一個支持錯誤定位的批處理數據擁有性證明方案?
2019-03-05 03:45:38龐曉瓊王田琪陳文俊任孟琦
軟件學報 2019年2期
龐曉瓊,王田琪,陳文俊,2,任孟琦
1(中北大學 大數據學院,山西 太原 030051)
2(中國人民銀行 太原中心支行,山西 太原 030001)
1 引 言
數據擁有性證明(PDP)方案使得數據擁有者(或校驗者)在沒有本地備份的情況下,不需要下載數據,就能以很高的概率遠程校驗用戶存儲在服務器上的數據是否完整.目前,大多數數據擁有性證明方案是針對單用戶存放在單服務器上的數據進行完整性校驗[1-11],但是現實的情境中,云存儲提供的服務是面向很多用戶的,同時,云服務提供商并不是單一的,每個云服務提供商所擁有的也不僅僅是單個服務器.為了更適應現實,近幾年,多用戶單服務器[12,13]、單用戶多服務器[14,15]、多用戶多服務器[16-19]情景下的批處理 PDP方案陸續被提出來.在這些批處理方案中,服務器在計算證明階段將被挑戰數據塊的證明按用戶或服務器進行聚合計算后,再將聚合證明發送給TPA(third party auditor)校驗,極大地降低了通信開銷,且有效地減少了TPA校驗的計算開銷.但是只有當所有用戶的數據都是正確存儲時,這樣的批量處理才能體現出其效率優勢,一旦有數據被損毀,批處理校驗將不通過,此時定位錯誤數據所在服務器和所屬用戶就成為一個亟需解決的問題.最直接的定位錯誤方法就是對被挑戰服務器返回的證明逐一校驗,但是這種方法的效率顯然不高,并且由于服務器通常返回的是聚合證明,故而目前多用戶多服務器環境下的批處理PDP方案中,即使采用逐一校驗法,TPA也只能定位錯誤數據所屬用戶或所在服務器,無法進行同時定位.因此需要一種有效的方法,在多用戶多服務器環境下實現批處理遠程數據完整性校驗的同時,還能在校驗不通過情況下高效地對錯誤數據定位,即找到錯誤數據屬于哪個用戶,且存放在哪個服務器上.
1.1 相關工作
2007年,Ateniese等人[1]首次提出了PDP的定義,并給出了一個支持公開校驗的PDP方案.2008年,Ateniese等人[2]提出了一個支持動態數據更新的 PDP方案,但是該方案只支持對文件塊的修改、刪除和附加操作,并不支持插入,且只能進行有限次校驗.2009年,Wang等人[3]利用Merkle哈希樹提出了一個全面支持數據動態更新的方案,同時引入了 TPA代替用戶驗證數據的完整性,但該方案沒有考慮用戶數據隱私會泄露給 TPA的問題.2010年,Wang等人[4]提出一個保護隱私的PDP方案,解決用戶隱私泄露給TPA的問題,但該方案不支持數據動態更新.2011年,Hao等人[5]提出了“針對第三方校驗者的隱私性”的安全性定義,并構造了一個在此安全性定義下可證明安全的PDP方案.2015年~2016年,Yu等人[6-9]重點研究了提高PDP方案安全性的問題.2016年~2017年,Yu等人[10,11]提出兩種基于身份的PDP方案,消除了PKI龐大的證書管理開銷.以上工作都是針對單用戶單服務器環境下的PDP方案.
在多用戶單服務器環境下,2013年,Wang等人[12]利用BLS短簽名構造同態驗證標簽,提出了一個保護隱私的批處理PDP方案.2014年,Ren等人[13]使用橢圓曲線上的Co-GDH簽名構造同態驗證標簽,提出一個支持數據動態更新的批處理PDP方案.在文獻[12,13]中,服務器將被挑戰塊的證明按用戶聚合之后發送給TPA,TPA對所有證明聚合計算后進行批量校驗.不同的是,文獻[12]在批校驗不通過時,TPA會利用二分查找判斷哪個用戶的數據出錯;而文獻[13]并未考慮定位錯誤數據所屬用戶的問題.
在單用戶多服務器環境下,2015年,Wang[14]提出了一個基于身份的分布式批處理PDP方案.2016年,Mao等人[15]利用BLS短簽名提出了一個批處理PDP方案.這兩個方案中,被挑戰服務器將其上所有被挑戰數據塊的證明聚合計算后發送給 organizer,organizer將所有被挑戰服務器發來的聚合證明再次聚合成一個值,并發送給TPA進行校驗.文獻[14,15]這種交由 organizer統一聚合證明的方式極大地減輕了 TPA的計算開銷,但也使得TPA無法定位錯誤數據所在服務器.
在多用戶多服務器環境下,2014年,Liu等人[16]利用雙線性對提出一個批處理 PDP方案,并且使用有序的Merkle Hash Tree來抵抗置換攻擊.該方案中,被挑戰服務器將其上所有被挑戰塊的證明聚合后發給 organizer,organizer將所有被挑戰服務器返回的聚合證明再次聚合并發送給TPA審計,這種交由organizer聚合,再由TPA審計的方式在一次挑戰響應中無法實現錯誤數據定位.2016年,Zhou等人[17]基于CDH假設,利用雙線性對提出了一種基于身份的批處理 PDP方案.該方案中,被挑戰服務器將其上所有被挑戰塊的證明聚合后發送給 TPA,TPA將所有被挑戰服務器返回的證明再次聚合后進行批量校驗.雖然文獻[17]并未考慮錯誤數據定位問題,但是在批量審計不通過的情況下,TPA可以采用最直接的逐一校驗方式定位錯誤數據所在服務器,但無法定位錯誤數據所屬用戶.
在多用戶多服務器環境下的批處理PDP方案中,也曾有學者提出錯誤數據定位的想法.2013年,He等人[18]提出了一個僅能定位出錯數據所屬用戶的批量審計 PDP方案.該方案中,TPA批處理校驗不通過后,逐一校驗organizer服務器返回的按用戶聚合的證明以實現定位.2015年,Shin等人[19]提出了一個僅能定位出錯數據所在服務器的批量審計PDP方案,并且只能在單個服務器出錯的情境下進行定位.該方案中,被挑戰服務器為其上屬于不同用戶的被挑戰塊計算一個聚合證明,并發送給 TPA批量審計和錯誤定位.文獻[18,19]不能同時支持定位錯誤數據所屬用戶和所在服務器的原因在于:TPA收到的證明都是經過聚合計算之后得到的聚合值,這種“先聚合再審計”的策略使得TPA在審計時無法同時區分這些聚合證明中涉及的數據塊所在的服務器和所屬的用戶,故而在定位錯誤時只能定位錯誤數據所屬用戶或所在服務器.
本文中,我們提出利用定位標簽輔助TPA快速定位錯誤的方法,并在Zhou等人[17]方案的基礎上,在多用戶多服務器環境下給出了一個具體實現.方案在支持批處理校驗的同時,可以在審計到數據出錯后,僅通過比較操作實現錯誤快速定位,同時找到出錯數據的擁有者與其所處的服務器.
1.2 貢 獻
(1)提出了利用定位標簽輔助第三方審計員快速定位錯誤的方法,并給出一個多用戶多服務器環境下支持批處理校驗和錯誤數據定位的數據擁有性證明方案框架.云用戶對自己的每個文件塊計算相應的數據標簽,將其和文件塊存儲在服務器中,同時對存儲在不同服務器上的數據計算定位標簽并發送給TPA;TPA接收到多個云用戶的審計請求后,可同時對這些用戶存儲在多個云服務器上的數據進行挑戰;在收到被挑戰云服務器返回的證明后,TPA基于發送的挑戰和服務器返回的證明進行有效性批量驗證,若驗證不通過,則利用定位標簽,確定出錯數據的所屬用戶和存儲位置.
(2)給出了一個具體實現.我們的方案是在 Zhou等人[17]基于身份的批處理 PDP方案基礎上增加了定位標簽生成算法,云用戶利用MHT為其數據塊構建定位索引表,并將定位索引表發送給TPA.在審計階段,如果批處理校驗不通過,TPA則利用服務器重構的 MHT樹根查找定位索引表以定位錯誤數據所屬用戶和所在服務器.我們的方案能夠實現僅通過一次比較操作,即可判斷出特定用戶存放在特定服務器上的數據是否遭到破壞.
