基于Word2Vec的神經網絡協同推薦模型
2019-01-17 02:15:20張華偉
網絡空間安全 2019年6期
張華偉


摘? ?要:在信息推薦系統中,傳統的方法是通過對內容、行為去預測用戶的興趣點來實現信息推送。國內外研究實驗結果表明,這種模型推薦性能較為顯著,說明用戶行為和內容是相關的。根據相關性的對稱原理,文章提出了基于用戶行為的Word2Vec協同推薦算法,通過神經網絡模型來隱式地抽取商品和用戶的相互關系并進行向量化表示,能夠更好地計算商品和用戶間的相似性,以達到提升模型的推薦效果和泛化能力。
關鍵詞:Word2Vec;詞向量;協同推薦;卷積神經網絡
中圖分類號:TP311.1? ? ? ? ? 文獻標識碼:A
Abstract: In the information push system, the traditional method is to predict the user's interest points through content and behavior to achieve information push. The domestic and foreign research results show that the recommendation performance of this model is still remarkable, which also shows that user behavior and content are related. According to the symmetry principle of relativity, this paper proposes a Word2Vec collaborative recommendation algorithm based on user behavior, which implicitly extracts and vectorizes the relationship between goods and users through the neural network model, so that we can better calculate the similarity between goods and users, and improve the recommendation effect and generality of the model.
Key words: Word2Vec; word vector; collaborative recommendation; convolution neural network
1 引言
推薦系統是互聯網時代的一種信息檢索工具,自上世紀90年代起,人們便認識到了推薦系統的價值,經過了二十多年的積累和沉淀,推薦系統逐漸成為一門獨立的學科在學術研究和業界應用中都取得了很多成果。
1994年明尼蘇達大學推出第一個自動化推薦系統Group Lens[1],這是最早的自動化協同過濾推薦系統之一。1997年Resnick等人首次提出推薦系統(Recommender System,RS)一詞,自此,推薦系統一詞被廣泛引用,并且推薦系統開始成為一個重要的研究領域。1998年亞馬遜(Amazon.com)上線了基于物品的協同過濾算法。2003年亞馬遜的Linden等人發表論文,公布了基于物品的協同過濾算法,據統計推薦系統的貢獻率在20%~30%之間。1999年開始ACM每年召開的電子商務研討會,推薦系統相關研究逐漸增多,2001年SIGR開始專門把推薦系統作為一個研討主題,2007年在美國舉行第一屆ACM推薦系統大會。2016年,You Tube發表論文,將深度神經網絡應用推薦系統中,以達到從大規模候選信息中計算出最優的推薦內容[2]。
