基于模糊聚類分析方法的高含水期油藏層系優化
2019-02-04 06:34:53李小波劉威李健
當代化工 2019年11期
李小波 劉威 李健

摘??????要:針對高含水期油藏的層系優化問題,提出了一種基于模糊聚類分析的方法,闡述了在高含水期油藏層系優化過程中的使用過程,并實際驗證應用效果。研究表明:使用模糊聚類分析方法以后,各層之間的矛盾明顯減少,且各層系都具有一定的原油儲量和厚度,各油井都具有一定的產能,每個層系都可以成為獨立的開發系統。
關??鍵??詞:模糊聚類分析;方法概述;應用步驟;高含水期油藏;層系優化
中圖分類號:TE 151???????文獻標識碼:?A ??????文章編號:?1671-0460(2019)11-2630-05
Optimization of Reservoir System in High Water Cut
Period Based on Fuzzy Clustering Analysis
LI Xiao-bo, LIU Wei, LI Jian
(China Petroleum Exploration and Development Research Institute, Beijing?100083,?China)
Abstract: In order to optimize the layer system in high water-cut reservoirs, a method based on fuzzy clustering analysis was proposed. The use process of this method in the reservoir layer optimization process in high water cut period was expounded, and the application effect was verified. The study showed that after using the fuzzy clustering analysis method, the contradiction between layers was significantly reduced, and each layer had a certain amount of crude oil reserves and thickness, each well had a certain capacity, and each layer became an independent development system.
Key words: Fuzzy clustering analysis; Method overview; Application steps; High water cut reservoir; Layer optimization
對于我國油田而言,由于地層壓力不足,因此必須采取加壓采油方案,一般來說,我國大多數油田都是采用注水的方式增加地層壓力[1]。隨著油田注水時間的不斷增加,大多數油田已進入高含水期階段。高含水油田普遍具有層間干擾嚴重、地層剩余原油較為分散等問題,直接造成油田單位的采收率下降,原有的層系組合方式不能滿足采油的需求[2,3]。因此,十分有必要對高含水期油田進行層系優化,為提高采油效率奠定基礎。
