松耦合云環境下的虛擬網絡異常實體檢測研究
2018-10-24 07:59:24張舟遠吳承榮葉家煒
計算機應用與軟件 2018年10期
張舟遠 吳承榮 葉家煒
(復旦大學計算機科學技術學院 上海 200433)(教育部網絡信息安全審計與監控工程研究中心 上海 200433)
0 引 言
隨著云計算技術應用規模的不斷擴大,對數據中心網絡的要求也逐漸提高。由于傳統網絡在拓撲和IP地址空間等方面存在著固有缺陷[1],為了克服這些缺陷,就產生了網絡虛擬化的基本需求。
網絡虛擬化技術[2]可以將一個物理網絡劃分為多個完整而又彼此隔離的邏輯網絡,即虛擬網絡。這些虛擬網絡通過同一套物理設備提供給云平臺中不同的租戶。租戶可以通過自定義的方式向云管理人員申請并獲得具備自己所需要的拓撲結構和IP地址空間的網絡,從而滿足了新型數據中心的需求。對于租戶而言,除了上述需求外,虛擬網絡的安全問題也是非常需要關注的問題。與傳統物理網絡不同,虛擬網絡中的網絡設備既包括了傳統的物理網絡設備,又包括了部署在物理服務器上的虛擬網絡設備。因此虛擬網絡除了需要應對傳統的網絡安全問題以外,還需要有應對新的網絡安全的能力。
當前的主流云平臺,尤其是以OpenStack為代表的開源云平臺,其整體架構大多都是松耦合的。在這樣的整體架構下,云平臺中的各層次,每個層次中的各模塊都可以獨立進行設計開發和維護,帶來極大的便利。但與這種便利相對應的,則是層次和層次之間的依賴性降低,缺乏良好的反饋機制。當底層出現狀況的時候,上層往往難以及時發現這些問題,從而給整個系統帶來安全隱患。虛擬網絡異常實體問題就是其中的一種安全問題。所謂虛擬網絡異常實體,指的是云平臺中沒有正常地在云管理平臺以認證和發出請求的方式,而是以直接調用底層的相關管理工具或者是API的方式直接添加、刪除或者是改變配置的虛擬網絡端口以及連接在該端口上的虛擬機。
本文對松耦合云環境下出現虛擬網絡異常實體問題的原因進行了探討,提出一種能夠及時發現虛擬網絡異常實體的方案,并通過實驗對該方案的有效性加以驗證。
1 相關工作
網絡安全歷來是一個非常重要的問題,而隨著虛擬網絡的出現和發展,網絡安全問題也迎來了新的挑戰。一般認為,虛擬網絡由于可以使用更為細粒度的訪問控制,因此安全性要高于傳統網絡。早在2008年和2009年,文獻[3-4]就指出了虛擬環境下存在通過攻擊Hypervisor獲取整個系統控制權,進而實施其他攻擊手段的安全問題。盡管當時主要把研究重點放在了虛擬機安全管理上,但隨著網絡虛擬化技術在云計算中的大量應用,無論是學術界還是工業界也都已經開始對虛擬網絡的安全問題進行了相關研究,提出各自的解決方案。
