數字保存的持續完整性風險檢測
2018-10-25 01:54:06臧國全朱曉慶李哲金燕
大學圖書館學報 2018年2期
臧國全 朱曉慶 李哲 金燕
摘要 針對數字保存風險之一的持續完整性風險設計檢測方法,并針對檢測方法進行實驗研究。(1)調研相關文獻,找出研究的切入點;(2)界定持續完整性的含義,析出產生持續完整性風險的因素;(3)設計持續完整性風險型元數據,設置該類風險的檢測點;(4)基于一個實際保存系統,利用分層隨機抽樣法,采集數字對象及其持續完整性風險型元數據內容的實驗樣本;(5)編制代碼,檢測數字對象樣本集的持續完整性風險點.統計檢測結果,分析可能的產生原因,制定可能的降低風險措施;(6)基于實驗結果,分析檢測方法的局限性.說明檢測方法的使用事項。
關鍵詞 數字保存持續完整性風險 風險檢測
分類號 G250
DOI 10.16603 /j.issn1002 - 1027.2018.02.010
1 文獻綜述
1.1 風險識別方面
數字保存的風險管理研究已有20余年。康威(Conway)是該領域的較早研究者,在其《數字世界的保存》中將數字保存活動識別為風險管理過程。之后,相關研究可歸為三類:
專用型風險模型。主要有數字對象文件格式的風險、保存介質的風險、特定類型數字資源(如Web數字資源)的保存風險等。這類模型適合于相應領域的風險識別,盡管它們具有一定的互補性,但無法替代綜合型風險模型。
綜合型風險模型。結構上有等級式風險模型、同位列表式風險模型、網狀式風險模型。另外,有些綜合型風險模型也描繪了風險、數字對象、保存環境之間的關系。《成功的數字保存威脅識別:用于風險評估的SPOT模型》一文從數字保存核心職責角度識別保存風險。由于這類模型的應用環境和目的不同,導致它們在風險的種類、數量及模型展現形式等方面存在差異。
數字保存風險的實證研究。如基于羅森塔爾(Rosenthal)模型并進行適當改造,對美國國會圖書館數字保存的風險檢查;基于萊特(Wright)模型的對大英圖書館數字保存介質的風險評估。這類研究是對已有模型的實證分析,有助于數字保存項目選擇合適的風險評估模型。
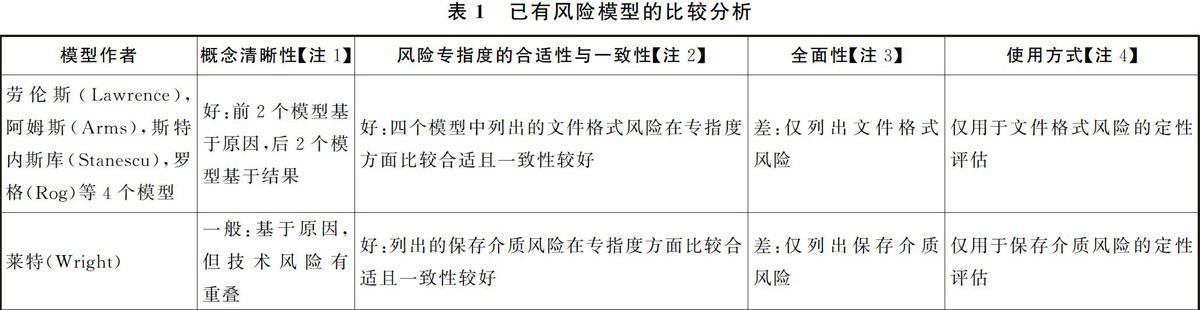
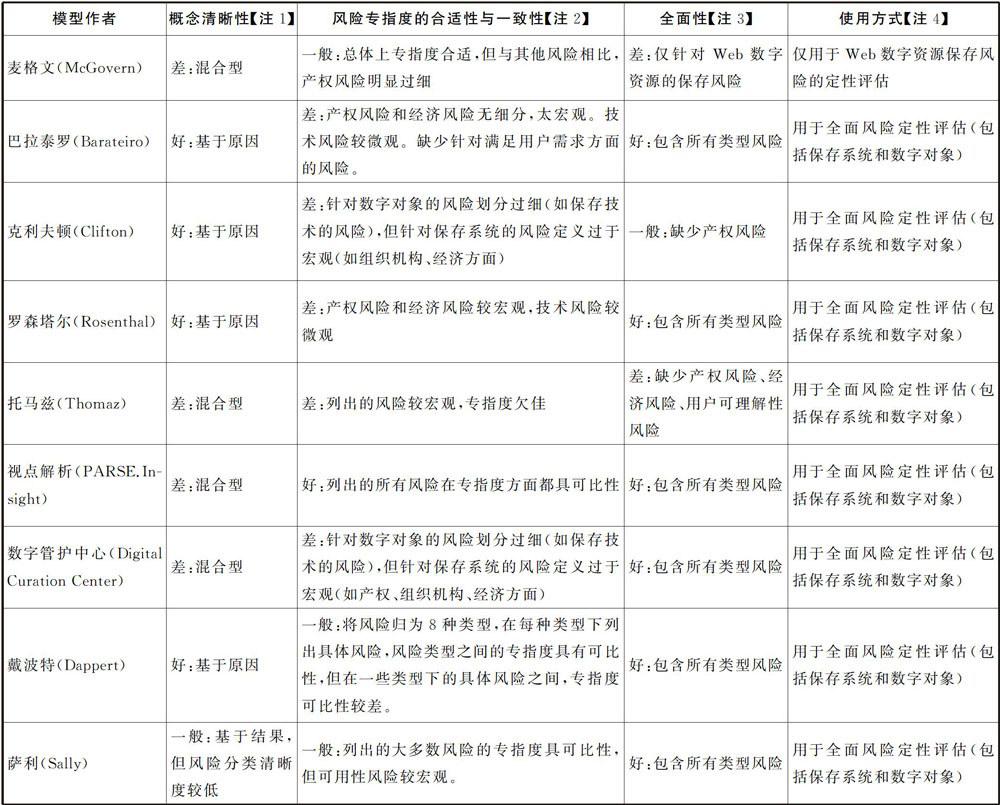
上述風險模型的優缺點分析見表1。基于表1的分析,已有的風險模型都存在不同程度的缺憾,還沒見到完全滿足表1列出指標的模型的報道。
[注1]:指應按照一種方法識別風險,避免歧義和重復。識別方法有兩種:一是基于風險發生的原因,如存儲介質退化;二是基于風險發生的結果,如二進制數據流序列被破壞。混合式風險列舉方法將影響概念的清晰性。
[注2]:指列舉的風險在概念外延上適中。外延太大的風險較難測度,也較難識別產生風險的具體原因;外延太小的風險可能會導致重復檢測;概念模糊的風險會導致檢測結果的誤差。另外,在任何結構的模型(等級式、同位列表式、網狀式)中,同位風險的概念外延應大致相當,且外延之和應與上位風險大致吻合。
[注3]:應列出模型界定范圍內的所有主要風險。比如,一個基于原因的針對數字對象的風險識別模型,若無存儲介質風險,則保存系統無法識別和管理這種風險。
[注4]:使用方式有兩種:定性評估和定量檢測。在所列模型的使用說明中,均表示可用于定性評估,但若用于定量檢測,需針對每個風險點設置檢測項目。
1.2 相關標準
ISO14721:2003。《OAIS參考模型》(OpenArchive Information System),制定了數字保存系統的框架結構和概念規范。起源于國際空間數據系統咨詢委員會(Consultative Committee for SpaceData Systems).目的在于維護數字對象的長期有效存取。
IS0 16363:2013。《可信任數字保存的審計與認證》,制定了保存系統的質量標準。其中的《可信任數字保存審查表》及其認證程序間接地展示了數字保存的風險。
IS0 16919:2014。《可信任數字保存的審計和認證機構要求》,制定了審計和認證的程序,以及對認證機構的基本要求。
由上可知,相關標準都不是真正的數字保存風險列表。ISO14721提供一個數字保存功能框架模型,目的是保證數字對象在長期保存過程中規避可能的保存風險,但不是一個風險列表。IS0 16363的《可信任數字保存審查表》實際上是數字保存的質量評價指標體系,雖然本質上每個指標隱含一種或多種風險,但并不是風險列表。IS0 16919是對數字保存質量認證機構的要求,也不是風險列表。
1.3 本研究的切入點
