MIC-PCA耦合算法 在徑流預報因子篩選中的應用
2018-10-12 11:37:10王麗萍李寧寧馬皓宇紀昌明李貴博
中國農村水利水電 2018年9期
王麗萍,李寧寧,馬皓宇,紀昌明,李貴博
(華北電力大學可再生能源學院,北京 102206)
0 引 言
徑流預報是根據前期水文氣象要素,通過成因分析與數理統計等方法,對未來一段時期的徑流進行科學的預測。準確及時的徑流預報,對于爭取防汛、抗旱的主動權,制定科學的水資源調度方案,確保水利設施的安全和發揮其經濟效益具有重要意義[1]。傳統徑流預報方法一般包括物理成因法和數理統計法等[2,3]。近年來國內外學者從各個方向對徑流預報的理論與方法進行了深入的研究與探索,提出了許多基于現代智能方法和數值天氣預報的綜合預報模型,主要包括模糊分析[4]、灰色系統理論[5]、混沌理論[6]、小波分析理論[7]、人工神經網絡等[8],這些方法對于提高徑流預報結果的精度和可靠性有著重要意義。然而,相比于預報模型,目前對水文預報因子選取的研究相對較少,預報因子作為預報模型的輸入側,直接影響預報結果的準確性和短期預報的實效性,如何從眾多預報因子中篩選出關于預報對象信息含量高、冗余信息少的預報因子集是當前預報工作中的重點。
預報因子(輸入變量)的選取是預報模型應用于實際工程的關鍵問題之一。若模型的輸入變量過多,會導致輸入信息冗余,樣本觀測誤差增加,模型復雜度隨之提升,增大預報誤差和計算時間。輸入變量過少,則模型輸入側提供的預報信息不足,無法很好地解釋輸出變量的變化機理,難以得到準確的預報結果。預報因子的篩選主要利用因子與預報對象間的相關關系,剔除含有不相關和重復信息的因子,確保篩選出高信息量、強相關性的預報因子。現階段,傳統的預報因子選取方法有先驗判斷法、逐步回歸法、相關系數法等。先驗判斷法容易受判斷者主觀意識的影響,缺乏客觀性;逐步回歸法與相關系數法只能處理線性問題,在處理非線性問題時存在較大偏差。朱雙等[9]采用灰色關聯分析來量化預報因子與預報對象的關聯程度,并按關聯度大小從眾多的相關因子中挑選出對徑流過程影響顯著的預報因子;趙銅鐵鋼[10],劉蕊鑫[11]等將互信息運用于神經網絡徑流預報模型輸入變量的選取,并對結果進行了分析,證明該方法具有一定的實用性;紀昌明等[12]建立最大聯合互信息模型進行預報因子篩選,新方法能夠為預報模型提供更加科學的輸入,提高模型的預報精度;閃麗潔等[13]分別以相關系數法、逐步回歸法以及相關系數法-逐步回歸法篩選出的因子作為預報的輸入項,結果表明綜合方法篩選出的預報因子組合可以取得較好的模擬效果;周育琳等[14]驗證了相關系數法-主成分分析法結合的綜合方法優選預報因子的效果優于單一方法。
在現有研究的基礎上,本文引入一種新的衡量相關關系的度量指標——最大信息系數,并將其與主成分分析法結合,提出最大信息系數-主成分分析耦合方法(MIC-PCA),應用于徑流預報因子篩選。并選取BP人工神經網絡作為預報模型,該模型廣泛應用于復雜的非線性系統建模。將耦合算法篩選出的因子集輸入到預報模型中以驗證因子篩選的效果。研究結果表明,相比于現行方法,MIC-PCA法能夠為水文預報模型提供更加準確科學的輸入,提高模型的預報精度。
