基于Hadoop的車輛調度算法優化及應用①
2018-10-24 11:07:02陳燕,于放,田月,劉璐
計算機系統應用 2018年10期
陳 燕, 于 放, 田 月, 劉 璐
1(中國科學院大學, 北京 100049)
2(中國科學院 沈陽計算技術研究所, 沈陽 110168)
移動互聯網、物聯網等技術快速走向應用, 現代物流技術正在實現跨越式發展.這種進步正在深刻影響著社會信息化進程, 以物流技術的發展牽引著人類社會的不斷進步.正是現代物流技術的進步使得人們能夠足不出戶的實現商品的消費, 交易便捷化也進一步要求現代物流技術能夠更為快速地實現商品的配送.
車輛調度問題主要分為靜態和動態兩類.靜態車輛無法適應動態的運營環境, 現代車輛調度問題研究熱點集中于動態車輛調度以及結合數字地圖導航技術的動態路徑規劃等方面.如馮亮等針對客戶需求、配送車輛實時匹配需求, 以GPS/GIS地圖數據為基礎, 應用混合遺傳算法實現了動態車輛調度及路徑規劃, 能夠有效提升物流配送效率、降低物流企業成本以及改善物流服務質量[1].并提出以客戶需求、配送車輛/節點以及路網狀態等為約束條件, 構建了混合整數線性規劃模型, 同樣實現了動態快速的車輛動態調度及路徑規劃[2].對于能夠獲取公交車輛GPS數據的應用場景, 針對公交車輛動態調度問題, 可利用大數據實現公交車輛相關參數的預測, 并利用改進遺傳算法實現車輛的高效調度[3].針對實時性要求更高的應急車輛調度及配置問題, 研究學者利用城市快速路網相對固定的特征, 通過構建路網模型, 并利用混合蛙跳算法實現了快速準確的路徑實時動態規劃[4].而對于網購配送過程中, 末端配送存在的需求隨機性強、配送服務時效性要求高等問題, 提出了移動配送模式, 并以配送與懲罰成本為目標函數, 對移動配送模式的實時動態求解進行了驗證, 從研究成果看該模型能夠有效提升配送反應效率, 實現了高效車輛調度[5].顯然針對不同的應用場景, 現有研究的算法難以通用化, 特別是大規模、高實時性的車輛調度問題, 傳統啟發式算法是難以在實際應用場景中確保實時性的.本文主要實現的就是現有車輛調度算法的高效并行處理,以提高處理大規模、高實時性車輛調度問題的能力.
為此本文針對動態車輛調度過程中對算法實時性要求高, 傳統啟發式算法性能難以滿足不確定環境下多約束的大規模車輛調度的現狀, 提出基于Hadoop的車輛調度算法優化, 實現傳統啟發式算法的高效并行計算, 提升算法的加速比及擴展性, 能夠有效大規模動態車輛實時調度問題.
1 傳統啟發式算法
1.1 遺傳算法基本原理
遺傳算法 (Genetic Algorithm, 簡稱 GA)是應用最早的現代啟發式優化算法之一, 其基本原理是借鑒自然界生物“優勝劣汰、適者生存”的進化機制, 以遺傳變異理論為基礎, 實現代際間的迭代搜索, 從而實現隨機全局搜索以及優化.
遺傳算法通過設計一種代表生物進化基因的編碼來實現代際間的迭代搜索, 其基本要素包括:編碼、種群、適應度評估、選擇、交叉、變異等.通常包含以下步驟:(1)將問題的參數進行編碼;(2)生成初始群體;(3)計算群體中各個體的適應度函數值;(4)按選擇策略選擇將要進入下一代的個體;(5)按交叉概率Pc進行交叉操作;(6)按變異概率Pm進行變異操作;(7)如果不滿足終止準則, 則轉到(3), 否則轉入下一步;(8)將適應度函數值最優的個體作為該問題的最優解,輸出[6].
1.2 粒子群算法基本原理
粒子群算法(PSO)屬于群智能算法的一種, 是通過模擬鳥群捕食行為設計的.假設區域里就只有一塊食物(即通常優化問題中所講的最優解), 鳥群的任務是找到這個食物源.鳥群在整個搜尋的過程中, 通過相互傳遞各自的信息, 讓其他的鳥知道自己的位置, 通過這樣的協作, 來判斷自己找到的是不是最優解, 同時也將最優解的信息傳遞給整個鳥群, 最終, 整個鳥群都能聚集在食物源周圍, 即得到問題最優解.
