一種基于KMP算法思想的字符串匹配算法的研究與實(shí)現(xiàn)
2018-12-08 07:14:08唐永群孔令順
網(wǎng)絡(luò)安全技術(shù)與應(yīng)用 2018年12期
◆邵 嵐 唐永群 孔令順
?
一種基于KMP算法思想的字符串匹配算法的研究與實(shí)現(xiàn)
◆邵 嵐 唐永群 孔令順
((CLO 北京 100054)
KMP算法是一種高效的字符匹配算法,它的思想在于其在匹配失敗以后,不需要再對(duì)內(nèi)容字符序列從頭匹配,這樣就減少了匹配的次數(shù),提高效率。本方通過(guò)舉例比較說(shuō)明這個(gè)算法的優(yōu)點(diǎn)。
KMP;模式匹配;KMP算法
0 引言
我們身處一個(gè)信息爆炸時(shí)代,每天產(chǎn)生的信息幾乎都是海量。無(wú)論是金融、文學(xué)、生物還是計(jì)算機(jī)領(lǐng)域,文本都是必不可少的信息載體。而大到大型網(wǎng)站論壇,小到公司內(nèi)部項(xiàng)目都不可避免的要涉及信息的查找、過(guò)濾等相關(guān)功能,比如在一個(gè)文件中查找出所有給的字符串,然后過(guò)濾,不好的設(shè)計(jì)思想導(dǎo)致遲遲得不到結(jié)果,無(wú)法滿(mǎn)足實(shí)時(shí)性高的要求,這個(gè)過(guò)程中如何高效的處理就顯得尤為重要,各種字符串查找匹配算應(yīng)運(yùn)而生。
基于目前公司項(xiàng)目開(kāi)發(fā)中正好要用到字符串查找功能,借此機(jī)會(huì)對(duì)字符串匹配算法做一次分析與比較,希望能對(duì)項(xiàng)目的運(yùn)行效率有所裨益。
本文先簡(jiǎn)單了解BF算法,隨后介紹KMP算法及其思想、move數(shù)組的求解,最后介紹KMP算法在項(xiàng)目中的實(shí)現(xiàn)和簡(jiǎn)單應(yīng)用。
1 BF算法
BF算法的基本思想比較簡(jiǎn)單,就說(shuō)從內(nèi)容串C的第一個(gè)字符開(kāi)始和關(guān)鍵字串K的第一個(gè)字符開(kāi)始逐個(gè)進(jìn)行比較,如果相等則進(jìn)一步比較二者的第二個(gè)字符,依次往后移動(dòng)兩者的指向,如果在某個(gè)字符比較時(shí)失配了,則分別將關(guān)鍵字串K的第一個(gè)字符與內(nèi)容串的第二個(gè)字符作為最初指向再重新進(jìn)行比較,匹配時(shí)指向各自向后移動(dòng)一個(gè)位置,以此類(lèi)推。