學術界的主要研究思路是基于開源軟件來提出并開發相應的解決方案。例如,文獻[6]將處于同一虛擬網絡的虛擬機放置于同一臺物理機中,并將物理網卡配成多IP模式作為地址池,物理網卡與支持網絡虛擬化的物理交換機相連,物理機與物理交換機之間通過部署防火墻來實現網絡安全。文獻[7]則在每臺物理機的Hypervisor上部署了沙盒,并基于安全策略來保證虛擬機的網絡安全。文獻[12]探討了軟件定義網絡(SDN)環境下的虛擬網絡安全問題。文獻[13]進一步將SDN和NFV(網絡功能虛擬化)集成到OpenStack中,提高其網絡安全性。文獻[14]通過將入侵檢測系統(IDS)和蜜罐網絡集成到云環境中的方法實現減輕已知和未知的攻擊。此外,還有部分研究將重點放在了虛擬網絡中傳輸數據本身的安全上,例如文獻[11]設計了一種基于加密傳輸的網絡虛擬化系統來保證網絡中數據的安全。
工業界根據搭建虛擬網絡的解決方案的不同,有著不同的虛擬網絡安全機制。主要分為兩種:(1) 以VMWare和Cisco(思科)為代表的商用虛擬網絡解決方案;(2) 以OpenStack為代表的開源虛擬網絡解決方案。
商用解決方案包括了以VMware為代表的軟件解決方案和以Cisco為代表的硬件解決方案。其中:VMware提出了一種名為NSX[8]的虛擬網絡解決方案和產品,該產品底層使用了VMware自己開發的VDS虛擬交換機,上層則和VMware vSphere相結合,各層次之間耦合度很高,具備非常良好的交互與反饋機制,管理人員可以很好地掌握整個系統的運行情況;Cisco則提出了一套名為ACI[9]的虛擬網絡解決方案,該方案的特點在于其仍將硬件作為虛擬網絡的核心,所有對網絡的操作都是基于硬件設備能力來實現的,并且采用了新的網絡協議,使得其相比較于使用樂高積木式組建網絡的軟件方案的功能更為強大。