(3)為了防止服務器在某次審計成功后直接存儲用戶數據的MHT樹根,并利用其在以后的挑戰中構造證明欺騙TPA,本方案中,每個用戶對其存儲在不同服務器上的數據分別用不同的參數值構建λ棵MHT,即對相同數據計算λ個不同的定位標簽,在每次挑戰時,選用不同的 MHT參數值,要求服務器計算相應的MHT樹根.由于服務器無法提前得知每次挑戰指定的MHT參數,則其成功欺騙TPA的概率是可忽略的.
(4)方案在隨機諭言機模型下是可證明安全的.相對于逐一校驗定位錯誤的方式,我們的方案在實現錯誤數據定位的能力和效率方面均有優勢.另一方面,除了可以一次性完成的額外計算外,因定位功能而在審計階段增加的計算和通信開銷都是可以接受的.
1.3 組織結構
本文第 2節介紹一些相關知識和工具.第 3節介紹系統模型和本文中所使用的符號,并且提出方案框架和安全性定義.第4節是具體方案的構造細節.第5節對方案進行安全性分析和性能分析,并提供實驗結果.第6節進行總結.
2 預備知識
2.1 雙線性對
設q是一個大素數,群G1和G2是兩個階為q的乘法循環群,設G1的生成元為g,則群G1到G2的一個雙線性映射e:G1×G1→G2,滿足下面的性質.
(1)雙線性:對于任意的u,v∈G1和a,b∈Zq,有e(ua,vb)=e(u,v)ab.
(2)非退化性:e(g,g)的值不等于群G2中的單位元.
(3)可計算性:對任意的u,v∈G1,存在一個有效的算法可以計算e(u,v).
2.2 CDH困難問題
定義1(CDH問題).設q是一個大素數,群G1是一個q階乘法循環群,G1的生成元為g,CDH問題指的是當a,b未知,三元組已知時,計算gab∈G1.設一個概率多項式時間(PPT)算法A解決群G1上的CDH問題的概率為ε=Pr[gab←A(g,ga,gb)].
定義2.若對于任意PPT算法A,其解決以上CDH問題的概率ε是可忽略的,則稱群G1上的CDH問題是困難的.
2.3 Merkle Hash Tree
Merkle Hash Tree(MHT)是一種二叉樹,常被用來進行數據驗證.數據值做Hash計算后得到的值作為其葉子節點,每個父親節點的值是由兩個子節點的連接值做 Hash計算后得到的.當一個父親節點只有 1個子節點時,父親節點的值為單個子節點值做Hash計算后得到的值.
一般來說,一棵MHT的構造方法如圖1所示.
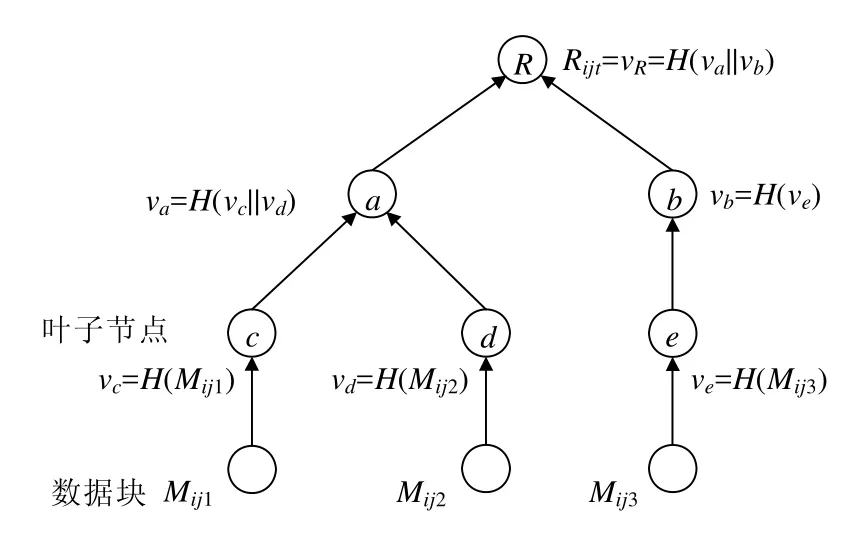
Fig.1 Construction diagram of MHT圖1 MHT構造示意圖
3 定義與模型
3.1 系統模型與設計目標
一個支持批處理和錯誤定位的數據完整性驗證系統(error locating batch provable data possession,簡稱ELBPDP)包含3類實體:數據擁有者(即用戶,DO)、云服務器(CS)、第三方審計員(即校驗者,TPA).
· 數據擁有者:在支持批處理和錯誤定位的數據完整性驗證系統中,有多個數據擁有者.每個數據擁有者擁有各自的文檔數據,他們將文檔數據預處理后對所有數據塊計算數據標簽,將數據塊和數據標簽外包給云服務提供商;對存儲在各個服務器上的數據計算定位標簽,并發送給第三方審計員.
· 云服務器:在本系統中,云服務器的數量也有多個.每個云服務器存儲著數據擁有者們提交的文件塊及其數據標簽.在接收到第三方審計員發送的校驗挑戰后,云服務器計算并返回證明.
· 第三方審計員:收到數據擁有者的審計請求后,第三方審計員給各個云服務器發送挑戰,并對被挑戰服務器返回的證明進行批處理校驗.如果校驗未通過,則根據定位標簽繼續確定錯誤數據塊所屬的用戶和所在服務器,最后將校驗結果發送給相應用戶.
支持批處理和錯誤定位的數據完整性驗證系統的結構如圖2所示.
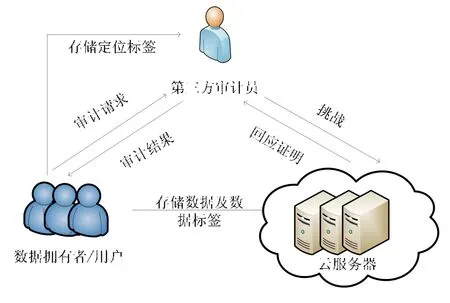
Fig.2 System model diagram圖2 系統模型圖
支持錯誤定位的批處理PDP方案,應滿足如下要求.
(1)支持批處理校驗:校驗者可以一次性批量校驗多個用戶存儲在多個服務器上的數據是否完整.
(2)支持錯誤定位:在批處理校驗失敗后,校驗者可以同時找出錯誤數據所屬用戶與所存儲的服務器.
(3)公開審計性:允許第三方審計員驗證存儲在云服務器上的用戶數據的完整性,但是不需要從云服務器上下載全部的數據.
(4)存儲完整性:確保云服務器只有真實存儲用戶的完整數據才能通過校驗者的驗證.
3.2 符號定義
方案中涉及到的符號含義由表1給出.
