改進Kmeans算法的海洋數(shù)據(jù)異常檢測
2018-10-24 03:06:50王慧嬌羅一迪
計算機工程與設(shè)計 2018年10期
關(guān)鍵詞:檢測
蔣 華,季 豐,王慧嬌,王 鑫,羅一迪
(桂林電子科技大學 計算機與信息安全學院,廣西 桂林 541000)
0 引 言
近十幾年來我國海洋監(jiān)測領(lǐng)域有了長足發(fā)展,獲取了大量Argo浮標監(jiān)測數(shù)據(jù)。但是據(jù)Argo資料的應用研究顯示,Argo浮標由于自身所攜帶的電導率傳感器,在運行過程中由于系統(tǒng)漂移而導致出現(xiàn)錯誤的監(jiān)測數(shù)據(jù),需要在海洋Argo浮標監(jiān)測數(shù)據(jù)處理過程中盡可能的將異常數(shù)據(jù)剔除。
在“無監(jiān)督學習”(unsupervised learning)中,Kmeans算法是應用最廣研究最多的聚類算法之一。研究者們在傳統(tǒng)Kmeans基礎(chǔ)上提出了許多改進算法,如MinMaxKmeans算法[1]、KMOR算法[2]、Seeded-KMeans[3]和IWO-KMeans算法[4]等,聚類效果相較于傳統(tǒng)算法有了明顯改善,在此基礎(chǔ)上進行的異常值檢效率也更高。文獻[5-10]提出了K模式聚類的兩種不同的初始化算法,但不能保證初始中心點均勻分布,且算法復雜度較高。文獻[11-13]提出了3種分階段聚類方法,但時間復雜度高,人為設(shè)置約束信息使聚類變成有監(jiān)督聚類。聚類和異常檢測[14,15]作為數(shù)據(jù)挖掘的兩個重要研究方向,可以很自然地結(jié)合起來共同研究。
為解決海洋Argo浮標數(shù)據(jù)中存在異常值問題,第一步,提出DMKmeans算法,通過計算給定鄰域范圍內(nèi)數(shù)據(jù)點密度值,按密度值大小降序排列數(shù)據(jù)集,剔除低于平均密度值的數(shù)據(jù)點。排除密度稀疏點,在剩下的數(shù)據(jù)點中選取初始聚類中心點。第二步,基于DMKmeans算法對海洋監(jiān)測數(shù)據(jù)進行異常檢測研究,根據(jù)數(shù)據(jù)點距離所在簇簇心的最近距離與平均距離比較,結(jié)合數(shù)學模型來判斷異常點。DMKmeans算法優(yōu)化了傳統(tǒng)Kmeans算法選取初始中心點的方法,降低了聚類迭代次數(shù)并達到全局最優(yōu)結(jié)果,有效提高海洋監(jiān)測數(shù)據(jù)異常檢測率。
1 相關(guān)理論研究
1.1 傳統(tǒng)Kmeans算法
傳統(tǒng)的Kmeans算法是“無監(jiān)督學習”算法,即對未標記的數(shù)據(jù)集進行聚類分析。算法思想:首先隨機選取k個初始聚類中心,每一個聚類中心代表一類數(shù)據(jù)集簇;然后將數(shù)據(jù)點劃分到最近的數(shù)據(jù)簇;重新計算數(shù)據(jù)簇中心點,直到聚類準則函數(shù)收斂。收斂函數(shù)定義請參見文獻[15],函數(shù)如下
(1)
式中:E為Kmeans算法針對樣本D={x1,x2,…,xk}聚類所得簇C={C1,C2,…,Ck}劃分的最小化平方誤差,ui表示為
(2)
