基于TMS320F28335的聲碼器設計與實現
2018-10-24 07:46:28孫鳳梅薛顏李克靖
電子設計工程 2018年20期
關鍵詞:系統
孫鳳梅,薛顏,李克靖
(中國電子科技集團公司第五十八研究所江蘇無錫 214035)
近年來,語音通信系統發展迅速,需要使用不同速率的語音編解碼算法,在有限的帶寬中對語音進行編碼去冗余并準確地傳遞[1]。面對越來越復雜的通信環境,低速率語音編解碼算法能夠在保證了合成語音質量的同時,有效地提高通信系統容量,主要應用于軍事保密通信,衛星通信和數字語音存儲系統[2]。低速率語音編解碼算法可以分為波形編碼、參數編碼及混合編碼。典型的編碼算法有:多帶激勵編碼、混合激勵線性預測編碼、正弦變化編碼、正弦激勵線性預測(SELP)等[3-7]。其中清華大學自主研發的SELP模型基于線性預測技術,具有提取參數方便、合成語音質量高的特點,是極具潛力的低速率語音編碼模型。基于SELP模型已經實現了各種低速率編解碼算法[8]。然而,通過研究發現,當清濁音判決不夠準確或發生基音周期的倍/半頻錯誤時,一些碼率下的語音編碼算法的合成語音會出現機器音較重、偶發性嘶啞及變調等問題。因此,為得到更高質量的合成語音,需要提高參數提取的精度[9]。
目前,語音編解碼專用集成電路并不是很多。其中最著名的是美國DVSI公司生產的AMBE系列的聲碼器芯片,包括AMBE-1000TM、AMBE-2000TM、AMBE-3000TM等系列。其中,AMBE-3000TM是DVSI公司生產的新一代編解碼芯片,能夠提供最低2.0 kb/s的編碼速率,編碼速率可以在2.0~9.6 kb/s之間靈活選擇[10-11]。但多數情況下,用戶需要根據實際應用設計專用的編解碼算法并實現其硬件模塊,因此在當前的衛星通信、數字移動通信、數字聲音存儲等領域,通過數字信號處理器(DSP)實現的實時語音編解碼器得到越來越廣泛的應用[12-15]。
文中設計實現了一種基于TMS320F28335 DSP的多速率聲碼器,該聲碼器可實現基于SELP算法的2.4 kb/s、1.2 kb/s及0.6 kb/s 3種低速率的語音編解碼算法。在參數提取過程中,通過支持向量機分類器進行清濁音的判決。根據算法復雜度及DSP芯片結構對算法進行優化,在硬件集成和調試后,實時實現了聲碼器通信系統。