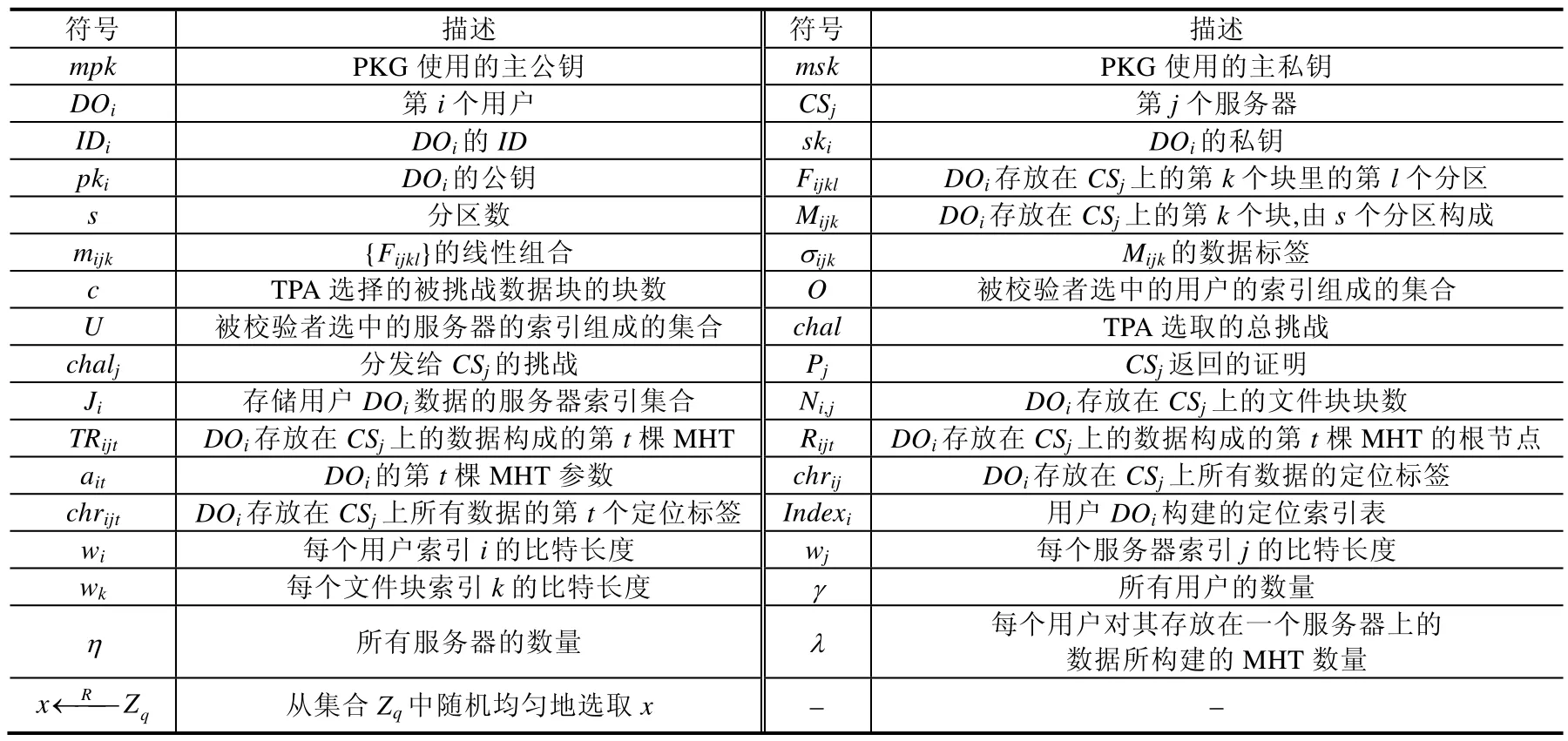
Table 1 Table of symbols and notions表1 符號表
3.3 方案框架
定義3.一個支持批處理和錯誤定位的公開可驗證的數據擁有性證明方案ELBPDP=(SetUp,Extract,TagGen,PosTagGen,Challenge,Prove,Verify)包括以下7種算法.
1)Setup(1k)→(params,mpk,msk).以安全參數k為輸入,PKG(private key generator)輸出公共參數params,主密鑰對(mpk,msk),msk僅為PKG所知.
2)Extract(params,msk,IDi)→(ski,pki).以公共參數params、主私鑰msk和用戶身份IDi為輸入,PKG輸出用戶相應的私鑰ski和公鑰pki.
3)TagGen(params,IDi,ski,mpk,{Mijk})→({σijk}).以公共參數params、用戶身份IDi和私鑰ski、主公鑰mpk、文件數據塊的集合{Mijk}為輸入,用戶DOi對每個塊計算數據標簽σijk,并輸出數據標簽集合{σijk},然后將{Mijk}和{σijk}存儲到相應的服務器端.服務器收到數據塊和數據標簽后校驗其可用性.
4)PosTagGen(params,mpk,{Mijk})→{chrij}.以公共參數params、主公鑰mpk、文件數據塊的集合{Mijk}為輸入,用戶DOi對其存儲在服務器CSj上的數據塊計算定位標簽chrij,并將所有的定位標簽{chrij}發送給校驗者TPA.
5)Challenge({i,j,k})→(chal,{chalj}).以所有文件塊的索引集為輸入,TPA輸出總挑戰chal,并將chal按服務器劃分成若干分挑戰{chalj},然后將每個chalj發送給相應的服務器CSj.
6)Prove(params,chalj,{IDi},{σijk},{Mijk})→Pj.收到挑戰的服務器CSj以公共參數params、挑戰chalj、用戶身份集合{IDi}、數據標簽集合{σijk}和CSj上所存儲的數據塊集合{Mijk}為輸入,計算證明Pj,并將Pj發送給校驗者TPA.
7)Verify(params,chal,{IDi},{Pj},mpk,{chrijt})→{1,{(i,j)}}.以公共參數params、總挑戰chal、用戶身份集合{IDi}、所有被校驗的服務器返回的證明{Pj}、主公鑰mpk、定位標簽集{chrijt}為輸入,TPA批處理校驗證明集{Pj}的有效性,以確定各個被校驗服務器中的數據保存是否完整.若{Pj}有效,則輸出“1”;否則,定位所有出錯數據所屬用戶和所在服務器,并輸出其索引對{(i,j)}.
3.4 安全定義
敵手模型:在我們的方案中,考慮校驗者即 TPA是誠實且好奇的,它總會按照協議規定執行,因為作為第三方審計,一旦被用戶得知會與服務器勾結,對其聲譽有極大的損害,但 TPA也有可能對用戶的數據有一定好奇心.而云服務器為了更高的利益,可能會刪除用戶不常用的數據,而且在丟失或損毀用戶數據后,會偽造數據標簽或者證明企圖通過校驗,欺騙校驗者和用戶.綜上,我們對敵手模型的設定有其合理性.
定義4.偽造數據標簽游戲Dtag-forgeA(k).
1.Setup:挑戰者C運行Setup(1k),得到(params,mpk,msk),將(params,mpk)發送給敵手A,msk秘密保存.
2.Query:敵手A適應性的對C做ExtractQuery和TagGenQuery兩種詢問:
(1)ExtractQuery:敵手A詢問IDi的私鑰.C運行算法Extract(params,msk,IDi),得到私鑰ski,并將其發送給A.C設置一個集合S1={IDi},存放被查詢過的用戶身份.
(2)TagGenQuery:敵手A詢問文件塊Mijk的數據標簽,C運行算法TagGen(params,IDi,ski,mpk,{Mijk})得到數據標簽σijk,并將其發送給A.C設置一個集合I1={(i,j,k,Mijk)},存放被查詢過數據標簽的文件塊.
3.Forge:敵手A對一個身份為的用戶所擁有的文件塊,偽造出一個數據標簽,且
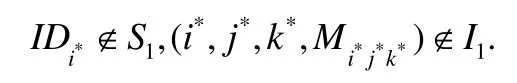
4.如果敵手A輸出的數據標簽是有效的,則游戲輸出為1;否則輸出為0.如果Dtag-forgeA(k)=1,則稱敵手A贏得了這次偽造數據標簽游戲.
定義5.對于任意一個PPT敵手A,如果在一個文件塊集上存在一個可忽略的函數negl,使得:則稱在這個文件塊集上的數據標簽是不可偽造的.
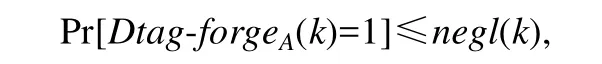
定義6.偽造數據標簽證明游戲DtagProof-forgeA(k).
1.Setup:與偽造數據標簽游戲的Setup階段相同.
2.Query1:與偽造數據標簽游戲的Query階段相同.
3.Challenge:挑戰者C生成一個包含c*組數據的挑戰chal*,其中至少有 1個,使得,且.挑戰者C將挑戰chal*發送給A.
4.Query2:與偽造數據標簽游戲的Query階段相似,設置一個集合S2={IDi}存放本階段被查詢過的用戶身份,設置一個集合I2={(i,j,k,Mijk)}存放本階段被查詢過數據標簽的文件塊.挑戰chal*中至少存在 1個,使得,且.
5.Forge:敵手A針對挑戰chal*,偽造出一個證明.
6.如果敵手A輸出的數據標簽證明是有效的,則游戲輸出為1;否則輸出為0.如果DtagProof-forgeA(k)=1,則稱敵手A贏得了這次偽造數據標簽證明游戲.
