基于在線學習的雷達目標跟蹤技術研究
2018-10-12 01:23:38耿利祥尹曉燕蔡文彬
雷達與對抗 2018年3期
耿利祥,尹曉燕,蔡文彬,李 偉
(中國船舶重工集團公司第七二四研究所,南京 211153)
0 引 言
傳統的α-β濾波和卡爾曼濾波對線性系統高斯過程的跟蹤性能好,但對于非線性非高斯過程性能較差,擴展卡爾曼濾波以及不敏卡爾曼濾波是針對非線性過程進行改進的。基于蒙特卡洛方法的粒子濾波算法在非線性、非高斯系統均表現出一定優越性,近年來得到了研究人員的青睞[1]。交互多模型跟蹤算法在機動目標跟蹤方面表現出了強大的能力[2],另一類算法是利用檢測的方法跟蹤目標。Collin[3]通過尋找最具分辨率的特征空間計算其與目標和背景的相似度比值,選擇比值高的候選樣本作為目標。Grabner[4]提出了基于在線Boosting的跟蹤算法,利用了集成學習算法的思想。為了能夠解決長時間目標穩定跟蹤問題,Kalal Z[5]在視頻跟蹤中引入跟蹤—學習—檢測(Tracking-Learning-Detection,TLD)的跟蹤機制,從而達到目標長時間穩定跟蹤的目的。在長時間雷達目標跟蹤任務中,雜波的干擾和目標本身的機動性是導致目標跟蹤不穩定的兩個主要原因。一方面,復雜的雜波環境直接導致目標被遮蔽、誤檢,使目標跟蹤很容易關聯到雜波,導致目標跟丟跟錯。另一方面,機動目標運動模式參數變化較大,單一模型很難及時準確辨識機動參數,造成模型的不準確,導致算法性能下降。
本文采用了TLD跟蹤框架,引入了在線學習機制,將雷達目標檢測器和跟蹤器通過在線學習算法結合在一起,充分發揮了檢測器和跟蹤器的優勢,同時將多模型算法作為雷達TLD框架中的跟蹤器,提出了多模型優化的在線學習雷達目標跟蹤算法(Multiple Model Tracking Learning Detection,MM-TLD),從而提高目標長時間跟蹤過程中目標跟蹤的魯棒性,減少目標狀態變化和干擾引起的不穩定性。
1 多模型優化的在線學習雷達目標跟蹤算法
1.1 跟蹤-學習-檢測(TLD)算法框架
作為一種全新的跟蹤架構,TLD將跟蹤任務分為跟蹤、學習和檢測3個部分。通過引入P-N學習[6],將單純的跟蹤器和檢測器聯系起來,利用目標更多的時間和空間的信息,使目標更加穩定。其流程如圖1所示。檢測器不斷地修正跟蹤器。跟蹤器對目標進行跟蹤,并且更新檢測器。學習器估計出檢測器和跟蹤器中的錯誤并及時對它們進行更新。
1.2 基于多模型優化的在線學習雷達目標跟蹤算法(MM-TLD)
作為解決目標機動的有效方法,在目標的長時間跟蹤過程中,多模型針對不同的過程噪聲級建立不同模型,并將不同濾波結果經由專家學習機制生成目標檢測分類器的輸入樣本。
1.2.1 多模型跟蹤器
多模型算法(Multiple Model,MM)[7]可以在目標運動模式的結構和參數起伏很大的情況下利用不同的模型估計變化的運動參數,以適應目標多種參數變化,減少目標跟丟的情況。對于雷達目標而言,掃描時所產生的屬性量測均可作為目標屬性特征建立目標的狀態向量X。令Mj表示具有先驗概率Pr{Mj}=μj(0),(j=1,2,…,r)的模型j是正確的事件。在模型j的假定下,k時刻的量測的似然函數為
(1)
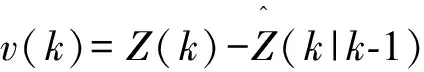
μj(k)
(1)
利用上述概率作為權重進行加權平均就是目標的狀態估計,因此最終得到的組合狀態和協方差估計為
(2)
(3)
跟蹤器中多個濾波器并行工作,每個模型對應的概率在根據學習器學習后模型反饋結果進行更新,糾正跟蹤器中的模型估計,以提高模型估計的概率的準確性。
1.2.2 檢測器
目標檢測器采用了Adaboost算法[8],利用一組串行的弱分類器級聯成一個強分類器。在對待識樣本分類時,前一級分類器判決為正樣本則送入后一級分類器,負樣本則直接輸出。每一級的分類器均判決為正的樣本作為正樣本輸出。Adaboost算法結構的示意圖如圖2所示。
1.2.3 學習器
P-N學習是一個新的基于結構化、未標記數據的學習訓練方法。數據中的結構被稱為正約束和負約束。正約束指定正樣本可接受特征。負約束指定負樣本可接受特征。具體實現步驟如下:
首先以有監督學習的方式利用被標注為正負樣本的目標學習訓練一個初始的分類器。然后,將正樣本加入到正樣本庫內,將負樣本訓練分類器輸出給檢測器,檢測器根據輸入的新分類樣本把結果輸出給P-N專家學習;P-N專家檢查分類結果,將漏檢目標更新到正樣本庫,將虛假檢測更新到負樣本庫,再次訓練分類器,重復迭代直到滿足收斂條件為止。將P-N專家約束得到的結果送給跟蹤器,更新每個模型的概率。