粒子群算法通過設計一種無質量的粒子來模擬鳥群中的鳥, 粒子僅具有兩個屬性:速度V和位置X, 速度代表移動的快慢, 位置代表移動的方向.每個粒子在搜索空間中單獨的搜尋最優解, 并將其記為當前個體極值Pbest, 并將個體極值與整個粒子群里的其他粒子共享, 找到最優的那個個體極值作為整個粒子群的當前全局最優解Gbest, 粒子群中的所有粒子根據自己找到的當前個體極值Pbest和整個粒子群共享的當前全局最優解Gbest來調整自己的速度和位置.粒子群算法的思想相對比較簡單, 主要分為:(1)初始化;(2)評價粒子,即計算適應值;(3)尋找個體極值Pbest;(4)尋找全局最優解Gbest;(5)修改粒子的速度和位置.
1.3 并行啟發式算法原理
并行啟發式算法的基本原理是基于現代并行計算的概念和原理, 同時融合現代啟發式算法的全局隨機搜索優化能力, 使算法能夠更好的適用于大規模種群、動態多樣性、更快的收斂速度和全局尋優能力.目前, 并行啟發式算法已經是大數據計算領域的熱點研究領域.其主要優點包括:(1)并行啟發式算法染色體的并行編碼形式, 使初始種群具有很好的多樣性;(2)由單機全局搜索到多機局部搜索, 使算法實時性得以提高;(3)并行啟發式算法通過海量數據的預處理,能夠得到K個局部優化方案集, 提高了算法的求解質量.
2 基于Hadoop的并行啟發式車輛調度算法
2.1 算法流程設計
基于Hadoop的車輛調度并行啟發式算法優化主要分兩個階段:(1)利用并行遺傳算法算法對海量的車輛調度相關數據(路況的實時監控視頻、車輛基本運行狀況等)進行預處理, 得到K個局部優化的調度及路徑規劃方案集(對創建的方案集進行源節點和方案集是否為空判斷), 為下一步啟發式算法實現高效全局優化奠定基礎.(2)利用并行的啟發式算法(遺傳算法、粒子群算法等)對局部優化的調度及路徑規劃方案集進行全局優化搜索, 得到最優的方案.基于Hadoop的并行遺傳算法充分利用Hadoop的主從計算模式, 通過數據并行方式, 實現大規模、高實時的車輛調度優化.對某一區域內的車輛調度數據進行最短路徑分析, 得到局部的最短路徑方案集, 根據方案集生成向量列表,此時啟動并行啟發式算法, 對車輛調度及路徑規劃方案集進行全局優化.主要的Map Reduce編程模型包括了Map、Combine和Reduce 3個階段.
在執行此算法前, 集群主節點首先將已得到的簇類中心向量列表和簇中心數目廣播到各個子節點上.Map函數的輸入依然是各個數據塊集合, Map的輸入格式為
Combine函數的輸入是Map的輸出
Reduce函數處理屬于同一簇的所有數據對象向量, 并重新生成新的簇類中心向量, 其輸入輸出均是鍵值對形式.此時調用傳統啟發式算法, 實現輸入數據對象的隨機快速搜索.
