方法級別的細粒度軟件缺陷定位方法?
2019-03-05 03:45:12李自強杜宇航
軟件學報 2019年2期
張 文,李自強,杜宇航,楊 葉
1(北京化工大學 經濟管理學院,北京 100029)
2(北京工業大學 經濟管理學院,北京 100124)
3(School of Systems and Enterprises,Stevens Institute of Technology,Hoboken,NJ 07030,USA)
軟件缺陷是計算機程序或系統中的錯誤、故障或瑕疵,導致其產生不正確或意料之外的行為方式[1].軟件缺陷的存在,會導致軟件產品在某種程度上不能滿足用戶的需求.在軟件項目開發過程中,一些缺陷跟蹤系統常被用于管理缺陷,如 Bugzilla(Bugzilla:https://www.bugzilla.org/)、JIRA(JIRA:http://www.atlassian.com/software/jira/)、Mantis(Mantis:https://www.mantisbt.org/)等.這些缺陷跟蹤系統被用于管理軟件項目開發中缺陷報告的提交、確認、分配、修復、關閉等整個軟件缺陷的生命周期[2].對于一個大型軟件項目來說,每天都會收到用戶提交的大量軟件缺陷報告,而且修復這些軟件缺陷耗費了缺陷修復人員大量的時間和精力.例如,在Eclipse項目版本發布日期附近,每天有將近200個缺陷報告被提交到Eclipse項目缺陷報告庫.同樣,每天有將近150個缺陷報告被提交到Debian項目缺陷報告庫[3].根據Jeong等人[4]的研究,在PostgreSQL項目中,大部分缺陷需要100天~200天被修復;甚至有50%的缺陷報告需要將近100天~300天才能被修復.根據本文對所采用的Tomcat7項目的觀察結果:大部分缺陷在40天~200天之內被修復;10%的缺陷在10h之內可以得到修復;另有5%的缺陷需要將近2年才能被最終修復.
一旦軟件缺陷報告被缺陷管理人員所確認和分派給開發人員進行缺陷修復,那么被指派的缺陷修復人員就要進行缺陷定位,也就是找出為修復該缺陷所需修改的代碼片段,然后進行缺陷修復[5].對于軟件維護人員來講,要對某一個缺陷進行修復,首先必須對缺陷相關信息進行充分的了解.為此,軟件維護人員需要閱讀大量的軟件源代碼來幫助自己確定缺陷所在的位置.當缺陷報告和源代碼文件的數量很多時,軟件缺陷定位就是一件非常費時、費工的任務.如果一個缺陷久久不能定位到正確的位置,缺陷修復的時間就會增加,相應的軟件項目的維護成本也會增加,同時用戶對軟件產品的滿意度就會下降.
近年來,研究學者提出了一系列軟件缺陷定位方法,以期輔助缺陷修復人員進行軟件缺陷定位,減少其在缺陷修復時的工作量.軟件缺陷定位一般可分為靜態定位方法和動態定位方法:靜態缺陷定位依賴于軟件缺陷報告、源代碼和開發過程靜態信息來進行軟件缺陷定位[6];動態缺陷定位依賴于插樁技術、執行監控和形式化方法等技術來進行軟件運行時狀態跟蹤,以確定軟件缺陷可能發生的位置[7].靜態定位方法的優點主要是不要求一個可運行的軟件系統,可以使用在軟件開發和維護的任意階段[8].本文的研究焦點在于靜態缺陷定位方法,即如何利用信息檢索技術來提高軟件缺陷定位的精度和效率.
不同于傳統的將軟件缺陷定位為文件級別的方法,本文提出了一種方法級別的細粒度軟件缺陷定位方法:MethodLocator,輔助軟件缺陷修復人員進行缺陷定位.具體來說,為了解決方法體中的詞項稀疏問題,MethodLocator使用基于word2vec詞向量的文檔向量表示方法[9]對缺陷報告和源代碼方法體內容進行向量表示;然后,利用夾角余弦計算缺陷報告和源代碼方法之間的相似度,進而對查詢結果進行排序.在對方法體進行自然語言預處理的過程中,考慮到單個方法相對于單個缺陷報告的文本內容較短,本文根據方法之間的相似度,利用其他方法對該單個方法的內容實施了進一步的擴充.本文的貢獻包含了以下3個方面.
1)在對傳統的缺陷定位方法進行全面回顧的基礎之上,本文提出了一種方法級別的缺陷定位方法MethodLocator.
2)本文首次提出了結合詞向量[9]和TD-IDF的源代碼方法和缺陷報告向量表示方法,并提出利用單個方法的相似方法對其表示向量進行擴充的方法,其目的是減小單個方法向量表示的特征稀疏性.
3)本文自行完成了對ArgoUML、Ant、Maven和Kylin這4個開源項目的缺陷數據及其對應的方法級別的源代碼變更數據的收集,建立了方法級別的缺陷定位研究的標桿數據集.
本文第1節介紹近年來在軟件缺陷定位方法研究方面的相關研究進展.第2節提出一種方法級別的細粒度缺陷定位方法MethodLocator.第3節和第4節對本文所提出的MethodLoactor方法與基準方法進行實驗論證和充分比較.第5節總結全文并提及未來的工作.
1 相關研究
本文的相關研究主要包括軟件缺陷靜態定位方法.Poshyvanyk等人利用潛在語義索引和概率檢索模型提出了PROMESIR方法[10].該方法將源代碼中的特征定位問題轉化為不確定性的決策問題.PROMESIR結合了兩種特征定位技術,即基于情景的事件概率排序和使用潛在語義索引的信息檢索技術來進行軟件缺陷定位.他們對Mozilla Web瀏覽器的源代碼缺陷數據進行了實驗,其結果表明,與獨立使用一種技術相比,PROMESIR組合使用兩種特征定位技術,顯著提高了缺陷定位的有效性.
Lukinsu等人[5]提出了一種基于LDA(latent dirichlet allocation)的自動缺陷定位技術,并就下述5個問題開展了廣泛的實驗:(1)他們在之前基于LSI的缺陷定位方法應用的數據集上進行了實驗,結果顯示,基于LDA的缺陷定位方法的準確性更優;(2)在軟件項目Rhino的數據集中進行實驗,驗證了基于LDA的缺陷定位方法的有效性;(3)在兩個軟件項目Rhino和Eclipse中進行實驗,驗證了基于LDA的缺陷定位方法的可擴展性;(4)他們分析了基于LDA的缺陷定位方法的準確性與軟件系統規模之間的關系,發現該方法在軟件缺陷定位方面的準確性與軟件系統的規模并無顯著相關關系;(5)同時,他們也分析了基于 LDA的缺陷定位方法的準確性與軟件系統設計的穩定性之間的關系,結果顯示,二者并無顯著相關關系.
Zhou等人[11]提出了一種基于信息檢索的缺陷定位方法BugLocator.該方法分為4個步驟,即語料庫創建、缺陷報告和源代碼索引、查詢構建/缺陷報告檢索、源代碼文件排序.首先,他們在BugLocator方法中提出了修正的向量空間模型(rVSM),用以對缺陷報告和源代碼文件進行文本表示;然后,他們根據給定的缺陷報告與歷史缺陷報告的相似度、該缺陷報告與源代碼文件的相似度以及歷史缺陷報告改動的源代碼文件記錄這3個維度來對修復該缺陷報告可能需要修改的源代碼文件進行排序.他們在Eclipse、SWT、AspectJ、Zxing這4個項目的數據集上進行了實驗,實驗結果表明,BugLocator定位效果優于基于LDA、LSI的定位方法.
