基于SVM模型的油井工況智能診斷分析系統
2018-12-21 12:14:26王紹平李永平李廣輝劉繼紅向東奎
石油知識 2018年6期
王紹平 李永平 李廣輝 劉繼紅 向東奎
(長慶油田分公司第二采油廠 甘肅慶陽 745100)
0 引言
長慶油田第二采油廠管理著馬嶺、華池、城壕、西峰等11個油田,近年來隨著開發規模的擴大,油水井的井數日漸增多。在人工智能、大數據及物聯網等新興技術發展的今天,借助智能傳感器、知識庫管理及數據互聯等手段,通過計算機代替人工分析降低人工成本、提高管理效率已成為流行解決方案之一。
1 油水井工況系統應用現狀及存在問題
第二采油廠數字化建設從2003年開始,經歷西峰油田先導性試驗、老油田數字化升級改造、功能拓展深化應用三個階段,單井數字化裝配配套已趨于完善:油井已經實現了功圖遙測、功圖計量、電參數控制等功能,水井已經實現了穩流配水、壓力、流量參數遠程監控,同時建立了油水井工況系統,對參數進行遠程監控和分析,用于輔助油水井管理,取得了良好的應用效果。但隨著近年來油田生產行業發展和變化,在用系統無法完全滿足目前及未來的生產需求,主要體現在三個方面:一是現有系統智能化程度不高,無法代替人工分析降低人工成本;二是現有系統未建立油水井閉環管理流程,不能滿足精細化管理需求;三是現有系統使用的技術老舊,系統性能無法滿足現有生產規模。
2 油水井智能診斷優化系統設計
基于解決以上問題的目的,2017年第二采油廠設計了油水井智能診斷優化系統,該系統在當前數字化前端設備基礎上適當增加新傳感設備,通過建立完善各類單井問題診斷模型庫、知識庫,系統參與到單井的診斷、預警、措施制定、生產預測、優化等各個環節。通過建立問題消息推送機制,實現問題井的定人、定責與限期處理,并對實施情況進行跟蹤監控、統計分析,最終將單井的人工管理情況、單井治理效果反饋至知識庫,為后期單井管理提供參考,形成問題井閉環管理。
