基于規則和N?Gram算法的新詞識別研究
2019-02-20 02:07:48姜如霞黃水源段隆振羅麗娟
現代電子技術 2019年4期
姜如霞 黃水源 段隆振 羅麗娟


關鍵詞: 新詞識別; N?Gram算法; 構詞規則; 中文分詞; 碎片庫; 召回率
中圖分類號: TN911?34; TP391 ? ? ? ? ? ? ? ? 文獻標識碼: A ? ? ? ? ? ? ? ? ? ?文章編號: 1004?373X(2019)04?0166?05
Research on new word recognition based on rules and N?Gram algorithm
JIANG Ruxia, HUANG Shuiyuan, DUAN Longzhen, LUO Lijuan
(School of Information Engineering, Nanchang University, Nanchang 330031, China)
Abstract: A lot of word fragments can be produced and the meanings after word segmentation are very different from original meanings after word segmentation using the current word segmentation tool, and the formation rules of new words have the characteristic of high freedom degree. As a result, the current word segmentation method cannot effectively identify new words in network. The fragment library is constructed combining the formation rules of new word structures on the basis of the ICTCLAS2016 word segmentation system. The Bi?gram and Tri?gram modes are adopted to extract the candidate word strings in the fragment library. The left and right adjacent entropies are used for expansion and filtering of the candidate word strings. A new word recognition method based on rules and N?Gram algorithm is proposed. The results show that the word segmentation accuracy, recall rate and F values of the method are improved. The experimental results show that the new word recognition method can effectively construct the candidate new word sets and improve the effect of Chinese word segmentation.
Keywords: new word recognition; N?Gram algorithm; word formation rule; Chinese word segmentation; fragment library; recall rate
0 ?引 ?言
新詞是一個最近鑄造的發明詞或者詞的重新組合,來源于新事物的產生、方言的引言吸收,簡略詞匯、網絡新詞匯、外來語、舊詞新用等,如“藍瘦”“一帶一路”。 隨著網絡的發達及網絡用戶的增多,新詞在網絡上傳播較快,使用頻率也越來越廣,但對新詞的處理也帶來許多挑戰。目前,很多分詞工具不能識別或是有效識別出這些新詞,對這些新詞分詞后形成字碎片,沒有表現它完整的語義甚至語義完全相反。
