基于TextRank的文本情感摘要提取方法
2018-10-24 08:33:20楊玉珍
計算機應用與軟件 2018年10期
荀 靜 楊玉珍
1(西安工業大學圖書館 陜西 西安 710021)2(荷澤學院計算機學院 山東 荷澤 274015)
0 引 言
文本情感摘要技術是文本情感分析在自動摘要技術領域的應用。該技術是從給定的評論文本中提取帶有情感信息并且能夠表達文章主旨的內容,有助于用戶快速有效地把握評論文本的全局情感傾向,獲取主題信息。
近年來,針對漢語特點的中文文本自動摘要技術取得大量研究成果。文獻[1]將文本中句子的出現看成一個隨機變量,應用主題模型與信息熵抽取中文文本的摘要。文獻[2]提出了一種基于云計算的分布式多文本自動摘要技術,通過MapReduce框架抽取文本的主題句。文獻[3]采用基于回歸的有監督技術對提取的熵和相關度兩組特征進行權衡,進而提取文本的摘要。文獻[4]將文本情感摘要看成是一個二元分類問題,利用有監督學習方法抽取能夠代表評論廣泛意見的句子構建文本情感摘要。文獻[3-4]的兩種方法屬于有監督的自動摘要技術,準確度較高,但易受訓練語料的影響。
圖排序算法是當前主流的無監督方法之一,能夠充分考慮文本圖的全局信息,不需要人工標注訓練集,目前已被廣泛應用到信息檢索、關鍵詞提取和自動文摘等領域[5]。熊嬌等[6]融合詞項權重信息和文本信息,提出了一種基于詞項-句子-文本的三層圖模型,進行多文本自動摘要提取。余珊珊等[7]結合篇章結構和句子的上下文信息提出基于改進的TextRank自動摘要提取方法,但未考慮情感信息。林莉媛等[8]針對同一產品的多個評論,提出一種基于情感信息的PageRank算法。通過構建一個基于主題和情感的雙層圖模型來抽取最有代表性的句子作為某個產品評論的情感摘要。劉志明等[9]通過主題收斂,融合句子語義相似度和情感相似度,提出一種基于主題的SE-TextRank情感摘要方法。王瑋等[10]在LexRank算法中加入情感信息,提出融合句子情感和主題相似性的中文新聞文本情感摘要方法。這些方法在生成文本的情感摘要時引入了情感信息,能夠有效地識別文本中的情感關鍵句,但未考慮句子的情感強度和位置、線索詞、句式、長度等句子自身特征對生成情感摘要的影響。
基于TextRank算法,綜合考慮主題信息、情感信息和句子自身特征等影響因素,本文提出一種融合多特征的文本情感摘要提取方法。實驗結果表明,該方法能夠有效地提取文本中的情感主題句,實現評論文本的濃縮和提煉。
1 TextRank算法
TextRank算法來源于PageRank,是一種基于圖排序的文本處理模型[11]。它的基本思想是將文本中的句子看成圖中的一個節點,若兩個句子之間存在相似性,則認為對應的兩個節點之間有一條無向有權邊,權值是句子間的相似度。通過TextRank算法計算得到的權重排序靠前的若干句子可作為文本的摘要。
給定一篇文本D,對文本進行分句后得到句子集合D={s1,s2,…,sN},1≤i≤N。基于TextRank模型,構建句子的無向加權網絡圖G=(V,E,W),其中:V是節點的集合,E是節點間各個邊的非空有限集合,W是各邊上權重的集合。
圖G節點間的概率轉移矩陣SDn×n是一個n×n的對稱相似度矩陣,對角線上元素的取值為1。
(1)
根據構建的網絡圖G和SDn×n可迭代計算每個節點的權重,具體公式如下:
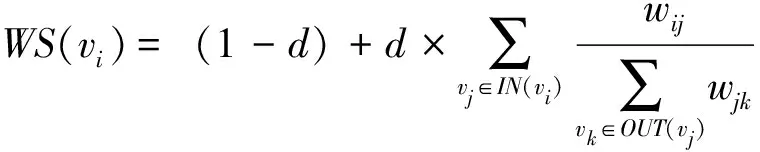
(2)
式中:d為阻尼系數,一般設定為0.85;對于一個節點vi,WS(vi)代表節點的權重,IN(vi)代表指向vi的節點集合,OUT(vi)代表vi指向的其他節點集合,WS(vj)表示上次迭代后節點vj的權重,wij表示節點vi和節點vj間的相似度值。