從風險發生的角度。數字保存的風險有兩個范疇:數字對象風險、保存系統的風險。前者有數字對象的獲取、存儲、維護和傳播等方面的風險,后者有保存系統經濟方面、產權管理方面的風險。已有的標準和風險識別模型(除專用型)都包括上述兩個范疇。本研究限定在第一個范疇,即數字對象產生的風險,當然第二個范疇的風險也會影響數字對象的風險,但這種影響是間接的,尤其是針對本研究的持續完整性風險。另外,一些保存活動也會導致數字對象產生風險,但這類風險常需要依據保存政策來判斷。所以,本研究的風險檢測點以風險型元數據形式呈現,包括數字對象方面的、保存事件方面的和保存政策方面的三種。
從風險類型的角度。數字對象的風險有多種,如持續完整性風險、可用性風險、可呈現性風險、真實性風險、可識別性風險、可理解性風險等。已有的標準和風險識別模型都囊括了數字對象的所有類型風險。但作為一篇學術論文,本研究僅限定在持續完整性風險,其他類型的風險后續研究。
從風險識別方法的角度。上述模型中的風險識別方法有三種:基于風險發生的原因、基于風險產生的結果、同時包括這兩種方式的混合型識別法。本研究首先基于全面風險管理理論劃分風險的范疇,然后針對每個范疇的風險,基于風險發生的原因,識別出風險點。
從風險評估的角度。已有的評估方法都是定性的,本研究的評估方法是定量的。為此,本研究對每個風險點設計檢測項目,編制代碼進行定量檢測,統計并分析檢測結果。
2 持續完整性及其風險檢測思路
2.1 持續完整性及其風險
持續完整性指構成數字對象的比特流持續存在且沒有被破壞,處于可使用、可操作狀態,并可從保存介質中完整檢索出來以實施瀏覽等操作。因此,確保數字對象比特流沒有發生任何形式的改變,并能從保存介質中被完整閱讀,是實現數字對象持續完整性的兩個必要條件。
持續完整性風險指保存系統中妨礙實現數字對象持續完整性的各種因素發生的可能性。這些因素包括:(1)數字對象的不適宜存儲,如保存條件不足導致無法實現所需的保存級別,致使長期保存過程中數字對象比特流可能被破壞且無法恢復,出現難以被操作使用的情況;(2)存儲介質超出有效期,導致介質自然退化,致使存儲的數字對象比特流序列可能被破壞,出現無法被完整檢索、瀏覽的情況;(3)存儲介質被破壞,或病毒導致,或操作人員失誤導致,致使保存的數字對象比特流不再持續完整;(4)用于判斷數字對象持續完整性的信息沒有被記錄,如信息摘要、密鑰信息等,導致長期保存過程中無法驗證數字對象是否被破壞,致使其持續完整性可能出現風險;(5)保存系統沒有按照保存政策的要求實施必要的保存活動,如存儲介質刷新、固定性檢查、病毒檢查等,導致數字對象的持續完整性亦可能出現風險。
總之,數字對象持續完整性風險主要存在于存儲介質的管理、保存系統的保存能力、保存事件的實施、數字對象相關信息的記錄、數據安全方針的制定等方面。
2.2 檢測思路
本文設計的檢測思路是:(1)界定持續完整性的含義,由此析出產生持續完整性風險的因素;(2)基于風險產生因素,設計持續完整性風險型元數據,由此實現該類風險檢測點的設置,并設置每個風險點的檢測項目;(3)基于一個實際保存系統,利用分層隨機抽樣法,采集數字對象及其持續完整性風險型元數據內容的實驗樣本;(4)編制代碼,檢測數字對象樣本集的持續完整性風險點的各個檢測項目,統計檢測結果,分析可能的產生原因,制定可能的降低風險措施。
3 持續完整性風險型元數據
根據全面風險管理理論,企業風險產生于企業整個運營過程,不僅來自生產經營的對象,還來自生產經營的活動以及相關政策。針對數字保存,“生產經營對象”是數字對象,“生產經營活動”是保存事件,“相關政策”是保存政策。因此,可從數字對象、保存事件、保存政策等角度來分析數字保存風險的產生因素,設置風險型元數據。
3.1 數字對象方面的持續完整性風險型元數據
數字對象是保存系統存儲和用戶訪問的獨立知識單元。有四種:一是知識實體,是描述一項特定知識所需的內容集合,如一本書、一幅地圖、一張照片、一個數據庫等;二是表現,是將一個知識實體實例化的一個數字化對象,一般由多個數字化文件及結構化元數據組成,用于知識實體的展現,一個知識實體可以有多個表現;三是文件,是可以被操作系統識別的一組有序的字節;四是比特流,是文件內連續或非連續的數據。針對持續完整性,只需檢測文件和比特流,因為其他兩類數字對象均由多個文件或比特流組成,若其中一個文件或比特流的持續完整性m現風險,對應的知識實體或表現的持續完整性自動出現風險。
數字對象方面的持續完整性風險型元數據是用于描述與持續完整性相關的數字對象屬性,是持續完整性風險的檢測點。這類元數據的元素有:
(1)數字對象標識符(Object Identifier)。數字對象被賦予的唯一標識符,以供檢索和發現,亦方便參考和引用。該元素內容可由保存系統收錄數字對象時創建,也可由生產者創建并與數字對象一起提交給保存系統。賦值方式有保存系統自動生成和人工賦值兩種。該風險點的作用為:該元素內容缺失導致無法識別對應數字對象,也就無法進行后續風險點的檢測。
