基于受限玻爾茲曼機的Web服務質量預測方法
2018-12-06 06:45:48王興菲萬健陳璐殷昱煜俞立峰
中南大學學報(自然科學版) 2018年11期
王興菲,萬健, 3,陳璐,殷昱煜,俞立峰
?
基于受限玻爾茲曼機的Web服務質量預測方法
王興菲1, 2,萬健1, 2, 3,陳璐1, 2,殷昱煜1, 2,俞立峰4
(1. 杭州電子科技大學計算機學院,浙江 杭州,310018;2. 復雜系統建模與仿真教育部重點實驗室,浙江 杭州,310018;3. 浙江科技學院 信息與電子工程學院,浙江 杭州,310023;4. 杭州核新同花順網絡信息股份有限公司,浙江 杭州,310023)
針對協同過濾算法無法有效處理數據稀疏的問題,提出1種基于受限玻爾茲曼機的Web服務質量(QoS)預測方法;第1階段使用受限玻爾茲曼機模型對所有缺失的QoS值進行預測,并對原始的QoS矩陣進行填充;在第2階段基于該QoS矩陣進行全局鄰居篩選,同時將受限玻爾茲曼機引入到用戶近鄰的協同過濾模型中,以預測目標QoS值。研究結果表明:該方法能提高QoS預測精確度,在一定程度上降低數據稀疏對預測的影響。
Web服務;服務質量預測;協同過濾;受限玻爾茲曼機
Web服務分為功能性屬性和非功能需屬性,其中,服務質量(quality of service,QoS)通常用來描述非功能屬性[1]。基于QoS的Web服務預測是服務推薦的重要基礎[2]。隨著互聯網技術不斷發展,功能相似的Web 服務數量大量增加,如何提高QoS預測精度進行有效的Web服務推薦是服務推薦領域的熱點問題。目前,協同過濾由于具有簡易性而受到了廣泛關注[3]。在服務推薦領域,許多研究者開始將協同過濾應用于QoS預測[2],并取得了較好的效果。傳統協同過濾算法主要分為基于近鄰和基于模型2類[4]。基于近鄰的協同過濾算法具有很好的可解釋性以及較高的預測精確度,但無法有效處理數據稀疏情況[5]。由于數據稀疏,基于近鄰的協同過濾算法無法準確地獲取相似鄰居進而無法進行精確預測,因此,人們提出基于模型的協同過濾。目前,基于模型的協同過濾算法包括奇異值分解(singular value decomposition, SVD)模型[6]以及基于受限玻爾茲曼機(restricted Boltzmann machine, RBM)的無向圖模型[7]。奇異值分解模型通過降低矩陣維度進行模型學習,對稀疏問題并不敏感。近年來,RBM模型因其具有有效的特征提取能力和泛化能力以及較強的可靠性,在推薦系統領域受到較大的關注。在數據稀疏情況下,RBM能根據歷史行為提取有效的目標特征進行預測。但是,RBM需要從全局進行訓練,在預測中易產生局部最優而影響預測精度。