計算節點的權重首次迭代時要用到節點初始權重,即自身的權重。由于經過多次迭代后,每個節點的權重趨于穩定,因此節點的最終權重與初始權重無關,設定每個節點自身權重為1/|V|,即B0=(1/|V|,…,1/|V|)T,經過多次迭代計算后可得到收斂結果:
Bi=SDn×n·Bi-1
(3)
當兩次迭代的結果Bi和Bi-1取值差別非常小并接近于零時計算結束,得到包含各個節點權重值的向量,然后可根據權重值的大小進行排序,獲取節點相應排名。
2 文本網絡圖構造
2.1 特征選擇
文本的情感摘要不僅包含文本的全局情感信息,還要涵蓋文本的主題內容,因此本文綜合提取文本的主題特征詞和情感特征詞組成文本最終的特征向量。首先將輸入的文本劃分為句子,得到句子集合,并對文本中的句子進行結構標記,例如如果一個句子的結構標記值為[1,2,6],則表示該句子為第1自然段的第2個句子,第1自然段共包含6個句子;其次對每個句子進行切詞處理,去除停用詞和敏感詞,歸并同義詞和近義詞;最后對預處理后的特征詞條進行判定,若該詞為情感詞,則直接劃分到情感特征詞類別中,否則,通過IF-IDF方法評估特征詞條,將排名靠前的一定數量的特征詞劃分到主題特征詞類別中。文本特征向量提取流程如圖1所示。

圖1 文本特征向量提取流程圖
根據圖1處理結果,可以得到包含p個情感特征詞和q個主題特征詞的特征向量:
1) 文本D的特征向量,記為Dkey={key1:tf1,key2:tf2,…,keyp:tfp,…,keyq:tfq},1≤i≤p+q。其中:p+q為文本中所有特征詞的數量;tfi為特征詞keyi在文本D中出現的詞頻。
2) 句子sj的特征向量,記為sjkey={keyi1:stfi1,keyi2:stfi2,…,keyip:stfip,…,keyiq:stfiq},1≤i≤p+q。如果特征詞keyi在句子sj中出現,則stfi為詞頻,否則取值為0。
2.2 TextRank文本網絡圖
通過研究分析發現,在TextRank網絡圖中,迭代計算的結果主要受兩個節點間權重的影響,而節點間權重是通過計算句子間相似度得到的,因此,如何計算句子間相似度成為摘要提取的關鍵。根據特征選擇結果,本文分別在主題層面和情感層面上計算句子間的相似度,綜合句子主題和情感兩者間的相似度作為句子間的權重,計算公式如下:
Sim(si,sj)=μ×Simt(si,sj)+ω×Simr(si,sj)
(4)
式中:μ、ω是調節參數,并且μ+ω=1,通過多次測試確定最后的取值。Simr(si,sj)代表句子間基于情感的相似度,Simt(si,sj)代表句子間基于主題的相似度。
1) 基于情感的相似度 在文本情感分析研究中,句子的情感信息是通過其包含的情感詞表達的[12]。本文采用《知網》詞語語義相似度計算方法來計算選擇出情感特征詞的相似度,進而得到句子間的情感相似度[13]。《知網》中的詞語相似度是通過詞語的義原相似度體現的,對兩個情感詞w1和w2,假定w1含有n個義原X1,X2,…,Xn,w2含有m個義原Y1,Y2,…,Ym,則w1和w2的相似度如下:
(5)
式中:Sim(Xi,Yj)代表兩個義原間的相似度。對于句子sp={w1,w2,…,wa}和sq={w1,w2,…,wb},sp中包含a個情感詞,sq中包含b個情感詞。對兩個句子中的情感詞兩兩進行相似度計算,將計算過程中獲得的最大值作為本詞匯的相似度權重[9]。參照文獻[9]得到句子間的情感相似度,計算公式如下:
(6)
2) 基于主題的相似度 句子基于主題的相似度通過計算特征向量中主題特征詞的相似度來實現,本文采用余弦相似度方法,參照文獻[7],計算公式如下:
