基于高光譜圖像技術的小麥種子分類識別研究
2019-02-25 08:21:00姚傳安蔣夢夢姬豫航李華杰
麥類作物學報 2019年1期
張 航,姚傳安,蔣夢夢,姬豫航,李華杰
(1.河南農業大學機電工程學院,河南鄭州 450002;2.西安電子科技大學數學與統計學院,陜西西安 710126)
小麥為我國北方主要糧食作物,其產量豐欠關系國計民生,種子對產量的影響可達40%以上[1]。因此,小麥種子的鑒別分類對糧食生產意義重大[2]。隨著計算機技術和識別算法的發展,具有快速無損檢測特點的機器視覺技術、近紅外光譜分析技術和高光譜圖像技術在種子檢測中得到了廣泛的應用[3-5]。
高光譜圖像技術具有圖像和光譜信息合一的特點,在種子檢測中其圖像信息可以顯示種子外部形態的特征,光譜信息可反映種子內部蛋白質、淀粉、含氫基團等物質含量,因而可利用該技術快速實現種子的鑒別和分類[6]。如在少波段下融合光譜與圖像特征信息,運用多次遞進無信息變量消除算法和偏最小二乘投影分析法(MP-UVE-PLS)建立分類識別模型,實現了單粒水稻種子的識別[7],但較少的波段可能會丟失一部分光譜信息,影響分類精度;以不同波段下圖像的熵作為分類特征,通過偏最小二乘判別分析法(PLS-DA)實現了多類玉米種子的純度識別[8];應用支持向量數據描述方法(SVDD)可較好解決玉米種子新類別樣本的識別問題[9-10];通過全波段和特征波長分別建立偏最小二乘判別分析(PLS-DA)模型,實現了水稻種子活力分級[11];利用最小二乘支持向量機(LS-SVM)和最小二乘判別分析法(PLS-DA)算法對單粒小麥高光譜圖像中的光譜信息建立分類模型,實現了單粒小麥在強筋與弱筋、強筋與中筋不同類型的二分類識別,并且還發現小麥胚區域的光譜信息用于分類效果較好[12],但其僅實現了強筋、中筋、弱筋3個單籽粒小麥類型之間的分類,沒有實現多種小麥種子多籽粒之間的分類。
本研究基于小麥種子的近紅外(NIR)波段,本著盡量利用全波段光譜信息的原則,在NIR條件下對多種各自堆疊擺放的光譜信息,建立兩種種子擺放方式下用于小麥種子分類識別的PCA-SVM模型,并從三個品種分類開始不斷優化改進模型,再擴展到四個品種、六個品種等多類種子分類,以期實現多種小麥種子多籽粒的便捷高效分類識別。
1 材料與方法
1.1 實驗材料
實驗小麥種子選取河南地區主要種植的品種,由國家小麥工程技術研究中心提供,包括矮58、淮麥0360、開麥20、中優9507、周麥27、周麥22等6個品種以及實驗備用小麥品種洛麥18。每種小麥種子去除殘粒、過于干癟粒和雜質,并保證大小正常。每類小麥種子純度均達到98%。將實驗種子分別裝在標記好的密封小塑料袋中置于5攝氏度恒溫空間中保存。
