基于于頻繁模式挖掘的共享單車數據分析
2019-01-03 02:30:28邢一丹
電子制作 2018年24期
邢一丹
(西安市第七十中學,陜西西安,710000)
0 引言
共享單車作為一種環保節能、方便快捷的綠色公共交通工具,十分經濟實用。共享單車擁有與政府為主導的公共自行車相同的目的一通過將自行車 與其他幾種交通方式相結合,吸引居民從私家車出行依賴向公共交通方式出行轉變減少私家車出行量,緩解城市交通擁堵問題,使這一方式成為城市公共交通的一部分實現城市交通'最后一公里"的無縫有效銜接的綠色交通模式,并最終成為居民交通出行的主要選擇。共享單車的出現,在一定程度上多元化居民的出行選擇,降低居民出行成本,道路資源利用率得以提高的同時也有利于交通擁堵問題的改善,共享單車出行還擁有環保節能,降低有害氣體排放,加快公共交通循環,完善公共交通體系,有助于提高市民的生活環境提高居民低碳環保出行的意識與誠信觀念等優點。
根據共享單車的發展,可以劃分為四個階段:萌芽階段、成長階段、泛濫階段、洗牌階段。在各個單車分別完成了多輪融資之后,單車投放量也都在不斷加大,開始出現單車扎堆,影響交通,管理混亂的現象。除此之外由于有樁的公共自行車容易出現“租/還難”問題,不同區域間的流量不平衡造成了公共自行車利用率的下降,無樁的共享單車雖然理論.上可隨時隨地租還,但也由于潮汐現象的存在,造成某些時候用戶在租車時發現附近沒有一-輛可以借的車(或者只有壞車),而在還車的時候,雖然沒有還車難的問題,但是會出現亂停放、目的地車輛扎堆等問題(在地鐵站、公交站等地尤為嚴重),這會造成一定的交通擁堵和城市管理混亂。在本文的研究中,嘗試使用頻繁模式挖掘來解決摩拜單車停放點預測的問題,提出了較為新穎的創新思路和創新方法。
1 模式介紹
2.1 術語介紹
項:我們分析的最小元素;項集:若干項組成的集合;事務:一種特殊的項集,作為輸入數據,常用ti表示一個事務;事務的集合叫事務集,用T表示;支持度計數:這個項集在所有事務集中出現的次數;支持度:支持度計數與事務的總數N的比值;規則:形如X→Y的表達式就是一個規則,X叫這個規則的前件或左件,Y叫這個規則的右件或后件,其中X∩Y=?;置信度:描述一個規則可信程度的量;最小支持度閾值min_sup:這個閾值就是判斷一個項集是否足夠頻繁的標準,滿足最小支持度閾值的項集就是頻繁項集,有k個項的頻繁項集就是頻繁k項集;最小置信度閾值min_conf:這個閾值是判斷一個規則是否足夠可信的標準;一般情況下的閾值設定,支持度閾值: 0.2/0.3 ,置信度閾值: 0.6/0.75。
2.2 模式引入
采用關聯分析算法、聚類分析算法,并使用Python編程語言實現。
數據來源2017摩拜杯(Mobike CUP)算法挑戰賽。
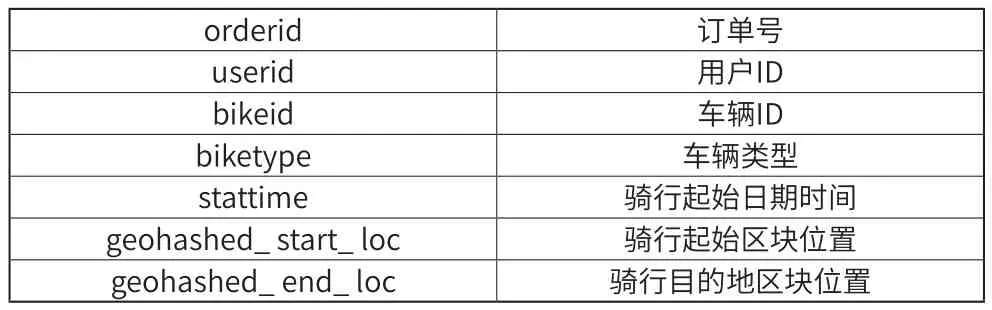
表1 數據含義
易知該模式中項包括訂單號,用戶ID,車輛ID,車輛類型,騎行起始日期時間,騎行起始區塊位置,騎行目的地區塊位置,通過數據中由項所組成的項集進行分析即使用頻繁模式挖掘來解決摩拜單車停放點預測的問題。
3 數據處理
3.1 數據介紹
