基于CUDA架構并行設計圖像去噪算法
2018-11-13 05:31:20霍迎秋陳春榮王雨菲尹加
現代電子技術 2018年22期
霍迎秋 陳春榮 王雨菲 尹加
摘 要: 針對圖像去噪算法中由于數據量大、計算復雜度高導致的實時性低的問題,通過對經典K?SVD圖像去噪算法的并行性進行研究分析,設計基于CUDA架構的并行K?SVD圖像去噪算法。該算法主要對去噪算法中矩陣拉伸、快速OMP和SVD等部分進行并行設計,采用“共享內存”“歸并求和”等策略進行優化。實驗結果表明,基于CUDA架構的并行算法比串行算法速度有了顯著提高,最高加速比為12倍,極大提高了圖像去噪算法的處理速度。
關鍵詞: CUDA; 圖像去噪; K?SVD; 圖形處理器; 并行優化; 矩陣拉伸
中圖分類號: TN911.73?34; TP311 文獻標識碼: A 文章編號: 1004?373X(2018)22?0053?06
Abstract: In allusion to the low real?time performance caused by mass data quantity and high calculation complexity in the image denoising algorithm, a parallel K?SVD image denoising algorithm based on computer unified device architecture (CUDA) is designed by means of parallelism research analysis of the typical K?SVD image denoising algorithm. In the algorithm, the parallel design of matrix stretching, fast OMP, SVD and other parts in the denoising algorithm is conducted. Strategies like memory sharing and summation by merging are adopted for optimization. The experimental results show that the parallel algorithm based on CUDA has a significant higher speed than the serial algorithm and a speed?up ratio as high as 12, which greatly improves the processing speed of the image denoising algorithm.
Keywords: CUDA; image denoising; K?SVD; graphic processing unit; parallel optimization; matrix stretching
圖像處理技術被廣泛應用于航空航天[1?3]、CT裝置[4?5]、工業工程[6]等多個方面。其中,圖像去噪算法能夠去除在圖像的生成、傳輸和存儲過程中產生的噪聲,提高圖像的質量。目前主要的圖像去噪算法有中值濾波[7]、維納濾波[8?9]等經典方法。
本文主要研究基于K?SVD[10](K?Singular Value Decomposition)的圖像去噪算法。K?SVD是一種字典學習法[11],基于K?SVD的圖像去噪方法能夠有效抑制加性高斯白噪聲,在對紋理圖像處理中優勢明顯[12]。但是這種算法計算復雜度高,計算量大,導致算法的實時性較低,難以滿足工程中高實時性的實際要求。