下面通過(guò)一個(gè)簡(jiǎn)單的例子,我們可以來(lái)了解一下BF算法的原理。假設(shè)有一個(gè)內(nèi)容串C和關(guān)鍵字串K,C=”xyxyy”,K=“xyy”,也就是在C中去匹配K。由于例子比較簡(jiǎn)單,我們可以繪制出整個(gè)的匹配過(guò)程。如圖1所示。
BF算法的基本思想從圖中的七個(gè)過(guò)程就能得到完整的體現(xiàn),簡(jiǎn)單的描述一下上面的流程是這樣的:首先以關(guān)鍵字串K的第一個(gè)字符和內(nèi)容串C的第一個(gè)字符作為各自的起始位置進(jìn)行比較,經(jīng)過(guò)前兩次的匹配都成功后,這時(shí)的比較位置都移動(dòng)到第3個(gè)字符,也就是將關(guān)鍵字串的第三個(gè)字符’y’與內(nèi)容串的第三個(gè)字符’x’比較,由于不能匹配,就要進(jìn)行下一輪的重新匹配,也就是要重新確定比較的初始位置。對(duì)于模式來(lái)說(shuō),重新定位就是第一個(gè)字符作為初始比較位置,而對(duì)于內(nèi)容串來(lái)說(shuō)就是移動(dòng)一個(gè)位置而不是上一次匹配成功的最后位置。BF算法的實(shí)現(xiàn)比較簡(jiǎn)單,思維方式也很直接,但是存在不足之處:就上面的例子來(lái)說(shuō),內(nèi)容串的定位”走了回頭路”;而且比較操作也重復(fù)執(zhí)行了:第一次失配后,在接下來(lái)的第二次匹配時(shí),我們會(huì)首先用關(guān)鍵字串的第一個(gè)字符與內(nèi)容串的第二個(gè)字符比較,但是這個(gè)過(guò)程是可以省略的,因?yàn)槲覀兺ㄟ^(guò)觀察關(guān)鍵字串可以發(fā)現(xiàn)關(guān)鍵字串的前兩個(gè)字符是不相等的,而上一輪比較過(guò)程中,關(guān)鍵字串的第二個(gè)字符與內(nèi)容串的第二個(gè)字符是想等的,因此可以判斷關(guān)鍵字串的第一個(gè)字符與內(nèi)容串的第二個(gè)字符是不相等的。如果能在比較過(guò)程中避免這些重復(fù)比較,匹配效率也將得到很大的提高,KMP算法則正好避免了上面BF算法的不足。
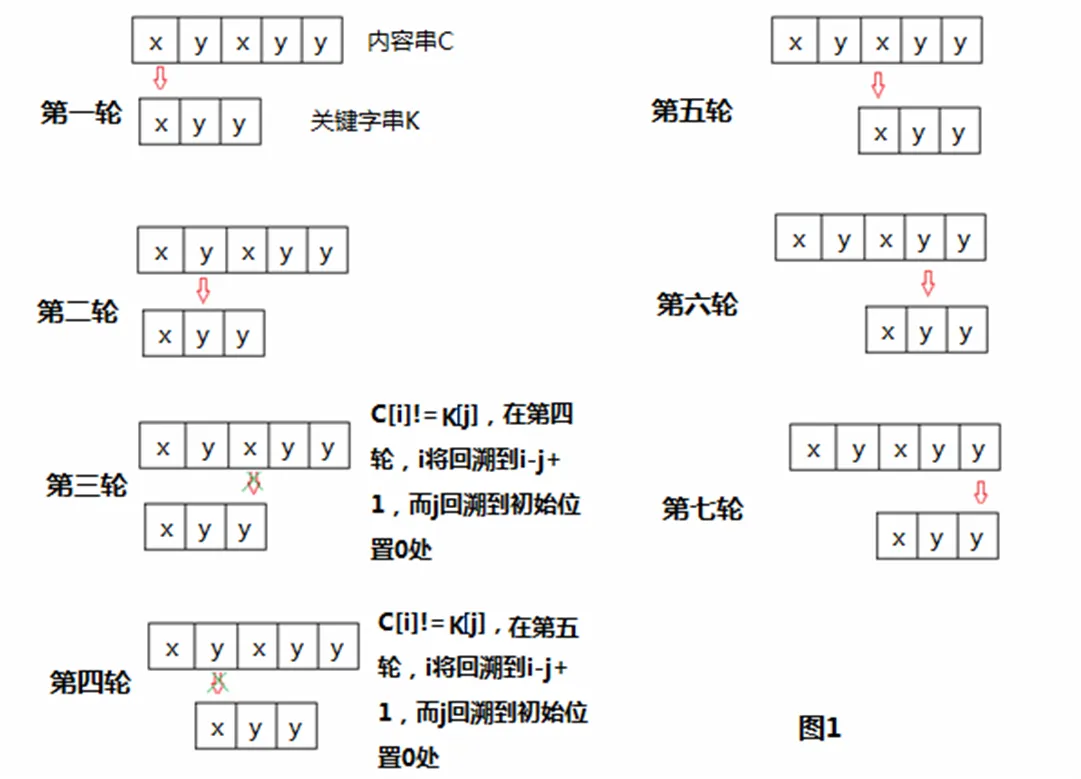
圖1 匹配過(guò)程
2 KMP模式匹配算法
2.1 算法前瞻
