新型數據管理系統研究進展與趨勢*
2019-03-01 10:42:36童詠昕許建秋張東祥
軟件學報 2019年1期
關鍵詞:數據庫
崔 斌,高 軍,童詠昕,許建秋,張東祥,鄒 磊
1(北京大學 信息科學技術學院,北京 100871)
2(軟件開發環境國家重點實驗室(北京航空航天大學),北京 100083)
3(南京航空航天大學 計算機科學與技術學院,江蘇 南京 211106)
4(電子科技大學 計算機科學與工程學院,四川 成都 611731)
5(北京大學 計算機科學技術研究所,北京 100871)
21世紀以來,隨著計算機技術,尤其是互聯網和移動計算技術的發展,大量新型應用應運而生.這些應用不僅對人類的日常生活、社會的組織結構以及生產關系形態和生產力發展水平產生了深刻的影響,也使得人們能夠獲取的數據規模呈爆炸性增長.“大數據”這一詞匯被發明出來,用以概括這種態勢.
目前廣泛認為大數據具有所謂的“4V”特征,即規模大(volume)、變化快(velocity)、種類雜(variety)和價值密度低(value).為了有效地應對大數據的上述“4V”特征,各類新型數據管理系統也逐漸涌現出來.表1中我們列舉了部分典型的新型數據管理系統.

Table 1 Category of novel data management systems表1 新型數據管理系統分類
數據規模大在諸多數據處理場景中都有所體現.例如社交媒體應用中的用戶關系數據,若用圖數據模型進行建模,其涉及的節點數可高達幾億.為了處理這類大規模的數據,一個樸素的想法是分而治之,即,將數據分布式地存儲在多臺機器上分別處理.據此,人們提出了各類分布式數據管理系統.
數據變化快這一特征具體體現在數據實時到達、規模龐大、大小無法提前預知,并且數據一經處理,除非進行存儲,否則很難再次獲取.在金融應用、網絡監控、社交媒體等諸多行業領域,都會產生這類變化極快的數據.為了解決這一問題,人們提出了流數據處理系統.
針對數據種類雜的特征,人們采取“各個擊破”的手段,針對各類數據分別提出專門的數據管理系統,圖數據管理系統和時空數據管理系統是典型代表.圖數據模型是一種具有高度概括性的數據模型,其典型應用包括社交媒體數據的建模和知識圖譜等.時空數據在人們的日常生活中也十分常見,例如各類地圖應用在提供導航服務時,都需要對大量的時空數據進行高效的處理.
大數據的價值密度通常較低,例如社交媒體中大量的圖片數據在未經標注之前,并不具備顯著的價值.眾包正是解決該問題的有效手段之一.眾包通常是指“一種把過去由專職員工執行的工作任務通過公開的Web平臺以自愿的形式外包給非特定的解決方案提供者群體來完成的分布式問題求解模式”,是完成大規模的對計算機較為困難而對人類相對容易的任務的有效手段,例如數據標注.為了有效地對眾包過程中的數據和眾包參與者群體進行有效管理,人們提出了眾包數據管理系統.
如表1所示,我們可以看到:人們已經提出了分布式數據管理系統、圖數據管理系統、流數據管理系統、時空數據管理系統和眾包數據管理系統以應對大數據的“4V”特征帶來的挑戰,并設計了大量代表性數據管理系統,在實際應用中已經取得了較好的效果.下面我們將針對不同系統類型分別闡述上述技術及相關系統的進展,并展望后續發展趨勢.本文最后對新型數據管理系統在數據模型、計算模型和體系結構等方面的挑戰和機遇進行了探討.
1 分布式數據庫
1.1 引 言
在大數據時代下,移動互聯網、智能設備以及物聯網技術的發展,使得全球數據量呈現爆發式增長,遠遠超出傳統的單機版數據庫的處理能力.近幾年,分布式數據庫一直是工業界和學術界的研究重點.分布式數據庫應該具備強一致性、高可用性、可擴展性、易運維、容錯容災以及滿足ACID屬性的高并發事務處理能力.但在實際設計中,一方面受限于 CAP理論[1],即,在必須支持分區容錯性(partition tolerance)的前提下,系統實現只能側重一致性(consistency)和可用性(availability)的一個方面而無法同時滿足;另一方面,支持ACID事務屬性及高并發事務處理一直是分布式關系數據庫的難點.針對這些挑戰,現有的解決策略大致可分成 3類:(1) 將現有商業關系數據庫(如Oracle、SQLServer、MySQL、PostgreSQL)在分布式集群或者云平臺上進行小規模擴展和部署;(2) 放棄關系數據庫模型和 ACID的事務特性,選擇靈活的 schema-free數據模型及高可用性和最終一致性的NoSQL數據庫;(3) 融合關系數據庫和NoSQL優勢的新型數據庫(NewSQL).
1.2 主要研究問題
主流的分布式數據庫基本上圍繞數據強一致性、系統高可用性和ACID事務支持等核心問題展開研究工作,這些性質與系統的擴展性和性能密切相關,甚至相互制約,往往需要根據具體的應用需求進行取舍.
· 數據強一致性:銀行交易系統等金融領域往往有數據強一致性和零丟失的需求.當更新操作完成之后,任何多個后續進程或線程的訪問都要求返回最近更新值.如果在這個分布式系統中沒有數據副本,那么系統必然滿足數據強一致性要求,原因是只有獨本數據,才不會出現數據不一致的問題.但是分布式數據庫系統的設計需要保存多個副本來提高可用性和容錯性,以避免宕機時數據還沒有復制,導致提供的數據不夠準確.如何低成本地保證數據的強一致性,是分布式數據庫系統的一個重要難題;
· 系統高可用性:在分布式數據庫中,系統的高可用性和數據強一致性往往不可兼得.當存在不超過 1臺機器發生故障的時候,要求至少能讀到一份有效的數據,往往需要犧牲數據的強一致性來保證系統的高可用性.相當一部分NoSQL數據庫采用這個思路來支持互聯網場景下的大規模用戶并發訪問請求,它們通過實現最終一致性來確保高可用性和分區容忍性,弱化了數據的強一致要求.為了解決數據不一致問題,不同的分布式數據庫設計各自的沖突機制.另外,有效的容錯容災機制也是保障系統高可用性的堅實后盾;
· ACID 事務支持:ACID 指的是事務層面的原子性(atomicity)、一致性(consistency)、隔離性(isolation)和持久性(durability).如何有效地支持ACID事務屬性,一直是分布式數據庫的難點,涉及到很多復雜的操作和邏輯,會嚴重影響系統的性能,很多NoSQL數據庫都是放棄支持事務ACID屬性來換取性能的提升.近年來,新型數據庫(NewSQL)的出現給分布式數據庫的發展帶來新的方向,它的目標是提供與NoSQL相同的可擴展性和性能,同時支持事務的ACID屬性.這種融合一致性和可用性的NewSQL已經成為分布式數據庫的研究熱點.
1.3 國內外研究現狀
1.3.1 基于分布式集群或云平臺的關系數據庫
MySQL集群是一種常見的開源分布式數據庫,它基于無共享的(shared-nothing)數據存儲模式,采用讀寫分離的主從模式(master-slave)來實現高可用性.該設計方法也被主流的云平臺關系數據庫采納和應用,包括亞馬遜的Amazon RDS(Amazon relational database service)[2]、谷歌的 Google Cloud SQL[3]、微軟的Azure SQL Database[4]以及國內的阿里云RDS[5]、騰訊CDB(cloud DataBase)[6]和網易的蜂巢RDS[7].與傳統數據庫相比,這些云數據庫往往同時支持MySQL、SQL Server及PostgreSQL等數據庫引擎,具有低成本、易運維、可伸縮、高可用等優勢,并提供容災、備份、恢復、監控、遷移等數據庫運維全套解決方案.
基于分布式集群或云平臺關系數據庫的主要缺陷是很難低成本地保持數據的一致性,每次將數據寫到master節點后,都要及時同步slave節點,所以往往犧牲性能來保障強一致性.另外,如果master節點宕機,會直接導致業務不可寫,也會影響整個系統的高可用性.為解決這一問題,MySQL集群自帶的數據同步策略從最初的異步復制進化為MySQL 5.7版本的半同步復制,但效果依舊有限.各大企業也紛紛設計MySQL補丁來保證數據一致.Amazon Aurora將事務引擎和存儲引擎分離,redo日志從事務引擎中剝離,歸并到存儲引擎中,屬于典型的shared disk架構,通過存儲層共享來解決一致性問題.Galera Cluster采用多主架構(multi-master)來實現真正的多點讀寫,即集群中每個節點都可讀寫,無需讀寫分離.集群不同節點之間數據同步是基于 Galera replication中間件,避免了MySQL集群主從節點之間的復制延遲.
國內的云關系數據庫也對數據一致性的提升做出了原創性貢獻.阿里巴巴的AliSQL利用了分布式一致性協議(Raft)[8]以保障多節點狀態切換的可靠性和原子性.為了保證多節點之間的 binlog的強一致性,騰訊的PhxSQL使用分布式一致性協議Paxos實現master管理.同時,用BinlogSvr來支持MySQL的異步復制協議以支撐微信后臺的賬號系統、企業微信及QQ郵箱等.網易RDS則是采用虛擬同步復制技術,確保所有主機的更新事務在提交前都首先在從機上落盤,保證主從切換后數據完全一致.在節點上使用了并行復制技術,大幅度提高了從機回放主機事務的速度,復制延遲消失,保證了在秒級完成主從切換.
1.3.2 NoSQL數據庫
由于事務處理過程對 ACID屬性的嚴格要求,云關系數據庫的可擴展性相對有限.為提升系統存儲和處理海量數據的能力,NoSQL從底層數據模型進行考慮,放棄關系模型,也不保證支持 ACID事務處理.它采用schema-free的數據模型,可以根據不同應用需求衍生出多種類型的分布式數據庫.按照存儲模型來分類,可將NoSQL 數據庫分為列式存儲(如 HBase[9]和 Cassandra[10])、鍵值存儲(如 Redis[11]、MemcacheDB[12]、DynamoDB[13]、SimpleDB[14])和文檔存儲(如 MongoDB[15]和 CouchDB[16]).
一個分布式系統最多同時滿足一致性(consistency,簡稱 C)、可用性(availability,簡稱 A)和分區容錯性(partition tolerance,簡稱 P)中的兩項,可根據相應的設計目的進行選擇.對 NoSQL而言,分區容錯性是不能犧牲的,因此只能在一致性和可用性上加以取舍.如果在這個分布式系統中數據沒有副本,那么系統必然滿足強一致性條件,因為只有獨本數據,不會出現數據不一致的問題,此時C和P都具備.但是,如果某些服務器宕機,那必然會導致某些數據是不能訪問的,那 A就不符合了;反之,如果在這個分布式系統中數據是有副本的,那么如果某些服務器宕機,系統還是可以提供服務的,即符合A,但是很難保證數據的一致性.因為宕機時可能有些數據還沒有復制到副本中,那么提供的數據就不準確了.一般情況下,對于一致性要求比較高的業務在訪問延遲時間方面就會降低要求,適合選擇 CP模式;對于訪問延時有高要求的業務在數據一致性方面會降低要求,適合選擇 AP模式.
· CP 模式
CP模式要求分區容忍性,同時對數據一致性要求較高,即,能夠保證所有用戶看到相同的數據.當網絡通信出現問題時,暫時隔離開的子系統可繼續運行(分區容忍性),但是不保證某些節點故障時,所有請求都能被響應.如果主節點宕機,可能需要選舉新的主節點,同步節點間數據以及進行數據回滾等操作,這會使系統的可用性降低.常見的 CP 模式系統有 BigTable[17]、HBase[9]、Redis[11]、MongoDB[15]和 MemcacheDB[12].