1 MIC-PCA耦合算法
1.1 最大信息系數
最大信息系數(The maximal information coefficient MIC)是一種基于互信息的度量二維變量間相關關系的指標,由麻省理工學院的David N.Reshef[15]等人于2011年提出。該方法是在互信息的基礎上經不等間隔尋優與矯正處理[16],相比于傳統的相關關系度量指標(Pearson相關系數、Spearman相關關系、互信息等),主要具有以下3個優點。
(1)普適性。MIC法總能找到一種網格劃分,搜索最優的分割點計算其互信息值,使其能有效反應變量之間的任意函數關系(包括線性或非線性關系),在函數的疊加等非函數關系的度量上也有優異的表現。
(2)穩健性。MIC不易受到觀測樣本中異常值的影響,水文資料一般序列較長,往往存在異常值,因此,MIC適合分析水文資料的相關關系。
(3)公平性。對于2組信息量相同的變量,其對應的MIC值也相同,可以放在同一等級上公平對待。當2個隨機變量滿足函數或函數疊加關系時,MIC依概率收斂到1;當2個隨機變量相互獨立時,MIC依概率收斂到0。MIC值理論上在[0,1],相關程度一目了然,使其在不同關系中具有可比性。
因而MIC在相關關系辨識、特征選擇等方面的應用范圍更廣,將MIC引入到徑流預報因子篩選是可行的。
1.2 主成分分析
主成分分析(Principal Component Analysis,PCA)由美國運籌學家Salty在1977年提出,該方法[17]利用降維思想,在保證數據信息損失最小的前提下,經線性變換和舍棄一小部分信息,把多變量轉化為少數幾個綜合變量(即主成分)。PCA的基本原理是借助于一個正交變換,將其分量相關的原隨機向量轉化成其分量不相關的新隨機向量,在代數上表現為將原隨機向量的協方差矩陣變換成對角形陣,在幾何上表現為將原坐標系變換成新的正交坐標系,使之指向樣本點散布最開的若干個正交方向,然后對多維變量系統進行降維處理,使之能以一個較高的精度轉換成低維變量系統。對于一個矩陣來說,將其對角化即產生特征根及特征向量的過程,也是將其在標準正交基上投影的過程,而特征值對應的即為該特征向量方向上的投影長度,因此該方向上攜帶的原有數據的信息最多。主成分空間內每一個主成分表示轉換后有效的新特征。張輝[18]等選用主成分分析法進行經濟學指標篩選。遲國泰[19]等通過主成分分析法刪除了因子負載小的指標。說明了主成分分析法在因子篩選及降維中的實用性。
傳統主成分分析法的計算步驟簡述如下。
(1)形成樣本矩陣,樣本標準化處理。
(2)計算樣本矩陣的協方差矩陣。
(3)對協方差矩陣進行特征值分解,計算主成分貢獻率及累計貢獻率。
(4)按照一定的累計貢獻率選取最大的n個特征值對應的特征向量組成投影矩陣, 得到降維后的新樣本矩陣。
1.3 MIC-PCA