以OpenStack[5]為代表的開源云平臺則采用了輪詢的方式來檢測虛擬機的網絡連接,一旦發現虛擬機沒有連接到虛擬網橋上就會通過管理工具在對應的網橋上重新創建虛擬端口。但由于設計這一機制的目的是為了解決虛擬交換機運行時自身出現故障的問題。因此只能判斷虛擬機所對應的虛擬端口是否存在,既無法保證虛擬端口是否被正確配置,也無法感知不受OpenStack管控的虛擬端口。其各不同層次的組件通常分屬不同的開源產品,雖然每個產品都能夠提供一定程度的安全管理機制,但由于層次間的耦合程度低,尚未出現一個系統的統一安全管理方案,也沒有專門針對虛擬網絡異常實體問題進行過相關設計。本文主要針對松耦合架構的開源云平臺下存在的虛擬網絡異常實體問題進行研究。
2 虛擬網絡異常實體問題分析和檢測
2.1 松耦合云環境下的虛擬網絡異常實體問題
圖1以OpenStack為例,展示了松耦合云環境下虛擬網絡的典型結構。租戶或管理員通過云平臺Portal提供的圖形化界面進行配置,云平臺通過分別調用Nova和Neutron的相關API對底層設備進行操作。
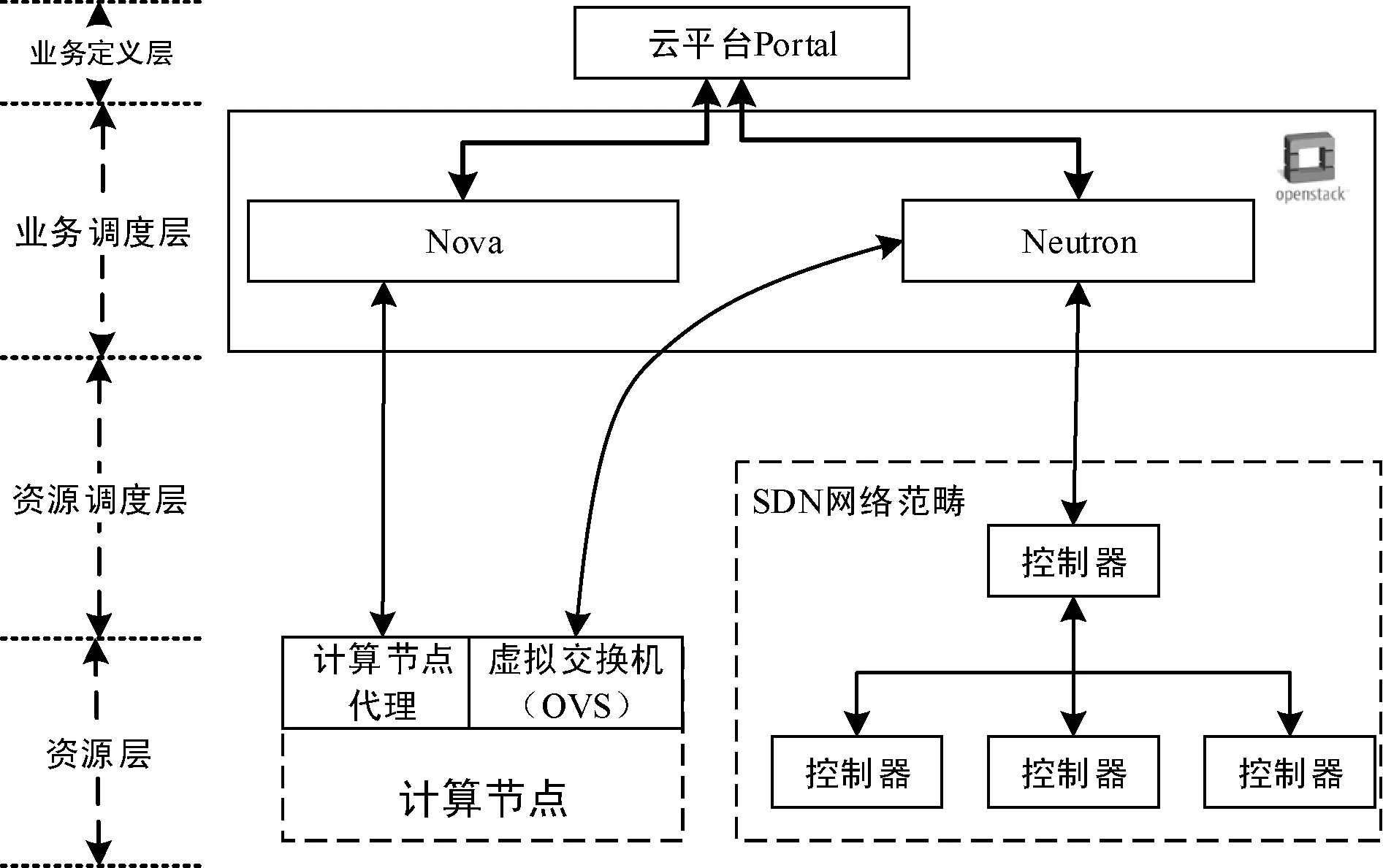
圖1 OpenStack環境下虛擬網絡典型結構
在這樣的結構下,各層次之間缺乏良好的反饋機制,只有在上層調用下層提供的服務時,下層才會將執行結果返回上層,下層本身不會主動向上層報告自身的運行情況。這是因為在OpenStack環境下,云平臺的下層,即資源調度層和資源層,大量使用了第三方軟件,而這些第三方軟件本身不具備主動對上層反饋的機制。在正常情況下,租戶或管理員經過云平臺Portal的認證,自上而下一層一層地對虛擬交換機進行操作,每一層都會將調用結果反饋給上層并且在日志中留下記錄,因此這樣的設計不存在問題。然而在非正常情況下,例如沒有經過云平臺的認證而是直接調用底層虛擬交換機提供的管理工具進行操作時,由于底層設備不會主動向上層報告,因此上層的云管理平臺無法及時獲取相關的信息并加以處理,從而導致虛擬網絡異常實體的出現。這些異常實體或者成為垃圾資源無法正常使用,從而影響租戶的正常業務,或者成為攻擊者的“肉機”或跳板,從而危害整個系統安全。
根據對虛擬交換機的不同操作,虛擬網絡異常實體可以分為兩類:(1) 不受OpenStack管控的虛擬網絡端口及相關聯的虛擬機;(2) 被篡改網絡配置的虛擬網絡端口及相關聯的虛擬機。下面分別介紹這兩類虛擬網絡異常實體及其形成原因。
