基于染色質免疫共沉淀的高通量測序數據集的順式調控模體發現算法
2018-08-28 08:53:08馮艷霞張志紅張少強
計算機應用 2018年6期
馮艷霞,張志紅,張少強
(天津師范大學計算機與信息工程學院,天津300387)
(*通信作者電子郵箱zhangshaoqiang@tjnu.edu.cn)
0 引言
基于新一代基因測序的高通量技術,特別是染色質免疫共沉淀的高通量測序(ChromatinImmunoprecipitation Sequencing,ChIP-Seq)技術[1],在全基因組范圍內的使用,很大程度上改變了生物學家定位大規模真核基因組順式調控元件和模體的方式[2]。順式調控模體是同一轉錄因子結合位點的序列集合。模體發現問題一直是生物信息學比較重要的研究課題之一。模體所蘊含的遺傳信號,對于在全基因組范圍內研究基因的轉錄與調控機制具有重大意義。在ChIP-Seq技術之前的模體發現,主要是通過比較同源基因或共調控基因非編碼區域的保守性來預測調控元件模體,其主要方法包括:通過多序列比對尋找保守序列片段;通過位置賦權矩陣更新來遍歷調控元件;運用統計取樣的估計方法等。這些方法均取得了較好的預測結果,并應運而生了大量模體發現算法和工具,例如多重期望最大模體提取(Multiple Expectation maximization for Motif Elicitation,MEME)算法[3]、MotifSampler算法[4]、Weeder算法[5]等,為生物學家對真核生物全基因組[6]的解讀和研究提供了有利保障,推動著生物信息學的蓬勃發展。模體發現算法的工作流程如圖1所示。
由于ChIP-Seq單次實驗產生了海量的堿基讀序(reads),通過序列比對拼接及結合峰預測[7]后仍有成千上萬條序列,這比傳統的同源基因或共調控基因序列規模大很多。為了處理如此大規模的數據,近來的算法主要采用“有區別的”(discriminative)模型[8]策略,主要包括:一是選擇數據集的子集作為實驗的輸入;二是在消耗較大數據存儲空間的情況下,運用新型數據結構來節省運行時間;三是將實驗數據集分割成兩個不等的部分,即實驗組和對照組,僅將實驗組作為模體發現算法的核心運行數據,然后根據實驗組發現的模體,與對照組進行比對。