BigTable是一個GFS[18]之上的索引層,采用兩級的B+樹索引結構.GFS保證至少寫入一次成功的記錄并由BigTable記錄索引.為了保證BigTable的強一致性,同一時刻同一份數據只能被一臺機器服務,且BigTable中的Tablet Server沒有對每個Tablet備份.HBase是Apache Hadoop中的一個子項目,屬于BigTable的開源版本,是滿足強一致性的分布式數據庫,主要用來存儲非結構化和半結構化的松散數據.HBase利用Hadoop HDFS[19]作為其文件存儲系統,借助 MapReduce[20]計算模型來處理海量數據,并使用 Zookeeper作為分布式協同服務.HBase使用了事務機制中常見的一致性實現方式WAL(write-ahead logging)[21].
Redis集群通常是主備,主節點負責寫入和讀取,而slave節點只是用來備份.當主節點失敗時,slave節點有機會被提升為主節點.MongoDB采用類似于Redis的主從集群方式,主節點作為單點寫操作服務,然后同步到slave節點,可以通過設置 autoresync發現 slave節點的數據不是最新,則自動地從主服務器請求同步數據.MongoDB使用基于Raft協議選主策略,一旦主節點發生故障,整個MongoDB會進行交流,然后選擇一個合適的slave節點快速實現故障恢復.
MemcacheDB是一個新浪網基于 Memcached開發的分布式 Key-Value存儲持久化開源項目,它使用BerkeleyDB[22]作為存儲引擎,通過為Memcached增加Berkeley DB的持久化存儲機制和異步主輔復制機制,使Memcached具備了事務恢復能力、持久化能力和分布式復制能力,非常適合超高性能讀寫速度和持久化保存的應用場景.
· AP模式
AP模式主要以實現最終一致性來確保可用性和分區容忍性,但卻弱化了對數據的一致要求,大部分NoSQL系統都屬于AP模式范疇.
Amazon Dynamo[13]是一個分布式鍵值存儲系統,它采用去中心化、松散耦合方式,由數百個服務組成面向服務架構,不支持復雜的查詢.Dynamo利用一致性哈希來完成數據分區,給系統中的每個節點隨機分配一個token,這些token構成一個哈希環.執行數據存放操作時,首先計算key的哈希值,然后存放到順時針方向第1個大于等于該哈希值的 token節點上.這種算法的優點是:節點的增刪只會影響哈希環中相鄰的節點,對其他節點沒有影響.
Cassandra[10]由 Facebook開發并于 2008年開源,系統架構與Dynamo一致,均為基于DHT(分布式哈希表)的完全P2P架構,具有高度可擴展性和高度可用性,沒有單點故障.Cassandra使用由Dynamo引入的架構特性來支持BigTable數據模型,并采用MemTable和SSTable方式進行存儲.在Cassandra寫入數據之前,需要先記錄日志(CommitLog),再將數據開始寫入ColumnFamily對應的MemTable中.
Amazon SimpleDB[14]是一個可大規模伸縮、用Erlang編寫的高可用數據存儲,類似于Amazon S3,但兩者的一致性有很大的區別.Amazon S3[23]一致性模型為弱一致性,只支持最基本的Put/Get/Delete操作,且每個操作之間是互相獨立的.SimpleDB除了支持Get/Put/Delete,還需要支持強一致讀以及基于條件更新或者刪除的樂觀鎖機制.Amazon S3直接使用“Last Write Wins”的方式解決沖突,因為集群內部機器時鐘不一致的概率很低.另外,發生同一條記錄被多個客戶端更新且同時發生機器故障等異常情況的概率也很低.SimpleDB需要支持一些條件更新或者刪除,從而支持樂觀鎖機制以實現最終一致性.
Apache CouchDB[16]是一個面向文檔數據管理的開源數據庫,使用JSON存儲半結構化的數據,查詢語言為JavaScript并封裝MapReduce和HTTP作為API,適合CMS、電話本、地址本等的應用.其最顯著的特性是支持多主復制,沒有鎖機制,通過使用MVCC(多版本并發性控制)[24]實現最終一致性.Tokyo Cabinet[25]的開發者是日本人Mikio Hirabayashi,主要被用在日本最大的SNS網站mixi.jp上,也曾是鍵值數據庫領域的熱點.其他的高可用性NoSQL數據庫還有Voldemort[26]、Riak[27]等(見表2).

Table 2 Comparison of representative NoSQL systems表2 代表性NoSQL數據庫比較
1.3.3 NewSQL數據庫
近年來,以Spanner[28]為代表的新型數據庫(NewSQL)的出現,給數據存儲和分析帶來了SQL、NoSQL之外的新思路.NewSQL指的是提供與NoSQL相同的可擴展性和性能,并同時能支持滿足ACID特性的事務.這保留了 NOSQL的高可擴展和高性能,且支持關系模型.融合一致性和可用性的 NewSQL可能是未來大數據存儲新的發展方向.
Spanner是第一個將數據分布到全球規模的系統,并且在外部支持一致的分布式事務,設計目標是橫跨全球上百個數據中心,覆蓋百萬臺服務器.不同于 BigTable版本控制的鍵值存儲模型,Spanner演化為時間上的多維數據庫.舊版本數據根據可配置的垃圾回收政策處理,應用可以讀取具有舊時間戳的數據.Spanner顯著的特點是外部一致讀寫和在某一時間戳的全度跨數據庫一致讀取.對于最典型的讀寫事務,Spanner使用常見的兩階段鎖策略(2PL)來控制并發,并實現了一個所謂的外部一致性.F1[29]是Google公司提出的建立在Spanner基礎上的用于廣告業務的存儲系統.F1實現了豐富的關系型數據庫的特點,包括嚴格遵從的 schema、強力的并行 SQL查詢引擎、通用事務、變更與通知的追蹤和索引.其存儲被動態分區,數據中心間的一致性復制能夠處理數據中心崩潰引起的數據丟失.Google F1提供了一種可能性:OLTP與OLAP融合的可能性,這是在其他數據庫中從未沒有實現過的.
國內數據庫在NewSQL領域的代表性系統包括阿里巴巴的OceanBase[30]和騰訊的DCDB[31].OceanBase是支持海量數據的高性能分布式數據庫系統,實現了數千億條記錄和數百PB數據的跨行跨表事務.數據多副本通過 Paxos協議同步事務日志,多數派成功事務才能提交.缺省情況下,讀、寫操作都在主副本進行,保證強一致.存儲采用讀寫分離架構,沒有主從結構,集群節點全對等,每個節點都具備計算和存儲能力,無單點瓶頸.騰訊DCDB又名TDSQL,是一種兼容MySQL協議和語法且支持自動水平拆分的高性能分布式數據庫,即:業務顯示為完整的邏輯表,數據卻均勻地拆分到多個分片中.每個分片默認采用主備架構,提供災備、恢復、監控、不停機擴容等全套解決方案,適用于TB或PB級的海量數據場景.這幾年,TDSQL不斷進步,研發了很多新特性,諸如多級分區、熱點更新、隱含主鍵、分布式事務等,不僅有力地支撐了事務型數據庫應用,而且在體系結構上也朝Spanner架構上邁進,是一個名副其實的NewSQL系統.
TiDB[32]作為NewSQL開源社區的代表,是PingCAP公司基于Google Spanner/F1論文實現的開源分布式NewSQL數據庫,能夠實現分布式事務以及跨數據中心數據強一致性保證.TiDB最底層用Raft來同步數據.每次寫入都要寫入多數副本,才能對外返回成功,即使丟掉少數副本,也能保證系統中還有最新的數據.TiDB的事務模型采用樂觀鎖,只有在真正提交時才會做沖突檢測,如果有沖突,則需要重試.由于分布式事務要做兩階段提交,并且底層還需要做 Raft復制,一個非常大的事務會使得提交過程非常慢,并且會卡住下面的 Raft復制流程,所以在設計上,TiDB和Spanner對事務的大小進行了限制.
1.4 總結與展望
本節從CAP理論出發,對分布式數據庫的數據一致性、系統可用性和ACID事務屬性進行了綜述,并針對國內外數據庫的發展狀況,介紹了現有商業關系數據庫如何在云平臺上進行擴展和部署,NoSQL數據庫如何支持schema-free數據模型、高可用性和最終一致性,以及新型數據庫(NewSQL)如何提供與NoSQL相同的可擴展性和性能,同時能夠支持滿足ACID特性的事務.
在大數據環境下,NoSQL分布式數據庫與傳統分布式數據庫的最終目標都是對用戶提供完善的數據存儲和查詢功能,并且在運營上能夠實現可伸縮和高可用等特性,并提供容災、備份、恢復、監控等功能.兩者最大的區別在于傳統分布式數據庫追求數據強一致性,并且需要提供ACID事務支持,導致其在峰值性能、伸縮性、容錯性、可擴展性等方面的表現不盡如人意,很難滿足海量數據的柔性管理需求.NoSQL則是以犧牲支持ACID為代價,換取更好的可擴展性和可用性.NewSQL是一種相對較新的形式,旨在將 SQL的 ACID保證與 NoSQL的可擴展性和高性能相結合.
未來幾年,融合關系數據庫和NoSQL優勢的NewSQL將繼續在分布式數據庫領域大放光彩,并成為一個重要的研究熱點.以OceanBase和DCDB為代表的國內NewSQL系統也將在海量復雜業務的推動下持續發展和優化,并作為國家大數據發展戰略提供有力支撐.這也意味著,我國有可能在下一波數據庫技術潮流當中占領先機,進入第一梯隊.
2 圖數據庫
2.1 引 言
近年來,隨著社交網絡與語義網的發展,基于互聯網的圖數據規模越來越大.截止到 2017年底,微信已經有了將近 10億的活躍用戶,這些用戶相互關聯與通信,僅在 2016年春節期間,用戶之間就互相分發了 32億個紅包[33].在語義網的Linked Open Data項目中,已有超過1 184個RDF圖數據集,合計超過800億條邊[34].針對這些規模巨大的圖數據,設計與實現高效的圖數據管理系統成為一個很重要的研究熱點.
現階段,工業界和學術界已經設計并實現了不少大規模圖數據管理系統.按照對圖數據管理的抽象程度,可以將其分成如下兩類.
· 低層次抽象的提供編程接口的圖數據管理系統:這類系統會針對圖數據管理中的基本操作設計并實現相應的編程接口,用戶利用這些編程接口來實現相應的管理功能;
· 高層次抽象的提供描述性查詢語言的圖數據管理系統:這類系統設計圖數據管理描述性查詢語言,用戶將相應的管理需求用描述性查詢語言表達,系統解析這些描述性查詢語句并生成相應的查詢計劃以進行執行處理.
表3中,我們列舉了本文即將介紹的圖數據管理系統以及它們的分類.

Table 3 Category of graph data management systems表3 圖數據管理系統分類
2.2 主要研究問題
針對大規模圖數據處理,主要有以下幾個常見問題.
· 圖搜索:給定一個圖,從一個點出發沿著邊搜索其他所有節點.常見的圖搜素方法有寬度優先、深度優先和最短路徑等.圖搜索是圖計算問題的基礎,用于衡量圖計算的 Benchmark Graph500[35]就是以寬度優先搜索性能作為評測機器的圖計算能力的標準;
· 基于圖的社區發現:社區發現是社交網絡分析中一個重要的任務,用于分析網絡圖中的密集子圖.這對于理解社交網絡中的用戶行為和朋友推薦等都具有非常重要的應用價值,典型的社區發現算法有K-core[36]、K-truss[37]以及K-clique[38];
· 圖節點的重要性和相關性分析:計算圖中某個節點的重要程度,例如在網頁鏈接圖中分析網頁的重要程度,代表性工作是Pagerank[39];衡量圖上兩個節點的相關性,例如社交網絡中兩個人之間的關系,代表工作包括SimRank[40]和Random Walk[41]等;
· 圖匹配查詢:給定數據圖和查詢圖,圖匹配查詢找出所有在數據圖上與查詢圖同構的子圖,這個問題常用于描述針對圖結構的查詢.圖匹配查詢的應用包括化學分子庫中的分子拓撲結構查詢[42]、在一個社交網絡圖中的特定社交結構查詢[43]等.面向RDF知識圖譜數據的SPARQL查詢語言就是基于子圖匹配的查詢語義[44,45].