第一類虛擬網絡異常實體,即不受OpenStack管控的虛擬網絡端口及相關聯的虛擬機,指的是攻擊者繞過云管理平臺的認證機制,直接調用Open vSwitch等虛擬交換機提供的管理工具,將不屬于OpenStack管控的虛擬機接入OpenStack網絡中。這些虛擬機無法通過OpenStack進行管理,但是可以作為內部網絡成員和所接入網絡內的虛擬機正常通信,且不受部署在虛擬網絡邊界的網絡安全系統如防火墻等的影響。同時,由于將虛擬機接入OpenStack網絡的操作沒有經過OpenStack的任何一個模塊,因此OpenStack既無法感知這些虛擬機,也無法發現虛擬機接入網絡的任何操作,于是就會產生第一類虛擬網絡異常實體。
第二類虛擬網絡異常實體,即被篡改網絡配置的虛擬網絡端口及相關聯的虛擬機,包括兩種情況:(1) 通過篡改虛擬網絡端口的配置使虛擬機接入其他網絡;(2) 通過篡改虛擬網絡端口的配置將虛擬機從虛擬網絡中刪除。在這兩種情況下,虛擬機的網絡配置都和云管理平臺中所記錄的網絡配置不同,從而形成異常實體。由于OpenStack的架構是松耦合的,其主要模塊無法通過底層的主動報告來獲取其運行情況,而只能采用定時輪詢的方式檢測虛擬網絡端口的配置是否正確。如果輪詢的時間間隔設置得合適,并且能夠將發現的異常實體及時報告給安全管理人員的話,這也不失為松耦合架構下的一種可行的安全措施。然而OpenStack的定時輪詢機制并不是作為一種安全機制而設計的,而僅僅是為了防止底層的虛擬交換機自身在運行時出現錯誤,從而保證云管理平臺下發的各種指令能夠正確執行。正是出于這一目的,OpenStack在發現虛擬網絡端口的配置與自身數據庫中記錄的不同時,只會根據自己記錄的信息重新配置虛擬網絡端口,而不會向安全管理人員報告,也不會留下任何日志信息供安全管理人員查看。
為了驗證上文所論述的異常實體的存在和危害,本文繞過OpenStack平臺,直接對虛擬交換機Open vSwitch進行了以下操作:
操作1:使用ovs-vsctl add port命令,將不受OpenStack管控的虛擬機接入OpenStack網絡中。
操作2:使用ovs-vsctl set port命令,改變虛擬網絡端口配置,從而將相關聯的虛擬機接入另外的網絡中。
操作3:使用ovs-vsctl del port命令,刪除虛擬網絡端口,從而將相關聯的虛擬機從網絡中刪除。
每次操作前都先將OpenStack恢復原狀,通過這些操作并分別查詢Dashboard界面、Neutron日志以及虛擬機本身情況,結果如表1所示。
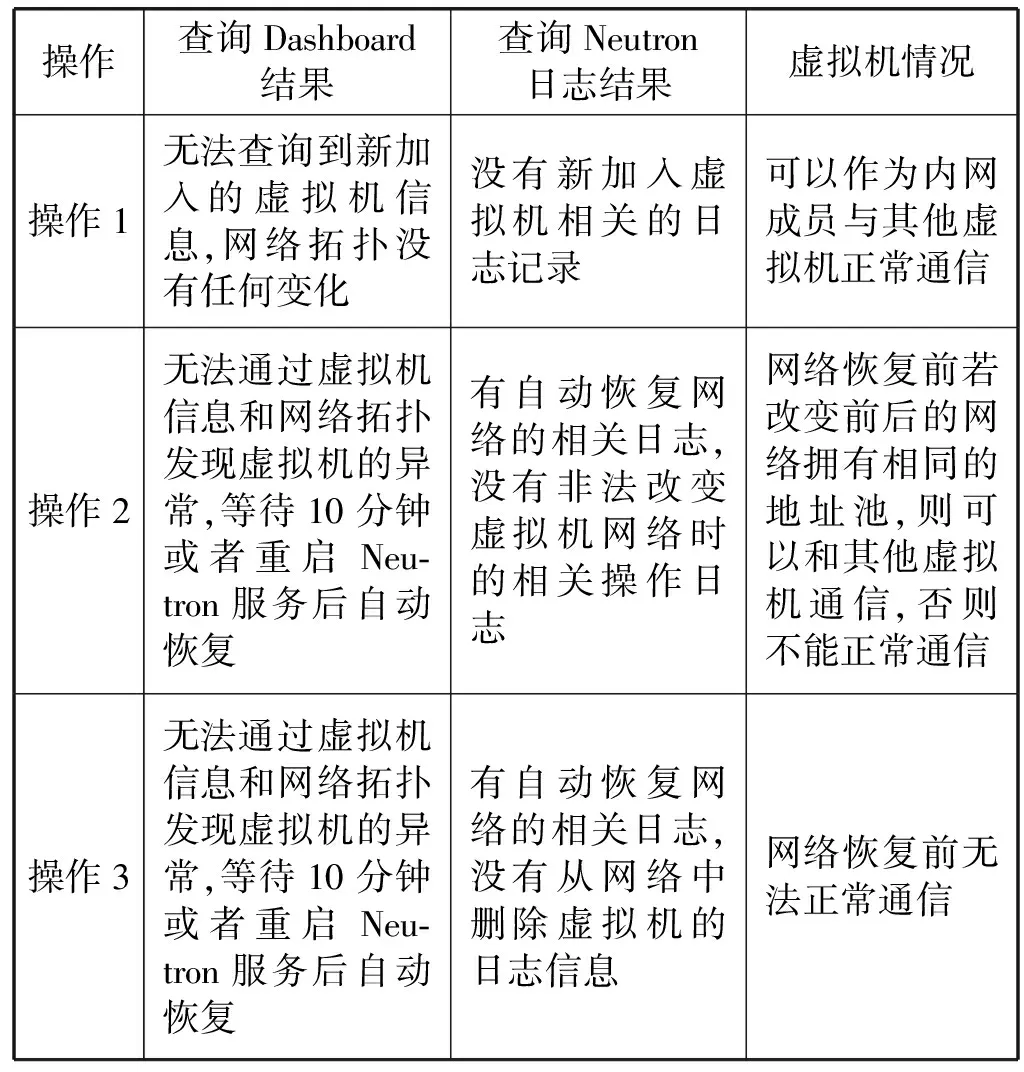