定義7.對于任意一個PPT敵手A,如果在一個文件塊集上存在一個可忽略的函數negl,使得:
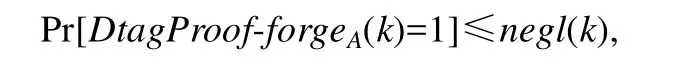
則稱在這個文件塊集上的數據標簽證明是不可偽造的.
4 具體方案
方案的具體細節如下.
1)Setup(1k)→(params,mpk,msk):輸入一個安全參數k,PKG執行以下操作.
PKG選擇兩個階為q的乘法循環群G1和G2,q是一個大素數且滿足q>2k,取G1的生成元為g,在群G1和G2上選擇一個雙線性映射e:G1×G1→G2.
PKG選擇4個密碼學Hash函數H1、H2、H3、H4和一個偽隨機函數f,其中,:(H1和H3、H2和H4分別是不同的Hash函數),.
3)TagGen(params,IDi,ski,mpk,{Mijk})→({σijk}):用戶DOi執行以下操作.
DOi隨機選取,對自己的每個文件塊計算,并計算.令文件塊的數據標簽為.
DOi將其所有的文件塊{Mijk}和相應的數據標簽{σijk}按服務器索引發送給相應的服務器.每個服務器收到用戶發送的數據塊和數據標簽后,通過校驗下面的等式是否成立來確定數據標簽是否可用:
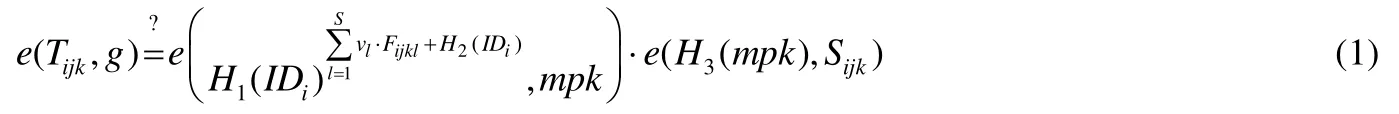
4)PosTagGen(params,mpk,{Mijk})→{ait,chrijt}.
用戶DOi隨機選擇.
設存儲DOi數據的服務器索引集合為Ji,且DOi在服務器CSj(j∈Ji)上存儲的文件塊塊數為Nij.用戶DOi對每一個服務器CSj(j∈Ji),分別以ait(1≤t≤λ)為 MHT參數,對其存儲在CSj上的Nij個數據塊構建λ棵 MHT.每棵樹用TRijt(1≤t≤λ)表示,TRijt的根節點用Rijt表示.
例如,用戶DO1在服務器CS1上共存放了 4 個數據塊M111、M112、M113、M114,使用a1t(1≤t≤λ)作為參數,TR11t的構建如圖3所示,樹的根為R11t.
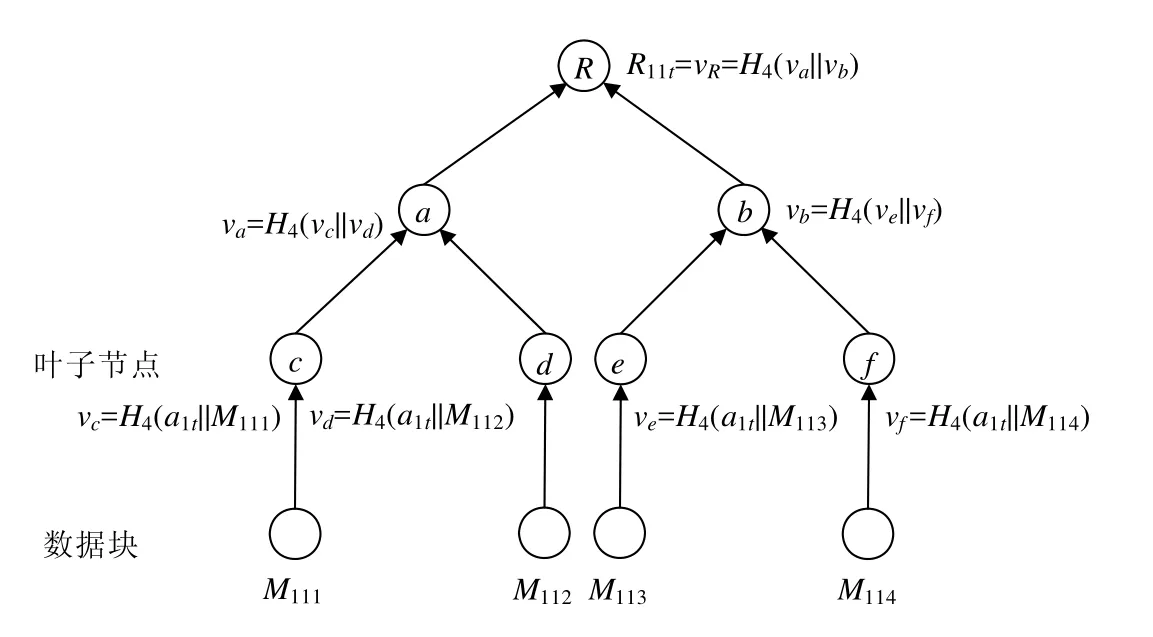
Fig.3 MHTTR11tconstructed byDO1 with the data block stored inCS1 and parametera1t圖3DO1以a1t為參數,針對CS1上的數據塊構建的MHTTR11t
DOi令.
設服務器共有η個.DOi構建一張定位索引表,其中,若不存在,即j?Ji,則令將定位索引表發送給校驗者.定位索引表見表2.

Table 2 Table of locating indexes constructed byDOi表2 用戶DOi構建的定位索引表
校驗者接收用戶DOi發來的審計請求,請求為DOi所有數據塊的索引集{(i,j,k)},包括用戶索引i、存儲DOi數據的服務器CSj索引j∈Ji、存放在CSj上的塊索引k.收到多個云用戶的審計請求后,TPA將所有審計請求做并集,得到總的審計請求集合.
校驗者從總的審計請求集合Q中選出c個塊進行校驗,令表示被選中的c個塊,構建索引集合I={(in,jn,kn)|n=1,…,c}.
校驗者令總挑戰chal=(I,K,α).
設被挑戰的數據塊所在服務器的索引集合{j}用U表示,校驗者將挑戰chal按被挑戰服務器的不同,劃分成|U|個分挑戰{chalj},有.每個,其中,并且.
校驗者將chalj發送給服務器CSj.
Prove-DataTag:收到挑戰chalj的服務器CSj計算(此處{rn}表示服務器CSj對其收到挑戰chalj中所有塊分別計算的偽隨機函數值構成的集合),對chalj中涉及的每一個用戶,計算,得到集合,其中,Oj表示Ij中包含的所有云用戶的索引集合.然后,CSj利用標簽計算.
Prove-PositionTag:服務器CSj針對每個被挑戰的用戶DOi(i∈Oj),對存儲在其上的所有數據塊Mijk,以αj中與DOi的數據塊索引對應的aiτ為參數,按照如圖3所示的方法重構相應的 MHT,表示為TRijτ,其樹根為Rijτ.所有Oj中云用戶的數據塊構建的MHT樹根和與其對應的用戶、服務器索引構成集合{(i,j,Rijτ)|i∈Oj}.
7)Verify(params,chal,τ,{IDi},{Pj},mpk,{chrijt})→{1,{(i,j)}}.
設校驗者生成的總挑戰中所涉及的用戶DOi的索引集合{i}用O表示.校驗者收到所有被挑戰服務器發回的證明后,先計算(此處{rn}表示 TPA對總挑戰中所有被挑戰塊分別計算的偽隨機函數值構成的集合),然后校驗等式(2)是否成立:
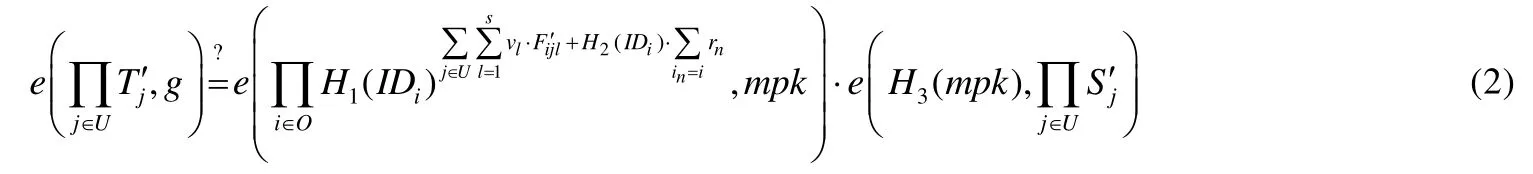
· 若等式(2)成立,則說明批處理校驗通過,即總挑戰中涉及的云用戶的數據審計結果為驗證通過,校驗者輸出1;
· 若等式(2)不成立,則對云服務器CSj(j∈U)返回的集合中的每個元素(i,j,Rijτ),TPA利用(i,j)和τ,查詢定位索引表Indexi中第τ行、第j+1列中的值并校驗等式(3)是否成立:

若不成立,則輸出相應的(i,j).