1.2 高光譜圖像采集儀器
高光譜采集儀器采用芬蘭SPECIM公司的SisuCHEMA高光譜成像工作站,其主要包括顯示器、暗箱和線性位移平臺,線光源為SPECIM特制擴散線性光源單元(Dolan JennerIndustries Inc.Finland),SPECIM PFD-65-V10E 成像光譜儀(Spectral Imaging Ltd.Oulu,Finland)、C-mount 成像鏡頭OLES30(Specim,Spectral Imaging Ltd.Oulu,Finland)以及內置光譜采集存儲軟件。其中線性平臺為全黑背景平臺,可采集的最大樣品尺寸為200 mm×300 mm×45 mm(W×L×T),光譜分辨率為3 nm。為保證高光譜圖像采集合適,經過多次調試將物鏡高度設置為 21 cm,曝光時間設置為300 ms,平臺移動速度設置為3 cm·s-1。高光譜圖像用ENVI4.8軟件進行處理,后期數據處理以及模型建立采用MATLAB2012b軟件。
采集高光譜圖像時,由于暗電流、光源光強波動以及環境的影響會對高光譜實驗數據的采集帶來一定的干擾,為了減除噪聲帶來的誤差影響,每次高光譜數據采集后都進行黑白板校正[13]。
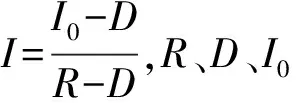
1.3 高光譜采集方式
為了解種子擺放方式對分類的影響,采集高光譜數據時設置兩種種子擺放方式:整齊式和堆疊式。整齊式是將小麥種子整齊排列,鑒于載物移動平臺的尺寸,為保障數據有效,種子擺放排列成12行,每行7粒,共計84粒種子,種子間間隔5 mm左右;堆疊式是將大約300粒左右種子盡量不重疊地聚攏擺放在移動平臺上形成一個半徑5 cm左右的圓形。對兩種擺放方式分別采集VNIR(400~1 000 nm)和NIR(900~1 700 nm)兩種高光譜數據。擺放方式如圖1所示。
2 高光譜數據處理和模型介紹
2.1 提取光譜圖像中的感興趣區域
選擇小麥種子感興趣區域(region of interest,ROI),采集高光譜圖像數據。對高光譜圖像中每粒種子靠近胚乳部位提取20個像素點(4×5)的矩形ROI作為一個實驗樣本。其中,整齊式每類種子采集84個樣本,堆疊式每類種子遵從五點采樣原理共采集100個ROI樣本。ROI提取如圖1和圖2所示。
2.2 感興趣區域光譜數據處理
在NIR下光譜數據共有224個波段,每粒樣本種子提取20個像素點的ROI。將每個波段作為一個列向量,每個像素點作為一個行向量,生成各個像素點在每個波段下的光譜反射率值矩陣。每個像素在全部波段下共產生244個光譜反射率值,則每粒種子提取的感興趣區域光譜反射率值共有20×224個。