圖形處理器(Graphic Processing Unit,GPU)的通用計算能力正在高速發展中,極大地提高了計算機圖形處理的速度和質量[13]。基于GPU設計并行算法成為近年來研究的熱點[14?16]。本文通過利用GPU并行計算能力,提出一種基于CUDA(Computer Unified Device Architecture)架構的并行K?SVD圖像去噪算法。使其能夠大大降低算法所需時間,提高運行速度,因此在實際工程中具有重要的應用意義。
1 K?SVD原理
Michal Aharon等人在2006年提出了K?SVD算法[11],它可以對字典進行自適應更新,K指算法進行了K次迭代,每次都使用了SVD算法。此算法可以針對目標圖像構建特定的、能夠反映目標圖像特征的字典,從而在圖像去噪、壓縮等領域取得較好的效果[17]。
1.1 K?SVD數論基礎
當K?SVD算法中每個信號只用到一個原子來近似時,K?SVD算法就變化成K?均值聚類算法。同理,稀疏表示也可以看作是廣義的矢量量化(Vector Quantization,VQ),其中的多個原子的線性組合可以表示一個信號,令D表示字典,y表示訓練信號,x表示訓練信號的稀疏表示向量,Y是N個訓練信號的集合,X是Y的解向量集合。
假設字典D是固定的,用MP(Matching Pursuit),OMP(Orthogonal Matching Pursuit)或BP(Basis Pursuit)等算法可以得到字典D,矩陣X是Y的稀疏表示系數,然后根據矩陣X可以求解出更好的訓練字典D。
2 串行圖像去噪算法
2.1 K?SVD算法技術實現
本文基于C語言來實現K?SVD串行圖像去噪算法。在算法實現過程中主要實現圖像的讀取、圖像的拉伸、字典的生成。通過實現快速OMP算法生成稀疏矩陣,實現SVD算法來分解矩陣然后更新字典與稀疏矩陣;通過實現OMP算法生成稀疏矩陣。然后根據生成的稀疏矩陣與字典來更新拉伸矩陣,把拉伸矩陣還原成圖片實現圖像去噪。

2.2 實驗結果與分析
本文算法的計算機配制是Intel(R) Core(TM) E7400 2.80 GHz,內存為2 GB。在Windows 7環境下,使用Visual Studio 2010進行研究與測試,其中圖片大小為256×256。首先給原始圖像加上加性高斯白噪聲形成噪聲圖像,然后使用K?SVD圖像去噪算法去噪,最后得到去噪后的圖像。
通過對實驗結果分析發現,稀疏度對圖像去噪效果和算法性能產生很重要的影響。當稀疏度為128時,實驗結果如圖2所示。加噪后的PSNR值為20.28,去噪之后的PSNR值為28.53。
當稀疏度為512時實驗結果如圖3所示。加噪后的PSNR值為20.29,去噪之后的PSNR值為28.51。
分析可知,K?SVD圖像去噪算法去噪效果非常好,但是在不同稀疏度的情況下算法耗時不同,詳細情況如表1所示。
對表1分析發現,串行運行K?SVD算法進行圖像去噪非常耗費時間,實時性不高,對算法優化以減少其運行時間就變得非常重要。
3 基于CUDA并行設計圖像去噪算法
3.1 去噪算法并行性分析
分析發現,K?SVD算法中用到大量的矩陣運算,如矩陣相乘、矩陣轉置、矩陣求逆,矩陣運算可以進行并行優化。K?SVD圖像去噪算法主要耗費時間是在快速OMP和SVD部分。下面就快速OMP部分和SVD部分進行并行優化設計可行性分析。
3.1.1 快速OMP并行分析