Moreno[12]提出了一種名為Lobster的靜態缺陷定位方法.該方法將缺陷報告中的堆棧信息引入到軟件缺陷靜態定位方法研究中來,利用堆棧分析和文本檢索相結合的方法進行缺陷定位.具體來說,Lobster方法使用缺陷報告中的堆棧信息來計算缺陷報告的代碼元素和軟件系統的源代碼之間的相似度.結合堆棧信息與源代碼的相似性和文本信息與源代碼之間的文本相似性來定位與缺陷報告相關的代碼片段.
Saha等人[13]提出一種僅需要源代碼和缺陷報告來進行缺陷定位的方法BLUiR.該方法使用TF-IDF模型,并結合結構信息檢索來度量缺陷報告和源代碼文件之間的相似性.首先,他們計算了缺陷報告的2個字段(即報告總結(summary)和內容描述(description))與源代碼文件中的 4個部分(即類名(class)、方法名(method)、變量名(variable names)和注釋(comments))兩兩之間的相似性;然后將得到的 8個相似分數組合,得到缺陷報告與源代碼文件之間的最終相似度,并依據此最終相似度,針對給定的缺陷報告對源代碼文件進行排名.他們在C程序軟件的缺陷定位中驗證了BLUiR缺陷定位方法的有效性[14].
Wang等人[15]認為,將源代碼的版本歷史、結構化信息、相似缺陷報告三者結合起來可以提高軟件缺陷定位的性能,并提出了一種新的缺陷定位方法 Amalgam.該方法集成了 Rahman[16]提出的缺陷預測算法來分析源代碼的版本歷史,然后使用BugLocator來分析缺陷報告系統中類似的缺陷報告,最后使用BLUiR對源代碼的結構化信息進行分析.他們在 4個開源項目(AspectJ、Eclipse、SWT和 ZXing)中進行的實驗結果表明,Amalgam的缺陷定位性能優于BugLocator和BLUiR.
Le等人[17]提出了一種多模式軟件缺陷定位方法,他們同時考慮了缺陷報告和程序光譜來進行軟件缺陷定位.該方法通過構建Bug-Specic模型,將特定的缺陷報告映射到其可能需要修改的源代碼文件.他們在4個項目AspectJ、Ant、Lucene、Rhino的157個實際缺陷中進行了實驗,驗證了他們提出的方法的有效性.
Wong等人[18]提出使用代碼分段和堆棧跟蹤分析來提高缺陷定位的性能.首先,他們將每個源代碼文件分成一系列的代碼片段,對于給定的一個缺陷報告,他們使用與該缺陷報告最相似的代碼片段來表示該源代碼文件;然后,他們分析缺陷報告中的堆棧信息與源代碼文件之間的相似性;最后,通過綜合兩種分析結果來定位到可能發生問題的源代碼文件.
Ye等人[19]定義了一個排名模型,使用Learning to Rank(LtR)方法度量缺陷報告和源文件之間關系的6個特征來進行缺陷定位.這6個特征包括:(1)缺陷報告和源代碼文件之間的相似性;(2)缺陷報告和源代碼API文檔之間的相似性;(3)以前修復過的類似缺陷報告;(4)缺陷修復新進度,即以月為單位的上次修復時間;(5)缺陷修復頻率,即文件被修復的頻率;(6)特征縮放.他們通過設定對應比例,綜合這6個方面的評分,從而得出單個源文件用于當前修復該缺陷報告的可能性.Ye等人[20]認為,以自然語言(例如英語)表達的搜索查詢與通常以代碼(例如編程語言)表示的檢索文檔之間的“詞匯鴻溝”使得信息檢索技術在軟件工程中的搜索任務變得困難.他們提出引入詞向量以解決“詞匯鴻溝”的問題,之后的實驗證明了使用詞向量能夠對之前的缺陷定位方法進行改進.缺陷定位方法的研究從最初的只考慮源代碼文件與缺陷報告之間的相似性,到后來的考慮缺陷報告的結構化信息,再加上源代碼文件的結構化信息、缺陷報告中的堆棧信息等,逐漸豐富了缺陷定位的信息源,使缺陷定位的準確率得到提升.這也在一定程度上減輕了軟件維護人員修復缺陷的復雜度,提高了缺陷修復的效率.
上述關于軟件缺陷定位的研究都在源代碼文件級別,而關于方法級別上的軟件缺陷研究目前較少.在軟件缺陷預測的研究中,Giger等人[21]認為,大多數缺陷預測方法是對文件級別的缺陷作出預測,這通常會使得開發人員花費大量的精力去檢查文件中的所有方法,直到找到發生錯誤的地方.為了減少開發人員手動檢查工作所需要的時間和精力,Giger等人[21]提出了一個方法級別的缺陷預測模型,之后,原子等人[22]和Hideak等人[23]也對方法級別的缺陷預測進行了研究.
和軟件缺陷預測類似,在軟件缺陷定位工作中,大多數軟件缺陷定位方法將研究粒度放在文件級別,整體存在著粒度比較粗糙的問題[24].如果將缺陷定位的粒度提高到方法級別,就可以進一步提高缺陷修復人員的工作效率,減少軟件的維護成本.就目前的文獻調研結果來看,僅有Youm等人[25]提出一種綜合分析(bug localization using integrated analysis,簡稱BLIA)方法來進行方法級別的軟件缺陷定位.BLIA利用缺陷報告文本、堆棧信息、源代碼注釋、源代碼文件結構信息和源代碼變更歷史信息進行軟件缺陷定位.值得一提的是,BLIA 1.0基于文件級別的缺陷定位,BLIA 1.5將文件級別的缺陷定位的粒度提高到了方法級別.在其方法級別的定位技術中,首先,他們利用BLIA完成對文件級別的排序;然后選取排名前10的文件,對此類文件中的方法體進行分析,得到源代碼方法體的排序,以此來實現方法級別的軟件缺陷定位.
2 細粒度軟件缺陷定位
2.1 問題描述
圖1展示的是 Maven項目 ID為#MNG-4367的缺陷報告(https://issues.apache.org/jira/si/jira.issueviews:issue-html/MNG-4367/MNG-4367.html).