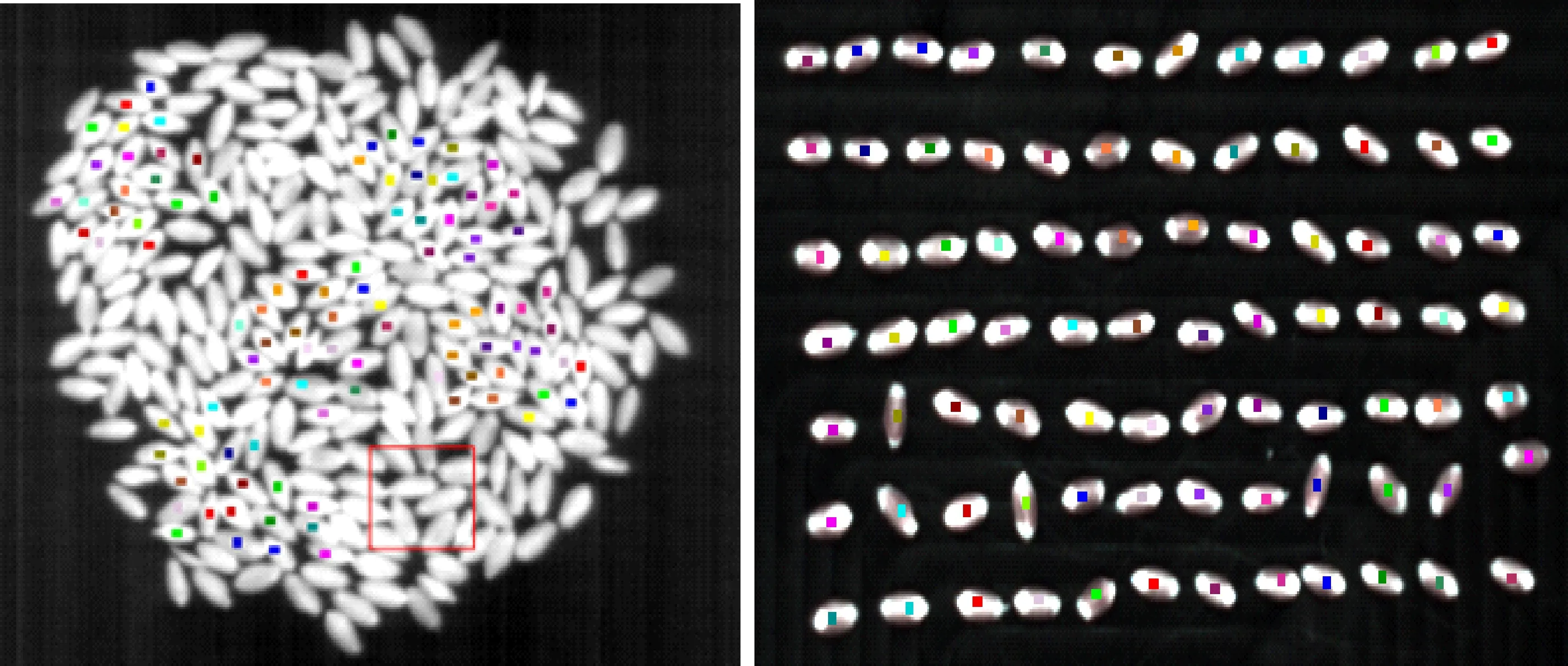
圖1 兩種采樣擺放方式及ROI提取

圖2 4×5矩形ROI的提取示意圖
整齊式擺放的每類小麥種子提取84個樣本的感興趣區域,可生成一個1 680×224的光譜反射率值矩陣。堆疊式擺放的每類小麥種子提取100個樣本的感興趣區域,可生成一個2 000×224的光譜反射率值矩陣。對每粒種子的20個像素點在各個波段下分別求平均值,則整齊和堆疊兩種擺放方式下每類種子的高光譜數據可分別壓縮成為84×224與100×224兩個矩陣,將整齊式和堆疊式樣本感興趣區域光譜反射率平均值各自累計到一個矩陣中則分別轉換成504×224和600×224的矩陣。由于這兩個矩陣行數明顯大于列數,因而適用于PCA降維。
2.3 模型算法介紹
對堆疊擺放方式和NIR條件下6個小麥品種在提取ROI平均光譜降噪后進行主成分分析(PCA)[14]。由表1可看出,前四個主成分累計貢獻率達到97.37%,可以近似代替原224個波段變量所表示的光譜反射信息。因此,本研究采用前四個主成分來作為分類模型輸入量。
支持向量機(SVM)是基于統計學習理論和結構風險最小化的新型機器學習算法,具有很強的范化性能,可避免過擬合現象[15]。SVM是針對二分類任務設計的,可以推廣到多分類任務中。其基本原理是建立一個分類超平面作為決策曲面,使得正反例間隔最大化。將輸入變量通過核函數變換映射到某個高維空間中,然后在變換空間中求解最優分類面,以獲得決策函數,從而獲得全局最優解[16]。
設PCA后得到的訓練樣本為(xi,yi),i=1,2,3…,n,xi∈R4,yi{1,-1},n為樣本個數,xi為PCA降維后提取的四個主成分。
當樣本線性可分時,假設線性分類器為wTx+b=0,w為超平面的法向量,b為位移項。假設超平面(w,b)能將訓練樣本正確分類,滿足
(1)
s.t.yi(wTxi+b)≥0,i=1,2,…,n
(2)
當原始樣本空間線性不可分時,可將樣本映射到高維的特征空間。令φ(x)表示將x映射后的特征向量,于是劃分超平面表示為
f(x)=wTφ(x)+b
(3)
引入松弛因子ξi≥0,設懲罰因子為c,式(2)可重寫為
(4)
ξi≥0,i=1,2,…,n
利用拉格朗日乘子法得到式(4)的對偶問題為
(5)
0≤αi≤c,i=1,2,…,n
定義核函數為k(xi,xj)=φ(xi)Tφ(xj),式(5)可重寫為
(6)