在快速OMP過程中,取訓練信號的一列向量與字典相乘。從得到的向量里面選取最大的[K]個數,再從訓練信號中選取對應的列數組成一個矩陣,求該矩陣的廣義逆,得到相應列的稀疏矩陣。各列之間沒有相互依賴關系,可以進行并行優化。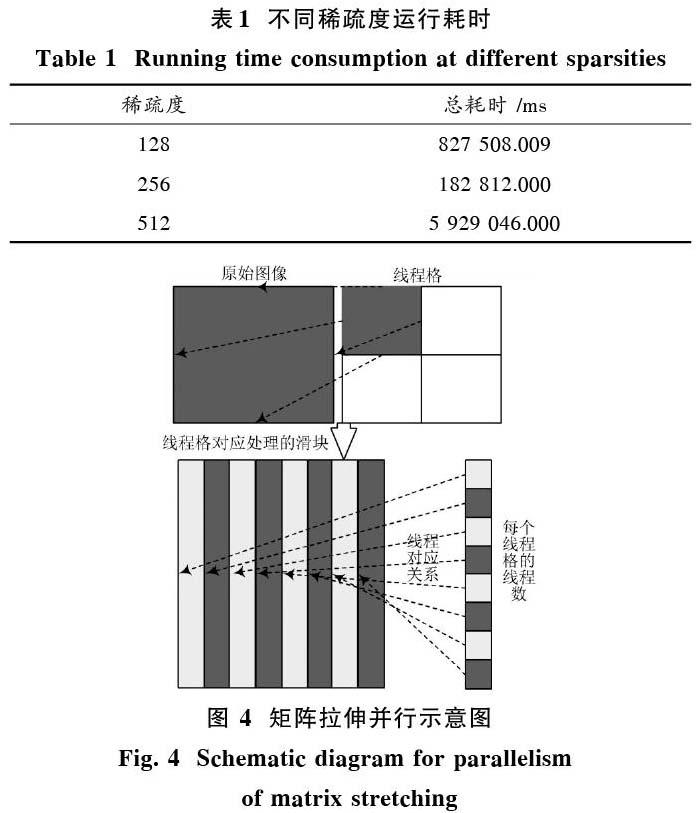
3.1.2 SVD算法并行分析
在奇異值分解過程中,主要是求矩陣的特征值和特征向量。將矩陣轉置與自身相乘得到一個方陣,構造一個值全部為1的向量,方陣與這個向量相乘更新構造的那個向量,將向量的每個元素都除以該向量的最大值,迭代這個過程。研究發現,每個迭代過程之間無關聯,能并行優化。
通過以上分析可知,在基于K?SVD的圖像去噪算法中用到了大量矩陣運算。在矩陣運算中每個元素都可以獨立地進行計算,為后續的并行優化提供了良好的基礎和可能性。
3.2 基于CUDA并行設計圖像去噪算法
在并行設計過程中,首先對耗時較大的部分進行并行設計,這樣才能顯著地降低所需要的時間。而且要結合GPU的硬件特點,合理使用硬件資源才能得到好的效果。
優化的重點放在耗時較大的算法上。整體優化過程分矩陣拉伸優化、快速OMP算法優化和[SVD]算法優化。X.m和mat.m用以表示矩陣的行,X.n和mat.n用以表示矩陣的列。
3.2.1 矩陣拉伸優化
1) 讀取圖像生成一個大小為256×256的圖像矩陣,生成字典D。
2) 設計8×8大小的滑動窗口,從原始圖像左上角滑動到右下角。將1)中得到的陣拉伸為64×62 001的矩陣。設計一個blocks為(249,249),threads為64的核函數進行矩陣拉伸變換的并行計算。其中,249是對應256-8+1,64對應8×8。從最左邊滑到最右邊則要滑動249次,同理,從最左邊滑到最右邊則也要滑動249次。生成的拉伸矩陣共有249×249=62 001列。具體情況如圖4所示。
3.2.2 快速OMP算法優化
1) 使用快速OMP算法將第3.2.1中1)得到的字典與第3.2.1中2)拉伸矩陣生成稀疏矩陣。生成稀疏矩陣的函數全部用CUDA核函數實現。構建一個線程數量為D.m的核函數,D.m是字典D的行數,將字典中的一列提取出來。為避免每次循環都需要耗費80 ms時間在數據從CPU到GPU的傳輸上,直接在顯卡端聲明一個變量保存每次循環需要提取的第幾列。
開辟一個X.n個線程格,每個線程格中有64個線程的核函數,每個線程計算對應元素的乘積,其結果保存在共享內存中,最后歸并求和得到共享內存數組所有元素的和。
計算上述稀疏矩陣的稀疏度,令為sparse,設計一個線程數為64的核函數。提取出上述過程得到的向量中前sparse個最大的數,并記錄下索引值。每個線程找出對應映射的元素里面的最大值,將512個線程中歸并找出最大值,獲得所有元素中最大值的索引,并將最大值賦值為0。再求次最大值,得到除去最大值之外第二大元素的記錄索引。依次類推,得到向量中前sparse個最大值及其索引。
令核函數的線程塊大小為X.m,線程數量是sparse,將向量中前sparse個值所對應的列取出,組成一個矩陣。其中有訓練信號行數m個線程格,每個線程格中線程都對應取一個元素。該元素的索引為上述選取的最大值對應的索引,得到的元素構成一行,設計核函數的線程塊為sparse,線程數為X.m,即要轉置矩陣的列,對該行進行矩陣轉置。矩陣相乘核函數線程格grid,即第一個矩陣的行與第二個矩陣的列構成的線程格數,線程數為X.m。將轉置后的矩陣與原矩陣相乘,每個線程格負責生成相乘之后矩陣中的一個元素。每個線程計算對應元素的乘積,存放到共享內存中,最后歸并求和。