基于近鄰的協同過濾雖是從局部中學習,但數據稀疏會導致其無法獲得準確的局部信息來進行精確預測。本文作者將兩者融合,提出一種基于受限玻爾茲曼機的Web服務QoS預測算法;通過訓練基于RBM的協同過濾模型提取目標近鄰的特征,將目標特征用于第1階段預測,利用這些預測結果填充用戶服務矩陣以降低數據稀疏的影響;在第2階段,利用重新形成的用戶服務矩陣進行全局篩選,并使用基于RBM與用戶近鄰融合的協同過濾模型預測得到最終QoS結果。
1 基于受限玻爾茲曼機的Web服務QoS預測
1.1 基于受限玻爾茲曼機的Web服務QoS預測框架
基于受限玻爾茲曼機的Web服務QoS預測算法框架如圖1所示。由圖1可知:在第1階段,該方法使用基于RBM的協同過濾模型進行預測,并將其結果填充于用戶服務矩陣,緩解了數據稀疏問題。在第2階段,通過重新形成的用戶服務矩陣進行全局篩選,使用基于RBM與用戶近鄰融合的協同過濾模型進行預測,最終得到QoS預測結果。
1.2 第1階段預測
RBM是一種無監督的、具有2層結構、對稱連接且無自反饋的隨機神經網絡模型。該網絡模型可以視為1個無向圖,由一些可見單元(對應可見變量,即訓練數據集項目數)和一些隱藏單元(對應隱藏變量,可視為特征提取器)構成。只有可見單元和隱藏單元之間才會存在邊,可見單元之間以及隱藏單元之間都不會有邊連接。RBM模型是一種基于能量的模型,能量最小化時網絡達到理想狀態,而網絡的訓練就是最小化其能量函數。

圖1 基于受限玻爾茲曼機的Web服務QoS預測框架圖
基于受限波爾茲曼機模型的協同過濾模型如圖2所示。該模型將可見單元轉化為1個維的0?1向量單元。其中,表示評分范圍,將用戶評分所在的分量置為1,其余分量置為0。其次,對于沒有評分的數據用單元表示,且這類單元不與隱藏單元連接,可將其視為分量全為0的向量單元。

圖2 基于受限波爾茲曼機的協同過濾模型圖
本研究中,由于用戶服務矩陣中的QoS值為浮點數,考慮到RBM需要的為整數,由QoS值四舍五入得到。在本文采用的數據集中,范圍為[0, 1, …, 20]。
該模型的能量函數為
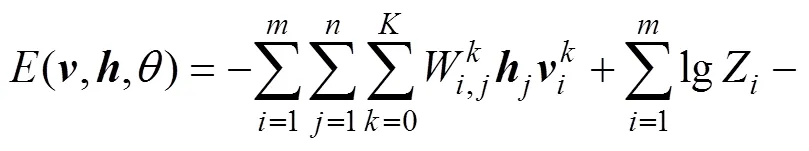
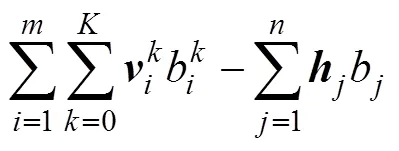
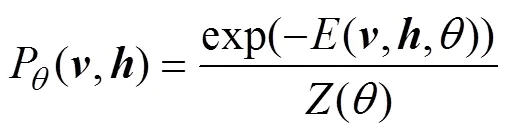


由于RBM層間全連接,層內無連接,可見單元和隱藏單元之間是獨立的特殊結構。當給定可見單元時,各個隱藏單元的激活概率之間是相互獨立的;反之,當給定隱藏單元時,各個可見單元的激活概率之間也是相互獨立的,且RBM結構是對稱的,因此,根據得到的可見單元和隱藏單元可以分別得到第個隱藏單元和第個可見單元的激活概率:
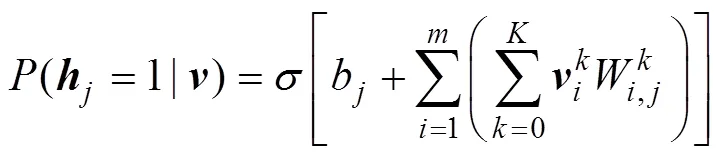