5 正確性、安全性及性能分析
5.1 正確性證明
定理1.若校驗者和服務器都是誠實的,那么服務器返回的關于數據標簽的證明就可以通過TPA的批處理校驗.
證明:等式(2)的右邊可以進行如下變換:
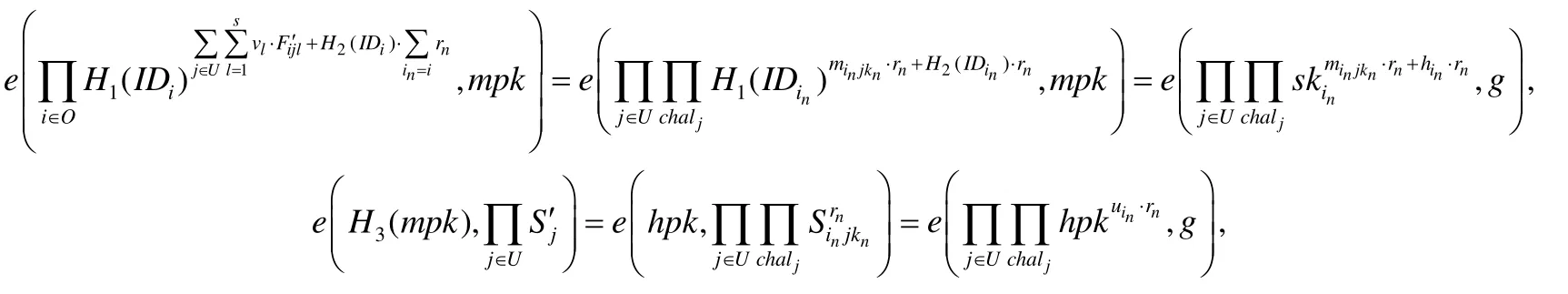
則等式(2)的右邊就等于:
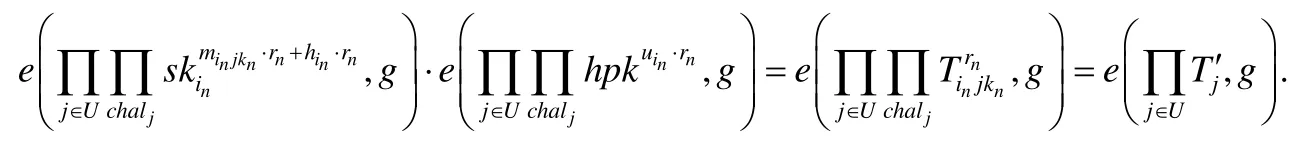
故等式(2)成立.證畢. □
5.2 安全性分析
定理2[17].如果CDH問題是困難的,則在隨機諭言機模型下,不存在一個PPT敵手能夠以不可忽略的概率贏得偽造數據標簽游戲.
證明:令B的輸入為(g,gx,gy)∈G3,其中,G1為q階乘法循環群,g為生成元.B作為挑戰者,想要通過與敵手
1A進行交互得到gxy∈G1,模擬過程如下.
1.Setup:B選擇一個q階乘法循環群G2,在群G1和G2上選擇一個雙線性映射e:G1×G1→G2,隨機選擇,設置mpk=gx,將(G1,G2,q,g,e,mpk,{vl})發送給敵手A.
2.H1-Query:A可以隨時查詢隨機諭言機H1,B需要構建維護一張H1列表H1-list={(IDi,bi,ai,H1(IDi))}來存儲對A的回應.當A對IDi查詢H1,B回應方法如下:
1)若H1-list中有包含元素IDi的元組,則B讀取四元組(IDi,bi,ai,H1(IDi)),并將H1(IDi)發送給A.
2)若H1-list中沒有包含元素IDi的元組,則B根據bi的值對A進行回應,其中,bi由B通過二項分布Pr[bi=0]=δ,Pr[bi=1]=1-δ確定.
a)若bi=0,B隨機選擇一個,計算;
b)若bi=1,B隨機選擇一個,計算.
B將(IDi,bi,ai,H1(IDi))加入表H1-list中,并將H1(IDi)發送給A.
3.H2-Query:A可以隨時查詢隨機諭言機H2,B需要構建維護一張H2列表H2-list={(IDi,H2(IDi))}來存儲對A的回應.當A對IDi查詢H2,B回應方法如下.
1)若H2-list中有包含元素IDi的元組,則B讀取二元組(IDi,H2(IDi)),并將H2(IDi)發送給A.
2)若H2-list中沒有包含元素IDi的元組,則B隨機選擇一個H2(IDi)發送給A,然后將二元組(IDi,H2(IDi))加入表H2-list中.
4.H3-Query:A可以隨時查詢隨機諭言機H3.B需要構建維護一張H3列表H3-list={(mpki,zi,H3(mpki))}來存儲對A的回應.當A對mpki查詢H3,B回應方法如下.
1)若H3-list中有包含元素mpki的元組,則B讀取三元組(mpki,zi,H3(mpki)),并將H3(mpki)發送給A.
2)若H3-list中沒有包含元素mpki的元組,則B隨機選擇,計算,并將H3(mpki)發送給A.然后,B將三元組(mpki,zi,H3(mpki))加入表H3-list中.特別地,當mpki=mpk時,B將相應的元組記為(mpk,z,H3(mpk)=gz).
5.ExtractQuery:A可以隨時查詢隨機諭言機Extract.B需要構建維護一張表Extract-list={(IDi,ski)}來存儲對A的回應.當A對IDi查詢諭言機Extract,B回應方法如下.
1)若Extract-list中有包含元素IDi的元組,則B讀取二元組(IDi,ski),并將ski發送給A。
2)若Extract-list中沒有包含元素IDi的元組,則B查找H1-list中是否有包含元素IDi的元組,若沒有,則B生成一個H1(IDi)的查詢,使得四元組(IDi,bi,ai,H1(IDi))存在.B根據bi的值對A進行回應.
a)若bi=0,則B計算,并將ski發送給A.然后,B將(IDi,ski)加入表Extract-list中;
b)若bi=1,則B報告失敗,并終止模擬.
6.TagGenQuery:A可以隨時查詢隨機諭言機TagGen.B需要構建維護一張表TagGen-list={(i,j,k,Mijk,σijk)}來存儲對A的回應.當A對(i,j,k,Mijk)查詢諭言機TagGen,B回應方法如下.
1)若TagGen-list中有包含元素(i,j,k,Mijk)的元組,則B讀取五元組(i,j,k,Mijk,σijk),并將σijk發給A.
2)若TagGen-list中沒有包含元素(i,j,k,Mijk)的元組,則B查找H1-list中是否有包含元素IDi的元組,若沒有,則B生成一個H1(IDi)的查詢.然后,B查找H2-list中是否有包含元素IDi的元組,若沒有,則B生成一個H2(IDi)的查詢.然后,B查找H3-list中是否有包含元素mpk的元組,若沒有,則B生成一個H3(mpk)的查詢.B根據bi的值對A進行回應.
a)若bi=0,則B隨機選擇Sijk∈G1,計算:
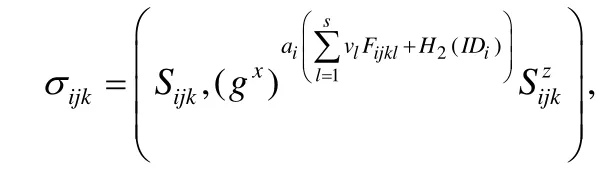
并將σijk發送給A.然后,B將五元組(i,j,k,Mijk,σijk)加入表TagGen-list中.可以驗證,(i,j,k,Mijk,σijk)滿足等式(1),即σijk為數據塊(i,j,k,Mijk)的有效標簽.
b)若bi=1,則B報告失敗,并終止模擬.