1 語音編解碼算法
SELP算法采用與基因頻率成倍頻關系的正弦信號激勵,使需要編碼量化傳輸的語音參數數目大大降低,從而降低了編碼速率。
1.1 SELP語音編解碼算法
SELP語音編碼算法原始輸入語音為PCM信,采樣率為8 kHz。算法采用分幀處理方法,每幀語音包含樣點數160~240。本文算法中,子幀幀長為25 ms,采樣點數為200個。圖1為SELP模型的編碼框圖。
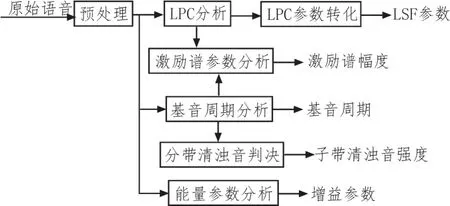
圖1 SELP編碼端框圖
輸入語音首先進行預處理。是對8 kHz濾波后的語音信號再進行以下的分析處理。線性預測分析得到10維的預測系數(LPC)。通常將LPC系數轉換為頻域上的線譜對(LSF)參數進行量化傳輸。余量譜提取時先進行512點DFT變換,將最大峰值作為諧波幅度。SELP算法采用子相關法提取基音周期。采用帶通語音信號的子相關函數和其包絡信號的自相關函數聯合判斷子帶的清濁狀態。為了提高算法的抗誤碼性能,采用對殘差信號的處理得到短時能量參數。
在特征參數的量化時,一般共有5個語音參數用于量化編碼,將碼流傳遞到解碼端。但在低速率情況下,為了節省比特數,在矢量量化時采用了超幀策略,以2幀或3幀構成一個超幀為運算單元。1200 b/s的編解碼算法由2個連續語音子幀組成一個超級幀,600 b/s則是由3個子幀組成一個超級幀。另外,余量譜參數可以不參加量化,在解碼端用歸一化“1”值代替。3種不同編解碼速率具體參數的量化比特分配見表1。
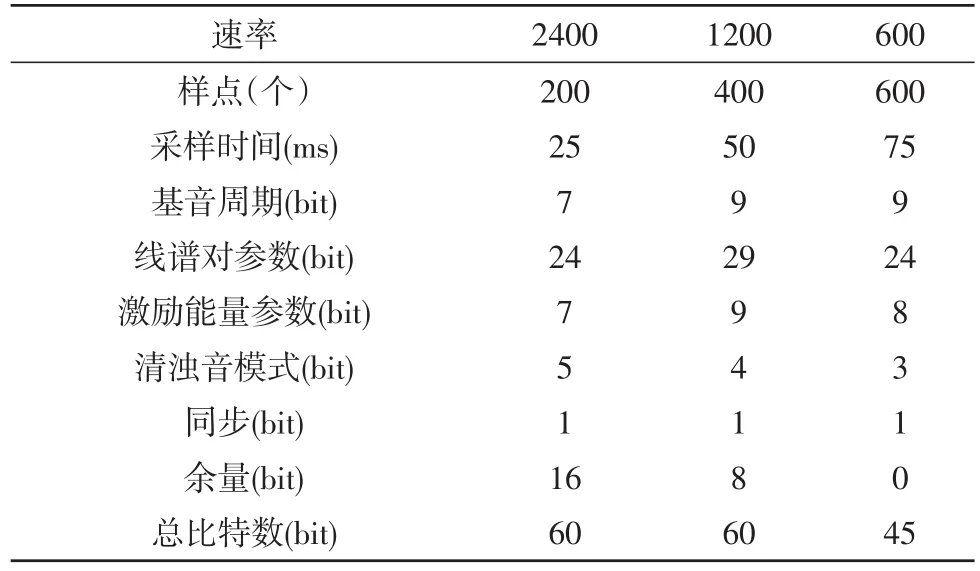
表1 SELP算法比特分配
在解碼端,將接收到的各個特征參數進行反量化,得到基音周期、線譜對參數等5組特征參數。SELP模型的解碼原理框圖如圖2所示。激勵信號采用清音成分與濁音成分混合組成。根據子帶清濁判決結果,其中清音成分用白噪聲描述,由噪聲發生器產生。濁音成分由一組不同幅度、頻率變化的的正弦信號疊加而成。最后,合成的激勵信號通過合成濾波器、后濾波器濾波后得到合成語音。
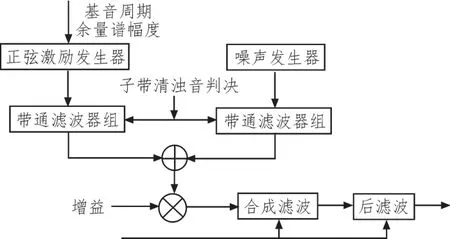
圖2 SELP解碼端框圖
1.2 基于SVM的清濁音判決