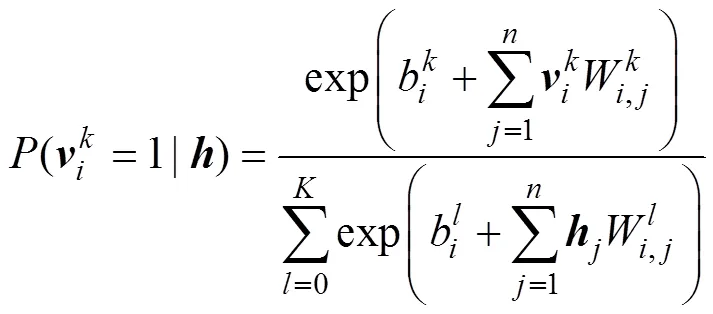
HINTON[8]提出了基于對比散度的快速學習算法(contrastive divergence,簡稱CD算法)。有了以上條件概率,就可以直接使用CD算法訓練RBM,其中各參數的更新準則如下:
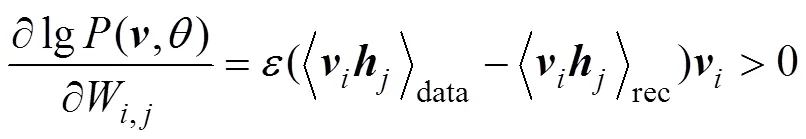
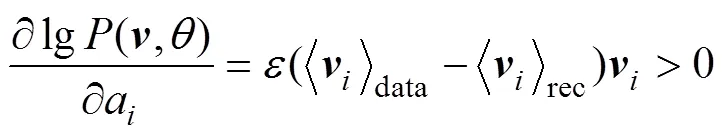
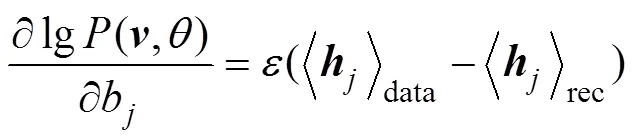
模型訓練好后,若用戶調用服務的QoS值已知,則該用戶調用服務的QoS值為的概率可直接通過公式求出。根據RBM預測當前用戶調用服務的QoS值為
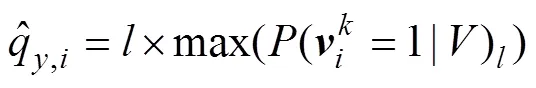
1.3 第2階段預測
在第2階段預測中,首先利用填充后的QoS矩陣全局篩選相似鄰居,然后通過基于RBM與用戶近鄰的協同過濾模型預測最終QoS結果。
1.3.1 相似度計算
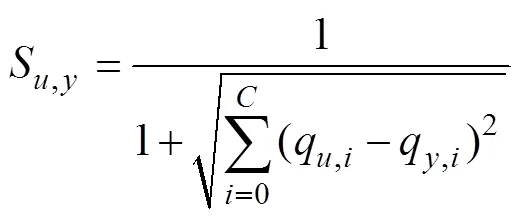
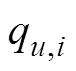
1.3.2 全局篩選
全局篩選相似鄰居流程圖如圖3所示。傳統的協同過濾算法僅僅使用有調用目標服務記錄的用戶作為相似鄰居,忽略了具有較高相似度但有未調用目標服務記錄的用戶以及具有相同網絡位置的用戶,導致基于近鄰協同過濾算法在數據稀疏的情況下篩選鄰居不準確。為了提高篩選準確率,本文作者在相似度的基礎上利用網絡位置信息與RBM預測結果進行進一步篩選。
網絡位置信息包括自主網絡系統(autonomous system, AS)與國家。將具有相同AS的用戶聚類為1組,稱為AS用戶組;再將具有相同國家的用戶聚類為1組,稱為國家用戶組。在基于相似度篩選的基礎上,將處于同一AS或是同一國家的用戶視為相似 鄰居。
通過第1階段預測,QoS矩陣得到了填充,緩解了由于數據稀疏性而無法得到準確近鄰的問題。在第2階段預測中,利用通過填充后的QoS矩陣進行全局篩選,充分考慮了具有較高相似度但有未調用目標服務記錄的用戶。
最后,通過加入網絡位置信息的全局篩選結果得到最終的相似鄰居集合(),()包括原始未調用目標服務記錄的用戶1()以及原始有調用目標服務記錄的用戶集合2()。
1.3.3 基于受限玻爾茲曼機與用戶近鄰的QoS預測方法
由于QoS值屬于離散分布,而RBM需要從全局進行訓練,在預測中易產生局部最優。基于近鄰的協同過濾雖是從局部中學習,但因為數據稀疏而無法獲得準確的局部信息,為此,本文作者提出基于RBM與用戶近鄰的QoS預測方法,并構建基于RBM的Web服務QoS預測模型。
