基于VGG-M 網絡模型的前方車輛跟蹤?
2019-02-15 08:28:50劉國輝張偉偉吳訓成宋曉琳溫培剛
汽車工程 2019年1期
劉國輝,張偉偉,吳訓成,宋曉琳,許 莎,溫培剛
(1.上海工程技術大學機械與汽車工程學院,上海 201600; 2.湖南大學,汽車車身先進設計制造國家重點實驗室,長沙 410082)
前言
近年來,基于車載相機的視覺目標跟蹤技術已被成功應用在ADAS(advanced driver assistance systems)上,其對于ADAS系統前方車輛的距離判斷、碰撞預警等具有重要意義。傳統的視覺跟蹤方法主要分為生成式和判別式[1]。生成式的代表性算法有稀疏編碼、在線密度估計和主成分分析等。LU H等[2]使用了一種新穎的pooling校正方法探索目標的部分信息和空間信息,在局部補丁上進行pooling得到的相似性,不僅定位目標更準確,且能適應一定程度的遮擋,該方法有效地利用稀疏系數在目標與背景之間的差異性,降低了跟蹤漂移概率。與之相對地,判別式方法通過訓練分類器來區(qū)分目標和背景,將目標跟蹤轉化為一個二分類問題。文獻[3]中使用隨機森林算法,通過在線學習高置信度的特征來更新目標模型,跟蹤性能表現更加穩(wěn)定。
前兩種方法都依賴于淺層的手工特征,有一定的局限性,無法利用目標的高級語義信息[4],導致其泛化能力不足,往往在復雜場景難以實現穩(wěn)定的跟蹤,如尺度自適應變化、遮擋后復原跟蹤。近年來,深度學習的方法憑借其卓越的性能已經在圖像識別和檢測領域取得了成功。在跟蹤系統中,影響其性能的關鍵在于特征的表達,深度學習因為其深層結構可以提取圖像的高級語義特征,其較強的特征表達能力在目標跟蹤領域有較好的應用潛力。
本文中的跟蹤模型是通過一個卷積網絡的全連接層softmax分類器和在線觀測模型來定位前方車輛,通過常規(guī)更新方案來更新網絡,實現對前方車輛的穩(wěn)定可靠跟蹤。
1 基于深度學習的車輛跟蹤器
將深度學習的方法應用到車載相機的目標實時跟蹤上,主要瓶頸在于短時間內可供在線訓練的樣本不足。WANG N在文獻[5]和文獻[6]中提出了DLT(deep learning tracker)算法,通過線下預訓練獲得物體特征的通用表示,一定程度上減少了目標訓練樣本的需求。但是DLT因線下訓練的數據集分辨率較低,無法學習到足夠強的匹配跟蹤序列的特征表示。2015年在DLT的基礎上提出了SO-DLT(structured output deep learning tracker),該模型使用類似AlexNet的網絡結構,利用圖片本身的結構化信息,直接從概率圖確定目標框的位置。