上述第一種方法數據損失較多,要預測的結合位點模體信息在子集中可能不保守,從而大大影響算法準確性,例如獨立成分分析(Independent Component Analysis,ICA)和套層抽樣相結合的的模體發現算法——NestedMICA(Nested saMpling and ICA)[9];第二種方法的主要問題是隨著數據規模增加,會成倍增加內存需求和時間復雜性,從而降低了算法運行速度,例如有區別的正則表達式模體提取(Discriminative Regular Expression Motif Elicitation,DREME)算法[10];相比較而言,第三種方法更注重序列數據集的分隔方法,但不恰當的數據分隔可能導致錯誤的結果,例如Amadeus[11]、Trawler[12]。特別是,隨著 ChIP-Seq 數據的海量增長,其噪聲也越來越多,從而導致預測結果具有較高的錯誤發生率(False Discovery Rate,FDR)。此外,模體發現算法在追求時間與空間的高效外,還應準確識別出模體的真實長度。
為了解決上述問題,本文設計了一個基于ChIP-Seq數據集的順式調控模體發現算法——FisherNet,該算法既能提高模體預測的準確率,又能提高算法運行速度。
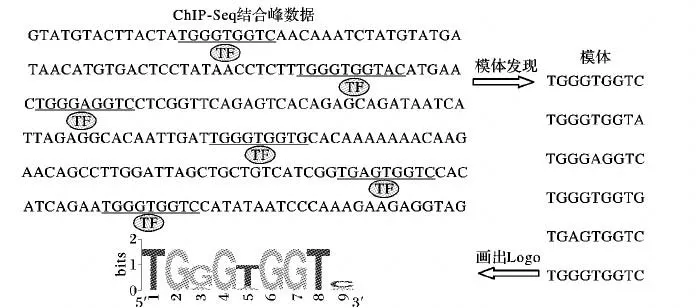
圖1 模體發現流程Fig.1 Flow chart of motif finding
1 數據來源與預處理
為了檢驗算法的優越性,FisherNet算法使用與DREME[10]算法相同的數據集,包括13個小鼠胚胎干細胞(Mouse Embryonic Stem Cell,mESC)ChIP-Seq 數據集[13]、3 個小鼠紅細胞數據集和1個人類淋巴母細胞系數據集。mESC數據集為12個轉錄因子,它是維持多能性和CTCF的關鍵。小鼠紅細胞的數據集為 Gata1[14]、Klf1[15]和 Tal1,是紅細胞生成的關鍵調節者。人體淋巴細胞數據集是維生素D受體包括在使用骨化三醇的刺激前和之后的ChIP-Seq數據。另外,基于人的 ENCODE(Encyclopedia of DNA Elements)[16]數據庫的ChIP-Seq數據集規模超大,本文選取其中的10個有已知模體的轉錄因子(ATF1、ATF3、CTCF、E2F4、EBF1、ECF1、POL2、ZNF274、USF2、YY1)數據集進行比較。這些數據集源文件格式為FASTQ格式。
2 算法的主要步驟
本文算法的流程如圖2所示。
2.1 生成背景數據集
FisherNet算法采用了三階馬爾可夫鏈[17]生成背景數據,即遍歷實驗組ChIP-Seq數據集統計每三個堿基短序列(共43=64種)后出現各個堿基的頻率得到概率轉移矩陣。然后用該轉移矩陣生成與實驗組數據中序列長度和數目相同的背景序列數據集。
2.2 遍歷短序生成哈希表