2.3 國內外研究現狀
2.3.1 低層次抽象的提供編程接口的圖數據管理系統
提供低層次抽象編程接口的圖數據管理系統包括 Pregel[46]及其衍生[47-51]、Trinity[52]、GraphX[53]等;系統會將常見的圖運算中的基本操作抽象成編程接口.雖然這類系統屏蔽了包括圖數據的內部數據結構表示、分布式環境下的通信處理等底層系統問題,但是由于是低層次抽象的編程接口,用戶還需要將具體的圖計算任務轉換成系統提供的低層次抽象編程接口邏輯.
這類系統中典型的是“點計算模型”,即允許用戶定義每個點的計算任務.最早的系統是谷歌提出的一種分布式圖數據管理系統Pregel[46],該系統基于BSP分布式計算模型[54]進行設計,圖數據的每個點為基本計算核心,機器之間通過消息傳遞來實現同步.Pregel將圖運算用一系列的超級計算步(superstep)來描述,在運算每一次超級計算步時,每一個頂點都能接收來自上一次超級計算步的信息,然后將這些信息傳送給下一個頂點,并在此過程中修改其自身的狀態信息(例如以該頂點為起點的出邊狀態信息)或改變整個圖的拓撲結構.Pregel系統將不同機器的通信進行了封裝,用戶需要通過編程來描述點計算函數進而實現自身的需求.
Pregel的基于BSP的點計算模型得到了工業界以及學術界的廣泛關注與認可.很多人在Pregel上開發了效率更高的系統,包括 Giraph[47]、PowerGraph[48]、GraphLab[49]、Quegel[50]、PAGE[51]等.
除了基于“點計算”的圖計算系統,Trinity[52]是微軟研發的一個基于內存的分布式圖數據管理系統.Trinity認為:隨著時代的發展,一方面內存越來越大且越來越便宜;另一方面,圖數據上的基本操作非常復雜,將數據存儲在外存會導致操作不便,所以利用內存進行圖數據管理才是更好的選擇.因為單機內存規模總是有限的,所以Trinity使用了內存云的技術,也就是將多臺機器的內存封裝起來,使得用戶能夠同時使用多臺機器的內存,而且無需知道底層細節.Trinity的基本數據結構是鍵值對,可以通過鄰接表的形式存儲與管理數據圖,用戶通過編程調用內存中的鄰接表來實現自身需求.
GraphX[53]將圖計算任務分成兩種:圖并行計算任務(graph-parallel computation)和數據并行計算任務(dataparallel computation).所謂圖并行計算任務,主要是指基于BSP點計算模型來實現的迭代計算任務,如PageRank;所謂數據并行計算任務,主要是指圖上代數運算,如構建一個圖、合并兩個圖、跨越多個圖等等.GraphX的作者認為:現有的圖計算系統(如Pregel[46]、GraphLab[49])通過限定編程框架的形式來提高圖并行計算任務的執行效率,但是這些系統并不適合數據并行計算任務.基于上述觀察,GraphX在分布式計算平臺Spark[55]的基礎上構建了GraphX,以同時處理圖并行計算任務和數據并行計算任務.GraphX以圖為第1類組成對象,以屬性圖為數據模型.所謂屬性圖,就是每個點和每條邊都可以關聯一個屬性值表.GraphX定義了很多圖上的操作.既包括一些圖并行計算任務,如Pregel等,也包括一些數據并行計算任務,如map、filter等.
2.3.2 高層次抽象的提供描述性語言的圖數據管理系統
所謂高層次抽象的提供描述性查詢語言的圖數據管理系統包括Neo4J[56]、EmptyHeaded[57,58]、gStore[44,45,59]等.這些系統為了方便用戶對圖數據的使用,在構建圖數據管理系統的基礎上,設計或者采用了一些描述性查詢管理語言.用戶可以將自身的需求表達成描述性語句,然后系統將這些任務語句解析成執行計劃,最后由系統按照執行計劃進行處理進而得到計算結果.因為這類系統用描述性查詢語言作為用戶和系統的交互中介,所以這類系統具有較好的用戶友好性.
Neo4J[56]是一個由美國Neo Technology公司開發的基于Java平臺的開源圖數據管理系統,具有如下4個特點:支持滿足ACID特性的事務操作、很好的可用性、很高的可擴展性、支持高效率遍歷查詢.Neo4J的描述性查詢語言是 Cypher[60],適合于開發者和在數據庫上進行查詢的數據專業操作人員.針對實際中各種應用需求,Cyper定義不同的方法來描述與表達.Cyper的許多關鍵字受SQL的啟發,如like和order by,它是一個申明式的語言,焦點在如何從圖中找回(what to retrieve),而不是怎么去做.在不公布實現細節的前提下,用戶關心如何查詢優化.
EmptyHeaded[57,58]是由斯坦福大學開發的圖數據管理系統,這個系統首先將圖上的計算任務轉化成邊的連接操作,然后利用現有關系數據庫關于多路連接的最新研究成果[61]找出最優的多路連接查詢執行計劃.在查詢執行階段,EmptyHeaded利用SIMD技術來提高查詢執行效率.EmptyHeaded提出了自己的描述性查詢語言,主要整合了聯合查詢、聚集操作和迭代運算,支持常見的子圖匹配、PageRank計算、最短路徑計算等.
著語義網的發展,越來越多的數據被表示成 RDF(resource description framework,即資源描述框架)[62]形式發布到網絡上.在RDF模型下,網絡資源及其關系也可以被表示成一個圖,方便用戶利用圖技術進行數據表示與管理.針對 RDF數據,已經有推薦的描述性結構化查詢語言 SPARQL(simple protocol and RDF query language)[63],可以實現大規模RDF的數據管理.
針對 RDF知識圖譜的數據管理,可以采用基于關系數據庫的方法,也可以采用圖計算的策略.利用 RDF知識圖譜的圖結構特性來管理數據,代表性系統有基于圖的 RDF知識圖譜數據管理系統 gStore[44,45,59]和支持自然語言問句的RDF知識圖譜檢索系統gAnswer[64].
2.4 總結與展望
本文分類闡述了兩類圖數據管理方法,對圖數據計算任務進行了不同程度的抽象,進而提出了不同的交互方式.研究人員也提出了一些新的研究問題,包括在異構計算環境下的圖數據管理問題,例如,如何利用新型高性能計算芯片FPGA進行圖數據處理.異構計算環境下的圖數據計算問題是一個開放性研究課題,同時,在傳感器、社交網絡等環境下的圖數據管理問題具有多源且實時更新的特點,面對多源的流式圖數據管理也是圖數據管理所面臨的新的挑戰.
3 流數據管理
3.1 引 言
智能手機的普及和移動互聯網的發展極大地加速了數據的生成過程,令數據呈現出爆炸式的增長,并給大數據的實時管理帶來了前所未見的難題和挑戰.例如,微信的月活躍用戶已超過了 10億,用戶之間的交互則會帶來更大規模的數據,包括語音、視頻、圖片以及相關的文本等.數據的規模和復雜性還在高速增長,如社交網絡每天以億級別的發文[65]、軌道交通應用形成的大規模定位與軌跡信息以及網絡通信中的數據傳播等.為了處理實時增長的大規模復雜數據,流數據的管理和相關系統的研究一直是學術界和工業界的熱點問題,包括早期的關系型數據為主的數據流管理系統、近期在工業界普遍使用的流式計算系統以及目前廣泛關注的對圖數據流管理系統的探索.
3.2 主要研究問題
流數據有眾多不同的定義,但統一起來可以用隨時間不斷增長的數據模型來概括.除了基本的數據查詢統計等操作外,主要有3方面的研究問題——流數據采樣、持續性數據查詢和流數據并行計算.
· 流數據采樣.基于有限的存儲來管理無限的動態數據是流數據管理中的基本挑戰之一,應對這一挑戰的最經典的思路則在于流數據上的高效采樣.將高速更新的流數據采樣到有明確規模邊界的有限存儲中,通過對采樣數據的計算和挖掘來反映流數據所蘊含的重要信息.一方面,需要研究不同流數據場景下采樣策略的選取,進而能夠利用有限的資源盡可能地反映原流數據的特征信息;另一方面,需要結合計算需求,精準分析采樣數據上的計算與挖掘結果相對于精確解的近似程度,控制計算結果的偏移范圍;
· 持續性數據查詢.流數據模型所對應的最核心的現實場景是實時監控.對不斷生成的現實數據進行高效的計算挖掘,能夠及時獲取現實世界中的重要信息.例如銀行對實時的交易數據進行監控,及時規避欺詐風險和追蹤洗錢等違法行為.因此,給定基于結構特征、統計特征的數據查詢模式,實時地監控流數據中匹配的目標,一直都是研究的熱點.一方面,需要保存已計算的中間結果來減少重復性的計算,另一方面,又需要避免中間結果維護帶來過高的額外開銷;
· 流數據并行計算.應對流數據高速生成的一個重要策略就是利用數據和計算的獨立性進行并行處理,提高系統吞吐量.系統日志數據、銀行流水數據以及大量的移動應用產生的用戶數據等在其初期的歸整處理上都可以利用數據獨立性進行流水線式的并行處理.在更復雜的數據計算和分析過程中,針對計算獨立性和流場景的一致性要求,設計鎖機制來實現計算分析的并行化.
3.3 國內外研究現狀
本節將通過流數據管理研究的 3個不同階段分別闡述流數據管理系統目前的研究脈絡:首先,簡單了解早期以關系型數據為主的數據流管理系統(DSMS);然后,詳細介紹近期針對大規模復雜數據的流式計算系統;最后討論目前興起的對圖數據流管理系統的探索.
3.3.1 數據流管理系統
數據流管理系統(DSMS)是指管理持續性數據流的計算機軟件.不同于傳統的數據庫管理系統(DBMS),數據流管理系統支持持續性查詢,每個查詢從注冊開始有效直至撤銷結束,不僅僅執行一次.在有效期間內,隨著數據流的不斷更新,持續性查詢的結果也會更新.傳統的數據庫管理系統一般假定有足夠的外存用來持久化數據,并且可以進行隨機訪問.而數據流管理系統中主要強調用有限的內存來處理無限的數據流,并且只能順序訪問,這也是數據流管理最獨特的特征以及最大的挑戰.
目前,數據流管理系統并沒有統一的系統框架,但在查詢語言上,絕大多數都采用類似于傳統數據庫管理系統中SQL的聲明式語言來表達查詢,包括持續性查詢語言(continuous query language,簡稱CQL)[66]、流SQL[67]等.流查詢語言也會支持窗口表達.在圖示化的查詢語言中,每個細分的查詢由一個“查詢盒”表達,各個細分查詢的關聯與組合通過“查詢盒”[68]間的箭頭連線表達.這個結構可以理解為流計算框架(諸如Storm等)中數據處理與傳輸架構的前身.