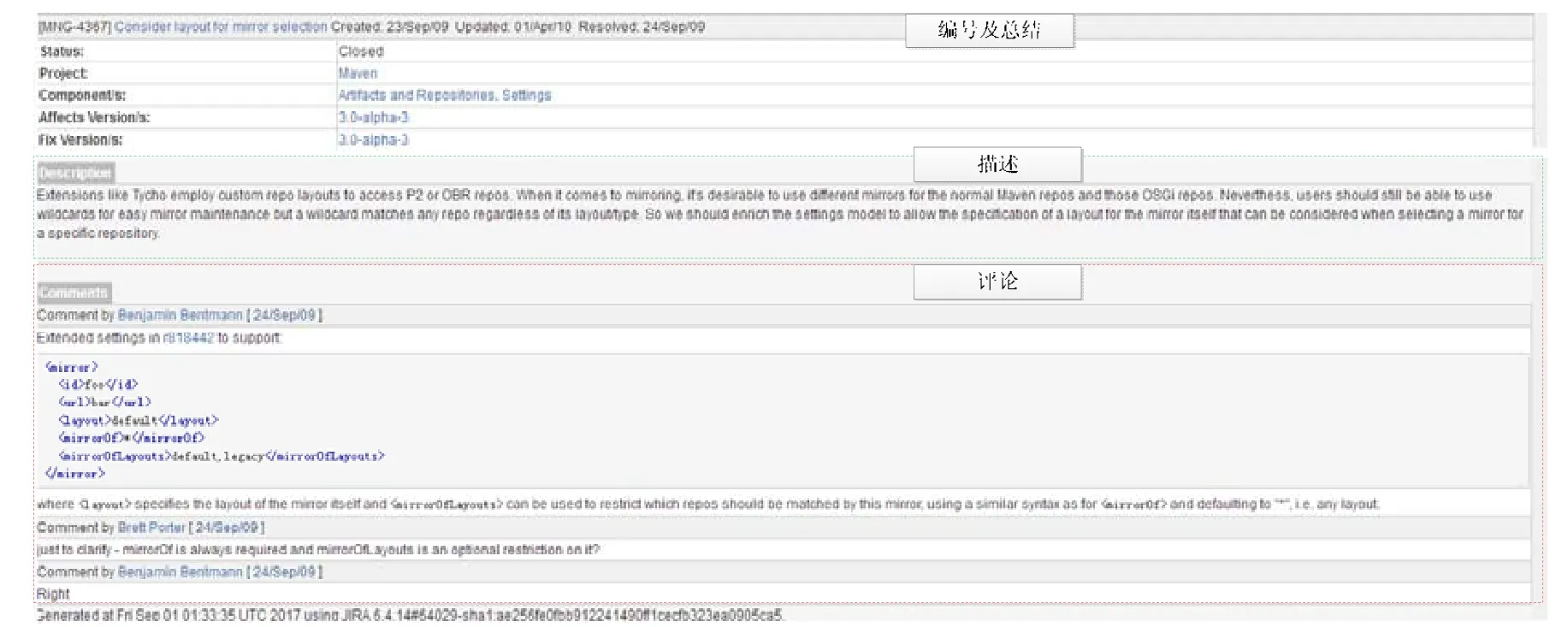
Fig.1 An example of a bug report for a Maven project圖1 一個Maven項目的缺陷報告示例
該缺陷報告頂端是缺陷的編號和缺陷的總結;接下來是缺陷提交者對該缺陷做的詳細描述(description),主要包括缺陷發生時的軟件運行上下文信息;對此缺陷感興趣的軟件項目開發人員可以在詳細描述下面進行評論(comment),系統會自動記錄評論人和評論時間.對缺陷報告進行評論是軟件開發者圍繞該缺陷主題進行交流溝通的主要方法.在遇到比較難以解決的軟件缺陷時,對該缺陷報告的評論可能多達幾十條.
假定對于一個軟件項目有n個缺陷報告BR=(br1,br2,…,brn),bri表示其中的一個缺陷報告.為了將bri所描述的缺陷進行修復,其所修改的文件為集合為表示該軟件項目的所有源代碼文件的集合,|f(bri)|表示集合f(bri)中元素的數量).事實上,當一名缺陷修復人員在修改文件時,他僅僅修改了文件中的1個或多個方法,表示文件中所有方法的集合).在傳統的方法中,軟件缺陷定位描述為如何利用缺陷報告bri從F中準確定位所需修改的文件集合f(bri).然而在本文中,這里所關注的問題是如何利用缺陷報告bri從F中準確定位所需修改的文件集合f(bri)及其對應的方法.
表1展示了Maven項目修復MNG-4367所涉及的具體文件及方法示例.缺陷報告MNG-4367如圖1所示.Maven項目包含的源代碼文件總數為898個.為了修復缺陷報告MNG-4367描述的缺陷,需要對2個源代碼文件即DefaultMirrorSelector.java和DefaultMirrorSelector.java中的6個方法做出修改,其中,DefaultMirrorSelector.java文件總共包含了5種方法,實際需要修改其中的3種方法;MirrorProcessorTest.java文件總共包含了14個方法,實際需要修改其中的3種方法.具體需要修改的方法見表1.由此,本文將方法級別的軟件缺陷定位問題描述為:利用根據缺陷報告 MNG-4367的描述內容,從 Maven項目 898個源代碼文件中找到要修改的 2個文件(DefaultMirrorSelector.java,MirrorProcessorTest.java),并進一步找出在這2個文件中需要修改的6種方法.

Table 1 Source code files and methods for fixing MNG-4367 as well as ranking of the changed methods by MethodLocator表1 修復MNG-4367所涉及具體文件和方法以及MethodLocator對所需修改方法的排序
2.2 MethodLocator細粒度軟件缺陷定位方法
本文提出了 MethodLoactor方法,以缺陷報告bri(包括缺陷報告中的總結內容 summary、描述內容discription和評論內容comment)作為查詢,以M={m1,…,mk}(M表示所有源文件中方法的集合,mj表示其中的一個方法)作為查詢對象.使用基于詞向量word2vec的表示方法[9]對缺陷報告和源代碼方法體內容進行向量表示,并利用夾角余弦計算缺陷報告和源代碼方法之間的相似度,進而對查詢結果進行排序.
表1中給出了MethodLocator方法對于Maven項目缺陷編號為MNG-4367的缺陷的定位效果,可以看到,6種被修改的方法分別出現在結果排序的第3位、第6位、第9位、第4位、第1位、第10位.
圖2展示了本文提出的錯誤定位方法MethodLocator的總體架構.如圖2中步驟③~步驟⑤所示,當新的缺陷報告被提交時,MethodLocator將其視為查詢并計算源代碼庫中的各方法與該缺陷報告的余弦相似度;從源代碼方法的查詢中返回定位到的相關方法的排名;最后,MethodLocator按相似度降序排列所返回的方法,以定位可能導致該缺陷的方法.
考慮到方法級別的方法體(包括方法名稱和方法體內容)的內容相對于缺陷報告來說較少,長度也較短,在查詢匹配時往往帶來了大量的稀疏性.在對近幾年關于短文本擴充和查詢擴充相關主題研究成果[26-29]進行調研的基礎上,本文提出了一種方法體短文本擴充方法.它根據方法體之間的相似性,利用其他方法體對當前方法體短文本進行擴充.MethodLocator大致可以分為方法體擴充和相似度計算兩個階段,其具體細節見第2.3節和第2.4節.

Fig.2 Overall structure of MethodLocator圖2 MethodLocator的總體結構圖
2.3 方法體向量表示及方法體擴充
圖3詳細解釋了圖2中的方法體提取①和方法體擴充②部分.如圖3中第I部分所示,需要對方法內容進行預處理.首先,從源代碼文件中提取方法體,這里,通過抽象語法樹(abstract syntax tree,簡稱AST)來實現對源代碼文件的解析,對于從源代碼.Java文件中提取出的一個方法體,記為mi(1≤i≤n,n為源代碼中方法體的總數);然后,對每個方法體進行文本預處理,包括依據 Java編程駝峰命名規則從方法名中分離出英文單詞(Saha等人[13]的研究表明,將方法名進行分離,對于基于信息檢索的缺陷定位方法來說,可以提高缺陷定位的準確率)、去掉停用詞、去掉Java保留關鍵詞、去掉各種符號,得到預處理后的方法;最后,對進行向量表示,并將對方法mi預處理后的向量表示為.

