基于CNN模型的遙感圖像復(fù)雜場景分類
2018-12-20 11:03:48張康黑保琴李盛陽邵雨陽
自然資源遙感 2018年4期
張康, 黑保琴, 李盛陽, 邵雨陽
(1.中國科學(xué)院空間應(yīng)用工程與技術(shù)中心,北京 100094;2.中國科學(xué)院太空應(yīng)用重點實驗室,北京 100094;3.中國科學(xué)院大學(xué),北京 100049)
0 引言
隨著對地觀測技術(shù)的迅速發(fā)展,遙感圖像的數(shù)據(jù)量顯著增加,大量堆積的遙感圖像中所蘊含的有價值信息亟待充分挖掘和利用。遙感圖像的復(fù)雜場景識別和分類是提取并分析這些信息的重要內(nèi)容之一,它能夠廣泛應(yīng)用于土地利用[1]、全球環(huán)境污染監(jiān)測[2]和軍事領(lǐng)域目標(biāo)檢測[3]等方面,具有重要的理論意義和實踐價值[4]。傳統(tǒng)的遙感圖像場景分類方法,例如貝葉斯模型和k-均值[5]等方法,都有一定的應(yīng)用限制,通常要求樣本足夠大并且樣本數(shù)據(jù)服從正態(tài)分布,才能得到較為理想的分類結(jié)果[6]。此外,雖然之后的支持向量機(support vector machine,SVM)方法在遙感圖像識別與分類任務(wù)中取得了較優(yōu)的效果[7-8],但其本質(zhì)上屬于淺層的結(jié)構(gòu)模型,計算單元有限,難以有效地表達(dá)復(fù)雜函數(shù),對于復(fù)雜的分類問題其泛化能力仍不足[9-10]。
為了克服淺層學(xué)習(xí)模型以及人工提取特征所帶來的問題,Hinton等[11]于2006年提出了深度學(xué)習(xí)的概念。以卷積神經(jīng)網(wǎng)絡(luò)(convolutional neural net-work,CNN)為代表的深度學(xué)習(xí)方法,主要是用于識別二維形狀而特別設(shè)計的一種多層感知器。CNN模型的卷積層可以實現(xiàn)自動化的圖像特征提取,從而避免過多的人為干涉,同時其局部連接、權(quán)值共享等技術(shù)能夠有效地減少網(wǎng)絡(luò)參數(shù),從而降低網(wǎng)絡(luò)模型的計算量并提升模型的泛化能力[9]。目前,利用CNN模型在遙感圖像領(lǐng)域已經(jīng)取得了一定的研究成果,例如行人檢測[12]、火災(zāi)識別[13]、船艦檢測[14]等領(lǐng)域,但是對于遙感圖像的復(fù)雜場景分類應(yīng)用仍然較少。本文提出了一種基于CNN模型的遙感圖像復(fù)雜場景分類方法,并在UC Merced Land Use和Google of SIRI-WHU這2組數(shù)據(jù)集中進(jìn)行實驗。由于上述2組通用數(shù)據(jù)集的樣本量不是很大,為了提高小樣本數(shù)據(jù)下的分類精度,本文采用對CNN中典型的AlexNet[15]模型進(jìn)行預(yù)訓(xùn)練的方法來提取多尺度圖像特征;為了使模型適應(yīng)不同大小的遙感圖像,模型前增加了預(yù)處理模塊,該模塊通過改變步長和隨機裁剪尺寸的方式來獲取最大圖像輸入,從而保證了濾波器的不變性,有利于特征提取;為了橫向比較分類器的選擇問題,在模型中采用了Softmax和SVM這2種分類器。
1 遙感圖像復(fù)雜場景分類的CNN模型