首先基于用戶近鄰的協同過濾算法,根據TopK算法選擇與目標用戶最為相似的用戶鄰居集合,記為N()。其次,通過該目標用戶的相似鄰居集合對目標服務的歷史行為預測目標用戶對目標服務的行為。基于用戶近鄰的協同過濾算法表達式為
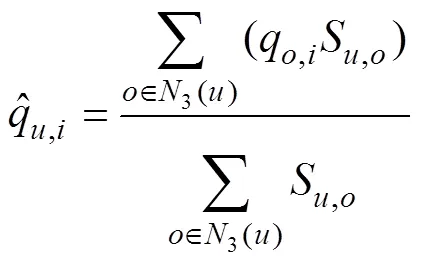
在基于用戶近鄰協同過濾算法的基礎上,構建基于RBM的Web服務QoS預測模型:
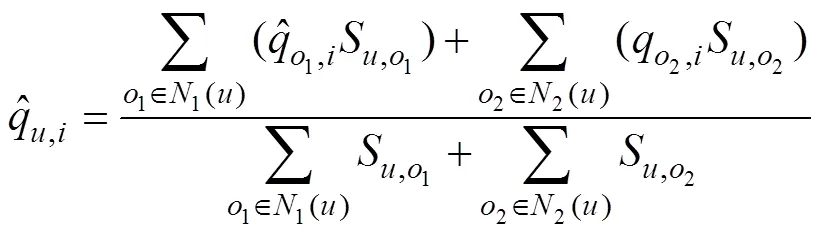
最后,將所得模型命名為基于受限玻爾茲曼機的Web服務QoS預測模型(RBMCF)。
2 實驗分析
2.1 數據集
實驗采用WSDream公開數據集[9]。該數據集包括5 825個服務和339個用戶,以及2個服務質量屬性即響應時間和吞吐量。本文使用其中的響應時間數據集,該數據集被廣泛用于QoS預測準確度評估,因此,基于該數據集的實驗是可信且可靠的。
2.2 評估標準
實驗采用平均絕對誤差MAE,即計算預測值與實際值的平均誤差來評估系統的推薦質量,MAE越小,則預測的準確率越高。MAE的計算公式如下:

同時使用歸一化平均絕對誤差NMAE來進一步衡量算法的預測準確度。歸一化平均絕對誤差的計算公式如下:
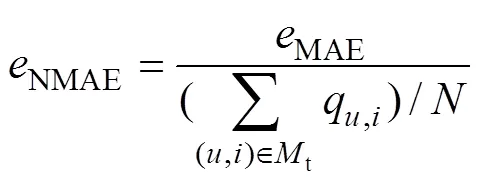
式中:t為測試集;為測試集中待預測服務質量的個數;(,)為測試集中待預測服務質量的(用戶,服務)對。平均絕對誤差和歸一化平均絕對誤差越小,表示預測準確度越高。
2.3 實驗環境設置
在真實環境下,用戶服務矩陣是非常稀疏的,用戶通常只調用少部分服務,不同用戶之間重合的服務調用更稀少。為了模擬真實環境,本文作者從原始WSDream數據集中抽取部分數據作為訓練集,其余則為測試集。本文選取4個不同稀疏度的訓練集進行實驗,稀疏度分別為5%,10%,15%和20%,其余全部作為測試集。對4個不同稀疏度的訓練集進行10次實驗并取平均結果作為最終結果。
2.4 性能比較
為了更好地評估本文提出算法的性能,本文實現下述幾個常見的服務質量值預測算法,并在該實驗集上進行了大量比較實驗。
1) UserMean。該方法通過求每個用戶的平均QoS值對缺失值進行預測。
2) RBM[7]。該方法是利用RBM的算法對缺失值進行預測。
3) ItemMean。該方法通過求每個Web服務的平均QoS值對缺失值進行預測。
4) UPCC[10]。該方法基于用戶協同過濾算法,使用皮爾遜相似度計算用戶間的相似度。
5) IPCC[11]。該方法采用基于物品的協同過濾算法,使用皮爾遜相似度計算物品間的相似度。
