隱私計算-面向隱私保護的新型計算
2019-01-18 05:21:16西安電子科技大學網絡與信息安全學院執行院長
信息通信技術 2018年6期
李 暉 西安電子科技大學網絡與信息安全學院執行院長
移動互聯網、云計算和大數據等技術的快速發展,催生了眾多新的服務模式和應用,這些服務和應用一方面為用戶提供精準化、個性化的服務,給人們的生活帶來了極大便利,另一方面又采集了大量用戶的相關信息,而所采集信息中往往含有大量包括病史、收入、身份、興趣及位置等在內的敏感信息,對這些信息的收集、共享、發布、分析與利用等操作會直接或間接地泄露用戶隱私,給用戶帶來極大的威脅和困擾。因此,個人隱私保護已成為人們廣泛關注的焦點。
隱私信息是大數據的重要組成部分,隱私保護關乎個人、企業乃至國家利益。2016年4月歐盟通過了《通用數據保護條例》(GDPR)并于2018年5月25日正式在歐盟境內生效實施。GDPR定義了7類個人敏感數據,明確規定了數據主體對服務提供方收集個人敏感數據以及處理這些數據的方式具有知情權,可以要求服務方刪除個人敏感數據(即被遺忘權)。我國于2016年11月頒布了《中華人民共和國網絡安全法》,并于2017年6月1日正式實施,其中對個人信息保護做出了明確規定。各國重視數據安全和隱私保護立法的另一面,是互聯網環境下隱私保護理論與技術研究的嚴重滯后。
針對隱私保護問題,學術界開展了大量的研究工作,并在社交網絡、位置服務、云計算、大數據、智能醫療、智能電網、智能交通等方面提出了諸多具體的隱私保護方案。目前已有的各類隱私保護方案大多針對單一場景,隱私缺乏定量化的定義,隱私保護的效果、隱私泄露的利益損失以及隱私保護方案融合的復雜性三者之間的關系刻畫缺乏系統的計算模型,使隱私信息在不同系統、不同用戶間共享、交換和分析過程中難以被準確刻畫和量化,阻礙各類計算和信息服務系統對隱私進行統一評價。
針對這一問題,李鳳華、李暉等人2016年在通信學報上發表的論文《隱私計算研究范疇及發展趨勢》提出隱私計算的概念,對隱私計算的內涵加以界定,從隱私信息的全生命周期討論隱私計算研究范疇,對互聯網環境下隱私保護的關鍵理論與技術給出了體系化的發展路徑建議。
1 隱私計算定義
隱私是指個體的敏感信息。含有隱私的信息會在網絡中傳播、在各類信息服務系統中存儲、處理(編輯、融合、發布和轉發)。隱私信息的全生命周期如圖1所示。

圖1 隱私信息的全生命周期
隱私計算是面向隱私信息全生命周期保護的計算理論和方法,具體是指在處理視頻、音頻、圖像、圖形、文字、數值、泛在網絡行為信息流等信息時,對所涉及的隱私信息進行描述、度量、評價和融合等操作,形成一套符號化、公式化且具有量化評價標準的隱私計算理論、算法及應用技術,支持多系統融合的隱私信息保護。
隱私計算涵蓋了信息所有者、搜集者、發布者和使用者在信息采集、存儲、處理、發布(含交換)、銷毀等全生命周期過程的所有計算操作,是隱私信息的所有權、管理權和使用權分離時隱私描述、度量、保護、效果評估、延伸控制、隱私泄漏收益損失比、隱私分析復雜性等方面的可計算模型與公理化系統。
2 隱私計算的關鍵問題
2.1 隱私信息感知
從包含隱私的信息中構建隱私變量集合,從變量集合中確定變量的取值或取值范圍,對隱私進行標記和編碼,確定隱私變量的概率分布,從而對隱私變量中隱私度量的大小進行計算,為實施隱私保護提供支撐。針對互聯網環境下信息敏感性隨時間、場景、載體類型/內容、主觀感知等因素動態變化的特點,可基于信息熵的概念,從主體、客體、場景、操作等維度對蘊含于海量數據中的隱私數據進行分析和量化,提出融合主觀感知能力的多維度隱私動態度量方法,形成隱私數據分類定級標準,解決互聯網環境下數據隱私的精準度量問題,使隱私計算模型可以具備對主體、時間、空間三維演化的刻畫能力。
2.2 隱私保護
根據隱私感知得到隱私信息保護效果需求選用相應隱私保護方法。主流的隱私保護方法可分為數據無失真的隱私保護方法和數據有失真隱私保護方法,如表1所示。
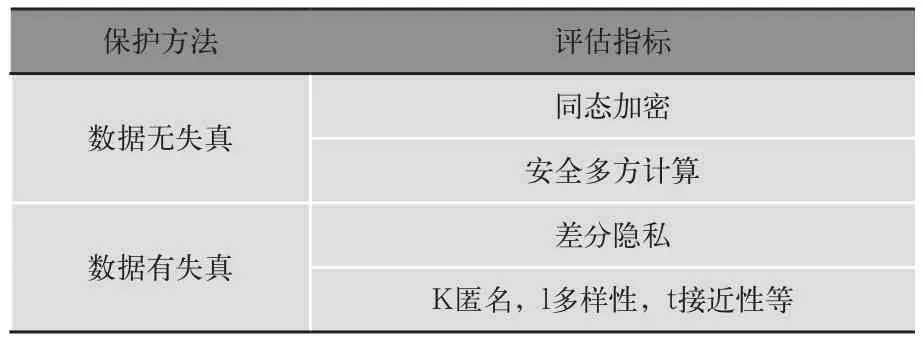
表1 隱私保護方法
