計算機視覺研究綜述
2018-12-26 03:32:16張曉亮梁星馳
移動信息 2018年10期
張曉亮 梁星馳
?
計算機視覺研究綜述
張曉亮 梁星馳
中國人民解放軍32140部隊,河北 石家莊 050000
研究綜述了計算機視覺中分類與回歸、目標跟蹤、圖像分割、圖像超分辨率、風格轉移、著色、行為識別、姿勢預估和關鍵點監測等重要算法的原理和架構。
計算機視覺;神經網絡
1 分類與回歸
從ILSVRC 2017發布的分類與回歸問題的結果(圖1)可以看出,在分類與回歸問題上的錯誤率又有了較大幅度下降。分析原因主要是網絡的加深和對網絡結構的優化。以往對網絡優化,多從空間維度上進行。例如Inside-Outside考慮了空間中的上下文信息,還有將Attention機制引入空間維度。ResNet[1]很好地解決了隨著網絡深度的增加帶來的梯度消失問題,將網絡深度發展到152層。Inception[2]結構中嵌入了多尺度信息,聚合多種不同感受野上的特征來獲得性能增益,目前已經發展到inceptionV4并由于ResNet融合。DenseNet[3]比ResNet更進一步,對前面每層都加了Shortcut,使得Feature map可以重復利用。每一層Feature被用到時,都可以被看作做了新的Normalization,即便去掉BN層,深層DenseNet也可以保證較好的收斂率[4]。
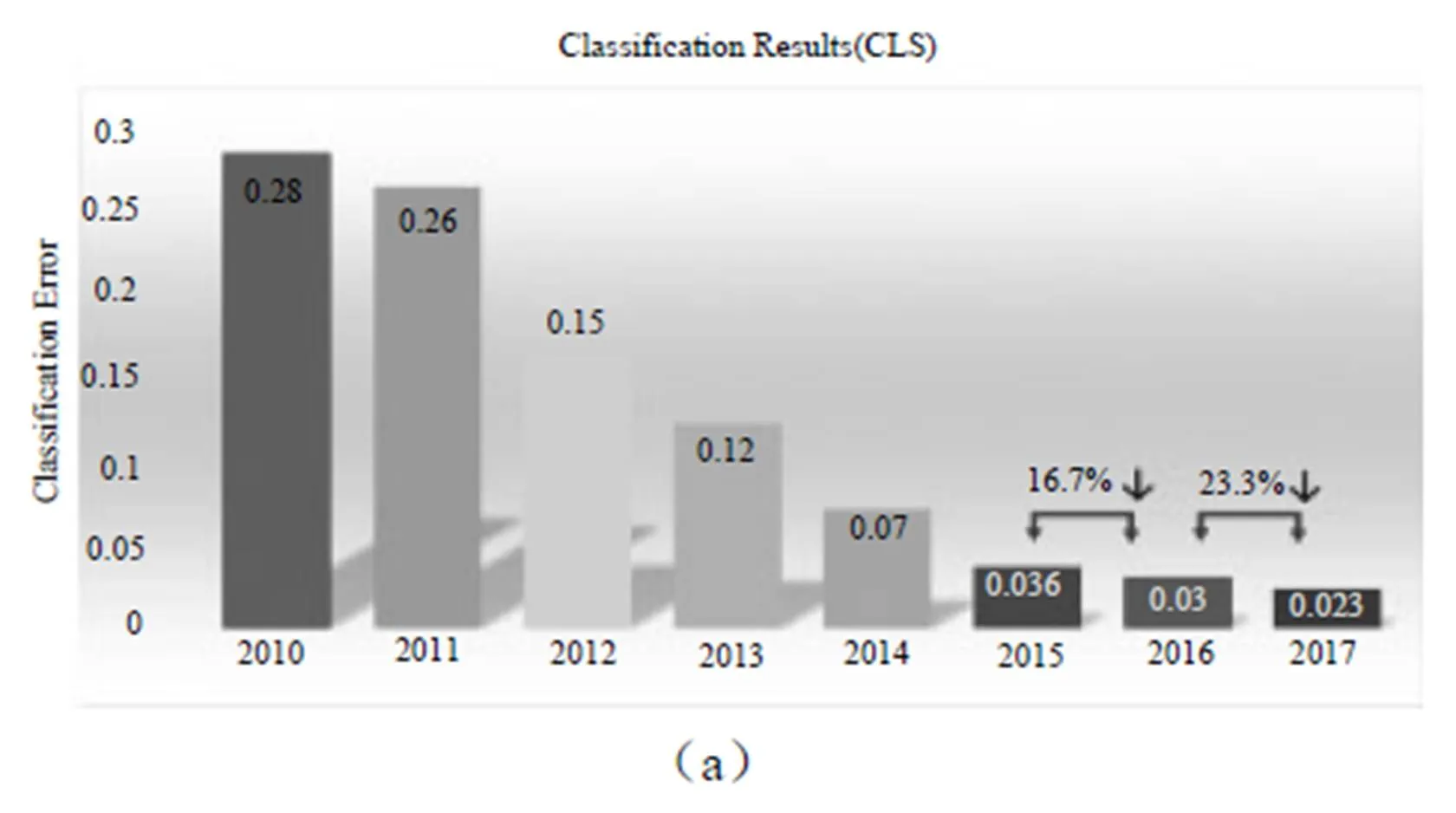
圖1
今年的分類冠軍是國內自動駕駛公司Momenta研發團隊(WMW)提出的SEnet架構。與從空間角度提升網絡性能有所不同,SEnet的核心思想是從特征通道的角度出發,為特征通道引入權重,通過學習權重參數來提升重要特征通道的地位。