目前,主要的數據流管理系統有 STREAM[69]、Aurora[68]、TelegraphCQ[70]、NiagaraCQ[71]以及 Gigascope[72]等.STREAM 是斯坦福大學研發的基于關系模型的多功能數據流管理系統,它聚焦在數據流計算時的內存管理以及近似查詢.Aurora是一個以工作流為導向的數據流管理系統,用戶可以通過“查詢盒”來定義查詢計劃,每個“查詢盒”含有基礎的操作命令,“查詢盒”之間的數據流指向決定了各個步驟結果的傳輸框架.TelegraphCQ是一個由伯克利大學開發的自適應數據流管理系統,用于支持不同場景的數據流應用.NiagaraCQ是針對動態 Web內容進行持續性 XML-QL查詢的數據流管理引擎(XML-QL是 XML查詢語言的一種擴展,用來支持大 XML文檔上的數據抽取,能夠跨多個不同的DTD解釋XML數據以及集成多個不同源的XML數據).它對XML數據的抽取、查詢與監控分別由3個主要組件來支撐:搜索引擎、查詢引擎以及觸發管理.Gigascope是面向網絡數據流監控的分布式數據流管理系統,可以用來支撐網絡流量分析、入侵檢測、路由配置分析等,也能夠進行網絡搜索、性能監控等.
表4給出了數據流管理系統的對比情況.這些系統的核心初衷在于對靜態數據管理系統的流模型擴展,因此,這些系統在查詢語義和執行計算的數據處理邏輯方面與傳統的數據管理模型有很大的重疊,可以認為是在傳統數據管理系統的語義和架構上的擴展,以支撐數據流場景的持續性查詢.目前,大規模高速生成的數據結構復雜,基于關系模型的數據流管理系統難以應對這種大數據場景.
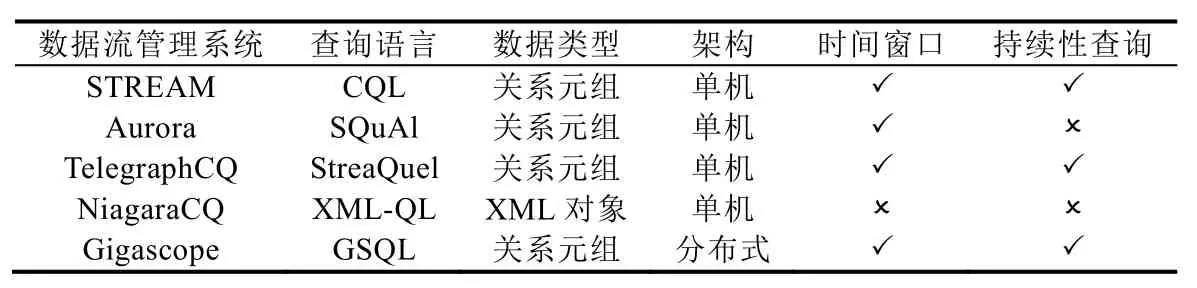
Table 4 Comparisons of data stream flow management systems表4 數據流管理系統對比
3.3.2 流計算框架
流計算系統是目前學術界和工業界廣泛使用的進行大規模數據處理的計算系統.目前,主流的流計算框架主要有5個:Storm[73,74]、Spark Stream[75]、Samza[76,77]、Flink[78,79]以及Kafka Stream[80].流計算框架具有兩個重要概念:交付保證(delivery guarantee)[81]、流處理類型中的實時處理流和微批量處理流.
交付保證是系統在處理新來的數據項時提供相應層次的處理保障,分為3種:第1種是“至少1次”,也就是說,即便出現系統宕機等錯誤,也仍然能夠保證新來的每個數據項被處理1次,可能會出現多次重復處理;第2種是“最多1次”,也就是說,新來的數據最多會被處理1次,在宕機等錯誤情況發生時,有可能數據會被丟棄而導致沒有被處理;第3種則是“恰好1次”,也就是要求最嚴格的交付保證,確保無論發生什么情況,新來的數據項有且僅有1次處理.
流處理類型[82]的實時處理流是指每個新來的數據項都會被立即處理而無需等待后續的數據項,代表流框架有Storm、Samza、Flink以及Kafka Stream;微批量處理流是指數據項并不是到達之后立即處理,而是等待一段很短的時間使其聚成一定單位大小的單個小批量數據后再處理,對應的流框架有 Spark Stream以及 Storm-Trident(Storm的一個擴展,一個以實時計算為目標的基于 Storm的高度抽象.它在提供處理大吞吐量數據能力(每秒百萬次消息)的同時,也提供了低延時分布式查詢和有狀態流式處理的能力).
Storm是一個Twitter開源流系統,也是最早出現的開源流式計算框架.在初始化時,需要用戶定義一個實時計算框架,其結構是一個有向圖.圖中的點是集群中的計算節點,而邊則對應整體計算邏輯中數據的傳輸,這個圖框架也被稱為拓撲.在一個拓撲中,傳輸的數據單元是一系列不可修改的鍵值對(tuple),鍵值對從 spout(消息源)點中輸出形成流數據并傳輸到 bolts(消息處理者)點中進行計算,進而產生出新的輸出流.bolt輸出流也可以傳輸給其他bolts節點,形成流水線式的計算處理流.Storm也有不足之處,它并不支持狀態管理以及窗口、聚集等操作,支持的交付保證為“至少一次”而不是高要求的“恰好一次”.Storm 的容錯機制是 Ack機制,通信過程中需要的額外開銷可能會影響流計算的吞吐量.
Spark Stream(又稱為Structured Stream)其實是Spark[83,84]核心API的一個擴展,其對流式處理的支持其實是將流數據分割成離散的多個小批量的RDD數據(RDD是Spark的數據單元),然后再進行處理.這些小批量的數據被稱為DStream(D為Discretized,即離散化的意思).Spark Stream采用的是Lambda[85,86]架構,即同時運行批量處理和實時流處理的架構,其中,批量處理用來確保計算的正確性,而實時流處理則是為提高吞吐量.當實時流處理計算結果與批量處理的計算結果不一致時,則會校正錯誤,因為有批處理的存在,所以自然而然就實現了容錯機制.Spark Stream支持的是“恰好一次”的交付保證,而且與Storm一樣,Spark Stream并沒有狀態管理.
Samza系統處理的流數據單元是類型相同或相近的消息,這些消息在產生之后是不可修改的.新產生的消息將被追加到流中,而流中的消息也不斷地被讀取.每條消息可以有相應的鍵值,這些鍵值可以被用來對流中的所有消息進行分割.Samza的工作過程是按需計算轉換(或過濾)一組輸入流中的消息數據,并將計算結果以消息數據的形式附加到輸出流中.因此,運行工作負載可能包含多個工作組,工作組之間可能有流數據的依賴關系,進而將整體計算抽象成一個數據流圖框架.Samza的一大特色在于對狀態管理的良好支持,可以用來支撐流數據的連接操作,其狀態管理的引擎主要是RocksDB[87]和Kafka Log.
Flink與Storm相似,其整個數據處理過程被稱為Stream Dataflow,既定的數據流動框架類似于Storm的拓撲.Flink提取數據流的操作Source Operator、數據轉換(map,aggregate)的操作Transformation Operator以及數據流輸出的操作Sink Operator與Storm架構中Spout與Bolts之間、Bolts和Bolts之間的數據流是高度對應的,區別在于容錯機制:Flink的容錯機制是Checkpoint,通過異步實現并不會打斷數據流,因此Checkpoint的開啟與關閉對吞吐量的影響很小;Storm采用的是Ack機制,開銷大而且對吞吐量的影響明顯.另外,Flink提供的API相對 Storm更高級.Storm的優勢主要是具有比較成熟的社區支撐和經過較長期迭代之后的穩定性.目前,Flink成熟度較低,仍有部分功能需加以完善,如在線的動態資源調整等.Flink提供的交付保證是“恰好一次”,優于Storm的“至少一次”.Flink廣泛受到大公司的親睞,包括Uber和阿里巴巴,其中,阿里巴巴開發了基于Flink的流計算系統Blink,并應用在電商流數據計算中.
Kafka Stream是Apache Kafka[80,88]中的一個輕量級流式處理類庫,用來支撐Kafka中存儲數據的流式計算與分析.利用這個類庫計算的結果既可以寫回 Kafka,也可以作為數據源向外輸出.目前的流式計算系統基本都支持以Kafka Stream的輸出作為數據源,如Storm的Kafka Spout.Kafka Stream作為一個Java類庫而非系統,是流計算的重要工具之一.它可以非常方便地嵌入任意Java應用中,也可以任意方式打包和部署,除了Kafka之外,并沒有任何外部依賴.與流計算系統相比,使用 Kafka所受到的邏輯限制較少,開發者能夠更好地控制和使用Kafka Stream上的應用.Kafka Stream提供的是“恰好一次”的交付保證,并且能夠利用RocksDB進行狀態管理.目前,大公司在Kafka Stream上的實踐較少,相關技術有待進一步成熟.
這些流系統最主要的相似性是針對數據獨立性設計分布式并行計算策略,即:針對流式的輸入,利用集群進行協作計算,而整體的數據依賴框架一般是一個有向無環圖.集群的整體協作更像是流水線的協作,計算框架中的數據依賴所形成的數據流動方向基本上是單一既定的.除了數據處理的先后關系外,這些流系統對不同工作組之間的數據獨立性往往要求更高,可實現較好的并行效果.
已有針對這些流系統的基準比較(benchmarking)[89],然而系統的參數各不相同,同一系統在不同參數下的性能也會大相徑庭,所以benchmarking的結果可信度不足(見表5).目前,從流系統支持的功能上來看,Flink的功能是最完備的,有狀態管理、高吞吐量和低延遲、支持最嚴格的“恰好一次”交付保證、可調控內存使用等,并且不會出現容錯機制影響吞吐量的情況(如Storm).雖然Flink的社區積累較少,相關API不夠成熟,但在Uber、阿里巴巴等公司的使用和推廣之下,目前逐漸成為廣受歡迎、功能強大的流計算框架.

Table 5 Comparison of stream computing systems表5 流計算系統對比
3.4 圖數據流管理系統的探索
目前的流數據除了規模大和增長快之外,還有結構復雜的特點,而圖模型能夠以簡易的形式表達出豐富的語義,因此,圖模型與流數據模型融合而成的圖數據流模型應運而生[90].圖數據流的多種定義可以用無限增長的邊序列來概括(孤立點的現實意義有限),對應的研究問題除了傳統的圖計算問題之外,還有針對時間先后信息定義的研究問題,如滿足時序約束的路徑、子圖查詢等[91].常見的時序約束有時間先后、時間間隔.例如,阿里巴巴通過網購交易數據中的環形子圖的實時監控來追蹤通過網購進行惡意信用卡套現的行為[92].如圖1所示:一個信用卡惡意的套現模式中,套現者向商戶發起信用卡虛假購買,銀行將真實的資金支付給商戶之后,商戶通過中間人將資金回流到套現者儲蓄卡中,實現惡意套現.整個流程中,參與的對象和資金的流向構成了圖的結構,而每個行為環節有其明確的時間先后關系.因此,針對圖數據流的管理能夠解決很多現實中的重要問題.

Fig.1 Malicious cash arbitrage model of credit card[92]圖1 信用卡惡意套現模式[92]
在圖數據流的管理方法上,核心的思路仍是在于利用已計算出來的結果來加速當前的計算,并且需要將中間結果維護上的時間和空間代價控制在可接受的范圍內[93].以流數據上的子圖匹配為例,如果采用靜態算法構建復雜的索引的思路來加速查詢,則需要針對復雜的索引設計高速更新的算法.然而往往對查詢的加速容易增加更新的代價,在無索引的極端情況下,針對子圖的匹配需要完全重算;而在另一種極端情況下,即構建復雜的索引時,往往需要高額的更新時間甚至整個索引重構.因此,圖數據流下的計算首要考慮的是計算結果的維護與計算加速的權衡.此外,在圖數據流的高速更新場景下,多線程的并發計算仍然具有重要的意義.然而,圖數據中不同部分的關聯程度較高,如單條邊的刪除能夠導致大量路徑特征的改變等,因此,在圖數據流下進行并行算法設計和并發訪問控制等具有嚴峻的挑戰.