篩選預報因子主要目的是剔除含有較多冗余信息的因子,冗余信息既包括有效信息含量低,對預報對象影響不顯著的信息,又包括重復信息,無論因子的信息含量高或低都可能含有重復信息。所以預報因子的篩選過程分為2個步驟:一是要篩選出信息含量高,對預報結果和預報精度影響顯著的因子。這一步剔除了冗余信息中的無關信息,信息含量低的因子與預報變量相關程度很低甚至無關,輸入到預報模型中不僅會增加模型復雜度,還會影響預報結果的準確性,可能造成對訓練樣本的擬合度不夠,即“欠學習”。二是要剔除高信息量因子中重復信息含量較高的因子。強相關關系的高信息量因子之間存在著較大的信息重疊部分,即因子之間存在較多的信息冗余。這樣的因子輸入到預報方法中會使預報模型過為復雜,影響預報結果的準確性,可能產生“過學習”,增加預報模型的復雜程度。
現有的預報因子篩選方法,一部分以相關系數法、互信息法等為代表,其只考慮最大化因子集的信息含量,而無法保證篩選出的因子集中重復信息少;另一部分以主成分分析法為代表,只考慮對變量空間進行降維,獲得代表原始變量的主要成分,而無法保證篩選出的因子集信息量最大化。目前,很少有方法可以達到2者兼顧,而且單一的方法也很難同時滿足這2點要求。因此,考慮對這2種方法進行有機結合,為預報因子的選取工作提供了新的思路。
基于此,本文提出最大信息系數-主成分分析耦合方法(MIC-PCA),應用于2階段徑流預報因子篩選中。第1階段,通過最大信息系數有效衡量預報因子與實際徑流系列的相關關系,篩選出與實際徑流系列相關性強的因子,這些因子通常為高信息量因子,對于預報變量影響顯著;第2階段,從高信息量因子中剔除掉含有較多重疊信息的因子。
主成分分析的目的就是 “去冗余”。“去冗余”的目的就是使保留下來的維度間的相關性盡可能小,傳統方法中以協方差來描述相關性,本文提出用MIC特征矩陣替代協方差矩陣來衡量“信息”的多少。MIC矩陣的主對角線上的元素與協方差矩陣主對角線上的元素一樣具有“方差”的含義,其他元素是兩兩維度間的相關性度量。因此,用MIC特征矩陣替代協方差矩陣是合理的。通過計算預報因子之間的最大信息系數以建立預報因子MIC特征矩陣,采用主成分分析法剔除信息重疊的因子,得到最終的預報因子集,可保證因子集含有最大信息量的同時重疊信息較少。MIC特征矩陣替代協方差矩陣具有如下優點。
(1)協方差矩陣本身含有單位,需要變量進行歸一化處理以消除單位帶來的影響。
(2)協方差只能表征變量間的線性關系,而MIC可以衡量變量間的非線性關系甚至非函數關系[20]。
(3)MIC基于信息熵,本身就含有“信息”的屬性,可以比協方差更好地度量信息量。
設初始預報因子集為X={X1,X2,…,Xn},預報對象為Y,MIC[21,22]-PCA的具體計算步驟如下。
(1)在2個因子的散點圖(集合D)上進行x×y劃分,將其元素按x值劃分到x個格子中,按y值劃分到y個格子中。
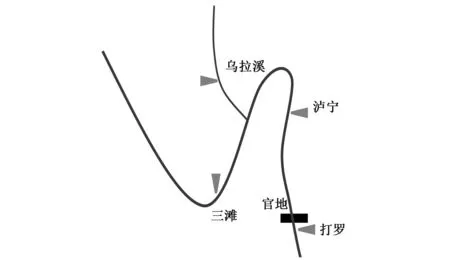
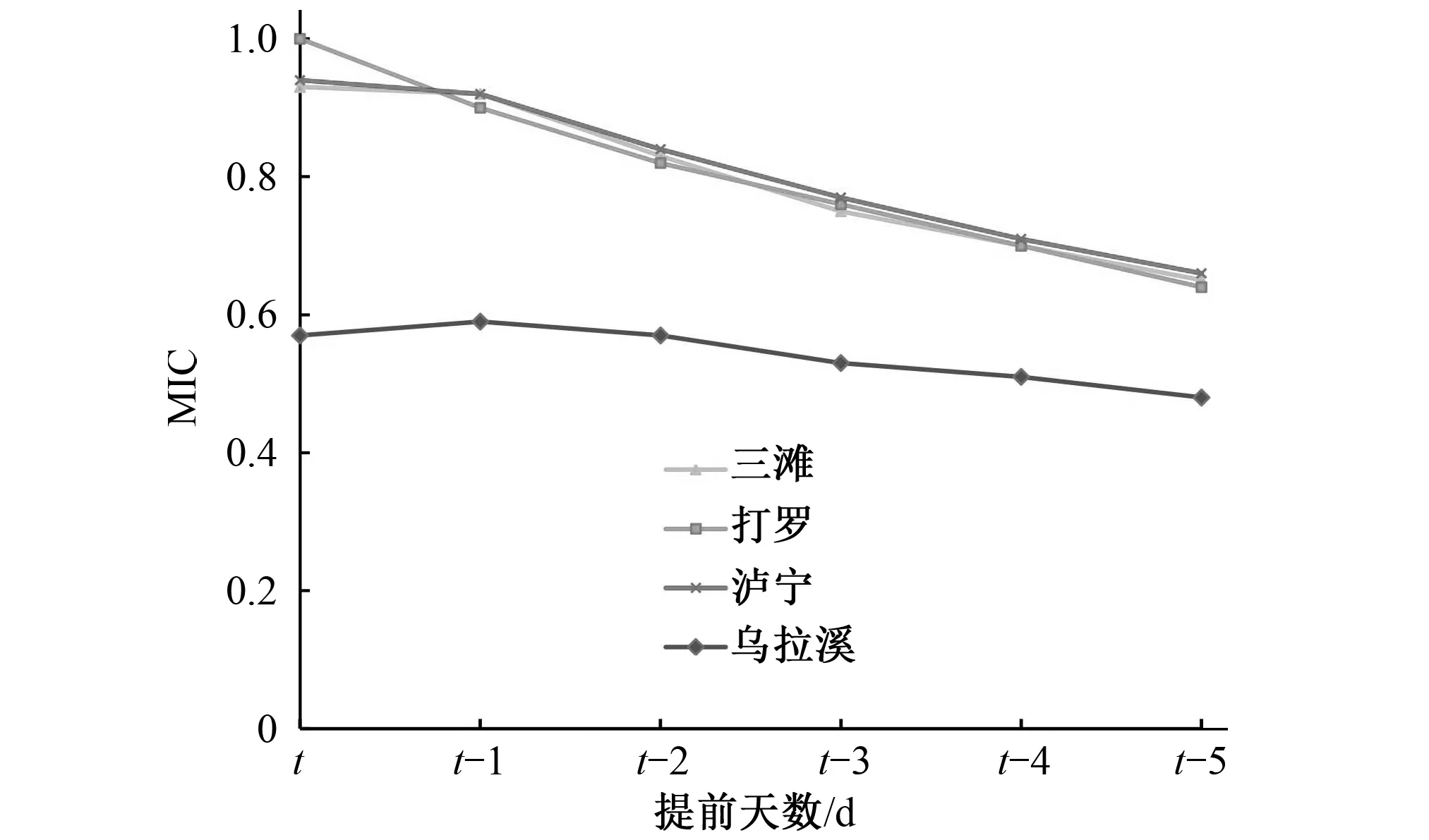
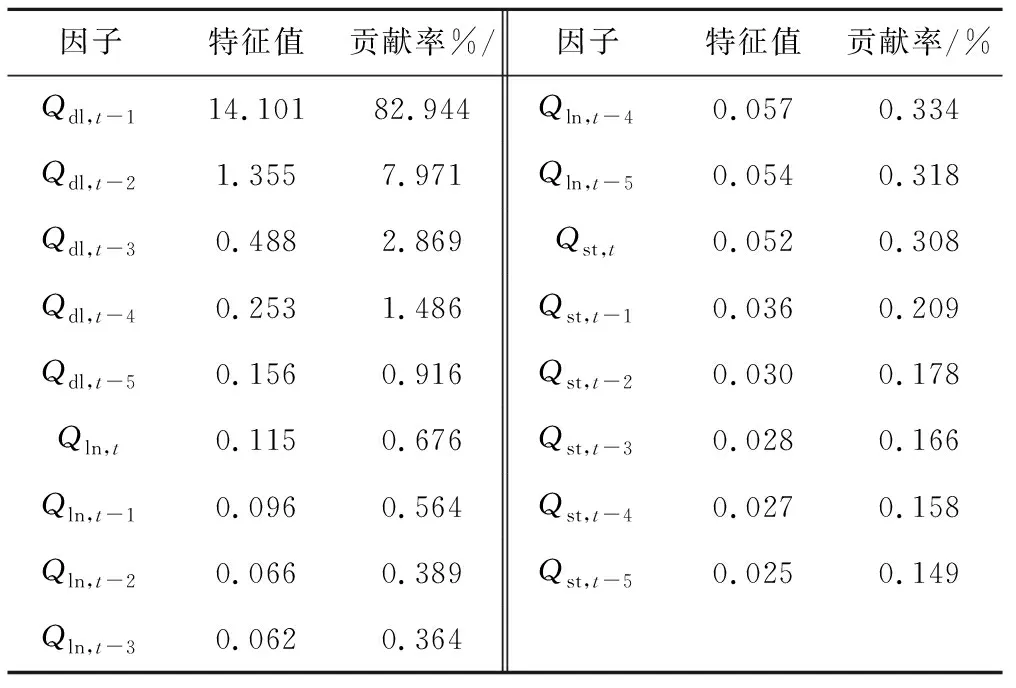