SEnet架構如圖2所示。在Squeeze步,將每個特征通道變成一個實數。這個實數某種程度上具有全局感受野,使得靠近輸入的層也可以獲得全局信息,這一點在很多任務中都是非常有用的。Excitation步是一個類似于循環神經網絡中門的機制,通過參數w來為每個特征通道生成權重。最后是Reweight操作,我們將Excitation輸出的權重看作特征選擇后的每個特征通道的重要性,然后通過乘法逐通道加權到先前的特征上,完成在通道維度上的對原始特征的重標定。目前只見到相關介紹,還未見到成稿的論文發表。
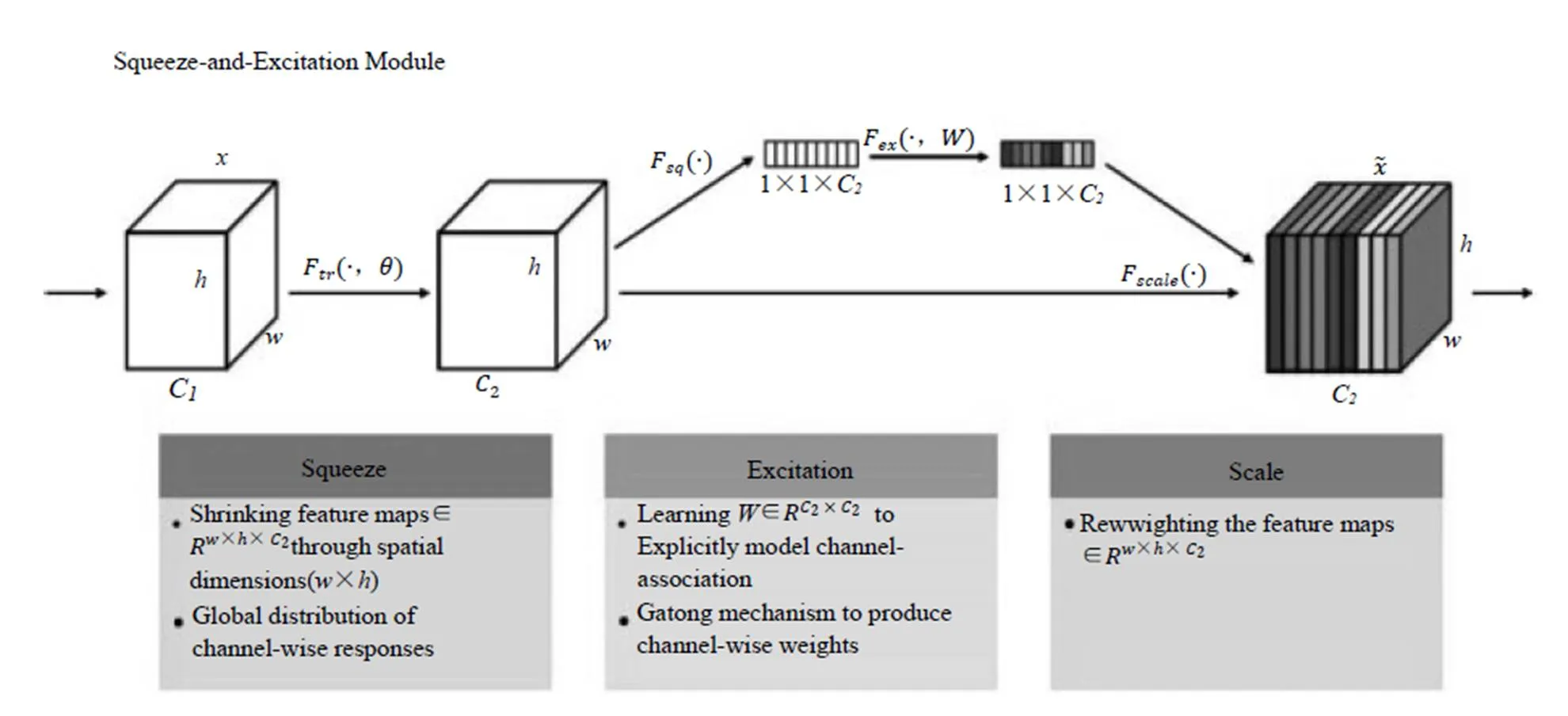
圖2
2 目標檢測
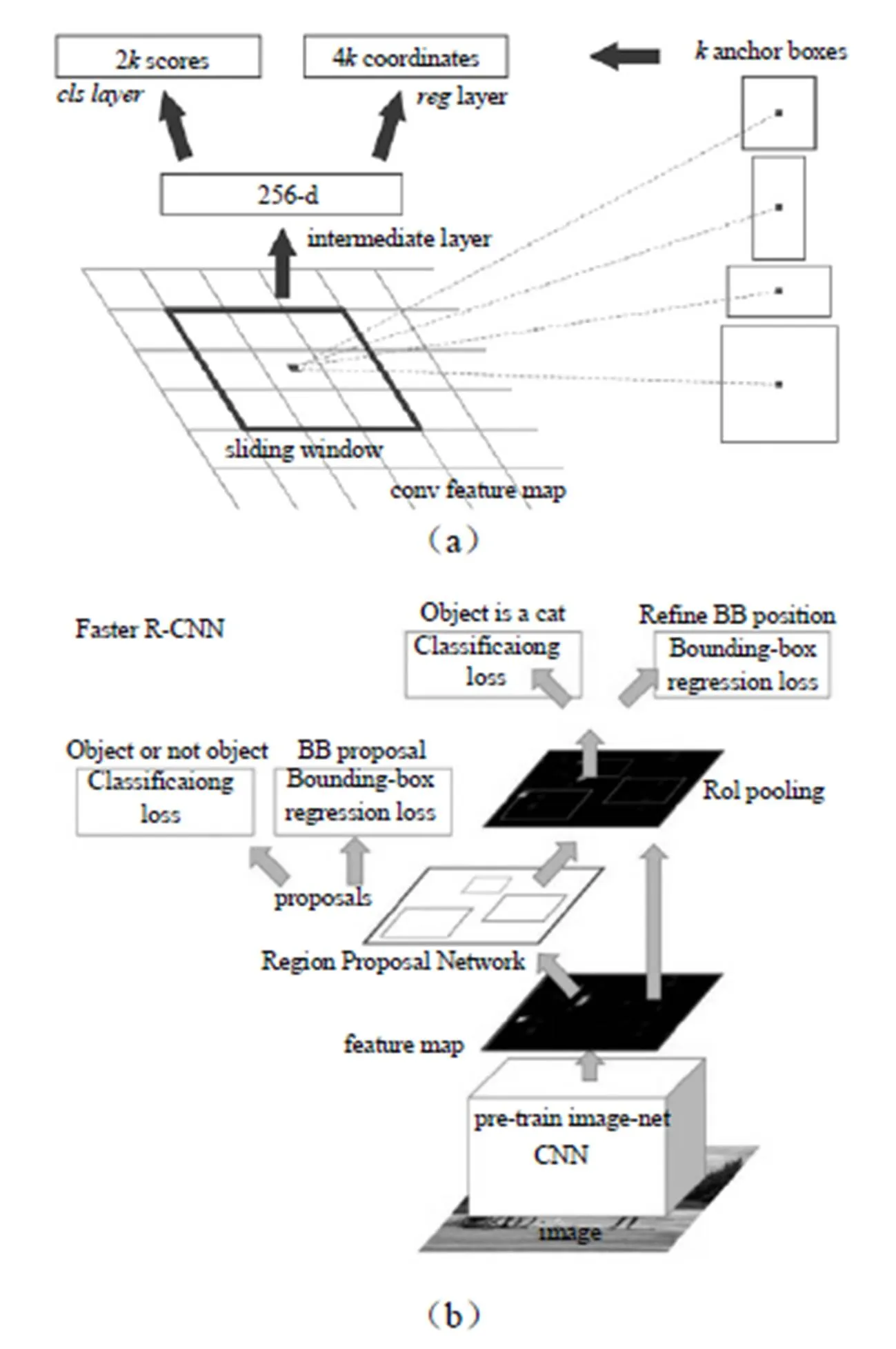
圖3
隨著自動駕駛、智能監控、人臉識別等大量有價值的應用逐步落地,快速、精準的目標檢測系統市場也日益蓬勃,模型不斷創新。Faster R-CNN、R-FCN、YOLO、SSD等是目前應用較廣的模型。Faster R-CNN[5]的架構如圖3所示,主要創新是用RPN網絡代傳統的“選擇搜索”算法,使速度大幅提升,如圖3所示,在最后卷即得到特征圖上使用一個3×3的窗口滑動,并將其映射到一個更低的維度上,(如256維),在k個固定比例的anchor box生成多個可能的區域并輸出分數和坐標。
分類需要特征具有平移不變性,而檢測具有一定的平移敏感性。Faster R-CNN在ROI pooling前都是卷積,是具備平移不變性的,在ResNet的91層后插入ROI pooling,后面的網絡結構就不再具備平移不變性了,而R-FCN[6]架構如圖4所示,在ResNet的第101層插入ROI pooling,并去掉后面的average pooling層和全連接層,構成了一個完整的全卷積網絡,提升了響應速度。