7.Forge:敵手A對一個身份為的用戶所擁有的文件塊偽造數據標簽,要求敵手A之前并未對進行過ExtractQuery,且未對進行過TagGenQuery.B查找H1-list中是否有包含元素的元組,若沒有,則B生成一個的查詢.然后,B查找H2-list中是否有包含元素的元組,若沒有,則B生成一個的查詢.然后,B查找H3-list中是否有包含元素mpk的元組,若沒有,則B生成一個H3(mpk)的查詢.B根據bi的值做如下操作.
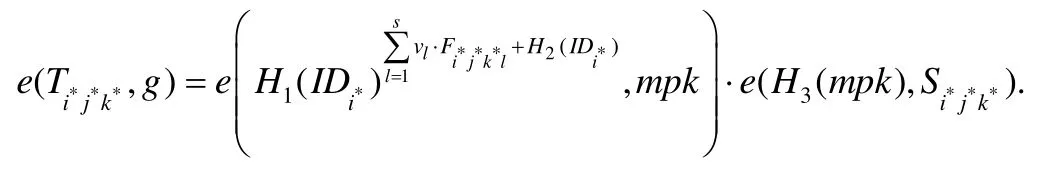
B可得到:
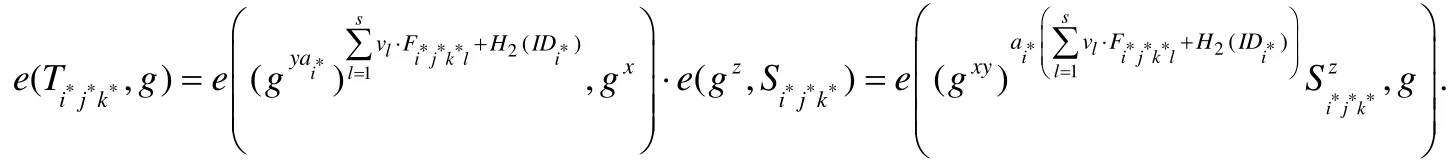
B計算.
令E表示事件B求解出gxy,經過上面分析可知:在A進行nEQ次ExtractQuery和nTQ次TagGenQuery時模擬未終止,且A對數據塊成功地偽造出有效的數據標簽;同時,在對進行H1-Query時,若元組中,則事件E發生.若敵手A贏得偽造數據標簽游戲的概率ε不可忽略,則不可忽略,即B解決群G1上的CDH問題的概率不可忽略.當δ=(nEQ+nTQ)/(nEQ+nTQ+1)時,取得最大值.證畢. □
定理3[17].如果CDH問題是困難的,則在隨機諭言機模型下,不存在一個PPT敵手能夠以不可忽略的概率贏得偽造數據標簽證明游戲.
證明:令B的輸入為,其中,G1為q階乘法循環群,g為生成元.B作為挑戰者,想要通過和敵手A進行交互得到gxy∈G1,模擬過程如下.
1.Setup:B選擇一個q階乘法循環群G2,在群G1和G2上選擇一個雙線性映射e:G1×G1→G2,隨機選擇,選取偽隨機函數,設置mpk=gx.將(G1,G2,q,g,e,f,mpk,{vl})發送給敵手A.
2.B對H1-Query、H2-Query、H3-Query、第1階段Extract-1Query、TagGen-1Query的回應方式與定理2證明中的回應方式相同.
3.Challenge:令S1表示第 1階段被Extract-1Query過的用戶身份IDi的集合,集合I1存放第 1階段被TagGen-1Query的(i,j,k,Mijk).B生成挑戰chal*=(I*,K*,α*),其中,,,其中至少有1個,且對于相同的,至少有1個塊將挑戰chal*發送給A.
4.第2階段Extract-2Query,TagGen-2Query與定理2中ExtractQuery,TagGenQuery相同,并令S2表示第2階段被Extract-2Query過的用戶身份IDi的集合,集合I2存放第 2階段被TagGen-2Query過的(i,j,k,Mijk).需保證挑戰chal*中至少有1個,且對于相同的,至少有1個塊.
5.Forge:敵手A針對挑戰chal*,偽造證明.B在H1-list中查找,對于不存在列表中的,B對其做H1-Query.B在H2-list中查找,對于不存在列表中的,B對其做H2-Query.B在H3-list中查找是否有(mpk,z,gx),若沒有,則B對mpk進行H3-Query.B根據的值做如下操作.
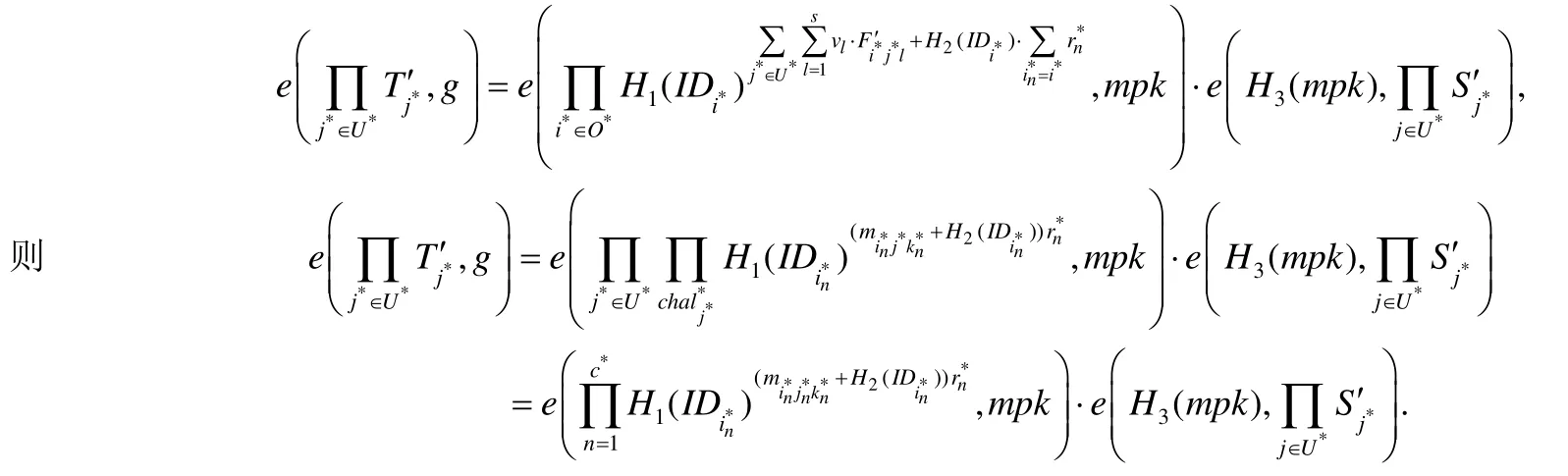
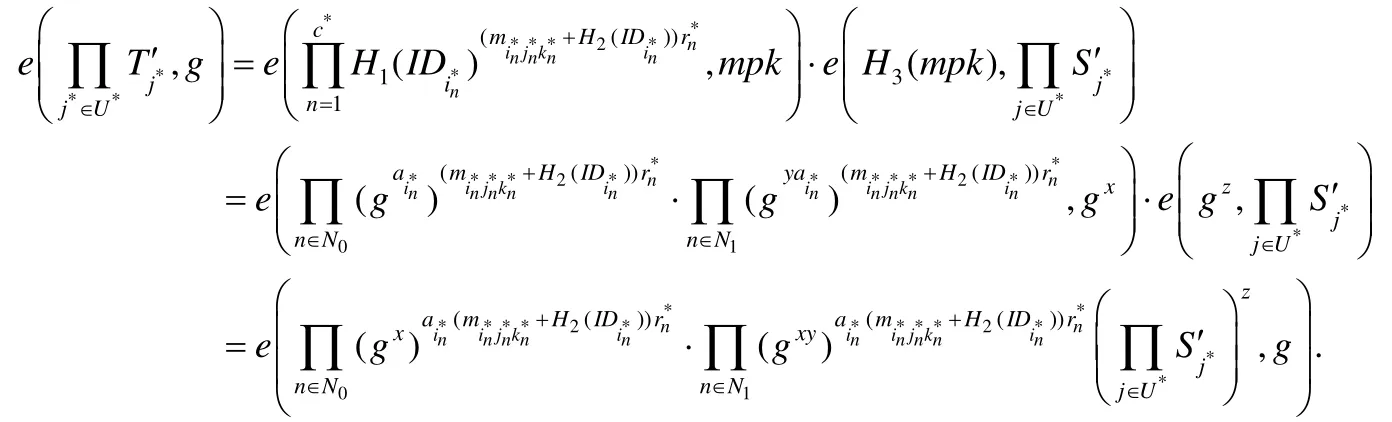
B計算.
