
云環境中Web信息抓取技術的研究及應用
2018-11-19 07:30:16王仕艷
通信電源技術 2018年9期
王仕艷
(川北幼兒師范高等專科學校,四川 廣元628000)
目前互聯網中的數據還存在更新換代快、推送慢影響消息利用率、客戶獲得數據速度慢等問題[1-3]。而云時代下信息具有傳播速度快、數據集中管理、批量傳送數據等特點,同時還支持個性化服務,根據這些特點為用戶推送出滿足需求的數據信息,可提高數據信息的利用率。
當前的數據抓取技術有多種,其中hadoop云平臺框架被廣泛使用,但是這些技術多以java技術實現[4-5]。面對快速系統開發時java語言不太能滿足,為此本文以C#語言作為系統開發語言使用開源nwebcrawler框架作為數據采集工具。
1 系統需求分析
互聯網中包含大量信息,如何獲取這些信息加以使用能夠給企業、個人提供更多的信息資源從而增加企業競爭和個人信息獲取來源。信息獲取大多來源于網站,由于行業、服務對象等不同造成網站有多種形式。如何獲取不同類別網站的信息是當前面臨問題。段青玲等文獻對農業網絡信息進行了獲取[4],文獻[6]對海上信息進行了獲取,他們對不同的網站信息進行了不同的獲取信息開發,這樣增加了獲取信息的成本。為解決這一問題,本文提出了一種通用網站信息獲取系統開發。系統功能主要有:(1)系統登錄管理,該功能用于權限管理,保障用戶信息安全。(2)系統配置管理,該功能用于抓取數據規則配置、數據管理等。(3)數據抓取管理,根據配置信息進行數據抓取。(4)數據存儲管理,由于抓取的數據量比較大需要對數據進行備份、還原等管理。系統用戶主要有:系統管理員、普通用戶兩類,系統管理員對系統管理,普通用戶進行相應的數據抓取管理。如圖1為系統總體用例圖。
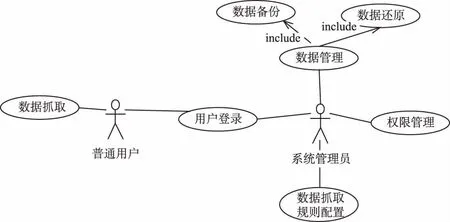
圖1 系統總體用例圖
2 系統設計
2.1 系統總體設計
Web信息抓取平臺主要由三部分組成:數據源、數據采集以及數據分析,如圖2所示。在數據源中包含了多種類型的網站,這些網站提供采集信息;此外系統還配置有txt、xml、sqlite以及excel文件,這些文件用于存儲采集信息、配置信息等。數據采集功能有:抓取、抽取、分類等。信息服務中主要進行信息發布、信息查詢、信息推薦、數據管理、收費管理等。
2.2 系統關鍵技術
在云環境下數據采集目的是方便用戶快速查詢信息,系統關鍵技術有:數據采集、數據抽取、數據分類、數據查詢等。下文詳細分析系統關鍵技術。
2.2.1 網站采集數據
Web數據采集主要是從Web上獲取網站網頁,將網頁保存在文檔中,并將文檔中的信息提取出來。為提高系統開發效率,本文使用C#語言進行網站數據采集系統開發,該語言具有簡單、易用特征,非常適合快速系統開發。當前網站數據采集框架有多種,比如:WebCollector、Nutch、nwebcrawler等[7-8]。本 文選擇nwebcrawler框架作為網站采集數據框架,該框架具有源代碼開發、性能優越等特點。如圖3為網站采集活動圖。
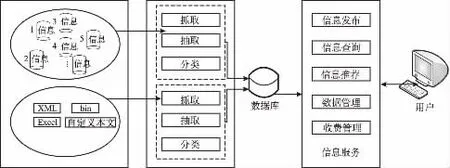
圖2 系統總體設計
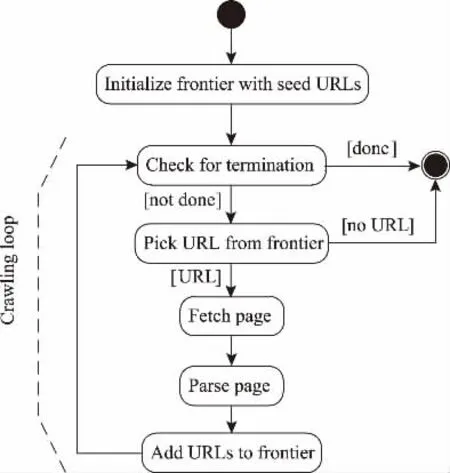
2.2.2 數據抽取技術