3 油水井智能診斷優化系統框架
為滿足油水井的日常管理需求,系統共分7個模塊進行設計(圖1),每個模塊的主要功能如下:
(1)智能診斷:應用系統診斷算法模型、知識庫,對單井生產數據、實時數據進行油水井智能診斷(目前診斷間隔設定為30min),同時對診斷問題報警并提供處置措施建議。
(2)預警報警:分層級統計單井問題報警、預警信息及處理情況。根據單井所屬組織架構、區塊層系、預報警時間等條件分類匯總,并以數據表格、GIS方式展示。
(3)措施跟蹤:對預報警問題的處置措施進行分類匯總統計,提供措施變更、審核、發布功能。借助智能調度系統對措施分發、進度跟蹤,在統計分析模塊進行效果評價。形成措施安排→跟蹤反饋→效果評價的閉環管理。
(4)預測優化:分析單井歷史生產數據規律,結合預測優化算法對單井周期性問題進行預測。
(5)統計分析:統計系統相關數據,并分析得出直觀指標,便于用戶應用考核及系統后期持續優化內容做參考。
(6)知識庫:管理系統的算法模型及知識模型,并為系統的診斷提供依據。重點包括功圖特征庫、診斷算法庫及措施處置庫。
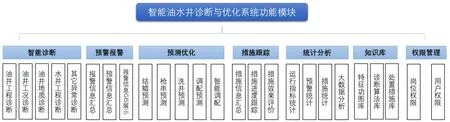
圖1 油水井智能診斷優化系統功能模塊設計
(7)用戶管理:通過崗位管理實現系統模塊、操作、審核權限按崗位配置,系統將根據員工所在崗位自動分配訪問權限。
4 油水井智能診斷優化系統應用技術