支持向量機在線性分類器的基礎上,引入結構風險最小原理和最優化理論,根據有限的樣本信息,在模型學習能力和復雜性之間尋求最佳折衷,克服了“維數災難”[16]。
假設訓練樣本集有n個訓練樣本,分為兩種類別:(x1,y1),…,(xn,yn),xi∈Rk,其中yi∈{-1,1}是分類標簽。典型SVM的主要思想是構造一個間隔最大的最優超平面wTx+b=0。如果存在一個超平面可以將所有訓練數據無錯誤地分開,并且離超平面最近的向量與超平面之間的距離是所有可能情況中最大的。即對于w和b,滿足以下條件:
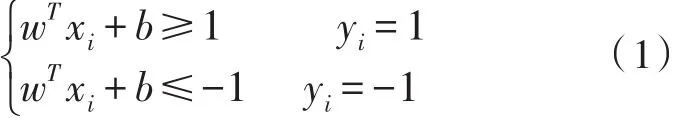
由統計學習理論可知,使分類距離最大實際上就是使推廣性的界中的置信范圍最小。通過引入松弛變量ξi求解以下優化問題得到參數w和b,得到廣義的最優分類面:
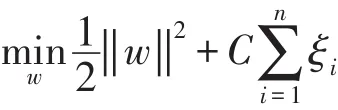
約束條件:
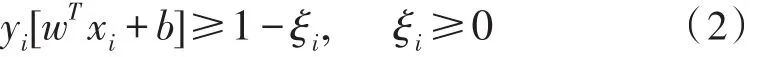
其中C為懲罰因子,C值越大表示對錯誤分類的懲罰越大。
提取語音特征參數的原則是:特征參數要對不同模式的分類可靠有效且取值范圍在待分類別中的交疊較少。下面給出本文算法所涉及到的最大自相關值(r),過零率(z),短時幀能量(e)和譜傾斜度(t)等4個特征參數的定義。
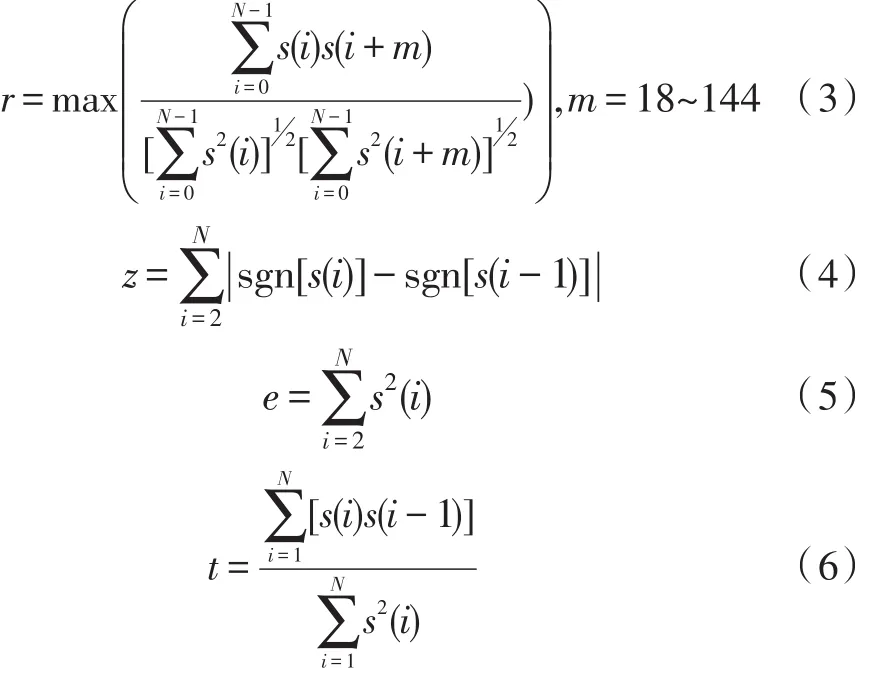
其中,N為每幀樣點數,s(i)為經過濾波后的語音信號。
通過對比分析,可以較為明顯地看出:濁音段的最大自相關值和短時幀能量較大,過零率較小;清音段的有較小最大自相關值和短時幀能量,及較大的過零率。譜傾斜度可以在一定程度上提高訓練所得分類器的分類準確度。對已經標記完成的語音樣本提取4個參數組成特征向量X=(r,z,e,t),輸入SVM進行訓練。
2 多速率聲碼器的硬件設計
2.1 芯片選擇
聲碼器是數字通信系統中一個關鍵的部分,通常要求其體積盡量小,成本和功耗盡量低、可靠性高。因此,在不影響系統性能的前提下盡可能簡化硬件設計。
TMS320F28335 DSP是高性能低功耗32位數字信號處理器,工作頻率為150 MHz,資源豐富,數據處理能力強,功耗低,集成了256k的Flash存儲器及34k的SRAM存儲器。由于完成3種速率下的編解碼算法的代碼量和所需的量化碼表所需的存儲空間非常大,TMS320f28335能夠滿足多速率語音編解碼算法對存儲空間的需求,不需要額外設計存儲器,即可用于完成語音編碼算法和控制功能。