其創新點在于ROI pooling中引入位置敏感分數圖,直接進行分類和定位,省去了Faster R-CNN中每個Proposal圖像單獨計算的計算量。Faster R-CNN和R-FCN以及以前的其他變化的模型都是基于Region Proposal的,雖幾經優化,在精度上達到最高,但無法做到實時,而SSD和YOLO兄弟都是基于回歸思想的檢驗算法,精度不及Faster R-CNN,但是速度快(45?FPS/155?FPS)。YOLO V1[7]利用全連接層數據直接回歸邊框坐標和分類概率,YOLO V2[8]不再讓類別的預測與每個cell(空間位置)綁定一起,而是讓全部放到anchor box中,提高了召回率(從81%到88%),準確率略有下降(從69.5%到69.2%),文獻[8]中還提出使用WordTree,把多個數據集整合在一起,分類數據集和通過實驗過這個算法,識別速度特別快,能做到實時,檢測數據集聯合訓練的機制,可檢測9000 多種物體,缺陷就是準確率還有待提高,特別是小目標的識別效果不好。
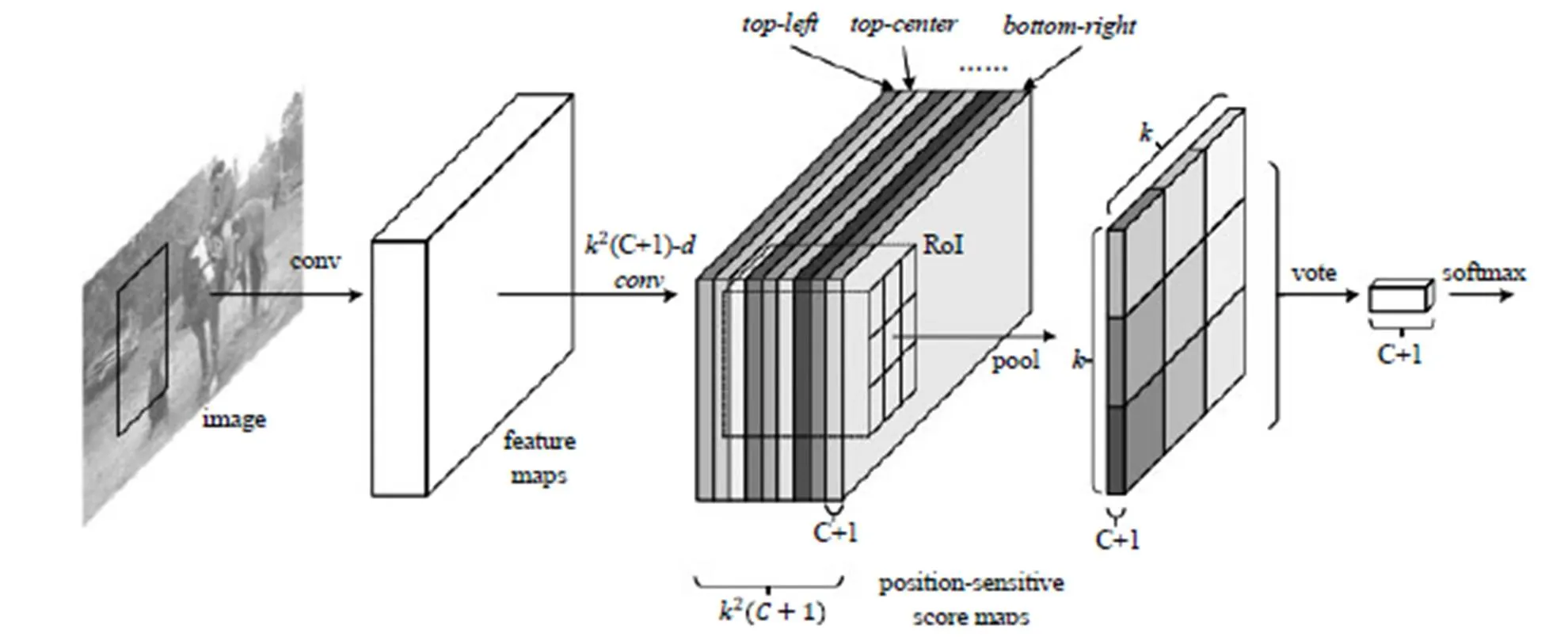
圖4
圖5
ILSVRC2017的目標檢測冠軍是BDAT團隊,該團隊包括來自南京信息工程大學和倫敦帝國理工學院的人員,目前尚未見到相關論文發表。
3 目標跟蹤
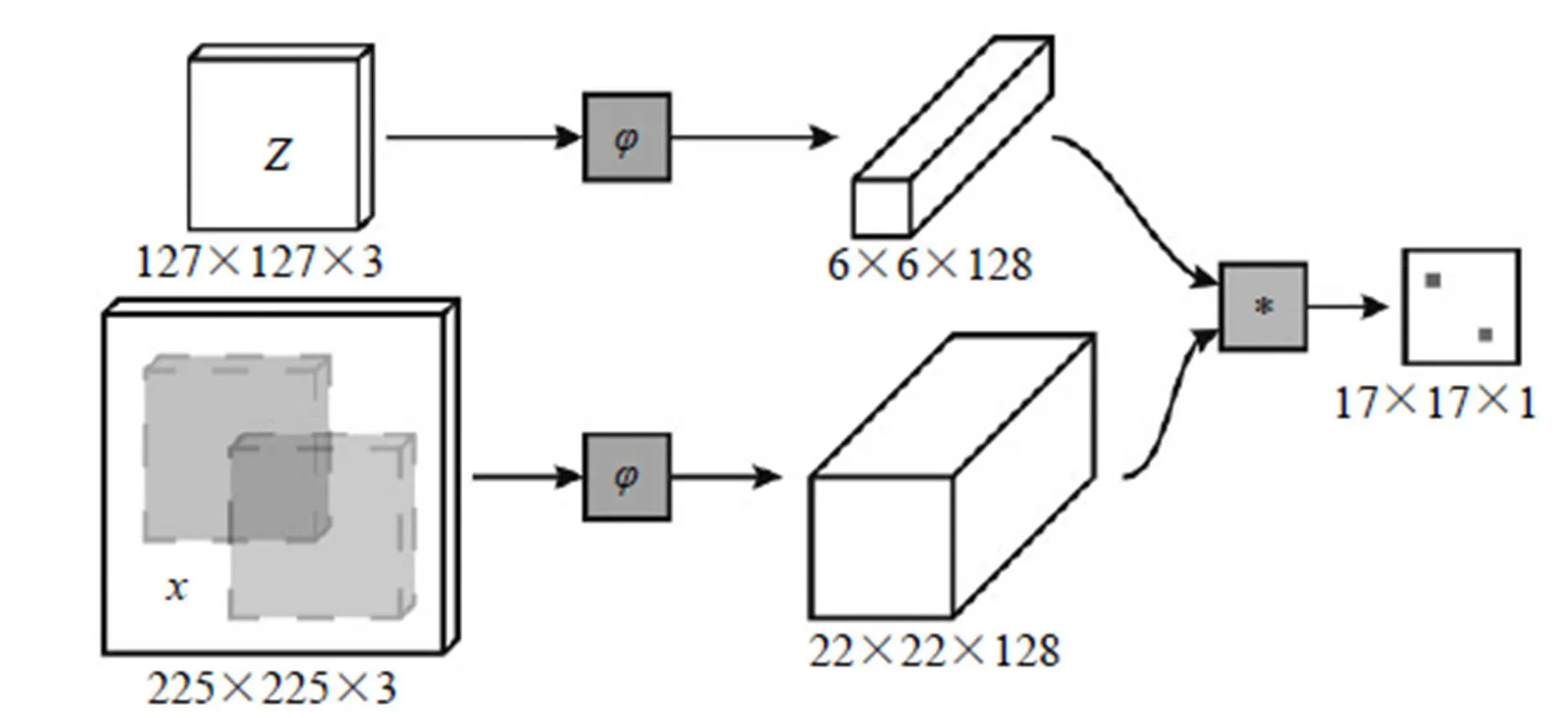
圖6
在OpenCV 3.2集成了六種目標跟蹤API,可以很方便地調用。其中BOOSTING、MIL、KCF、TLD和MEDIANFLOW都是基于傳統算法的,GOTURN是基于深度學習的。通過實驗,CV里集成的算法普遍存在對快速移動物體跟蹤失效的問題。雖然目前深度學習算法與傳統算法的距離沒有拉開,相信后續還會有突破,這里只介紹基于深度學習的算法。GOTURN[9]是發表在ECCV 2016的一篇文章,也是第一個檢測速度速度達到100?FPS的方法。