0≤αi≤c,i=1,2,…,n
由式(6)解出α后,求出w和b可得到劃分超平面
f(x)=wTφ(x)+b
(7)
經過不斷驗證,用徑向基函數作為分類模型的核函數時分類效果最好。徑向基函數形式為:
(8)
另外,算法中的SVM分類模型通過MATLAB中的libsvm插件實現。

表1 主成分貢獻率及累計貢獻率Table 1 Contribution rate and cumulative contribution rate of the top four principal components %
2.4 分類模型參數的確定
分類模型中有兩個不定參數:第一個是懲罰因子c,其表示對誤差的寬容度,c越大,說明越不能容忍出現誤差,容易過擬合,即訓練集準確率可能很高而測試集準確率不高,c越小,容易欠擬合;第二個是核函數參數g,其間接地決定了數據映射到新特征空間后的分布狀況,g越大,支持向量越少,可能會造成過擬合;g越小,支持向量越多,可能出現大的平滑效應,無法在訓練集上得到特別高的準確率,影響最終測試集的分類準確率(即測試樣本正確分類個數與總測個數的比值)。因此,c與g的選擇需要維持一種動態平衡,不僅要有較高的測試集分類準確率,而且還要保證分類器的通用性、泛化性等性能。
本研究主要采用交叉驗證和網格化尋優方法確定SVM分類模型中參數c與g的最佳值。具體做法是先讓c和g在[20,210]范圍內進行取值,對于確定的c和g,把訓練集作為原始數據并利用K-CV(K-fold Cross Validation)交叉驗證方法得到在此組c和g下訓練集驗證分類準確率。而在交叉驗證的基礎上對參數c和g在選定范圍內進行網格劃分,從網格中進行c和g參數點的取值,最終得到訓練集驗證分類準確率最高的那組c和g作為最佳參數。并且當多組c和g都對應同一個最高分類準確率時,選取第一組出現的參數c最小的那一組c和g作為最佳參數。
第三,加強社會主義核心價值觀教育,注重職業精神培育。獨立學院培養的人才不僅要具備較高的物質基礎,還要有更高的精神追求,要將社會主義核心價值觀教育融入本科教育中,培養的畢業生除了具有專業知識和職業技能外,還要有較高的職業道德素養,要培養追求職業精神、敬業愛崗的社會主義勞動者。
本實驗的分類模型最佳參數分為兩種:第一種是在一組確定的幾種小麥種子進行分類時的最佳參數,用上述尋參的交叉驗證和網格化尋優方法得到。第二種是某分類類型的小麥種子分類模型的最佳參數,比如小麥種子的三分類(即3個品種種子分類)模型為例,小麥種子的三分類模型的最佳參數建立在第一種參數確定的多組三種小麥種子分類最佳參數c和g的基礎上,通過確定三分類的多組小麥種子的參數c與g來大致確定第二種適合整個三分類模型的參數范圍,在該范圍內按照一定步長進行取值,找到使得這些組別的測試集準確率平均水平最高的參數c和g值,以此作為三分類模型的整體最佳參數。