2 相關技術
2.1 Word2Vec模型
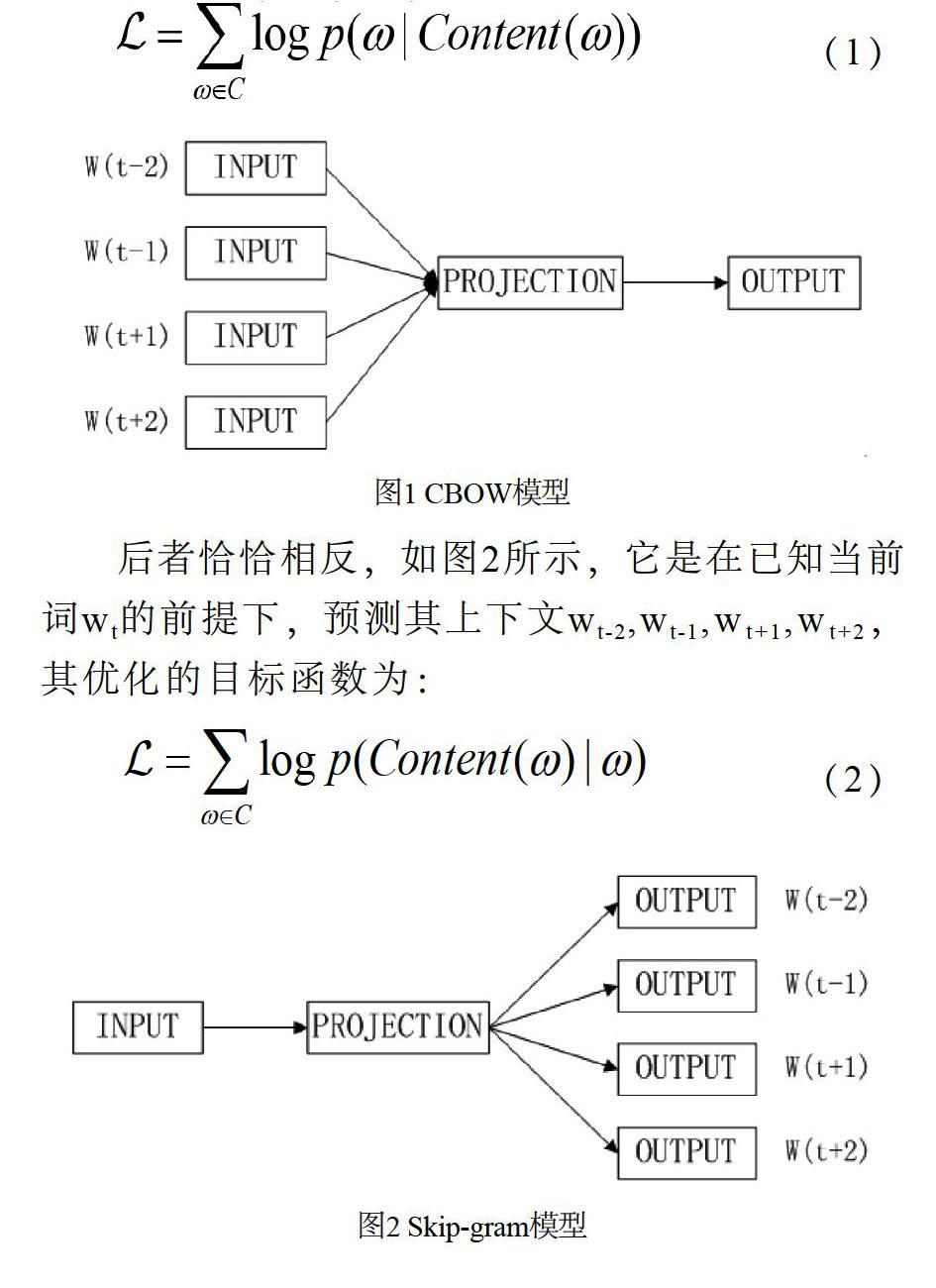
Word2Vec[3]是由Mikolov提出的基于NNLM算法的詞向量模型,其除了擁有很高的處理效率外,經訓練出的詞向量可以揭示特征詞之間的語義關系。Word2Vec有兩個重要模型[4],分別是CBOW模型(Continuous Bag-of-Words Model)和Skip-gram模型(Continuous Skip-gram Model)。
兩個模型都包含三層,即輸入層、投影層和輸出層。CBOW模型如圖1所示,它是在已知當前詞wt的上下文wt-2,wt-1,wt+1,wt+2的前提下預測當前詞wt,其優化的目標函數為:
后者恰恰相反,如圖2所示,它是在已知當前詞wt的前提下,預測其上下文wt-2,wt-1,wt+1,wt+2,其優化的目標函數為:
2.2 卷積神經網絡
卷積神經網絡(Convolutional Neural Network)[5]是一種前饋神經網絡。它由卷積層、池化層和全連接層構成,每一層通過一個可導的激活函數將上一層的輸出變為下一層的輸入。
(1)卷積層
卷積層[6]是卷積神經網絡的核心部分,通過卷積運算來獲取輸入數據的局部特征,然后將局部特征進行連接形成整體特征。假設有兩個函數f(x)和g(x),其卷積運算(f×g)(n)是指,對f(x)和g(x)的乘積進行求和。
進行卷積運算時,過濾器在輸入矩陣上移動,進行點積運算。數據特征進行卷積之后,要使用激活函數進行非線性變化,減少處理后的數據特征表達能力不足的問題,具體計算公式如下:
常用的激活函數f有sigmod或tanh等非線性函數。
(2)池化層
池化(Pooling)也稱為欠采樣或下采樣,通過對卷積計算產生的特征進行劃分不同的區域,并通過算法統計出該區域的池化值,于此可看出池化層主要用于特征降維和減小過擬合問題,同時提高模型的容錯率。
(3)全連接層
經過卷積層和池化層多次交替結構后(具體的交替次數根據實際情況而定),最終匯聚到全連接層。全連接層和卷積層的區別是,在卷積層中的神經元只與前一層的局部連接,并通過權值共享方式減少連接的參數,而全連接層的神經元與前一層的所有激活單元連接。
3 推薦算法
3.1商品向量化表示
推薦算法通過用戶的點擊、評價、用戶偏好和內容文本信息詞嵌入向量。可以把用戶已經訪問過的項目看成一個N維向量,基于項目向量來計算條件概率。假設用戶已經訪問的項目向量為un,用戶接下來會訪問的K個項目的向量[7~9]為,因此,可以用激活函數來計算條件概率:
通過對目標函數最優化參數vc,vn使得上面條件概率最大,利用用戶訪問歷史記錄來預測用戶接下來要看的商品,具體計算公式如下:
3.2 協同推薦模型
利用公式(6)可以構造推薦系統中的用戶和商品向量,作為卷積神經網絡的輸入,本文設計了基于Word2Vec協同推薦算法(W-CNN)。
(1)將每個用戶的歷史行為序列Item映射為一個d維的詞向量,生成一個n×d維的矩陣,其中n代表Item數,d代表每個Item映射的緯度。
(2)對于詞向量,將每個映射的d維向量堆疊,利用CNN對堆疊結果的局部特征進行提取,采用多種不同大小的水平卷積核來學習多個Item之間的特征關系,得到輸出向量Vector1。