算法框架如圖5所示,將上一幀的目標和當前幀的搜索區域同時經過CNN的卷積層,然后將卷積層的輸出通過全連接層,用于回歸當前幀目標的位置,文獻作者發現前后幀的變化因子符合拉普拉斯分布,因此在訓練中加入了這個先驗知識,對數據進行了推廣,整個訓練過程是Offline的。在使用時只需要進行前饋運算,因此速度特別快。
SiameseFC[10]算法也是一個能做到實時的深度學習算法。如圖6所示,算法本身是比較搜索區域與目標模板的相似度,最后得到搜索區域的score map。其實從原理上來說,這種方法和相關性濾波的方法很相似。
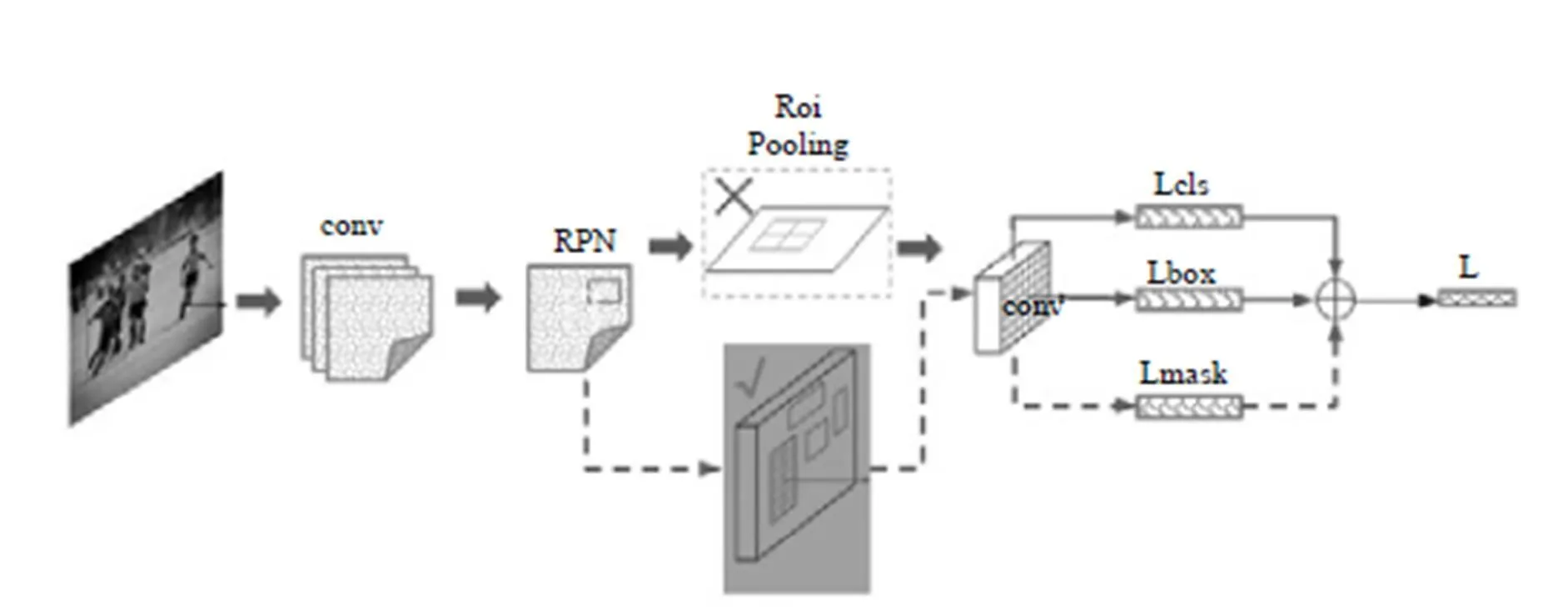
圖7
4 圖像分割
圖像分割技術是自動駕駛的基礎,具有商用價值。在這一領域貢獻較大的是Facebook的人工智能研究中心(FAIR),該團隊2015年開始研究DeepMask,生成粗糙的mask作為分割的初始形式。2016年,推出SharpMask[11],它改進了DeepMask提供的“蒙板”,糾正了細節的損失,改善了語義分割,除此之外MultiPathNet能標識每個掩碼描繪的對象。
特別值得一提的是,今年何愷明又研究出一種新的架構Mask R-CNN[12],即一種基于像素級別的分割算法。
為便于理解,對Mask R-CNN原文圖示進行了簡單的修改,如圖7所示,其主要思路是在Faster-RCNN的基礎上進行拓展,將ROI Pooling層替換成ROI Align,使用雙線性內插法,解決了像素對齊問題,并添加了mask層用于輸出二進制掩碼來說明給定像素是否為對象的一部分。通過我們的實驗master R-CNN確實產生了非常精妙的分割效果,但對于某些樣本的邊緣分割,還存在像素分配錯誤的情況,尤其是對照低照度下成像的樣本更明顯。