(2)計算集合D的點落在給定的網格G上所得到的頻率分布D|G,(允許某幾個網格內沒有落入數據集D中的點)。為了保證既不會因為網格過為細密造成每個樣本點都有自己的小格,而導致即便對隨機數據也有MIC≠0,又不會因為網格過為稀疏而不能精確地反映數據集的信息,需要合理選擇網格G的劃分上界B(n),ω(1) (3)計算不同的網格G確定不同的概率分布,即I(D|G) ,表示點集基于分布D|G的互信息。 (4)在基于x×y網格G的所有可能分布D|G的互信息中找到最大的互信息maxI(D|G)記為I*(D,x,y)。然后將不同大小網格G上的最大互信息標準化,使得各最大互信息均在(0,1)內,保證了公平性,得到二維數據集D的特征矩陣M(D)。 (1) (5)從步驟(4)得到的結果中找出最大者,即為最大信息系數。 MIC(D)=maxx y (2) (6)分別計算各預報因子與實測徑流間的最大互信息系數MIC(Xi,Y),并按照從大到小的順序依次排列,篩選出排名靠前的若干因子組成新的因子集X′={X1,X2,…,Xm},m≤n。 (7)分別計算因子集X′中各因子之間的MIC值MIC(Xi,Xj)(i,j≤n),組成MIC特征矩陣。 (8)計算MIC特征矩陣的特征值并使其按從大到小順序排列λ1≥λ2≥…λm≥0。分別求出對應于特征值λi的特征向量ei(i=1,2,…,m),要求‖ei‖=1。 (9)計算主成分貢獻率及累計貢獻率。一般取累計貢獻率達85%~95%的p個特征值所對應的p個主成分,即得到最終的預報因子集X″={X1,X2,…,Xp}。 貢獻率: (3) 累計貢獻率: (4) 運用MIC-PCA進行預報因子篩選的流程圖如圖1所示。 本文選取雅礱江流域打羅水文站日徑流預報作為研究對象。打羅水文站位于官地水電站下游,官地水電站是雅礱江水電基地下游卡拉至江口河段規劃的5個梯級電站之一。由于官地水電站上游未設有入庫水文站,官地的入庫徑流一般通過“反推”得到。徑流變化對于水電站水庫調度、發電及農業灌溉等有重要影響,準確預報打羅水文站的徑流量可以提前推算出官地的入流情況,對官地水電站提前制定調度方案,指導電站科學合理運行具有重要意義。打羅站位于雅礱江干流上,其徑流主要由支流九龍河(烏拉溪站控制)匯入雅礱江干流(三灘站控制)形成,上游有瀘寧站匯入。徑流的傳遞具有時延性,所以上游站點已發生的當日流量直接影響著下游站點未來的流量。另外,由于流量序列具有自相關性,打羅站前期流量對當日流量的預報有著重要作用。 為驗證本文提出的因子篩選方法的可行性與優越性,選取打羅站2009年汛期5-10月日流量作為預報對象,即Y={Qdl,t},選取1998-2008年共10 a汛期(5-10月)打羅水文站前1 d至前5 d天然日徑流和上游水文站三灘站、烏拉溪站、瀘寧站的當日徑流及前1 d至前5 d流量實測數據作為候選預報因子集:X={Qdl,t-1,…,Qdl,t-5,Qln,t,…,Qln,t-5,Qst,t,…,Qst,t-5,Qwlx,t,…,Qwlx,t-5},采用MIC-PCA耦合法進行預報因子篩選。 圖1 MIC-PCA法預報因子篩選流程Fig.1 Flow chart of prediction factor screening by MIC-PCA method 其中Qdl,t-1,…,Qdl,t-5代表打羅站前1 d至前5 d天然日徑流,其他符號含義以此類推。