需要明確的是,某組的三分類最佳參數不一定是所有組別三分類的最佳參數;而整體最佳參數不一定是某一組的最佳參數,但一定是使得所有三分類中平均識別率最高的參數。為保證分類模型的通用性,本研究主要用第二種參數作為模型的最佳參數。
3 結果與討論
3.1 VNIR與NIR波段下小麥種子平均光譜反射率分析
以矮抗58為例,從VNIR與NIR兩種波段下的平均光譜反射曲線(圖3)可以看出,VNIR下在500~1 000 nm波段曲線較為平緩,缺少特征峰,并且在400~550 nm波段下噪聲比較明顯,易受外界影響。在NIR下光譜反射率曲線有明顯的特征峰且噪聲相對較低,比較適合用于種子分類。在堆疊采樣模式下,品種間NIR光譜反射譜線有明顯差異(圖4),理論上可以用于種子分類。
3.2 在NIR波段下三分類中整齊與堆疊兩種擺放方式的分類準確率
由于高光譜實驗采樣平臺原因,整齊式每類種子采集了84個樣本,而堆疊式每類種子提取了100個樣本。為保證條件一致,隨機選取同類品種堆疊式100粒樣本中的84粒作為分類樣本,將其與整齊式在NIR波段下進行分類準確性比較。選取每類樣本的四分之三即63粒作為訓練集,剩余四分之一即21粒作為測試集。分別對兩種擺放方式的數據進行PCA降維處理,提取的前四個主成分累計貢獻率均達到85%以上,所以分別用前四個主成分作為模型輸入量。對SVM分類模型在經驗基礎上選取采用徑向基函數作為核函數且參數c取2,g取1,模型輸入量進行歸一化處理,以消除不同量綱的影響。對兩種擺放方式在上述模型中選取三組三類小麥組合進行分類識別分析。由表2可知,兩者分類準確率相差無幾,但堆疊式采樣更貼合實際應用,因此采用堆疊式種子高光譜數據來探究小麥多品種種子分類。
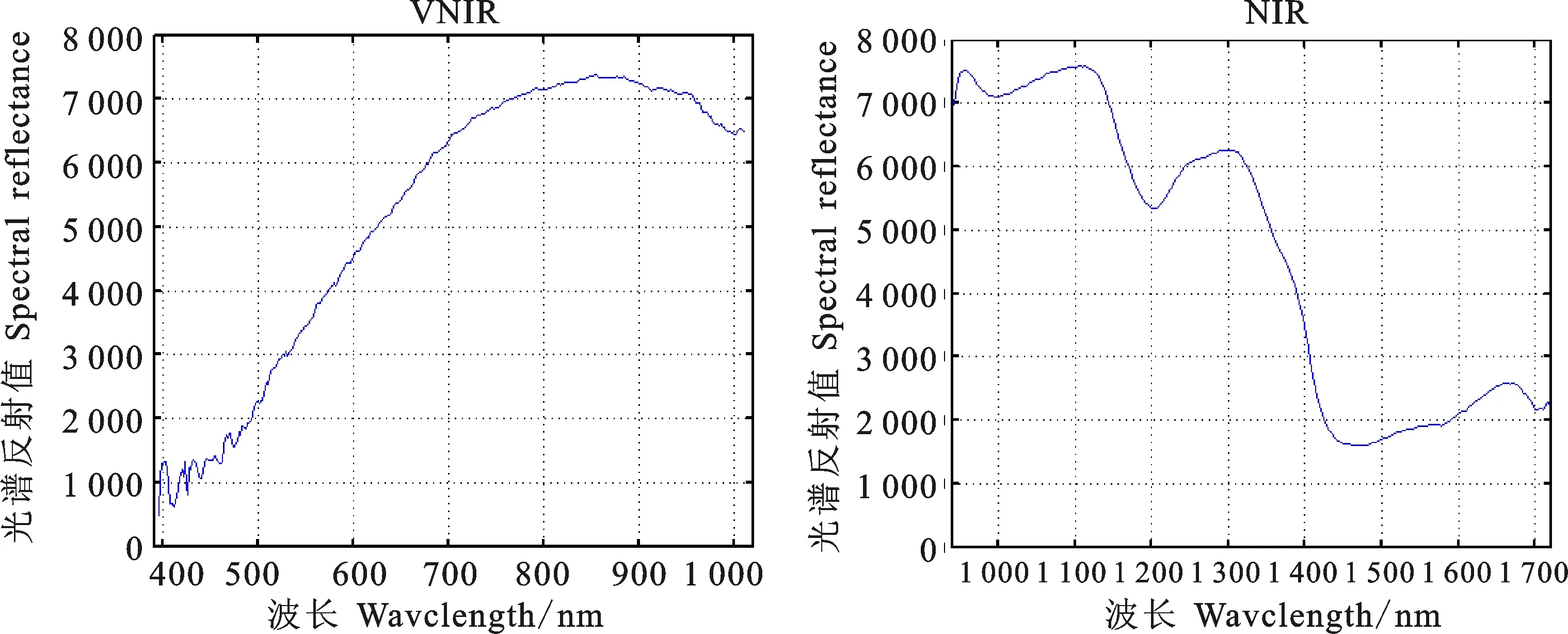
圖3 矮抗58在VNIR和NIR條件下平均光譜反射曲線
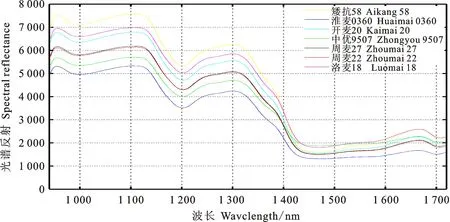
圖4 小麥種子NIR波段下堆疊擺放平均光譜反射曲線

表2 兩種擺放方式的種子分類準確率對比Table 2 Comparison of the accuracy of the two placement methods
3.3 堆疊式擺放在NIR波段下三分類模型SVM各個參數和條件的選擇