6) WSRec[9]。該方法對UPCC和IPCC的預測結果進行線性組合,將線性組合后的值作為預測結果。
7) LFM[6]。該方法通過對用戶服務矩陣進行降維分解,發現用戶與服務之間的隱含特征,根據隱含特征信息來進行預測。
8) NLBR[12]。該方法利用網絡位置信息結合矩陣分解發現隱含特征,并進行預測。
表1所示為不同訓練矩陣密度下不同模型的預測性能比較。表1中,MAE為平均絕對誤差,NMAE為歸一化平均絕對誤差,為訓練矩陣的數據稀疏度。從表1可以看出:本文提出的預測方法RBMCF的預測準確度比其他方法的高;另外,在不同數據稀疏度下,算法的性能差異不明顯,特別是在數據稀疏性高的情況下,RBMCF模型的預測準確度仍舊較高,這說明RBMCF能夠較好地應對數據稀疏性問題。
2.5 參數Tu的敏感性分析
參數u表示協同過濾算法中基于相似度為用戶選擇的相似鄰居數量,其中相似度是基于歷史數據并使用平均歐式距離計算得到的。平均歐式距離越大,表示用戶之間的相似度越小。圖4所示為不同數據稀疏度下,u對預測準確度的影響。數據稀疏度越高,意味著可用信息越少。
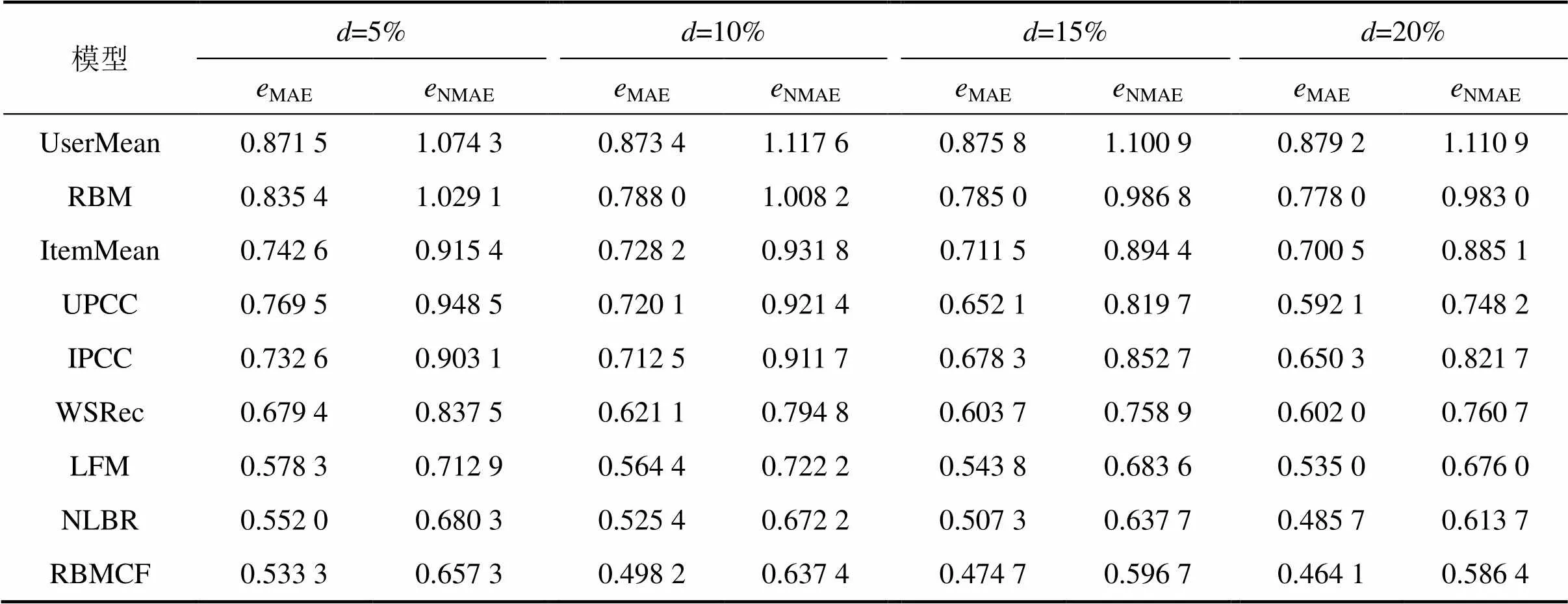
表1 不同訓練矩陣密度情況下不同模型的預測性能比較

d/%:(a) 5;(b) 10;(c) 15;(d) 20
從圖4可以看出:在初始階段,隨著u逐漸增大,MAE迅速減小。這是因為隨著相似鄰居數量增多,選中目標用戶真正的相似鄰居的可能性變大,同時,由于本文利用全局信息進行相似鄰居篩選,會添加那些因稀疏而被過濾的用戶(這些用戶和目標用戶表現出很強的相似性,卻因為沒有公用調用記錄而被過濾),同時排除那些因為偶然原因成為相似鄰居的用戶(這些用戶和目標用戶并沒有表現出很強的相似性,僅僅因為需要滿足相似鄰居數量而成為目標用戶的相似鄰居),因此,相似鄰居的可靠性增強。由此可見,通過使用全局過濾可以提高篩選鄰居準確度進而提高模型的預測精確度。
另一方面,當u增大到一定程度后,MAE趨向于平緩,這是由于參數取較大值后,相似度的定義變得寬松,很多相似性不強的用戶也被篩選為目標用戶的相似用戶,影響了預測精確度。
3 討論
目前,已有大量基于近鄰的協同過濾方法被成功應用于實際系統中[13?14]。WU等[15]提出了1種基于新型相似度計算方法的協同過濾算法。該方法采用比例值作為新的相似度度量方法,提高了預測準確度且計算時間更短。TANG等[16]提出了利用位置信息的協同過濾算法并將其應用于服務推薦,使得篩選鄰居更加準確。
