基于Offload和FPGA的網絡傳輸設計與實現
2018-08-30 08:50:14賀亞龍
機電設備 2018年4期
薛 鐳,賀亞龍
(中國船舶重工集團公司第七一五研究所,杭州 310023)
0 引言
目前主流的操作系統網絡協議棧基本上都使用TCP/IP協議棧。經典的TCP/IP參考模型從上至下分為4個層次:應用層、傳輸層、網絡互聯層和主機到網絡層[1]。在以太網通信中,最大傳輸單元(Maximum Transmission Unit,MTU)規定了經過網絡層封裝的數據包的最大長度。當 IP層需要傳送的數據超過 MTU值時,IP層需要對該數據包進行分片,使每一片的長度小于或等于MTU值;在TCP通信建立連接時,取兩端提供的最大報文長度(Maximum Segment Size,MSS)的最小值作為會話的MSS值,由于TCP分段有MSS值的限制,通常情況下TCP數據經過IP層封裝后的長度不會大于MTU。因此,在一般情況下,TCP數據包不會進行IP分片。如果出現網絡數據包太小的情況,操作系統網絡協議棧及應用軟件對網絡數據的解析計算會消耗大量的CPU時間,導致網絡數據傳輸效率急劇下降,甚至出現丟包。為了解決這些問題,本文著重研究了一種基于offload和FPGA的網絡數據采集方法,將網絡數據的解析工作放到FPGA中進行,然后通過PCIe總線高速傳輸到PC機應用程序中處理。
PCIe總線可以提供更大的總線帶寬,PCIe V3.0支持的最高總線頻率為4 GHz,遠高于PCI-X總線支持的最高總線頻率。PCIe總線支持虛通路(Virtual Channel,VC)技術,優先級不同的數據報文可以使用不同的虛通路,而每一路虛通路可以獨立設置緩沖,從而相對合理地解決了數據傳送過程中存在的服務質量問題[2]。
1 設計原理
本文描述的offload主要是指將原本在網絡協議棧中進行的IP分片、TCP分段、重組、checksum校驗等操作轉移到FPGA中進行,以降低系統CPU負荷、提高處理性能。
1.1 發送模式
TSO(TCP Segmentation Offload)就是把TCP分段的過程轉移到 FPGA中進行,直接把不超過滑動窗口大小的payload下傳給協議棧,而由FPGA進行TCP分段操作,并執行checksum計算和包頭、幀頭的生成工作。
UFO(UDP Fragmentation Offload)是一種專門針對UDP協議的特性,主要機制就是將IP分片的過程轉移到 FPGA中進行,用戶層可以發送任意大小的UDP數據包(UDP數據包總長度最大不超過64k),而不需要協議棧進行任何分片操作。
1.2 接收模式
LRO(Large Receive Offload)在FPGA層面上接收到多個TCP數據包,并將其聚合成一個大的數據包,然后上傳給應用程序處理。這樣就可以減少CPU處理的開銷,提高系統接收TCP數據的能力和效率。
RSS(Receive Side Scaling)可以將不同的網絡數據流分成不同的隊列,再將這些隊列分配到多個 CPU核心上進行處理,從而將負荷分散,充分利用多核處理器的能力,提高數據接收的能力和效率。
1.3 總體功能與結構
網絡數據經過FPGA主控處理后,通過PCIe總線傳遞給PC主機應用程序處理,FPGA網卡傳輸功能框架如圖1所示。