令E表示事件B求解出gxy,經過上面的分析可知,在A進行nEQ次ExtractQuery和nTQ次TagGenQuery未終止,且A針對挑戰能夠成功偽造出可通過校驗的數據標簽證明;同時,對進行H1-Query時,其中至少有1個,則事件E發生.設敵手A贏得偽造數據標簽證明游戲的概率為ε,則B解決群G1上的CDH問題的概率為時,取得最大值.證畢. □
定理4.如果Hash函數是抗碰撞的,則不存在一個PPT敵手能夠以不可忽略的概率偽造出通過TPA校驗的定位標簽證明.
證明:被挑戰服務器在每次挑戰時都會收到TPA發來的重構MHT的參數.由于每次挑戰用于定位的MHT根標簽所使用的參數不同,使得服務器無法提前預知、計算并存儲葉子節點,所以收到挑戰的服務器都需要根據挑戰中MHT參數集{αj}重新計算相應的MHT根值作為證明.在MHT中,葉子節點是參數與文件塊連接后做Hash運算得到的,而根值是由所有葉子節點經過多層計算Hash值得到的,所以,若Hash函數是抗碰撞的,則要在不知道參數與文件塊值的情況下偽造出可通過校驗的根值的概率是可以忽略的.證畢. □
此外,要說明的是,為了實現錯誤定位,且使得用戶端不額外存儲多余的信息,有些信息,如用戶數據塊所存儲的服務器和所有用戶數據的定位索引表,TPA都是知道的.而定位索引表中的元素是每個用戶存儲在不同服務器上的數據所構成的MHT樹根,若Hash函數是抗原象攻擊的,則TPA無法得知用戶原始數據塊值.
5.3 性能分析
在下面的分析中,n表示所有云用戶的文件塊總數,c表示TPA選中的被挑戰塊的數量,n1表示c個被挑戰塊所屬用戶的數量,n2表示c個被挑戰塊所在的服務器的數量,η表示所有云服務器的數量,γ表示所有云用戶的數量,s表示每個數據塊的分區數,λ表示每個用戶對其存放在一個服務器上的數據所構建的 MHT數量.cj表示被挑戰服務器CSj上被挑戰的塊數,有1≤cj≤cmax=c-n2+1.假設云用戶DOi總共將mi個文件塊存儲到多個服務器中,服務器CSj上共存儲了m′j個文件塊.
方案的通信輪數為1輪,在此一輪通信中既實現了批處理校驗,又能實現錯誤數據的定位功能.
1.關于通信復雜度
在初始階段,云用戶除了將文件塊{Mijk}和相應的數據標簽{σijk}發送給服務器以外,為了實現對其錯誤數據進行定位,還需要將定位索引表發送給TPA,每個用戶的定位索引表中包含λ(η+1)個Zq中的元素.
在挑戰階段,TPA發送總挑戰chal=(I,K,α),其中,I中包括3c個整數,K中包含c個Zq中的元素,α中也包含c個Zq中的元素.綜上,挑戰階段的通信復雜度為O(c).
2.關于存儲復雜度
服務器存儲著用戶的數據塊和相應的數據標簽,與其他方案相似.TPA需要存儲所有用戶發來的數據塊定位標簽,共有γ張定位索引表,包含γλ(η+1)個Zq中的元素,存儲復雜度為O(γλη).
3.關于計算復雜度
云用戶:除了為每個數據塊計算相應的數據標簽以外,為了實現錯誤定位,額外地,云用戶需要對其存儲在不同服務器上的數據塊分別構建λ棵MHT.含有Nij個葉子節點的MHT最多需要做次Hash運算.擁有mi個數據塊的云用戶DOi最多計算次 Hash,因此,DOi計算定位標簽的時間復雜度為O(λmi),這項工作是一次性的.
被挑戰服務器:計算的證明包含兩部分:(1)用于批處理校驗的部分,需要做cj次偽隨機函數運算、2cj次指數運算、2(cj-1)次群中乘法運算、s·cj次普通乘法運算,最多s·(cj-1)次普通加法運算;(2)用于定位錯誤的部分,最多需要進行次Hash運算.
TPA:批處理校驗包括c次偽隨機函數運算、n1次指數運算和3次雙線性對運算,最多n1(s-1)·(n2-1)+c次普通加法運算、最多s·min(n1n2,c)次普通乘法運算、2(n2-1)+(n1-1)次群中乘法運算.若批處理校驗不通過,則再對服務器返回的樹根一一進行對比校驗,判斷某一用戶存放在某一服務器上的數據是否遭到損毀,只需一次比較操作.
下面將我們的方案與其他多用戶多服務器環境下支持批處理校驗的方案進行比較.從效率和是否支持錯誤定位方面,我們的方案與He等人[18]、Shin等人[19]和Zhou等人[17]的方案進行對比的結果見表3.
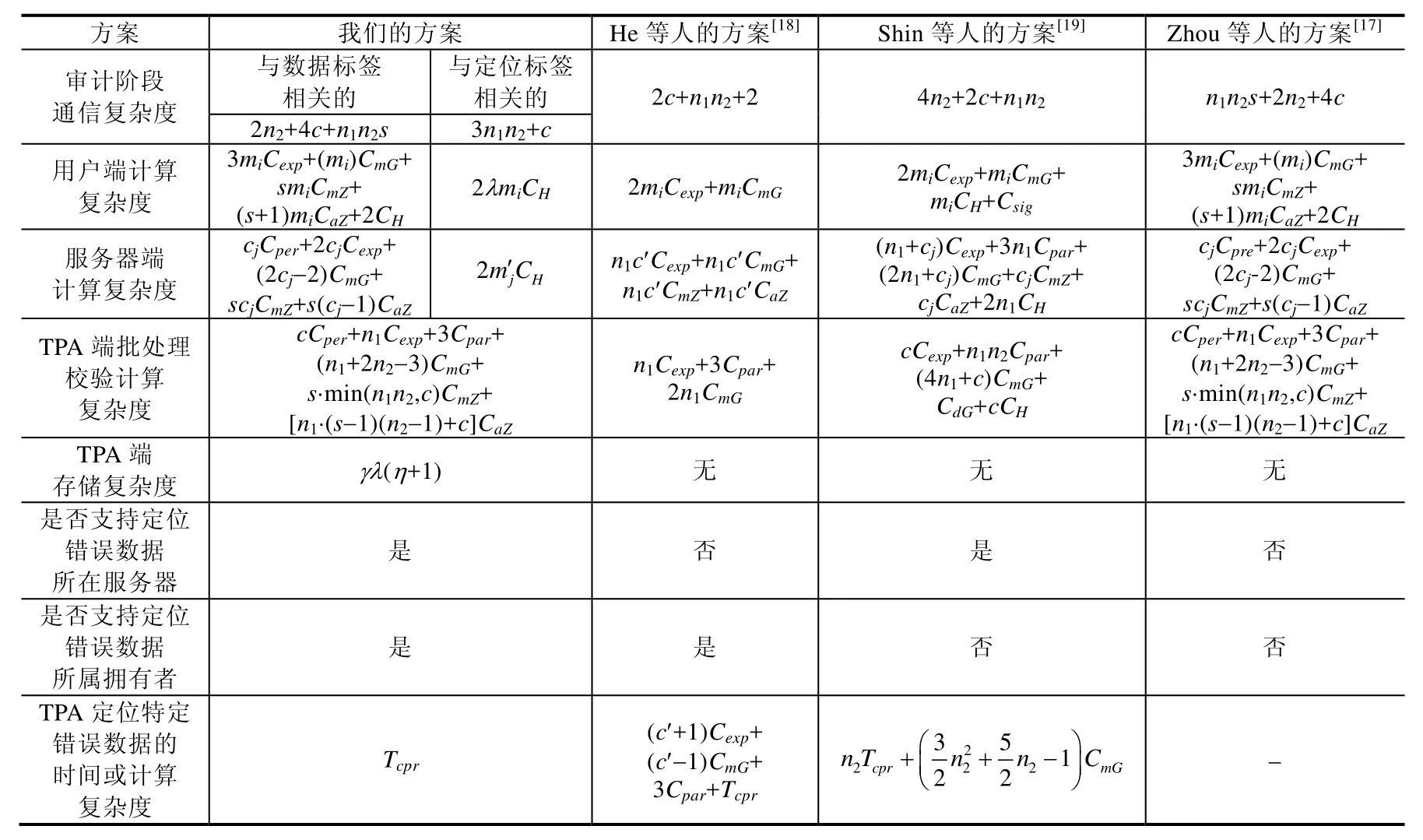
Table 3 Comparison of efficiency and location function表3 效率及定位功能比較
其中,Cexp表示群G1上單個指數運算的開銷,CH表示單個Hash函數運算的開銷,Cpar表示一個雙線性對運算的開銷,Cper表示一個偽隨機函數運算的開銷,CmG表示群上單個乘法運算的開銷,CdG表示群上單個除法運算的開銷,CmZ表示單個普通乘法運算的開銷,CaZ表示單個普通加法運算的開銷,Tcpr表示一次比較的時間開銷.因為文獻[18]中每個用戶的數據都會被挑戰且被挑戰的塊索引相同,令c′表示一個被挑戰用戶被挑戰的塊數,即c=c′·n1.