數據無失真的隱私保護方法主要基于密碼學方法,包括同態密碼方案和安全多方計算。同態加密允許用戶直接對密文進行特定的運算,將其解密所得到的結果與對明文進行同樣的運算結果一樣。2009年Gentry構造出了第一個全同態加密方案,經過近10年的改進,現有的全同態加密方案計算復雜度仍然很高,無法應用到實際系統中,所以目前主要的方法是針對具體的處理需求采用效率相對較高的部分同態方法設計密文計算方案,以支持數據匿名化統計、數據關聯分析、多功能密文檢索等隱私保護的數據處理。
數據有失真的隱私保護方法主要是數據匿名和數據擾動。數據匿名包括去除不同隱私數據間的關聯性、數據泛化等,如k-匿名,l-多樣性,t-鄰近性等方法,使得攻擊者無法獲得個人的具體數據。這類方法的主要問題是不能抵抗背景知識關聯分析。差分隱私技術(Differential Privacy)主要應用在對數據集作統計量的時候保護用戶隱私,通過統計學的方法來模擬一個效果,使得從數據集中去掉(或替換)任何一個個體的數據之后,得到同樣的統計結果的概率和不去掉(或不替換)該個體記錄時候得出的結果在很高概率上是一樣的。差分隱私的具體實現方式是對數據集統計量輸出疊加一個適當的噪聲。數據有失真的隱私保護核心問題是達到數據可用性和隱私保護效果的最佳折中。
2.3 隱私信息的融合處理
在隱私數據的融合處理環節中,由于不同系統在隱私界定、度量方法、隱私保護需求等方面都存在差異,而且隨著時間場景的變更,人們對隱私認知也在不斷的變化,此外,隱私信息可能被進行二次轉發、局部處理、隱私分割、延伸授權等,因此需設計一套協議和封裝描述方法,可根據不同的隱私屬性、場景、隱私信息等級來自適應地選擇不同的隱私保護措施,充分發揮現有隱私保護技術的各自優勢。
2.4 隱私信息的銷毀
在不再需要隱私信息,或隱私信息所有者希望終止隱私信息傳播時,需要將隱私數據永遠不可逆刪除或銷毀,GDPR賦予用戶“被遺忘權”。從技術角度而言,實現這一權力需要研究可信刪除,或稱為確定性刪除技術,以確保隱私信息的所有者、管理者和使用者都不可再恢復該信息。同時確保隱私保護的信息不能被隱私分析提取,并建立一套體系或機制,可通知關聯系統,一旦數據被銷毀,釋放相應的存儲空間。在當前泛在網絡空間環境中,隱私信息的銷毀難度非常大。
3 隱私計算的未來研究方向
3.1 隱私動態度量
當前大型互聯網服務機構所控制的數據跨系統、跨境、跨生態圈流轉,數據海量、數據類型與應用場景多樣,需要在適應多媒體多場景的隱私信息度量方法、隱私度量動態調整機制及隱私度量與約束規則/策略自動映射等三個方面開展研究,解決巨數據集下的隱私信息的動態度量核心問題,以支撐開放環境下場景自適應的隱私按需控制。
3.2 隱私保護的基礎算法
針對不同類型數據和隱私保護需求的隱私保護操作,需研究高效隱私保護原語的基礎理論。在基于加密的隱私保護原語方面,重點在于全同態加密方法、部分同態加密算法、密文搜索、密文統計等密文計算理論。數據有失真的隱私保護原語方面,重點將在于差分隱私模型各種改進,以及信息論等新的理論方法的引入。
3.3 隱私保護效能評估
隱私保護算法的效能評估重點是要建立一套科學合理的量化體系,在這一量化體系指導下,對數據無失真和有失真的隱私保護原語以及原語的組合提出各對應指標的量化評估方法,包括隱私保護效果、數據可用性、算法復雜度等,以期為隱私保護方案的設計、比較和改進提供科學的評價依據。
3.4 隱私計算語言
研究隱私計算語言的語法體系,包括語句定義、編程接口、隱私保護原語的融合等,為復雜隱私保護方案的實現提供方便快捷、硬件和操作系統等平臺無關編程工具,以支撐隱私保護機制在復雜互聯信息系統中的實施部署。
4 結束語
隱私計算意圖建立全生命周期的隱私保護理論體系,通過推動隱私計算的聚焦研究所取得的成果,將有力支撐大型互聯網信息系統隱私保護的具體實現,指導大型信息系統隱私保護系統的開發,為隱私保護標準制訂提供支撐,為評測機構提供理論支撐,為網絡安全法個人信息保護的落地實施提供技術手段。
猜你喜歡
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中華手工(2017年2期)2017-06-06 23:00:31
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
祝您健康(1987年2期)1987-12-30 09:52:28