遙感圖像場景分類的核心在于圖像特征的有效提取。相比于傳統(tǒng)的特征提取方法(例如局部二值模式、尺度不變特征變換、梯度方向直方圖和Gabor濾波器等方法),CNN具有旋轉(zhuǎn)、平移、縮放不變性,并能夠提取更加豐富的高層特征信息,充分地降低圖像低層視覺特征與高層語義之間的“鴻溝”[16]。
基于CNN模型的遙感圖像復(fù)雜場景分類的總體流程如圖1所示。

圖1 基于CNN模型的遙感圖像場景分類總體流程
本文構(gòu)建了一個用于遙感圖像復(fù)雜場景分類的CNN模型框架,如圖2所示。該框架包括5個卷積層(C1—C5),3個池化層(S1—S3),以及一個由全連接層fc6,fc7和Softmax組成的神經(jīng)網(wǎng)絡(luò)。其中采用ReLu(rectified linear units)函數(shù)作為神經(jīng)元的激活函數(shù),以解決使用傳統(tǒng)的Sigmoid及Tanh等激活函數(shù)易出現(xiàn)梯度彌散等問題。
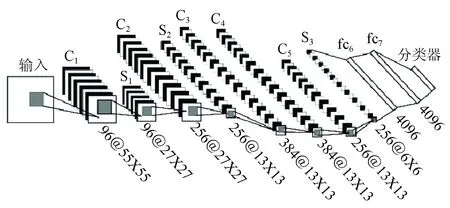
圖2 遙感圖像場景分類的CNN框架
圖2中的Ci層為卷積層,相當(dāng)于一個濾波器,該層的輸入特征與卷積核進(jìn)行卷積操作,然后通過一個激活函數(shù)就可以計算出輸出特征。卷積層的計算公式為
(1)
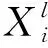
Si層為池化層,又稱下采樣層,主要用于將特征映射為一個平面。如公式(2)所示,它對公式(1)的計算結(jié)果進(jìn)行下采樣操作,并且加上權(quán)重和偏置項,最后通過激活函數(shù)獲得了一個縮小的特征映射圖,該操作能夠減少網(wǎng)絡(luò)模型參數(shù),從而降低網(wǎng)絡(luò)復(fù)雜性,提高網(wǎng)絡(luò)的泛化能力,即
(2)
然后將最后一個特征圖(S3)進(jìn)行光柵化操作,即將一系列的特征圖像轉(zhuǎn)換為神經(jīng)網(wǎng)絡(luò)所能接收的向量形式。fc6,fc7和Softmax是一個全連接的神經(jīng)網(wǎng)絡(luò),主要是充當(dāng)分類器的角色,用于對特征進(jìn)行分類。
將CNN模型應(yīng)用于UC Merced Land Use圖像數(shù)據(jù)集和Google of SIRI-WHU圖像數(shù)據(jù)集的具體過程如下:首先第一個卷積層使用96個11×11大小的卷積核對227×227的UC Merced Land Use圖像數(shù)據(jù)集的場景圖像進(jìn)行步長為4的濾波操作,而對173×173的Google of SIRI-WHU圖像數(shù)據(jù)集的場景圖像進(jìn)行步長為3的濾波操作,均生成96個55×55(計算過程:(227-11)/4+1=55和(173-11)/3+1=55)的特征圖;然后對生成的特征圖進(jìn)行核大小為3、步長為2的Max-Pooling操作,產(chǎn)生96個27×27(計算過程:(55-3)/2+1=27)的特征圖。第二個卷積層使用256個5×5的卷積核對27×27的特征圖進(jìn)行零填充大小為2、步長為1的濾波操作,產(chǎn)生256個27×27(計算過程:27+2×2-5+1=27)的特征圖;然后對生成的特征圖進(jìn)行核大小為3、步長為2的Max-Pooling操作,產(chǎn)生256個13×13(計算過程:(27-3)/2+1=13)的特征圖。第三個和第四個卷積層均使用384個3×3的卷積核對13×13的特征圖進(jìn)行零填充大小為1、步長為1的濾波操作,產(chǎn)生384個13×13(計算過程:13+2×1-3+1=13)的特征圖。