基于多模型優化的在線學習雷達目標跟蹤算法流程如圖3所示。
2 仿真實驗與結果分析
為了驗證本文算法在長時間雷達目標跟蹤過程中的魯棒性和穩定性,實驗運用蒙特卡洛仿真方法仿真了多次長時間跟蹤的數據集,并對每一組數據采用了經典的卡爾曼濾波算法和本文算法作對比。
考慮到雷達回波的起伏以及受雜波的影響,由于雷達回波受雷達目標散射截面的影響,因此利用RCS的分布特征χ2分布來表征雷達目標回波起伏。χ2分布概率密度函數為
(4)
其中,λ為雙自由度。
試驗中,地雜波采用瑞利分布,航跡噪聲采用高斯分布。χ2分布雙自由度λ取2,σ為瑞利系數取0.5,疊加高斯噪聲均值取0,方差取50,時間間隔取2 s。仿真實驗中采用了500組目標作為實驗對象,以相同的算法對該組目標進行跟蹤,其中一個機動目標的仿真航跡和跟蹤結果如圖4所示。
從圖4中可以看出,目標機動性較強的情況下,卡爾曼濾波在跟蹤過程中由于受到了雜波影響導致跟蹤到錯誤的量測,造成了目標跟丟;而本文MM-TLD算法由于利用在線學習機制,當有錯誤跟蹤或者跟丟情況發生時學習機制通過P-N學習及時發現,并且可以通過檢測器重新初始化跟蹤器,最終及時糾正模型中錯誤跟蹤,達到長時間穩定魯棒跟蹤的效果。
為了測試目標跟蹤受雜波影響,實驗模擬了虛警概率10e-3、探測概率0.9條件下的500組目標。每組目標個數為10個勻速運動目標,并計算每批目標跟蹤航跡與模擬的真實航跡的均方根誤差(RMSE),同時測量了算法的平均耗時。實驗模擬了虛警3*10e-3、探測概率0.8條件下500組目標。每組目標為10個勻速運動目標,并采用了文獻[9]的方法計算了目標的平均穩定跟蹤周期數。最后,實驗模擬了虛警概率10e-3、探測概率0.9條件下的500組目標。每組目標個數為10個最大加速度為3 g的機動運動目標,將跟丟的目標個數除以總的目標個數作為目標跟丟率。實驗中,算法采用了目標的9種屬性特征,其中包括點跡中心、高度及俯仰質量、解模糊識別碼、點跡回波數、幅度、環境估值、回波展寬度、多普勒特性、關聯質量。跟蹤數據率2 s。算法運行平臺為CPU:Intel?CoreTMi5-3230M,主頻:2.6 GHz,內存4 GB;算法運行環境:matlab。表1反映了兩種算法實驗的跟蹤結果均方根誤差、跟丟率、每一離散時刻平均耗時和平均穩定跟蹤時間。
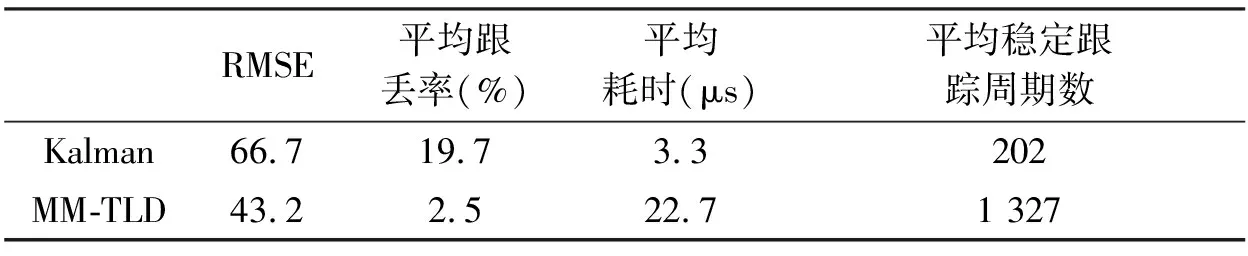
表1 算法性能比較
表1中結果反映出卡爾曼濾波和本文MM-TLD算法在跟蹤性能上有明顯差異。長時間跟蹤任務對目標跟蹤的穩定性要求較高,因此保證目標一直不跟丟很重要。MM-TLD算法的跟丟率較之傳統的算法有了顯著的改善。雖然本文MM-TLD算法的耗時高于卡爾曼濾波算法,但在2 s數據率的數據處理中,本文算法的多批目標的處理時間可以滿足數據處理的實時性,在高穩定性的長時間跟蹤任務中可以滿足任務要求,在此基礎上MM-TLD算法的魯棒性和穩定性更優越。
3 結束語
本文提出了一種基于在線學習的MM-TLD雷達目標跟蹤算法。該算法能夠在雜波環境中準確地對雷達目標進行長時間精確跟蹤。算法通過引入P-N學習,將目標檢測和目標跟蹤結合使用,在TLD架構的基礎上利用多模型跟蹤器產生多個跟蹤訓練正樣本,并利用P-N學習糾正模型中的錯誤,在跟丟情況下通過檢測器重新初始化跟蹤器成功在雜波環境中對雷達目標實現長時間穩定跟蹤。相較于傳統的跟蹤方法,本文MM-TLD算法在保證實時性的基礎上目標跟丟率遠比傳統卡爾曼算法低,取得了更為精確而穩定的跟蹤效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
測控技術(2018年12期)2018-11-25 09:37:34
北京航空航天大學學報(2017年9期)2017-12-18 07:12:25
光學精密工程(2016年6期)2016-11-07 09:07:19
電源技術(2016年9期)2016-02-27 09:05:39
核科學與工程(2015年4期)2015-09-26 11:59:03
電源技術(2015年1期)2015-08-22 11:16:28
電測與儀表(2015年24期)2015-04-09 12:04:36