目前,國內外眾多學者對層系優化問題進行了深入研究,并取得了一定的成果。2011年,曾雪梅等[4]根據原油開發中面臨的眾多問題,結合影響原油采收率的相關因素和地層的層系特征,對層系進行了重新優化,使得層系與井網之間緊密結合,具有提高采收率的效果,但是該研究所考慮的地層因素不足,因此,提高采收率的效果十分有限;2012年,代興斌等[5]對薩中油田地層內剩余油的分布情況進行了調研,根據油田井網的分布情況,提出了二次開發的層系優化方案,該研究為薩中油田的二次開發奠定了良好基礎,但是該研究具有很強的針對性,所提方案對于其它油田并不適用;2014年,周羽佳等[6]對杏一區油田的地層特征進行了調研,并對層系進行了細分和優化,層間干擾得到了降低,使得開發效果得到了提高,在該研究中,所考慮的因素相對較小,同時所提方案也具有很強針對性。
通過以上分析可以發現,目前的研究主要針對特定的區塊,并沒有提出一種適用于大多數油田的方法,而且所考慮的因素并不完善。針對這些問題,本次研究提出了一種模糊聚類分析的層系優化方法,該方法具有一定的普適性,且所考慮的因素相對較為完善,最后,本次研究以G油藏為例進行了驗證,以此證明該方法的可行性。
1 ?模糊聚類分析方法簡介
1.1 ?模糊聚類分析方法概述
模糊聚類分析方法是數學中常見的一種分類方法,該種方法基于多元分析理論,目前該種方法已經在各個領域都得到了一定程度的應用[7]。模糊聚類分析方法的主要原理是:在現實中,任何事物都可以根據自身的相似性組合成一個群體,這里所談論的相似性并沒有嚴格的界限,可以定義成具有一定的模糊關系,而模糊聚類方法就是根據事物之間的模糊性(即無界限的相似性)進行劃分,通過事物的各種特點建立模糊矩陣,使用數學的方式對事物進行分類,該種分類方法具有簡單易懂且分類速度相對較快的特點[8]。
 (5)
(5)
(4)聚類分析
在實施聚類分析的過程中,需要使用上文計算得到的模糊關系![]() ,如果該模糊關系并不滿足等價條件,則需要對其進行自乘處理,即
,如果該模糊關系并不滿足等價條件,則需要對其進行自乘處理,即![]() ,然后再進行二次自乘,即
,然后再進行二次自乘,即![]() ,不斷自乘,直到
,不斷自乘,直到![]() ,當
,當![]() 滿足模糊等價關系時,即可停止該過程[12]。得到
滿足模糊等價關系時,即可停止該過程[12]。得到![]() ,即可根據置信水平
,即可根據置信水平![]() 的不同,進行聚類處理,
的不同,進行聚類處理,![]() 可以依次取值為
可以依次取值為![]() ,該過程的具體步驟為:
,該過程的具體步驟為:
首先假設![]() (最大值),然后對
(最大值),然后對![]() 進行相似類處理,即
進行相似類處理,即![]() ,該過程就是將滿足
,該過程就是將滿足![]() 的兩個樣本歸為一類,從而形成相似類。相似類和等價類之間存在一定的區別,兩個樣本歸為相似類,則說明兩個相似類中可能含有共同的變量,即可能會出現
的兩個樣本歸為一類,從而形成相似類。相似類和等價類之間存在一定的區別,兩個樣本歸為相似類,則說明兩個相似類中可能含有共同的變量,即可能會出現![]() ,此時就需要將兩個樣本中的共同變量進行合并,就可以得到
,此時就需要將兩個樣本中的共同變量進行合并,就可以得到![]() 的等價分類[13]。假設
的等價分類[13]。假設![]() 為次大值,在
為次大值,在![]() 中尋找相似度等于
中尋找相似度等于![]() 的樣本對,同時將樣本對中共同變量進行合并,此時就可以得到
的樣本對,同時將樣本對中共同變量進行合并,此時就可以得到![]() 的等價分類。以此類推。
的等價分類。以此類推。
2 ?G油藏模糊聚類分析方法應用
(1)評價指標的確定
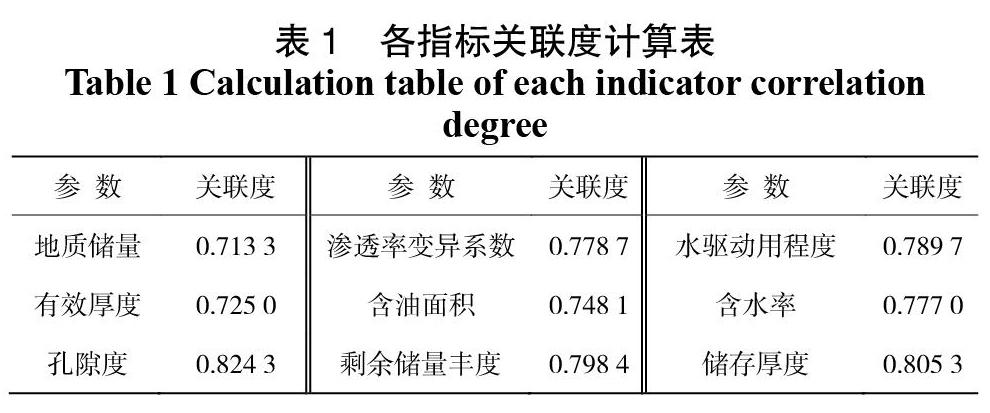
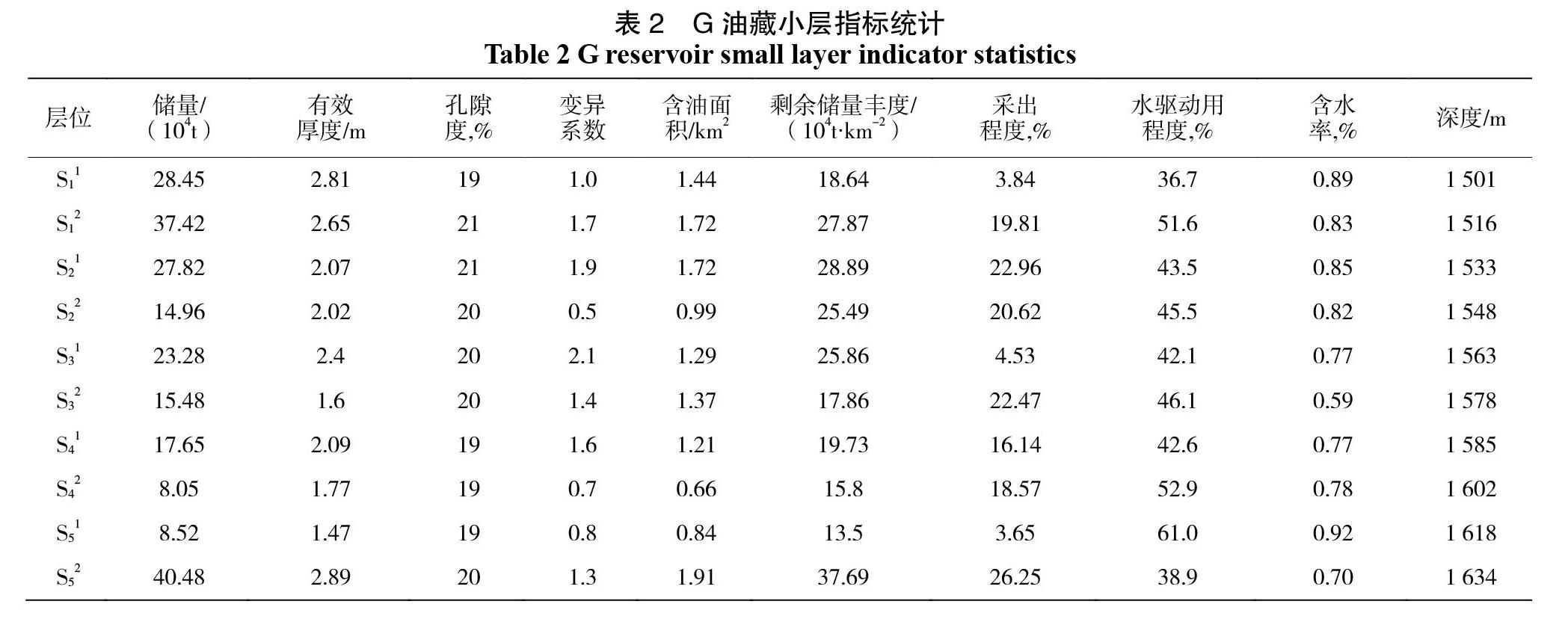