第五個卷積層使用256個3×3的卷積核對13×13的特征圖進(jìn)行零填充大小為1、步長為1的濾波操作,產(chǎn)生256個13×13(計算過程:13+2×1-3+1=13)的特征圖;然后對生成的特征圖進(jìn)行核大小為3、步長為2的Max-Pooling操作,產(chǎn)生256個6×6(計算過程:(13-3)/2+1=6)的特征圖。經(jīng)過第一個全連接層,產(chǎn)生4 096個神經(jīng)元,再將經(jīng)過ReLu激活函數(shù)產(chǎn)生的神經(jīng)元作為第二個全連接層的輸入;第二個全連接層也產(chǎn)生4 096個神經(jīng)元,同樣將ReLu激活函數(shù)產(chǎn)生的神經(jīng)元作為Softmax層的輸入,對于UC Merced Land Use圖像數(shù)據(jù)集,最終的輸出結(jié)果即為21類的概率結(jié)果,對于Google of SIRI-WHU圖像數(shù)據(jù)集的輸出結(jié)果為12類的概率結(jié)果。
由于CNN訓(xùn)練需要大量的帶有標(biāo)簽的樣本數(shù)據(jù),而實際中獲取如此龐大的遙感圖像場景分類的樣本數(shù)據(jù)較為困難,成本也很高。因此,采用遷移學(xué)習(xí)[17]的方法,將目前世界上最大的圖像識別數(shù)據(jù)庫ImageNet[15]學(xué)習(xí)到的權(quán)重作為框架的初始權(quán)重,而不是隨機確定初始化權(quán)重從頭開始訓(xùn)練。該方法能有效地解決小樣本數(shù)據(jù)訓(xùn)練模型易產(chǎn)生的過擬合問題,同時能夠大大縮減模型訓(xùn)練的時間。CNN模型的訓(xùn)練和分類過程如圖3所示。
圖3 基于CNN的遙感圖像場景分類方法
訓(xùn)練過程中,首先將帶標(biāo)簽數(shù)據(jù)隨機分為2類,作為測試數(shù)據(jù)集和訓(xùn)練數(shù)據(jù)集,訓(xùn)練數(shù)據(jù)集輸入CNN模型后,經(jīng)過前向傳播(feed forward, FF)得到模型輸出,再計算模型輸出和實際數(shù)據(jù)標(biāo)簽的誤差,根據(jù)誤差求導(dǎo)計算梯度,通過反向傳播(back propagation, BP)更新網(wǎng)絡(luò),如此往復(fù)便可訓(xùn)練出優(yōu)化的CNN模型。在對模型訓(xùn)練的過程中,引入了鏡像和隨機裁剪方法(通過對每個圖像進(jìn)行旋轉(zhuǎn),然后隨機選取位置裁剪n×n大小作為新的圖像數(shù)據(jù))來增加樣本數(shù)據(jù)量,以避免過擬合現(xiàn)象。此外,在全連接層采用“dropout”技術(shù)隨機使隱含層的某些節(jié)點的權(quán)重不工作,也能有效地防止過擬合,同時很大程度地降低模型的訓(xùn)練時間。在對測試數(shù)據(jù)集進(jìn)行分類的過程中,使用基于CNN模型進(jìn)行遙感圖像復(fù)雜場景分類的2種策略:①使用Softmax分類器直接對測試集數(shù)據(jù)進(jìn)行分類;②將Softmax替換為采用基于經(jīng)典核函數(shù)徑向基函數(shù)(radial basis function,RBF)的SVM分類器,然后使用SVM分類器對CNN模型fc7層的特征進(jìn)行分類,從而代替CNN模型的輸出層。
2 遙感圖像場景分類實驗
2.1 實驗數(shù)據(jù)集的選取和處理