模擬音頻接口部分采用TLV320AIC23B芯片。該芯片是一款通用型低功耗16位AD,DA音頻接口芯片,用于處理語音以及寬帶音頻,是可移動數字音頻應用系統中模擬輸入輸出的理想選擇。
2.2 聲碼器硬件實現
TLV320AIC23B與TMS320f28335都是TI公司提供的高速芯片,兩者在速度和時序上能夠完全匹配,實現芯片間的無縫連接。圖3為聲碼器硬件結構圖。
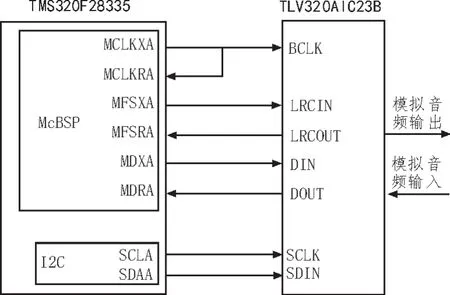
圖3 聲碼器硬件結構
TLV320AIC23B的編解碼器數字接口可直接與TMS320F28335的多通道緩沖串口(MCBSP)連接。其中BCLK提供位時鐘信號,FS提供幀同步信號,DIN為串行數據輸入,DOUT為串行數據輸出。TMS320F28335的I2C與TLV320AIC23B的控制口連接,對TLV320AIC23B的寄存器進行設置,配置語音幀速率為8 kHz,采樣精度為16 bit。
3 多速率聲碼器的系統實現
3.1 系統優化
3.1.1 存儲空間配置
存儲空間的合理分配是聲碼器實現的基礎,高效的存儲空間配置可以提高系統地處理速率,滿足聲碼器實時處理要求。在完成系統設計后,需要將程序固化在FLASH。然而,CPU訪問FLASH一般至少需要5個以上的等待周期。因此,在實際的實時處理系統中是需要通過Bootloader將程序從FLASH上加載到SRAM中并在SRAM中運行,使代碼運行最有效率。具體操作如下:
1)將code_start段中LB_c_int00語句更改為LB copy_sections;
2)將wd_disable段中中.text語句更改為.sect“wddisable”;
3)將wd_disable段中中LB_c_int00語句更改為LB copy_sections;
4)通過#pragma DATA_SECTION指令將數據放置SRAM上。
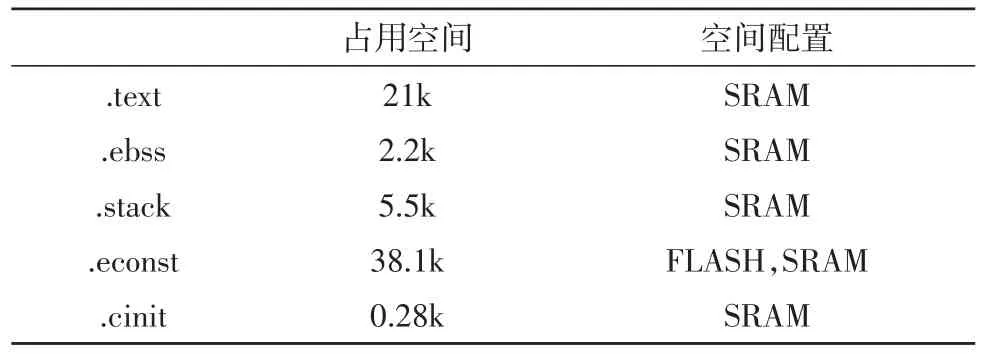
表2 聲碼器占用存儲器資源
