改進(jìn)的FSVM算法用于非平衡情感數(shù)據(jù)分類
2018-11-17 01:48:10張雪英陳桂軍
計(jì)算機(jī)工程與設(shè)計(jì) 2018年11期
張雪英,張 波,陳桂軍
(太原理工大學(xué) 信息工程學(xué)院,山西 晉中 030600)
0 引 言
計(jì)算機(jī)語音情感識(shí)別[1]能力應(yīng)用多樣,在多媒體分段與檢索、測(cè)謊儀、疾病診斷等方面有著廣泛的用途。SVM在解決小樣本以及維數(shù)災(zāi)難問題中有著良好的分類效果。但是它也有缺陷,在分類的過程中有些區(qū)域不可分,影響分類結(jié)果。當(dāng)數(shù)據(jù)集中的正負(fù)樣本不平衡性較大時(shí),SVM對(duì)少數(shù)類的識(shí)別效果很差。同時(shí),支持向量機(jī)對(duì)噪聲和孤立點(diǎn)也比較敏感,影響最終的分類結(jié)果。
針對(duì)以上缺陷,文獻(xiàn)[2]用FSVM對(duì)不同的不平衡率樣本集進(jìn)行分類,但忽略了樣本點(diǎn)附近的樣本分布情況造成了誤分。文獻(xiàn)[3]在模糊支持向量機(jī)的基礎(chǔ)上引入了不平衡調(diào)節(jié)因子,對(duì)少數(shù)類樣本賦予較大的權(quán)值,多數(shù)類樣本賦予較小的權(quán)值,有效解決了樣本分布不均勻的問題。文獻(xiàn)[4]設(shè)置了參數(shù)值調(diào)整選取訓(xùn)練樣本的范圍,有效地避免了孤立點(diǎn)對(duì)最優(yōu)的分類超平面所造成的影響。文獻(xiàn)[5]提出了DEC算法分別給兩類樣本賦權(quán)重,但這種方法沒有考慮到樣本點(diǎn)周圍的疏密性對(duì)分類超平面的影響。文獻(xiàn)[6]提出了一種近似支持向量機(jī)(Proximal SVM),將模型轉(zhuǎn)化為簡(jiǎn)單的二次規(guī)劃問題,提高了學(xué)習(xí)速度。文獻(xiàn)[7]通過對(duì)支持向量上采樣提出了一種不平衡數(shù)據(jù)分類方法。文獻(xiàn)[8]提出了一種核函數(shù)選取和欠采樣相結(jié)合的算法來提高少類樣本的準(zhǔn)確率。本文提出一種FSVM算法,考慮到每個(gè)樣本臨近區(qū)域的樣本分布狀況以及樣本集的不平衡程度,設(shè)定控制值靈活的控制樣本集的范圍,減弱野值點(diǎn)的影響并有效突出支持向量的作用,提高了識(shí)別準(zhǔn)確率。
