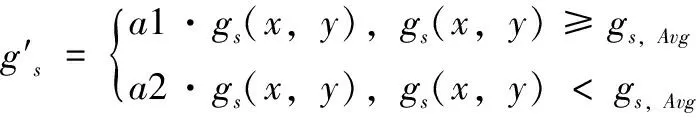
(2)
gs(x,y)是該cell內的(x,y)位置的梯度幅值,該cell屬于s這個block。b是cell內的像素數目。a1和a2分別是調整系數,要求a1≥a2,且a1>1.0,a2>0。當a1>a2時,就會將梯度值大于均值的梯度以a1比例增大,梯度值小于均值的像素梯度會以a2的比例減小;經過上述對梯度幅值的調整,可以增大每個cell直方圖的方差,使cell內的差異更突出。本文實驗中a1=1.5,a2=0.8。特征增強過程如圖2所示。
由圖2可以看出,該直方圖縱坐標值小于均值的bin均被壓縮,大于均值的均被放大。所以整個直方圖的對比度被顯著增強,方差也被增大,對該cell內部特征的描述力更強。根據式子(1)和(2)進行了cell特征的調整,block大小為2×2cell。選取其中一塊block特征,進行特征調整,調整前后的block特征進行統計對比,如圖3所示。對調整前后的特征進行數值分析,如圖4所示。

圖3 調整前后的block特征值

圖4 block特征
觀察圖4可知,在0~38 bin的范圍內,block-PHOG特征比block-HOG特征局部對比度更大,但整體趨勢保持一致。block內特征的方差由0.063 414 083增大到0.098 959 88,提高了大約3.5%。對該block所在的窗口提取PHOG特征,將其可視化展現,并與HOG特征進行對比,如圖5所示。

圖5 傳統HOG特征與PHOG特征對比圖
觀察圖5可知,不僅是行人目標的梯度分布特征被增強,背景的特征也被增強,從而目標與背景的整體差異被增大。
上述基于PHOG特征檢測的詳細步驟如下:
1)預處理部分。對圖像進行灰度化,再利用gamma變換降低噪聲和光照的干擾。gamma壓縮如公式(3)所示。實驗中gamma=1/3。
I(x,y)=I(x,y)gamma
(3)
2)根據公式(4)和(5)計算像素的梯度。
g(x,y)x=I(x+1,y)-I(x-1,y)
(4)
g(x,y)y=I(x,y+1)-I(x,y+1)
(5)
其中:I(x,y)是像素灰度值,g(x,y)x和g(x,y)y分別是該像素點處的x方向和y方向的梯度。該像素點處的梯度幅值和方向分別由式(6)和(7)計算。?(x,y)是該點的梯度方向。本文實驗水平、垂直梯度算子取[-1,0,1]、[-1,0,1]T。
(6)
(7)
3)構建cell梯度方向直方圖。
將cell內像素的梯度插值,再投影到9維的直方圖,用來描述cell內的梯度分布特征。其中每個cell內的梯度方向規定分為9個(0~180度),每個bin對應著該方向的梯度幅值加權和。考慮到部分像素的梯度方向處于兩個bin的臨界區域附近,則必須計算對相鄰區域的影響。所以對該像素梯度方向的相鄰區域進行投影,最后再疊加該像素在相鄰區域的投影值,獲得綜合的梯度幅值。將該幅值作為直方圖的縱坐標。
4)歸一化block值。
由于光照不均勻或者噪聲的影響,導致某些block區域與周圍的區域差異很大,生成的HOG特征變化較為劇烈。這種HOG特征訓練得到的分類器的泛化能力會大大降低。所以為了增加該特征的魯棒性,對block區域內的像素梯度進行歸一化處理,減弱局部劇烈特征對總體特征的不良影響。本文采用的是L2-Norm進行歸一化,如式(8)。ε是一個很小的常數值,本文實驗ε=0.23。
(8)
根據上述檢測步驟,PHOG特征提取過程如圖6所示。