從表2中可以看出,應用程序及編解碼數據量比較大,片內RAM空間不足以把所有的代碼和數據搬移到片內RAM,因此在搬移程序會將所有.text搬移到SRAM,而通過#pragma DATA_SECTION指令將部分碼表數據放置SRAM上。
3.1.2 程序匯編優化
通過集成開發環境CCS(Code Composer Studio,CCS)工具的profile功能可以分析統計算法各部分運算復雜度,測試所有函數運算量。根據profile的輸出結果,按照復雜度從高到低的順序編寫DSP匯編程序,直到達到實用水平。可以采用匯編語音實現。算法中調用頻繁,消耗較多CPU周期數的函數用匯編實現,大大提高程序的處理速度,實現了語音編解碼的實時處理。
3.2 系統碼率變換方式
由于聲碼器能夠實現0.6 k/1.2 k/2.4 kbps 3種速率的編解碼算法,在系統工作前,需要確定系統編解碼的速率。不同于AMBE系列芯片通過外部控制MCU發送控制命令字來改變聲碼器速率的方式,我們的聲碼器通過外部引腳高低電平的配置,直接來確定編解碼速率。具體控制接口的配置如表2。當MOD1與MOD2都配置為高電平時,編解碼速率為2.4 kbps。當MOD1配置為高電平,MOD2配置為低電平時,編解碼速率為1.2 kbps。當MOD1配置為低電平,MOD2配置為高電平時,編解碼速率為0.6 kbps。其中MOD1和MOD2為TMS320F28335的兩個通用GPIO。
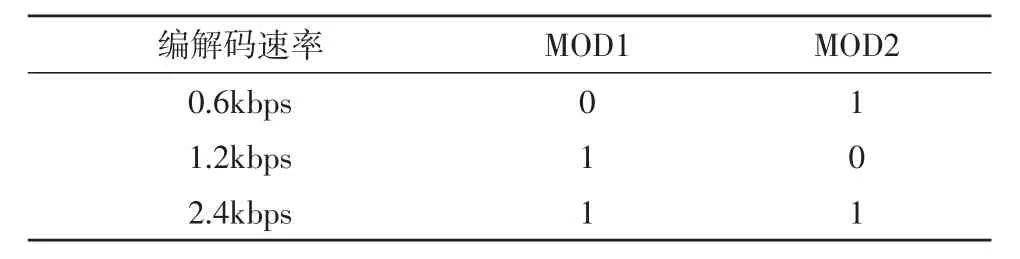
表3 編解碼速率控制接口的配置
3.3 系統工作流程
基于多速率聲碼器實現的語音通信系統的工作流程如圖4所示。完成系統初始化、語音參數配置、語音編碼和語音解碼。
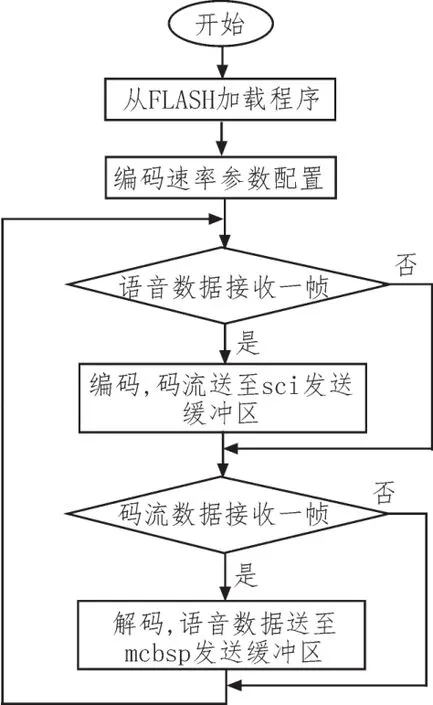
圖4 系統工作流程圖
系統開機加電或復位后,TMS320F28335運行自引導程序,將片上FLASH中的程序和數據加載至DSP內部SRAM。通過設置寄存器,初始化DSP系統和外圍電路,打開MCBSP、SCI中斷源。
讀取速率控制接口的值,根據速率控制接口的設置,確定編解碼速率,并初始化編解碼所需要的參數。數據化的語音信號通過多通道緩存串口傳送到DSP內部的緩沖區,送入編碼器進行編碼,得到的數據流經SCI傳輸。從SCI接收到的數據流傳給DSP內部緩沖區,送入解碼端解碼,得到的數字語音經MCBSP傳給DAC,轉換成模擬信號輸出。