基于目前已有的圖數據管理的探索,可以總結出圖數據流管理系統所需要解決的三大重要問題.
· 第1個是對圖數據流中數據的基本操作的支撐,包括邊序列的存儲、增刪改查以及已獲取圖數據的基本訪問操作,如節點度數、鄰居等;
· 其次是針對圖數據流上的更復雜的挖掘和查詢支撐,包括邊流行為分析、路徑計算以及更復雜的子圖結構匹配等.對于復雜查詢和挖掘的支撐,所設計的索引一方面需要考慮對計算的加速保證,另一方面需要考慮在高速更新場景下對索引的更新維護代價;
· 第3個問題則是事務管理和并發、并行調度等機制的設計,旨在提高系統的吞吐量和縮短響應時間.
3.5 總結與展望
已有的數據流管理系統主要是在傳統的數據流管理模型和架構上作了持續性查詢的簡單擴展,兩者在語義和計算邏輯方面有相似之處,大部分數據流管理系統來自高校科研團隊,而且這些數據流管理系統已經難以處理大規模復雜數據流的查詢和計算.主流的流計算框架采用分布式的計算方式,利用數據獨立性的特點進行并行計算,與傳統的數據管理模型有很大區別.對數據的格式要求不高,能夠處理大規模的多種復雜數據流,有大量的社區支持以及大規模企業的實踐與推廣,大部分是來自開源社區而鮮有是學術界的科研團隊開發的.目前,對大規模生成的復雜數據的計算處理基本上依賴于流計算框架.由于對數據的獨立性要求較高,流計算框架不適于處理數據之間有高度關聯關系的模型,因此,目前針對圖數據流管理系統的研究受到了學術界和工業界的高度關注.
4 時空數據庫
4.1 引 言
時空數據庫是管理空間、時態以及移動對象數據的數據庫系統,與傳統的關系型數據相比,時空數據具有多維度、多類型、動態變化、更新快等特點,關系型數據庫不能很好地處理此類數據,需要新的有效數據管理方法.近年來,時空數據庫在地理信息系統、城市交通管理及分析、計算機圖形圖像、金融、醫療、基于位置服務等領域有著廣泛的應用.根據時空數據特點,時空數據庫大致包括以下3種.
· 空間數據庫:主要處理點、線、區域等二維數據,數據庫系統需提供相應的數據類型以支持數據表示、存儲、常見拓撲運算操作和高效查詢處理,同時需要與傳統的關系數據庫系統融合以擴展數據庫系統處理能力,支持不同類型數據的查詢處理;
· 時態數據庫:管理數據的時間屬性,包括有效時間(valid time)、事務時間(transaction time)等.時間可以為時間點或者時間區間:如果是時間區間,數據庫管理系統將以開始和結束時間兩個屬性或一個區間屬性進行存儲.不同的應用場景下,時間屬性會有相應的特點(例如周期性);
· 移動對象數據庫:管理位置隨時間連續變化的空間對象,主要有移動點和移動區域:前者僅是位置隨時間變化,后者還包括形狀和面積的變化.移動對象具有數據量大、位置更新頻繁、運算操作復雜等特點.近年來,隨著定位設備的不斷普及,例如智能手機,采集這類數據越來越容易.同時,與地圖興趣點(例如酒店、餐館等)相結合,使得移動對象具有語義信息,帶來各種新的應用,例如基于位置服務、最優路徑規劃等.
4.2 主要研究問題
· 數據模型和查詢語言
數據模型包含數據類型和運算操作兩個方面.時空數據類型包含多個,有些為定長記錄存儲(例如點、區間),有些為變長記錄存儲(例如區域、移動點).運算操作定義時空拓撲運算(例如相交intersect、重合 overlap),包含語法和語義兩個層面:前者描述輸入輸出參數類型,后者定義抽象層含義.時態和移動對象數據庫均處理具有時間因素的對象,數據類型和運算操作都涉及隨時間變化的數值,增加了復雜性,主要體現在如何表示數值的動態變化以及拓撲運算定義和求解方法上.移動對象除了要考慮自身的時空屬性外,還需要結合對象所在的受限制空間環境,例如道路網、室內空間等,因為位置表示與此相關.此外,不確定性時空數據也是研究內容之一,包括數據模型和查詢語言.時空數據類型可作為關系屬性嵌套在關系模式下,從而對查詢語言SQL擴展(運算操作、謂詞),以得到時空數據查詢語言,支持形式化查詢描述.
· 索引結構
根據不同時空數據的特點設計訪問結構,以支持快速查詢處理,常見的空間和時態索引有R-tree、K-d Tree、Interval-tree等.不同的索引結構有相應的運算操作,包括創建、插入、刪除、更新及查詢.其中,R-tree是最為廣泛使用的結構,為提高查詢效率,需對數據排序(例如 z-order),目的是將相似數據存儲在鄰近結構里,以減少搜索的I/O代價.同時,基于該結構的預測模型可以估計查詢的I/O代價,為進一步優化提供分析的依據.根據時間因素,移動對象索引可分為兩類:(i) 歷史數據索引,管理移動對象從開始到結束的所有位置和時間;(ii) 當前數據及預測索引,管理移動對象當前位置和速度并進行預測,提供有效的位置更新策略及數據緩存方法.由于移動對象的位置、時空分布、查詢等頻繁發生變化,主存索引及并行技術往往比外存索引更具優勢,自動調優技術對索引的參數動態調整以使性能最優.時空數據索引可以融入語義描述,從而拓展時空數據管理能力,以支持具有語義的時空查詢.
· 查詢處理及優化
選擇查詢和最近鄰查詢是空間和移動對象數據庫最常見的兩類查詢:前者返回在空間/時空查詢窗口內的對象,后者返回距離查詢目標最近的對象.當查詢目標是移動對象時,其最近鄰對象也動態地發生變化,稱為連續最近鄰查詢;當返回結果的最近鄰是查詢目標對象時,稱為反向最近鄰查詢.相似性查詢定義評價函數,用于計算對象之間的相似度,返回與查詢目標最相近的對象;連接查詢用于返回兩個數據集中所有符合查詢謂詞條件(例如相交、重合)的實體對,例如找出所有長江和黃河途經的城市.與選擇查詢、最近鄰查詢相比,連接查詢的復雜性更高,相關優化技術有數據劃分、索引創建、排序等.時空數據查詢還包括聚類查詢、模式匹配、距離查詢等.將關鍵字或語義描述與位置相結合,可進行具有語義的ranking或top-k查詢,返回對象不僅符合時空約束,而且滿足關鍵字條件,增加了用戶對時空對象的全面理解.
· 時空數據管理系統
在定義了抽象模型的基礎上,需要有系統實現模型包括數據結構和算法、邏輯設計及實現,同時需要將時空數據模型和關系模型有效融合,從而擴展數據庫處理能力.由于時空數據管理系統涉及多種索引結構和查詢算法(例如,基于R-tree的深度優先和寬度優先),因此需對數據庫系統的功能、性能及可擴展性等進行全面測試和評估,發現系統性能瓶頸從而進行優化.這主要通過基準測試完成,一般包括數據集(真實和模擬)、查詢集、索引結構及參數設置等,為模擬各種時空數據分布,需要相應的數據產生器及可視化工具.
除上述研究問題外,時空數據庫管理還涉及時空數據倉庫、時空圖數據、時空數據流、基于位置服務(最優路徑規劃和交通預測)、軌跡數據壓縮、時空數據挖掘和分析等方面.
4.3 國內外研究現狀
4.3.1 空間數據庫
依據不同的環境,空間數據庫的研究包括自由空間和受限空間(例如道路網、有障礙空間),主要區別在于距離函數,受限空間的距離計算依賴于最短路徑求解,比自由空間要復雜.相關查詢有范圍查詢、最近鄰(反向最近鄰)、Skyline查詢、動態道路網下最短路徑查詢和路徑規劃等,索引技術和搜索策略在查詢中起到了關鍵性作用[94].查詢過程一般包括過濾和提煉兩個階段:過濾階段借助于索引和估計值找到一組備選對象,提煉階段對每個備選對象進行準確值求解.空間數據庫查詢還包括最大范圍求和、容量受限分配等.在基于位置服務的應用中,隱私保護是一個重要的研究內容,已有的工作包括基于位置隱私的攻擊及保護方法,如模糊表示、匿名等.
近10年來,空間關鍵字查詢(spatial keyword search)得到了廣泛和深入的研究[95],通過將空間位置與文本相結合,用戶可以查詢同時符合空間和語義條件約束的對象,常見查詢有Top-k、k-NN等.由于傳統的空間數據索引不支持文本數據管理,一般將空間索引與文本索引或位圖技術相結合構成混合索引結構,支持同時對空間和文本數據的查詢,以縮小搜索范圍.
4.3.2 時態數據庫
在過去的20年里,時態數據管理一直是數據庫的活躍領域之一,研究內容包括數據模型、查詢語言、索引結構及高效查詢算法,各種查詢語言也被提出以支持時態數據查詢的形式化描述.Enderle等人基于常見的時態數據索引之一——Interval-tree設計了相應的外存結構以及在關系數據庫系統中的實現方法,可以有效支持相交查詢和連接查詢[96];Top-k查詢用于返回與查詢點(區間)相交且權重最大的k個對象.Dign?s等人將時態數據運算操作、轉換原則及查詢優化方法集成到關系數據庫系統內核中(PostgreSQL),以擴展其處理能力[97],商用數據庫Oracle提供了數據類型PERIOD及相關謂詞和函數.
近幾年,時態數據庫的研究主要集中在高效處理各種連接查詢(例如 overlap join,merge join)、聚類查詢(aggregation)以及數據劃分和排列方法(partition/splitter,align).同時,硬件技術(例如多核 CPU)的發展也有助于提高查詢效率.不確定性時態數據將時態數據和不確定性相結合,也有不少相關研究工作,包括數據表示及建模、不確定性時態數據查詢等;時態數據集成是根據用戶指定優先規則對多源時態數據加以融合.
4.3.3 移動對象數據庫
早期的移動對象數據庫研究主要集中在數據模型、索引和查詢處理等[98],代表性索引結構有 TB-Tree、SETI、TPR-tree、STRIPES等[99],這些結構的差異主要體現在時空數據的管理方法(例如插入原則、時空優先權)上,常見的移動對象查詢有范圍查詢、(連續)最近鄰、相似性軌跡、連接查詢等.針對大規模移動對象位置的實時更新,有學者提出了有效的更新策略及監控方法,也有學者對不確定性移動對象進行了研究[100].近年來,面向特定應用的移動對象查詢得到了廣泛的關注,例如軌跡模式匹配、異常現象分析、基于軌跡的用戶行為推薦、軌跡壓縮等.由于大規模移動對象數據獲取已相對容易,對歷史數據分析其結果可為應用提供支撐,例如最優路徑推薦、最優出行方式及路線規劃、交通流量預測等.除了支持時空查詢,系統也需要對用戶的位置信息進行有效保護,針對這一問題,有學者開展了基于位置隱私保護的研究.
人的運動除了在自由空間下,更多的時候是在受限空間下,例如道路網[101]、有障礙空間[102]和室內環境.不同環境的主要區別在于移動對象位置表示和距離函數:自由空間的位置通過坐標表示,距離函數基于歐式距離;而受限空間下的位置依賴于底層空間環境,距離函數與最短路徑相關,求解過程相對復雜.例如,道路網環境下采用Map-matching技術,將GPS位置(經緯度)映射到道路網從而得到道路網移動對象;在室內環境,移動對象位置獲取一般依靠RFID、WiFi等技術,位置表示則采用基于符號的表示方法.上述工作均是針對單個空間環境下的移動對象,也有學者將多個環境的不同位置表示方法相融合,形成統一的位置表示方法,支持人的完整運動軌跡表示以及不同運動方式的移動對象數據管理,例如步行→公交車→步行→室內.
