基于詞向量的圖書館圖書推薦模式研究
2019-02-20 14:26:10楊志明
現代商貿工業 2019年4期
關鍵詞:圖書館
楊志明

摘要:個性化推薦算法中,傳統的協同過濾算法通常存在數據稀疏和計算復雜的問題,造成實際推薦效果不夠理想。據此,針對圖書館圖書推薦問題,提出了基于詞向量的圖書推薦算法,實驗中通過和傳統的協同過濾算法對比,基于詞向量的方法不管是在計算圖書相似性還是實際推薦效果均顯著提升。
關鍵詞:圖書館;推薦系統;詞向量;word2vec;協同過濾
中圖分類號:TB文獻標識碼:Adoi:10.19311/j.cnki.16723198.2019.04.093
1引言
個性化推薦中,基于內容的推薦算法、基于協同過濾的推薦算法和混合推薦算法方法最為常用。而在數字圖書館圖書推薦中,基于協同過濾和關聯規則的推薦算法是最為常用推薦算法。但是由于大多數高校圖書館沒有讀者對圖書的評分信息,導致傳統的協同過濾算法面對數據稀疏和計算復雜的問題。而基于關聯規則的推薦算法則存在關聯規則不容易發現的問題,最終導致兩種算法在實際的推薦中效果均不理想。因此本文提出基于詞向量的方法計算學生與圖書的相似度從而幫助優化推薦系統的推薦結果。
2傳統協同過濾算法
傳統的協同過濾算法通過對學生借閱記錄的挖掘發現學生借書的偏好,基于不同的偏好按照相似性對學生或者圖書進行劃分從而推薦相似的圖書。協同過濾算法又可分為基于鄰居的協同過濾算法和基于模型的協同過濾算法,基于鄰居的協同過濾又分為兩類,分別是基于用戶的協同過濾算法,和基于物品的協同過濾算法。
基于用戶的協同過濾,通過挖掘學生借閱記錄,來度量學生之間的相似性,找到“鄰居”,基于學生之間的相似性做出推薦圖書。基于物品的協同過濾的原理和基于用戶的協同過濾類似,只是在計算鄰居時采用物品本身,不是從用戶的角度,即根據借閱記錄找到相似的圖書,然后根據學生的歷史偏好,給該學生推薦相似的圖書。在數字圖書館圖書推薦中,由于用戶特征數據、行為數據的缺失,導致傳統的協同過濾算法面臨數據稀疏等問題,最終導致推薦效果不理想。本文提出基于word2vec的方法計算學生與圖書特的相似度從而幫助優化推薦系統的推薦結果的方法。
3詞向量和Skip-gram模型
word2vec是 Google 的Mikolov 等人提出的一種分布式詞向量模型,包括 Skip-gram 和 CBOW,模型結構如圖1所示。
4.2實驗設計和結果分析
4.2.1實驗過程
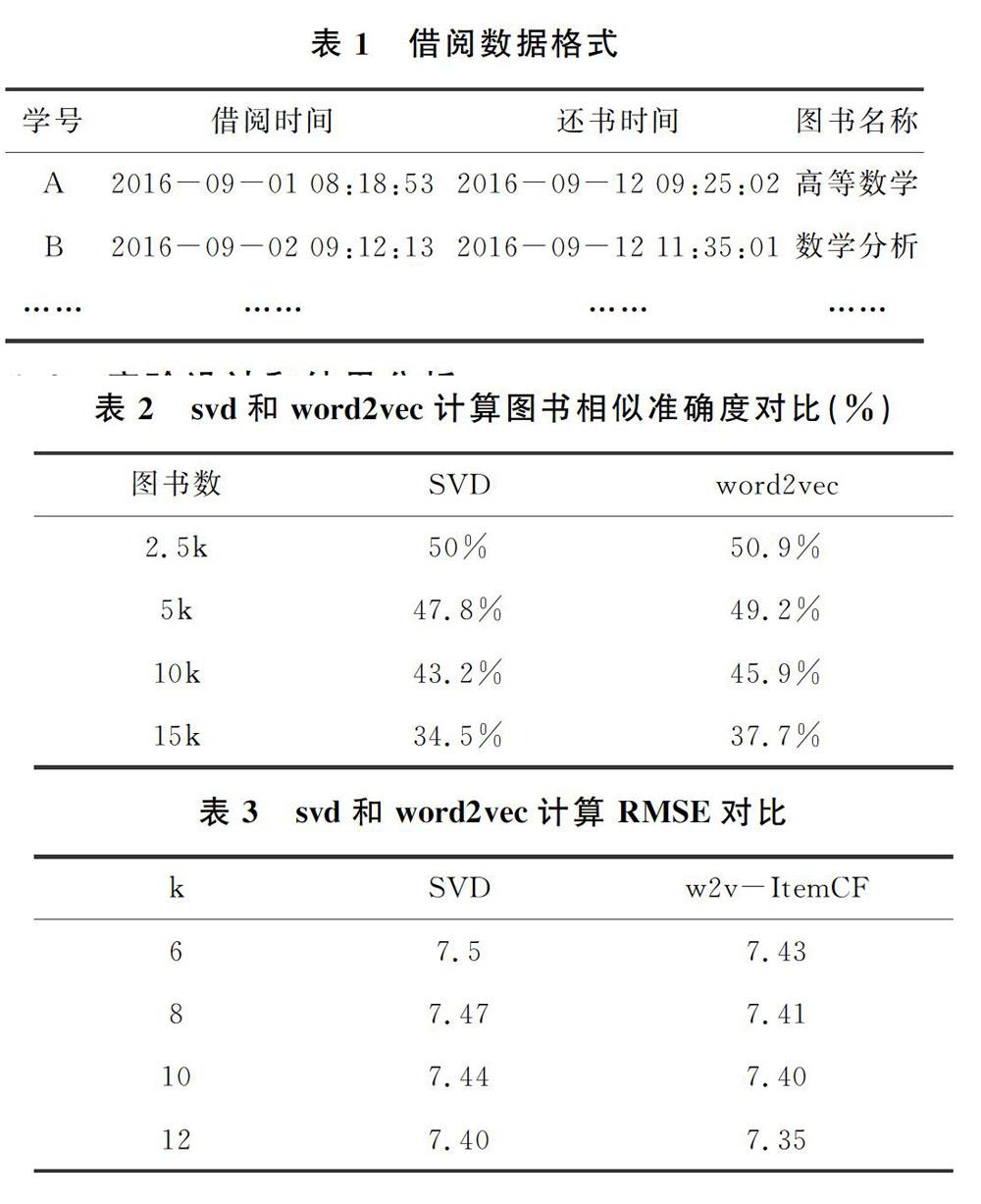
傳統的協同過濾算法依賴的讀者圖書評分數據,高校圖書館后臺管理系統中并不存儲產生讀者對圖書的評分數據,而生成讀者圖書評分數據可根據本文所采用的數據集中讀者借閱信息表來生成,采用目標讀者對目標圖書的總借閱天數來代表讀者對該圖書的評分,其中0在矩陣中表示讀者未借閱過該圖書,并且對評分進行歸一化處理。
為了評估詞向量方法在計算圖書相似性的有效性,本章采取計算目標圖書A與其緊鄰的K本圖書在圖書類別上的一致性的方法來評估,其中每本圖書的類別按照《中圖法》的標準確定。如O212.6/23的分類為O21,通過word2vec方法計算的該書最相近的4本圖書為O211.64/15,O212.4,O212.1/94,O241.6/48-1,幾本書的分類分別為O21,O21,O21,O24,采取投票法確定這幾本書的最終分類為O21,和目標圖書的分類一致。實驗中我們采取word2vec以及基于SVD的協同過濾兩種方法計算相近圖書,在不同近鄰數k(k=6,8,10,12)下對不同數目的圖書進行實驗。
