深入淺出ELK
2018-11-07 02:47:38
網絡安全和信息化 2018年8期
關鍵詞:功能
ELK簡介
ELK的涵義
E代 表 ElasticSearch,是整個ELK的心臟,它負責索引的創建、搜索、分析以及數據的存儲等工作,這個組將在后面做詳細介紹。
L代表Logstash,是用來做數據采集、接收、處理和轉發的工具,它講采集來的數據經過分析和處理以后,將數據發送到ElasticSearch存儲。它本身支持非常多的數據源。
K代表Kibana,作用是負責將ES中數據進行炫酷的展示。
整理概括一下整個ELK就是:
Logstash負責數據采集、分析和處理,然后將數據發送給ElasticSearch做進一步的存儲、分析和搜索,最后Kibana講ElasticSearch中的數據炫酷地展示出來。
ELK常用架構
ELK的常用架構如圖1所示,使用Logstash Shipper在機器上采集相關的數據或日志,你可以理解為Logstash的一個agent,中間使用Redis做隊列,也有很多的公司使用Kafka來代替Redis。
ELK在業界的使用情況
目前ELK比較活,社區也很活躍,有很業務都在使用,主要分為三類應用:
1.全文檢索
如GitHub和維基百科。
2.日志監控類
比如騰訊云監控、斗魚日志分析平臺。
3.數據分析和查詢
比如 :DELL,Sprint。
此外國外還有一些公司用ES來存儲地理位置數據,如Foursquare公司,結合搜索和地理位置兩者提供更優質的服務。
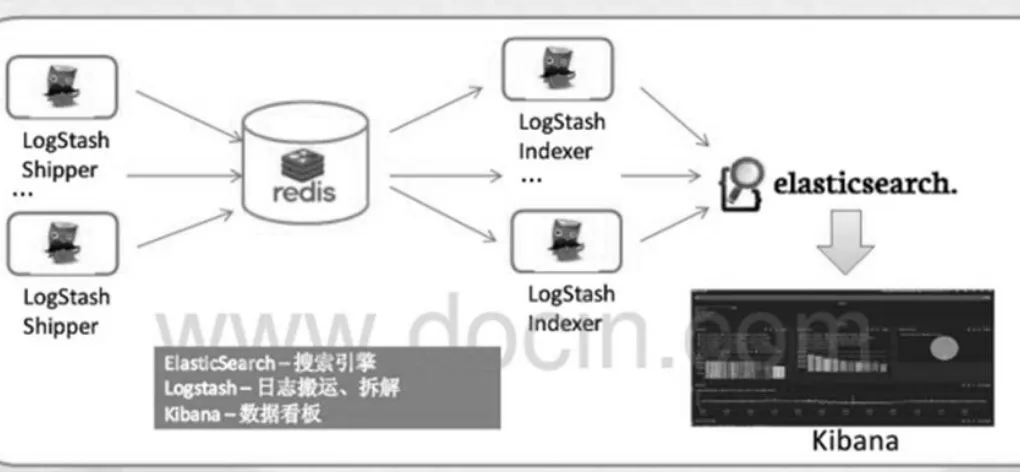
圖1 ELK的常用架構
ES技術細節
ES技術細節部分主要介紹如下幾個方面。
ES的特性
1.Base on Apache Lucense
Lucense是高性能的搜索引擎庫,提供了查詢引擎、搜索引擎和文本分析引擎。但使用Lucense成本很高,需要掌握很多關于搜索的知識。而ES使用Lucense作為底層架構,在其上做了大量的易用性、擴展性、容災及性能方面工作,使得用戶經過很少的配置就可以快速ES進行數據存儲和檢索。
2.Distributed and horizontally scalable
ES是分布式的,可以水平擴展,比如添加節點的時候能自動均衡數據。
3.Full-text search and powerful search
ES支持前文支持全文索引,并且搜索功能非常強大。
4.Document & Json
ES是基于文檔的強大組件,交互數據全部采用Json標準格式。
5.Restful API
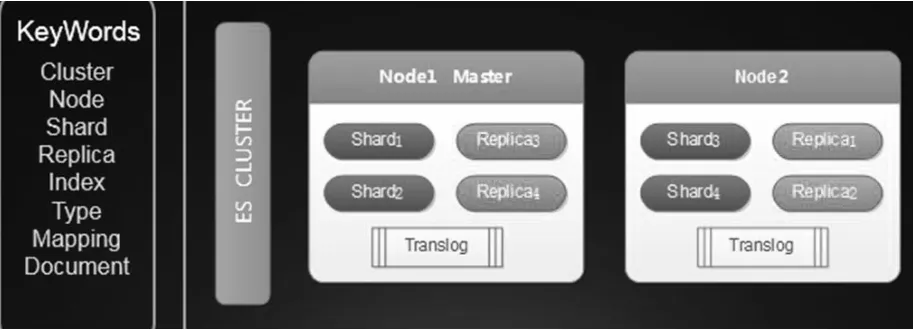
圖2 ES集群組成
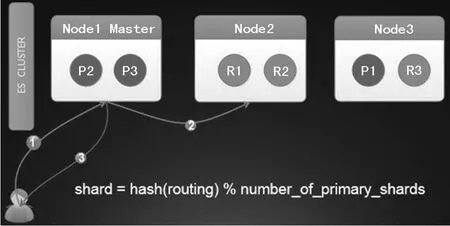
圖3 ES的寫入簡圖
6.Open Source
7.Query DSL
ES提供了基于JSON的query DSL查詢語言,傳統的SQL語句很容易轉化成query DSL。后面做的關于MySQL和ES的性能比對也是將標準SQL改寫成query DSL實現的。Translog為ES提供高性能以及數據安全保障。
ES集群組成