式中:ui是簇Ci的均值向量。直觀來看,式(1)在一定程度上刻畫了簇內(nèi)樣本圍繞簇均值向量的緊密程度,通常E值越小則簇內(nèi)樣本相似度越高。
Kmeans算法描述見表1。

表1 Kmeans算法描述
傳統(tǒng)的Kmeans算法對于大量數(shù)據(jù)集聚類有一定的效果,是研究者廣泛研究的聚類算法之一,仍然存在初始聚類中心點的隨機選定造成聚類結(jié)果局部最優(yōu)問題。
1.2 密度分布函數(shù)
在數(shù)據(jù)空間Rd中,存在數(shù)據(jù)對象x和x′,數(shù)據(jù)點x′對數(shù)據(jù)點x的影響函數(shù)定義為DensityB(x,x′),本質(zhì)上該影響函數(shù)由兩個數(shù)據(jù)點之間的距離決定,如歐氏距離函數(shù)。高斯函數(shù)是經(jīng)典的影響函數(shù),其定義如下
(3)
而數(shù)據(jù)點x的密度函數(shù)則是鄰域參數(shù)δ范圍內(nèi)所有最近鄰居對其影響函數(shù)之和,即若給定n個數(shù)據(jù)對象X=(x1,x2,…,xn)對于數(shù)據(jù)點x的密度函數(shù)可定義如下
(4)
式中:xi∈X,d(x,xi)為數(shù)據(jù)點x到其第i個最近鄰點的最小距離,直觀的通過密度函數(shù)式(3)可以看出d(x,xi)值越小Density(x)的值越大則數(shù)據(jù)點x的密度越大。
1.3 貝塞爾公式
貝塞爾公式是常用的標準偏差δ估計方法,在實際應用常常是對有限的數(shù)據(jù)樣本量做標準偏差估計,但由于它并不是一個總體的標準偏差而只是一個近似估計值,因此用s表示
(5)

1.4 拉伊達準則
在整理聚類結(jié)果數(shù)據(jù)時,往往會發(fā)現(xiàn)總有一些數(shù)據(jù)會存在偏差較大或者分布較為突出的數(shù)據(jù),這些數(shù)據(jù)很可能是異常值(Outliers)或噪音數(shù)據(jù),拉伊達準則主要用以判別這些數(shù)據(jù)是否異常值從而可以決定是否保留這些數(shù)據(jù)。若存在一組聚簇樣本D=(x1,x2,…,xn),算出其在某一準則如距離簇心最近距離下的平均值x以及待檢測數(shù)據(jù)元素的值xv,若是能夠符合下列關(guān)系
Tabn=|xv-x|≥3s
(6)
則判斷其為異常值點,其中s值為該樣本的標準偏差估計,可通過式(5)計算得出。
2 基于DMKmeans算法的異常檢測
2.1 DMKmeans算法
在本文的第二部分相關(guān)理論研究中,對傳統(tǒng)Kmeans算法進行深入研究,該算法快速簡單容易實現(xiàn),對于大量數(shù)據(jù)集有較好的聚類效果,自行優(yōu)化迭代次數(shù)比較適合大型數(shù)據(jù)集等優(yōu)點。但同時也存在一些缺點,最主要的是初始聚類中心的隨機選擇可能使聚類效果受到離群數(shù)據(jù)的影響,造成聚類結(jié)果的局部最優(yōu)而非全局最優(yōu)。針對Kmeans算法的這些不足提出了DMKmeans算法,計算Rd空間上數(shù)據(jù)集X中的每一個數(shù)據(jù)點x在給定鄰域半徑δ范圍內(nèi)的最近鄰居點集合G(x),計算數(shù)據(jù)點x的密度函數(shù)Density(x)得到其密度值,并且按照升序放入集合X′中,剔除密度值小于平均密度值的數(shù)據(jù)點,從集合X′中選出密度值最大的數(shù)據(jù)點為聚類中心點,以選定的初始聚類中心點開始聚類,這樣聚類結(jié)果相對穩(wěn)定并可以保證全局最優(yōu)。