表1 異常實體問題驗證結果
由此可見,OpenStack中出現的兩類虛擬網絡異常實體既不能通過Dashboard界面進行監控,也不能通過查詢Neutron日志進行事后排查,這一點必須引起安全管理人員的重視。
2.2 虛擬網絡異常實體檢測方案
2.2.1 基本原理
上文曾經提到,定時輪詢方案可以作為一種可行的虛擬網絡異常實體的檢測方案,而OpenStack現有的定時輪詢方案還存在著一些問題。本文基于OpenStack的定時輪詢思想,并作出一些改進,在不對云平臺本身進行改動的前提下提出一種針對虛擬網絡異常實體的檢測方案。本方案的基本原理是對Open vSwitch和OpenStack中分別記錄的虛擬網絡信息進行比對,如果發現記錄不一致,則存在虛擬網絡異常實體。其中:Open vSwitch中記錄的是虛擬機的實際網絡配置信息,而OpenStack中記錄的則是虛擬機應當具備的網絡配置信息。本方案的工作流程如圖2所示。
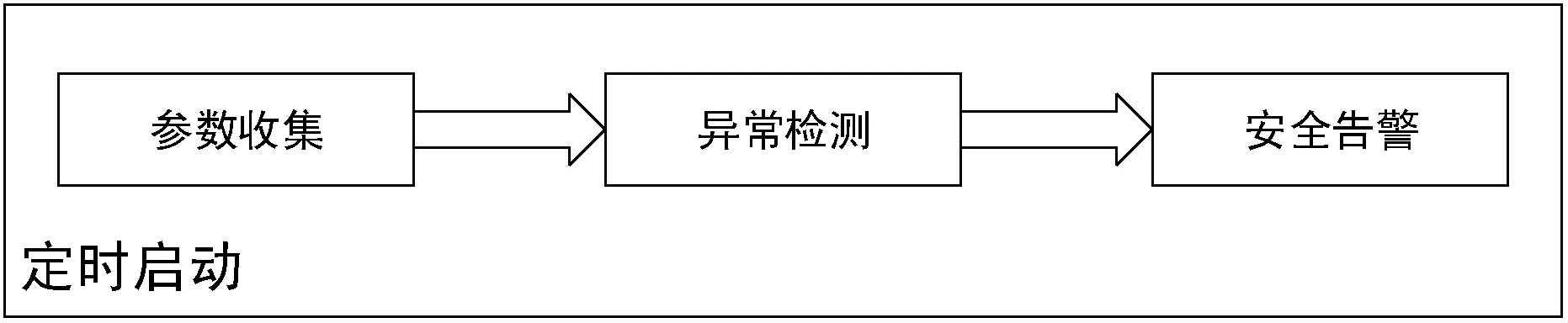
圖2 虛擬網絡異常實體檢測流程
根據本方案編寫的虛擬網絡異常實體檢測程序利用Linux提供的cron服務定時啟動,并且按照以下步驟工作:
(1) 參數收集 首先需要收集兩部分重要參數作為輸入。一部分是Open vSwitch的所有連有虛擬機的端口以及這些端口上所連接的虛擬機信息。另一部分是OpenStack上所存儲的虛擬機相應的信息以及這些虛擬機的相應網絡信息。
(2) 異常檢測 用步驟1中所獲取的兩部分虛擬機信息以及虛擬網絡端口信息進行比對,從而發現網絡中不受OpenStack管控的第一類虛擬網絡異常實體以及OpenStack中實際網絡配置和云管理平臺中記錄的配置不同的第二類虛擬網絡異常實體。
(3) 安全告警 如果在異常檢測這一步驟中發現了虛擬網絡異常實體,那么會在數據庫中生成一條告警記錄。這條告警記錄的信息會及時通過有效的反饋機制告知安全管理人員。
2.2.2 具體實現
根據上文的工作流程具體描述虛擬網絡異常實體的檢測實現細節。