為了驗證CNN模型分類方法的有效性,選用2組數(shù)據(jù)集進(jìn)行實驗,分別是包含21類場景的UC Merced Land Use圖像數(shù)據(jù)集[18]和包含了12類場景的Google of SIRI-WHU圖像數(shù)據(jù)集[19],如圖4和圖5所示。UC Merced Land Use數(shù)據(jù)集通過從美國地質(zhì)調(diào)查局的國家地圖城市圖像中手工獲取。該數(shù)據(jù)集的每類場景包含100幅256像素×256像素的圖像,圖像的空間分辨率為0.3 m;Google of SIRI-WHU數(shù)據(jù)集從Google Earth獲取,主要覆蓋中國的城市地區(qū),由武漢大學(xué)的RS_IDEA團(tuán)隊設(shè)計建成。該數(shù)據(jù)集的每類場景包含200幅200像素×200像素的圖像,圖像的空間分辨率為2 m。在本文的2類實驗中,每類場景隨機選取80%的圖像作為訓(xùn)練數(shù)據(jù)集,剩余的圖像作為測試數(shù)據(jù)集。

圖5 Google of SIRI-WHU遙感圖像數(shù)據(jù)集
對于本文所使用的網(wǎng)絡(luò)模型來說,在圖像輸入前需要增加預(yù)處理模塊,以適應(yīng)不同的圖像大小。首先設(shè)置模型中第一層的濾波器大小為11×11,卷積特征圖C1大小為55。為了使模型在具有通用性的同時有利于特征提取,需要保證濾波器和特征圖C1的大小不變。因此對于輸入大小為a像素×a像素的圖像,預(yù)處理模塊要使步長x和圖像隨機裁剪大小y滿足關(guān)系式y(tǒng)=54x+11(其中y為不大于a的最大值,從而盡可能保留更多圖像信息)。所以第一個數(shù)據(jù)集UC Merced Land Use的圖像大小為256像素×256像素,經(jīng)過預(yù)處理模塊后的輸入為227像素×227像素的隨機裁剪圖像和步長值為4。Google of SIRI-WHU數(shù)據(jù)集的圖像大小為200像素×200像素,經(jīng)過預(yù)處理模塊后的輸入為173像素×173像素的隨機裁剪圖像和步長值為3。
然后設(shè)置2個數(shù)據(jù)集的訓(xùn)練參數(shù)如下:①UC Merced Land Use訓(xùn)練和測試數(shù)據(jù)集的批量處理大小分別為56和42,測試集迭代次數(shù)為10次(測試集數(shù)據(jù)量420/42),完整訓(xùn)練一次需要迭代30次(1 680/56),因此設(shè)置每迭代30次測試一次;②Google of SIRI-WHU訓(xùn)練和測試數(shù)據(jù)集的批量處理大小分別為64和48,測試集迭代次數(shù)為10次(測試集數(shù)據(jù)量480/48),完整訓(xùn)練一次需要迭代30次(1 920/64),因此仍然設(shè)置每迭代30次測試一次。
2.2 實驗結(jié)果與分析
2組數(shù)據(jù)集的分類結(jié)果如圖6所示。
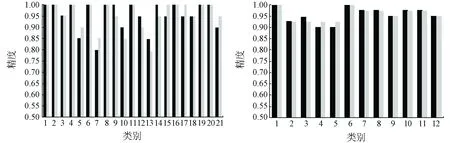
(a) UC Merced Land Use數(shù)據(jù)集的分類結(jié)果 (b) Google of SIRI-WHU數(shù)據(jù)集的分類結(jié)果