在使用上文所提到的模糊聚類方法對地層的層系進行優化時,首先需要對影響因素進行關聯度分析,在另一方面,層系優化的優劣與否,將直接決定著地層原油的采出程度,因此,可以將采出程度作為該過程的母序列,將影響采出程度的因素作為子序列,計算子序列與母序列之間的關聯度數值,然后確定進行模糊聚類分析的指標[14]。關聯度分析的結果如表1所示。通過表1可以看出,本次選擇的影響采出程度的9個因素都與采出程度之間具有良好的關聯性,因此,在本次研究中,可以將這9個因素和采出程度共同作為模糊聚類分析的指標,然后將相似度較高的地層歸為一套層系。如表2所示即為G油藏的相關指標數據。
(2)原始數據變換處理
由表2可以知道,進行模糊聚類分析的相關指標總共有10項,這就是進行層系優化的主要指標,由于每個指標的單位及數量級都存在差距,為了去除這種差距的影響,需要對其進行歸一化處理,從而將每個指標數據都壓縮到[0,1]之間。使用MATLAB軟件對表2中的數據進行歸一化,得到歸一化數據以后,即可通過相似系數法來建立模糊聚類分析所使用的相似矩陣,使用MATLAB軟件,通過相似系數法得到的相似矩陣,歸一化后的矩陣和相似矩陣如下兩式所示。

(3)模糊聚類
對得到的相似矩陣進行聚類處理,首先需要給出置信水平![]() ,當
,當![]() 的數值不斷降低時,樣本也將從細到粗的進行不斷歸類,根據置信水平所取數值的不同,得到的分類結果也將存在差距,在本次研究中,依次將置信水平分別取值為0.925、0.899、0.889、0.886、0.884、0.878,由此得到的分類結果如表3所示。
的數值不斷降低時,樣本也將從細到粗的進行不斷歸類,根據置信水平所取數值的不同,得到的分類結果也將存在差距,在本次研究中,依次將置信水平分別取值為0.925、0.899、0.889、0.886、0.884、0.878,由此得到的分類結果如表3所示。
根據表3所示的聚類結果可以形成6種不同的層系優化方式,但是置信水平分別為0.925、0.899、0.878時,分別存在一套層系原油的儲量相對較少,一般情況下,層系優化以后,不但需要避免層間的干擾,還應保證每套層系都存在一定的原油儲量,此時才能證明層系優化的結果相對較好,因此,對表5的聚類結果進行分析以后,優選出了置信水平分別為0.889、0.886、0.884時層系分類結果,最終確定了三套組合方式。
3 ?G油藏層系優化方案研究
目前,G油藏的剩余原油儲量約為221.65萬t,油藏的厚度大約為200 m,油藏的跨度相對較大,原油儲層底部與底部之間的距離為1 450~1 640 m,井段的長度相對較長,如果僅使用一套井網進行后續的開發工作,則層間產生干擾的可能性相對較大,????此時會產生層間矛盾,由于不斷開發以后,地層的含水率將持續上升,此時開發的難度也將持續增加,因此,必須對G油藏進行層系優化,減小層間矛盾,已達到在緩慢地層含水率的前提下提高原油采收率的目的。在對G油藏進行層系優化實際的過程中,所堅持的原則為:
(1)所提出的層系優化方案一定要簡潔;
(2)每口油井的控制產量盡量要大于4萬t;
(3)層系之間的矛盾必須得到顯著降低;
(4)油層的動用程度一定要大于80%。
根據該油藏進行層系優化的基本原則,使用上文中模糊聚類分析后的結果,在考慮G油層開采現狀的前提下,對層系進行了優化,從而制定出來三種優化方案,其結果如下表4所示:
方案1:?S11-S32層共同形成一套層系,該層系的厚度為13.55?m,該層系的儲量為146.93萬t;?S41-S52層共同形成另一套層系,該層系的厚度為8.22 m,該層系的儲量為74.72萬t,根據目前的開采現狀,第1套層系的采出程度為15.25%,第2套層系的采出程度20.44%。
方案2:?S11-S31層共同形成一套層系,該層系的厚度為11.95 m,該層系的儲量為131.23萬t;?S32-S52層共同形成另一套層系,該層系的厚度為9.88 m,該層系的儲量為104.11萬t,根據目前的開采現狀,第1套層系的采出程度為14.39%,第2套層系的采出程度20.79%。