4 實驗結果
在算法程序優化后進行軟件仿真測試,測試的語音格式為PCM,采樣為8000 Hz,語音數據精度為16bit,選自中國科學院聲學研究所語音數據庫。在清濁音判決中,SVM訓練樣本幀長為25 ms,訓練樣本共有2500幀。發音人為兩男兩女,其中清音約占55%,濁音45%。采用國際電信聯盟(International Telecommunication Union,ITU)建議的 p.862 MOS分測試軟件,測試指標為平均意見得分(Mean Opinion Score,MOS)。通過測試,平均MOS得分為3.197。圖為3種碼率下原始語音與合成語音的波形對比圖。
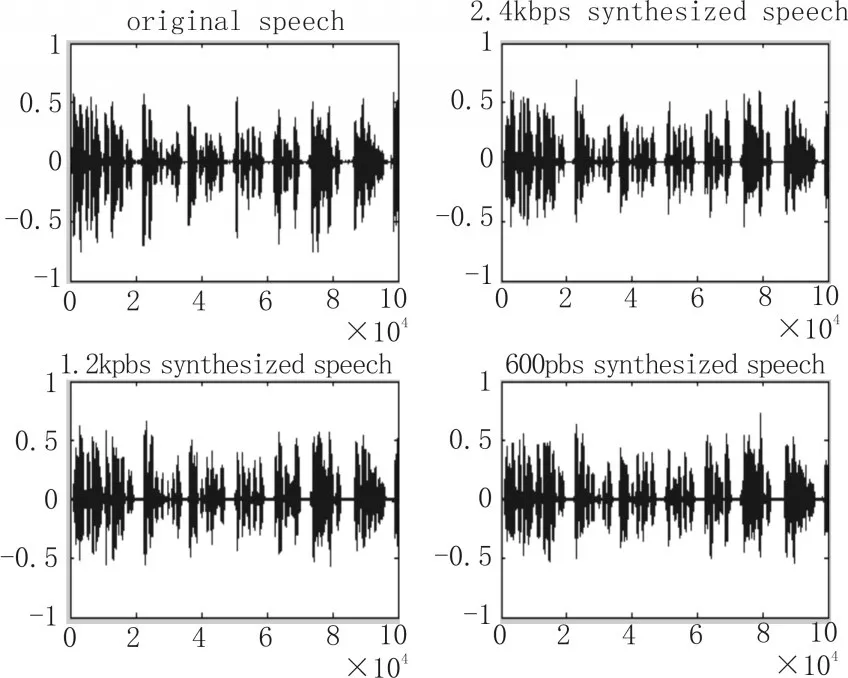
圖5 原始語音與合成語音的波形圖比較
為了測試了聲碼器的實時處理效果,在軟件優化、硬件集成后,實現了一個簡單的語音通信系統。下圖為已經完成的聲碼器語音通信系統實物圖。

圖6 聲碼器語音通信系統實物圖
通信系統中,需要兩塊聲碼器,聲碼器A和B都能夠同時進行編解碼,聲碼器的碼流通過SCI接口直接發送接收,通信波特率配置為115200 bps,無奇偶校驗位。從安排多人進行試聽的反映來看,合成語音清晰自然,偶發性嘶啞和變調問題得到一定的改善。聲碼器實現了2.4 kb/s,1.2 kb/s和0.6 kb/s 3種速率的編解碼算法,合成語音清晰自然。該聲碼器通過端口配置進行碼率轉換,具有較好的通用性和靈活性。
5 結論
文中設計實現的聲碼器軟件方面完成了2.4kbps、1.2 kbps及0.6 kbps 3種不同速率的編解碼算法,能夠適應不同環境下的通信場合。在參數提取過程中,通過支持向量機分類器進行清濁音的判決,能夠在一定程度上解決合成語音的偶發性嘶啞、變調等問題。聲碼器硬件設計能夠充分利用TMS320F28335 DSP的硬件資源,在成本、體積和功耗方面有一定優勢,通過端口配置進行碼率轉換,具有較好的通用性和靈活性。實驗結果表明,該聲碼器合成語音質量清晰自然,達到了預期的效果,在其低速率語音通信場合具有一定的應用前景。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