5 圖像超分辨率、風格轉移、著色
大多數現有的SR算法將不同縮放因子的超分辨率問題作為獨立的問題,需要各自進行訓練,來處理各種scale。VDSR[13]可以在單個網絡中同時處理多個scale的超分辨率,但需要雙三次插值圖像作為輸入,消耗更多計算時間和存儲空間。SRResNet[14]成功地解決了計算時間和內存的問題,并且有很好的性能,但它只是采用ResNet原始架構。ResNet目的是解決高級視覺問題。如果不對其修改直接應用于超分辨率這類低級視覺問題,那么就達不到最佳效果。微軟的CNTK里提供了VDSR、DRNN、SRGA和SRResNet四種API,通過我們的實驗確實能達到文獻中描述的效果。
EDSR[15]是NTIRE 2017超分辨率挑戰賽上獲得冠軍的方案。其架構如圖8所示,去掉了ResNet中BN層,減少了計算和存儲消耗。相同的計算資源下,EDSR就可以堆疊更多層或者使每層提取更多的特征。EDSR在訓練時先訓練低倍數上的采樣模型,接著用得到的參數初始化高倍數上的采樣模型,減少了高倍數上采樣模型的訓練時間,訓練結果也更好。這個模型我們也試驗過。與微軟API里的SRGAN和SRResNet模型相比確實有差別,但肉眼很難區別得特別清楚,也可能是我們選擇自己生活照為樣本的原因。
Prisma在手機里的應用讓更多人了解圖像風格轉換。文獻[16]第一個將神經網絡用在風格轉換上,基于神經網絡的風格轉換算法得到更多的發展。在文獻[17]中將風格轉換應用到了視頻上,畫面風格轉換,還是很完美的。文獻[18]實現了基于像素級別的風格轉換。