所選各站徑流資料由雅礱江公司提供,該公司之前也利用此數據資料作過相關的分析,可以充分反映官地上游來水情勢以及水文變化情況,選取的10 a資料,時間跨度大,能夠體現該流域徑流在時間上的變化,該數據具有代表性好,可靠性高等特點。文中提及的水庫、水文站點的布設示意圖如圖2所示。 圖2 水文站點布設示意圖Fig.2 Layout of hydrological stations 第1階段,計算因子集中各因子與打羅站當日徑流間的最大信息系數MIC(Xi,Y),計算結果如圖3所示。分析圖3中的計算結果可以得到以下結論。 (1)打羅站當日徑流序列與其自身的MIC值為1,是完全相關關系,以該點作為參照點,那么打羅站當日徑流序列與打羅站t-1~t-5、瀘寧站和三灘站t~t-5的徑流序列的MIC值均在0.6以上,說明這些預報因子與預報對象相關關系強,而與烏拉溪站的最大信息系數均位于0.6以下,且明顯遠小于其他因子,說明烏拉溪站徑流與打羅站徑流的相關性較弱,所含信息量相比于其他站點較少,可以剔除。 (2)打羅站、瀘寧站和三灘站的最大信息系數曲線差距很小,基本重疊,表明這3個站點在同一時刻的因子所含信息量接近,之間可能存在重復信息,需要考慮進一步剔除簡化;再次,每一個站點的曲線都大致呈下降趨勢,說明打羅站當日徑流序列與各站徑流序列的相關程度隨著時間間隔增加而減弱,即預報因子與預報對象的時間差越小,其包含的預報信息越多,該因子在預報中所起的作用越大。 (3)瀘寧站與三灘站的曲線在t時刻到達最高點,且與t-1時刻接近,可以推測瀘寧站與三灘站的徑流只需不到1 d即可流經打羅站,烏拉溪站在t-1時刻到達最高點,且與t、t-2時刻的最大信息系數值非常接近,所以烏拉溪站的徑流要經過1~2 d才能抵達打羅站。這與各站點間的布設位置和距離的實際情況相一致。綜上所述,第1階段篩選后得到的預報因子集為X′={Qdl,t-1,…,Qdl,t-5,Qln,t,…,Qln,t-5,Qst,t,…,Qst,t-5},因子集由23個因子初步簡化為17個。 圖3 MIC(Xi, Y)計算結果Fig.3 Calculation results of MIC(Xi,Y) 第2階段,在MIC法篩選出的因子集的基礎上,采用改進的主成分分析法剔除冗余的預報因子,精簡預報集。計算因子集X′中各因子之間的最大信息系數MIC(Xi,Xj),得到17×17的最大信息系數矩陣;計算MIC矩陣的特征值向量及各因子的主成分貢獻率向量。計算結果見表1。 表1 MIC-PCA法第2階段計算結果Tab.1 Second phase calculation results of MIC-PCA method 顯然,前3個因子的累計貢獻率達到99%以上,說明前3個因子含有的預報信息量占17個因子的99%以上,其余因子間的相關關系很強,可以互相取代,存在較多冗余信息。說明瀘寧站、三灘站與打羅站的徑流十分接近,可能3個站在地理位置上距離鄰近。因此完全可以用這3個因子代替17個因子,則最終篩選出的預報因子集為X″={Qdl,t-1,…,Qdl,t-3},因子集由17個因子簡化為3個。 為了驗證MIC-PCA法的有效性,本文選取BP人工神經網絡作為預報模型,將篩選得到的預報因子集的觀測樣本作為模型的輸入樣本,對預報模型進行訓練和測試,通過徑流系列的預測結果檢驗預報因子集的篩選效果。