在大數據背景下,新應用要求數據包含更多的信息以全面理解用戶行為,移動對象數據也從傳統的時空數據拓展到具有語義信息和行為描述[103,104].語義軌跡是將 GPS數據和時空場景相結合,例如興趣點或用戶行為,給移動對象賦予相關描述(可通過數據挖掘算法得出并以標簽形式存儲),豐富移動對象表示.基于語義軌跡的常見查詢有模式挖掘和匹配[103]、時空語義關鍵字查詢、top-k查詢以及移動用戶行為分析(規律性地訪問某些位置、規避和會合等).基于硬件的技術也被用于大規模軌跡數據查詢和分析,例如基于主存的軌跡存儲和查詢方法、分布式/并行軌跡數據處理平臺(基于Spark和Hadoop)、基于GPU的交互式時空數據查詢等,軌跡數據可視化技術也有相關研究.
4.3.4 時空數據管理系統
時空數據管理系統的設計主要有兩種思路:一種是對傳統關系數據庫管理系統的內核修改或擴展以支持時空數據管理,包括數據類型、訪問方法、查詢語言等;另一種則通過在應用層和傳統數據庫管理系統層之間構建一層結構,用于時空數據和傳統數據的相互轉換,即,在應用層以時空數據處理而在系統存儲層還是以傳統數據形式來加以處理.第1種方法能夠保證效率最優,第2種方法則能夠在較短時間內達到實際可行的效果.
并行處理技術在時空數據庫領域也得到了快速發展,主要用于大規模數據查詢處理[105].在空間數據庫方面,SpatialHadoop和HadoopGIS均是基于Hadoop的空間數據處理系統,Simba是基于Spark技術的空間數據分析系統[106],其對 SparkSQL進行了擴展,能夠有效地支持并發查詢.在時態數據庫方面,有基于PostgreSQL的時態數據查詢原型系統和在線實時時態數據分析系統 OceanRT.在移動對象數據庫方面,有針對軌跡數據處理的引擎 Hermes、支持多種軌跡數據挖掘操作及可視化系統 MoveMine、基于內存的分布式系統 SharkDB、DITA[107]、軌跡數據在線分析系統T-Warehouse、大規模軌跡數據管理和分析平臺UlTraMan[108].SECONDO是一個開源可擴充性數據庫管理系統,可對空間、時態和移動對象數據有效管理且支持并行處理[109].
4.4 總結與展望
時空大數據具有多維度、多類型、變化快等特點,給數據庫管理系統提出了新的挑戰:一方面,需要提供數據類型和運算操作以支持時空數據查詢;另一方面,高效查詢處理對數據庫性能有較高的要求.迄今,時空數據庫的發展趨勢包含以下幾點.
· 具有語義描述的時空數據管理,可分為時空數據和流數據兩類:前者針對包含關鍵字的時空數據進行查詢,后者針對高頻率的流數據進行連續查詢.為增加用戶滿意度,交互式和探索式查詢也是進一步研究的方向之一;
· 并行/分布式環境下的大規模時空數據管理系統.現有的時空數據庫原型系統需要在支持的查詢種類和通用性數據表示上進一步提升.同時,隨著越來越多的時空數據管理系統被研發,需要在統一標準下對系統的功能及性能進行全面測試和評估(benchmark).新型存儲設備(例如,SSD具有快速隨機寫等特點)的發展,將給位置頻繁更新的移動對象研究帶來新的契機;
· 具有智能性的時空數據庫系統.在人工智能技術快速發展的背景下,如何融入機器學習方法以增加系統的智能性,是新一代時空數據庫管理系統研究的內容,即,系統根據當前處理數據及查詢的特點自動進行索引結構和相關算法的調整以使性能最優,例如參數配置、數據劃分、緩存設置等.
5 眾包數據庫
5.1 引 言
Web 2.0時代涌現出了海量的在線互聯網應用.這些應用在悄然改變人們生活的同時,也為傳統的人本計算(human computation)提供了一種通過群體智慧求解問題的新模式——眾包[110],即“一種把過去由專職員工執行的任務,通過公開的 Web平臺,以自愿的形式外包給非特定的解決方案提供者群體來完成的分布式問題求解模式”[111].在過去的10余年里,基于Web的眾包技術已與人們的日常生活息息相關.維基百科(Wikipedia)、雅虎問答(Yahoo! Answers)以及百度知道等各類“問答系統”平臺均是這一技術的典型代表.近年來,移動互聯網的爆發更是催生出眾包的新形態——時空眾包[112,113].這是一種新型眾包計算模式,以時空數據管理平臺為基礎,將具有時空特性的眾包任務分配給非特定的眾包參與者群體為核心操作,并要求眾包參與者以主動或被動的方式來完成眾包任務,并滿足任務所指定的時空約束條件.時空眾包因具有信息世界與物理世界相聯系的特點,使其成為共享經濟的新型計算范式.實時專車類應用滴滴出行和物流派送類應用百度外賣都是共享經濟時代時空眾包應用的典型代表,并取得了巨大成功.眾包在通過互聯網匯聚群體智慧求解各類問題的過程中,動態生成海量多源異構數據,對這些數據進行有效的管理,是發揮眾包應用價值的關鍵.
5.2 主要研究問題
眾包數據管理的主要研究問題來自眾包工作流程中的3個不同階段.
· 第1階段:眾包任務的發布者將任務提交至眾包數據管理系統,系統將任務分配給適當的眾包參與者執行;
· 第2階段:眾包參與者將任務執行結果提交給眾包數據管理系統,系統對這些結果進行集成和處理后,將最終結果反饋給眾包任務發布者;
· 第3階段:眾包任務發布者收到系統反饋的任務執行結果后,根據任務完成質量等因素向眾包參與者提供適當的報酬.
上述工作流程中的3個階段反映了眾包數據管理中的3個研究問題.
· 任務分配:該問題涉及眾包工作流程的第 1階段,其核心目標是將眾包任務分配給合適的參與者,以實現各類不同的優化目標.例如,在基于Web的眾包中,眾包任務會根據其類型被分配給擅長執行該類任務的參與者,以優化任務完成的質量;在時空眾包中,眾包任務通常會被分配給任務位置附近的參與者,以優化任務發布者的等待時間.對該問題的研究主要面臨以下難點:(1) 任務分配具有動態性,即眾包任務和參與者動態出現在眾包平臺上;(2) 任務分配具有約束復雜性,即將任務分配給參與者通常需滿足各項約束條件;(3) 任務分配還要求兼顧有效性和效率.上述難點要求研究人員在對眾包數據進行有效存儲和索引的基礎上,設計高效的求解算法;
· 質量控制:該問題涉及眾包工作流程的第 2階段.眾包通過匯聚人類的群體智慧求解各類問題.因為人難免會犯錯,所以眾包數據管理系統通常無法將眾包參與者所反饋的任務執行結果直接反饋給任務發布者,而需要對結果進行質量處理.在基于Web的眾包中,系統通常根據對眾包參與者可靠程度、擅長領域和對問題的難度等因素建模,通過投票等方式對任務的結果正確性進行推斷,并將結果的可靠程度一并返回給任務發布者;在時空眾包中,系統則主要會考慮到任務位置與參與者的距離以及參與者的上線等時空因素,對任務完成的質量進行控制;
· 激勵機制:該問題涉及眾包工作流程的第3階段.眾包參與者執行任務需要花費各類稀缺資源,例如:在基于Web的眾包中,參與者執行各類圖片標注任務需花費注意力;而在時空眾包中,網約車平臺的私家車車主則需付出車輛的使用成本等.眾包數據管理系統需要對參與者進行有效激勵,以使得他們愿意繼續留在眾包系統中以提供服務.雖然金錢激勵是直接而有效的激勵方式,但是制定健全而合理的激勵額度并不是一個簡單的問題.在基于 Web的眾包中,參與者完成任務的質量以及任務的難度是激勵機制設計的重要參考指標,而在時空眾包中,不同時空區域內任務和參與者之間的供需狀況也會對激勵機制產生影響.
除上述研究問題外,眾包數據管理還研究眾包任務的設計、對眾包參與者隱私的保護等方面.
5.3 國內外研究現狀
近年來,國內外研究人員已展開了眾包數據處理的相關研究,并取得了不少技術突破[114-116].眾包數據處理可分為兩類:眾包數據管理機制與基于眾包策略的數據處理技術.此外,基于上述研究,人們還設計和開發了各類眾包數據管理系統.
5.3.1 眾包數據管理機制
下文將對任務分配、質量控制與激勵機制這3類問題進行簡單分析.
1) 任務分配
任務分配一直都是算法研究領域的重要問題之一,文獻[117]首先針對單一用戶所提供的同一類型眾包任務定義了在線任務分配問題,旨在一段時間內,以在線方式最大化眾包任務分配數量.文獻[117]設計了一種采用原始對偶模式(primal-dual schema)的近似算法用于在線任務分配.后續工作擴展了在線任務分配問題的定義,提出了在線異構任務分配問題,也針對此問題擴展了原始對偶模式近似算法[118].文獻[119]針對時空眾包中任務和參與者均動態出現的應用場景,提出了具有競爭比保證的任務分配算法,以最大化總收益.文獻[120]研究了最小化眾包參與者總移動距離的雙邊在線任務分配問題.文獻[121]考慮到眾包任務執行場所的影響,研究了面向 3類對象的在線任務分配問題.文獻[122]提出了基于預測[123]的眾包參與者調度和眾包任務分配算法.文獻[124]針對拼車問題提出了通用的優化方法,其解決方案適用于眾包參與者具有容量約束的眾包任務分配問題.
2) 質量控制
眾包技術已被應用于眾多領域,質量控制機制是眾包研究的核心問題之一,針對各類具體應用的眾包質量控制研究被廣泛提出.具體而言,眾包數據處理的質量控制機制研究可分為如下兩類:(1) 眾包參與者誤差估計;(2) 眾包結果的集成機制.前者側重于對不同眾包參與者單一個體的誤差估計;而后者需根據誤差估計所得誤差概率,再進一步對不同眾包參與者的反饋進行符合質量控制要求的結果集成,并匯聚成最終答案.下文將對這兩方面研究分別加以簡要回顧.
眾包參與者誤差估計通常是指采用少數服從多數原則、EM算法或其他學習算法,根據眾包參與者的歷史數據推斷出眾包參與者的誤差率.文獻[125]針對標注查詢設計了一種概率圖模型,用來推斷任務標注、每位眾包參與者的誤差率與眾包任務難度.文獻[126]提出了一種經驗貝葉斯算法——SpEM,通過EM框架中的迭代過程來清除水軍用戶,從而采用真實標注對最終標注結果進行估計.另一類有代表性的工作是針對不同的眾包任務選擇不同的眾包參與者,從而保證執行每個眾包任務的眾包參與者的誤差率盡可能地小.例如,文獻[127]提出了一種選擇性重復標注的方法,通過重復標注來提高標注結果的準確性.以上 3項研究均提供了啟發式的眾包參與者誤差估計算法,而如下 3項工作又進一步對其所估計的誤差率進行了定界分析:當給定一個眾包參與者的集合時,文獻[128]證明了全部眾包參與者集體的誤差估計值上界,但無法用于單一眾包參與者誤差的估計;對于單一的眾包任務,文獻[129]證明了每項任務所最終得到正確答案的概率上界與下界,但其所分析的目標為眾包任務而非眾包參與者的誤差率;最后,文獻[130]對單一眾包參與者誤差進行了區間估計分析,并對眾包參與者的誤差估計提供了置信區間估計算法.