為了統計每個長度為k的短序(k-mer)[18]在各個序列是否存在,FisherNet分別遍歷實驗數據集和背景數據集中的每條序列并用兩個哈希表分別存儲所有的k-mer信息。哈希表的鍵為k-mer,鍵值為該k-mer所在序列編號集合。因為真核生物的結合位點長度主要介于4~8個堿基長。FisherNet算法默認k從4到8個堿基為窗口長度分別進行遍歷。在遍歷過程中,同時考慮k-mer在序列的互補鏈是否存在,若存在,則將該序列的編號也放到該k-mer鍵值對應的集合中。遍歷過程如圖3所示。

圖2 本文算法流程Fig.2 Flow chart of proposed algorithm
2.3 根據費舍爾精確檢驗計算P值
FisherNet算法采用費舍爾精確檢驗分析每個k-mer的富集情況[19]。對于每個k-mer,通過哈希表查詢記錄下它在實驗數據集和背景數據集中出現的序列條數。如表1所示,a代表某k-mer在實驗組數據集中出現過的序列數,b代表該短序在背景數據集中出現過的序列數,相對地,c和d分別代表該短序在兩組實驗數據集中未出現的序列數。
根據表1通過超幾何分布公式計算P值[20]為:
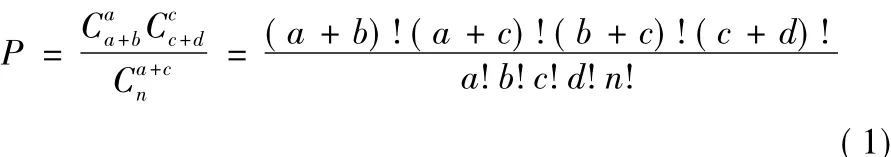
若P值大于意義臨界值0.05(假設檢驗常規設P值的閾值為0.05,在算法中該閾值作為輸入參數可由使用者自主調整),說明該條DNA短序列存在基因信息與背景差異較小,則對其不再考慮。上述計算P值的式(1),對于小規模數據集效果良好,對于大型ChIP-Seq數據集,則階乘n!會是超大的數,甚至超出計算機整數計數范圍。對此,FisherNet引入了斯特林(Stirling)公式,對組合數的計算先取其對數ln,再取指數。斯特林如式(2)所示,與ln C推導如式(3)、(4)所示:
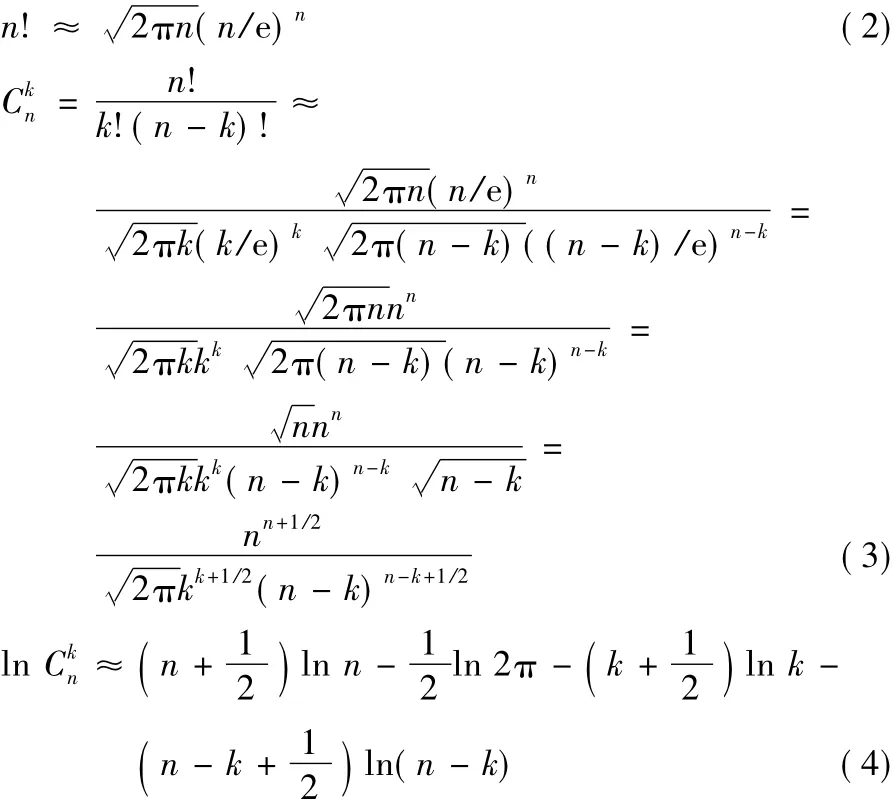
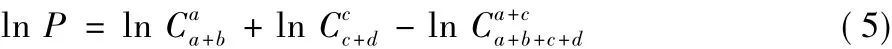
則P值公式就等價于:
對式(1)兩邊取對數得:
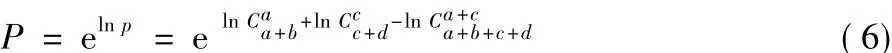

對于每個k-mer,用式(6)計算其P值,若P值小于0.05,以此k-mer為鍵,其P值為鍵值保存到一個新的哈希表。通過比較各k-mer的鍵值,對k-mer進行排序得到候選k-mer集合。

表1 k-mer(模體)序列在實驗組和背景組的數據統計Tab.1 Statistics of k-mer(motif)sequence in experimental group and background group