目前有的新詞發現[1]方法可大致分為基于語言規則的方法和基于統計學習的方法。鑒于上述兩種方法各自的不足,現在大多數學者都采用統計與規則相結合的方法,從而改進新詞發現結果。
霍帥等提出基于統計的詞關聯性信息與統計特征與詞法特征相結合的新詞發現方法[1]。林自芳等首先進行重復串查詢,之后結合詞內部模式的特征對位置成詞的概率和首尾單字成詞改進方法,最后進行統計[2]。周超等首先對微博語料進行分詞,將在兩停用詞間的相鄰字串兩兩組合,根據組合后的字串頻率統計取得新詞候選串,再通過組合成詞規則進行篩選獲得候選新詞,最后通過詞的鄰接域變化特性去除垃圾串獲得新詞[3]。
1 ?相關技術分析
1.1 ?候選字串結構制定規則
根據詞語模式可知詞語的長度大多介于2~4之間,因此本文提取的新詞候選字串為二元組、三元組、四元組這三種類型。在碎片詞中根據新詞候選字串組成形式,二元組新詞候選字串只有一種組合形式:“單字”+“單字”;三元組新詞候選字串,有三種組合形式:“二字詞+單字”“單字+二字詞”“單字+單字+單字”;四元組新詞候選字串,有五種組合形式:“單字+單字+單字+單字”“單字+單字+二字詞”“單字+三字詞”“二字詞+單字+單字”“三字詞+單字”。形成碎片庫序列MC的獲取規則如下:
1.1.1 ?單 ?字
1) 當連續單字碎片為n=1,若該單字碎片下一個編號的詞是一個二字詞或者三字詞,則將它們加入到碎片庫MC中;
2) 當連續單字碎片為n=2,若該單字碎片下一個編號的詞是一個二字詞,則將它們加入到碎片庫MC中;
3) 當連續單字碎片為n>2,則該連續單字碎片加入到碎片庫MC中;
4) 當與其連續的上一個編號的詞是一個單字且與其連續的下一個編號的詞是一個二字詞,則將它們加到碎片庫MC中;
5) 當與其連續的上一個編號的詞是一個二字詞且與其連續的下一個編號的詞是一個單字,則將它們加到碎片庫MC中。
1.1.2 ?二字詞
若與其連續的上兩個編號的詞是兩個單字或其連續的下兩個編號的詞也是單字,則將它們加到碎片庫MC中。
1.1.3 ?三字詞
當與其連續的上一個編號的詞是一個單字或者與其連續的下一個編號的詞也是一個單字,則將它們加到碎片庫MC中。
當遇到的是單字、二字詞或者三字詞,不存在與其連續編號的詞,則跳到下一個編號的詞開始判斷。
1.2 N?Gram統計模型
N元統計模型[4]的主要思想是:一個單詞的出現與N?Gram模型建立在一種假設前提下,即假設第n個詞的出現只與前面n-1個詞相關,并且與其他任何詞都不相關,得到的各個詞出現的概率的乘積就是整句的概率。
這種方法隨著i的增大,其存在兩個致命的缺陷:一個缺陷是wi的歷史基元增多,不可能實用化;二是數據稀疏嚴重。
為了解決wi的歷史基元增多,不可能實用化引入了馬爾科夫[5]假設:一個詞的出現僅僅依賴于它前面出現的一個或者有限的幾個詞。
如果一個詞的出現僅僅與它前面出現的一個詞有關稱之為二元Bi?Gram。如果一個詞的出現僅僅與它前面出現的兩個詞有關稱之為三元Tri?Gram。
為了得到[Pwiw1,w2,…,wi-1],采用一種簡單的估計方法:最大似然估計。即可得到: ? [Pwiw1,w2,…,wi-1=C(w1,w2,…,wi)C(w1,w2,…,wi-1)] (1)
式中,[Cw1,w2,…,wi]是統計序列[w1],[w2],…,[wi-1]出現在語料庫中的次數。
而對于數據稀疏這個問題,需要進行數據平滑(Data Smoothing)處理。數據平滑的目的有兩個:一個是使所有的N?Gram概率之和為1;二是使所有的N?Gram概率都不為0。
較為常用的平滑技術主要包括:Jelinek?Mercer的方法、Katz的方法、Church?Gale的方法。本識別方法使用的平滑技術是Katz[6]平滑模型:Back?off Model,該技術優點是參數較少可以通過計算得出,結果也更接近實際概率分布。該技術的思想是當一個N元Gram模型對[(wi-n+1,w2,…,wi)]詞序列出現的概率為0時,將按照一個折扣估計退回到低元模型,并按照[Pwiwi-n+1,w2,…,wi]的比例分配為出現的N元模型對。