在C#網站數據抽取的類有:WebClient、Web-Browser、HttpWebRequest。本系統使用nwebcrawler框架、WebClient、WebBrowser進行數據采集開發。數據抽取是系統核心技術。如下為網站數據抽取部分核心代碼。
//獲取網頁中所有的<td...></td>標簽
HtmlElementCollection htmlCol = webBrowser1.Document.GetElementsByTagName("td");
if(htmlCol.Count<4)
{
return;
}
//根據網頁源代碼可以知道前四個是標題
//設置表格標題
dataGridView1.ColumnCount=4;
dataGridView1.Columns[0].Name = htmlCol[0].InnerText;
dataGridView1.Columns[1].Name = htmlCol[1].InnerText;
dataGridView1.Columns[2].Name = htmlCol[2].InnerText;
dataGridView1.Columns[3].Name = htmlCol[3].InnerText;
dataGridView1.Rows.Clear();
//從第四個即標題后面開始四個一行加入列表中
for(int i=4;i<htmlCol.Count &&i+4<htmlCol.Count;i+=4)
{
dataGridView1.Rows.Add(new string[]{htmlCol[i].InnerText,htmlCol[i+1].InnerText
htmlCol[i+2].InnerText,htmlCol[i+3].Inner-Text});
}
2.3 數據庫設計
Web信息抓取系統中使用數據庫有兩類:一類是SQLite數據庫用于存儲相應的參數;一類是網絡數據庫Mysql。在信息抓取系統中包含的數據表有:用戶權限表、信息存儲表、參數配置表等。
(1)用戶權限表。該表用于存儲用戶權限信息,包含的字段有:權限ID、權限內容、用戶名、用戶ID、用戶密碼等,表1為詳細說明。

表1 用戶權限表
(2)參數信息表。該表用于存儲系統參數信息,包含的字段有:參數ID、參數名、參數內容、參數大小、參數時間、備注等。表2為參數信息詳細說明。
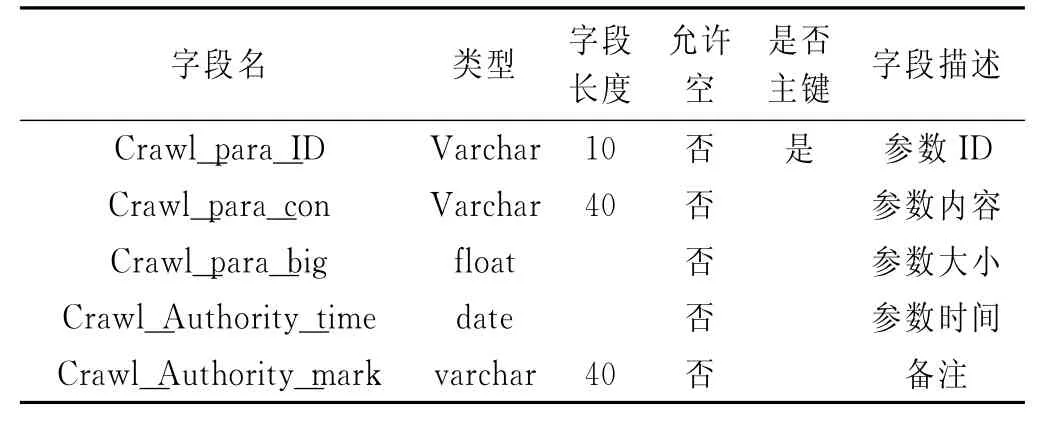
表2 參數信息表
3 系統實現
本文系統使用B/S模式進行開發。由于系統功能較多,本文只列舉網站數據采集創建過程。用戶需要在界面中輸入網址規則、下載深度、網址過濾(使用正則表達式)、重復下載網址過濾、下載參數設置、網頁數據設置、javascript引擎設置、登錄設置、基本信息設置等。圖4為網站數據采集創建界面。
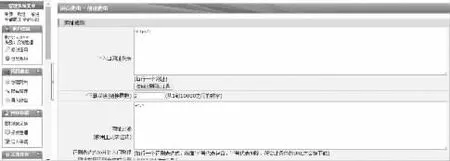
圖4 網站數據采集創建界面
4 結 論
本文構建了Web信息抓取系統,實現了Web信息采集,主要結論為:系統實現了數據采集、數據抽取、數據分類,用戶可在界面中輸入相應的信息進行數據采集,提高了系統的復用性。
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
家庭影院技術(2017年9期)2017-09-26 03:41:45
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