KMP算法之所以高效,在于其在匹配失敗以后,不需要再對(duì)目標(biāo)字符序列從頭匹配,這樣就減少了匹配的次數(shù),提高效率。算法實(shí)現(xiàn)的核心就是基于一個(gè)move數(shù)組,move數(shù)組存儲(chǔ)了關(guān)鍵字串的特征信息。
下面圖2我們舉一個(gè)例子,從中體會(huì)一下KMP算法的思想并且與BF算法做一下比較,就能找出KMP算法的高效所在,假設(shè)有一個(gè)內(nèi)容串C和關(guān)鍵字串K ,C=” ababcabcacb”,K =”abcac”,當(dāng)比較到到第二個(gè)字符時(shí)出現(xiàn)失配,即C[2]!=K[2]。

圖2 例子
這時(shí)如果按照傳統(tǒng)的BF算法,則第二輪的比較應(yīng)該從內(nèi)容串的第一個(gè)字符與關(guān)鍵字串的第零個(gè)字符開(kāi)始,這種思想前面我們已經(jīng)知悉。KMP算法則會(huì)首先發(fā)現(xiàn)K串本身的一些特性,即最開(kāi)始的兩個(gè)字符是不相等,同時(shí)根據(jù)第一輪的比較發(fā)現(xiàn):C[0] = K[0],C[1] = K[1]。因此可以立即得出結(jié)論C[1] != K[0],所以可以省略它們的比較,直接從C第二個(gè)字符與K第零個(gè)字符進(jìn)行比較開(kāi)始,如圖3:
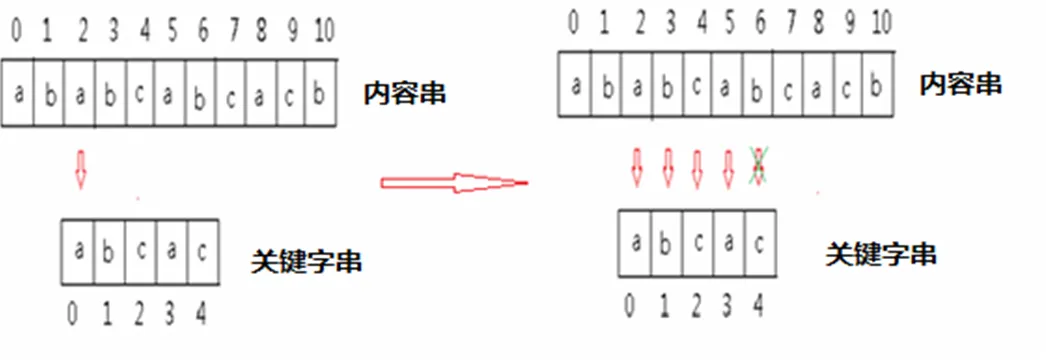
圖3 第二輪比較
從圖中可以看到,當(dāng)比較到C[6]和K[4]時(shí),再次出現(xiàn)失配情況。根據(jù)KMP思想只要從C[6]和K[1]開(kāi)始進(jìn)行比較即可。如圖4:

圖4 從C[6]和K[1]開(kāi)始進(jìn)行比較
可以看到整個(gè)過(guò)程中只發(fā)生了3次重新匹配,就得到了匹配成功的結(jié)論,加快了匹配的執(zhí)行速度。上面的例子只是大概描述了方法的思路,但是這種方法的本質(zhì)到底是什么,又如何才能精確的描述,最后到代碼的實(shí)現(xiàn),我們下面就來(lái)解決這些問(wèn)題。
2.2 KMP模式匹配算法思想
通過(guò)上面的例子分析,我們可以看到整個(gè)匹配過(guò)程中,失敗時(shí)只對(duì)關(guān)鍵字串K的初始比較位置回溯,而內(nèi)容串的比較位置一直是向后,沒(méi)有重復(fù)。