系統通過建立專家診斷經驗知識庫、故障樣本特征庫,對油水井常見故障建模,采用模型匹配、決策樹等技術實現油水井故障智能診斷。
4.1 專家診斷經驗知識庫
按照油水井故障類別,從工程、工況、地質三個方面建立故障診斷知識庫[1]。系統設計了知識庫管理模塊,方便對專家診斷知識進行維護和更新。知識庫內容建設由系統開發人員與工藝所、地質所專家組成專家算法項目組。針對每一項油水井單井故障,歸納整理單井參數變化特征、確定故障判定參數經驗值和算法,作為程序診斷的邏輯條件和參數。
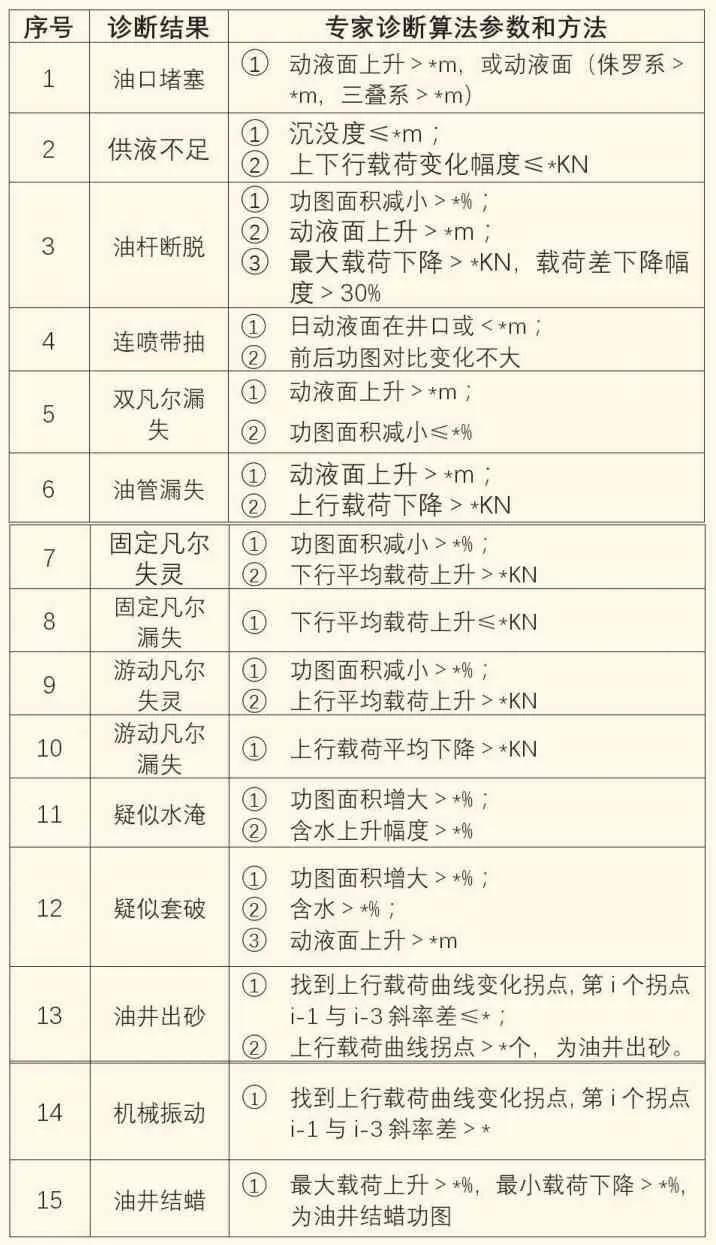
表1 專家診斷算法示例
比如油井工況故障診斷知識庫,通過與工況分析技術專家深入對接,針對易混淆的示功圖工況類別,制定15種專家診斷算法(表1),其中的算法參數都是專家經驗參數,不同油田和不同區塊的參數都需要根據實際情況進行設定。
4.2 故障工況SVM模型庫
本系統中示功圖底層采用SVM圖形識別。首先搜集歷史故障樣本工況,提取樣本圖形特征建立SVM模型庫。本系統采取HOG+SVM方法進行特征提取、訓練和檢測,利用OpenCV[2]開源計算機視覺庫實現。具體算法流程有以下三個方面。
4.2.1 HOG特征提取
HOG特征[3]的核心思想是利用物體的像素梯度以及邊緣方向分布來描述該物體的appearance 和shape。具體提取步驟為:①提取故障示功圖并歸一化處理為灰度圖像;②計算每個像素梯度的大小和方向;將圖像劃分成小cells;③統計每個cell的梯度直方圖;④將2x2cell或者3x3cell或者更多組成一個block,一個block內所有cell的特征descriptor串聯起來便得到該block的HOG特征descriptor。再將圖像內的所有block的HOG特征descriptor串聯起來就可以得到該圖像的HOG特征descriptor。