Fig.3 Method body pretreatment圖3 方法體預處理
2.3.1 方法體向量表示
TF-IDF[30]是一種統計方法,用以評估一個字詞對一個文件集或一個語料庫中的其中一份文件的重要程度.字詞的重要性隨著它在文件中出現的次數呈正比增加,但同時會隨著它在語料庫中出現的頻率呈反比下降.雖然TF-IDF能夠體現出各個詞在文檔中的重要程度,但是使用TF-IDF對文檔進行向量表示沒有考慮文檔中詞之間的順序問題,句子中詞之間沒有聯系,會丟失很重要的信息.結合本文實際問題,源代碼中方法體內容較少,包含詞的數量比較少,以Maven項目中方法體boolean equals(Object obj)為例,經過預處理后,該方法體只包含7個詞.使用TF-IDF表示后,得到類似于這樣形式的向量表示(a1,a2,…,a7,0,...,0,0,0,0,0,0),其中包含了5 494個0項(詞典中詞根總數為5 501),所以只使用TF-IDF對方法體進行向量表示,還會使得向量表示具有很大的稀疏性.
將詞映射到一個新的空間中,并以多維的連續實數向量進行表示,叫做“Word Represention”或“Word Embedding”,其最大的貢獻就是使相關或者相似的詞在距離上更接近了.本文使用 Word2Vec(word2vec:https://deeplearning4j.org/word2vec)模型中的Skip-gram模型進行訓練,得到詞所對應的向量表示.Skip-gram模型[31]根據當前詞語來預測上下文的概率,如圖4所示.采用基于Word2Vec的方法體向量表示方法一方面可以降低向量表示的緯度,減少向量表示的稀疏性;另一方面挖掘了詞之間的關聯屬性,從而提高了向量語義上的準確度.Ye等人也在文獻[20]中使用詞向量來解決自然語言表述的缺陷報告和代碼表示的源代碼文件之間的“詞匯鴻溝”問題,提高了軟件缺陷定位的準確率.
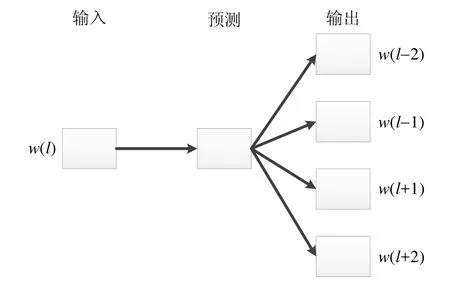
Fig.4 Skip-gram model圖4 Skip-gram模型
唐明等人在文獻[9]中提出了一種基于 word2vec的文檔向量表示方法.該方法結合了詞向量和 TF-IDF方法,并利用實驗驗證了該方法的有效性.本文中研究的方法體具有如下特點:包含內容少、文本長度較短.采用基于詞向量的表示方法可以挖掘出詞之間的關聯屬性,從而提高了向量語義上的準確度.使用TF-IDF可以考慮單個詞對整個方法體的影響力.為了能夠挖掘出方法體中更多的信息,方便之后的方法體擴充,本文采用了文獻[9]中的文檔向量表示方法,即結合詞向量和TD-IDF對方法體進行向量表示.
· 首先,將所有的缺陷報告bri和方法mi′通過 Skip-gram 模型[28]訓練,得到mi′中每個詞項對應的N維詞向量w,即w=(v1,v2,…,vN),其中,vN表示在第N個維度的值.本文在使用 Skip-gram模型[31]進行訓練時,結合一般經驗[32],將維度N的值設置為300.由于方法體中包含的單詞個數比較少,所以將Skip-gram模型的最低頻率設置為1,將窗口數設為默認值5.
· 然后,MethodLocator選用的基于詞向量的表示方法[9]結合了詞向量和經典的TF-IDF方法[30],其一方面利用 Skip-gram 模型[30]計算每個詞項的詞向量;另一方面,也同時計算每個詞項的tfidf值,也就是分析每個詞項的詞匯頻率tf和逆文本頻率idf,然后計算其tfidf值.{t1,t2,…,tm}表示從方法體中提取出的詞項,m表示詞干總數,則對于單個詞項ti,其tfidf計算方式如公式(1)所示.

公式(1)中,tf(ti),idf(ti)的計算方式如公式(2)所示.
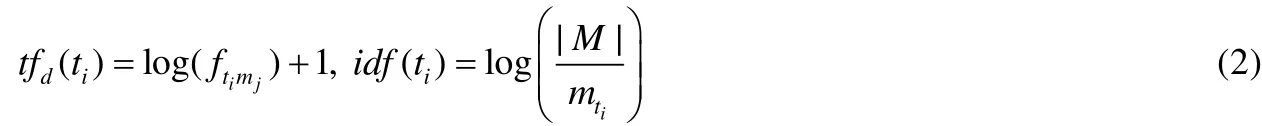

2.3.2 方法體擴充
圖3第II部分展示了方法之間的相似度計算過程.首先,以第k(1≤k≤|M|)種方法作為查詢,將其他方法視為查詢對象;然后,通過計算余弦相似度來對進行排序,由此得到一個大小為|M|-1的序列;最后,通過對所有|M|種方法中的每一種方法的相似方法進行排序,從而得到|M|個大小為|M|-1的序列.
圖3第 III部分展示了方法體的擴充過程.這里以第k(1≤k≤|M|)種方法為例,假設其與其他|M|-1種方法之間的夾角余弦相似度為.其中,方法與方法的夾角余弦相似度如公式(4)所示.



圖5顯示了擴充的偽代碼.

Fig.5 Method body expansion algorithm圖5 方法體擴充算法
2.4 缺陷報告與方法體相似度計算及排序
在第2.3節中,Skip-gram模型[31]的輸入為所有缺陷報告bri和所有方法.同理,對缺陷報告的內容也利用詞向量進行表示.具體而言,對于第k個缺陷報告brk,其包含的詞項為.首先,利用詞向量將缺陷報告brk中的每個詞項wk,i表示為;然后,將brk中所有的詞項量進行聚集,并利用最大池化 MaxPooling方法[33]在每個特征維度上選取最大值作為brk的表示向量在該維度上的最大值,即中的第i個維度的值為.需要說明的是,結合前人的經驗及人工觀察,本文選取了缺陷報告中的總結、描述和評論這3個部分的內容.經過上述處理后,如圖2中步驟③~步驟⑤所示,MethodLocator以所有經過處理的方法ami作為查詢對象,以缺陷報告作為查詢.通過計算二者的余弦相似度,選取相似度較大的方法視作為修復缺陷而可能修改的方法.