1 模糊支持向量機(jī)
1.1 改進(jìn)FSVM算法
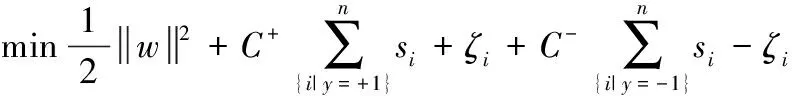
(1)
式中:C+,C-為常數(shù),分別代表正負(fù)類樣本的懲罰因子,為求解式(1),通過拉格朗日函數(shù),出其對(duì)偶規(guī)劃為
(2)
約束條件為
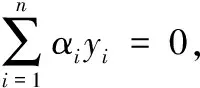
(3)
其中,k(xi·xj)=φ(xi)φ(xi)T為核函數(shù)。模糊因子si的確定是模糊支持向量機(jī)工作性能好壞的關(guān)鍵,本文重心在于如何精確的對(duì)模糊因子si賦值。
1.2 DEC算法
SVM對(duì)不平衡的大數(shù)據(jù)樣本集做分類,超平面會(huì)偏移,優(yōu)化性能很差,具體表現(xiàn)在多數(shù)樣本分類遠(yuǎn)遠(yuǎn)優(yōu)于少數(shù), DEC算法通過對(duì)不同類別樣本分別給予重要程度,優(yōu)化分類超平面,使偏移性降低,增強(qiáng)分類結(jié)果,文獻(xiàn)[5]表明當(dāng)C-/C+的比率等于n+/n-(n+,n-分別表示正樣本和負(fù)樣本的數(shù)量)時(shí),算法最優(yōu),能實(shí)現(xiàn)最好的分類。基本大多樣本類別數(shù)目相差懸殊的時(shí)候都用此算法,一定范圍上可以提高準(zhǔn)確性,但并未考慮樣本分布情況的影響,若是空間復(fù)雜性樣本分布或者不規(guī)則分布時(shí),算法便不能優(yōu)化分類超平面了。本文將模糊隸屬度與懲罰因子結(jié)合起來,根據(jù)對(duì)分類超平面的貢獻(xiàn)值為每個(gè)樣本分配不同的權(quán)重,使分類器分類偏移幅度盡可能的小。
2 面向非平衡數(shù)據(jù)集的FSVM隸屬度設(shè)計(jì)
2.1 傳統(tǒng)隸屬度函數(shù)設(shè)計(jì)
為了減少異常值和噪聲點(diǎn)對(duì)最優(yōu)分類超平面的影響,傳統(tǒng)的隸屬函數(shù)主要是根據(jù)從樣本到類中心的距離來設(shè)計(jì)的。