(2)數字對象類型《Object Category)。用于描述數字對象的類型(知識實體、表現、文件、比特流)。該風險點的作用為:篩選用于檢測的文件和比特流對象;該元素內容缺失導致無法判斷數字對象是否適合持續完整性風險的檢測。
(3)固定性信息(Fixity Information)。描述數字對象在長期保存過程中是否被改變的驗證所需信息。固定性檢查需要計算數字對象的信息摘要,并與系統收錄時產生的信息摘要對比,如果兩個摘要相同,則該數字對象在保存過程中沒有改變,否則說明發生了改變。因此,固定性檢查是一個保存事件,記錄該保存活動的實施時間和檢查結果。但作為數字對象的一個屬性,固定性信息的描述項有:(a)信息摘要算法,如消息摘要算法第五版(MessageDigest Algorithm,MD5)、可變長度的哈希算法(Hashing Algorithm with Variable Length, HA-VAL)、安全散列算法(Secure Hash Algorithm,SHA-256)等;(b)信息摘要,信息摘要算法運行的結果。固定性信息的賦值可由數字對象提交者產生,但需保存系統驗證,否則需由保存系統在收錄數字對象時產生。
該風險點的檢測項目有:(a)若信息摘要算法內容為空,則無法計算新的信息摘要,無法判斷數字對象是否改變;(b)若信息摘要內容為空,則基于原始算法計算出的新信息摘要缺失對比的基準值,也無法判斷數字對象是否改變;(c)基于原始算法計算出的新信息摘要與原始信息摘要比較,若不同,數字對象發生改變。上述三種情況均歸為在該風險點上產生風險。
(4)簽名信息(Signature Information)。常用于信息傳輸過程中接收者確認信息來源的真實性。在數字保存中,可借用來判斷數字對象在長期保存過程中是否改變。基于數字簽名的持續完整性驗證方法為:(a)數字簽名值的生成,保存系統收錄數字對象時,采用一種哈希算法生成信息摘要,再使用保存系統私鑰對信息摘要進行加密生成簽名值;(b)持續完整性驗證,采用相同哈希算法生成數字對象的新信息摘要,使用保存系統的公鑰對數字簽名值解密獲取原始信息摘要,對比兩個信息摘要,若不同,則數字對象發生改變。
簽名信息的描述項有:(a)簽名者,若數字對象提交時已有簽名值,則簽名者為提交者,否則保存系統需生成簽名值,簽名者為保存系統;(b)簽名方法,生成簽名值所使用的加密方法和哈希算法,如數字簽名一安全散列算法(Digital Signature Algorithm-Secure Hash Algorithm,DSA-SHAl),前者為加密方法,后者是哈希算法;(c)信息摘要,基于簽名方法中哈希算法生成數字對象的摘要;(d)簽名值,使用私鑰對信息摘要加密生成的值;(e)密鑰信息,驗證數字簽名所需的簽名者公鑰信息。
該風險點的檢測項目有:(a)若簽名方法的內容為空,則無法計算新的信息摘要,導致無法判斷數字對象在保存過程中是否改變;(b)若密鑰信息或簽名值的內容為空,無法還原原始信息摘要,導致新信息摘要缺失對比的基準值;(c)基于簽名方法計算出的新信息摘要與基于密鑰信息和簽名值還原的原始信息摘要比較,若不同,則數字對象發生改變。上述三種情況均歸為在該風險點上產生風險。
與固定性信息相比,數字簽名增加了信息摘要的加密和對加密的信息摘要進行解密的過程,這種方法雖較復雜,但更準確,消除了同時惡意修改原始信息摘要和數字對象內容使基于固定性判斷結果數字對象沒有被改變的可能性。
(5)文件大小(Size)。數字對象的字節數量。若保存系統采用一個計量單位(如G,M,K),該元素只需記錄數字對象大小的值,無需記錄計量單位。
該風險點的檢測項目有:(a)將數字對象文件大小的檢測值與該元素的描述值比較,若不相等,數字對象發生變化;(b)若該元素內容為空,數字對象大小的檢測值缺失對比的基準值,無法判斷數字對象是否改變。上述兩種情況均歸為在該風險點上產生風險。
另外,如果數字對象的檢測值與該元素的描述值相等,也不能確保數字對象沒有發生改變,但為簡便起見,本文作為無風險處理。因此,該風險點的檢測結果具有一定誤差,遺漏了雖數字對象大小沒有改變但內容已變化的情況。
(6)保存級別(Preservation Level)。描述針對一個數字對象實施相應保存功能的保存決策信息,以及實施這些保存功能所需的保存環境信息。