DMKmeans算法步驟如下:
(1)在空間Rd上的數(shù)據(jù)集X={x1,x2,…,xn}中的每一個數(shù)據(jù)點xi,其中xi∈X,計算其在給定鄰域半徑δ內(nèi)的最近鄰集合Gk(xi),即d(xi,xj)≤δ且xj∈Gk(xi),其中k為xi在鄰域范圍內(nèi)最近鄰數(shù)據(jù)點個數(shù);
(2)計算數(shù)據(jù)點xi的密度函數(shù)值
(7)
式中:xj∈Gk(xi),當xi在鄰域范圍內(nèi)的最近鄰點xij的密度值小于平均密度值時,即滿足下列條件
(8)
則將數(shù)據(jù)點xij視為稀疏數(shù)據(jù)并剔除掉,從而得到密集點集合X′;
(3)從密集點集合X′中,選取密度值最大的點Densitymax(x),為第一個初始聚類中心C1;然后取距離C1最遠的數(shù)據(jù)點作為第二個聚類中心C2;對于第s個中心點的選取則是滿足如下條件的數(shù)據(jù)點xs且xs∈X′,取滿足xs與以選中的聚類中心Cs的距離值最小的數(shù)據(jù)點作為中心點,即max(dmin(xs,C1),dmin(xs,C2),…,dmin(xs,Cs-1))其中3≤s≤k,直到最終得到所需k個初始聚類中心點,并代表k個類簇ωl,l∈(1,…,k);
(4)計算數(shù)據(jù)集X中數(shù)據(jù)點xi至各個聚類中心點的歐氏距離
(9)
式中:i=1,2,…,n且j=1,2,…,k;如果d(xi,Cj)為最小距離值,則將數(shù)據(jù)點xi歸入中心點Cj所代表的數(shù)據(jù)簇ωj中,重復該過程直到最終聚類完成;
DMKmeans算法,使用密度函數(shù)來計算出數(shù)據(jù)集中各個數(shù)據(jù)點的密度值,結(jié)合最遠距離原則在高密度數(shù)據(jù)集合中選取初始中心保證其均勻分布,避免噪音數(shù)據(jù)對取定初始聚類中心的影響,使聚類迭代過程從數(shù)據(jù)高密度區(qū)域出發(fā),有效提高迭代效率,減少迭代次數(shù)。
2.2 基于DMKmeans算法的異常檢測
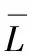
(10)
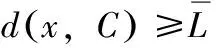
算法過程如下:
(1)設(shè)置空間Rd上的數(shù)據(jù)集X中數(shù)據(jù)點的鄰域半徑δ值;
(2)在空間Rd上的數(shù)據(jù)集X={x1,x2,…,xn}中的每一個數(shù)據(jù)點xi,其中xi∈X,計算其在給定鄰域半徑δ內(nèi)的最近鄰集合Gk(xi),即d(xi,xj)≤δ且xj∈Gk(xi),其中k為xi在鄰域范圍內(nèi)最近鄰數(shù)據(jù)點個數(shù);
(3)據(jù)點xi的密度函數(shù)值
(11)
式中:xj∈Gk(xi),當xi在鄰域范圍內(nèi)的最近鄰點xij的密度值小于平均密度值時,滿足下列條件
(12)
則將數(shù)據(jù)點xij視為稀疏數(shù)據(jù)并剔除掉,從而得到密集點集合X′;