如圖1所示,H1與H2上各有3個(gè)支持向量,每個(gè)支持向量到屬于本類的類中心間距不一,這6個(gè)支持向量對(duì)于確定H這個(gè)分類超平面起著決定性作用,如果根據(jù)間距賦重要性程度,那么每個(gè)支持向量被給予的權(quán)值都不同,但實(shí)際情況,它們重要性是一樣的,傳統(tǒng)方法賦值存在很大漏洞,不能單靠與類中心間隔比較來確定重要與否。只有將這些不足之處填補(bǔ),才能優(yōu)化分類器的性能,減小數(shù)據(jù)偏移,大數(shù)據(jù)氛圍下,有大量數(shù)據(jù)樣本點(diǎn)需要做處理、做賦值,必須優(yōu)化算法才能解決這一問題。
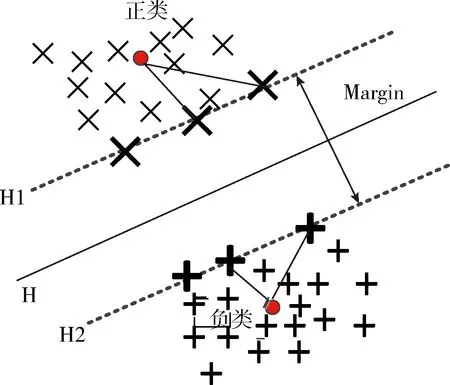
圖1 根據(jù)樣本到類中心的距離進(jìn)行隸屬度函數(shù)設(shè)計(jì)
2.2 根據(jù)樣本分布情況進(jìn)行設(shè)計(jì)
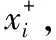
(4)
(5)
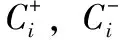
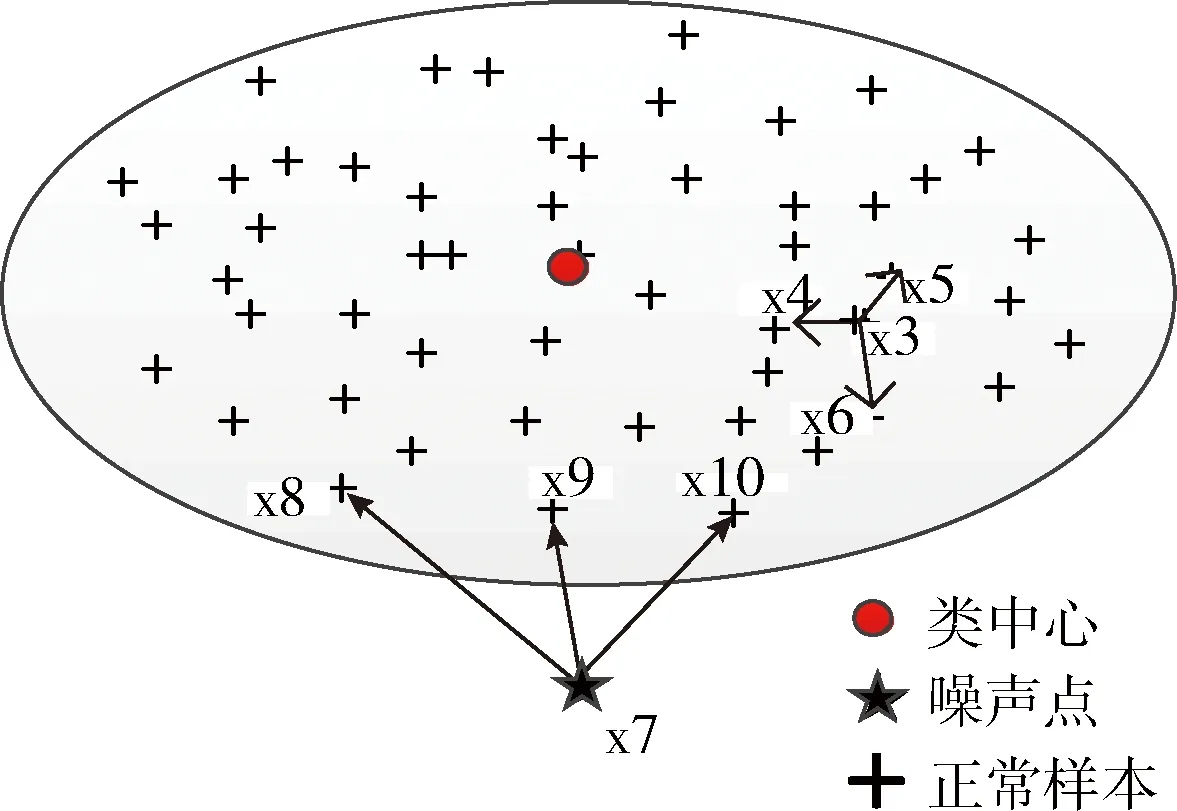
圖2 帶有一個(gè)噪聲點(diǎn)的橢圓分布數(shù)據(jù)
wx++b1=1;wx-+b2=-1
(6)
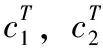
(7)
兩類樣本到各自類中心的距離
(8)
正樣本到過負(fù)樣本中心超平面的距離
(9)
負(fù)樣本到過正樣本中心超平面的距離
(10)
計(jì)算兩類類中心的距離
(11)
取
D+=max{di+},D-=max{di-}
(12)
隸屬度函數(shù)計(jì)算公式為
(13)
(14)

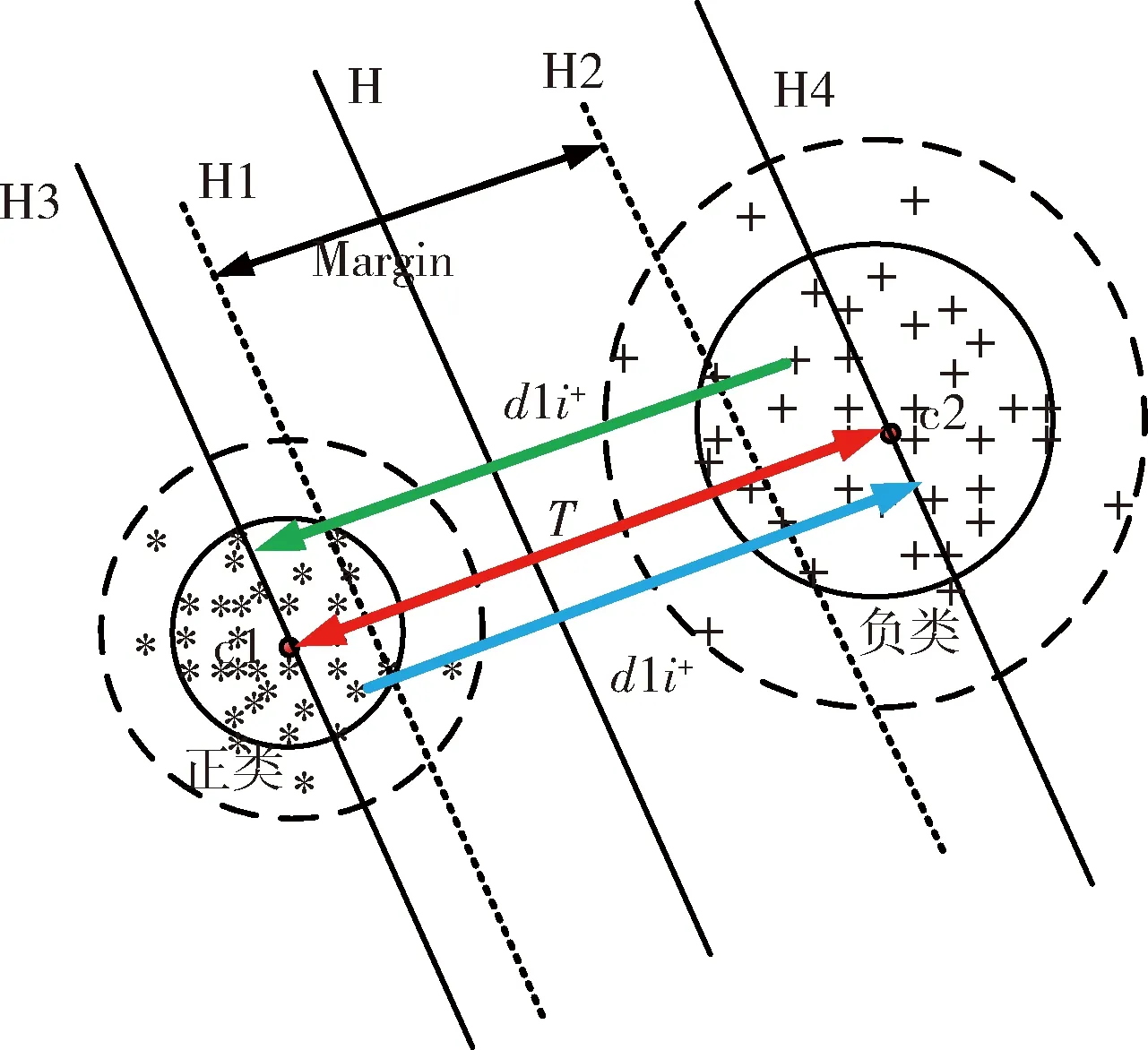
圖3 新型不平衡隸屬度函數(shù)設(shè)計(jì)
將樣本點(diǎn)到過負(fù)類中心超平面的距離d1i+和T值進(jìn)行比較,可以彰顯H1和H2線上支持向量點(diǎn)效果,突出其對(duì)分類超平面的貢獻(xiàn),DEC算法能大幅度降低分類超平面偏移幅度,另外結(jié)合緊密度能夠確定噪聲點(diǎn)將其剔除。
3 實(shí)驗(yàn)與結(jié)果分析
實(shí)驗(yàn)選取兩種情感庫,CASIA漢語語料庫包括5類情感,空間分布規(guī)則,不重疊,情感色彩鮮明。太原理工大學(xué)TYUT2.0庫包括4種情感,由多名學(xué)生錄制判別,選取大多趨向定義情感類,具有可靠性,兩種庫比較適合用來做情感識(shí)別實(shí)驗(yàn)。