舊照片著色是很有趣的,文獻[19]利用CNN作為前饋通道,訓練了100萬張彩色圖像。在“彩色化圖靈測試”評估中騙過32%的人類,高于以前的方法,正如文中所講任何著色問題都具有數據集偏差問題。不是所有照片都能呈現完美效果。文獻[20]利用低級和語義表示,訓練模型預測每像素顏色直方圖。該中間輸出可用于自動生成顏色圖像,或在圖像形成之前進一步處理。文獻[21]提出了一種新穎的技術來自動著色灰度圖像結合了全局先驗和局部圖像特征,與基于CNN的大多數現有方法不同,該架構可以處理任何分辨率的圖像。
文獻[21]的框架如圖9所示,由四個主要部分組成:一個低級特征網絡,一個中級特征網絡,一個全局特征網絡和一個著色網絡。這些組件都是緊密耦合的,并以端到端的方式進行訓練。模型的輸出是與亮度融合形成輸出圖像的色度。
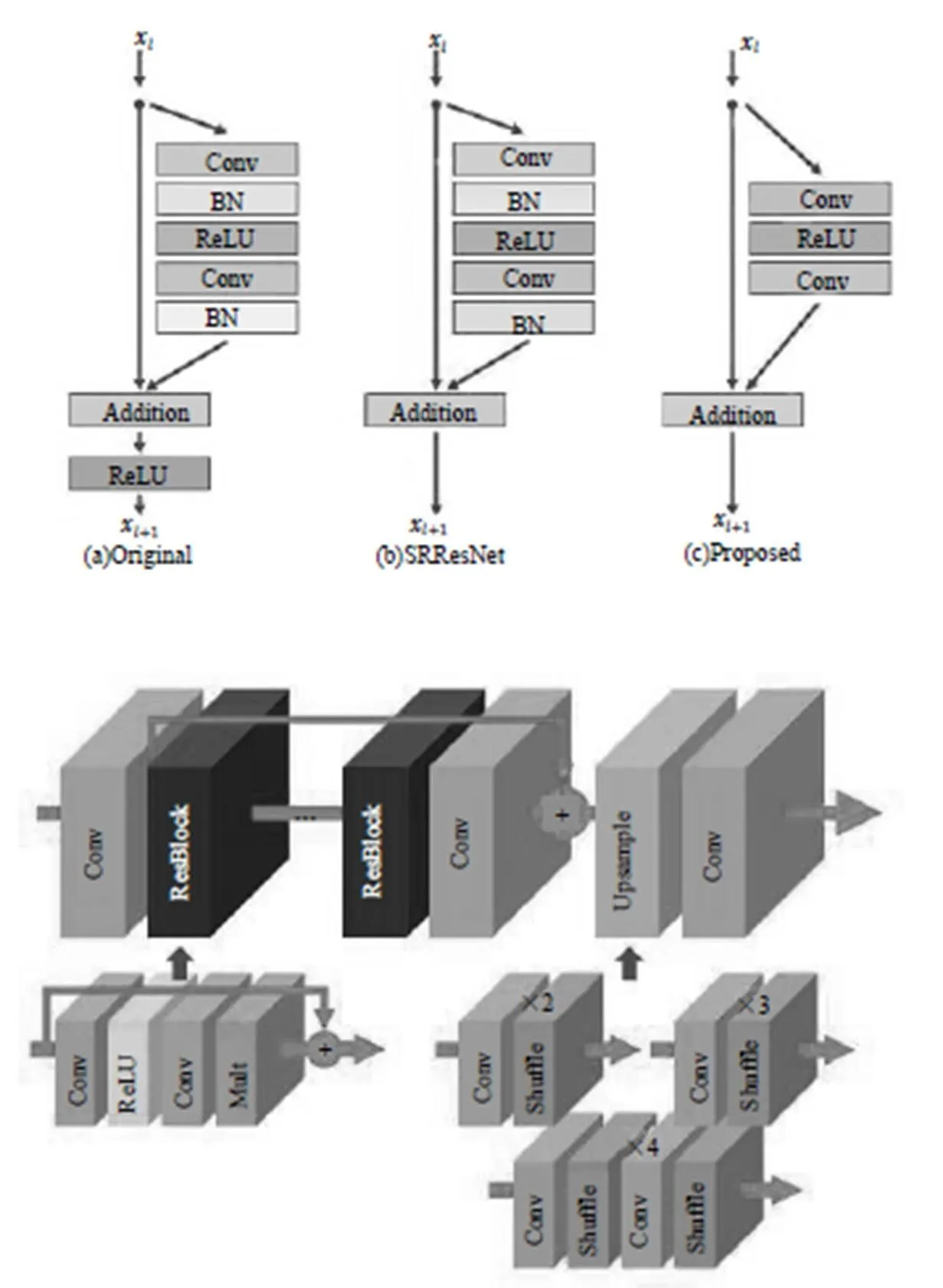
圖8
圖9
6 行為識別、姿勢預估和關鍵點監測
文獻[22]利用人類行為的時空結構,即特定的移動和持續時間,使用CNN變體正確識別動作。為了克服CNN長期行為建模的缺陷,作者提出了一種具有長時間卷積(LTC-CNN)的神經網絡來提高動作識別的準確性。文獻[23]用于視頻動作識別的時空殘差網絡將雙流CNN的變體應用于動作識別任務,該任務結合了來自傳統CNN方法和ResNet的技術。文獻[24]是CVPR 2017的論文,也是MSCOCO關鍵點檢測冠軍。使用Bottom-Up的方法,先去看一張圖有哪些人體部位(Key Point),接著再想辦法把這些部位正確的按照每個人的位置連起來算Pose。如圖10所示,輸入一幅圖像,經過卷積網絡(VGG19)提出特征,得到一組特征圖,然后分成兩個岔路分別使用CNN網絡提取Part Confidence Maps和Part Affinity Fields,得到這兩個信息后,使用圖論中的Bipartite Matching將同一個人的關節點連接起來,得到最終的結果。