對于數據挖掘而言,需要從海量的數據中挖掘出有用的模式和信息,也就是“沙里淘金”的過程。數據雖然是抽象概念,但是,它也具有規模和屬性。通俗來講,數據規模就是數據的多少,數據越多,規模就越大,現在所說的大數據就是規模極大的數據;數據屬性就是數據所具有的性質,數據具有的性質越多,我們稱其屬性越多,或維度越大,人們常說的數據降維處理就是盡可能地減少數據的無關屬性,以達到篩選的目的。
同樣,數據也有用來描述自己的單位,這個人們就接觸的比較多。數據的單位常常被稱作數據的寬度,日常生活中的網絡速度、下載速度、存儲空間等等都應用到了數據的單位方面的內容。
3.2 數據預處理的方法
數據預處理的主要方法就是數據清洗和數據歸約。
數據清洗主要包括對數據集進行異常檢測、識別并消除數據集中近似重復對象、對缺失數據進行清洗。數據集的異常檢測主要就是消除少數異常數據對總體的影響,常常運用均值和標準差進行檢測;重復記錄的清洗主要就是篩掉重復的數據,使數據集更加精簡,減少不必要的數據分析; 對缺失數據的清洗與灰色預測模型有些相似,旨在對缺失數據進行預測,其中涉及了許多高級的理論方法,這里就不再一一描述。
數據歸約主要包括高維數據的降維處理和離散化技術減少給定連續屬性值的個數。高維數據降維處理其本質就是刪除數據的冗余屬性,避免其對預測過程造成影響,簡化對數據分析的過程;而離散化技術減少給定連續屬性值的個數這種方法大多數是遞歸進行的,看似花費了大量的時間,其實卻節省了后面步驟的時間。
3.3 分析Mobike單車數據
在此,本文以摩拜公司提供的北京市的2017年5月10日至2017年5月24日的部分共享單車真實用戶抽樣數據為例進行分析和探索,該數據包含了幾十萬個摩拜單車用戶的出行信息,如訂單編號、用戶編號、車輛編號、車輛類型、騎行初始時間、騎行起始區塊位置、騎行目的區塊位置等信息,其中包含接近300萬條的真實用戶租還記錄。
在預測共享自行車的用戶出行目的地之前,需要先根據用戶的歷史騎行規律,構建出用戶最可能去往的目的地集合,稱作用戶出行候選地預測。在預測候選地的時候,需要根據用戶歷史的行為,分析出最有可能去的地方,這就需要挖掘用戶與初始地、目的地的頻繁模式項。實現代碼如表1所示。
首先,在數據集上統計出用戶的出行熱門地點,將目的地區塊作為分組進行統計,計算用戶騎行目的地次數最多的5個地點和所對應的地理位置經緯度。如表2所示。
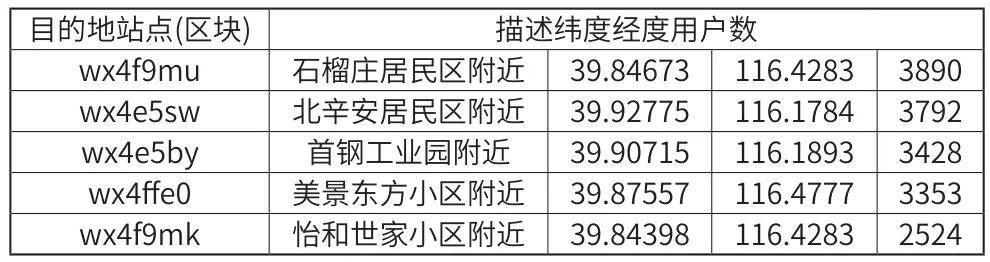
表2
接下來按照騎行地與目的地的組合對進行統計,觀察分析起始地和目的地之間都有哪些規律。
圖1
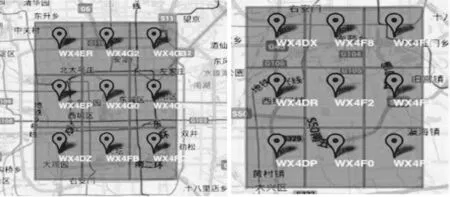
圖2 北京城區GeoHash編碼區圖北京郊區GeoHash編碼圖
起始地描述目的地描述軌跡數如表3所示。
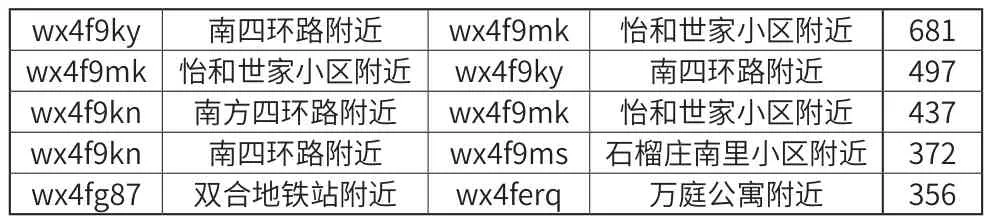
表3
其中起始地與目的地對應關系涉及到的區域的經緯度信息如下:
首先,可以發現頻繁度比較高的模式對主要是出現在環路附近、居民區以及地鐵站附近等地方,他們之間關系抽象出來主要有:環路-居民區、居民區-地鐵站等。這也與日常生活中的情況比較吻合,用戶經常由于工作需要往來于居民區、地鐵站或者環路等附近。因此這些規律性比較具有普遍意義。