[Pwiwi-n+1,…,wi-1=discounted*Cwi-n+1,…,wiCwi-n+1,…,wi-1] ? ? (2)
[βwiwi-n+1,…,wi-1= ? ? ? 1-Cwi-n+1,…,wi-1>0Pwiwi-n+1,…,wi-11-Cwi-n+2,…,wi-1>0Pwiwi-n+2,…,wi-1] (3)
1) 當[Cwi-n+1,…,wi>0]時,則:
[Pwiwi-n+1,w2,…,wi-1=P(wi)Pwiwi-n+1,…,wi-1] (4)
2) 當[Cwi-n+1,…,wi=0]時,則:
[Pwiwi-n+1,w2,…,wi-1=βwiwi-n+1,…,wi-1Pwiwi-n+2,…,wi-1] (5)
結合式(2)~式(5)可以得到基于N?Gram模型分詞算法的最佳切分輸出方式。將[s=(wi-n+1,w2,…,wi)]詞序列的最佳切分輸出方式代入到式(1),推導可得如下公式:
[Ps=argmaxMi=1mPwiwi-n+1,…,wi-1] ? (6)
在實際計算中,為防止機器誤差將很小的概率值當作零來處理,通常采用負對數處理的方式將問題轉化為求極小值問題,具體公式為:
[P′s=-ln Ps=argminMi=1mlnC(wi-1,wi)C(wi-1)] (7)
1.3 新鄰接熵
鄰接熵一般用于統計方法的新詞發現。使用鄰接熵計算一對詞之間的左熵和右熵,熵越大,字符串成詞概率越大,越有可能是一個新詞。
左鄰接熵:
[HLx=-p(ax)log p(ax)] ? (8)
右鄰接熵:
[HRx=-p(bx)log p(bx)] ?(9)
式中: [p(ax)]表示a為候選詞x的左鄰接字符的概率;[p(bx)]表示b為候選詞x的右鄰接字符的概率。
2 ?詞識別
新詞不同于普通詞的構成結構,詞語組成比較自由,并沒有嚴謹的遵循傳統語法結構。因為單純的基于規則的方法,制定規則非常耗時,而且可移植性差,而單一的N?Gram模型移植性好,但是在大規模的數據中計算量大,所以本文提出了基于新詞結構制定規則和N?Gram方法的新詞識別方法。主要步驟如下:
步驟1:通過對預處理文本中的分詞碎片進行處理,得到候選新詞集合。
在加入碎片庫MC過程中把每個文本中連續編號組成一個碎片子集序列FS,根據上述規則可知,FS是大于2個詞的詞序列。
例如:“第一/遍/可能/還/一知半解/不明/覺/厲”。根據規則可以得到2個FS :“第一遍可能”和“不明覺厲”。
基于N?Gram模型碎片庫MC提取FS的候選字串算法如下:
算法:候選新詞提取算法。
輸入:MC//碎片庫序列;FS//碎片子集序列;
輸出:CS//候選新詞集合。
過程:
1) 在碎片庫序列MC中,根據關鍵詞候選串制定規則提取FS作為二元的Bi?Gram和三元的Tri?Gram模式的處理對象;
2) 先統計每個FS中每個詞的頻數,之后做歸一化處理,最后利用Bi?Gram模式根據式(6)分別計算每個FS的二元組、三元組和四元組字符串的概率。把字符串和概率保存到數據庫中;
3) 根據式(2)計算每一種分詞結果的概率,選擇最優結果,即利用式(6)求出概率P(s)的極大值,若是很小概率則使用式(7)計算概率。把所有字符串的概率按由大到小排序,選取排在前面一半的字符串作為候選字串CS1;
4) 利用Tri?Gram模式,重復過程2)、過程3),得到候選字串CS2,最后選取同時存在與CS1和CS2中的字符串作為候選新詞集合CS。
步驟2:采用鄰接熵對候選新詞集合進行外部成詞概率的篩選。
候選新詞為二元組或四元組,計算左右鄰接熵均大于閾值[7],加入新詞集合。
候選新詞為三元組,首先計算左鄰接熵,是否大于閾值;若大于閾值,再對右鄰接熵進行計算,把左右鄰接熵均大于閾值的候選新詞加入新詞集合,否則向右擴展一個字符,再次計算右鄰接熵;否則向左擴展一個字符,再次計算左鄰接熵。
本文提出的新詞識別方法具體流程如圖1所示。
3 ?實驗設計與結果
3.1 ?數據采集與預處理