在OpenCV框架中,HOG特征提取方法已經封裝在HOGDescriptor類庫中,首先創建HOGDescriptor類實例,指定winSize、blockSize、blockStride、cellSize、nbins如下圖:

圖2 OpenCV中HOGDescriptor 類構造參數
然后調用HOGDescriptor.compute(src,descriptors,Size(8,8))方法,即可計算源圖像src的描述子,步長設定為(8,8)。
4.2.2 SVM分類訓練學習
SVM模型[4]是一種二類分類模型,其基本模型定義為特征空間上的間隔最大的線性分類器,其學習策略便是間隔最大化,最終可轉化為一個凸二次規劃問題的求解。
在OpenCV中,可以通過CvSVM類來進行分類訓練:①設置訓練樣本集。準備兩組數據,一組是故障的類別,一組故障的HOG特征向量信息。②設置SVM參數。利用CvSVMParams類實現類內的成員變量進行設置,其中Cvalue為損失函數。③訓練SVM。調用CvSVM::train函數建立SVM模型,調用函數CvSVM::predict實現分類。最后將訓練好的SVM模型保存為xml文件(圖3),使用時加載模型數據進行檢測即可實現示功圖故障自動識別(圖4)。
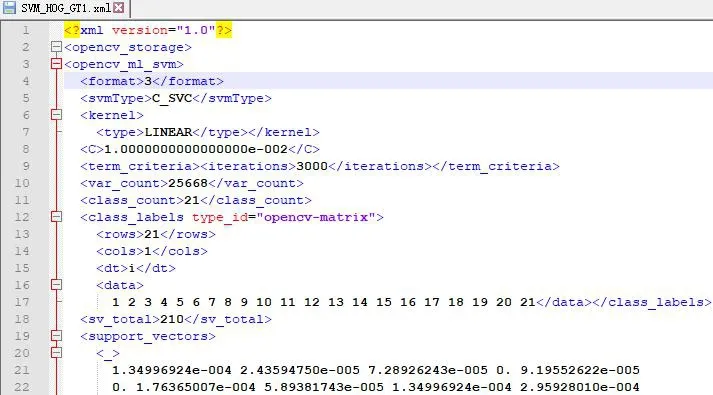
圖3 故障樣本SVM分類模型數據
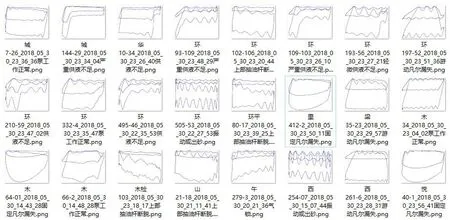