眾包結果的集成機制:根據眾包參與者誤差的估計值,對一項眾包任務的不同眾包參與者反饋進行集成并產生最終任務結果,也是眾包質量控制機制的一個主要研究方向.文獻[131]提出了一個質量敏感應答模型CDAS,包含預測模型與驗證模型兩個子模型:前者用于估計一項指定眾包任務所需眾包參與者的數量,后者則根據用戶反饋選擇最優答案.另一類有代表性的工作是根據眾包參與者的誤差率,為一項眾包任務發現一個最優的眾包參與者群體,又被稱為陪審團(jury).最優有兩類定義:第 1類是指在給定眾包預算成本的條件下,發現一個陪審團,使其對此任務的陪審團錯誤率(jury error rate,簡稱JER)盡可能地小[132];另一類定義是指在給定陪審團錯誤率的條件下,發現一個陪審團,使其支付成本盡可能地小[133].文獻[132]證明了第 1類定義是 NP-Hard的,并給出相應的近似求解算法;隨后也對第2類定義給出了相應的近似算法[133].
(3) 激勵機制
激勵機制也一直是眾包機制研究的核心.對于一項指定的眾包任務,在眾包平臺中應該如何定價才能保證有足夠的眾包參與者協同完成此任務.文獻[134]針對通用在線眾包平臺上的眾包市場提出了兩種定價策略:第1種是在給定眾包任務預算約束的條件下,通過優化定價策略來最大化被分配的任務數量;第2種是在給定需完成任務數量的約束條件下,最小化支付成本.針對每種定價策略,文獻[135]分別給出了常數競爭比的在線近似算法.文獻[135]提出了一個基于遺憾最小化方法(regret minimization approach)的在線定價機制,該機制提出一種基于貪心策略的采購拍賣算法,從而獲得近似最優的求解保障.文獻[136]著重研究了完成眾包任務的時間延遲與眾包定價策略之間的關系.針對給定任務完成截止時間與給定任務預算成本兩類不同約束條件,分別設計了一系列基于隨機過程的最優定價算法,并證明了近似算法存在近似最優解.文獻[137]研究了針對復雜眾包任務的激勵機制,通過將復雜任務適當地分解成微任務,在滿足任務完成質量的約束下最小化支付成本.文獻[138]針對時空眾包市場中不同空間區域和時間段供需不平衡的特點,提出了基于匹配的動態定價策略.
綜上所述,3類眾包數據管理機制的研究都針對于現存的在線眾包平臺,如 AMT、CrowdFlower和 oDesk等.下面兩節將分別進一步闡述3類機制在眾包數據處理和眾包數據管理系統中的應用和擴展工作.
5.3.2 基于眾包策略的數據處理技術
眾包數據處理技術作為當前數據庫與數據挖掘領域一項新興的研究熱點,主要側重于如何將眾包策略融入到傳統數據庫管理系統的經典查詢處理與挖掘操作之中,從而提高數據處理的質量或拓寬查詢處理與挖掘操作的應用范圍.本節主要對現存的基于眾包策略的幾類經典查詢與挖掘技術進行簡要的回顧.
(1) 篩選查詢
在基于眾包策略的查詢處理中,最基礎的一項查詢處理操作是篩選查詢(flitering query),文獻[139]首次在眾包數據處理的背景下提出此類查詢和其求解框架CrowdScreen.CrowdScreen的主要貢獻在于,其并不認為簡單的少數服從多數原則是合理的,并分別以眾包期望成本與結果期望誤差率為優化目標,將眾包的篩選查詢細化為 5類情況,并對每種情況給出了確定性與概率性求解算法.其后續擴展工作進一步放松了文獻[139]的眾多假設條件,從而進一步提高了通用性[140].通過增加眾包參與者們的先驗信息與后驗信息,以及對不同用戶能力的細化分析,大幅度提高了算法執行效率,同時也降低了眾包支付成本.
(2) 排序查詢與Top-k查詢
排序查詢(ranking query)與 Top-k查詢始終是數據處理技術中的核心操作之一.文獻[141]首先定義了眾包環境下的最大者查詢問題,即 Top-1查詢,該問題旨在返回滿足投票矩陣的條件下具有最大可能性的數值最大者.文獻[141]也證明了該問題是 NP-Hard,設計了一系列的啟發式求解算法.文獻[142]擴展了上述研究結果,提出了基于眾包的Top-k查詢,即:在滿足誤差閾值的情況下,最小化眾包支付成本(即眾包參與者為成對數據項進行比較的次數).文獻[142]證明了此眾包期望支付成本的理論下界.文獻[143]提出了一個基于打分和排序的眾包Top-k查詢計算框架.
(3) 連接查詢、實體同一與模式匹配
連接查詢是數據庫領域的經典查詢操作之一,其在眾包數據處理中通常是指基于眾包的實體同一性查詢.實體同一性查詢(entity resolution)與模式匹配(schema matching)是關系數據庫的數據集成過程中兩類重要的操作.
實體同一(基于眾包的連接查詢):文獻[144]提出一種人機混合的實體同一性查詢通用求解框架——CrowdER.該框架假設眾包參與者的反饋一定正確,將基于眾包的實體同一性查詢歸約到基于聚類的 HIT(human intelligence task)產生問題,并證明了此問題是NP-Hard,同時給出兩種高效的啟發式算法求解該問題.文獻[145]擴展了文獻[144]的求解框架,并融入了實體間傳遞性的概念,大幅度提升了基于眾包的實體同一性查詢效率.文獻[146]考慮了不同實體之間同一性的先驗概率分布,以最小化眾包任務期望詢問數量為目標,證明該優化問題是NP-Hard,并給出了相應的隨機求解算法.
模式匹配:文獻[147]首先提出了基于眾包的模式匹配問題,并通過可能世界語義對該問題進行了形式化描述,采用信息熵來度量模式匹配中任意兩模式相似度的穩定性.根據信息熵設計了基于貪心策略的模式匹配問詢機制,從而最小化眾包支付成本.文獻[148]研究了基于眾包策略的Web表格匹配問題,提出一種新型的效用函數,既包含匹配難度,又可測量不同Web表格屬性間的相似性.基于此效用函數,文獻[148]證明Web表格匹配問題是NP-Hard,并給出了近似比為(1-1/e)的近似算法.
(4) 計數問題與枚舉查詢
計數問題是集成查詢(aggregation query)的基礎,也是傳統關系數據庫理論中Group By子句執行的關鍵.為了擴展傳統集成查詢的適用范圍,文獻[149]首先提出了基于眾包的計數問題,即:給定一個數據項集合與一個篩選規則,令每名眾包參與者反饋符合篩選規則的數據項個數(可以不很精確),匯聚全部眾包參與者的反饋并估計最終符合篩選規則的數據項個數.不同于傳統的基于二選一投票類型的眾包操作,文獻[149]的眾包基礎操作就是一個粗糙的計數問題.同時,也針對網絡水軍(spammers)的檢測與清除設計了處理機制,最終給出了一種基于置信區間的計數估計算法.
枚舉查詢也是傳統數據處理的核心問題之一,其結果集的唯一性源自于傳統數據庫中的封閉世界假設(closed world assumption).為了擴展眾包數據處理的范圍,文獻[150]打破了封閉世界假設,并提出了基于眾包策略的枚舉查詢.在沒有封閉數據庫支持的情況下,新型查詢將處理如“枚舉北京航空航天大學喜愛看電影的同學”的查詢問題.核心思想在于通過不同眾包參與者的反饋分析其所枚舉的交集比重,采用置信區間以估計值快速計算枚舉結果的可信度,同時,在滿足置信度約束的情況下最小化眾包支付成本.
(5) 關聯規則挖掘與聚類分析
本部分主要介紹兩類基于眾包策略的數據挖掘研究.其中,關聯規則挖掘與聚類分析都是傳統數據挖掘中的核心技術,最近的相關研究已將眾包策略有效地融入到兩類技術之中,擴展了它們的適用范圍.文獻[151]打破了傳統數據庫中的“封閉世界假設”,進而提出基于眾包的關聯規則挖掘問題.旨在通過收集人腦中的關聯規則經驗,通過詢問眾包參與者形如“A與B是否經常一起出現?”的問題來估計不同項集的支持度,從而估計出關聯規則的置信度.文獻[152]提出了一個貝葉斯模型來學習不同眾包參與者的聚類特點與數據項自身的結構性特點,從而獲取基于眾包的高質量聚類結果.
5.3.3 眾包數據管理系統
近年來,隨著對眾包數據管理機制和基于眾包策略的數據處理技術的研究日益深入,依據上述成果的眾包數據管理系統也被設計和開發出來.代表性的眾包數據管理系統有眾包數據庫 CrowdDB[153]、Deco[154]、Qurk[155]、CDB[156]和眾包數據管理平臺DOCS[157]、gMission[158]等,下面分別對這些系統進行簡要介紹.
CrowdDB通過引入眾包機制,使得數據庫系統能夠完成一些本來無法完成的查詢操作,如針對未知或不完整信息的查詢、涉及主觀比較的查詢等.CrowdDB使用擴展自 SQL的查詢語言 CrowdSQL,支持用戶使用“CROWD”關鍵字定義數據表和屬性,指示數據表的內容和屬性列中的值需要通過眾包補充完整.CrowdDB設計和實現了相應的查詢編譯和運行時系統,能夠通過自動生成的用戶接口利用眾包獲取數據.
Deco與CrowdDB類似,同樣提供了基于SQL的查詢語言,允許用戶通過該語言在系統中存儲的關系數據和通過眾包獲取的數據上進行各類查詢.此外,Deco設計了具備可擴展性和通用性的數據模型,支持數據清洗等功能,并定義了精確的查詢語義.Deco的查詢處理器使用了一種新型的推拉混合式執行模型,在執行查詢的同時,兼顧眾包本身具有的時延、不確定性等特點所帶來的挑戰.
Qurk使用基于SQL的查詢語言,并支持用戶定義函數(user-defined functions,簡稱UDFs).為了方便用戶使用UDFs,Qurk提供了預定義的眾包任務模板,可以生成支持過濾和排序等眾包任務的眾包界面.此外,Qurk設計了任務緩存和任務模型進行查詢優化:任務緩存將先前眾包任務的結果緩存起來,任務模型基于已經收集到的眾包數據訓練模型預測眾包任務的結果.無法通過任務緩存和任務模型獲取的數據,將由系統自動地通過眾包方式獲取.
CDB定義了查詢語言CQL并使用基于圖的模型進行查詢優化,可提供細粒度的元組級別優化.在該模型的基礎上,CDB采取了一種統一框架,可對時延、成本、質量等多種目標進行優化.
表6對上述眾包數據庫進行了比較[159].

Table 6 Comparison of crowdsourcing DB systems表6 眾包數據庫系統的比較
除了上述眾包數據庫之外,學術界也提出了一些眾包數據管理平臺.DOCS是一個具備領域感知能力的眾包數據管理平臺,它通過知識庫對眾包參與者和眾包任務涉及的知識領域進行分析,并基于分析結果對參與者完成不同領域任務的質量進行細粒度建模.DOCS同時具備真值推斷和動態任務分配功能,能夠利用對參與者擅長領域的細粒度建模準確推斷出任務的真實結果,并把眾包任務分配給擅長任務相關領域的眾包參與者.gMission是一個開源的通用時空眾包數據管理平臺,具有任務分配和結果集成功能.
5.4 總結與展望
現存的研究已將眾包策略成功地集成到傳統數據處理技術之中.眾包策略可以提高傳統數據處理技術的準確性,同時可打破傳統數據處理的“封閉世界假設”,從而擴展傳統數據處理技術的適用范圍.此外,近年來,隨著移動互聯網技術的廣泛應用,時空眾包數據處理技術正在成為眾包數據處理研究中的新興熱點.為了進一步完善眾包數據管理系統,以下問題還有待解決.