本文基于詞向量的協同過濾方法主要思路把圖書名稱看作單詞,以學生借閱的圖書看作句子,利用 word2vec 模型構建圖書的向量空間。具體地,把學生的記錄按照7:3的比例隨機的分訓練集和測試集兩部分,分別構建基于word2vec的物品協同過濾模型(w2v-ItemCF)、基于SVD的協同過濾模型(SVD),在測試集上根據學生的歷史借閱圖書推薦相似的圖書從不同方面評估推薦效果。
評估推薦算法推薦效果的方法有很多,主要分為離線實驗、線上測試對比、用戶調查等幾種方式。線上測試通常是采取線上A/B測試的方式對效果進行評估,而用戶調查則是通過科學的調查方法,比如問卷、訪談等形式去估計評估效果,本文采用離線測試的方法對推薦效果進行對比。具體地,如文獻[1],評估推薦效果的常用指標有用戶滿意度、預測準確度、覆蓋率、多樣性、新穎度、驚奇度、信任度、健壯性等。本文由于是采取離線實驗的方式,主要從評分預測RMSE來評估推薦系統。
4.2.2實驗結果
表2是在近鄰數為10下分別利用word2vec以及SVD計算目標圖書和近鄰圖書類別一致性的對比結果,結果顯示基于word2vec的方法在不同數量圖書下計算的準確度均比SVD的方法高。 表3是兩種方法在訓練集上的誤差情況,可以看出基于word2vec的方法在預測誤差也明顯小于SVD的方法。
5結論
本文針對數字圖書館圖書推薦問題,針對只有借閱記錄的數字圖書館,傳統的協同過濾算法存在數據稀疏問題,針對此問題提出了基于詞向量的物品推薦算法。經過實驗對比顯示基于詞向量的方法在圖書相似性計算以及實際推薦的效果均好于傳統的SVD方法。
參考文獻
[1]項亮.推薦系統實踐[M].北京:人民郵電出版社,2012.
[2]王飛,楊國林.高校圖書館個性化推薦服務算法研究[J].內蒙古師大學報(自然漢文版),2015,44(6):802807.
[3]宋楚平.一種改進的協同過濾方法在高校圖書館圖書推薦中的應用[J].圖書情報工作,2016,60(24):8691.
[4]Mikolov T,Chen K,Corrado G,et al.Efficient Estimation of Word Representations in Vector Space[J].Computer Science,2013.
[5]Ozsoy M G.From Word Embeddings to Item Recommendation[Z].2016.
猜你喜歡
發明與創新(2021年6期)2021-03-10 07:13:54
小學科學(學生版)(2020年4期)2020-05-21 07:30:50
瘋狂英語·新悅讀(2019年10期)2019-12-13 09:02:24
文苑(2019年20期)2019-11-16 08:52:12
幽默大師(2019年5期)2019-05-14 05:39:38
小學生優秀作文(低年級)(2019年5期)2019-04-25 13:13:22
幼兒畫刊(2018年11期)2018-12-03 05:11:44
文苑(2018年17期)2018-11-09 01:29:40
小太陽畫報(2018年1期)2018-05-14 17:19:25
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