文獻[7]中使用經過預訓練的VGG-16(visual geometry group)網絡[8],提出 FCNT(fully convolutional networks tracker)跟蹤器,對卷積神經網絡特征在目標跟蹤的性能進行較為深入的研究,提出VGG-16網絡的特征圖可以做定位,且網絡的最后一層(Con5-3①)深層的特征圖具有較高的語義特征,可區(qū)分目標類間的特征差異,Conv4-3①較淺層的特征圖可區(qū)分類內差異,該方法不再把CNN(convolutional neural network)視為黑箱子,充分利用深度神經網絡的結構特點來對目標定位。但是在實際測試中,對遮擋的表現魯棒性不強。文獻[9]中在VGG-19網絡[8]上提取 Conv3-4①,Conv4-4①,Conv5-4①層的特征并結合相關濾波器提出了粗/精式的跟蹤算法,同樣取得了不錯的效果。
2016年文獻[10]中提出MDNet(multi-domain network),運用多維的訓練思路,將每個訓練視頻序列當成一個單獨的域。該方法應用了大量的線下預訓練,而減少了在線訓練的樣本需求。文獻[11]中提出了一種簡單有效的正則化技術branchout,減少了集成學習方法在模型多樣化和訓練樣本中噪聲標簽較少的限制,為深度學習應用在跟蹤領域上提供了一種新的方法。
在文獻[12]中,通過研究不同卷積網絡的深層結構,并對網絡的性能進行比較,確定了重要的實現細節(jié),得出VGG-M的網絡結構具有更快的檢測速度和更強的性能表現。VGG-M網絡是一個中等架構的卷積網絡,其網絡結構見文獻[12]中表1。其良好的目標特征表達能力和合理的網絡架構使其更加適合應用于目標跟蹤領域。本文中在VGG-M網絡特征的基礎上實現前方車輛的穩(wěn)定跟蹤。
2 車輛跟蹤模型結構
2.1 卷積網絡模型
本文中跟蹤模型的特征來自于CNN網絡結構,CNN可以通過訓練學習獲得目標的外部特征,網絡結構如圖1所示,網絡的輸入為107×107 RGB圖像,網絡結構的隱藏層一共5層,包括3個卷積層和2個全連接層,最后一層為softmax回歸模型。該網絡模型在文獻[12]中提出的VGG-M網絡結構的基礎上丟棄了卷積層Conv4和Conv5,全連接層fc4和fc5使用dropout進行正則化,最后一層全連接層fc6即為softmax分類器。除了softmax,其余所有權重層的激活函數都是ReLU(rectified linear unit)。在跟蹤之前,將網絡在ImageNet[13]進行預訓練。
跟蹤器采用較淺層的網絡模型,是因為過深的網絡結構不利于參數訓練,且深層的特征不利于目標的定位,不能完成精確的跟蹤[14]。在線跟蹤過程中,淺層網絡在正向傳播和反向傳播階段可以節(jié)省很多時間,且具有較好的跟蹤性能表現,通過大量跟蹤實驗對比分析發(fā)現,較少的卷積層數可得到更快的跟蹤速度,且由于淺層網絡特征含有更多的空間位置信息,具有更好的定位精度。本文中選擇3層卷積網絡來搭建跟蹤模型。VGG-M不同卷積層下跟蹤性能表現如表1所示。
在車載監(jiān)控的條件下,可以假設前方車輛的目標大小隨著與鏡頭距離的遠近呈現近似的高斯分布[15],于是本文中使用高斯模型,基于上一幀目標框的中心位置在其周圍對當前幀的車輛位置及尺度生成N個候選框Xti(i=1,…,N),針對某一位置,出現新的尺度時,及時對高斯均值和標準差更新。
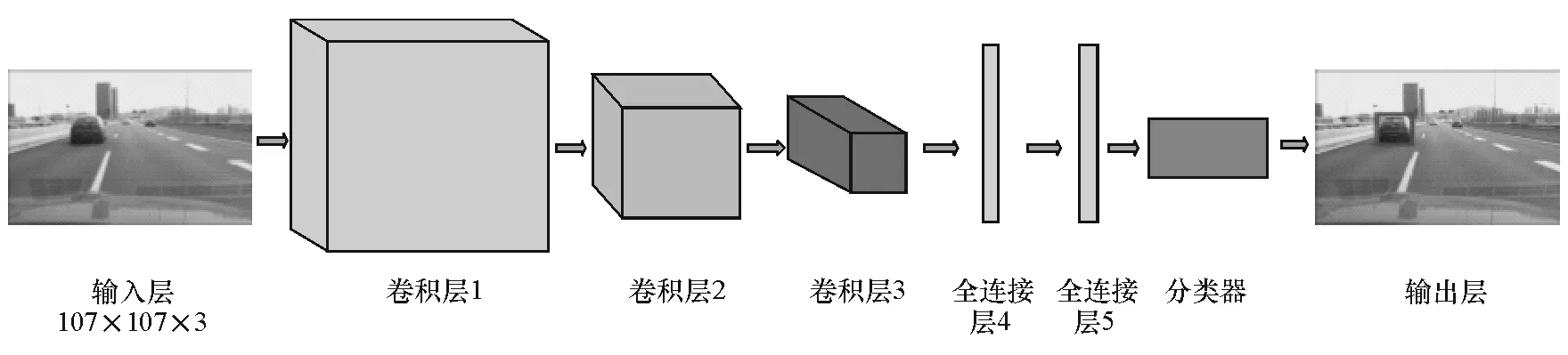
圖1 輸出的特征和圖像層