(1) 參數收集的實現 在檢測開始前,需要分別對Open vSwitch上的信息集合(記為Ov)和OpenStack上的信息集合(記為Op)進行信息收集。其中,Ov中的每一項都對應了Open vSwitch中的一個連有虛擬機的虛擬網絡端口信息,對于每一個端口可以收集到的信息包括端口名、端口UUID、端口VLAN tag、對應VxLAN的標識VNI、虛擬機UUID、虛擬機MAC地址等。這部分信息中,VNI信息需要從Open vSwitch的流規則中提取,其余所有信息都可以從Open vSwitch的數據庫,即ovsdb中獲取。Open vSwitch分別提供了ovs-ofctl和ovsdb-client兩個管理工具來獲取這一部分信息。這里需要特別指出的是,虛擬機的UUID信息和MAC地址信息有可能因為攻擊而無法從ovsdb中提取,這時需要調用Libvirt API來獲取這些信息。
而Ov中的每一項對應OpenStack中的一臺虛擬機及其網絡的配置信息,包括虛擬機UUID、虛擬機MAC地址、虛擬機IP地址、VxLAN標識VNI和虛擬網絡UUID等。這一部分信息可以分別從Neutron數據庫中的ports表、ml2_network表和ipallocations表中提取。為此,可以建立一張視圖匯總這方面的信息,如圖3所示,圖中的device_id、mac_address、ip_address、segmentation_id和network_id字段分別對應了上述信息。
(2) 異常檢測的實現 在完成參數收集的工作后,首先開始遍歷Ov中的每一項,檢查Ov中的每一項(記為Ovi)所記錄的虛擬機UUID是否都包含在Op中,如果不在Op中,則可以判定系統中有存在第一類虛擬網絡異常實體;如果虛擬機UUID包含在Op中,那么繼續比對這臺虛擬機在Ov和Op的記錄中是否在同一網絡中;如果不在同一網絡中,那么可以判定系統中存在第二類虛擬網絡異常實體且屬于第一種情況;在完成對Ov的遍歷后,繼續遍歷Op中的每一項(記為Opi),檢查是否每臺虛擬機都在Ov中有記錄,如果沒有,那么可以判定系統中存在第二類虛擬網絡異常實體且屬于第二種情況。這一過程可以用圖4所示的流程圖來表示。
(3) 安全告警的實現 虛擬網絡異常實體的告警記錄包含的內容如表2所示。告警信息應當及時通知安全管理人員處理,本文使用網頁展示的方式進行通知。實際應用中也可以使用電子郵件、短信通知等其他有效的方式。
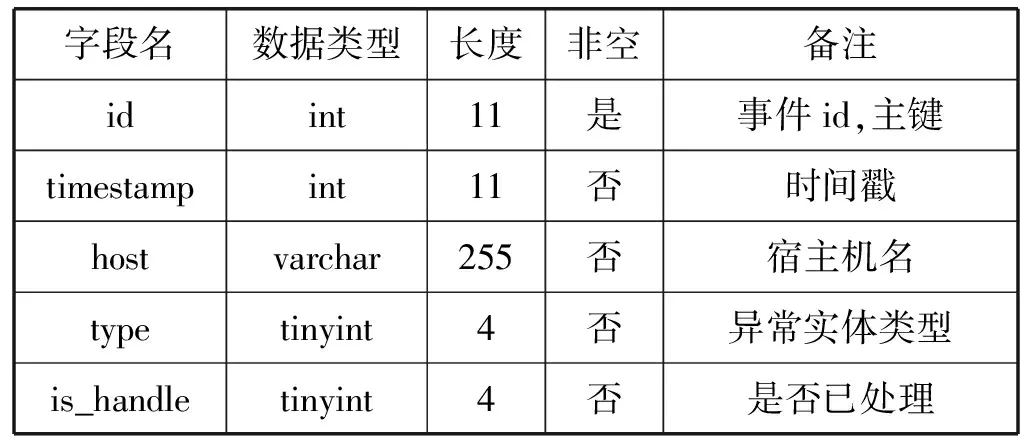
表2 異常實體數據庫表格式

續表2
3 實驗驗證
3.1 實驗環境