方案3:?S11-S12、S22-S31層共同形成一套層系,該層系的厚度為9.88 m,該層系的儲量為104.11萬t;?S21、S32-S52層共同形成另一套層系,該層系的厚度為11.89 m,該層系的儲量為118萬t,根據目前的開采現狀,第1套層系的采出程度為12.59%,第2套層系的采出程度21.30%。
進行層系優化以后可以發現,每一層之間都具有一定的原油儲量,地層的有效厚度和單井儲量也相對較好,層系與層系之間具有一定隔層,可以形成獨立的原油開發系統。
4 ?結?論
在本次研究中,首先對層系優化目前的研究成果進行了簡單分析,指出了目前研究成果的缺點,提出了基于模糊聚類分析方法的層系優化方法,對該種方法的使用步驟進行了簡單介紹,然后以G油藏為例,使用該種方法進行了層系優化,驗證了該種方法的可行性。通過本次研究,可以得出以下兩條結論:
(1)模糊聚類分析方法可以對存在模糊關系的事物進行分析,且這種方法的使用步驟較為簡單,并不需要太專業的知識就可理解,同時,該種方法還具有分類速度相對較快的特點,因此,對于石油領域存在模糊關系的樣本可以使用該方法進行聚類;
(2)使用模糊聚類分析方法對G油藏進行了層系優化,共提出了三種層系優化方案,這三種方案滿足層系優化的基本原則,層系優化以后,每一層之間都具有一定的原油儲量,地層的有效厚度和單井儲量也相對較好,層系與層系之間具有一定隔層,可以形成獨立的原油開發系統,證明該方法完全可行。
參考文獻:
[1]黃志雙. 薩北油田三類油層注聚對象及層系優化組合研究[J]. 大慶石油地質與開發, 2006, 25(8):83-84.
[2]方艷君, 孫洪國, 俠利華, 等. 大慶油田三元復合驅層系優化組合技術經濟界限[J]. 大慶石油地質與開發, 2016, 35(2):81-85.
[3]孫洪國, 周叢叢, 張雪玲, 等. 大慶油田特高含水期三元復合驅層系優化組合方法研究[J]. 長江大學學報(自科版), 2018(9):25-31.
[4]曾雪梅. 北二東開采層系重組改善水驅開發效果試驗研究[D]. 東北石油大學, 2011.
[5]代興斌. 特高含水期薩、葡、高油層井網、層系重構方法研究[D]. 東北石油大學, 2012.
[6]周羽佳. 杏一區薄差油層層系重組及開發效果研究[J]. 長江大學學報(自科版), 2014, 11(5):112-114.
[7]張敏, 于劍. 基于劃分的模糊聚類算法[J]. 軟件學報, 2004, 15(6):858-868.
[8]高新波, 謝維信. 模糊聚類理論發展及應用的研究進展[J]. 科學通報, 1999, 44(21):2241-2251.
[9]湯榮志, 段會川, 孫海濤. SVM訓練數據歸一化研究[J]. 山東師范大學學報(自然科學版), 2016, 31(4):60-65.
[10]梁家政, 薛質. 網絡數據歸一化處理研究[J]. 信息安全與通信保密, 2010(7):47-48.
[11]高新波. 模糊聚類分析及其應用[M]. 西安電子科技大學出版社, 2004:7-8.
[12]何清. 模糊聚類分析理論與應用研究進展[J]. 模糊系統與數學, 1998(2):89-94.
[13]鮑艷, 胡振琪, 柏玉, 等. 主成分聚類分析在土地利用生態安全評價中的應用[J]. 農業工程學報, 2006, 22(8):87-90.
[14]肖新平. 關于灰色關聯度量化模型的理論研究和評論[J]. 系統工程理論與實踐, 1997, 17(8):77-82.
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