表1 VGG-M不同卷積層數下的性能比較
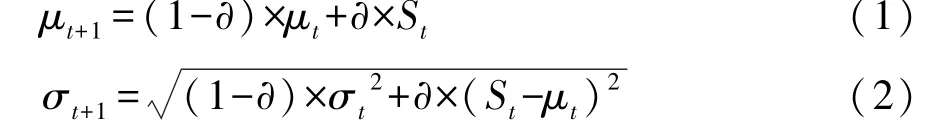
式中:?為學習率;St為第t幀車輛外接矩形框的面積;μt+1和σt+1分別為第t+1幀高斯均值和標準差。車輛的位置可以通過fc6層softmax分類器來估計,分別求的每個候選框Xti(i=1,…,N)的得分來獲得。

通過候選框得分的高低構建一個高質量樣本集,樣本集的每個框用其所在位置分別標記為Ω={wk|k=1,…,K},對于每一個候選框位置wk與其候選框的尺寸共同構建了mini-patch,利用在線觀測模型去估計他們的置信度。
2.2 在線觀測模型
VGG-M網絡應用于跟蹤時,網絡層數的加深,空間信息會被稀釋,從而影響分類器的定位精度,且卷積神經網絡更新的緩慢與滯后特性導致softmax分類器可能會出現誤差。為了提高VGG-M網絡的跟蹤精度,本文中特采用包括一個轉移模型和一個目標框尺度模型的在線觀測模型。該模型來源于在線被動攻擊算法(passive-aggressive algorithm)[16-17]。CNN特征包含輸入圖像的空間結構信息見圖2,通過在目標周圍提取負樣本mini-patches來訓練在線觀測模型。
盛旦老師輕輕敲了下桌子,給了查理一張紙,示意查理念出上面的文字,查理念道:“一張牌可以睡個懶覺,一張牌可以逃學一次,一張牌可以遲到一次……”念完所有的文字,班上就炸開了鍋。
由于一張輸入圖片有大量的負樣本和少量的正樣本,這樣可能會影響訓練模型的質量。為平衡正負樣本數量的差異對模型的影響,構建了一個二分模型解決這個問題,如果第k個mini-patch的中心落在預測框內就定義rt,k=1,否則rt,k=-1。其中Zt表示第t幀的轉移模型,xt,k(k=1,…,K)表示第t幀、第k個樣本的特征。轉移模型通過優(yōu)化函數獲得:

圖2 在線觀測模型訓練樣本
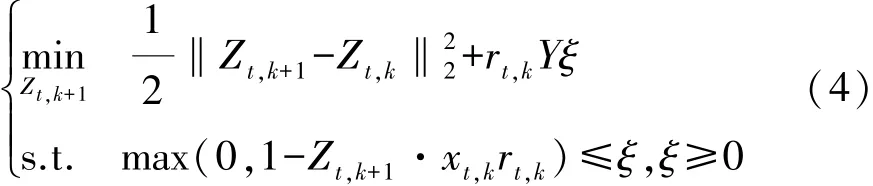
式中若xt,k為正樣本特征時Y=Y+,否則Y=Y-,其中Y+和Y-為經驗參數,是為了減少正樣本與負樣本由于數量上的差異對訓練模型造成的誤差。ξ為松弛變量,其中 Z1=0,Zt,0=Zt,Zt+1=Zt,K。 式(4)為一個凸優(yōu)化問題,可以通過拉格朗日乘子的方法解決。
使用轉移模型 Zt∈?W′×H′×D′計算每一個 minipatch的置信度SZt(Xt,k),每個候選框wk的置信度S(wk,xt,k)通過式(6)計算:

目標框尺度模型是一個被動攻擊的回歸模型,首先對K個mini-patch樣本定義不同的尺寸,回歸值rt,k∈[0,1]由mini-patch的softmax的得分來設定,通過式(7)優(yōu)化函數得到目標框尺度模型:
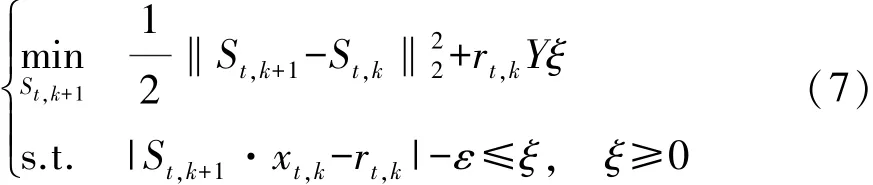
式中:ε為尺度變化的靈敏度,S1=0,St,0=St,St+1=St,k,對于任意一個mini-patch的置信度cSt(xt,k)可通過式(8)計算:

目標定位過程如圖3所示,圖3(a)為在車輛上一幀位置使用高斯模型得到的車輛候選框。首先將候選框輸入卷積網絡softmax分類器,使用一個固定閾值選取置信度較高的候選框(圖3(b)),最后使用在線觀測模型與車輛高置信度樣本響應大小確定車輛的最終位置與尺度(圖3(c))。

圖3 在線觀測模型優(yōu)化目標框位置和尺度流程
算法流程圖如圖4所示。利用VGG-M的特征輔助在線觀測模型對車輛定位。跟蹤過程中,從上一幀跟蹤的結果周圍取正負樣本訓練VGG-M網絡,通過判斷目標是否丟失而使用不同更新策略,提高跟蹤模型對多種工況的魯棒性。

圖4 跟蹤算法流程圖
3 網絡模型訓練
卷積網絡模型的檢測效果一定程度上依賴于訓練樣本的質量,符合正態(tài)分布的樣本可以得到更好的效果。但跟蹤過程中相鄰幀的目標具有相似的運動狀態(tài),太多的相似樣本易產生過擬合的現象,影響卷積網絡模型質量。使用文獻[18]中的方法,用優(yōu)化訓練集的方式去合并樣本。聯合概率分布p(x,y)中,x為訓練樣本的特征圖譜,y為訓練樣本得分。

式中:p(x)為Gaussian Mixture Model(GMM)的概率密度;δy0(y)為訓練樣本的狄拉克函數。p(x)=其中 L 為正樣本組件的總數量,πl(wèi)為不同組件的先驗權重,μl為組件l的期望值,協方差矩陣I使用一個固定矩陣,避免高維樣本空間的復雜的推理計算。高斯混合模型的參數通過EM算法(expectation-maximization algorithm)估計,因為車輛不同尺度的卷積特征的差異性,不同組件呈不同尺度樣本分布。
當有新的樣本xj出現時,通過初始化一個新的部件 Cn,令 πn=λ,μn=xj。 所有正樣本被劃分為{C(1),C(2),…,C(L)}。如果組件的樣本超過最大值X時,就刪除一個候選框得分最小的樣本。當組件的數量超過L時,就合并兩個相識度最高的組件。