實(shí)驗(yàn)選取MFCC特征,音質(zhì)特征還有韻律特征,歸一化,分別用CASIA庫,情感類為生氣的樣本,以及TYUT2.0,感受為高興的樣本,默認(rèn)為正類樣本,其余看作一類,不平衡比體現(xiàn),數(shù)據(jù)集的介紹見表1。

表1 情感語音數(shù)據(jù)集
3.1 參數(shù)對(duì)算法準(zhǔn)確率Gm的影響
對(duì)于非平衡情感數(shù)據(jù)集,本文采用不平衡數(shù)據(jù)學(xué)習(xí)中的Se,Sp,和Gm來評(píng)價(jià)[10],其定義為
(15)
TP、FN、TN、FP分別代表分類正確的正樣本、分類錯(cuò)誤的負(fù)類樣本、分類正確的負(fù)類樣本、以及分類錯(cuò)誤的正類樣本的個(gè)數(shù),用Gm對(duì)分類器性能進(jìn)行評(píng)價(jià),Gm越大分類效果越好。
本節(jié)用不同C值做實(shí)驗(yàn),比較文獻(xiàn)[4]中的HFSVM、文獻(xiàn)[11]中LFSVM方法,取 0,0.1,1,10,20,…,100,圖4、圖5分別給出了兩種情感庫數(shù)據(jù)集的實(shí)驗(yàn)結(jié)果。

圖4 C值的改變對(duì)CASIA漢語情感語料庫Gm的影響
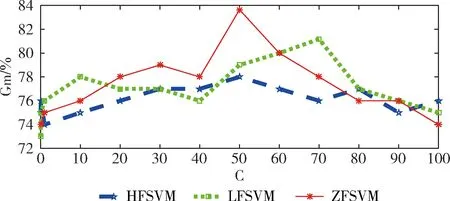
圖5 C值的改變對(duì)TYUT2.0情感語料庫Gm的影響
3.2 算法準(zhǔn)確率Gm對(duì)比分析
將文獻(xiàn)[4]中的HFSVM方法、文獻(xiàn)[11]中LFSVM設(shè)方法與本文方法對(duì)比,選取最高C值。表2為對(duì)CASIA漢語庫,TYUT2.0情感庫做識(shí)別的最終結(jié)果。
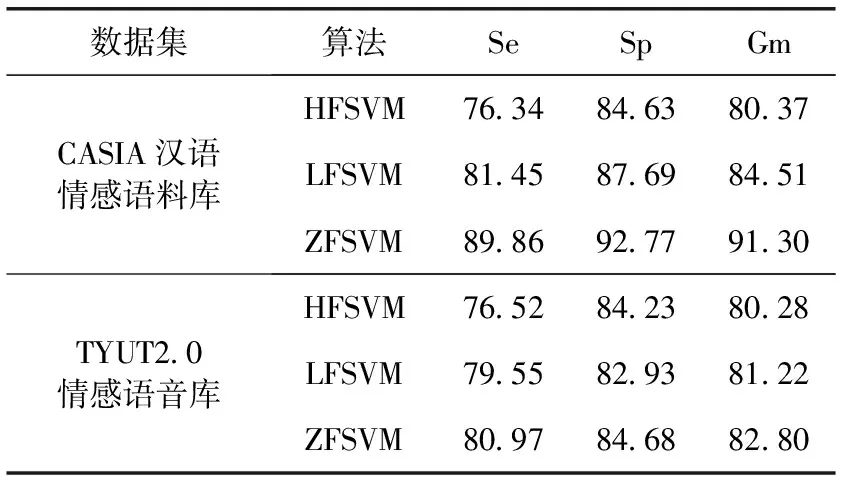
表2 3種算法的比較結(jié)果

圖6 3種算法對(duì)CASIA漢語情感語料庫的Gm值比較
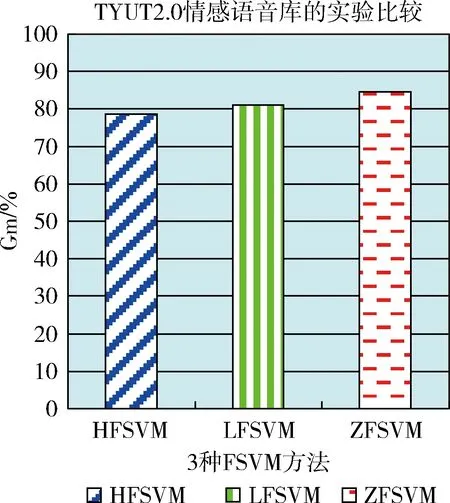
圖7 3種算法對(duì)TYUT2.0情感語音庫的Gm值比較