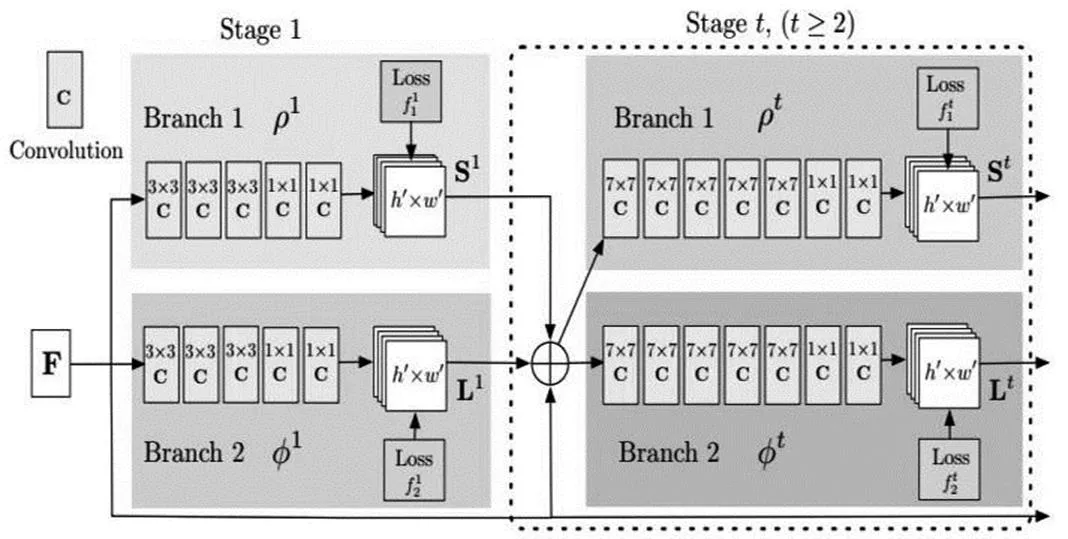
圖10
7 卷積網絡結構
卷積網絡結構是基于深度學習的計算機視覺基礎,從圖11中可以看出2012年AlexNet網絡取得歷史性突破以來得到很大發展。
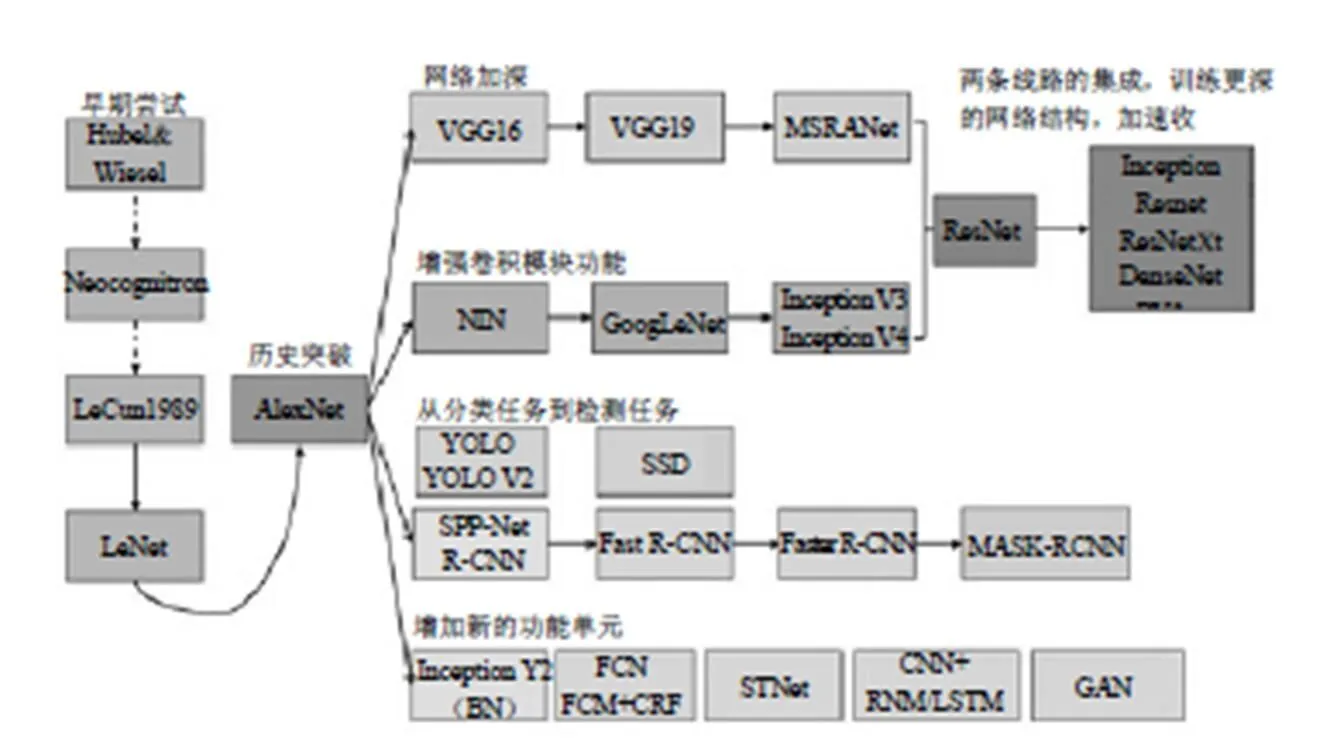
圖11
我們都知道深層CNN存在梯度消失問題。ResNet通過“skip connection”。結構一定程度上促進了數據在層間的流通,但接近輸出的網絡層并沒有充分獲得網絡前面的特征圖。DenseNet[3]在前向傳播基礎上,網絡每一層都能接受它前面所有層的特征圖,并且數據聚合采用的是拼接,而非ResNet中的相加。網絡模型如圖12所示。
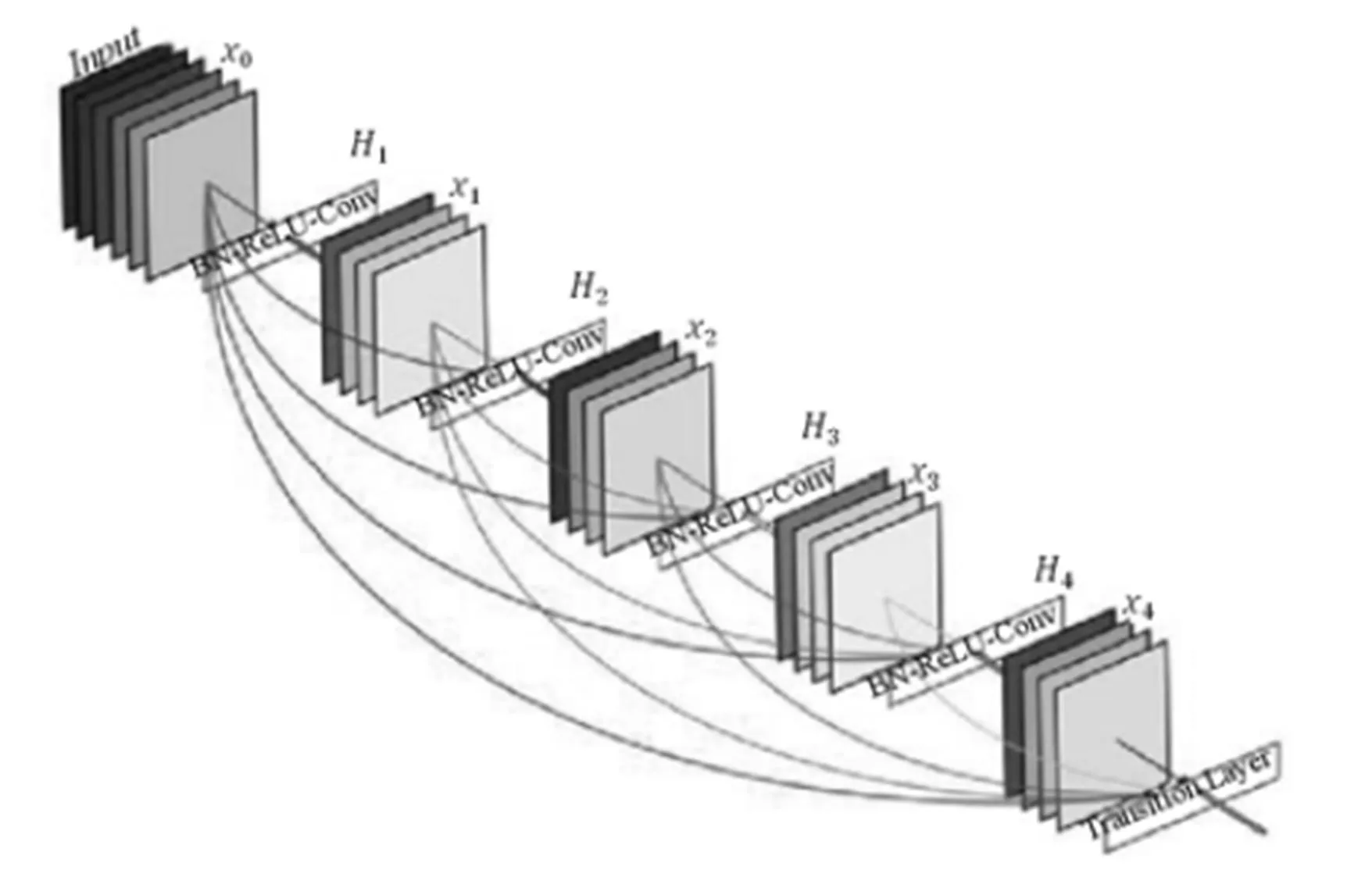
圖12
這種連接方式有一個很大的優點:前向傳播時深層網絡能獲得淺層的信息,而反向傳播時,淺層網絡能獲得深層的梯度信息。這樣最大限度促進了數據在網絡間的流動。另外,這種結構存在著大量的特征復用,因此只需要很少的參數,就可以達到state-of-the-art的效果,主要是體現在特征圖的通道數上,相比VGG、ResNet的幾百個通道,DenseNet可能只需要12、24個左右。
[1]He km,Zhang XY,Ren SQ,Sun J.Deep Residual Learning for Image Recognition[C]. 2016 CVPR,2016:770-778.