(7)
式中:h=|Dkey|為句子特征向量中主題特征詞的數量。
根據得到的句子間相似度構建一個無向加權TextRank網絡圖如下:以文本D中的句子sj為節點,句子間相似關系為邊,相似度為邊的權重,其中各節點的權重計算如下:
(8)
每個節點的初始權重設定為1/|D|,即B0=(1/|D|,…,1/|D|)T,則經過多次迭代計算后可得到收斂結果:
Bi=SDn×n·Bi-1
(9)
計算結束后可得到包含各個節點權重值的向量Bi,然后可根據權重值的大小進行排序。按照句子權重大小抽取情感主題句,并結合在文中的順序生成情感摘要。
3 融合多特征的TextRank文本情感摘要提取
3.1 情感特征
在傳統的情感傾向分析中認為一個句子中包含的情感詞數量越多,句子的情感傾向程度越大。本文在此基礎上考慮了情感詞的情感強度,通過情感詞的極性強度值累加來確定句子的情感強度。鑒于當前沒有統一標準的情感詞典,本文首先將收集到的HowNet詞典和大連理工大學詞典合并去重;然后以小學反義詞典為范本,添加情感分析COAE的領域情感詞;最后和課題組已有的極性詞典[13]合并去重,進而得到一個較為完善的情感詞典。基于情感強度的句子權重調整系數為:
(10)
式中:emotion(wi,k)是句子si中第k個情感詞wi,k的情感強度值;m是句子si中的情感詞個數。
經計算可得到基于情感特征的句子權重調整系數轉移矩陣TRh×1=[we(s1),we(s2),…,we(sh)]T,通過矩陣相乘Bi+1=Bi·TRh×1可對2.2節給出的句子最終權重進行調整。
3.2 句子自身特征
在提取摘要時,句子位置、線索詞、句式和長度等自身特征對摘要的準確度也有一定的影響,因此本文通過句子自身特征對收斂后的句子權重進行調整。
1) 位置特征 專家研究結果表明,80%以上文本的主題句出現在段落首句或尾句。因此,段落首句或尾句應該被賦予更高的權重,而越靠近段首和段尾的句子其權重相應地越高。基于位置的句子權重調整系數為:
(11)
式中:j為段落中句子所在的位置;H為段落中句子si的總數,并且j={1,2,…,H}。
2) 線索詞特征 句子是由詞組成的序列,而句子中包含的線索詞對作者表達的情感和觀點具有很大的提示作用。比如,指示性詞語,“因此”、“應該”等;總結性詞語,“綜上所述”、“總而言之”等;第一人稱代詞,“我認為”、“我建議”等。如果一個句子包含一個或多個線索詞,則該句子成為情感主題句的可能性越大。
基于線索詞的調整規則為:若句子中包含線索詞,則將該句子權重增加1倍;否則,句子權重保持不變。
3) 句式特征 句子的類型不同,對摘要提取的影響效果也不同。按照不同的表達方式,句子可分為4種類型:陳述句、疑問句、感嘆句和祈使句。疑問句和感嘆句常被用來表達主觀情感信息,因此有更大的可能成為摘要句。
基于句式的調整規則為:若句子為疑問句或感嘆句,則將該句子權重增加1倍;若句子為陳述句,則將該句子權重增加0.5倍;其他情況下,句子權重保持不變。
4) 長度特征 為了避免文本最終提取的情感摘要受句子過短或過長的影響,在此對文本中句子長度做歸一化處理,并過濾掉少于5個特征詞的句子。基于長度的句子權重調整系數為:
(12)
式中:L為句子的長度,length為文本中句子的平均長度。
3.3 情感摘要提取方法
融合多特征的TextRank文本情感摘要提取方法可分以下4個部分:文本預處理和特征選擇、TextRank網絡圖構建、句子權重修正和摘要句提取。
1) 文本預處理和特征選擇 每個句子進行切詞處理,去除停用詞,歸并同義詞。