圖6 PHOG特征提取示意圖
本文實驗使用的固定滑動窗口,大小為64×128,cell大小為16×16,block大小為2×2的cell,掃描步長設置為8個像素,所以該窗口的HOG特征向量的大小為9×4×7×15=3 780。由于該特征維數較高,本文在后面章節會進行PCA降維。
3 基于PHOG特征的行人檢測
基于PHOG特征的行人檢測流程如圖7所示。

圖7 基于PHOG特征的行人檢測
對檢測圖像先進行預處理后提取原圖像PHOG特征,得到該圖像的特征圖如圖8所示。觀察圖8可看出,PHOG特征圖相比于傳統的HOG特征,對行人目標梯度分布的刻畫更強。在該實驗原圖的特征圖中,傳統的HOG特征圖對行人的描述幾乎融于背景,觀察不出行人的位置,而PHOG特征可以大致描述出目標的位置及周邊環境的特征。

圖8 PHOG和HOG特征對比
3.1 PHOG特征金字塔
在提完PHOG特征后,為了加快檢測速度(在不降低檢測精度的前提下),本文提出對PHOG特征圖構建8層特征金字塔,替代傳統的構建原始圖片的金字塔。特征金字塔構建的具體步驟是:
先獲取第i=0層(最底層)特征圖,該特征圖即是原圖的PHOG特征圖。獲取第i=i+1層的特征圖。對第i層特征圖進行抽樣,抽樣長度根據2:1。即對第i層特征圖的一個block內的36維PHOG特征抽樣,得到第i+1層一個cell內的9維的PHOG特征。抽樣計算的公式如式(9)。
重復步驟2,直到i=8,獲取完整的特征金字塔。
k=1,2,...,36
(9)
式(9)的原理是計算36維特征數據中,縱坐標值最大的前5個bin值和縱坐標值最小的倒數4個bin值。分別記錄這些bin的橫、縱坐標值,組合得到新一層的9維cell特征。dmaxi,k是第i層的特征圖內block的特征值排序(降序)函數,k是該函數的第k個值。di+1,j是第i+1層的第j個cell的特征值。根據上述步驟構建的PHOG特征金字塔如圖9所示。

圖9 PHOG特征金字塔示意圖
構建的PHOG特征金字塔如圖9所示。由于是對特征圖進行向下采樣獲得的特征金字塔,該計算過程中只用到了簡單的抽樣等計算,相比于傳統的HOG圖像金字塔每層都要重新計算HOG特征,少了大量的計算量。該特征金字塔構建完成后,每層的滑動窗口都得到一個PHOG特征。整體的檢測時間都減少了很多。
3.2 PHOG-PCA特征
如上節所述,每個窗口的都得到一個PHOG特征。但該特征維數高達3 780維,為了加快檢測速度,本文對PHOG特征進行有效地PCA[15](Princpel Component Anlysis)降維,得到PHOG-PCA特征。降維實驗數據統計如表1所示。
由表1可知,本文基于PHOG特征的PCA降維實驗中,當主成分維數N=180時,有保持較高的識別率。當特征維數N在180附近時,檢測的識別率都有所下降。所以本文降維后的PHOG特征取前180個主成分,將該180維的PHOG特征記為PHOG-PCA特征。其中,該降維實驗中用到的行人分類器SVM是基于INRIA數據集訓練得到的。在檢測到行人目標后,再進行窗口融合,就獲得了精確的行人目標位置。