對上述相乘得到的矩陣求逆。先構造一個單位矩陣,使用初等變換法求逆。通過一次消元一列的方法讓矩陣變成單位陣,每次消元一列用到的核函數線程格和線程數均為sparse。映射元素如圖5所示。
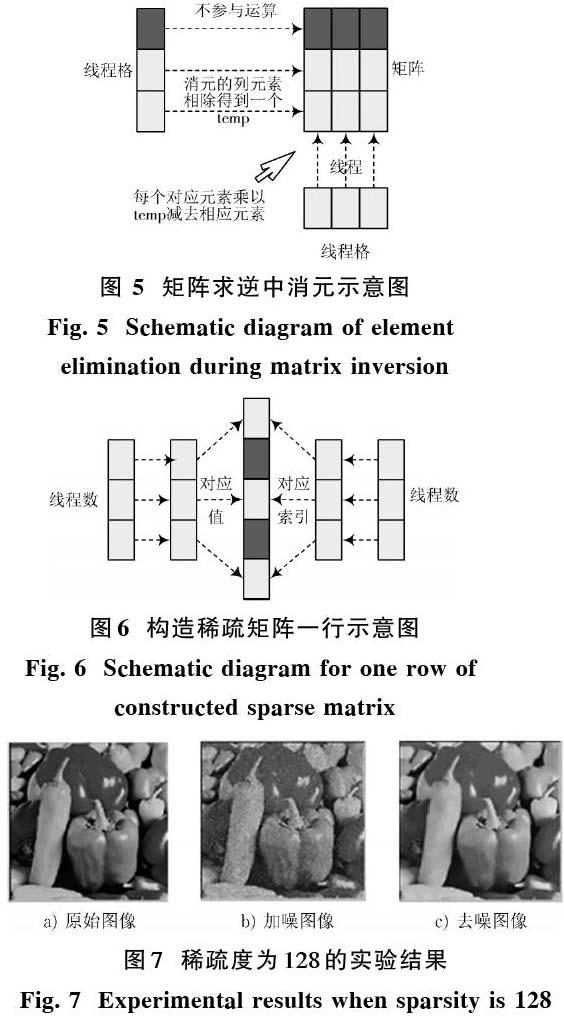
消元第一列之后,僅第一行第一列元素非零,第一列其余元素都為零。將求逆得到的矩陣與轉置的矩陣使用線程格為grid,線程數為sparse的核函數相乘,相乘得到的矩陣再與字典相應列相乘,令其線程格為sparse,線程數為64。將向量中得到的每個元素放入到對應位置構成稀疏矩陣。將該稀疏矩陣傳輸到主機端。其中的一行如圖6所示。
2) 將稀疏矩陣對應行的對應非零元素所在的列取出,與字典相乘。將訓練信號對應列取出,這兩個矩陣相減得到待SVD分解的矩陣,將該矩陣傳輸到顯卡端。
3.2.3 SVD算法優化
1) 將第3.2.2節中2)的矩陣轉置。
2) 將第3.2.2節中1)的矩陣與原矩陣相乘,核函數開辟的線程格為mat.n×mat.n個,線程數為mat.m個。使用一個線程格為1,線程數為mat.n的核函數構造一個全為1的向量。轉置后的矩陣與該向量相乘核函數的線程格和線程數均為mat.n,其結果為一個向量,從中找出最大值,該向量除以得到的最大值。
上述過程循環200次,完成SVD分解。在串行算法中,保持兩次最大值不改變從而完成SVD分解。如遵循串行算法的過程,則要不斷地將顯卡端獲得的最大值傳輸給主機端,比較是否滿足退出循環條件。傳輸的數據不多,但是很耗費時間。統計串行代碼中的循環次數,分析得出200次足夠得到一個好的特征值和特征向量。當然在稀疏度更大的情況下也要改變循環次數。用分解得到的向量更新字典與稀疏信號。
3) 將訓練得到的字典與訓練信號稀疏后,用稀疏信號與字典相乘從而更新訓練信號,將訓練信號還原成一張圖片,該圖片就是去噪之后的圖像。
3.3 實驗結果分析
算法運行環境:GPU顯卡型號為GTX770,CUDA架構版本是5.5;CPU為Intel Core2 E7400 2.8 GHz,內存2 GB。
在應用OMP算法對原始信號進行稀疏分解的過程中發現得到的稀疏矩陣的稀疏度不可知,可通過經驗值估計圖像的稀疏度。實驗測試發現,稀疏度越大,去噪效果越好,但是算法的運算量也越大。這是因為當稀疏度很大時,相應的圖像處理的計算量變大,后續的奇異值分解過程也變得非常復雜。如在稀疏度為4 000時,奇異值分解耗時不小于1 h。在用快速OMP算法對原始信號進行稀疏分解的過程中可以人為地控制稀疏度。在選定稀疏度為128的情況下發現算法整體耗時減少50%,但是圖像的去噪效果受到了很大影響。
選定稀疏度為128,256,512情況下,測試并行圖像去噪算法的性能。分析實驗結果可知,在三種稀疏度下并行去噪算法去噪后圖片的PSNR值都為29 dB,通過肉眼觀察結合PSNR值可知并行算法去噪效果非常好,具體如圖7~圖9所示。在稀疏度為128的情況下,圖像去噪的效果如圖7c)所示。其中加噪后PSNR值為20.29,去噪后的PSNR值是28.41。
在稀疏度為256的情況下,圖像去噪效果如圖8c)所示。其中加噪后的PSNR值為20.29,去噪之后的PSNR值為29.38。
在稀疏度為512時,圖像去噪效果見圖9c)。其中加噪后的PSNR值為20.29,去噪后的PSNR值為29.13。