式中Ca和Cb為兩個相識度最高的組件。
鑒于從鄰近幀提取的樣本最能體現車輛重新出現時的特征,對樣本生成模型進行了改進,增加一個鄰近部件用來保存最近X個樣本,如圖5所示。若跟蹤出現遮擋的情況,就將鄰近部件作為第L+1個組件作為訓練樣本。當目標出現遮擋時,及時更新網絡避免發(fā)生目標丟失。
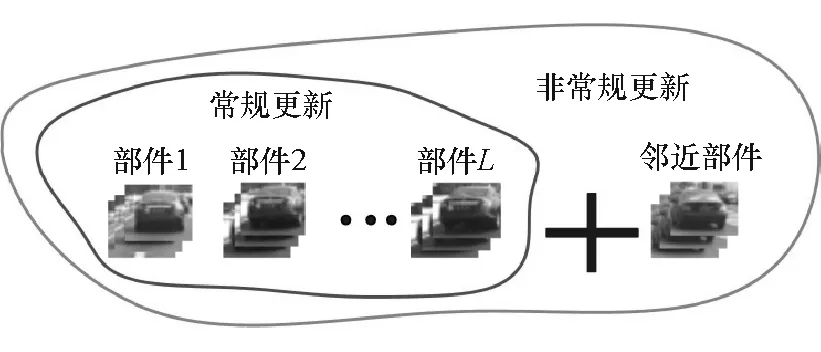
圖5 改進的樣本生成方案
4 網絡自適應更新模型
4.1 非常規(guī)更新
當檢測到新的特征圖譜時(即光照變化、角度變化、遮擋等),為了不丟失跟蹤目標,需要及時更新網絡,通過softmax預測框的置信度來量化,當連續(xù)3幀的預測得分的值均小于0.5時,即時,認定目標發(fā)生遮擋或者丟失,對于丟失目標視頻幀數,停止更新樣本生成模型,避免使用錯誤的樣本訓練分類器導致誤差不斷積累,發(fā)生跟蹤飄移的現象。
4.2 常規(guī)更新
當遠方目標距離本車較近時,其外部輪廓邊界信息較為清晰,單位面積內信息熵增加,softmax分類器的預測會更加準確;相反地,當目標距離本車較遠時,車尾圖像面積較小,內部像素信息熵急劇降低,其表面特征尤其是類內特征差距較小,因此需要動態(tài)提高更新頻率。本文中提出一種自適應更新模型,基于跟蹤輸出框大小和目標框與目標框尺度置信度聯合在線實時調節(jié)更新頻率n。

式中:參數k1,k2為一個常量;St為第t幀目標框的面積。
更新頻率n如果取值太大,跟蹤模型會因為更新不及時而導致中心誤差增加。如果更新頻率較低,平均跟蹤誤差雖然較小,但是持續(xù)的更新會大大降低了圖片跟蹤的幀率。此外大量的實驗表明,當幀率過低時,VGG-M網絡會產生過擬合現象,同樣導致中心誤差增加,如圖6所示。

圖6 自適應更新和固定值更新結果比較
從圖6中可以看到,采用自適應模型更新的方案,更新幀率n不再是一個固定不變的值,而是根據車輛的行駛狀態(tài)和目標框置信度在線選擇,表現出更好的跟蹤性能。
5 實驗結果
改進后樣本生成方法是將正樣本分為L+1個組件的方式,在學習到最近車輛行駛狀態(tài)特征的同時,還保留之前置信度較高的樣本,當車輛出現遮擋時,可重新定位車輛,如圖7所示,實驗證明了該跟蹤算法在遮擋時具有較強的魯棒性。