我們得到的結(jié)論是:KMP算法思想關(guān)鍵在于匹配失敗時(shí),我們能夠知道從關(guān)鍵字串的哪一個(gè)位置與內(nèi)容串在失配時(shí)的位置重新開(kāi)始比較,定位關(guān)鍵字串的重新比較位置就是整個(gè)算法思想的關(guān)鍵,而這些都與內(nèi)容串沒(méi)有干系。
KMP算法的關(guān)鍵是它的move數(shù)組,利用move數(shù)組能夠高效地確定在當(dāng)前失配的情況下,應(yīng)當(dāng)將關(guān)鍵字串移動(dòng)多少位才能夠避免不必要的匹配。KMP如何借助move數(shù)組移位,道理其實(shí)很簡(jiǎn)單,如果內(nèi)容串和關(guān)鍵字串的字符匹配,那么就同時(shí)移動(dòng)兩者的下標(biāo);如果不能匹配,關(guān)鍵字串就使用move數(shù)組來(lái)獲得移動(dòng)的數(shù)目。
2.3 求解move數(shù)組
move數(shù)組的含義:如果關(guān)鍵字串K與內(nèi)容串C匹配到了n個(gè)字符,這n個(gè)字符也就是關(guān)鍵字串K的前n個(gè)字符,我們對(duì)這個(gè)子串記為tmp做如下分析:
這個(gè)串tmp的前后是否有重復(fù)的內(nèi)容,哪怕是重復(fù)一個(gè)字符,當(dāng)然越多越好,我們也只記錄最多的重復(fù)情況,這個(gè)最多的長(zhǎng)度就是下次重新匹配時(shí)不需要再次匹配測(cè)試的長(zhǎng)度,同時(shí)也要記錄這兩個(gè)重復(fù)的部分之間的間隔距離,這個(gè)距離就是失配時(shí)關(guān)鍵字串K的回溯長(zhǎng)度。為提高效率,匹配長(zhǎng)度n就是move數(shù)組的下標(biāo)。我舉一個(gè)例子同時(shí)附一個(gè)表格來(lái)體會(huì)一下思想:
解析一下:
比如對(duì)于匹配到了2個(gè)字符,也就是K與C的前兩個(gè)字符都是ab,也即是K[0]=C[0], K[1]=C[1],但是K[2]!=C[2]失配,繼續(xù)比較時(shí),將K的指針回溯到K的頭部再偏移move[2]=0個(gè)長(zhǎng)度,這也應(yīng)該是K的最前部,而C不用回溯。
假設(shè)關(guān)鍵字串K = “abxabyz”,計(jì)算結(jié)果如表1:
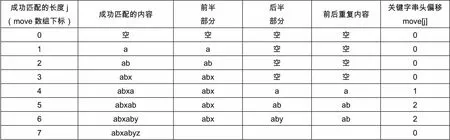
表1 計(jì)算結(jié)果