2.4 構建初始模體
在候選k-mer集合中選取P值最小的k-mer作為種子,依次向下遍歷與種子長度相同且只有一個位置不同的k-mer,將其合并形成初始模體。每合并一個k-mer就要通過計算出現模體和未出現模體的序列數來更新費舍爾精確檢驗表并計算合并后模體的P值,若P值 >0.05,則停止k-mer合并。統計初始序列上各堿基的出現頻率得到位置頻率矩陣P=(P(b,i))4×k[21],其中 P(b,i)表示堿基 b 在位置 i出現的頻率;然后再根據式(7)計算出對應的位置賦權矩陣W =(W(b,i))4×k[22],其中:P(b)是堿基 b 在實驗數據集上出現的頻率(為了能夠計算對數值,當P(b,i)=0,令P(b,i)=10-5)。構建初始模體的流程如圖4中第① ~③步所示。
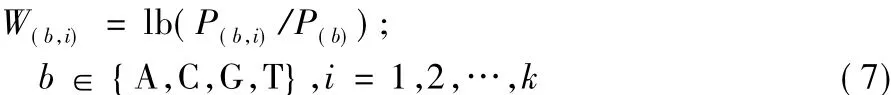
2.5 生成最終模體
用上述生成的位置賦權矩陣掃描候選k-mer集合中的每一個相同長度的k-mer={b1,b2,…,bk},為了衡量一個k-mer是否屬于模體,本文用式(8)(公式中的Smax、Smin分別為位置賦權矩陣中每列元素的最大值的和與最小值的和)計算k-mer的相對分數值R并只保留R≥0.80(根據已知模體統計有80% 的位置具有保守性)的k-mer,以此生成最終模體。如圖4中第④到⑤步所示。
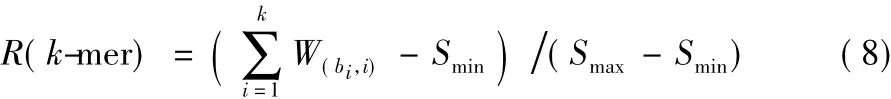
3 實驗與結果分析
FisherNet算法運用mESC的ChIP-Seq數據集和一個意義臨界值對結果進行具體分析。如表2為FisherNet算法預測出的模體發現情況。將算法發現的模體序列與Tomtom數據庫[23]中的真實模體進行比較,針對Tomtom標準數據庫中已有的13個重要模體,FisherNet算法發現了其中的10個。
此外,針對mESC ChIP-Seq數據集,本文分別運行了其他六種被廣泛應用且能發現輔調控因子模體的模體發現算法,即 MEME[3]、Weeder[5]、NestedMICA[9]、DREME[10]、Amadeus[11]、Trawler[12],并將這些算法的預測結果與 FisherNet順式調控模體算法相比較,統計結果如表3所示。其中:N為各算法發現的模體總數;S為與Tomtom標準數據庫中相匹配的模體數;C為算法發現的輔調控因子模體數。在發現轉錄因子模體上FisherNet與 DREME、Weeder、NestedMICA 和 MEME 均達到最高,但在發現輔調控因子模體上FisherNet算法要優于其他算法。這說明該算法在保證發現模體的精確度的同時,能發現更多的輔調控因子模體,FisherNet總體能夠達到80%(即(6.1+10)/20)的精確度。表3最后一列為各算法對13個mESC數據集的平均運行時間,可以看出,FisherNet是所有比對算法中平均運行時間最短的,而NestedMICA和Weeder是運行時間最長的兩個算法。