保存系統可以根據數字對象的特征(如數字對象的價值和唯一性、格式的可保存性、法律法規的要求等)提供多個保存級別。保存級別的描述項有:(a)保存級別類型,描述選擇的保存級別期望對數字對象實施保存功能的類型,如“基于字節安全的保存”(即“比特保存”)。(b)保存級別值,描述對應類型的保存級別期望實施的保存功能,如“比特保存”級別類型的保存功能可為:“低”(無備份)、“中”(異地一個備份,不定期實施完整性檢測)或“高”(異地三個備份,定期實施完整性檢測,備份之間高度獨立)。(c)保存系統的勝任狀態,描述保存系統能否實現保存級別值定義的保存功能,比如“有能力”(指能夠實現且已實現),“需要”(指期望實現,但現在無法實現)。(d)保存級別的賦值原因,當數字對象的保存級別值與常規不同時,需描述其原因,如根據法律規定或合同約定,對一個數字對象的保存級別的賦值要高于同類型的其他對象時,該元素的值是“法律需求”或“合同約定”。(e)保存級別指定日期,隨著時間變化,需對數字對象的保存級別進行評估和修改,以適應保存系統的保存需求、策略或能力的變化。
該風險點的檢測項目有:(a)檢查“保存級別值”與實際實施的保存功能的相符性,如一個數字對象的保存級別值為上例的“中”,但數字對象在“存儲位置”元素中的描述僅有一個位置(即無備份),表明數字對象在遭到破壞情況下期望恢復,但實際上無法實現恢復,則判定該數字對象在該風險點存在風險;(b)檢查“保存系統的勝任狀態”,若為“需要”,表明保存系統目前無法實現確保數字對象持續完整性所需的保存功能,則判定該數字對象在該風險點存在風險。該元素的檢測結果屬于間接相關風險,即可能產生風險。
(7)存儲位置(Content Location)。存儲系統為數字對象分配的存儲定位,通常情況下,通過程序分配。存儲位置的描述項有:(a)存儲位置類型,如物理存儲、URI、絕對路徑、相對路徑;(b)存儲位置值,存儲系統使用的用于描述數字對象存儲位置的具體值,可以是一個完整的絕對路徑,也可以是解析系統中與物理路徑相對應的信息,還可以是存儲系統使用的相對路徑信息。根據保存級別,若數字對象存在多個備份,存儲位置也應有多個,可采用重復該元素的方式分別描述。
該風險點的檢測項目有:(a)若該元素內容為空,即使數字對象的唯一標識符存在,也無法獲取具體的數字對象,故也無法對數字對象實施相應檢測;(b)比較存儲位置的描述個數與保存級別中要求的數字對象備份數量是否相符,若不同,則可判定該數字對象在該風險點存在風險。由于持續完整性與存儲的具體位置無關,因此在對數字對象進行持續完整性風險檢測時,只需判斷其是否有存儲位置以及存儲位置的個數,無需檢查其具體的位置。上述兩種情況均歸為在該風險點上產生風險。
(8)存儲介質(Storage Medium)。描述數字對象所存儲的物理介質(如磁帶、硬盤、CD-ROM、DVD等)。若數字對象有多個備份,存在多個存儲介質,可采用重復該元素的方式分別描述。
該風險點的檢測項目有:(a)基于保存政策中保存介質的使用壽命,判斷數字對象的保存介質是否過期,有多個存儲介質時應分別判斷,若過期,保存的數字對象可能因為介質自然退化而遭到損壞。(b)判斷該元素的描述值是否為空,若為空,無法識別數字對象的存儲介質,導致無法知曉存儲介質的狀況,難以判斷保存的數字對象是否遭到破壞。(c)基于該元素的描述值,尋找保存政策中設置的相應存儲介質的刷新周期,判斷保存事件“介質刷新”的執行是否符合保存政策的要求,若不相符,保存的數字對象可能因為介質損傷沒有得到及時發現和修補而遭到破壞。上述三種情況均歸為在該風險點上產生風險。
3.2 保存事件方面的持續完整性風險型元數據
用于描述對數字對象實施保存操作的信息有兩種類型,一是執行結果產生新數字對象的事件,如數字遷移;二是執行結果不產生新數字對象的事件,如固定性檢查。由于持續完整性風險僅需對數字對象(包括相關保存環境)的檢查,所以這類風險檢測僅限在第二類事件。這類元數據的元素有:
(1)固定性檢查(Fixity Check)。根據保存政策對數字對象進行固定性檢查。如果沒有執行該事件或雖執行但不符合保存政策要求,該風險點產生風險。
(2)信息摘要計算(Message Digest Calculation)。保存系統通過計算獲得數字對象的原始信息摘要(若數字對象提交者提供原始信息摘要,保存系統需計算予以驗證)。如果沒有執行該事件,原始信息摘要缺失,無法執行固定性檢測事件,也無法進行固定性信息、數字簽名信息風險點的檢測,該風險點產生風險。
(3)保存介質刷新(Storage Medium Refresh)。根據保存政策對數字對象保存的介質進行刷新。如果沒有執行該事件或雖執行但不符合保存政策要求,該風險點產生風險。
(4)病毒檢測(Virus Check)。根據保存政策進行病毒檢測。如果沒有執行該事件或雖執行但不符合保存政策要求,該風險點產生風險。
3.3 保存政策方面的持續完整性風險型元數據