3 實 驗
3.1 標桿數據集建立
為了驗證MethodLocator方法在實際軟件缺陷定位中的有效性,本文選取了4個開源軟件項目:ArgoUML、Ant、Maven、Kylin,并收集它們的缺陷報告和源代碼變更信息,以開展本文的實驗.實驗數據集的收集步驟具體如下所述.
(1)獲取源代碼文件.
這一步的目的是從開源項目代碼庫中獲取實驗所需的源代碼文件,對于ArgoUML項目和Ant項目,本文利用SVN工具來獲取源代碼數據;對于Maven項目和Kylin項目,本文利用Git工具來獲取源代碼數據.
(2)建立由缺陷修復引起的文件變更數據集.
首先,利用SVN或者Git工具將步驟(1)中所收集的源代碼文件中所有的.java文件的log日志收集下來,并就每一個.java文件,在其log日志中將bug_number(缺陷編號,與缺陷報告編號相同)利用SZZ算法[34]抽取出來.然后,從 log日志中獲取該 bug_number對應的.java文件的當時版本號.隨后,從 log日志中找出該 bug_number當時版本的前面所有版本(按修改時間由近到遠排序).接著,利用 diff命令比較前面版本與當時版本,選擇一個最近的有改動的前面版本作為基礎版本.比較當時版本與基礎版本的diff(不同的地方),作為修復該bug_number的bug所導致的代碼變化.然后,利用AST抽象語法樹對每個基礎版本源代碼文件和當時版本源代碼文件進行解析,提取出所有的method,并查找diff結果代碼行所屬于的method.最后,將bug_number、修改的Java文件、修改的代碼行以及修改的method集中起來,建立一個數據集.
(3)缺陷報告獲取.
本文分別從這 4個軟件項目的缺陷跟蹤系統中獲取到對應的缺陷報告.結合前人的經驗及人工觀察[2],本文選取了缺陷報告的總結(summary)、描述(description)和評論(comment)這3個字段的內容作為缺陷報告的自然語言描述內容.為了保證實驗的可重復性和可驗證性,本實驗從全部缺陷報告中選出缺陷變更記錄可追蹤性良好的部分缺陷報告作為實驗數據,即通過缺陷編號(bug_number),能夠準確地對應缺陷報告以及步驟(2)中的源代碼修改記錄.表2展示了本文收集到的4個開源項目的各類數據的信息.

Table 2 Information on experimental data表2 實驗數據信息
這里需要說明的是,在步驟(2)中,為了探明對某一個缺陷號 bug_number所做出的在源代碼中的具體修改,本文將源代碼文件的當時版本和之前的所有源代碼版本進行了 diff比較操作.這樣做的原因是,在某些源代碼的提交過程中,僅僅是對源代碼的注釋或者在版本控制系統的批注信息做了添加和變更操作,而未對源代碼本身做出實質的變更.因此,當在源代碼文件中得到一個缺陷號之后,我們需要追蹤離當時版本最近的一次的軟件源代碼變更,并將該變更視作為修復該缺陷所做出的變更.
3.2 Word2vec訓練
本文利用 deeplearning4j(deeplearning4j:https://deeplearning4j.org/word2vec)中的 Word2Vec完成各項目中的詞的訓練及詞向量的獲得.訓練基本情況見表3.
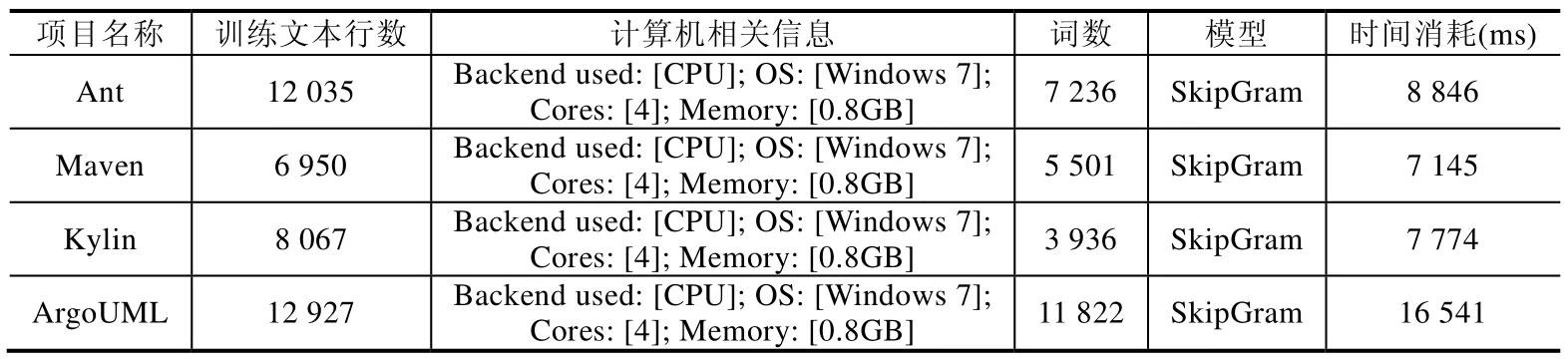
Table 3 Basic information of Word2Vec training表3 Word2Vec訓練的基本信息
3.3 基準方法
為了論證 MethodLocator方法在缺陷定位方面的實際性能,本文選取了兩種基準方法進行對比實驗,包括BugLocator[11]和BLIA 1.5[25].Zhou等人提出的Buglocator[10]是最近提出的靜態缺陷定位方法中比較典型和廣為接受的文件級別的定位方法.由于本文的關注點在于方法級別的軟件缺陷定位,因此,我們將BugLocator方法的定位粒度由原始的文件級別調整到方法級別,而其基本的計算過程得以完全重復,即由以前的使用源代碼文件建立索引變更為使用方法體建立索引;由考察相似缺陷報告修改的源代碼文件情況變更為考察相似缺陷報告修改的方法體情況.在方法級別的基于信息檢索的靜態缺陷定位方面,目前僅有Youm[25]提出的BLIA 1.5方法可用于實際比較.因此,本文同時也選擇了Youm的BLIA 1.5作為基準方法,用于論證MethodLocator的有效性.BLIA 1.5定位方法針對特定的缺陷報告,首先對可能作出變更的源代碼文件進行排序,然后選取排序靠前的文件對它們中的方法做進一步的排序,從而實現方法級別的定位.也就是說,BLIA 1.5定位方法過濾掉了排名較后的文件中的方法.BLIA 1.5方法中有4個參數可以對定位效果進行控制.經過反復實驗,本文確定了對應的各實驗數據的參數設置,具體設置如下:Ant(α=0.3,β=0.2,γ=0.4,k=120),Maven(α=0.2,β=0.2,γ=0.3,k=120),Kylin(α=0.0,β=0.2,γ=0.5,k=120),ArgoUML(α=0.3,β=0.0,γ=0.5,k=120).
3.4 評價指標
為了論證本文提出的缺陷定位方法的有效性及意義,本文選擇前N排名(topNrank)、平均準確率(mean average precision,簡稱MAP)和平均倒數排名(mean reciprocal rank,簡稱MRR)這3個指標進行實驗結果比較.對于某個項目的第i個缺陷報告bri,為修復該缺陷,實際修改的方法體的集合為.在對本文提出的方法進行評價時,需利用實際修改的方法體集合中所有方法體在本文推薦結果列表中出現的位置進行相應的計算,以此來評價本文提出的方法的優劣.