基于近鄰的協同過濾算法的難點之一是數據稀疏問題[5]。由于數據稀疏,基于近鄰的協同過濾算法無法準確獲取相似鄰居進而無法進行精確預測。近年來,已有研究者提出了解決基于近鄰協同過濾算法數據稀疏問題的方法。WU等[17]提出了1種利用時間感知的基于近鄰的協同過濾方法,在高稀疏度情況下有較高的精確度。但基于近鄰的方法難以處理大數據量,有研究者提出基于模型的協同過濾方法,主要有SVD模型[18]、外觀模型[19]以及基于RBM的協同過濾方法[7]。YU等[20]提出1種結合了相似鄰居的隱語義(latent matrix factorization, LFM)模型,提高了服務推薦的精確性。外觀模型是1種概率隱空間模型,使用偏好因子的1個凸組合來對用戶偏好進行建模[19]。
RBM的快速學習算法即對比散度(contrastive divergence, CD)算法[8]具有強大的非監督學習能力,引起了研究者的密切關注。RBM成功地應用于解決協同過濾、圖像特征提取等機器學習問題[21]。近年來,RBM在推薦系統中也得到了應用[22]。實踐表明,RBM是一種有效的特征提取方法[23],能有效地應對數據稀疏情況;將RBM用于初始化前饋神經網絡可明顯提高泛化能力,多個RBM堆疊組成的深度置信網絡能提取更抽象的特征[24]。SALAKHUTDINOV等[7]提出了基于RBM模型的協同過濾算法,其對傳統的受限玻爾茲曼機進行改造以處理協同過濾問題:首先,將可見單元轉化為1個維的0?1向量單元;其次,對于沒有評分的數據用缺失單元表示,且這類單元不與隱藏單元連接。GEORGIEV等[25]提出了1個基于實值的RBM模型并改進了模型的訓練過程,使RBM的可見單元可以直接表示為實值,模型的訓練和預測也得到簡化。由于基于近鄰的方法與基于模型的方法各有優缺點,KOREN等[26]提出將矩陣分解與近鄰方法相結合,并取得了較好的預測結果。然而,這些基于近鄰的協同過濾方法忽略了具有較高相似度但有未調用目標服務記錄的用戶,因此,無法準確地篩選相似鄰居。同時,RBM在應用中易產生局部最優導致無法得到精確的預測結果。
4 結論
1) 本文提出了1種基于受限玻爾茲曼機的Web服務QoS預測算法;通過引入受限玻爾茲曼機降低數據稀疏對預測結果的影響,并結合基于用戶的協同過濾算法得到最終QoS預測結果。
2) 本文算法的QoS預測算法結果優于已有的協同過濾模型所得結果。
[1] LIU Yutu, NGU A H, ZENG Liangzhao. QoS computation and policing in dynamic web service selection[C]// Proceedings of the 13th International World Wide Web Conference on Alternate Track Papers & Posters. New York, USA: ACM, 2004: 66?73.