從圖2中可以看到,ES集群是由多個節點組成,上圖中有1個master節點和2個data節點組成,并且創建了1個索引,索引有4個數據分片和1個副本組成。
ES的寫邏輯
如圖3所示,ES的寫操作分為兩類,一類是涉及到路由變更的索引創建和刪除(簡稱為索引的寫入),另一類是基于文檔的創建、更新和刪除(簡稱為文檔的寫入)。
下面單獨來進行介紹:
1.索引的寫入
無論是索引的創建還是刪除,都必須在master上進行。因此,如果寫入的請求是發到了非master節點,該節點會講對應的創建或者刪除的請求轉發給master,master會創建并修改元數據和路由信息,并將對應的修改同步到其他的候選的master機器上,至少需要需要一半以上的候選master返回后才算寫入成功。
2.文檔的寫入
文檔的寫入的前提是所有的寫入都必須先發送到主分片上,大致的步驟為:
(1)文檔寫入請求發送到任意的一個節點。
(2)節點根據shard =hash(routing) % number_of_primary_shards確定數據所在的分片及根據元數據確認主分片是在哪臺機器。
(3)在主分片上執行寫入操作和translog寫入操作,并將請求發送到副本上進行寫入和translog寫入。
(4)默認是同步操作,必須主分片和副本分片都些成功財返回結果,也可以人為調整為異步操作,不過會有數據安全性問題。
注意:默認ES提供近實時的搜索,也就是說文檔寫入或更新后不是馬上就能搜索出最新的變更,默認需要過1秒reflush后才能看到,如果業務對實時性要求非常高,也可將reflush的相關的參數設置為request,即有新的請求就執行reflush的操作,這種方式性能會較差。此外還可調用reflush的API手動進行reflush操作。
ES的讀邏輯
ES的讀邏輯如圖4所示。
ES查詢時如果指定了routing相關的值,就會只掃描確定的1個或少數文檔,如果沒有指定routing相關的值,就需要掃描所有分片。因此還會涉及到查詢的拆分和合并的步驟。詳情如下:
(1)查詢請求發送到任意一個節點。
(2)如果指定了routing相關值,根據shard = hash(routing) % number_of_primary_shards公式就能直接計算出請求的數據所在的分片,然后將請求發送到對應的分片就OK。如果指定routing的相關值,那么會發送到對應查詢涉及到的所有分片(這就是請求拆分)。
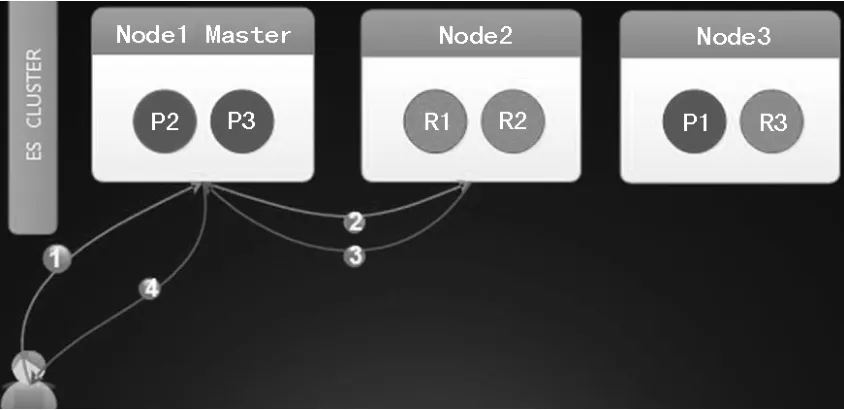
圖4 ES的讀邏輯
(3)如果查詢只涉及到1個分片,查詢的分片所在的機器返回查詢結果到初始請求的節點,初始請求節點再將數據返回給業務。而如果查詢涉及到多個分片,初始節點就會將請發送給多個分片并發查詢,此時查詢的分片所在的機器返回查詢結果到初始請求的節點后,初始節點還需要再進行結果的合并。初始節點將合并后的數據返回個業務。
ES的容災
ES有很完善的容災機制,候選master一般有多個,data節點也有多個,因此節點異常的時候通過將訪問切換到別的節點來容災。具體流程包含如下幾個流程:
1.故障發現