1)前N排名(topNrank)
它表示缺陷報告對應做出變更的方法體出現在返回結果的前N(N=1,5,10)位中的數量的比率.使用該度量方法,對于給定的缺陷報告,如果前N個查詢結果包含至少1個修復缺陷的方法體,就認為缺陷被準確定位.TopNRank度量值越大,說明缺陷定位方法的定位性能就越好.
2)平均準確率值(mean average precision,簡稱MAP)
它表示對所有缺陷報告進行源代碼定位后的準確率的平均值.MAP值反映了缺陷定位方法在全部缺陷上準確定位所有需要修改的源代碼的單值指標.缺陷定位方法檢索出來的需要修改的源代碼方法體越靠前(rank越高),MAP就越大;反之,如果缺陷定位方法沒有檢索出需要修改的源代碼方法體,則準確率默認為0.其中,單個缺陷的平均精度(表示為AvgP)如公式(7)所示.

其中,R表示一次缺陷定位中所能正確定位的源代碼方法體排序的集合,|R|表示正確定位的源代碼方法體個數,rankk表示第k個正確的源代碼方法體的排名.針對所有的缺陷報告的MAP如公式(8)所示.

其中,Q為缺陷報告的集合,|Q|表示Q中缺陷報告的數目,AvgPj表示第j個缺陷報告的平均精度值.
3)平均倒數排名(mean reciprocal rank,簡稱MRR)
表示相關源代碼方法體的位置倒數的平均值,MRR越高,說明算法的準確率越高.MRR計算公式如下.

其中,Q為缺陷報告的集合,|Q|表示Q中缺陷報告的數目,ranki表示定位出的與第i個缺陷報告相關的方法體最靠前排名的位置.
4 實驗結果及分析
為了全面評價 MethodLocator在方法級別的軟件缺陷定位上的性能,本文設置了以下 3個研究問題,對MethodLocator的參數設置以及基準方法進行了全面的分析.
· 研究問題1:在MethodLocator中,方法體擴充速率α的變化對軟件缺陷定位的性能有何影響?
· 研究問題2:當把文件級別的缺陷定位方法(BugLocator)運用于方法級別缺陷定位時,其性能與本文所提出的MethodLocator相比,孰優孰劣?
· 研究問題3:本文提出的MethodLocator與現有的方法級別的缺陷定位方法BLIA 1.5相比,孰優孰劣?
4.1 對研究問題1的分析
MethodLocator中,方法體擴充系數α變化對定位效果的影響如圖6~圖8所示,其中,圖6顯示了α變化對MAP的影響,圖7顯示了α變化對MRR的影響,圖8顯示了α變化對ToP-N的影響.本文實驗設置α從0到1變化,每次增加0.05.當α=0時,顯示的就是對方法體不進行擴充的定位效果.
從圖6~圖8展示的效果可以看出:
· 首先,在選定的4個項目中,當α=0.05時取得最優效果;當α>0.05時,定位效果逐漸變差,MAP、MRR和ToP-N值逐漸降低.當α的值增大到一定程度之后,Top-N指標、MAP指標和MRR指標的性能都會降低到α=0對應性能水平的下方.也就是說,當α的取值較大時,擴充的效果明顯不如不擴充的效果.對于這個結果的解釋是,當α較小時,其他方法對當前方法的擴充表示向量amk形成了有益補充;當α較大時,其他方法給當前方法的擴充表示向量amk帶來了大量噪聲.這也說明,在對方法體進行擴充時,在增強原方法體信息表示的同時也會引入一些噪聲干擾.α在一定的取值范圍內,增強效果大于干擾效果,這樣就使定位效果得到提升;當α取值離開該范圍時,干擾效果大于增強效果,這樣就會使定位效果變差.在 MethodLocator中,方法體擴充時如何減少干擾信息是一個難點.方法體擴充不可避免地會引入進干擾信息,α值的作用就是盡量控制干擾信息的影響.α值與定位效果的好壞息息相關.對于不同的方法體,其α值可能也會不同.本文在進行實驗時,將α值作為定值,以 0.05為步長進行實驗.關于如何更為精確和自動化地設定α的取值,本文會在未來的工作中進一步研究.