在預測共享自行車的用戶出行目的地之前,結合上面的分析,需要先根據用戶的歷史騎行規律,構建出用戶最可能去往的目的地集合,稱作用戶出行候選地預測。在預測候選地的時候,需要根據用戶歷史的行為,分析出最有可能去的地方,這就需要挖掘用戶與初始地、目的地的頻繁模式項。首先我們需要對所有項的出現個數進行統計,其次是只考慮對頻繁項集進行掃描。具體步驟如下:
(1)首先創建根節點,用Null來表示;
(2)統計所有的項中各個類型的總支持度,如起始地或目的地的總個數;
(3)遍歷每個項,按照總支持度計數進行降序排列,然后掛在根節點下方;
(4)遍歷后續的項,以相同方式順著根節點加入到樹結構中,并更新支持度計數。
根據用戶出行的歷史規律,可以考慮挖掘出“起始地-目的地”的頻繁項集,以歷史集合中出現頻次最高的,作為用戶出行目的地的候選集。總計為以下幾種:
(1)用戶-起始地-目的地頻繁項集(User-Start-Destination): 用戶、起始地和目的地在訓練集的組合中出現頻率較高的頻繁項作為該起始地對應的候選目的地。
(2)用戶-起始地頻繁項集( User-Start): 根據分析,用戶的歷史出行地也是用戶出行范圍的一-部分,因此歷史的出行地也可能是未來的目的地,因此要考慮將用戶、起始地在訓練集的組合中出現頻率較高的頻繁項作為該起始地對應的候選目的地。
(3)用戶-目的地頻繁項集(User-Destination):根據分析,用戶的歷史目的地必然是用戶出行范圍的一部分,因此歷史的目的地很也可能是未來的目的地,此可能性比起始地還要高,因此要考慮將用戶、目的地在訓練集的組合中出現頻率較高的頻繁項作為該起始地對應的候選目的地。
(4)起始地-目的地頻繁項集(Start-Destination):不挖掘具體用戶的頻繁項集,將整體的思考范圍調整到全部用戶,考慮僅僅將起始地、目的地在訓練集的組合中出現頻率較高的頻繁項作為該起始地對應的候選目的地。




4 結論
4.1 模型優勢
本文以北京摩拜單車的數據集為例分析了共享自行車用戶出行規律和影響共享自行車用戶出行的因素,然后采用常用的關聯分析算法、聚類分析算法,并使用Python編程語言實現,構建了用戶候選地預測模型。按照不同角度,如用戶與目的地、用戶與起始地、起始地與目的地、起始地附近地與目的地、起始地與目的地附近低等多種組合的頻繁項集,構建出來的預測模型召回率較高。
4.2 改進方向
由于能力及時間有限,對問題的考慮及處理方法上仍有很多不周的地方需要改進或后續進行深入研究,共享單車數據較難獲取,目前的研究是基于有限的數據集進行的,因此效果可能會有些影響,在真實場景下能夠有更大量的數據集用來訓練模型,效果應該會好很多。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
電子制作(2018年18期)2018-11-14 01:48:24
商用汽車(2016年11期)2016-12-19 01:20:16
山東工業技術(2016年15期)2016-12-01 05:31:22
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