輸入信息是各個子節點的combine結果, 輸出信息是簇類標識符和新的簇類中
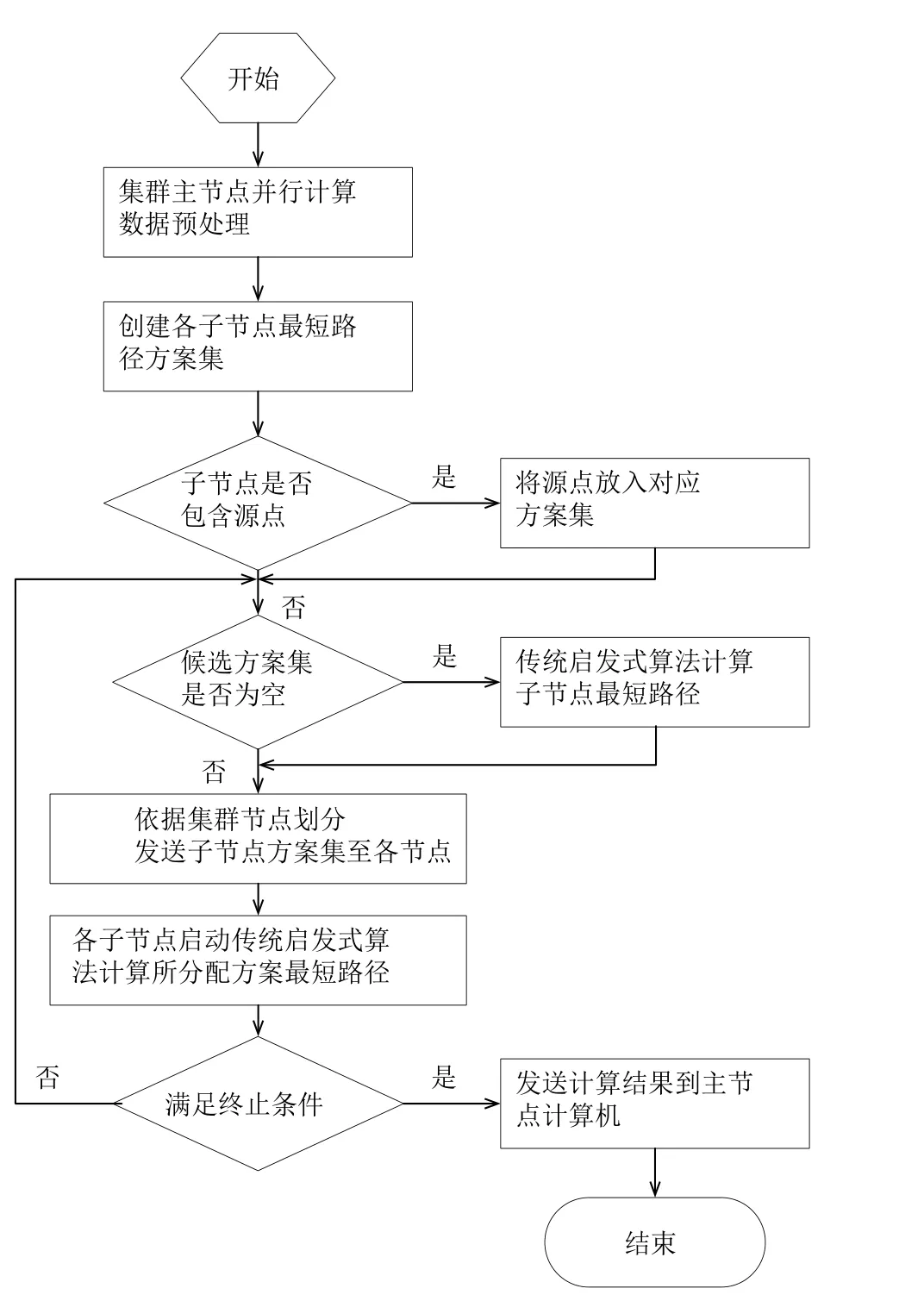
圖1 基于 Hadoop的并行啟發式算法流程
2.2 遺傳算法的MapReduce并行過程
(1) Map函數
種群適應值函數的計算(步驟(3)和(7))匹配Map函數, 它必須獨立于其他實例來計算.利用Map函數基本定義, 計算給定個體的適應值.并且將最好的個體的路徑保存下來最終寫到分布式文件系統HDFS的全局文件中.初始化任務的客戶端, 在MapReduce結束時從mapper中讀取這些值并檢查收斂條件是否滿足.GA每次迭代的Map過程偽代碼:


(2) C.Partitioner
若GA的選擇算子(步驟(4))在每個節點本地執行, 空間約束將會人為引入并降低選擇壓力, 并可能導致收斂時間增加.因此, 去中心化的、分布式的選擇算法成為首選.MapReduce模型唯一的全局通信點是Map和Reduce之間的Shuffle.在Map階段的最后,MapReduce框架使用分區將key/value對輸出給Reduce過程.分區會將中間的key/value對在各個Reduce之間進行拆分.函數GetPartition()返回給定的(key, value)應該發送給的 Reducer.在默認應用中, 它使用Hash(key)%numReducers, 以便具有相同key的值分配給同一個reducer, 從而可以應用Reduce函數.通過構建適宜的分區工具, 隨機地把個體分配給不同的Reducer.GA的隨機分割過程偽代碼:
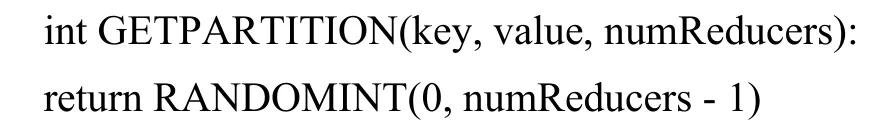
(3) Reduce過程