隨著稀疏度的逐漸增加,圖像去噪效果越來越好,但是算法的運算量也越來越大。算法運算量越大越能夠發揮GPU并行處理的優勢,相應的加速效果越明顯。例如:在稀疏度為128時,串行去噪算法整體耗時為827 508 ms,而并行算法耗時76 812 ms。在稀疏度為512時,串行去噪算法整體耗時高達5 952 046 ms,并行去噪算法耗時484 932 ms。詳細如表2所示。
在不同稀疏度情況下并行去噪算法的加速比如圖10所示。
通過對表2和圖10分析可知,隨著稀疏度不斷變大,并行算法相對于串行算法的加速比不斷提升。在稀疏度為128時,加速比為10.8;稀疏度為256時,加速比為11.6;稀疏度為128時,加速比為12.3。分析其主要原因是隨著稀疏度不斷變大,去噪算法的運算量也逐漸增大。去噪算法的非相關運算量增大,越能夠充分發揮GPU大量并行處理單元的優勢,因此加速比逐漸增大。綜合考量并行去噪算法的去噪效果和運行速度可知,并行去噪算法在保持算法去噪效果的同時,能夠極大地加速算法的運行,提高算法的實時性。
4 結 語
本文主要研究了基于K?SVD的圖像去噪算法,提出一種基于CUDA架構的并行圖像去噪算法。并行算法充分利用了GPU強大的并行計算能力,對基于K?SVD的圖像去噪算法進行了并行優化設計。共設計了三組實驗對比分析串、并行算法的性能以及去噪效果。分別測試在不同稀疏度下的串行、并行算法的耗時和去噪效果。實驗結果表明,在128,256,512三種稀疏度下串、并行算法去噪效果沒有區別,去噪后的圖片PSNR值都為29 dB。但是并行圖像去噪算法相對于串行算法運行速度得到了很大的提高,最高加速比達12,極大地提高了算法的實時處理性能。因此,本文設計的并行圖像去噪算法能夠替代串行去噪算法,且能夠有效提高圖像處理的實時性,在航空航天、CT裝置、工業、工程等需要進行圖像去噪的領域具有廣闊的應用前景。
參考文獻
[1] 趙育良,許兆林.基于圖像處理技術的航空相機鏡頭焦面自準直定位研究[J].應用光學,2012,33(2):288?292.
ZHAO Yuliang, XU Zhaolin. Autocollimation location system of aerial camera lens′ focus plane based on image processing technology [J]. Journal of applied optics, 2012, 33(2): 288?292.
[2] 孫世杰,張凱,孫力,等.基于圖像處理的航空儀表自動判讀系統設計[J].科學技術與工程,2011,11(6):1260?1263.
SUN Shijie, ZHANG Kai, SUN Li, et al. Automatic interpretation of aviation instrument based on image processing [J]. Science technology and engineering, 2011, 11(6): 1260?1263.
[3] 趙志彬,劉晶紅.基于圖像處理的航空成像設備自動調焦設計[J].液晶與顯示,2010,25(6):863?868.
ZHAO Zhibin, LIU Jinghong. Auto?focusing method for airborne image equipment based on image processing [J]. Chinese journal of liquid crystals and displays, 2010, 25(6): 863?868.
[4] 郝景宏,姜袁,梅世強,等.基于CT圖像處理技術的混凝土損傷演化研究[J].人民長江,2010,41(17):79?83.