(3)同時采用垂直卷積核對每次輸入的所有Item的關系進行綜合,得到輸出向量Vector2。
(4)將向量Vector1和Vector2拼接并得到一個長向量,將該長向量輸入到一個多層全聯接的神經網絡中,再采用負采樣的方法進行輸出優化,優化后的輸出結果是分別與每個Item一一對應的輸出概率值。
4 實驗
4.1 實驗環境與數據集
本文采用的硬件環境:32GB內存,Intel Core i7-7700處理器;GPU為Gigabyte GTX1080Ti Xtrem,實驗平臺基于TensorFlow和Python3.6語言,操作系統為Ubuntu18。
實驗使用的數據為MovieLens數據集, MovieLens包含2000多萬條評分數據、2.7萬部電影數據、46.5萬個電影類型標簽數據及13.8萬位用戶數據。對數據集進行規整化處理的方法與步驟:
(1)以電影所屬類型及符號“|”為依據進行分割;
(2)如果一個電影有多個類型,將分割成多個列表;
(3)將分割后得到的多個列表轉換為一個數據合集;
(4)將數據合集的索引設置為電影ID。
4.2 實驗結果分析
首先,通過設置不同的推薦個數(Top-N)來測試它對算法的影響。如圖3所示,在MovieLens數據集上,本文提出的W-CNN算法的準確率在TOP-N中相比于其他算法,具有較好的性能,并且隨著推薦個數的增加,算法性能處于平穩狀態,甚至有輕微的提升。
如表1所示,本文提出的W-CNN算法在MovieLens數據集上的準確率、召回率和F1值相對于其它算法都有較為明顯的提高。實驗結果表明,本文算法基于Word2Vec和卷積神經網絡,對用戶和項目進行向量化,能從整體上提升算法性能,從而提升系統推薦質量。
5 結束語
本文對基于Word2Vec的卷積神經網絡推薦模型做了較為全面的研究,首先利用Word2Vec對用戶的偏好、瀏覽記錄、用戶評價進行建模,并生成偏好矩陣和用戶主題矩陣向量,再利用該模型為用戶進行推薦,最后根據用戶的訪問記錄定期更新用戶偏好。實驗結果表明,本模型在MovieLens數據集上的準確率、召回率和F1值相對于其它算法都有較為明顯的提高,并且隨著推薦個數的增加,算法性能并處于平穩狀態,甚至有輕微的提升。
參考文獻
[1] 汪靜.協同過濾推薦算法研究綜述[J].中國新通信,2014(13):111-113.
[2] 黃立威,江碧濤,呂守業,等.基于深度學習的推薦系統研究綜述[J].計算機學報,2018,41(7):191-219.
[3] 李曉,解輝,李立杰.基于Word2vec的句子語義相似度計算研究[J].計算機科學,2017,44(9):256260.
[4] 曾誰飛,張笑燕,杜曉峰,等.基于神經網絡的文本表示模型新方法[J].通信學報,2017,38(4):8698.
[5] 張群,王紅軍,王倫文.詞向量與 LDA 相融合的短文本分類方法[J].現代圖書情報技術,2016,(12):27-35.
[6] 韓棟,王春華,肖敏.基于句子級學習改進CNN的短文本分類方法[J].計算機工程與設計,2019(01).
[7] 周慶平,譚長庚,王宏君,等.基于聚類改進的KNN文本分類算法[J].計算機應用研究,2016, 33(11):3374-3377+3382.
[8] 朱珠.卷積神經網絡的多目標跟蹤系統[J].網絡空間安全,2018,9(11):68-71.
[9] 吳春瓊,黃曉.基于猴群算法優化的神經網絡在入侵檢測中的應用研究[J].網絡空間安全,2016,7(06):14-18.