以新浪微博為實驗平臺,主要以新浪微博的API接口,并結合網絡爬蟲技術,對2016年8月15日—9月5日期間關注的9個熱點話題相關的微博數據進行采集。關注的7個熱點話題包括:王寶強離婚、里約奧運、傅園慧洪荒之力、大學生徐玉玉電信詐騙案、王健林的目標、三星Note 7、杭州G20。
對采集到各個話題相關的微博信息進行預處理,通過數據分析發現微博數據中包含各式各樣的垃圾數據,這些垃圾數據對話題發現的準確度產生負面影響。把篩選后的數據保存到數據庫中,主要包括微博用戶名、用戶的關注人數、用戶的粉絲數、微博發布時間、微博文本、微博評論等。oracle數據庫中,微博條數共102 104,用戶人數96 803,部分微博數據。把每條微博評論的內容放到每個TXT文檔中,文檔命名為微博編號。
對所有微博文本進行預處理:微博數據用ICTCLAS2016分詞系統分詞后,結合哈爾濱工業大學和百度停用詞庫,去除停用詞,如“不管”“了”“嗎”等后,把留下的詞語保存到詞語分詞表中的同時進行詞頻統計,為提取候選新詞做準備。文本預處理后保存,對前三個微博文本處理結果如表1所示(加位置編號)。
3.2 ?實驗過程與結果分析
評價中文分詞效果時,對評價指標召回率和精確度的具體定義如下:TP為正確切分的詞語數;TP+FP為切分出來的詞語總數;TP+FN為參考結果中的詞語總數。引入準確率P和召回率R的概念和綜合評價指標F1?Measure,有:
[P=TPTP+FP] ?(10)
[R=TPTP+FN] ? (11)
[F1?Measure=2×P×RP+R] ?(12)
式中:TP預測為正,實現為正;FP預測為正,實現為負;FN預測為負,實現為正;TN預測為負,實現為負。
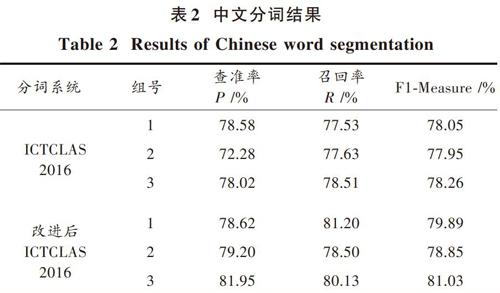
本次實驗抽取9 000條微博文本分三組作為輸入,分別使用本文算法和中文ICTCLAS2016分詞系統對其做分詞處理,根據評價指標得到的結果如表2所示。
分析表2可知,本文分詞算法在查準率、召回率和F1?Measure值上都要比使用中文ICTCLAS2016分詞系統分詞更好。
下面是對一條微博兩種方法的不同結果對比:
1領導叫你和另外兩位同志一起負責一個項目,他們兩個人有沖突,請問你怎么協調落開展工作?
2傅園慧里約奧運會走紅微博粉絲漲700萬洪荒之力,表情包瘋轉請問你怎么看?
3小趙出差在外還要一周才能回來,他母親生病,組織上特意派你去探望,請問你見到他母親會怎么說。
ICTCLAS2016分詞系統:
1/領導/叫/你/和/另外/兩/位/同志/一起/負責/一個/項目/,/他們/兩/個/人/有/沖突/,/請問/你/怎么/協調/落/開展/工作/?
2/傅/園/慧/里/約/奧運會/走紅/微/博/粉絲/漲/700萬/洪荒/之/力/,/表情/包/瘋/轉/請問/你/ 怎么/看/?
3/小/趙/出差/在/外/還/要/一/周/才/能/回來/,/他/母親/生病/,/組織/上/特意/派/你/去/ 探望/,/請問/你/見到/他/母親/會/怎么/說/?
本文算法:
1/領導/叫/你/和/另外/兩位/同志/一起/負責/一個/項目/,/他們/兩個人/有/沖突/,/請問/你怎么/協調/落/開展/工作/?
2/傅園慧/里約/奧運會/走紅/微博/粉絲/漲/700萬/洪荒之力/,/表情包/瘋/轉/請問/你怎么/看/?
3/小/趙/出差/在外/還要/一周/才能/回來/,/他/母親/生病/,/組織/上/特意/派你去/ 探望/,/請問/你/見到/他/母親/會/怎么/說/?
通過分析可知,使用本文第2節中的新詞識別方法處理“表情/包”“洪荒/之/力”“兩/個/人”“傅/園/慧”“里/約”,可以把候選新詞“表情包”“洪荒之力”“兩個人”“傅園慧”“里約”抽取出來。
4 ?結 ?語
本文利用規則和統計相結合的方法識別候選新詞,給出候選子串結構制定規則,采用鄰接熵選取新詞。對于新詞和人名ICTCLAS2016分詞系統沒有識別出來,而本文算法識別出來了,但是會把不同的字組合在一起形成錯誤的詞語。整體而言,本文分詞算法性能較高,新詞發現結果較好。
參考文獻
[1] 霍帥,張敏,劉奕群,等.基于微博內容的新詞發現方法[J].模式識別與人工智能,2014,27(2):141?145.