· 眾包數據管理系統的查詢優化問題.不同于傳統數據庫的查詢優化問題,其不同查詢方案的執行成本可得到較為準確的估計,且優化目標較為單一;在眾包數據庫中,由于所涉及的眾包群體存在較大不確定性,且優化目標涉及時延、質量、花費等諸多復雜因素,眾包數據管理系統的查詢優化問題還未得到有效解決;
· 時空眾包數據的存儲與索引問題.因為時空眾包數據包含動態的時空數據、高維屬性數據與時空沖突數據,所以,傳統的離線靜態場景中的時空數據查詢索引技術并不適用.如何對空間眾包數據進行有效的存儲與索引,進而支持各類時空眾包數據查詢處理,是未來研究的關鍵.一個極具潛力的研究問題是設計一種針對時空眾包數據特性的存儲策略與通用的索引結構;
· 隱私與數據保護問題.眾包機制已經廣泛應用于數據標注和收集等任務,在這些任務,特別是時空眾包任務的執行過程中,存在任務發布者數據泄露以及任務執行者隱私泄露的問題.通用的隱私和數據保護方案可在一定程度上緩解該類問題,但均會對眾包的效率和質量造成影響.
6 其他研究熱點
除了上述研究方向外,數據庫領域還涌現出很多其他研究熱點.例如:新硬件技術(包括內存技術)改變了數據庫的底層框架設計和查詢優化的代價模型;近似查詢技術能夠以更小的代價支持更大規模數據上的查詢;數據的可視化技術為用戶提供更加友好的數據展示方式.下面分別簡述這些研究熱點.
6.1 新硬件
新硬件技術的發展為數據管理技術帶來新的挑戰,也帶來明顯的機遇.作為系統軟件,數據庫底層需要針對新硬件的發展做出適應性調整,充分利用新硬件帶來的便利,同時避免新硬件自身約束導致的新瓶頸.目前研究較多的新硬件包括高性能和專用處理器、高速網絡、大內存(見下一小節)和非易失性內存等.
· 基于高性能和專用處理器的數據管理方法:目前,高性能處理器技術進入多核時代.相對應地,數據庫底層核心算法需要充分考慮多核并行的能力,重新設計連接、排序等基本操作[160].圖形處理器GPU[161]、現場可編程門陣列 FPGA[162]等專用處理器具備更大規模的數據并行操作能力,從而提升數據的向量處理效率,支持數據庫內核范圍內的機器學習等任務.同時,不同特性異構硬件的協同操作也成為研究問題.例如,GPU的顯存相比于內存容量要小,數據加載到 GPU顯存的操作代價較高,面向數據管理的CPU和GPU的協同架構就是希望充分發揮不同硬件的優勢[163],避免其中可能的瓶頸操作;
· 基于高速網絡連接的數據管理方法:在傳統的分布式數據庫或者并行數據庫環境中,網絡的傳輸速率遠低于內存訪問速率,在分布式查詢和事務管理等部件中都將網絡傳輸作為主要代價之一.隨著RDMA等高速網絡技術的發展,網絡傳輸代價大幅度降低.現有的研究工作基于RDMA高速網絡的特性,設計了新的分布式連接方法[164]和分布式并發控制策略[165]等;
· 基于非易失存儲的數據管理方法:非易失型存儲器支持內存式的按字節的高速尋址,同時支持外存式的持久化能力,得到數據管理領域的高度關注.非易失型存儲器存在讀寫操作不對稱和寫耗損等約束.目前,非易失型存儲器的價格較高、容量較小.現有的研究討論了非易失性存儲器和內存、閃存等不同特征的存儲介質在體系結構層面的結合方式[166]、非易失存儲環境中的數據庫恢復機制[167]等問題.
6.2 內存數據庫
內存數據庫就是以內存為主要數據存儲介質、在內存中直接對數據進行操作的數據庫.相對于以磁盤為主要存儲介質的傳統數據庫,內存數據庫帶來數量級的性能提升.內存數據庫的發展受益于內存價格的降低以及內存容量的迅猛增加.同時,目前內存常見的64位尋址,使得將全部數據加載到內存空間成為可能.
傳統數據庫查詢執行的主要瓶頸在于 I/O操作,而在內存數據庫中,內外存數據交換不再成為代價的主要來源.內存數據庫需要考慮現有CPU特性對內存操作的影響,如CPU中的緩存、指令和數據的預取、共享數據結構上并發訪問的控制機制等.上述變化導致內存數據庫在數據組織、數據索引、事務機制、查詢優化等方面與傳統數據庫不同[168].
· 數據組織.從CPU的角度,內存數據庫中數據可以按照其處理器核進行劃分,同一個劃分中數據操作串行,減少并發控制帶來的各種代價;也可以采用所有處理器核都可以訪問全部數據的方式.從數據版本的角度,內存數據庫通常采用多版本機制,提升查詢處理效率.從行列存儲的角度,內存數據庫可以選擇行存儲或者列存儲,同時,其列存儲在交易型應用中表現良好[169];
· 數據索引.內存數據庫索引設計主要考慮兩個主要因素:首先,內存索引節點的大小一般與CPU緩存大小相關,其索引數據的存儲滿足一定的連續性,從而在索引操作過程中提升CPU緩存的命中率,典型工作如 CSB+樹[170]等;其次,內存索引結構的設計需要考慮多核環境中的并發查詢和更新,盡量減少內存數據結構中并發鎖的使用,降低索引維護代價,典型工作如BW樹[171]等;
· 事務機制.內存數據庫的并發控制機制主要采用傳統數據庫的多版本并發控制協議[172],通過保存不同
版本,從而支持無阻塞高效率的讀取操作,部分協議采用樂觀并發機制,引入驗證階段判定事務是否可以提交.此外,考慮 CPU 的多核特性,內存數據庫還可以在數據按照處理器核來劃分的情況下,設計劃分串行執行協議[173],即:同一劃分內數據串行操作,劃分之間數據并行操作.目標是減少多核對同一數據并發控制代價或者沖突導致的回滾代價.
6.3 近似查詢
相對于傳統的數據庫精確查詢,近似查詢能夠以較小的代價獲得近似的查詢結果.近似查詢技術在大規模數據分析、趨勢發現、快速可視化等領域都有一定的應用前景.近似查詢技術可以通過不同維度來刻畫,包括所支持查詢的表達能力、錯誤模型和精度保證、運行時刻代價節省以及預計算結構的維護代價等[174].通常認為,幾乎不可能構建這樣的近似查詢系統:其能夠支持豐富 SQL特征查詢,運行時刻提供高質量的查詢質量保證,并且能夠明顯地節省運行時刻的代價.近似查詢技術可以粗略劃分為兩大類——在線查詢執行和通過預計算結果支持查詢[175].
· 在線查詢執行.其基本思想是:查詢能夠時刻反饋當前運行結果,同時提供結果精度區間.隨著時間的推移,參與計算的數據量增多,查詢結果精度不斷提升.用戶可以決定什么啟動查詢或者停止查詢.這一模式在粗略觀察數據的場景中得到應用.此外,這一模式沒有預計算結果的維護代價.執行過程中一般采用采樣策略,查詢基于動態采樣的數據執行.現有工作提出了不同采樣策略及其查詢處理策略,例如,偏有效查詢結果集合采樣的Wander連接策略[176]等.某些在線查詢的方法已經集成到開源或者商業數據庫系統中;
· 通過預計算結果支持查詢.其基本思想是:引入可控誤差,將大數據預計算為某種形式的、與原有數據某個特征類似的“小數據”.后續的查詢直接基于預計算結果執行.相對于在線采樣,基于預算結果的查詢執行方式更加高效.針對特定的預計算結果和查詢,這種模式能夠給出查詢的精度保證.但是隨著底層數據的變化,這些預計算的數據也需要維護.根據預計算結果的形態不同,預計算模式可以進一步劃分為基于直方圖的近似查詢(等寬直方圖、等高直方圖、壓縮直方圖、自適應直方圖等)、基于采樣的近似查詢(隨機采樣、有偏采樣、重要性采樣等)、基于小波的近似查詢等.這一模式也有相關的原型系統,如 BlinkDB[177]等.
6.4 數據可視化
數據可視化利用計算機圖形學、數據分析、用戶交互界面等技術,通過數據建模等手段,為用戶提供有效的數據呈現方式.數據可視化能夠幫助用戶迅速理解數據、定位問題.近期發展的可視化技術可以從不同維度來刻畫,如可視化后臺的數據類型、不同類型的可視化交互技術等[178].我們主要從數據類型的角度,分析數據可視化技術的進展.
· 圖數據可視化:圖數據在很多領域中自然存在,如社交網絡等.圖數據的海量規模(包括海量的節點和邊數據)以及有限的可視空間限制,成為圖數據可視化的主要挑戰.現有工作側重于圖簡化的思路[179],通過邊聚集或者點聚集,構建不同層次的圖,同時引入交互策略,支持用戶對其感興趣的部分作進一步的動態分析;
· 時空數據可視化:時空數據是包含時間維度和空間維度的數據,其空間維度通常與地理系統加以結合.為了展示對象隨著時空維度的變化情況,采用屬性可視化技術,如將事件流和地理流相結合的Flowmap方式[180]、時間-空間-事件等信息的三維立方體方式等;
· 多維數據可視化:多維數據是包括多個維度屬性的數據,如數據倉庫中銷售數據等.多維數據的可視化技術目標是更加友好地呈現數據,從而方便用戶對整體分布和不同維度之間關系的理解.具體的展示方式包括散點圖、平行坐標等[181].
7 總 結
數據相關技術的發展給整個社會帶來了巨大的變革,也給相關的技術領域帶來了巨大的挑戰.不同領域的學者均嘗試從自身的角度出發來解決大數據的種種問題,基于這些成果構建了若干實際可行的新型系統.但是隨著數據規模以及應用需求的進一步發展,未來的數據管理技術仍然面臨著新的問題和轉變.
· 新型數據管理系統需要更自然、更高效地支持不同類型、不同來源的數據.針對應用中出現的不同類型數據管理需求,現有的系統大多是通過構建專用系統來解決,例如圖數據管理系統、時空數據管理系統等.而應用中,這些數據混雜在一起,按照數據類型劃分到不同數據系統中,這種管理方式不高效,也不自然.新型數據管理系統需要提供通用的底層數據模型,統一支持不同類型數據的存儲、查詢、分析、優化等操作;
· 新型數據管理系統需要在體系結構方面實現擴展.為了減少系統復雜性,提高系統穩定性,在現階段通過松耦合包容不同類型數據的管理系統,為用戶提供統一的數據管理和分析服務,是支持不同數據模型的可行技術路線.此外,數據管理系統需要考慮異構的計算資源.異構計算環境廣泛存在于真實應用場景中,包括資源共享與競爭、網絡和計算能力差異以及新型硬件帶來的異構性.異構計算環境會對新型數據管理系統的效率帶來極大的影響,同時,新型硬件的發展也為新型數據管理系統提供了新的機遇;
· 新型數據管理系統需要在計算模型方面實現擴展,滿足不同數據模型的管理需求,支持系統松耦合管理體系.機器學習是目前的技術熱點,在自然語言處理、計算機視覺等方面取得突破.新型數據管理系統需要和機器學習實現融合,包括在數據庫內核層面實現機器學習方法,深度分析數據,提供更加強大、友好的用戶接口.此外,機器學習技術為現有數據操作實現帶來新的思路,如通過學習構建索引、自然語言查詢等,需要在數據管理內核方面融入更多的機器學習技術,通過緊耦合提升現有數據管理系統的效率和可用性.
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