圖4 SVM模型故障檢測結果
4.3 智能診斷算法模型
在實際生產應用中,油水井的工況非常復雜,依靠單一診斷算法無法準確得到診斷結果(表2)。本系統通過組合多種診斷算法建立診斷算法模型來提高診斷準確率。例如系統的工況診斷算法模型就是由圖形SVM模型識別、專家診斷經驗知識庫、功圖關鍵參數趨勢分析[5]及特殊工況診斷算法4種診斷算法構成(圖5)。

圖5 工況診斷算法模型
算法模型建立之后,還需要根據故障類別特征、各種算法的特性建立診斷決策樹,來提高診斷速度及準確度(表2)。
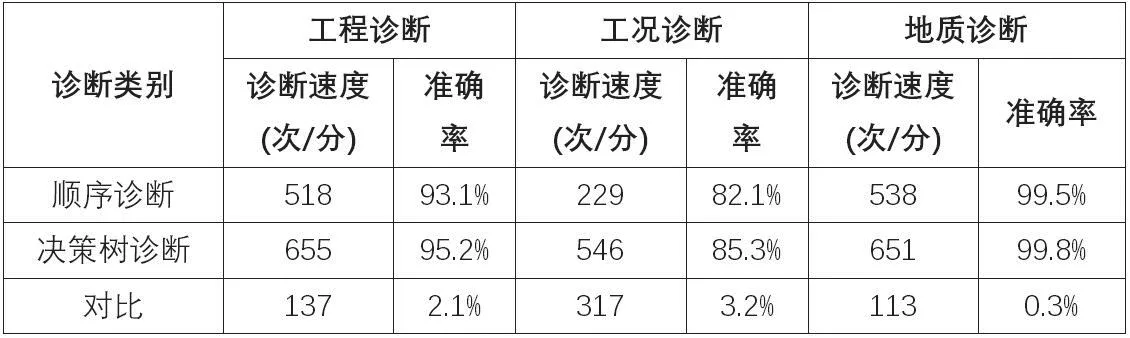
表2 應用診斷決策樹提高診斷速度與精度
下圖為斷脫類工況圖形故障診斷決策樹(圖6)。
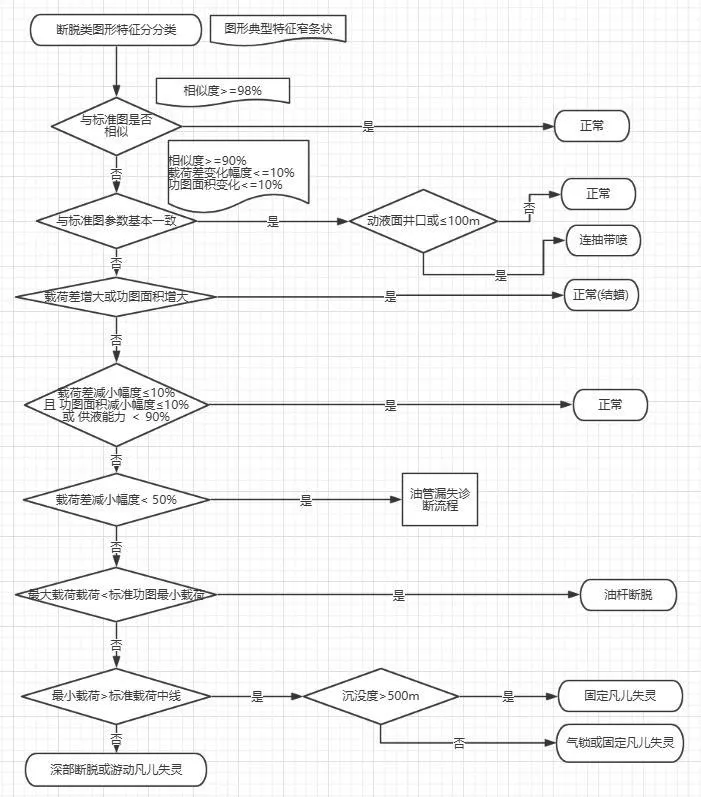
圖6 桿斷類工況特征診斷決策樹
最終系統工況智能診斷效果見圖7。
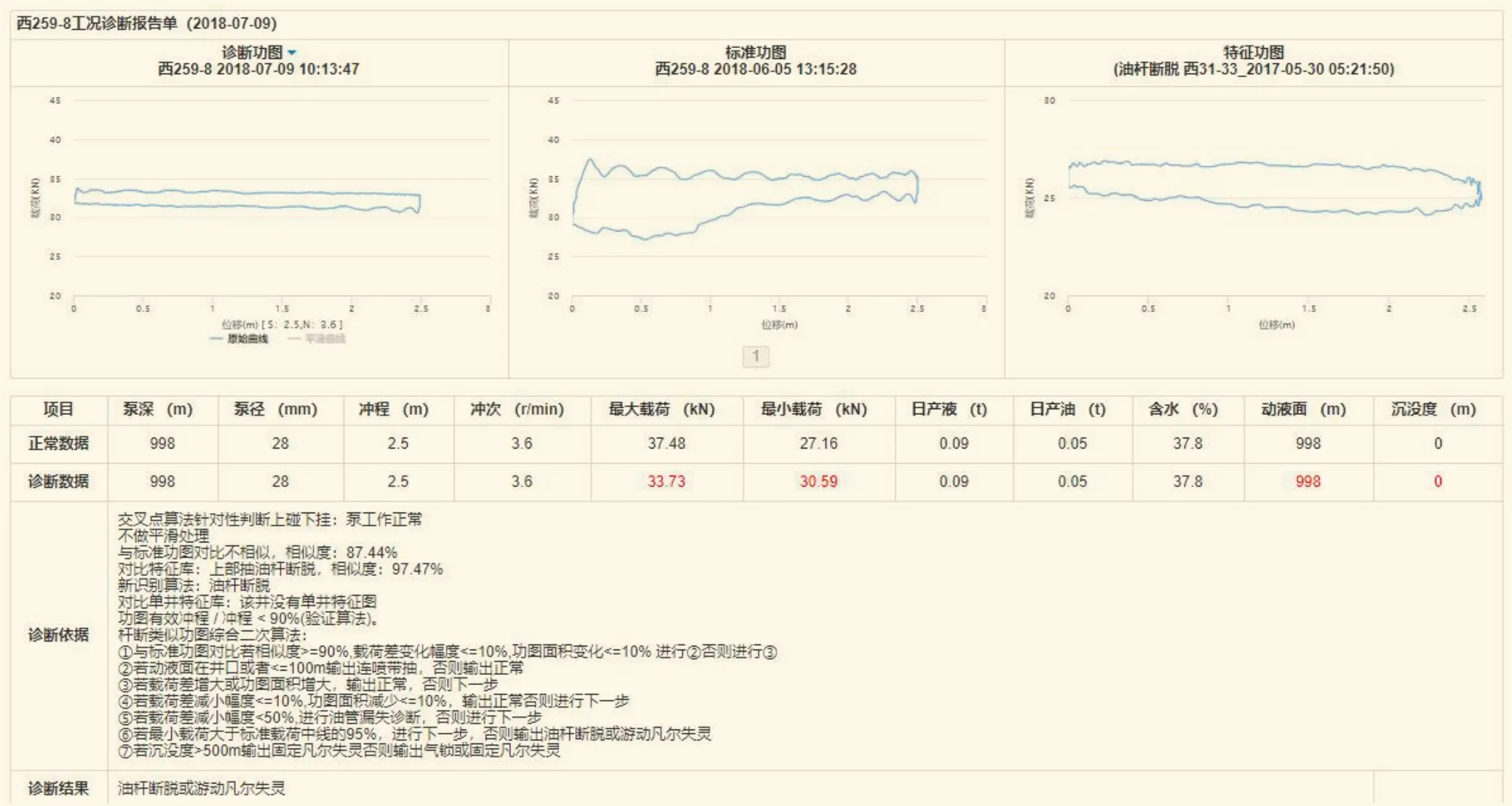
圖7 系統工況智能診斷實例
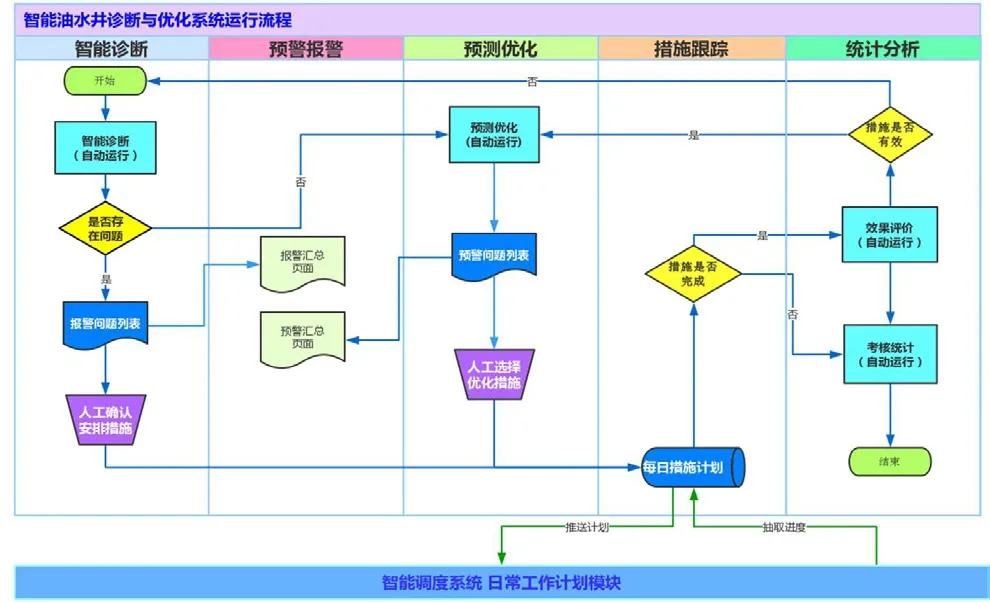
圖8 系統運行流程設計
5 油水井智能診斷優化系統運行流程
5.1 系統整體運行流程
油水井智能診斷優化系統是一套完整的油水井日常管理解決方案,系統設計的7個功能模塊互相交融、緊密聯系。其中知識庫及權限管理兩個模塊用于系統后臺服務,為用戶的使用及系統智能分析提供技術支持。其余5個模塊(智能診斷、預警報警、預測優化、措施跟蹤、統計分析)構建了油水井從發現問題→預警問題→處置問題→效果評價→預測優化整個閉環管理流程。(圖8)。
5.2 用戶問題處置流程