保存政策主要是數字保存操作的指標設置。分為兩類:一是保存系統對保存事件實施規則的描述信息,比如保存介質刷新的頻率、固定性檢測周期、病毒檢測周期等。二是保存系統對數字對象質量判斷的指標描述信息,比如數字對象的容錯率、數據丟失的允許率、內容失真的允許率、數字遷移的準確率等。與持續完整性相關的保存政策僅限在第一種類型,另外,判斷數字對象的存儲介質是否過期,需要參考存儲介質的使用壽命。因此,這類元數據的元素有:
(1)存儲介質的使用壽命(Media Life)。用于存儲介質風險點的檢測。
(2)保存介質刷新頻率(Media Refresh Rate)。用于保存事件“保存介質刷新”風險點的檢測。
(3)固定性檢測周期(Fixty Check Period)。用于保存事件“固定性檢測”風險點的檢測。
(4)病毒檢測周期(Virus Check Period)。用于保存事件“病毒檢測”風險點的檢測。
4 檢測實驗
4.1 數據采集
數字對象樣本來源于中國知網(CNKI),樣本采集量1萬件。
數字對象的樣本采集。(1)層次單元劃分。基于CNKI數字對象的時間區間、文獻類型、學科類型三個屬性,將其劃分為504個層次單元,即:7(時間區間數)×9(文獻類型數)×8(學科類型數)=504。其中,時間區間:1990年之前、1991-1995年、1996-2000年、2001-2005年、2005-2010年、2011-2015年、2016年之后;文獻類型:期刊、碩博論文、會議論文、年鑒、統計數據、專利、標準文獻、古籍、工具書;學科類型采用CNKI大類劃分:基礎學科、工程技術、農業科技、醫療衛生科技、哲學與人文科學、社會科學、信息科學、經濟與管理科學。(2)各層次單元樣本量計算。計算各層次單元的數字對象數量與《中國知網》數字對象總數量的比例,乘以1萬(設定的樣本總量),獲得各層次單元的抽樣數量,這樣,各層次單元數字對象以接近的概率被抽樣。(3)樣本集形成。基于無重復抽樣的簡單隨機抽取法,從各層次單元中抽取樣本,通過套錄形成有代表性的數字對象樣本集。如依據上述方法計算出層次單元為“1995 - 2000年時間區間工程技術的專利文獻”的樣本抽取量為100篇,通過對《中國知網》檢索,該層次單元共有512833件,在1到512833之間隨機生成100個不重復的數,套錄該100個數對應的檢索結果數字對象,獲得該層次單元的樣本。
元數據元素的賦值。純粹用于科研目的,CNKI幫助提供上述樣本對象的保存型元數據、管理型元數據和描述型元數據的內容。針對本文制定的持續完整性風險型元數據的每個元素,若出現在上述任一種元數據中,則該元素內容直接套錄,否則,該元素內容置空。上述過程由代碼實現,但需人工干預,比如對名稱與CNKI不同但含義相同的元素的賦值需人工甄別和轉換。
4.2 代碼編制
代碼功能:針對不同維度的風險檢測(見4. 3.1,4.3.2,4.3.3,4.3.4),檢查、統計并以可視化形式展現相應層次單元中數字對象在每個持續完整性風險型元數據元素的風險點上產生風險的概率。代碼設計過程中涉及下述問題:
(1)數字對象的選擇。在樣本集中,刪除標識符內容為空的數字對象,因為這類數字對象無法識別。刪除類型不為“文件”和“比特流”的數字對象。
(2)元數據元素的選擇。數字對象類型、數字對象標識符、所有保存政策的元數據元素等三類元素無需檢測。因為第一類元素用于篩選文件對象,第二類元素用于數字對象識別,第三類元素為保存事件元數據檢測提供參考基準值。
(3)元數據元素賦值內容的編碼。這是實現自動檢測的基礎。另外,需對表達不同但含義一樣的賦值內容歸并,賦予一個編碼,以提高檢測的準確性。
4.3 風險檢測
4.3.1 單維度風險檢測
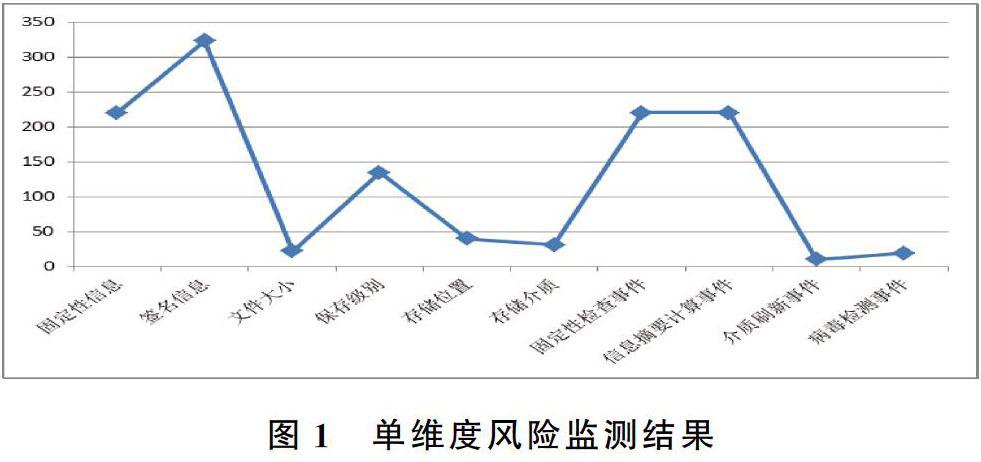
檢測并統計整個數字對象樣本集在持續完整性風險型元數據每一個元素的風險點上產生風險的概率。結果見圖1。風險概率較高的風險點依次為:簽名信息、固定性信息、固定性檢測事件、信息摘要計算事件、保存級別。
4.3.2 二維度風險檢測
基于數字對象的一個屬性,加上持續完整性風險型元數據的元素,建立一個二維空間坐標系,檢測并統計每個坐標點上的數字對象集合在該坐標點上持續完整性風險型元數據元素的風險點上產生風險的概率。有下述三種類型:
(1){時間區間,風險型元數據元素}二維風險檢測。檢測并統計由持續完整性風險型元數據元素、數字對象的時間區間屬性所建立的二維空間坐標系中,每個坐標點上的時間區間所覆蓋的數字對象集合,在該坐標點的持續完整性風險型元數據元素風險點上產生風險的概率。結果見圖2的左圖。主要風險點有:(a)簽名信息,主要分布在3個層次單元:2000年之前的3個時間區間文獻。(b)固定性信息,主要分布在2個層次單元:1995年之前的2個時間區間文獻。(c)固定性檢查事件,主要分布在2個層次單元:1995年之前的2個時間區間文獻。(d)信息摘要計算事件,主要分布在2個層次單元:1995年之前的2個時間區間文獻。(e)保存級別,主要分布在7個層次單元:所有7個時間區間文獻。