故障發現如圖5所示。從圖中可以看出,Master會去ping各個其他的節點,圖中只畫了datanode節點。而其他的節點也會去ping master節點,確認master節點是否正常。默認ping規則如下:
Discovery.zen.fd.ping_interval=1s 默認每隔1秒探測1次
Discovery.zen.fd.ping_timeout=30s 默認ping探測的超時時間為30秒
Discovery.zen.fd.ping_retry=3 默認重試3次
備注:以上參數可以根據自己的網絡情況和業務需求進行調整。
2.節點切換
master節點切換:
當其他節點探測到master異常并達到重試次數后,候選節點會進行競爭,選master的具體規則如下。
(1)每次選舉每個節點會把自己所知道的候選master節點根據nodeid進行一次排序,然后選出第1個節點,暫且認為它是master節點。
(2)如果對某個節點的投票數達到候選master數/2+1個并且該節點也選舉自己為master,那么這個節點即為master。否則重新選舉。
備注:之所以節點的投票數需要達到候選master數/2+1,是為了防止腦裂的問題發生。
data節點切換:
當master節點檢測到某個data節點有異常時,操作大致如下。
(1)master剔除該data節點,如果ES數據配置了1份副本保存,此時不存在數據丟失的風險,集群狀態為yelllow。如果數據沒有配置副本保存,則存在數據丟失,集群狀態為red。
(2)master對找出異常的data節點對應的所有的數據分片,如果是主分片,則將其他節點上的副本分片提升為主分片,全部主分片恢復后,異常data節點涉及的數據讀寫都恢復正常。
(3)業務恢復正常以后,master會將異常節點的數據遷移到正常的節點。
(4)當全部數據遷移完成后,集群狀態恢復為green。
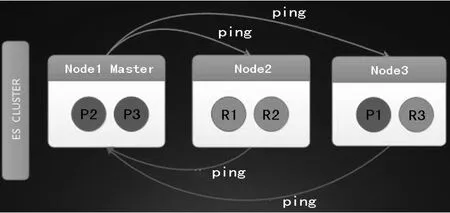
圖5 故障發現
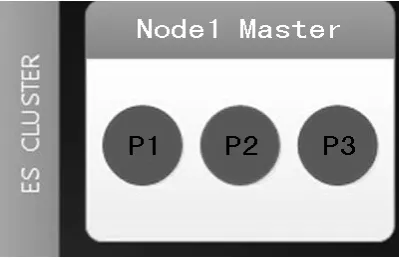
圖6 一個節點的ES Cluster
ES的擴容
ES設計成能讓你靈活地擴縮容模型,當添加或減少data節點時,ES會自動對數據進行均衡。如下幾個簡圖能讓你幾秒鐘了解ES的擴容問題,下面幾個圖的索引設置為number_of_shards=3&& number_of_replicas=1,即索引為3個分片且每個分片有1個副本。
1.一個節點的ES Cluster
從圖6中可以看到雖然設置了1個副本,但是datanode1只分配了3個主分片。這是因為ES認為如果副本和主分片在1臺機器上和沒有副本的效果一樣,當那臺機器異常時,數據一樣丟失。因此ES沒有在那臺機器上分配副本分片。
2.擴容一個節點后的ES Cluster
從圖7中,可以看到添加1個節點后,data節點2分配了2個副本。
3.再擴容一個節點后的ES Cluster
如 圖 8,data節 點 1上的P1被移動到data節 點 3,data節 點 2上的R3被移動到了data節點3,這是因為添加節點后,ES會自動均衡數據。
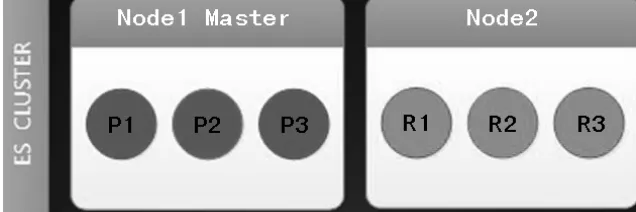
圖7 擴容一個節點后的ES Cluster