對于系統的最終用戶(基層技術管理人員),系統報警處置異常簡單,系統總體設計兩級人員參與,包括了問題處置及審核兩個環節,一個問題的處置最多3步即可完成(圖9)。
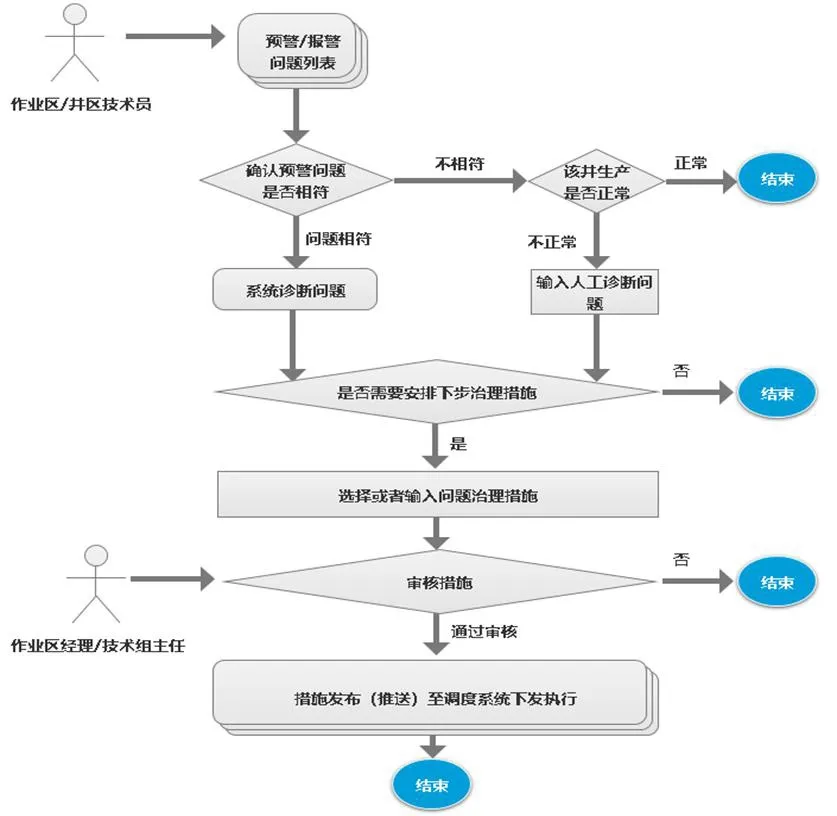
圖9 系統問題處置流程設計
6 系統應用效果及結論
系統自2017年投入研發,截止目前完成7大模塊、25項功能的開發,目前有特征功圖1300張、診斷算法36項,可診斷常見油水井故障63種,內置對應處置措施44項。2018年3月,系統投入生產使用,診斷準確率達到85%,診斷速度5000口/分鐘,系統漏報率0.5%,基本達到預期設計目的。
通過該系統的使用,目前達到了以下幾個應用目標:
(1)提高生產效率:對油水井的生產動態分析由人工分析轉向智能分析,把廣大技術人員從日常的分析統計工作中解放出來,大大提高工作效率;
(2)提高管理效率:建立了從問題發現->措施安排->落實監控->效果評價的管理流程,實現了閉環透明管理,提升了管理效率;
(3)保障生產時率:通過智能分析診斷及時發現油水井及生產管理中的各類問題,有效消減對產量的影響,提升異常問題的恢復效率。預計降低損失1831t,按照目前油價2925元/噸計算,折算經濟效益536萬元。
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
汽車維修與保養(2019年7期)2020-01-06 03:30:42
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
汽車維護與修理(2016年10期)2016-07-10 08:17:41