采用無替換競爭選擇算子.一場競爭在S個隨機選擇的個體直接進行, 選出其中的贏家.重復這個過程,重復次數為種群大小.由于隨機選擇個體相當于隨機對所有個體洗牌并按順序處理它們, Reduce函數也按順序處理每個個體.最初的個體為最后一輪競賽而緩存, 當比賽窗口滿了, 執行 SelectionAndCrossover算法.當交叉窗口滿了, 我們使用隨機交叉算子.在實際應用中, 可將S設為5, 交叉算子采用選出的兩個連續的父代個體進行.GA每次迭代的Reduce過程偽代碼:


3 實驗及結果分析
3.1 Hadoop環境構建
環境構建分為硬件環境和軟件環境, 其中Hadoop計算節點 4個, 操作系統為 Cent OS, 具體參數如下:
硬件環境:4臺PC機;
軟件環境:操作系統:Cent OS 6.5版本;JDK:1.8版本;Hadoop:3.0版本;Mahout:0.12.1版本.
3.2 計算實例及分析
本文通過Maple軟件實現配送網絡和驗證數據的隨機產生, 采用少量數據就能夠發現基于Hadoop的并行啟發式遺傳算法的高效性, 而Hadoop本身具有處理大數據的能力.為在論文中體現數據真實性, 采用隨機產生的方式以少量數據進行示例性說明(大量數據無法在文中展示, 也不利于論文結果重現).假設配送區域限定為 100×100 km2的正方形區域, 利用 rand 函數隨機獲得20個靜態需求位置數據和10個動態需求位置數據, 配送車輛最大配送體積為9 m3, 單個需求的體積最大為 3 m3, 車輛最大配送距離為 100 km, 配送中心的位置設定為 O(50 km, 50 km).隨機產生的靜態需求位置數據如表1所示, 動態需求位置數據如表2所示.
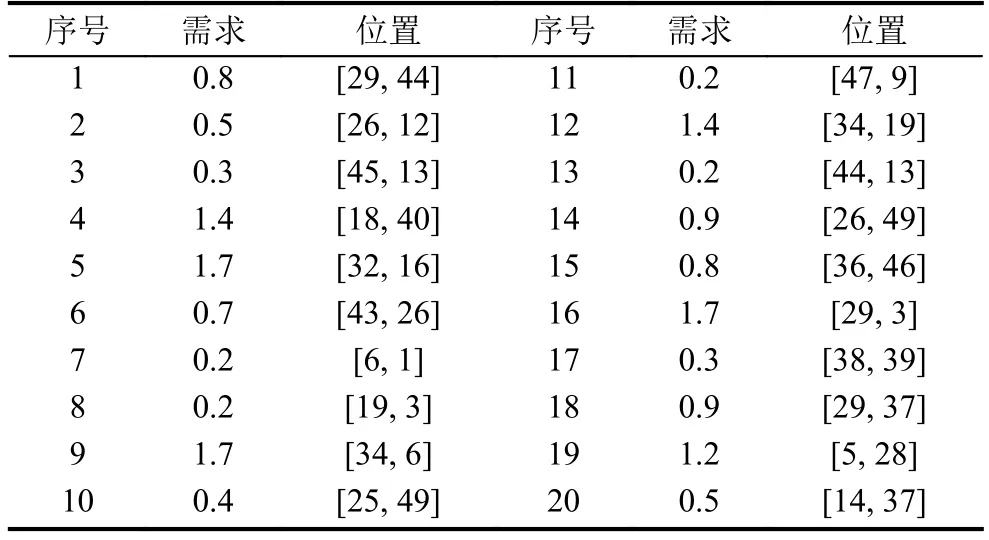
表1 靜態需求位置數據
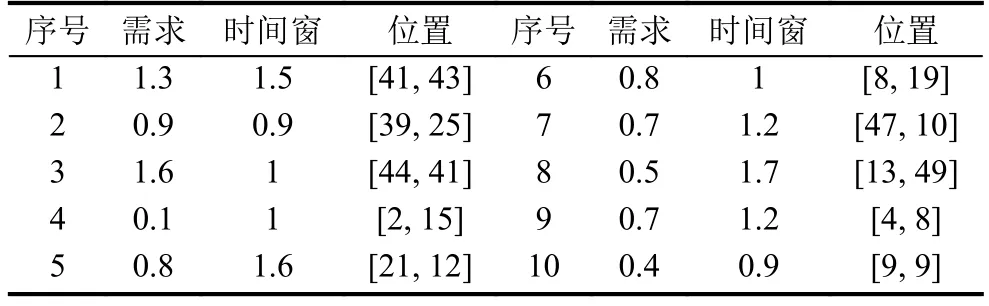
表2 動態需求位置數據
為了驗證基于Hadoop的車輛調度算法改進性能,對上述車輛調度問題進行求解, 得到基于遺傳算法、基于粒子群算法以及基于Hadoop的車輛調度算法的基本收斂性能, 如圖2所示.