· 其次,就4個項目來說,在所有的度量指標Top-N、MAP和MRR上,MethodLocator在Ant項目上的表現最好,而在其余3個項目ArgoUML、Maven和Kylin上的表現不相上下.經過對實驗數據的分析,我們發現,修復一個缺陷,在 Ant項目中平均要修改 4個方法體;在 Kylin項目中平均要修改 8個方法體;Maven項目中平均要修改5.4個方法體;Argouml項目中平均要修改6.2個方法體.就修復一個缺陷所要修改方法體的數量方面,明顯 Ant項目需要修改的數量最少,這在一定程度上降低了缺陷定位的難度,使得MethodLocator在Ant項目上具有較好的表現.
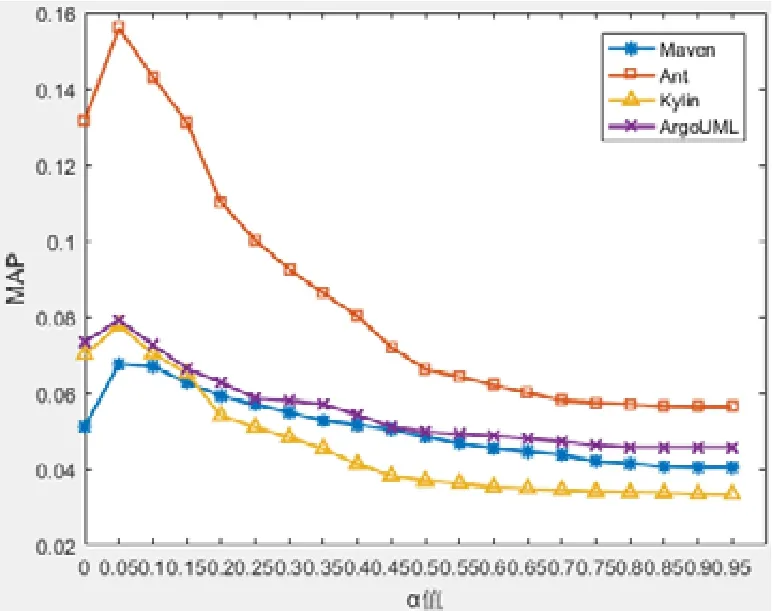
Fig.6 Effect of expansion coefficientαon MAP value in MethodLocator圖6 MethodLocator中,擴充系數α對MAP值的影響

Fig.7 Effect of expansion coefficientαon MRR value in MethodLocator圖7 MethodLocator中,擴充系數α對MRR值的影響
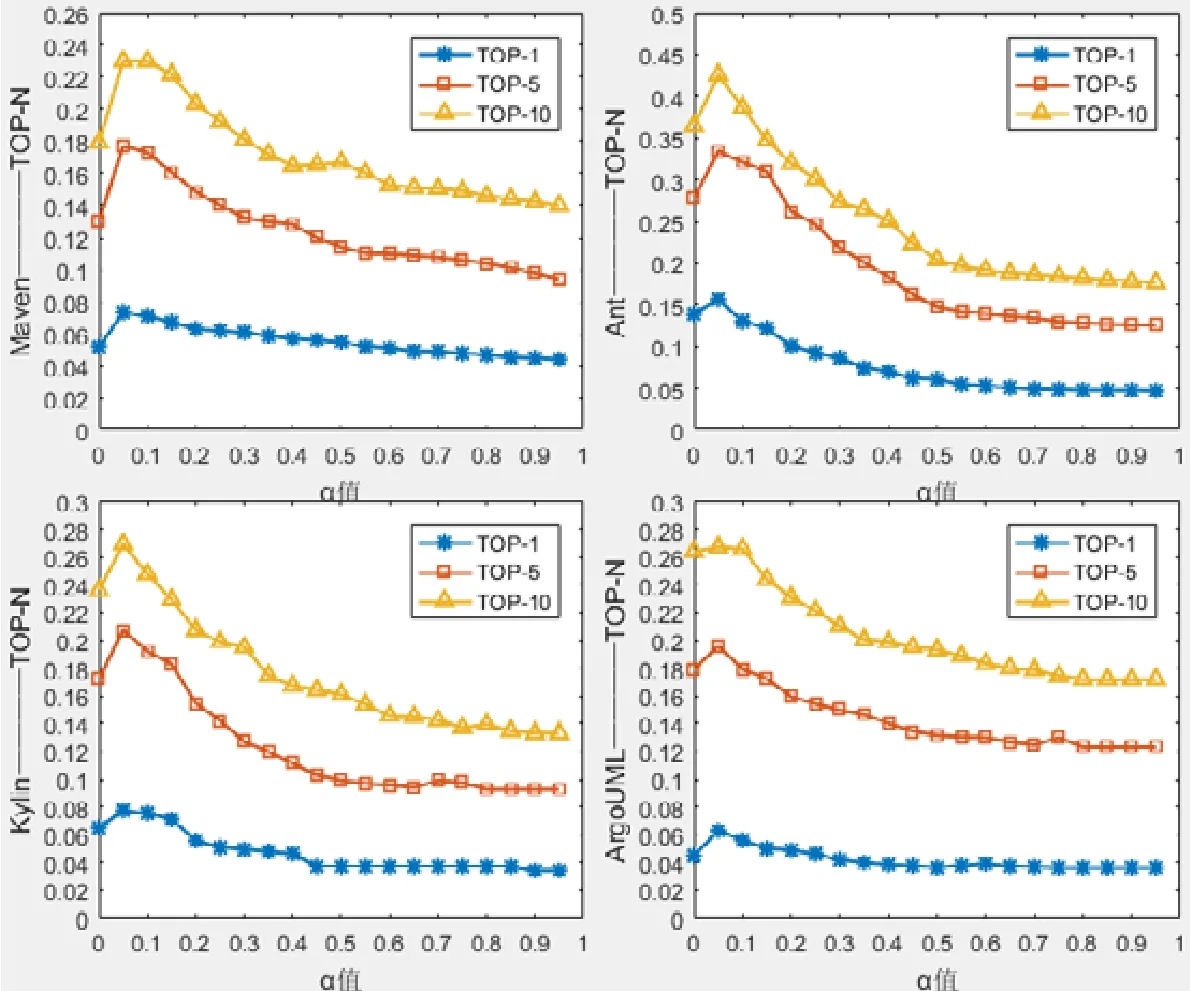
Fig.8 Effect of expansion coefficientαon ToP-Nvalue in MethodLocator圖8 MethodLocator中,擴充系數α對ToP-N值的影響
4.2 對研究問題2的分析
本文將傳統的文件級別的缺陷定位方法 BugLocator應用到方法級別進行實驗,以考察文件級別定位方法被運用到方法級別定位時的表現.當α=0.05時,與本文提出的方法 MethodLocator相比,二者的不同之處主要在于,BugLocator對方法體進行向量表示時直接采用 tfidf的向量表示方法,且沒有對方法體進行擴充;MethodLocator在對方法體進行向量表示時,采用將word2vec和tfidf相結合的方法,并且對方法體進行擴充.表4顯示了MethodLocator和BugLocator在本文選擇的4個項目上的實驗結果.
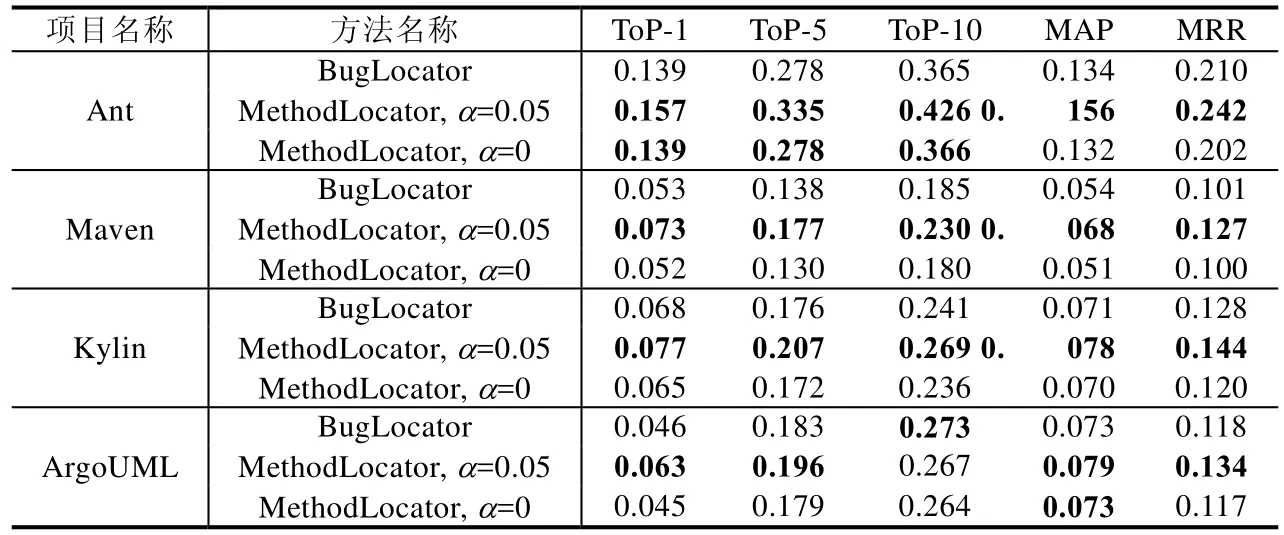
Table 4 MethodLocator and BugLocator comparison of experimental results表4 MethodLocator和BugLocator實驗結果對比
從表中可以看到,MethodLocator具有比BugLocator更好的效果.具體來說,在MAP指標上,MethodLocator較之BugLocator在4個項目上分別提高了16.4%、25.9%、9.9%、8.2%;在MRR指標上,MethodLocator較之BugLocator在 4個項目上分別提高了 15.2%、25.7%、12.5%、13.6%;在 TOP-N指標上,以 ToP-1為例,MethodLocator較之BugLocator在4個項目上分別提高了12.9%、37.7%、13.2%、37.0%.方法體相對于源代碼文件來說,文本內容及可包含信息明顯較少,對于傳統文件級方法運用到方法級別定位時,直接對方法體進行向量表示并進行定位,就會因為方法體信息表示不足而取得較差的結果.