采用1998-2008年共2 024組汛期數據進行模型訓練,神經元傳遞函數選取雙曲正切函數,隱含層神經元數量設為200,訓練次數10 000次。預測打羅站2009年5月1日至10月31日的日平均流量過程,并采用因子篩選方法中應用較多的互信息法(MI),與單一最大信息系數法(MIC)、傳統主成分分析法(PCA)和本文提出的MIC-PCA法的因子篩選結果和預報結果進行對比。預報結果的評定采用計算時間、平均絕對誤差MAE、均方根誤差RMSE、確定性系數DC和預報合格率QR這5項指標,對各模型的擬合結果進行檢驗,評定指標的計算公式見表2。 表2 預報準確度計算指標和計算公式Tab.2 The calculation index of forecast accuracy 表2式中:MAE代表預測值與實際值的偏差絕對值求平均;RMSE代表預測值與實際值之差的平方根的平均值;DC代表預報過程與實測過程之間的吻合程度,其值越接近1,偏離程度越小;QR代表預報合格點所占比重,短期徑流預報誤差小于15%為合格預報;N為序列長度;Q(i)為實際流量值;Qf(i)為預測流量值;n為預報合格次數。 互信息和MIC按照80%的單側置信度選取因子,主成分分析選取99%累積貢獻率的因子,各種方法篩選出的因子集及預報效果見表3。 表3 各方法篩選結果與預報準確度指標值Tab.3 The screening results of various methods and the index value of prediction accuracy 結果顯示:互信息和最大信息系數都是將與預報對象相關關系強的因子篩選出來,保證篩選出的因子集信息量最大。最大信息系數作為MIC-PCA的第1階段,目的是篩選出含有高信息量的因子,與互信息相比,因其衡量非線性、非函數關系的能力更強,更容易發現互信息無法檢測到的因子間的關聯信息,故篩選出的因子更多。但所篩選出的因子集作為BP人工神經網絡的輸入表現不佳,計算時間最長,預報精度和合格率都最低,說明這些因子間信息重疊部分較大,影響了預報的準確度。 互信息與主成分分析的計算時間相差不大,但主成分分析的預報效果明顯較好,主成分分析法基于各因子的線性組合,將系數大的識別為主成分,并通過降維剔除了大多冗余信息。但主成分分析法無法識別與預報對象非線性關系較強的預報因子,故遺漏了該部分因子所包含的信息,擬合效果欠佳。互信息法篩選出的因子集中保留了過多的因子,可能存在信息冗余,降低了BP人工神經網絡的學習效果,擬合效果不佳。 MIC-PCA在所有方法中表現最佳,預報因子集最為精簡,計算時間最短。雖然因子數量少,但衡量預報準誤差的MAE和RMSE均最小,DC最接近1,說明預報徑流與實際徑流的偏差小,擬合精度高,且預報合格的點數多,預報效果最佳。采用MIC-PCA篩選出的因子既保證了信息量充足,又剔除了較多重復信息,使因子集合理精簡保證了高質量、精準的模型輸入,因此預報模擬效果好。這說明MIC-PCA可以為官地水電站的入庫站徑流預報提供準確的預報因子集。 采用的互信息法、主成分分析法和MIC-PCA法用于徑流預報,3種方法的預報結果及實際徑流過程線如圖4所示。 