表1 PHOG特征降維實驗
4 實驗設計及分析
4.1 實驗設置
本文實驗采用INRIA數據集,該數據集背景種類較多,行人目標行為變化多樣,對于本文算法的測試具有很好的挑戰性。INRIA數據集含有訓練的正、負樣本和測試樣本。訓練的正、負樣本分別有2416和1218。測試集有正樣本568,負樣本462個。本文算法實驗的硬件的運行環境設置為Intel(R) Core(TM) i3-2410M CPU,4 G內存的筆記本。實驗采用PHOG-PCA+SVM的檢測結構進行檢測。
4.2 SVM訓練
本文行人檢測基于的是線性SVM(Surport Vector Machine)分類器。為提升分類器的泛化能力,本文對負樣本進行擴充。通過對INRIA負樣本圖片進行隨機窗口采樣,獲取到11120張訓練負樣本。將該訓練樣本的PHOG-PCA特征集,用于進行SVM交叉訓練。本文將訓練負樣本分成4組,不斷獲取新的難例,來提升SVM分類器的泛化性能。本文實驗基于該SVM分類器進行行人檢測實驗。
4.3 實驗結果及分析
本實驗參數:滑動窗口固定大小為64×128,cell大小為16×16像素,block由2×2個cell組成,提取的PHOG特征為3780維。再結合Objectness特征,得到O-PHOG特征,再經過PCA降維,得到196維的PHOG-PCA特征向量。
為驗證本文PHOG特征對窗口內行人的描述能力,將PHOG特征、PHOG-PCA特征和其他幾種常用行人特征進行檢測試驗,實驗數據如表2所示。

表2 各種特征的行人識別率試驗結果 %
由表2可知,本文基于多種特征分別進行了5次實驗,并進行了均值統計。相比于傳統的HOG特征,LBP特征和Haar特征訓練得到的分類器識別率較低,識別率均值分別為63.44%,61.14%。HOG特征的識別率最高為78.1%,均值為76.76%。LBP-HOG的聯合特征是的檢測率較傳統HOG有一定程度的提高。本文提出的PHOG特征識別率高于傳統的HOG特征,5次實驗中識別率最高的為86.8%,均值也為86.69%。PHOG-PCA特征和PHOG數值相差不大。
為反映本文特征與漏檢率的關系,將實驗數據統計如圖10,該圖反映了行人檢測漏檢率(Miss rate)和每個窗口的誤檢率(False positve per window)之間的關系。由該圖可看出當誤檢率一定時,本文PHOG特征、PHOG-PCA特征對窗口內目標的描述力最強,所以漏檢率比其余特征都低。