HUO Shuai, ZHANG Min, LIU Yiqun, et al. New words discovery in microblog content [J]. Pattern recognition and artificial intelligence, 2014, 27(2): 141?145.
[2] 林自芳,蔣秀鳳.基于詞內部模式的新詞識別[J].計算機與現代化,2010(11):162?164.
LIN Zifang, JIANG Xiufeng. A new method for Chinese new word identification based on inner pattern of word [J]. Computer and modernization, 2010(11): 162?164.
[3] 周超,嚴馨,余正濤,等.融合詞頻特性及鄰接變化數的微博新詞識別[J].山東大學學報(理學版),2015,50(3):6?10.
ZHOU Chao, YAN Xin, YU Zhengtao, et al. Weibo new word recognition combining frequency characteristic and accessor variety [J]. Journal of Shandong University (Natural science), 2015, 50(3): 6?10.
[4] MILLER D R H, LEEK T, SCHWARTZ R M. BBN at TREC7: using hidden Markov models for information retrieval [C]// Proceedings of the 7th Text Retrieval Conference. [S.l.: s.n.], 2008: 80?89.
[5] MANNING C D, SCHUTZEH H.統計自然語言處理基礎[M].苑春法,李慶中,王昀,等譯.北京:電子工業出版社,2005.
MANNING C D, SCHUTZEH H. Foundations of statistical natural language processing [M]. YUAN Chunfa, LI Qingzhong, WANG Jun, et al, translation. Beijing: Publishing House of Electronics Industry, 2005.
[6] HARB B, CHELBA C, DEAN J, et al. Back?off language model compression [C]// Proceedings of 10th Annual Conference of the International Speech Communication Association. Brighton: [s.n.], 2014: 352?355.
[7] 蘭沖.基于統計規則的中文分詞研究[D].西安:西安電子科技大學,2011.
LAN Chong. Research on Chinese word segmentation based on statistical rules [D]. Xian: Xidian University, 2011.
[8] 夭榮朋,許國艷,宋健.基于改進互信息和鄰接熵的微博新詞發現方法[J].計算機應用,2016,36(10):2772?2776.
YAO Rongpeng, XU Guoyan, SONG Jian. Micro?blog new word discovery method based on improved mutual information and branch entropy [J]. Journal of computer applications, 2016, 36(10): 2772?2776.
[9] 周霜霜,徐金安,陳鈺楓,等.融合規則與統計的微博新詞發現方法[J].計算機應用,2017,37(4):1044?1050.
ZHOU Shuangshuang, XU Jinan, CHEN Yufeng, et al. New words detection method for microblog text based on integrating of rules and statistics [J]. Journal of computer applications, 2017, 37(4): 1044?1050.
[10] 張海軍,李勇,閆琪琪.一種基于海量語料的網絡熱點新詞識別方法[J].計算機工程與應用,2015,51(5):208?213.
ZHANG Haijun, LI Yong, YAN Qiqi. Method of new Chinese words identification from large scale network corpora [J]. Computer engineering and applications, 2015, 51(5): 208?213.
[11] 杜麗萍,李曉戈,于根,等.基于互信息改進算法的新詞發現對中文分詞系統改進[J].北京大學學報(自然科學版),2016,52(1):35?40.
DU Liping, LI Xiaoge, YU Gen, et al. New word detection based on an improved PMI algorithm for enhancing segmentation system [J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2016, 52(1): 35?40.
[12] 邢恩軍,趙富強.基于上下文詞頻詞匯量指標的新詞發現方法[J].計算機應用與軟件,2016,33(6):64?67.
XING Enjun, ZHAO Fuqiang. A novel approach for Chinese new word identification based on contextual word frequency?contextual word count [J]. Computer applications and software, 2016, 33(6): 64?67.
[13] 黃軒,李熔烽.博客語料的新詞發現方法[J].現代電子技術,2013,36(2):144?146.
HUANG Xuan, LI Rongfeng. Discovery method of new words in blog contents [J]. Modern electronics technique, 2013, 36(2): 144?146.