圖4 以各方法的因子集進行徑流預報的結果Fig.4 The result of runoff forecast based on the factor set of each method 從圖4可以看出,無論是在低流量還是高流量的情況下,MIC-PCA的預報徑流曲線與實際徑流曲線十分接近,預報準確度較高;互信息法在低流量附近和峰值附近擬合偏差較大,前期5月1日至6月10日預報值偏大,之后普遍偏低。根據互信息法篩選出的因子集進行預報偏差較大,平均每個預測點與真實值的相差350 m3/s,不利于水庫汛期的安全運行;MIC-PCA法與主成分分析法的預測徑流比較貼近,但可以看出MIC-PCA法的的預報徑流曲線與實際徑流曲線更加吻合,尤其是在極端值附近。實測徑流序列最大峰值出現于2009年8月13日,為8 090 m3/s,MIC-PCA法預測為7 913 m3/s,而主成分分析法預測為7 273 m3/s,較實際值明顯偏小,若使用該預報值作為調度決策的參考,使官地水電站推算出的入庫徑流量偏小,會發生預留的防洪庫容不足的后果,對下游及水庫安全造成損害。而MIC-PCA法的預報值與實際值始終較為接近,預報合格率高達93%,可以為官地水電站的調度決策提供更加可靠的參考。 為解決現有徑流預報因子篩選方法較少能夠兼顧信息量高、冗余信息少等要求,本文將最大信息系數衡量變量間復雜相關關系的能力,與主成分分析法降維去除冗余信息的能力有機結合,提出MIC-PCA耦合算法,并應用于徑流預報因子篩選。第1階段,計算各預報因子與實測徑流間的最大互信息系數從而篩選信息含量高的因子;第2階段,采用改進的主成分分析法,即以預報因子之間的最大信息系數矩陣代替傳統方法中的協方差矩陣,剔除信息重疊的因子,最終得到篩選后的預報因子集。本文將該方法應用于打羅水文站的日徑流預報中,并將該方法篩選出的預報因子集與其他多種因子篩選方法的篩選結果分別作為BP人工神經網絡的輸入以驗證該方法的有效性,綜合各項結果可以看出,該方法能夠從眾多預報因子中篩選出高信息量低冗余度的因子,為預報模型提供精確合理的輸入,有助于提高預報模型的預報效果。綜上,本文提出的MIC-PCA耦合算法在預報因子篩選方面具有實用價值。 □2 實例分析
2.1 初始預報因子集選取

2.2 基于MIC-PCA法的預報因子篩選
2.3 方法對比



3 結 論
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50數學物理學報(2020年2期)2020-06-02 11:29:24中華手工(2017年2期)2017-06-06 23:00:31光學精密工程(2016年6期)2016-11-07 09:07:19Coco薇(2016年2期)2016-03-22 02:42:52Coco薇(2015年1期)2015-08-13 02:47:34小雪花·成長指南(2015年4期)2015-05-19 14:47:56中外會展(2014年4期)2014-11-27 07:46:46祝您健康(1987年3期)1987-12-30 09:52:32