比較圖6,圖7可以看出,ZFSVM在對(duì)不平衡率為14.28的CASIA漢語庫做識(shí)別時(shí),Gm值為91.70%,對(duì)不平衡率為4.89的柏林庫做識(shí)別時(shí)的Gm值為83.65%,算法性能的好壞受樣本的不平衡程度影響。不平衡程度越厲害,算法對(duì)樣本做處理的精確度越高,說明本文所提算法的有效性,造成最優(yōu)超平面偏移程度很小。此外相比其它兩種方法,本文方法的準(zhǔn)確性也有增長(zhǎng),因?yàn)閷?duì)每個(gè)樣本所配權(quán)值更加精準(zhǔn)了,隨著樣本數(shù)增多前面兩種方法會(huì)將部分對(duì)超平面貢獻(xiàn)相同的樣本賦予不同的權(quán)值,甚至?xí)o部分對(duì)超平面貢獻(xiàn)較大而距離類中心較遠(yuǎn)的樣本賦予小的隸屬度值,一定程度上減弱了支持向量的作用,影響分類結(jié)果。
4 結(jié)束語
為了解決SVM分類的缺陷,通過DEC算法,及樣本點(diǎn)附近樣本分布,對(duì)每個(gè)樣本點(diǎn)到類中心超平面的距離設(shè)計(jì)權(quán)值賦予方式,確定噪聲點(diǎn)。按照樣本點(diǎn)重要與否、程度大小各自賦值,大大減小了非支持向量點(diǎn)影響,去除了噪聲點(diǎn)干擾,某種意義上提高了支持向量機(jī)的抗噪性。實(shí)驗(yàn)結(jié)果表明,本文所提算法對(duì)不平衡語音情感數(shù)據(jù)庫的識(shí)別性能有顯著提高。但是,此方法需要設(shè)置參數(shù)重復(fù)實(shí)驗(yàn)以選擇優(yōu)值。下一步是更詳細(xì)地研究參數(shù)和隸屬函數(shù)之間的關(guān)系,并找到更方便的參數(shù)設(shè)置方法。
猜你喜歡
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中國(guó)生殖健康(2020年5期)2021-01-18 02:59:48
家庭醫(yī)學(xué)(下半月)(2020年4期)2020-05-30 12:42:50
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(bào)(2019年10期)2019-11-04 02:57:59
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中國(guó)生殖健康(2018年5期)2018-11-06 07:15:40
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