以矮抗58、淮麥0360、開麥20三類小麥種子為例,說明三分類參數尋優的方法與過程。提取三類種子樣本的前四個主成分作為分類模型輸入量。每類種子100粒樣本中任選80粒作為模型的訓練集,剩余20粒作為測試集。對分類模型SVM中的參數c和g確定最佳值,分別讓參數c與g在適當的范圍[20,210]內進行交叉驗證和網格化尋優,得到本組三類小麥種子三分類模型中最佳參數c為0.707,g為16(圖5)。
最佳參數確定后,對模型輸入量歸一化和不歸一代處理的分類結果進行比較,發現歸一化后60個測試集樣本中有4個被錯分,不進行歸一化分類時測試集樣本分類僅有1個被錯分(圖6)。這說明不用歸一化有助于提升分類準確率。
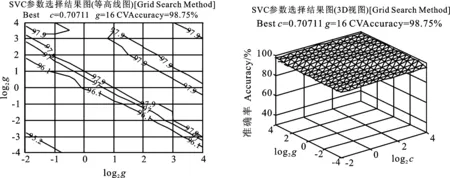
圖5 交叉驗證和網化尋優最佳參數c和g
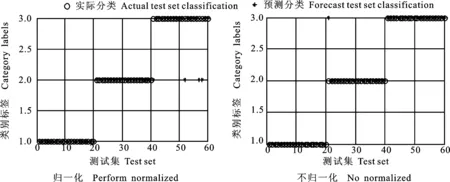
圖6 數據歸一化和不歸一化的分類準確率比較
3.4 6個小麥品種任選3個品種在最佳條件下進行種子三分類的識別結果
按照上述方法從矮抗58、淮麥0360、開麥20、中優9507、周麥27、周麥22等6個小麥品種中任選3個品種,對其NIR光譜數據進行主成分分析,確定分類模型SVM的輸入量。模型的徑向基函數參數c取1,g取8,模型輸入量不進行歸一化處理。
由表3可以看出,第10、16、19、20四組三分類種子在總計60粒小麥種子的測試集中錯分的籽粒分別為14、13、13、15粒,分類準確率低于80%。其余種子分類準確率平均在95%以上,其中第5和11組分類準確率達到100%,在實際應用中符合種子分類精度要求。
第10、16、19、20組分類準確率低的原因可能是模型選取參數主要考慮對于整體組別合適,而參數c和g取值不是該四組的最佳參數。對于該四組分別采用最佳參數c與g進行分析,結果(表4)表明,模型分類識別準確率沒有太大變化,其中第16組由于過擬合,準確率反而下降。因此,排除分類準確率低是由于參數不佳的原因。
進一步發現,上述四組都包含周麥27與周麥22,因而推測分類識別準確率低的原因可能是由于這兩品種間存在極大相似關聯性。經查閱文獻[17-18]發現,周麥27與周麥22血緣較近。如圖4在NIR波段下堆疊擺放的平均光譜曲線所示,周麥27和周麥22譜線大概位于圖中曲線中間位置,并且兩條曲線接近重合,NIR波段下的光譜信息沒有太大的差別。這兩個品種血緣關系較近,種子遺傳性狀相似,內部所含物質含量也相似,可能會造成在NIR波段下光譜信息類同,進而使得分類準確率較低。

表3 任意3個小麥品種分類準確率Table 3 Classification accuracy of any three wheat varieties