比如對(duì)于匹配到了5個(gè)字符,也就是K與C的前兩個(gè)字符都是abxab,也即是K[0]=C[0], K[1]=C[1]…K[4]=C[4]但是K[5]!=C[5]失配,繼續(xù)比較時(shí),將K的指針回溯到K的頭部再偏移move[5]=2個(gè)長(zhǎng)度,而C不用回溯,也就是用K中的K[2]=’x’字符與C[5]比較而不是K[0]與C[1]做比較。
2.4 求解move數(shù)組的算法實(shí)現(xiàn)
代碼其實(shí)并不復(fù)雜,整體思路是對(duì)于每一個(gè)關(guān)鍵字串與內(nèi)容串匹配到的長(zhǎng)度j,得到匹配的內(nèi)容tmp,然后將 tmp分拆為前后兩個(gè)部分,稱(chēng)為前綴和后綴,在前綴長(zhǎng)度不大于后綴長(zhǎng)度下,判斷前綴是否在后綴中重復(fù)出現(xiàn)。匹配長(zhǎng)度作為move數(shù)組的下標(biāo),前綴在后綴中能夠找到重復(fù)時(shí)的最大長(zhǎng)度值存放在move[j]中。move數(shù)組的初始值都是0,意思是關(guān)鍵字串默認(rèn)都回到頭部并且沒(méi)有偏移。

圖5 求解move數(shù)組的算法實(shí)現(xiàn)
3 算法在項(xiàng)目中的實(shí)現(xiàn)與應(yīng)用
3.1 KMP模式匹配算法實(shí)現(xiàn)
函數(shù)的功能是基于KMP思想,在內(nèi)容串中找出所有的關(guān)鍵字串的位置。簡(jiǎn)單的解釋一下:matchlen是匹配長(zhǎng)度的計(jì)數(shù)器,每次字符比較成功就+1(37行),當(dāng)完全匹配時(shí)(38行),matchlen置0(43行),重新開(kāi)始計(jì)數(shù)。當(dāng)出現(xiàn)失配情況時(shí)(50行),如果已經(jīng)匹配的長(zhǎng)度是0,也就是第一個(gè)字符就不匹配,就要后移內(nèi)容串指針(52行)。move[matchlen] (53行)中的matchlen表示已經(jīng)成功匹配了多少個(gè)字符,move[matchlen]則表示在成功匹配了matchlen個(gè)字符的情況下,前綴中有多少個(gè)字符在后綴中重復(fù)出現(xiàn),所以下一次重新比較時(shí),關(guān)鍵字串要定位到頭部再偏移move[matchlen]個(gè)長(zhǎng)度(54行)。跳過(guò)的長(zhǎng)度move[matchlen]雖然是不用重復(fù)比較的長(zhǎng)度,但是還是要算匹配長(zhǎng)度的,所以有53行的賦值。