由圖2可知, 三種算法中基于Hadoop的車輛調度算法能夠在 2 0代后實現快速收斂, 這得益于Hadoop并行遺傳算法的局部可行解集的提前獲取和全局并行計算的收斂性.
其次對比分析三者的搜索成功率、優化調度時間等基本性能, 如表3所示, 可以看出三種算法中基于Hadoop的車輛調度改進算法能夠實現全方位的性能提升, 特別是在收斂時間和平均迭代次數上.在車輛調度節點數量為靜態20, 動態數量為10的情況下, 利用4臺PC機, 計算時間由傳統啟發式算法大約17.5 s左右降低到3.1 s.對于更大規模的多約束高實時車輛動態調度問題而言, 基于Hadoop的并行遺傳算法能夠更快響應需求.
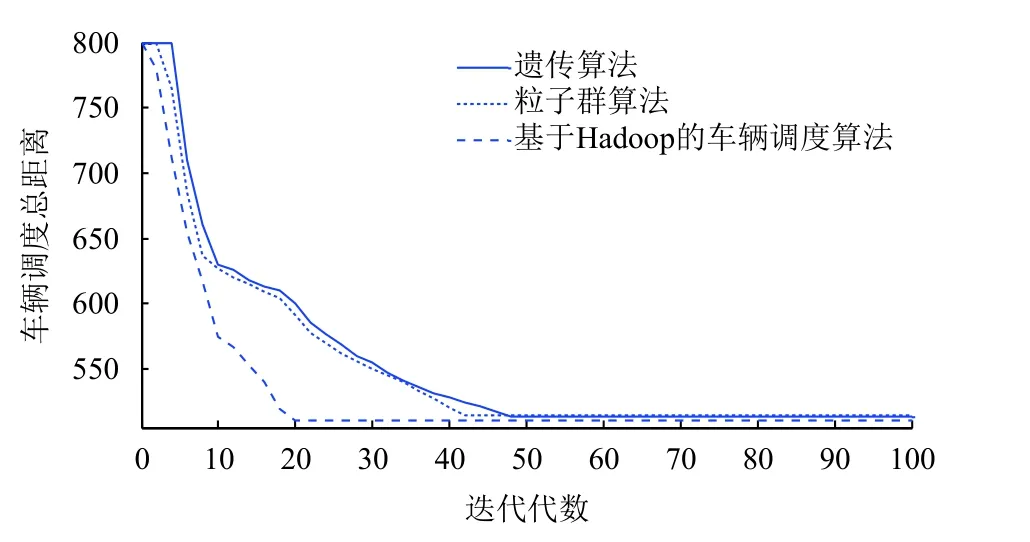
圖2 算法收斂性能

表3 算法計算結果
4 結論
本文針對傳統車輛調度算法在處理動態、實時、大規模車輛調度存在的不足, 特別是啟發式算法對初始種群敏感, 充分利用Hadoop在處理海量數據的快速性、計算效率等特性, 提出了一種基于Hadoop的車輛調度并行優化算法, 快速獲取可行的區域最短路徑規劃方案集, 并通過Map Reduce并行編程框架實現該算法來適應大規模車輛調度問題, 有效提高車輛調度算法的計算實時性及優化性能.仿真結果驗證了該算法在處理大規模車輛調度問題時具有良好的全局優化能力、計算加速比以及模型擴展能力.