3.5 模型擴展
選取上述6個小麥品種中的任意4個小麥品種進行四分類實驗,用上文所述的實驗最佳條件即NIR波段下小麥種子堆疊擺放,模型整體最佳參數c取16,g取5。從分類結果(表5)可以看出,分類準確率雖均在80%以上,但準確率有所下降。
對6個小麥品種矮抗58、淮麥0360、開麥20、中優9507、周麥27、周麥22在上述最佳實驗條件下進行六分類實驗,參數尋優后最佳參數c為5.65,g為16,結果為120粒測試集中錯分48粒,準確率為60%。考慮到周麥27、周麥22的血緣關系較近,故將周麥27置換為備用品種洛麥18,結果為錯分40粒,準確率66.67%,分類準確率雖有提升,但依然不高。
從整個實驗結果看,所建立的多種小麥種子分類模型基本能滿足三種和四種小麥種子的分類要求,但還存在著血緣較近小麥種子的分類能力差和隨著小麥種子分類種類的增加,模型分類準確率不斷下降的問題。其下降的原因可能是:血緣較近品種內部的蛋白質、淀粉以含氫基團等物質相似性較大,使得反射光譜信息較為相近和不易區分;隨著分類小麥品種的增多,品種間光譜反射率相似性也會提高。針對模型分類精度低的問題,下一步研究需要從兩個方向上尋求解決:第一,豐富光譜波段的種類,比如提取一部分VNIR可見近紅外波段下的某些特征光譜,增加分類識別模型的特征輸入量;第二,利用一部分高光譜圖像數據中的圖像特征信息來增加分類模型的特征輸入量。

表4 最佳參數下的分類準確率Table 4 Classification accuracy under optimal parameters

表5 四組四分類識別結果Table 5 Recognition results of four groups of four classification
4 結 論
本研究利用高光譜圖像技術和建立的PCA-SVM分類識別模型,在3個小麥品種之間除個別近源屬性外,能實現三個品種的分類識別,準確率平均在95%以上。4個小麥品種種子的分類準確率在80%左右,6個小麥品種種子的分類準確率相對較低,僅有66%左右。綜上所述,通過探究分類實驗的最佳條件,在多種小麥種子各自堆疊式擺放、盡量多的利用NIR譜段光譜信息、整體最佳參數模型等條件下,所建立的PCA-SVM分類模型對于3個或4個小麥品種種子多籽粒間相互區分的識別分類具有一定應用價值,對6個小麥品種種子分類有一定的參考價值,同時也為高光譜圖像技術對多籽粒小麥種子鑒別分類提供了一種思路方法。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