[2] ZHENG Zibin, MA Hao, LYU M R, et al. QoS-aware web service recommendation by collaborative filtering[J]. IEEE Transactions on Services Computing, 2011, 4(2): 140?152.
[3] LANGSETH H, NIELSEN T D. Scalable learning of probabilistic latent models for collaborative filtering[J]. Decision Support Systems, 2015, 74: 1?11.
[4] BREESE J S, HECKERMAN D, KADIE C. Empirical analysis of predictive algorithms for collaborative filtering[J]. Uncertainty in Artificial Intelligence, 1998, 98(7): 43?52.
[5] MIHA Gr?ar, DUNJA Mladeni?, BLA? Fortuna, et al. Data sparsity issues in the collaborative filtering framework[C]// International Workshop on Knowledge Discovery on the Web. Berlin, Germany: Springer, 2005: 58?76.
[6] KOREN Y, BELL R, VOLINSKY C. Matrix factorization techniques for recommender systems[J]. Computer, 2009, 42(8): 30?37.
[7] SALAKHUTDINOV R, MNIH A, HINTON G. Restricted Boltzmann machines for collaborative filtering[C]// International Conference on Machine Learning. New York, USA: ACM, 2007: 791?798.
[8] HINTON G E. Training products of experts by minimizing contrastive divergence[J]. Neural Computation, 2002, 14(8): 1771?1800.
[9] ZHENG Zibin, MA Hao, LYU M R, et al. WSRec: a collaborative filtering based web service recommender system[C]// International Conference on Web Services. Washington D C, USA: IEEE Computer Society, 2009: 437?444.
[10] RESNICK P, IACOVOU N, SUCHAK M, et al. GroupLens: an open architecture for collaborative filtering of netnews[C]// ACM Conference on Computer Supported Cooperative Work. New York, USA: ACM, 1994: 175?186.
[11] SARWAR B, KARYPIS G, KONSTAN J, et al. Item-based collaborative filtering recommendation algorithms[C]// International Conference on World Wide Web. New York, USA: ACM, 2001: 285?295.
[12] ZHOU Li, SONG Zhibo, ZHAI Suichu, et al. Predicting web service QoS via combining matrix factorization with network location[J]. International Journal of u- and e-Service, Science and Technology, 2014, 7(3): 303?318.
[13] HERLOCKER J L, KONSTAN J A, BORCHERS A, et al. An algorithmic framework for performing collaborative filtering[C]// Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. New York, USA: ACM, 1999: 230?237.
[14] LINDEN G, SMITH B, YORK J. Amazon.com recommendations: item-to-item collaborative filtering[J]. IEEE Internet Computing, 2003, 7(1): 76?80.
[15] WU Xiaokun, CHENG Bo, CHEN Junliang. Collaborative filtering service recommendation based on a novel similarity computation method[J]. IEEE Transactions on Services Computing, 2017, 10(3): 352?365.
[16] TANG Mingdong, JIANG Yechun, LIU Jianxun, et al. Location-aware collaborative filtering for QoS-based service recommendation[C]// IEEE, International Conference on Web Services.Washington D C, USA: IEEE Computer Society, 2012: 202?209.
[17] WU Chen, QIU Weiwei, WANG Xinyu, et al. Time-aware and sparsity-tolerant QoS prediction based on collaborative filtering[C]// IEEE International Conference on Web Services (ICWS). Washington D C, USA: IEEE Computer Society, 2016: 637?640.