(2){文獻類型,風險型元數據元素}二維風險檢測。檢測并統計由持續完整性風險型元數據元素、數字對象的文獻類型屬性所建立的二維空間坐標系中,每個坐標點上的文獻類型所覆蓋的數字對象集合,在該坐標點的持續完整性風險型元數據元素風險點上產生風險的概率。結果見圖2的中間圖。主要風險點有:(a)簽名信息,主要分布在2個層次單元:期刊文獻、會議文獻。(b)固定性信息,主要分布在1個層次單元:期刊文獻。(c)固定性檢查事件,主要分布在1個層次單元:期刊文獻。(d)信息摘要計算事件,主要分布在1個層次單元:期刊文獻。(e)保存級別,主要分布在1個層次單元:專利文獻。
(3){學科類型,風險型元數據元素}二維風險檢測。檢測并統計由持續完整性風險型元數據元素、數字對象的學科類型屬性所建立的二維空間坐標系中,每個坐標點上的學科類型所覆蓋的數字對象集合,在該坐標點的持續完整性風險型元數據元素風險點上產生風險的概率。結果見圖2的右圖。主要風險點有:(a)簽名信息,分布在8個層次單元:所有的8個學科文獻。(b)固定性信息,分布在8個層次單元:所有的8個學科文獻。(c)固定性檢查事件,分布在8個層次單元:所有的8個學科文獻。(d)信息摘要計算事件,分布在8個層次單元:所有的8個學科文獻。(e)保存級別,主要分布在5個層次單元:5個學科文獻(基礎學科、工程技術學科、農業科技、醫療衛生科技、信息科學)。
4.3.3 三維度風險檢測
基于數字對象的兩個屬性,加上持續完整性風險型元數據的元素,建立一個三維空間坐標系,檢測并統計每個坐標點上的數字對象集合在該坐標點上持續完整性風險型元數據元素風險點上產生風險的概率。有下述三種類型:
(1){時間區間,文獻類型,風險型元數據元素}三維風險檢測。檢測并統計由持續完整性風險型元數據元素以及數字對象的時間區間、文獻類型兩個屬性所建立的三維空間坐標系中,每個坐標點上的[時間區間,文獻類型]所覆蓋的數字對象集合,在該坐標點的持續完整性風險型元數據元素風險點上產生風險的概率。檢測結果見圖3。主要風險點有:(a)簽名信息,主要分布在6個層次單元:2000年之前的3個時間區間的期刊文獻、會議論文。(b)固定性信息,主要分布在2個層次單元:1995年之前的2個時間區間的期刊文獻。(c)固定性檢查事件,主要分布在2個層次單元:1995年之前的2個時間區間的期刊文獻。(d)信息摘要計算事件,主要分布在2個層次單元:19 95年之前的2個時間區間的期刊文獻。(e)保存級別,主要分布在7個層級單元:所有7個時間區間的專利文獻。
(2){時間區間,學科類型,風險型元數據元素}三維風險檢測。檢測并統計由持續完整性風險型元數據元素以及數字對象的時間區間、學科類型兩個屬性所建立的三維空間坐標系中,每個坐標點上的[時間區間,學科類型]所覆蓋的數字對象集合,在該坐標點的持續完整性風險型元數據元素風險點上產生風險的概率。檢測結果見圖4。主要風險點有:(a)簽名信息,主要分布在24個層次單元:2000年之前的3個時間區間的所有8個學科文獻。(b)固定性信息,主要分布在16個層次單元:1995年之前的2個時間區間的所有8個學科文獻。(c)固定性檢查事件,主要分布在16個層次單元:1995年之前的2個時間區間的所有8個學科文獻。(d)信息摘要計算事件,1995年之前的2個時間區間的所有8個學科文獻。(e)保存級別,主要分布在35個層級單元:所有7個時間區間的5個學科文獻(基礎學科、工程技術學科、農業科技、醫療衛生科技、信息科學)。
(3){文獻類型,學科類型,風險型元數據元素}三維風險檢測。檢測并統計由持續完整性風險型元數據元素以及數字對象的文獻類型、學科類型兩個屬性所建立的三維空間坐標系中,每個坐標點上的[文獻類型,學科類型]所覆蓋的數字對象集合,在該坐標點的持續完整性風險型元數據元素風險點上產生風險的概率。結果見圖5。主要風險點有:(a)簽名信息,主要分布在16個層次單元:所有8個學科的期刊文獻、所有8個學科的會議論文。(b)固定性信息,主要分布在8個層次單元:所有8個學科的期刊文獻。(c)固定性檢查事件,主要分布在8個層次單元:所有8個學科的期刊文獻。(d)信息摘要計算事件,主要分布在8個層次單元:所有8個學科的期刊文獻。(e)保存級別,主要分布在5個層級單元:5個學科(基礎學科、工程技術、農業科技、醫療衛生科技、信息科學)的專利文獻。
4.3.4 四維度風險檢測
基于數字對象的三個屬性,加上持續完整性風險型元數據的元素,建立一個四維空間坐標系,檢測并統計每個坐標點上的數字對象集合在該坐標點上持續完整性風險型元數據元素風險點上產生風險的概率。有下述一種類型:
{時間區間,學科類型,文獻類型,風險型元數據元素}。檢測并統計由持續完整性風險型元數據元素、以及數字對象的時間區間、學科類型、文獻類型三個屬性所建立的四維空間坐標系中,每個坐標點上的[時間區間,學科類型,文獻類型]所覆蓋的數字對象集合,在該坐標點的持續完整性風險元數據元素風險點上產生風險的概率。檢測結果的可視化圖太大,省略。主要風險點有:(a)簽名信息,主要分布在48個層次單元:2000年之前的3個時間區間的所有8個學科的期刊文獻、會議論文。(b)固定性信息,主要分布在16個層次單元:1995年之前的2個時間區間的所有8個學科的期刊文獻。(c)固定性檢查事件,主要分布在16個層次單元:1995年之前的2個時間區間的所有8個學科的期刊文獻。(d)信息摘要計算事件,主要分布在16個層次單元:1995年之前的2個時間區間的所有8個學科的期刊文獻。(e)保存級別,主要分布在35個層級單元:所有7個時間區間的5個學科(基礎學科、工程技術、農業科技、醫療衛生科技、信息科學)的專利文獻。
4.4 檢測結果分析
風險檢測的目的在于為保存系統的維護提供依據。由上可知.檢測維度越高,產生風險的數字對象集合越具體,風險識別的針對性越強,越利于保存系統采取針對性的措施降低或規避風險。針對本實驗,持續完整性風險主要集中在下述5個風險點的相應數字對象集合上:
(1)固定性信息、固定性檢查事件、信息摘要計算事件。這三個風險點產生風險的概率幾乎相同,且都集中在1995年之前各個學科的期刊文獻上。由此可以推測,該層次單元中一些數字對象收錄到保存系統時,可能沒有執行信息摘要計算事件,導致這些數字對象的信息摘要內容缺失,固定性元數據中信息摘要元素內容為空,固定性檢查事件因缺失對比的原始信息摘要基準值而無法執行。可能原因是1995年之前的期刊文獻的數字化版本大多是通過數字轉換獲得的,當時可能沒有完全執行對收錄數字對象計算信息摘要的保存政策。保存系統可對這類數字對象重新執行信息摘要計算事件,并將計算結果賦值到對應數字對象的固定性信息元數據的信息摘要元素中。
(2)簽名信息。該風險點產生風險的數字對象主要集中在兩個區域:1995年之前各個學科的期刊文獻、2000之前的所有學科的會議論文。針對第一個區域的數字對象,由于與本節(1)中文獻集合相同,且發生風險的概率值也與本節(1)中的三個風險點比較一致,所以可以推測,該區域的數字對象至少也缺失信息摘要的描述值,可能的原因和保存系統可以采取的措施也同本節(1)。針對第二個區域的數字對象,可能原因是缺失密鑰信息或簽名值的記錄,致使無法計算新的信息摘要,也可能是新信息摘要與原始信息摘要比較結果不同;針對前者,保存系統可以進一步核實數字對象的各項元數據元素的描述值,補充缺失內容;針對后者,保存系統可進一步分析導致數字對象發生改變的因素。
(3)保存級別。該風險點產生風險的數字對象集中在所有時間區間的5個學科(基礎學科、工程技術、農業科技、醫療衛生科技、信息科學)的專利文獻中。首先,在所有的8個學科中,其他3個學科(哲學與人文科學、社會科學、經濟與管理科學)很少產生專利文獻,所以專利文獻集中在上述5個學科;其次,產生風險的可能原因是專利文獻數字對象設置的期望保存級別較高(可能是這類數字資源提交者 國家知識產權局的要求,也可能保存系統認為這類數字資源的價值較高),而該風險型元數據的元素“保存級別的勝任狀態”的賦值為“需要”(意味著保存系統在實現該類數字資源的期望保存級別所需的支撐條件尚不足)。保存系統可以采取的措施是針對這類數字資源,完善保存環境,提升保存條件,滿足這類數字資源的保存需求。
5 檢測方法的局限性與改進思路
基于檢測結果與樣本數字對象的對比分析,檢測方法還存在下述一些不足,并針對每項不足提出對應的改進思路。
(1)風險識別單元的問題。檢測方法中,風險的識別單元是元數據(即風險點)。針對一件數字對象,一個元數據中任一檢測項目出現風險,該檢測點就產生風險,且有多個檢測項目出現風險時,也歸并為該檢測點出現風險一次。比如“固定性信息”風險點設置了3個檢測項目,本實驗中,有213件數字對象的“固定性信息”風險點產生了風險,但是具體到每件數字對象,是原始信息摘要算法缺失?原始信息摘要丟失?還是數字對象在長期保存過程中發生了改變?是發生了上述一種情況、二種情況?還是三種情況同時發生了?無從知曉。導致保存系統難以采取準確措施降低或規避風險。因為不同原因導致的風險,應采用的規避或降低方法不同。如前2個原因導致的風險的規避措施是補齊原始對象的信息摘要或算法即可;第3種原因導致的風險,只有通過本地或異地備份恢復數字對象來解決。