2) TextRank網絡圖構建 通過TextRank算法構建文本網絡圖,然后進行迭代計算,直至收斂,輸出句子權重。
3) 句子權重修正 融合句子情感強度、位置、線索詞、句式和長度等特征,修正計算出的句子權重,得到句子的最終權重。
4) 摘要句提取 根據修正后得到的權重對句子進行排序,生成粗文摘,然后利用最大邊緣相關(MRR)消除冗余算法依次提取摘要句。
4 實驗設置與結果分析
4.1 實驗數據及評價指標
本文的實驗數據是從國內各大新聞網站中搜集的評論性的新聞報道。按照主題可分為文化、科技、時事、財經、體育等幾類的文章,經過預處理后各選取500篇文本作為本文的實驗語料,并人工抽取這些文本中的句子形成基準情感摘要。
本文利用ROUGE-1.5.5工具對最終摘要的結果進行評測,并使用ROUGE-1、ROUGE-2、ROUGE-W作為評價指標。其中,1與2代表1元和2元語法長度,ROUGE-1為候選摘要與基準摘要間的1元語法召回率,ROUGE-2為候選摘要與基準摘要間的2元語法召回率,ROUGE-W為最長加權公共子序列。
4.2 實驗結果及分析
本文針對提出的融合多特征的TextRank情感摘要方法,共設計3組實驗。首先,確定調節參數μ、ω的最優值;然后依次加入各個特征,查看情感摘要的效果;最后,對比不同方法下生成的情感摘要的結果。
4.2.1 調節參數設置(實驗1)
本文首先假定TextRank圖模型中節點的初始權重為1,然后通過設置不同的μ、ω的取值,觀察評價指標的結果。分別測試μ為0.35、0.4、0.45、0.5、 0.55、0.6、 0.65、0.7、0.75時的評價值,相應的,ω=1-μ。實驗結果如圖2所示。
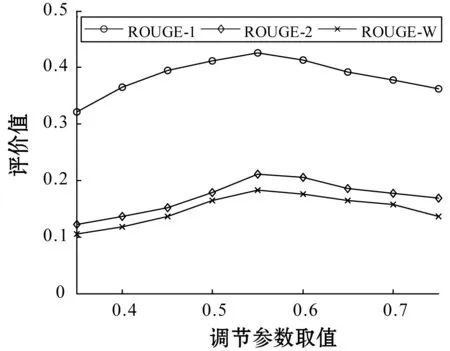
圖2 評價值在調節參數μ不同取值下的變化趨勢
從圖2可以看出,當μ=0.55,ω=0.45時,三個評價值的取值最高。因此,取μ=0.55,ω=0.45進行后續實驗。
4.2.2 各特征對情感摘要效果的影響(實驗2)
為了比較各特征對摘要的影響效果,該實驗分別加入每個特征,觀察情感摘要的結果。具體結果如表1所示。
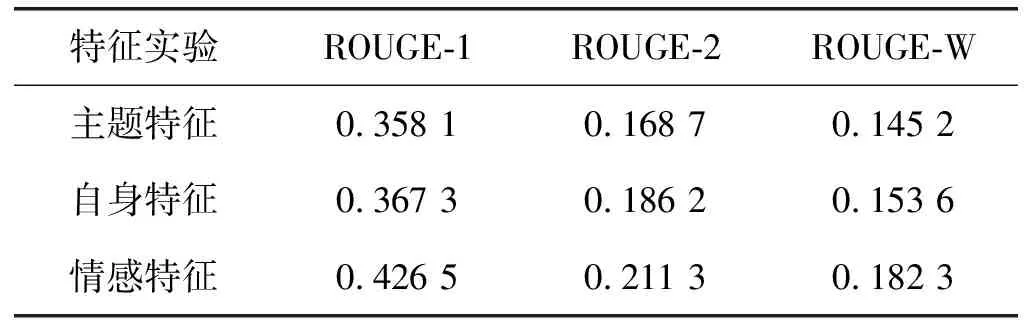
表1 特征影響效果實驗
實驗2首先利用主題信息提取摘要,然后加入自身特征,準確性得到提升,最后加入情感特征,準確性得到更顯著的提升。可以看出,每一個特征對情感摘要都有不同程度的影響,是生成摘要的重要因素。
4.2.3 對比試驗(實驗3)
本文將TF-IDF方法、傳統的TextRank方法和本文方法進行對比,以此驗證本文方法的有效性。實驗結果如表2所示。
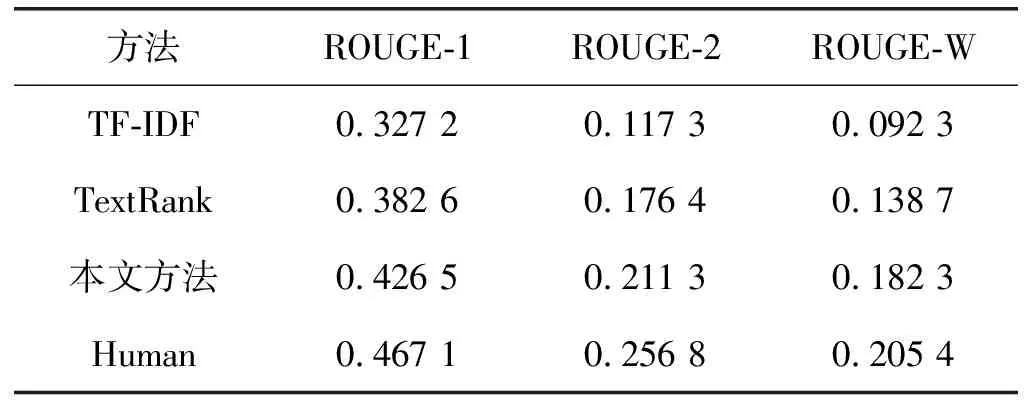
表2 對比實驗
表2的統計結果表明,本文方法在ROUGE-1、ROUGE-2和ROUGE-W三個評價指標上均有明顯提高。基于TF-IDF的方法只考慮了詞頻信息,相比其他方法效果最差。基于傳統的TextRank方法考慮了文本的主題信息,效果優于IF-IDF方法。本文方法進一步考慮了文本的情感信息和句子的自身特征,效果更優于傳統的TextRank方法。
5 結 語
情感摘要的生成是自然語言處理領域和文本情感傾向性分析領域的研究熱點。本文的方法在傳統的TextRank摘要抽取方法基礎上充分考慮了主題信息、情感信息、句子位置、線索詞、長度和句式等特征,有效地抽取評論文本的情感主題信息。下一步將嘗試把上述研究應用到多文本情感摘要領域,同時繼續完善中文情感詞典,進一步提高摘要的準確率。
猜你喜歡
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