[2]SZEGEDY C,Liu W,Jia YQ,SERMANET P,REED S,ANGUELOV D,ERHAN D,VANHOUCKE V,RABINOVICH A.Going Deeper with Convolutions[C]. 2015 CVPR,2015:1-9.
[3]Huang G,Liu Z,VAN DER MAATEN L,Kilian Q,WEINBERGER KQ. Densely Connected Convolutional Networks[C]. 2017 CVPR,2017:2261-2269
[4]Li H,li W,Yang O,Wang X. Multi-Bias Non-linear Activation in Deep Neural Networks[C]. arXiv: 1604.00676.
[5]Ren XQ,He km,GIRSHICK,ROSS. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal networks[C]. IEEE TRANSATIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE,2017,39:1137-1149.
[6]Li Y,He K,Sun J,Dai J.R-FCN:Object Detection via Region-based Fully Convolutional Networks[C]. ADV NEURAL INFORM PR,2016:379-387.
[7]REDMON J,DIVVALA S,GIRSHICK R,FARHADI A.You Only Look Once:Unified,Real-Time Object Detection[C]. 2016 CVPR,2016:779-788.
[8]REDMON J,FARHADI A.YOLO9000:Better,Faster, Stronger[C]. 2017 CVPR,2017:6517-6525.
[9]HELD D,THRUN S,SAVARESE S. Learning to Track at 100 FPS with Deep Regression Networks[C]. COMPUTER VISION-ECCV 2016,2016,9905:749-765.
[10]Bertinetto L,Valmadre J,Henriques JF. Fully-Convolutional Siamese Networks for Object Tracking[C]. COMPUTER VISION-ECCV 2016,2016,9914:850-865.
[11]PINHEIRO PO,LIN TY,COLLOBERT R,DOLLAR P. Learning to Refine Object Segments[C]. COMPUTER VISION-ECCV 2016,2016,9905:75-91.
[12]HE km,GKIOXARI G,DOLLAR P.Mask R-CNN[C]. 2017 ICCV,2017:2980-2988.
[13]KIM J,LEE JK,LEE km.Accurate Image Super-Resolution Using Very Deep Convolutional Networks[C]. 2016 CVPR,2016:1646-1654.
[14]LEDIG C,THEIS L,HUSZAR F,CABALLERO J, CUNNINGHAM A,ACOSTA A,AITKEN A,TEJANI A,TOTZ J,Wang ZH,Shi WZ. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network[C]. 2017 CVPR,2017:105-114.
[15]LIM B,SON S,KIM H,NAH S,LEE K. Enhanced Deep Residual Networks for Single Image Super-Resolution[C]. 2017 CVPR,2017:1132-1140.
[16]GATYS L,ECKER A,BETHGE M.A Neural Algorithm of Artistic Style[M]. CoRR abs,2015.
[17]RUDER M,DOSOVITSKIY A,BROX T.Artistic style transfer for videos[C]. GCPR 2016,2016,9796: 26-36.
[18]Liao J,Yao Y,Yuan L,Hua G,Kang SB. Visual Attribute Transfer through Deep Image Analogy[C]. ACM TRANSACTIONS ON GRAPHICS,2017,36.
[19]Zhang R,LSOLA P,ALEXEI A,EFROS A A. Colorful Image Colorization[C]. ECCV 2016,2016,9907: 649-666.
[20]LARSSON G,MAIRE M,SHAKHNAROVICH G.Learn Representations for Automatic Colorization[C]. ECCV 2016,2016,9908:577-593.
[21]LIZUKA S,SIMO-SERRA E,ISHIKAWA H. Let there be Color!:Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous Classification[C]. ACM Transactions on Graphics,2016,35(4).
[22]VAROL G,LAPTEV I,SCHMID C. Long-term Temporal Convolutions for Action Recognition[C]. IEEE TRANSACTION ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE:2018,40(6):1510-1517.
[23]FEICHTENHOFER C,PINZ A,RICHARD P,WILDES RP. Spatiotemporal Multiplier Networks for Video Action Recognition[C]. 2017 CVPR,2017:7445-7454.
[24]Cao Z,SIMON T,Wei S,SHEIKH Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields[C]. 2017 CVPR,2017:1302-1310.
A Survey of Computer Vision Research
Zhang Xiaoliang Liang Xingchi
32140 Troop of People’s Liberation Army of China, Hebei Shijiazhuang 050000
The paper reviews the principles and architecture of important algorithms such as classification and regression, target tracking, image segmentation, image super-resolution, style shifting, coloring, behavior recognition, pose estimation and key point monitoring in computer vision.
computer vision; neural network
TP391.4
A
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