檢測方法的改進思路。將檢測方法中以元數據為風險識別單元,改變為以檢測項目為風險識別單元。這樣,可視化展現時,不僅顯示每個元數據產生的持續完整性風險的數字對象總數量,還需顯示針對一個元數據的每個檢測項目上產生風險的數字對象數量,很顯然,可視化展示圖也會隨著增大很多。
(2)統計對象的問題。檢測算法中,在一個風險點上產生風險的所有數字對象將形成一個集合,統計該集合中數字對象的個數,形成一個數字,展示在可視化圖中相應風險點上。但到底是哪些數字對象?無從知曉,因為缺失數字對象的清單。導致的結果是,無法針對具體數字對象采取風險規避或降低措施。如針對上述例子,本實驗抽取的1萬件數字對象中,有213件產生“固定性信息”風險,但沒有列出這231件數字對象的具體唯一標識符,無法識別出具體的數字對象,也就無法實施風險規避或風險降低的措施。
檢測方法的改進思路:在可視化展示圖中,加入超級鏈接,將每個風險點鏈接到具體產生該類風險的數字對象清單上,并設置打印功能,需要時可打印輸出。
(3)元數據的相關性問題。檢測方法中設計的不同元數據與持續完整性之間的相關性是不一樣的。比如數字對象方面,“固定性信息”和“簽名信息”與持續完整性直接相關,相關性最大;“文件大小”“保存級別”“存儲位置”和“存儲介質”與持續完整性都是間接相關,相關性較小;保存事件方面,“固定性檢查”和“信息摘要計算”也是直接相關,但“介質刷新”和“病毒檢測”則是間接相關。直接相關的元數據的檢測結果更準確,間接相關的元數據的檢測結果都存在誤差,有的誤差很大。將檢測結果與樣本進行對比,“固定性信息”和“簽名信息”的2個風險點的檢測準確度都大于90%,“固定性檢查”和“信息摘要計算”的2個保存事件風險點的檢測準確度也都大于90%,但其他間接相關的風險點檢測結果的準確度都較低,在10%45%之間。這樣,對間接相關的元數據產生風險的數字對象的識別所需工作量很大。
檢測方法的改進思路:采用分級檢測,首先使用直接相關的元數據進行檢測,將產生風險的數字對象析出,剩余的數字對象再使用間接相關的元數據進行檢測。由于后者的檢測樣本集已減小,所以識別所需的工作量也隨著降低。
6 檢測方法的使用
本文設計的檢測方法針對CNKI進行了實驗,結果表明,除了存在上節列出的局限性外,其他方面均具有較好的適用性。CNKI保存的主要是文本型數字對象,針對其他類型保存系統(如多媒體數字對象的保存系統)的實驗沒有進行。因此,使用該檢測方法(尤其是非文本型數字對象的保存系統)時,保存系統需注意下述事項。
(1)元數據的完善。本檢測方法的核心是持續完整性風險型元數據的設計,檢測結果的準確度和全面性依賴于所設計的元數據方案的科學性。因此使用該方法時,保存系統應該針對其保存的數字對象、保存目標、保存政策、目標用戶群體等實際,分析、改造和完善本文設計的元數據方案。
(2)檢測項目的完善。本檢測方法中,每個元數據均設置一定數量的檢測項目,對元數據的檢測是通過對其設置的檢測項目進行檢測而實現的。因此,檢測結果的準確度完全依賴于設置的檢測項目。使用該方法時,保存系統應在上述完善元數據的基礎上,結合實際,改造和完善每個元數據的檢測項目。
(3)維度的劃分。本檢測方法的實驗樣品來自CNKI,因此實驗中的維度劃分完全基于CNKI的實際。但應用到其他保存系統時,需根據其收錄數字對象的實際,重新劃分維度。
(4)動態風險的監控。本檢測方法僅局限在靜態風險的檢測,沒有涉及動態風險的監控。可以在靜態風險檢測的基礎上,從時間維度設置一個檢測頻率(如每天檢測一次),基于該頻率進行持續的離散的靜態風險檢測,結果就形成了動態風險的檢測。當然,這種動態非完全連續,而是離散式的。實際上也無需完全連續檢測,因為保存系統中數字對象的狀態變化不可能完全連續,基于一個合理的檢測頻率進行離散式檢測即可。在此基礎上,可設置一個時間區間(如一個星期、一個月、一個季度或一年等),統計該時間區間內動態風險的檢測結果,實現包括集中趨勢、離散趨勢、分布形狀和時間趨勢等在內的各種統計,并以可視化形式呈現,最終實現動態風險的監控。
風險檢測應是數字保存的一項常規工作,也是規避和降低風險的基礎。本文僅對持續完整性風險設計了一種檢測方法。實際上,除了該類風險外,數字保存還存在其他類型的風險(比如可用性風險、真實性風險等),識別這些類型的風險并設計其元數據方案,并在此基礎上設計相應類型風險的檢測方法,乃至進一步整合為數字保存的全風險型元數據并進行全風險的檢測方法設計,是本課題的后續研究內容。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中華手工(2017年2期)2017-06-06 23:00:31
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