(4)從密集點集合X′中,選取密度值最大的點Densitymax(x),為第一個初始聚類中心C1;然后取距離C1最遠的數(shù)據(jù)點作為第二個聚類中心C2;對于第s個中心點的選取則是滿足如下條件的數(shù)據(jù)點xs且xs∈X′,即max(dmin(xs,C1),dmin(xs,C2),…,dmin(xs,Cs-1))其中3≤s≤k,直到最終得到所需k個初始聚類中心點,并代表k個類簇ωl,l∈(1,…,k);
(5)計算數(shù)據(jù)集X中數(shù)據(jù)點xi至各個聚類中心點的歐氏距離
(13)
式中:i=1,2,…,n且j=1,2,…,k;如果d(xi,Cj)為最小距離值,則將數(shù)據(jù)點xi歸入中心點Cj所代表的數(shù)據(jù)簇ωj中,計算其最小化平方誤差E,并對ωj中所有數(shù)據(jù)點計算距離均值從而得到新的聚類中心點;
(6)重復過程(5)直到聚類準則函數(shù)收斂,即前后兩次迭代所得出式(1)中E的值的差小于等于閾值η即|E-E′|≤η,聚類中心點不再改變,至此聚類過程結(jié)束,得出聚類結(jié)果;
(7)計算最終數(shù)據(jù)簇ωp中數(shù)據(jù)點xi到簇心Cp的平均距離
(14)
(8)若待觀察序列U中的數(shù)據(jù)點xa∈U到簇心的距離值da滿足條件
(15)
則判定該數(shù)據(jù)點為異常點,將其保留在數(shù)據(jù)集U中,否則的話將不滿足條件的數(shù)據(jù)點放回原來聚類數(shù)據(jù)簇中,重復上述過程直到最終異常值檢測完成并輸出異常值點。
基于DMKmeans算法的數(shù)據(jù)異常檢測算法,在全局最優(yōu)聚類結(jié)果基礎(chǔ)上使用拉伊達準則,貝塞爾公式等數(shù)學模型來進行數(shù)據(jù)異常檢測,異常檢測率較高。
3 實驗及結(jié)果分析
通過DMKmeans算法與傳統(tǒng)Kmeans算法以及MinMaxKmeans算法的海洋監(jiān)測數(shù)據(jù)仿真實驗對比,驗證算法的可靠性和穩(wěn)定性,實驗評估指標主要有運行平均時間、迭代次數(shù)、聚類準確率、異常檢測率等。
實驗環(huán)境:Matlab2016a、Windows7 64 bit、CUP 2.67 GHz、內(nèi)存6 G。所使用數(shù)據(jù)集為海洋Argo浮標監(jiān)測數(shù)據(jù)集,數(shù)據(jù)來源于中國Argo實時資料中心公開數(shù)據(jù)集。實驗參數(shù)δ=0.5,K=5,η=0.01。
圖1為本文所提DMKmeans算法海洋監(jiān)測數(shù)據(jù)異常檢測仿真實驗,圖2為MinMaxKmeans算法海洋監(jiān)測數(shù)據(jù)異常檢測仿真實驗,圖3為傳統(tǒng)Kmeans算法海洋監(jiān)測數(shù)據(jù)異常檢測仿真實驗,以上3個實驗圖形中均有5個聚類數(shù)據(jù)簇,其中‘+’代表檢測出的異常點。與其它兩種對比算法相比較,DMKmeans算法在聚類效果上聚類數(shù)據(jù)簇更加緊密清晰,類簇分布更加均勻,基于DMKmeans算法的海洋監(jiān)測數(shù)據(jù)異常檢測相比傳統(tǒng)Kmeans算法以及MinMaxKmeans算法準確率更高。