圖10 各特征檢測的漏檢率
為驗證本文提出的特征在整幅圖片中的漏檢率,進行了實驗與數據統計,如圖11。觀察圖11,PHOG特征和PHOG-PCA特征的漏檢率整體偏低。相比于傳統HOG檢測,在FPPI為10-2時,本文算法將漏檢率從35%降到了22%。分析原因是PHOG特征不僅增強了對行人目標的描述,而且也突出了背景的特征,進而增大了兩者間的差異,使分類器更易識別目標。實驗檢測結果如圖12所示。
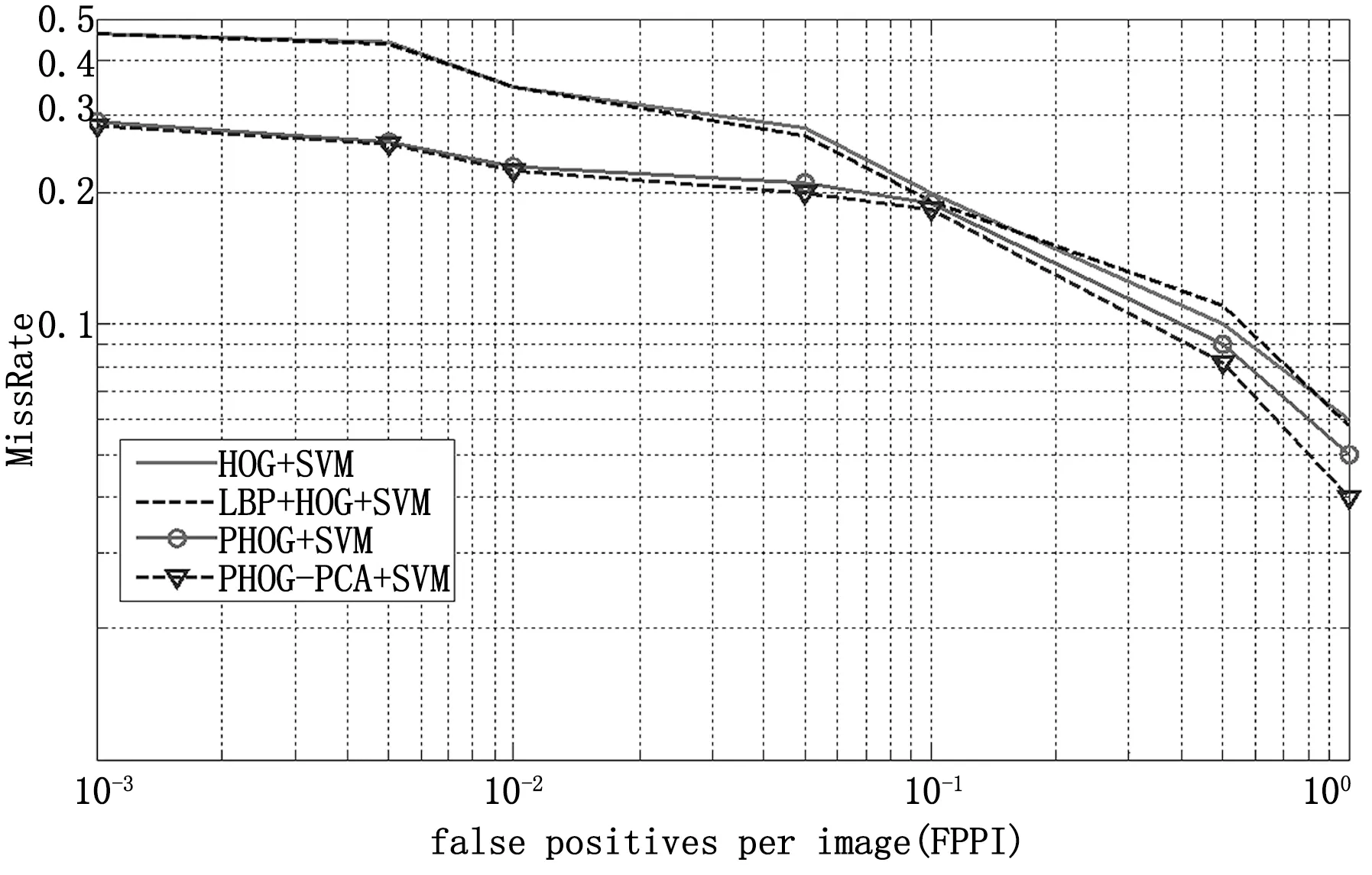
圖11 各特征實驗對比
本文提出的基于PHOG-PCA特征的行人檢測實驗結果,如圖12所示。由該圖可以看出,該算法能準確地檢測出圖片中的行人,幾乎沒有漏檢。

圖12 基于PHOG-PCA特征的檢測實驗結果圖
為直觀顯示本文算法檢測速度,將INRIA測試集尺寸縮減為192×256,在該測試集上進行檢測,平均檢測時間統計見表3。由表3可看出,本文提出的算法檢測速度較快,與其余算法時間相差較多,存在很大優勢。

表3 各算法檢測時間比較
5 結論
本文提出了一種基于PHOG特征的行人檢測算法,針對傳統HOG特征的行人檢測中存在較高漏檢和檢測速度慢的問題,提出了解決方法。首先提出了PHOG特征,該特征加強了對目標和背景的描述,有效降低了漏檢率。再通過構建特征金字塔及PCA降維,減少了計算量,進而加快了行人檢測的速度。從實驗結果可以看出,本文算法在行人檢測中有較大優勢。本文下一步的研究計劃是研究行人檢測中存在的遮擋問題,進一步提高行人檢測的準確率。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