本文采用CNN+Softmax算法和CNN+SVM算法對UC Merced Land Use和Google of SIRI-WHU2個數(shù)據(jù)集的遙感圖像場景分類的混淆矩陣如圖7所示。由圖7可以得出以下結(jié)論:整體而言,如圖6所示,Google of SIRI-WHU數(shù)據(jù)集的分類結(jié)果要優(yōu)于UC Merced Land Use數(shù)據(jù)集。在Google of SIRI-WHU數(shù)據(jù)集中所有類別的分類精度都達(dá)到了90%以上,圖7(c)和(d)中也可以看出2種算法對Google of SIRI-WHU數(shù)據(jù)集分類的各個類別之間的錯分率不超過5%;而UC Merced Land Use數(shù)據(jù)集中的建筑(類別5)、稠密住宅區(qū)(類別7)、高爾夫球場(類別10)和中等住宅區(qū)(類別13)等場景的分類精度較差,只能達(dá)到80%左右。這主要是因為不同類間的相似性較大(例如UC Merced Land Use數(shù)據(jù)集中的建筑(buildings)、稠密住宅區(qū)(dense residential)和中等住宅區(qū)(medium residential)場景,如圖8(a)所示),或者相同類之間的差異性大(例如高爾夫球場(golf course),如圖8(b)所示)。這一問題根據(jù)圖7(a)和(b)的混淆矩陣也可以看出。不論是Softmax還是SVM分類器,都能取得很好的分類效果。例如在第一個數(shù)據(jù)集中的中等住宅區(qū)類,使用CNN分類精度為85%,而使用CNN+SVM的分類精度為70%;然而在建筑類中,使用CNN的分類精度為85%,而使用CNN+SVM的分類精度為90%;在第二個數(shù)據(jù)集中,CNN和CNN+SVM的方法對每類的分類精度基本相差不大。因此,Softmax和SVM分類器沒有明顯優(yōu)劣之分,可以根據(jù)需求針對具體類別選擇合適的分類器。盡管2組數(shù)據(jù)集的分類結(jié)果有所不同,同一數(shù)據(jù)集下不同類別的分類結(jié)果也有差別,但總體而言,分類精度還是較高的,基本能保持在90%以上。
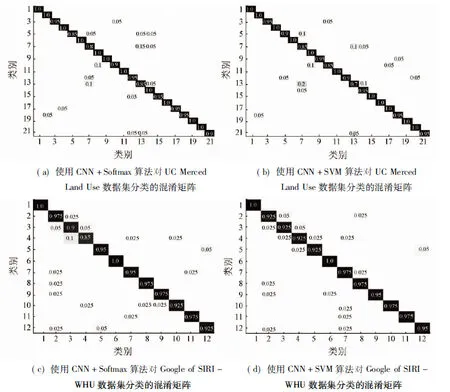
圖7 基于CNN模型的遙感圖像場景分類的混淆矩陣

(a) 不同類間的相似性

(b) 相同類間的差異性
為了更好地比較本文提出方法的優(yōu)勢,針對于UC Merced Land Use數(shù)據(jù)集和Google of SIRI-WHU數(shù)據(jù)集,表1和表2列出了現(xiàn)有的幾種其他方法的分類效果。
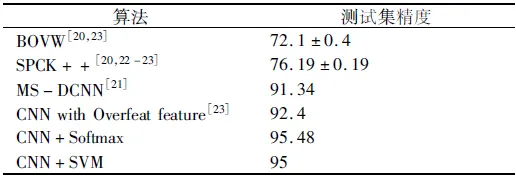
表1 不同算法UC Merced Land Use數(shù)據(jù)集的分類精度
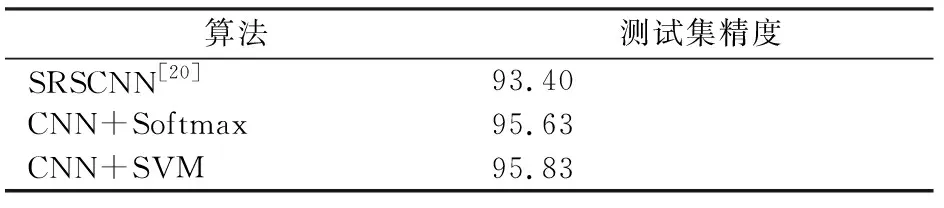
表2 不同算法Google of SIRI-WHU數(shù)據(jù)集的分類精度
從表1與表2中可以進(jìn)一步得到以下結(jié)論:
1)利用本文提出的方法對UC Merced Land Use數(shù)據(jù)集進(jìn)行分類,Softmax和SVM這2種分類器下的分類精度分別高達(dá)95.48%和95%,相比于現(xiàn)有的最優(yōu)方法,精度分別提升了3.08%和2.6%;而對Google of SIRI-WHU數(shù)據(jù)集進(jìn)行分類的精度也分別高達(dá)95.63%和95.83%,相比于現(xiàn)有的最優(yōu)方法,分類精度分別提升了2.23%和2.43%,從而說明本文所提出的方法是十分有效的。