HAO Jinghong, JIANG Yuan, MEI Shiqiang, et al. Study on damage development of concrete based on CT image processing [J]. Yangtze River, 2010, 41(17): 79?83.
[5] 田威,黨發寧,陳厚群.基于CT圖像處理技術的混凝土細觀破裂分形分析[J].應用基礎與工程科學學報,2012,20(3):424?431.
TIAN Wei, DANG Faning, CHEN Houqun. Fractal analysis on meso?fracture of concrete based on the technique of CT image processing [J]. Journal of basic science and engineering, 2012, 20(3): 424?431.
[6] 劉奇,李昌聰,黃韞梔,等.對接管焊縫的雙壁雙投影工業X射線圖像處理研究[J].四川大學學報(工程科學版),2015,47(2):89?94.
LIU Qi, LI Changcong, HUANG Yunzhi, et al. Image processing research on double?walled double?imaging industrial X?ray radiographs of butt weld [J]. Journal of Sichuan University (Engineering science edition), 2015, 47(2): 89?94.
[7] 丁繼生,衛偉,楊依忠,等.一種基于FPGA的開關中值濾波算法研究[J].合肥工業大學學報(自然科學版),2016,39(4):490?493.
DING Jisheng, WEI Wei, YANG Yizhong, et al. Research on switching median filtering algorithm based on FPGA [J]. Journal of Hefei University of Technology, 2016, 39(4): 490?493.
[8] 汪祖輝,孫劉杰,邵雪,等.一種結合小波變換和維納濾波的圖像去噪算法[J].包裝工程,2016,37(13):173?178.
WANG Zuhui, SUN Liujie, SHAO Xue, et al. An image denoising algorithm combined with wavelet transform and Wiener filtering [J]. Packaging engineering, 2016, 37(13): 173?178.
[9] 張小波.基于維納濾波的圖像去噪算法研究[D].西安:西安電子科技大學,2014.
ZHANG Xiaobo. Research of image denoising algorithms based on Wiener filter [D]. Xian: Xidian University, 2014.
[10] 焦莉娟,王文劍.一種快速的K?SVD圖像去噪方法[J].小型微型計算機系統,2016,37(7):1608?1612.
JIAO Lijuan, WANG Wenjian. Speeded?up K?SVD image denoising algorithm [J]. Journal of Chinese computer systems, 2016, 37(7): 1608?1612.
[11] AHARON M, ELAD M, BRUCKSTEIN A. K?SVD: an algorithm for designing overcomplete dictionaries for sparse representation [J]. IEEE transactions on signal processing, 2006, 54(11): 4311?4322.
[12] ELAD M, AHARON M. Image denoising via sparse and redundant representations over learned dictionaries [J]. IEEE transactions on image processing, 2006, 15(12): 3736?3745.
[13] 張海軍,陳圣波,張旭晴,等.基于GPU的遙感圖像快速去噪處理[J].城市勘測,2010(2):96?98.
ZHANG Haijun, CHEN Shengbo, ZHANG Xuqing, et al. GPU?based denoising to remotely sensing images [J]. Urban geotechnical investigation & surveying, 2010(2): 96?98.
[14] PARK J Y, CHUNG K S. Parallel LDPC decoding using CUDA and OpenMP [J]. EURASIP journal on wireless communications and networking, 2011(1): 172?179.
[15] MROZEK D, BROZEK M, MALYSIAK?MROZEK B. Parallel implementation of 3D protein structure similarity searches using a GPU and the CUDA [J]. Journal of molecular modeling, 2014, 20(2): 2067.
[16] 霍迎秋,秦仁波,邢彩燕,等.基于CUDA的并行K?means聚類圖像分割算法優化[J].農業機械學報,2014,45(11):47?53.
HUO Yingqiu, QIN Renbo, XING Caiyan, et al. CUDA?based parallel K?means clustering algorithm [J]. Transactions of the Chinese Society of Agricultural Machinery, 2014, 45(11): 47?53.
[17] 張曉陽.基于K?SVD和殘差比的稀疏表示圖像去噪研究[D].重慶:重慶大學,2012.
ZHANG Xiaoyang. Image denoising via sparse and redundant representations over K?SVD algorithm and residual ratio iteration termination [D]. Chongqing: Chongqing University, 2012.