圖1 網卡功能框架圖
2 硬件設計
2.1 芯片選型
網絡電路由PHY芯片及周圍電路組成,PHY芯片選用Marvel公司的88e1111型號,該芯片的特性為:支持GMII、RGMII和MII等接口;具備4個GMII時鐘模式;支持自適應功能;可選擇2.5 V和1.0 V輸入輸出電壓。
FPGA芯片采用Xilinx公司Virtex-5系列芯片,包含多種硬 IP系統級模塊,包括強大的 36 kb Block RAM/FIFO、第二代25×18 DSP Slice、帶有內置數控阻抗的SelectIO技術、ChipSync源同步接口模塊、系統監視功能、帶有集成數字時鐘管理器(Digital Clock Manager,DCM)和鎖相環(Phase Locked Loop,PLL)時鐘發生器的增強型時鐘管理模塊以及高級配置選項[3]。
2.2 FPGA程序設計
FPGA程序的組成框圖如圖2所示。FPGA程序主要實現如下功能:1)集成3個MAC核,實現與PHY芯片的通信以及以太網包的收發;2)根據 IP地址和PORT、數據類型進行網絡數據分包,并加上時間戳信息;3)使用MircroBlaze配置IP/PORT/MAC地址等參數;4)提供 PCIe接口接入 PC機操作系統,處理與PC機的PCIe數據交換。
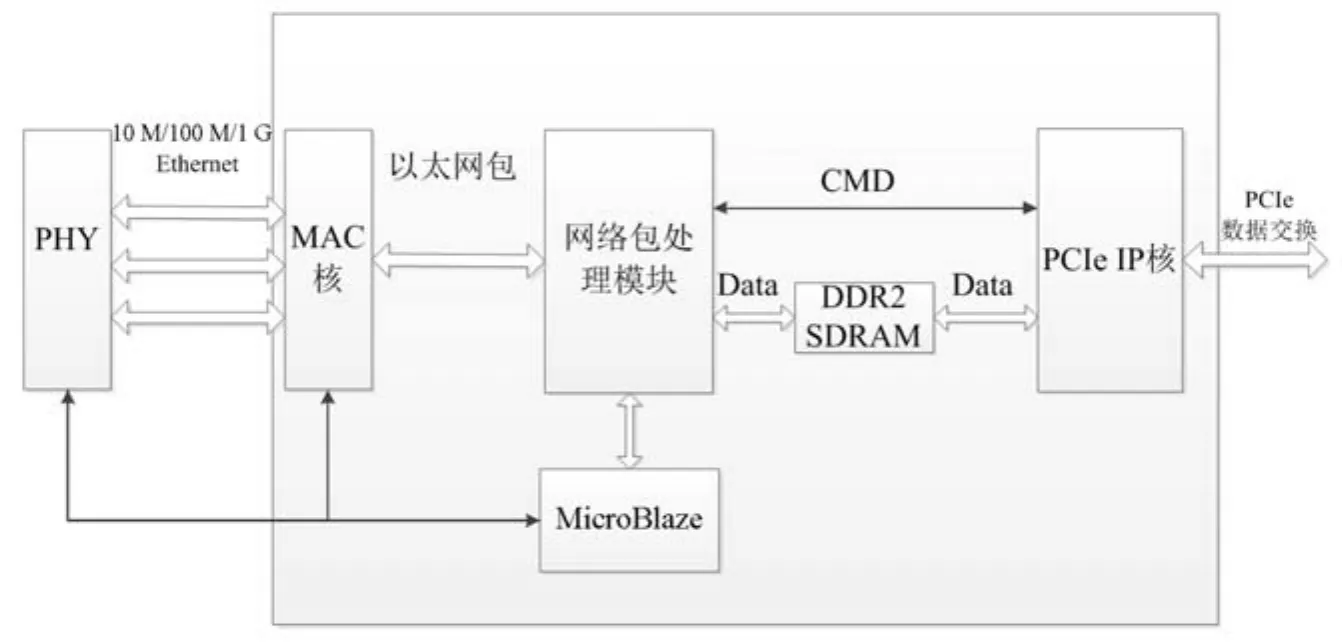
圖2 FPGA程序的組成框圖
2.3 工作流程
本程序對以太網包的處理采用嵌入式操作系統+邏輯模塊的結構,網絡包處理模塊采用片內邏輯資源設計,實現對以太網包 1~3層的解析和數據分發,收包流程如圖3所示。

圖3 網絡包處理模塊收包流程
按照上述流程,大部分以太網包由該模塊處理,或提交主機、或直接丟棄,其他少量命令/狀態包則提交給 MicroBlaze進一步處理,如命令 UDP包、ARP包、ICMP包、TCP包和其他未識別的以太網包等,這樣既確保了對各通道UDP數據包的線速處理,同時利用MicroBlaze內部的TCP/IP協議棧實現復雜網絡處理能力。
MicroBlaze除了解析命令UDP包外,還實現對返回給客戶端的狀態信息的打包,以及FPGA片內外寄存器空間的配置和狀態收集。
3 軟件設計
3.1 PCIe驅動程序設計
PCIe總線支持3個獨立的物理地址空間:存儲器空間、IO空間和配置空間[4]。每個PCIe設備都有一個配置空間,配置空間采用ID尋址方法,用總線號、設備號、功能號和寄存器號來唯一標識一個配置空間[5-6]。
FPGA的PCIe IP核在生成時,會生成相應的PCIe總線號、設備號等ID[7-8],驅動程序通過設備ID和廠商ID對設備鏈進行掃描,進行匹配。驅動與設備匹配之后,驅動程序中申請內存緩沖空間,提供DMA讀寫接口將數據從PCIe總線傳輸到PC機應用程序緩沖空間。
3.2 FPGA程序設計
FPGA程序實現了數據包的過濾,需要完成如下功能。
3.2.1 FPGA過濾規則配置
FPGA已從數字電路設計上實現了通道選擇,緩存大小設置,ARP協議、ICMP協議、IGMP協議、IP協議、UDP協議、TCP協議等網絡數據包過濾配置功能。應用程序需要在初始化階段完成過濾規則的參數配置。
3.2.2 數據緩沖隊列
初始化緩沖隊列,網絡數據包經過FPGA過濾之后,通過驅動程序傳輸進入內存不同協議的數據緩沖隊列。
3.2.3 數據解析
根據網絡協議規范,從各種數據緩沖隊列中取出需要的數據提交給應用程序處理,應用程序工作流程如圖4所示。

圖4 應用程序工作流程
4 試驗驗證
使用本文設計的基于offload的FPGA實現網卡功能,進行網絡數據傳輸,并與普通網卡進行對比,試驗數據如表1所示。

表1 網絡數據傳輸比對
測試結果顯示:基于offload的FPGA實現網絡數據傳輸的網速提升明顯、沒有丟包、網速較穩定無波動情形。
5 結束語
本文設計了基于offload的FPGA實現網絡數據傳輸,其充分運用了FPGA可編程的靈活性,具有結構簡單、易于控制、小型化、低功耗等特點。相關驗證測試結果顯示:該設計傳輸網絡數據正確、工作穩定可靠、傳輸速率提高20%以上、即使PC端應用程序出現卡頓也無丟包、對實時數據的處理與存儲效率有所提升,具有實際工程應用價值。
同時,結合 FPGA豐富的資源及并行處理能力,后續可以考慮優化應用程序軟件架構,進一步提高網絡數據傳輸與處理能力。