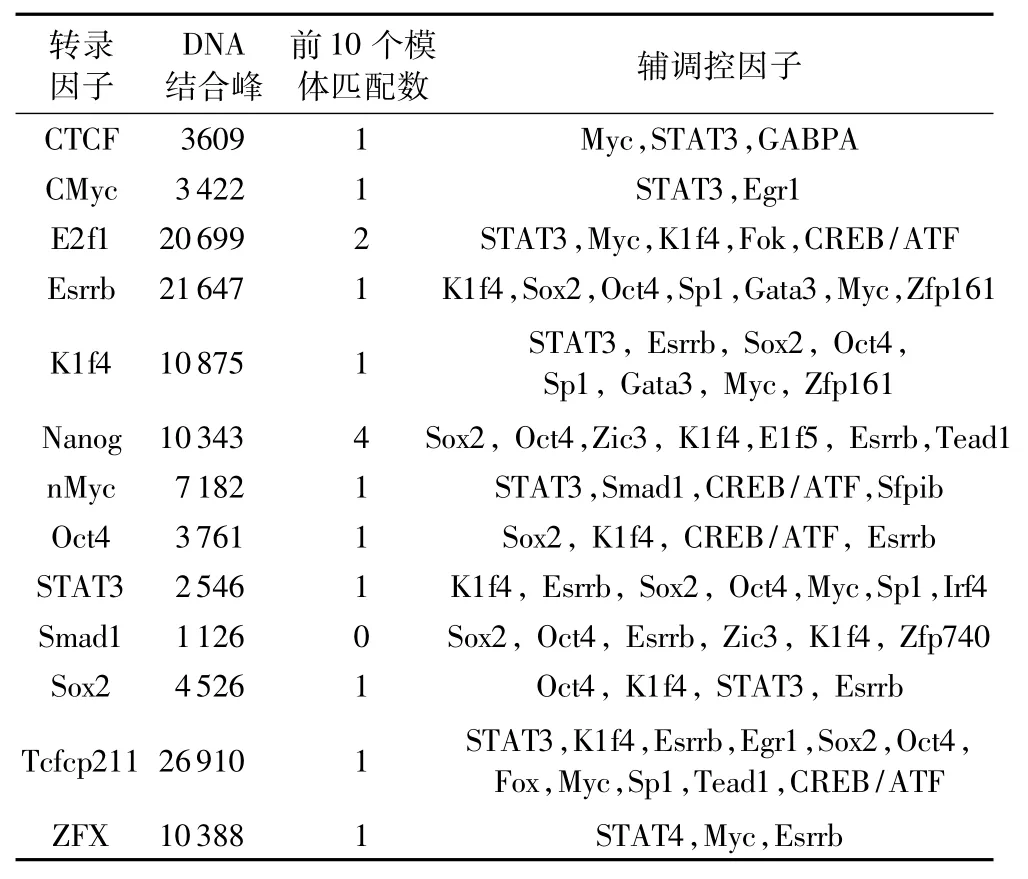
表2 小鼠的ES細胞ChIP-Seq數據集發現的模體Tab.2 Found motif in mouse ES cells ChIP-Seq dataset
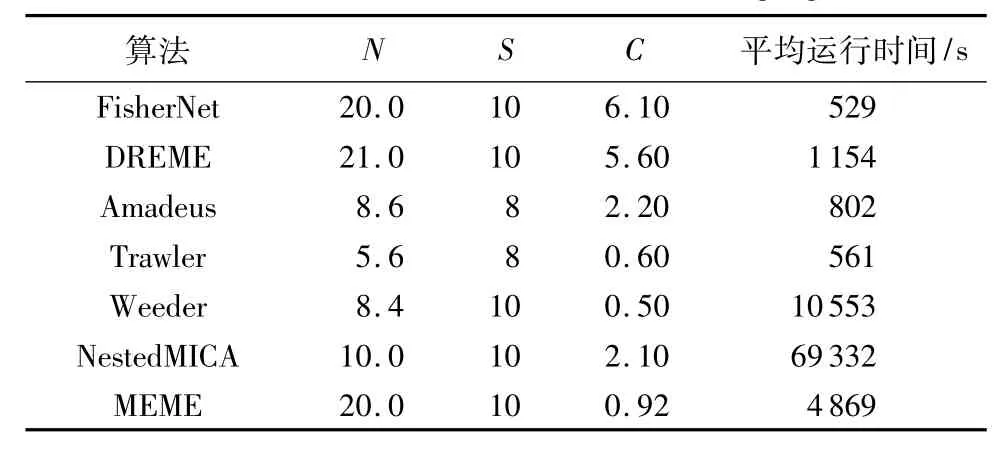
表3 不同模體發現算法結果統計Tab.3 Results statistics of different motif finding algorithms
由于DREME是MEME開發者設計的改進算法,為了進一步檢驗除了MEME、Weeder和NestedMICA之外的四種算法的效率,分別取序列規模為1兆、2兆、3兆和4兆堿基對的數據集進行運算,圖5為四種算法的運行時間評估折線圖。由圖5可以看出,與其他算法相比,隨著數據集序列堿基規模的增加,FisherNet算法運行時間最短且增加幅度不大,充分說明了該算法在運行效率上的優越性。將上述算法應用到選取的ENCODE[16]數據集中,發現每一個真實模體均存在于FisherNet算法輸出的前10個模體中,而其余算法的前10個模體中含有真實模體的準確度均小于80%。
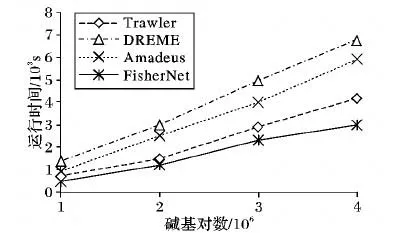
圖5 不同算法運行時間比較Fig.5 Running time comparison of different motif finding algorithms
4 結語
本文基于ChIP-Seq數據的模體發現,以ChIP-Seq結合峰數據集為算法輸入數據,提出一個全新的順式調控模體發現算法(本文的FisherNet由 Perl語言編寫,代碼下載地址為http://www.escience.cn/people/sqzhang/program.html.)。該算法運用費舍爾假設檢驗來尋找區分度高的k-mer并通過位置賦權矩陣進行優化篩選。與其他多種模體發現算法進行比較,驗證了該算法大大提高了模體發現的數目和準確度,成功預測到許多核心模體及輔調控因子模體。該算法目前只對幾種代表性的ChIP-Seq數據進行了驗證,對其他物種的數據是否具有魯棒性有待進一步驗證。