2)結(jié)合圖6的各類別分類結(jié)果可以看出,Softmax和SVM分類器都能得到很好的分類結(jié)果,因此在使用CNN模型對遙感圖像的場景分類中,可以根據(jù)自己需要是否使用SVM替換CNN的Softmax層。
上述分析說明了本文采用的CNN方法的有效性,而圖9則展示了2組數(shù)據(jù)集中訓(xùn)練數(shù)據(jù)集的損失函數(shù)變化曲線和測試數(shù)據(jù)集的精度變化曲線,其中訓(xùn)練數(shù)據(jù)集的損失函數(shù)變化曲線能夠反映出模型的輸出結(jié)果與實際結(jié)果的誤差,因此損失函數(shù)越小,說明該模型被訓(xùn)練得越好;測試數(shù)據(jù)集的精度變化曲線能夠反映模型泛化能力的好壞,因此,測試數(shù)據(jù)集精度越高,說明該模型的泛化能力越好。
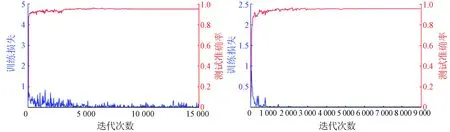
(a) UC Merced Land Use數(shù)據(jù)集 (b) Google of SIRI-WHU數(shù)據(jù)集
從圖9中可以看出,UC Merced Land Use數(shù)據(jù)集通過約7 000次迭代后,數(shù)據(jù)分類精度趨于穩(wěn)定,并保持在95%以上,而數(shù)據(jù)集的損失函數(shù)也降低至0.005左右,并保持穩(wěn)定;Google of SIRI-WHU數(shù)據(jù)集通過約5 000次迭代后,數(shù)據(jù)分類精度趨于穩(wěn)定,并保持在95%以上,同時數(shù)據(jù)集的損失函數(shù)也降低至0.000 1左右,并保持穩(wěn)定。然而,第一組訓(xùn)練數(shù)據(jù)集的損失函數(shù)比第二組的值大,正如圖8所描述的原因,第一組數(shù)據(jù)集中存在類間相似性大以及類內(nèi)差異性大的數(shù)據(jù)。即使如此,2組測試數(shù)據(jù)集的精度都能取得很好的效果,由此可見使用遷移學(xué)習(xí)的方法在提高時間效率上也具有明顯的優(yōu)勢,能有效地降低訓(xùn)練成本,同時仍然保持很好的分類效果。
3 結(jié)論
本文提出了一種基于CNN的遙感圖像場景分類方法。通過從ImageNet數(shù)據(jù)集中遷移知識,利用CNN來訓(xùn)練自己的數(shù)據(jù)集,解決了小樣本訓(xùn)練的問題,同時提高了時間效率;通過增加預(yù)處理模塊,提升了模型的適應(yīng)能力;最后以UC Merced Land Use數(shù)據(jù)集和Google of SIRI-WHU數(shù)據(jù)集的實驗驗證了該方法的有效性。實驗結(jié)果與現(xiàn)有方法的比較表明,本文方法能夠有效地提高遙感圖像場景分類的精度。此外,還比較了該模型分別選擇Softmax和SVM這2種分類器時的分類精度。2種分類器均能取得很好的分類結(jié)果,精度都達(dá)到95%以上。因此在使用該CNN模型進(jìn)行遙感圖像的場景分類時,可以選擇SVM或Softmax分類器。在后繼研究中,可以利用高光譜遙感圖像,通過引入更多的光譜信息來替代目前的RGB三通道輸入,從而實現(xiàn)對目標(biāo)更加準(zhǔn)確的識別與分類。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學(xué)小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