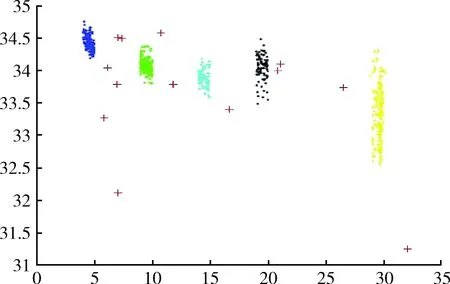
圖1 DMKmeans算法異常檢測
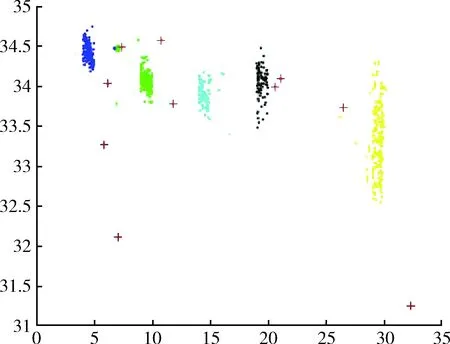
圖2 MinMaxKmeans算法異常檢測
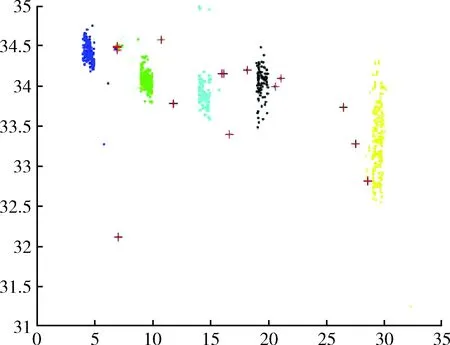
圖3 傳統(tǒng)Kmeans算法異常檢測
從表2、表3實驗數(shù)據(jù)可以看出,本文提出的DMKmeans算法在迭代次數(shù)和聚類準確率上都優(yōu)于MinMaxKmeans算法和傳統(tǒng)Kmeans算法,在此基礎(chǔ)之上所做的海洋監(jiān)測數(shù)據(jù)異常檢測仿真實驗,平均運行時間比MinMaxKmeans算法以及傳統(tǒng)Kmeans算法更短,異常檢測率較其它兩種算法要高。結(jié)合以上仿真實驗結(jié)果和數(shù)據(jù)分析可以得出結(jié)論,DMKmeans算法比MinMaxKmeans算法以及傳統(tǒng)Kmeans算法在聚類和異常檢測方面更加優(yōu)化,可以滿足實際應用的需求,有助于海洋Argo浮標數(shù)據(jù)集聚類以及異常檢測。

表2 聚類實驗結(jié)果對比
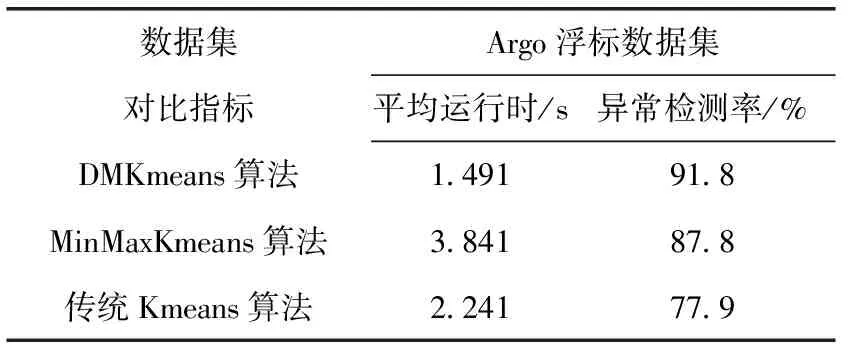
表3 異常檢測實驗結(jié)果對比
4 結(jié)束語
DMKmeans算法解決了傳統(tǒng)Kmeans算法初始聚類中心隨機選取造成聚類結(jié)果局部最優(yōu)的問題,選擇密度分布較高的數(shù)據(jù)點作為初始聚類中心可以有效排除離群點對初始聚類的干擾,初始聚類中心均勻分布,減少迭代次數(shù),使最終聚類結(jié)果全局最優(yōu),基于DMKmeans算法的海洋監(jiān)測數(shù)據(jù)異常檢測可以有效檢測出海洋Argo浮標數(shù)據(jù)集中的異常值。
通過DMKmeans算法與傳統(tǒng)Kmeans算法及MinMaxKmeans算法的海洋監(jiān)測數(shù)據(jù)異常檢測仿真實驗對比分析,DMKmeans算法在運行時間、迭代次數(shù)相比傳統(tǒng)Kmeans算法和MinMaxKmeans算法更少,聚類速度更快,對異常數(shù)據(jù)檢測更加穩(wěn)定。DMKmeans算法的聚類準確率和異常檢測率高于其它兩種對比算法。本文提出的DMKmeans算法能更好地檢測出海洋Argo浮標數(shù)據(jù)集中的異常數(shù)據(jù)。隨著大數(shù)據(jù)時代到來,使用大數(shù)據(jù)平臺對更加海量的數(shù)據(jù)集和高維數(shù)據(jù)集的異常檢測將會成為本文下一步研究的重點。
猜你喜歡
中國設(shè)備工程(2022年12期)2022-07-11 04:33:00
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2019年9期)2019-11-25 07:34:36
中學生數(shù)理化·七年級數(shù)學人教版(2019年9期)2019-11-25 07:34:34
中學生數(shù)理化·七年級數(shù)學人教版(2019年12期)2019-05-21 02:53:50
中學生數(shù)理化·七年級數(shù)學人教版(2019年12期)2019-05-21 02:53:48