當α=0時,表4中展示的即為不對方法體進行擴充時的缺陷定位效果.可以發現,在20個指標中,有3個是與BugLocator相同的,只有在1個指標上比BugLocator表現好.所以,只使用新的向量表示方法而不對方法體進行擴充,MethodLocator缺陷定位效果并沒有優于基準方法,進一步顯示出方法體擴充的重要性.關于采用新的向量表示方法與方法體擴充對準確率的影響更為詳細的測算問題,則需要設置更為精確的對比實驗來探討.
4.3 對研究問題3的分析
BLIA 1.5方法是一種綜合了多方面信息源進行方法級缺陷定位的方法.從文獻[25]中各信息源的影響分析中可以看到,如果一個缺陷報告包含有缺陷的堆棧信息,那么在缺陷定位中,堆棧信息的分析將起到主要作用,其次才是源代碼與缺陷報告之間的相似性;如果一個缺陷報告中不包含堆棧信息,在缺陷定位時,源代碼與缺陷報告之間的相似性則起主要作用.與本文所提出的MethodLocator相比,BLIA 1.5考慮的信息源較多.但是由于多源信息之間往往會存在相互沖突和噪聲情況,因此,BLIA 1.5在方法級別缺陷定位上的性能需要進一步驗證.
從表5可以看出,MethodLocator方法相對于BLIA 1.5方法在方法級別的軟件缺陷定位方面達到了較好的效果.具體來說,在MAP指標上,MethodLocator較之BLIA 1.5在4個項目上分別提高了16.4%、23.6%、6.9%、3.9%;在MRR指標上,MethodLocator較之BLIA 1.5在4個項目上分別提高了14.7%、24.5%、10.8%、11.7%;在TOP-N指標上,以ToP-1為例,MethodLocator較之BLIA 1.5在4個項目上分別提高了12.1%、32.7%、8.5%、28.6%.盡管BLIA 1.5方法單獨考慮了缺陷報告中的堆棧信息,將其與總結、描述和評論文本中的自然語言文本分開處理,但是首先,在本文所考察的項目中,所有缺陷報告中包含堆棧信息的缺陷報告所占比例并不大,普遍為 5%~10%之間,這些堆棧信息顯然并不能在缺陷定位的結果中起到決定性的作用;其次,即使缺陷報告中含有堆棧信息,然而,由于堆棧信息所包含信息往往從最表面調用的函數代碼追蹤到最深層出現問題的源代碼,整個堆棧軌跡的路徑較長,從而導致對可能發生缺陷的源代碼的誤判.例如,在本文考察的 ArgoUML項目缺陷報告4 173中,它包含的堆棧信息由表及里的追蹤到了11個類的14個函數.也就是說,11個類和14個函數以及它們依賴的類和函數都可能是造成該缺陷的原因.進一步來說,通過本文調研發現,堆棧信息一般在文件級別的粗粒度缺陷定位中有較好的效果[14,16].但是對于方法級別的細粒度定位,由于堆棧信息在引起缺陷的方法的指向性信息上弱化,因此并未見利用其改善缺陷預測或者定位的研究成果.由于以上諸多原因,在本文的實驗中,堆棧信息并不能顯著提高方法級別的缺陷定位的效果.
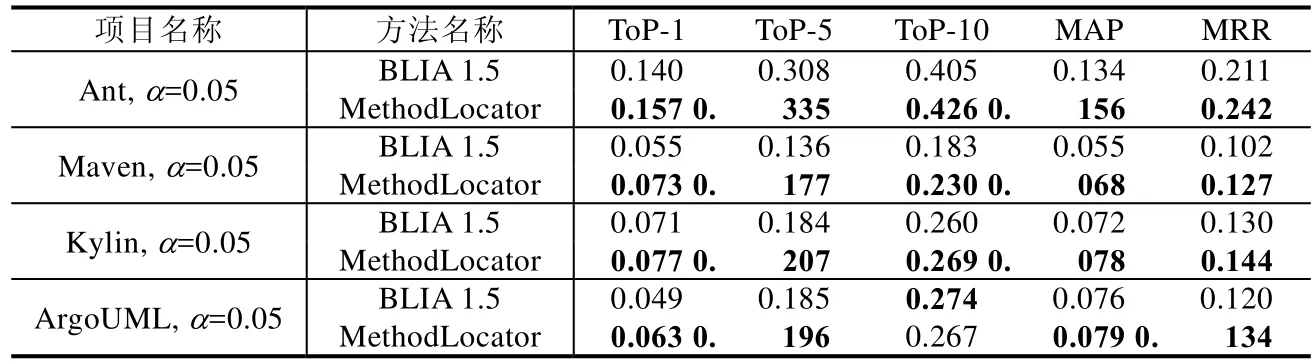
Table 5 MethodLocator and BLIA 1.5 comparison of experimental results表5 MethodLocator和BLIA 1.5實驗結果對比
5 結 論
對于任何軟件項目,軟件缺陷的出現都是不可避免的.為了提高軟件質量和用戶滿意度,必須快速而及時、準確而有效地修復軟件在實際使用中的缺陷.面對一個缺陷報告,軟件開發人員需要找到缺陷發生的位置并修復該缺陷,這是一項費時、費力的任務.為了幫助軟件開發人員能快速找到缺陷發生的位置,本文提出了一種基于信息檢索的方法級別的缺陷定位方法 MethodLocaor.不同于傳統的文件級別的定位方法,該方法旨在縮小缺陷定位的粒度而盡量減少缺陷修復人員的修復工作量.通過詞向量方法和TF-IDF方法,MethodLocaor實現了源代碼方法的初步向量表示.通過方法體擴充方法,MethodLocaor解決了源代碼方法在文本表示上的稀疏性.在 4個實際項目中的實驗表明,MethodLocaor的定位效果受到方法體擴充系數α的影響,在本文實驗的數據集上,α在0.05處定位效果最優;與傳統文件級定位方法BugLocator應用到方法級別的效果相比,MethodLocaor具有更好的定位性能;與方法級定位方法BLIA 1.5方法相比,MethodLocaor有更好的表現.
在未來的工作中,我們將綜合考慮缺陷報告和源代碼方法的豐富信息來進一步提高MethodLacator在方法級別上的缺陷定位效果.具體來說,在缺陷報告向量表示方面,我們將考慮缺陷報告提交人員的級別、缺陷報告提交時間、超文本鏈接信息、堆棧信息和代碼信息等;在源代碼方法方面,我們將考慮方法的圈復雜度、方法之間的依賴關系、開發人員版本信息等.目的是研究有關缺陷報告和源代碼方法的全方位信息,并利用其來進行軟件方法級別的缺陷定位,以期得到效果更好的缺陷定位方法.
猜你喜歡
南方人物周刊(2017年32期)2017-10-28 22:48:36
中華手工(2017年2期)2017-06-06 23:00:31
南風窗(2016年26期)2016-12-24 21:48:09
Coco薇(2016年2期)2016-03-22 02:42:52
南風窗(2015年22期)2015-09-10 07:22:44
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
南風窗(2015年7期)2015-04-03 01:21:48
中外會展(2014年4期)2014-11-27 07:46:46
祝您健康(1987年3期)1987-12-30 09:52:32