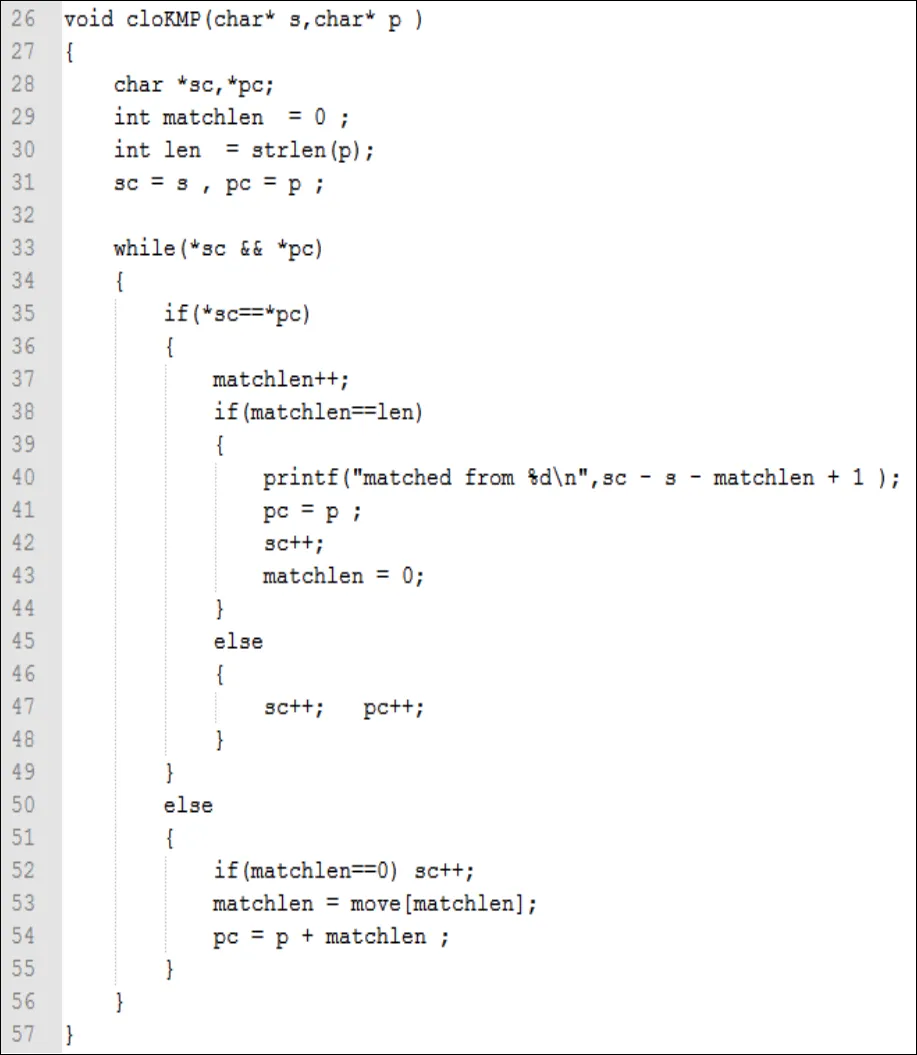
圖6 KMP模式匹配算法實(shí)現(xiàn)
3.2 KMP算法應(yīng)用
代碼很簡(jiǎn)單(圖7),看一下執(zhí)行結(jié)果(圖8):

圖7 代碼

圖8 執(zhí)行結(jié)果
4 結(jié)束語(yǔ)
本文從BF算法講起,隨后闡述KMP的算法思想以及優(yōu)勢(shì)、move 數(shù)組的簡(jiǎn)單求解以及KMP算法在項(xiàng)目中的實(shí)現(xiàn)。通過(guò)分析BF算法和KMP算法并通過(guò)實(shí)驗(yàn)證明在字符集較大的情況下,KMP算法在運(yùn)行比較次數(shù)和運(yùn)行時(shí)間上都優(yōu)于BF算法。綜上所述,KMP算法提高了匹配效率,具有廣闊的應(yīng)用前景。
通過(guò)上述對(duì)算法的分析,以及對(duì)不同算法的實(shí)現(xiàn)的運(yùn)行效率比較,為我們更清楚的分析算法的優(yōu)劣,去選擇對(duì)自己更實(shí)用的算法,提供了可遵循的方式方法,并廣泛應(yīng)用到自己的學(xué)習(xí)工作中。
[1] KMP算法詳細(xì)講解: https://blog.csdn.net/suguoliang/article/details/77460455
[2] KMP算法Move數(shù)組計(jì)算: https://blog.csdn.net/xiao xian8023/ article/details/8134292
猜你喜歡
科學(xué)大眾(2022年11期)2022-06-21 09:20:52
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2022年5期)2022-06-05 07:51:50
華人時(shí)刊(2022年7期)2022-06-05 07:33:26
科學(xué)大眾(2021年21期)2022-01-18 05:53:48
科學(xué)大眾(2021年17期)2021-10-14 08:34:02
當(dāng)代陜西(2021年13期)2021-08-06 09:24:34
人大建設(shè)(2019年4期)2019-07-13 05:43:08
當(dāng)代陜西(2019年12期)2019-07-12 09:11:50
臺(tái)聲(2016年2期)2016-09-16 01:06:53
軍事歷史(1984年2期)1984-08-21 06:27:08