圖8 再擴容一個節點后的ES Cluster
ES讓人驚喜的功能
做為一個運維人員,在學習ES的時候,遇到了很多讓人驚喜的功能,整理出來和大家共享。
ES的group功能
ES的group功 能 和HBase的group功能類似,可以將某些節點放到某一個group中,從而實現業務之間的隔離。
比如要將重點業務和普通業務隔離開來的話,就可以將重點業務放到指定的某個組,這個組不存在過保的設備,負載也比較低。而將普通業務放到普通的組中,這各組的設備由于比較老,故障率會比較高,組內的機器負載也會高一些。

圖9 ES的group功能
如圖9所示,分別包含 groupA和 groupB,其 中groupA中保存了某些索引,groupB中也保存著某些分片。ES有專門的參數控制索引可存儲在某個group或節點,具體參數如下:

ES部落節點功能
ES從1.0版本開始支持使用部落節點(tribe node),所謂的部落節點,就是作為聯合客戶端提供訪問多個ElasticSearch集群的能力。業務只需要訪問部落節點,就可以獲取多個ES集群的數據。并且可以通過部落節點寫入數據,寫入數據的時候部落節點會將寫入請求轉發到后端的集群節點進行數據寫入。但是不支持創建索引的操作。
注意:如果部落節點對應后端的ES集群含有相同的索引名稱就會出現莫名其妙的問題,因為ES的默認行為是從中選擇一個。也就是說如果后端2個集群含有相同的索引名字,那么知會有一個索引會被訪問到。
部落節點的圖解如圖10所示。
ES的IO流控功能
ES還有個比較好的功能就是IO流控的功能,這個功能對于分布式存儲是非常必要的,比如可以限制文件合并的時候的IO,從而使系統更平穩地運行。ES主要有節點級和索引級兩個限流機制。分別介紹如下:
1.節點級別限流sec

2.索引級別限流


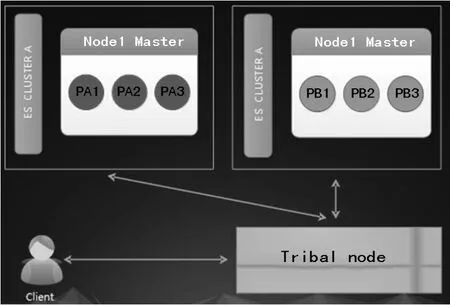
圖10 ES部落節點功能
ES的慢日志功能
ES有類似于MySQL的慢查詢功能,可以記錄下慢的操作,從而讓運維人員能通過慢的操作找到問題所在。
默認情況下慢日志是不開啟的,分別有query、fetch、index三類動作定義,如下是一個query的慢日志定義:


上面設置的意思如下:
查詢慢于10秒輸出一個WARN日志。
獲取慢于500毫秒輸出一個DEBUG日志。
索引慢于5秒輸出一個INFO日志。
ES的發現熱點功能
ES有個查詢集群熱點線程的功能,這個功能在集群突然變慢的場景下特別有用,它將幫助你找到消耗資源最多的線程。熱點線程的使用方法如下:

返回的結果中含有線程所在的節點信息、線程消耗資源的情況、線程名稱以及相關的堆棧信息。
猜你喜歡
鐘表(2023年5期)2023-10-27 04:20:44
中華詩詞(2022年6期)2022-12-31 06:41:24
當代陜西(2021年21期)2022-01-19 02:00:26
中學生數理化(高中版.高考數學)(2020年1期)2020-02-20 13:23:44
經濟技術協作信息(2018年11期)2019-01-14 03:07:20
中國科技論壇(2017年7期)2017-07-25 08:49:53
制造技術與機床(2017年3期)2017-06-23 08:11:33
媽媽寶寶(2017年2期)2017-02-21 01:21:24
國際漢語學報(2016年1期)2017-01-20 08:21:20
中國中醫藥現代遠程教育(2014年22期)2014-03-01 04:32:55