本文的實驗環境部署在3臺硬件配置相同的物理服務器上,詳細配置見表3。我們使用這3臺服務器搭建了一套小型的OpenStack環境。物理服務器操作系統為CentOS 7,其中一臺作為控制節點,安裝了MariaDB數據庫,其余兩臺作為計算節點,并使用Open vSwitch作為虛擬交換機來搭建虛擬網絡。
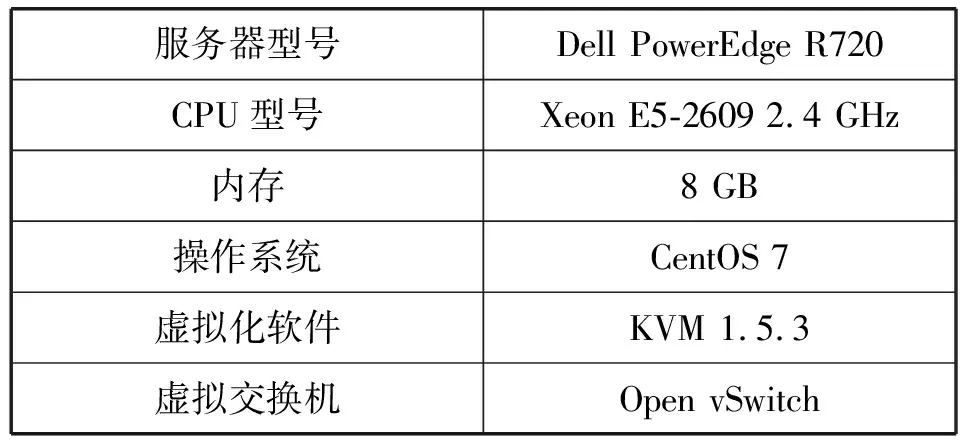
表3 物理服務器配置
我們用Python語言編寫了用于檢測虛擬網絡異常實體的腳本程序,并如圖5所示部署在計算節點的操作系統上。然后開啟Linux提供的cron服務,使用crontab命令配置任務,將該腳本程序設置為每分鐘執行一次。控制節點上部署了Java運行環境,使用Java Web技術開發安全告警事件的展示頁面,用于展示檢測程序寫入數據庫的安全告警事件。
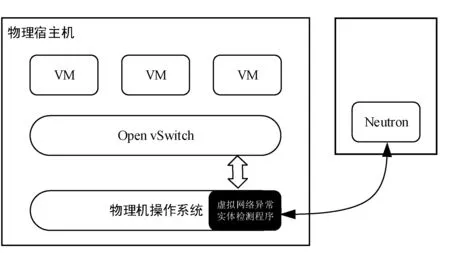
圖5 異常實體檢測程序物理部署
3.2 實驗設計和結果
為了驗證本文提出的虛擬網絡異常實體檢測方案的有效性,本文通過模擬產生虛擬網絡異常實體進行測試實驗。通過比較OpenStack的Dashboard頁面和虛擬網絡異常實體展示頁面中是否能夠將這些模擬產生的異常實體正確顯示來進行功能驗證。其中:對于OpenStack,主要查看虛擬網絡拓撲信息和相關操作日志;對于展示頁面,主要查看是否正確列出了告警事件。在開始實驗之前,首先查看原始的OpenStack網絡拓撲信息,如圖6所示。
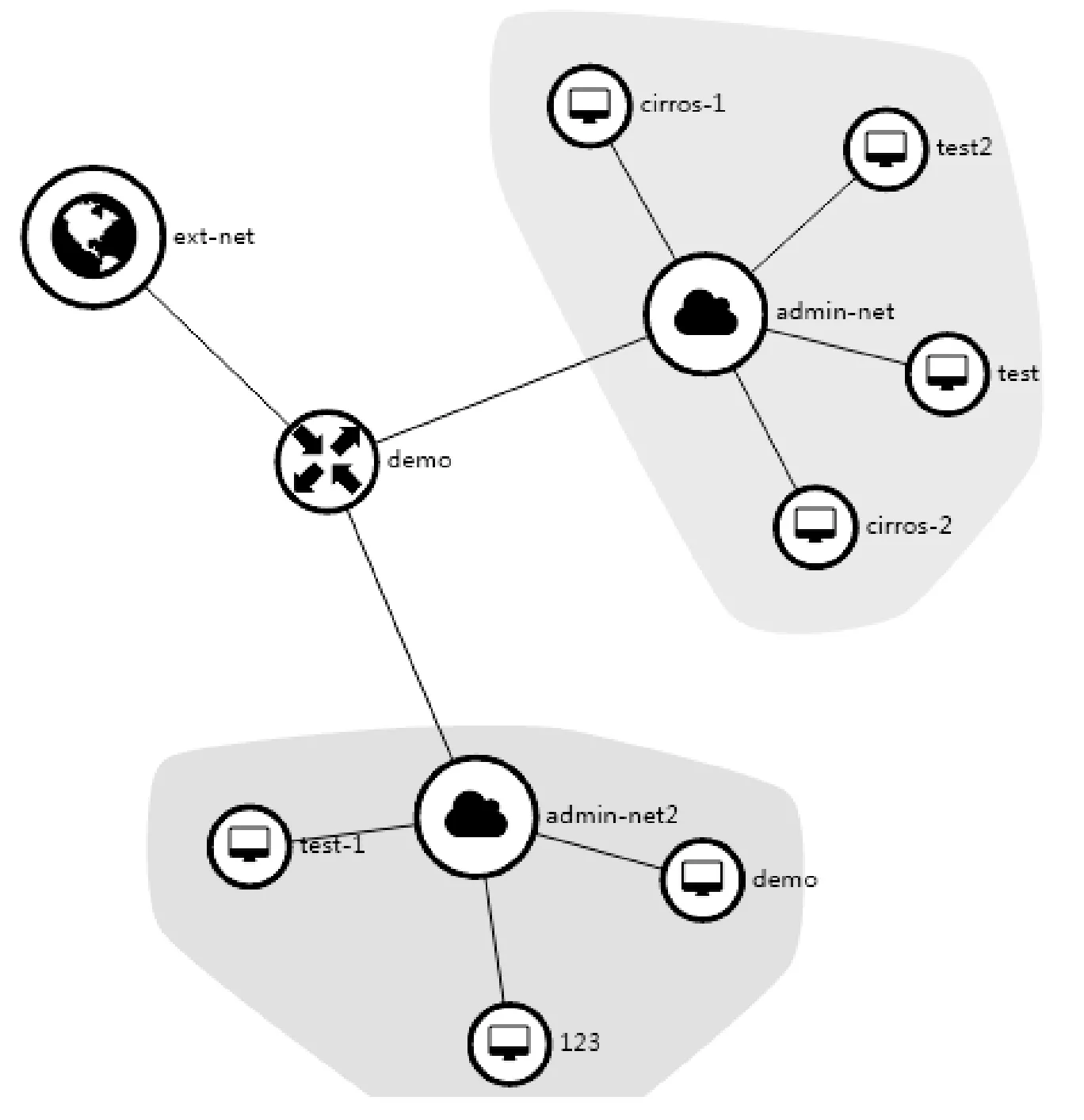
圖6 OpenStack原始虛擬網絡拓撲
本次模擬實驗將利用Open vSwitch提供的管理工具ovs-vsctl命令,繞過OpenStack的認證和請求機制,直接把圖6中的一臺名為demo的虛擬機以篡改虛擬網絡端口配置的形式從admin-net2網絡移動至admin-net網絡。
首先登錄demo虛擬機所在的計算節點Compute1,并查看確認Open vSwitch中現有虛擬網絡的配置情況,如圖7所示。通過OpenStack的Nova模塊可以查出,虛擬機demo連接在Open vSwitch上的虛擬端口是qvo44f28f88-20。通過Neutron模塊和ovs-db可以查出,admin-net對應在Compute1上的Open vSwitch虛擬網絡VLAN tag是1,admin-net2對應的VLAN tag是3。