圖7 目標遮擋時跟蹤結果比較
跟蹤的過程中VGG-M網絡的全連接層參數不斷被更新,使用改進的樣本生成方案后,當車輛發(fā)生遮擋時,可以避免只用最近幾幀的樣本更新網絡模型,從而避免在跟蹤過程中出現目標飄移的現象,在線VGG-M跟蹤器和壓縮跟蹤中心誤差如圖8所示。
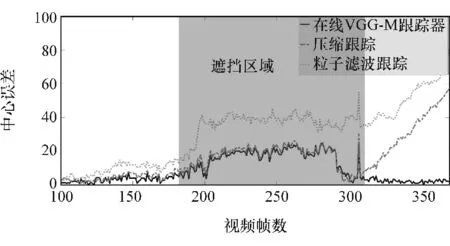
圖8 車輛遮擋時跟蹤誤差比較
跟蹤主要的困難除了遮擋外,還有光線的強度變化造成的跟蹤誤差。因為跟蹤的環(huán)境是復雜多變的,陰雨天、晴天、傍晚等不同光照條件下,都會影響跟蹤的精度,如圖9~圖11所示,常規(guī)更新和非常規(guī)更新兩種更新方式,提高了網絡模型的適應能力。實驗表明,在多種工況下,在線VGG-M跟蹤器都表現出較好的跟蹤性能。
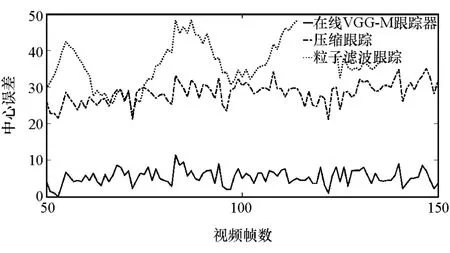
圖9 晴天車輛跟蹤中心誤差比較

圖10 傍晚車輛跟蹤中心誤差比較
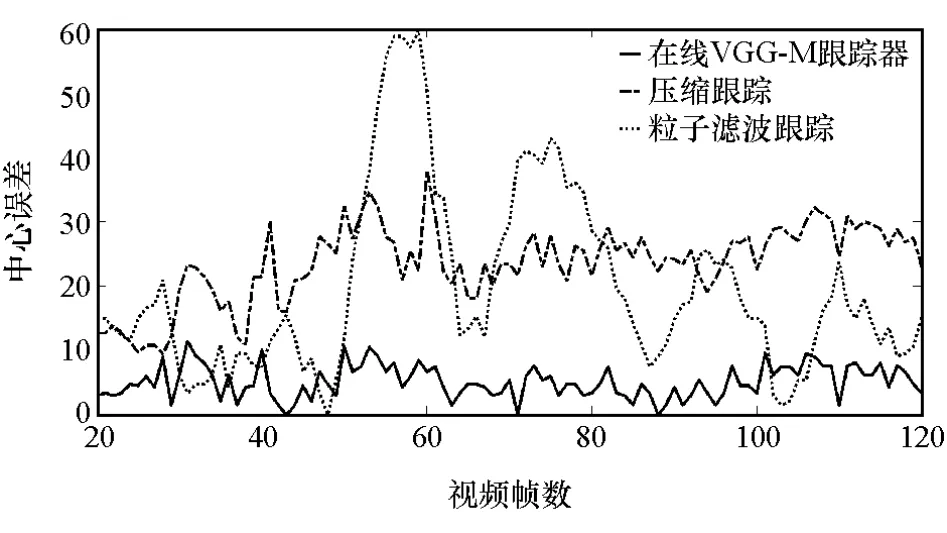
圖11 雨天車輛跟蹤中心誤差比較
實驗證明,在線VGG-M跟蹤器跟蹤精度相比傳統的跟蹤算法更加精確。本文中提出的算法在matlab上使用MatConvNet toolbox,在八核2.2GHz Intel Xeon E5-2660和NVIDIA TESLA K20m GPU上有約30fs的實時跟蹤效果。
6 結論
基于VGG-M網絡提出一種前方車輛跟蹤器,利用卷積網絡強大的特征表達能力對汽車尾部進行定位,通過在線觀測模型對目標中心位置和尺寸進行校正。所提出的跟蹤模型在遮擋等復雜條件下具有較高的跟蹤精度。
實驗表明,將卷積神經應用在跟蹤領域,選擇一個合適的網絡更新頻率對跟蹤性能的提高具有較明顯的積極意義。所采用的自適應跟蹤方案,通過目標的輪廓高寬比、內部信息熵和跟蹤的尺度置信度實時調節(jié)網絡更新頻率,使在線VGG-M跟蹤器具有較理想的跟蹤效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫(yī)藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