[18] ZHANG Sheng, WANG Weihong, FORD J, et al. Using singular value decomposition approximation for collaborative filtering[C]// Seventh IEEE International Conference on E-Commerce Technology. Washington D C, USA: IEEE Computer Society, 2005: 257?264.
[19] HOFMANN T, PUZICHA J. Latent class models for collaborative filtering[C]//Proceedings of the Sixteenth International Joint Conference on Artificial Intelligence. San Francisco, USA: Morgan Kaufmann Publishers, 1999: 688?693.
[20] YU Dongjin, LIU Yu, XU Yueshen, et al. Personalized QoS prediction for web services using latent factor models[C]//IEEE International Conference on Services Computing. Washington D C, USA: IEEE Computer Society, 2014: 107?114.
[21] MIDHUN, M. E, NAIR, et al. Deep model for classification of hyperspectral image using restricted Boltzmann machine[C]//Proceedings of the 2014 International Conference on Interdisciplinary Advances in Applied Computing. New York, USA: ACM, 2014: 1?7.
[22] HINTON G E. A practical guide to training restricted Boltzmann machines[M]. Berlin, Germany: Springer, 2012: 599?619.
[23] TRAMEL E W, MANOEL A, CALTAGIRONE F, et al. Inferring sparsity: compressed sensing using generalized restricted Boltzmann machines[C]// IEEE Information Theory Workshop (ITW). Washington D C, USA: IEEE, 2016: 265?269.
[24] POLANIA L, BARNER F, KENNETH E, et al. Exploiting restricted Boltzmann machines and deep belief networks in compressed sensing[J]. IEEE Transactions on Signal Processing, 2017, 65(17): 4538?4550.
[25] GEORGIEV K, NAKOV P. A non-IID framework for collaborative filtering with restricted Boltzmann machines[C]// Proceedings of the 30th International Conference on Machine Learning. New York, USA: ACM, 2013: 1148?1156.
[26] KOREN Y. Factorization meets the neighborhood: a multifaceted collaborative filtering model[C]// International Conference on Knowledge Discovery and Data Mining. New York, USA: ACM, 2008: 426?434.
(編輯 伍錦花)
Web service QoS prediction based on restricted Boltzmann machines
WANG Xingfei1, 2, WAN Jian1, 2, 3, CHEN Lu1, 2, YIN Yuyu1, 2, YU Lifeng4
(1. School of Computer, Hangzhou Dianzi University, Hangzhou 310018, China; 2. Key Laboratory of Complex Systems Modeling and Simulation of Ministry of Education,Hangzhou 310018, China; 3. School of Information and Electronic Engineering,Zhejiang University of Science and Technology, Hangzhou 310023, China; 4. Hithink RoyalFlush Information Network Co. Ltd., Hangzhou 310023, China)
Considering that collaborative filtering algorithm can not cope with data sparseness effectively, an approach for Web service QoS prediction based on restricted Boltzmann machine was proposed. In the first phase, restricted Boltzmann machine was used to predict all the missing QoS values and fill the original QoS matrix. In the second phase, global filtering was performed based on the filled QoS matrix to obtain the neighbors. Then restricted Boltzmann machine was integrated into user-based collaborative filtering model to predict target QoS values. The results show that the proposed method can improve the accuracy of QoS prediction and reduce the effect of data sparsity on prediction to a certain extent.
Web service; QoS prediction; collaborative filtering; restricted Boltzmann machine
10.11817/j.issn.1672-7207.2018.11.015
TP312
A
1672?7207(2018)11?2745?08
2017?12?11;
2018?01?28
國家重點研發計劃項目(2017YFB1400601);浙江省自然科學基金資助項目(LY12F02003);國家自然科學基金資助項目(61100043) (Project(2017YFB1400601) supported by the National Key R&D Program of China; Project(LY12F02003) supported by the Natural Science Foundation of Zhejiang Province; Project(61100043) supported by the National Natural Science Foundation of China)
殷昱煜,博士,碩士生導師,從事服務計算、業務流程管理、形式化方法研究;E-mail: yinyuyu@hdu.edu.cn
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
商周刊(2017年9期)2017-08-22 02:57:56
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