于是使用ovs-vsctl set port qvo44f28f88-20 tag=1命令就實現了把虛擬機demo從原本所在的admin-net2網絡篡改到了admin-net網絡,從而成功模擬出來第二類虛擬網絡異常實體。成功模擬攻擊后,分別查看OpenStack的Dashboard界面上的網絡拓撲以及虛擬網絡異常實體展示頁面,結果是OpenStack上顯示的網絡拓撲與改變網絡以前完全一致,并未發現系統中出現了異常實體。而在異常實體展示頁面上,則可以看到詳細的告警信息,告知管理人員虛擬網絡異常實體所在的主機、異常實體的類型、被檢測出的時間、相關聯的Open vSwitch虛擬端口名稱、虛擬機的UUID、MAC地址以及攻擊前后端VLAN tag等,并提示安全管理人員進行處理。
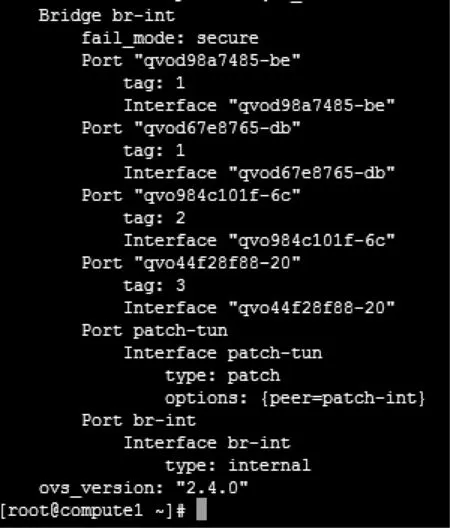
圖7 Open vSwitch端口信息
實驗表明,本文設計的虛擬網絡異常實體檢測方案確有實效,其他類型的虛擬網絡異常實體可以通過類似的實驗加以證明。
4 結 語
本文探討了當前以OpenStack為代表的松耦合架構的云平臺中存在的虛擬網絡異常實體問題,并提出了一種檢測方案。該方案可以及時有效地發現系統中存在的虛擬網絡異常實體,并通過實驗驗證了這一點。在接下來的工作中,我們準備結合操作日志,引入日志關聯分析的有關技術來還原這些異常實體產生的操作現場,使得安全管理人員不僅能夠及時發現問題,還能查明問題產生的原因,從而能夠更加全面地掌握系統的運行情況,最終可以更加高效地處理這些安全問題。
猜你喜歡
井岡教育(2022年2期)2022-10-14 03:11:44
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·八年級物理人教版(2019年9期)2019-11-25 07:33:00
中華手工(2017年2期)2017-06-06 23:00:31
中學生數理化·中考版(2017年12期)2017-04-18 12:55:05
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中學生(2015年2期)2015-03-01 03:43:33
中外會展(2014年4期)2014-11-27 07:46:46