4個方案中,審計階段都僅需1輪通信,我們的方案在1輪通信中不僅能夠實現批處理校驗,還能在校驗不通過情況下定位錯誤數據所屬用戶和所屬服務器;而文獻[18]只支持定位錯誤數據的擁有者;文獻[19]只支持定位錯誤數據所在服務器,并且僅適用于只有 1個服務器的數據被損毀的情景.我們的方案是基于查找的方式定位錯誤數據,判斷特定用戶存儲在特定服務器上的數據是否出錯僅需一次比較操作;而文獻[18,19]都是利用計算的方式來實現錯誤數據定位,文獻[18]判斷特定用戶的數據是否損毀需要O(c′)次指數運算,文獻[19]定位唯一的數據被損毀服務器需要次乘法運算.
在我們的方案中,為了計算定位標簽,用戶需要為其數據塊構建 MHT,服務器在計算證明時需要重構 MHT,所以相對于其他方案,在用戶端和服務器端分別增加了2λmi和2mj′次Hash運算.由于Hash運算的速度很快,所以增加的計算對總體的計算開銷影響并不顯著.為了定位錯誤,相對于文獻[17-19],TPA需要額外存儲γ張定位索引表,總共γλ(η+1)個Zq中的元素,而TPA進行批處理校驗的計算量相對于文獻[17]來說并沒有增加.
5.4 仿真實驗
我們首先對云用戶、服務器和 TPA各自計算的時間開銷進行了仿真實驗,然后對兩種定位錯誤方式的定位效率進行了對比.PC硬件配置為Intel Core2Duo處理器、4G內存,操作系統為Ubuntu 16.04 LTS 32位,利用PBC庫[20]、GMP庫[21]和Miracl庫[22],使用gcc編譯執行.實驗中,使用PBC庫中a.param參數設置雙線性對,構造MHT時采用SHA-256.
1.用戶計算數據標簽TagGen和定位標簽PosTagGen的計算開銷
用戶將文件分塊后,對每個數據塊計算相應的數據標簽,然后對存儲在不同服務器上的數據塊計算定位標簽.在實驗中,我們設置每個數據塊4KB,每個分區 20B,通過設置不同的文件大小來觀察 TagGen和 PosTagGen的計算開銷.令用戶文件大小為5MB~40MB,相應的數據塊數為1 250~10 000,設置步長5MB.TagGen的計算開銷與λ=64和λ=128時PosTagGen的計算開銷實驗結果如圖4所示.
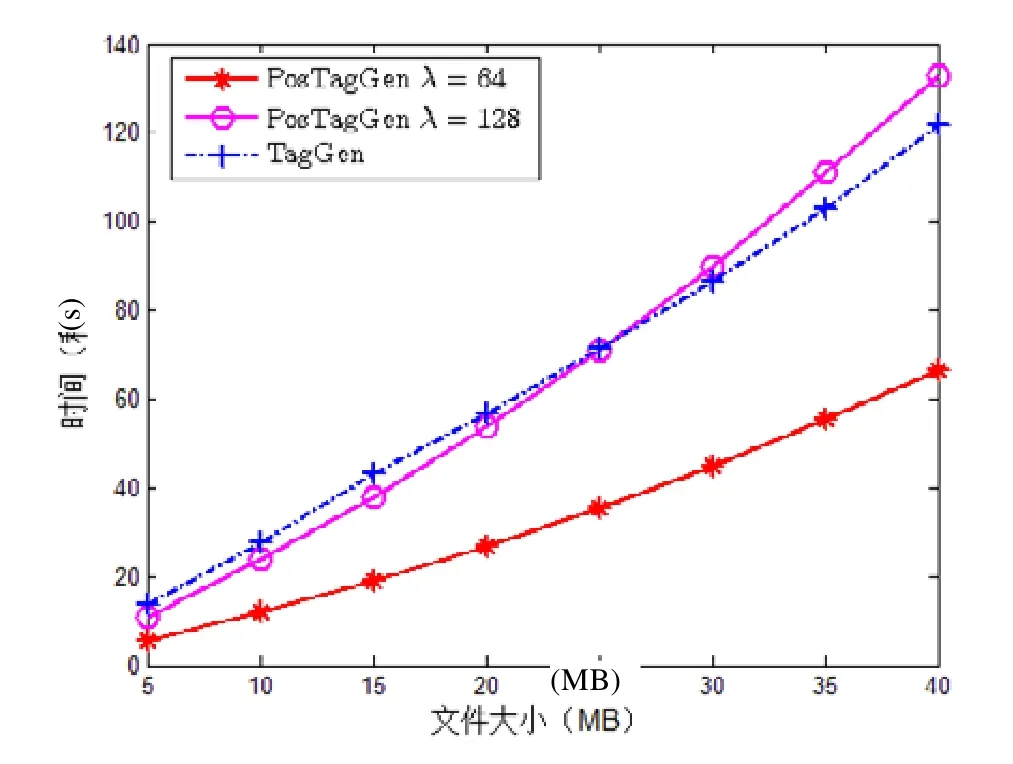
Fig.4 Computational cost of TagGen &PosTagGen for increased size of files圖4 文件大小增加時TagGen和PosTagGen的計算開銷
從實驗結果可以看出,TagGen的時間隨著文件大小的增長(數據塊數增長)呈線性增長,與性能分析結果一致.特別地,當文件大小為5MB(40MB)時,TagGen的時間為13.6s(121.7s).PosTagGen的計算開銷與文件大小(數據塊數量)和λ值是相關的:當λ值固定時,PosTagGen的計算開銷隨著數據塊數量增加而增大,基本呈線性增長,實驗結果與性能分析相符合.進一步觀察,當λ=64,文件大小為 5M(40M)時,PosTagGen的時間為 5.5s(66.5s).當λ=128,文件大小為 5MB(40MB)時,PosTagGen的時間為 11.0s(133.0s).TagGen與 PosTagGen的計算開銷較大,耗費的時間顯著高于其他操作耗費的時間,但是對于一個文件來說都僅需計算 1次.表4為當λ=64和λ=128時,TPA進行校驗的不同時間間隔所能支持的錯誤定位有效期.

Table 4 Error locating period of validity for different verification time interval表4 不同校驗時間間隔下,支持錯誤定位的有效期
2.服務器計算證明Prove-DataTag、Prove-PositionTag和TPA批量校驗數據標簽證明Verify的計算開銷
在挑戰響應階段,收到挑戰的服務器需要計算數據標簽的證明 Prove-DataTag和定位標簽的證明 Prove-PositionTag,而TPA需對被挑戰服務器返回的數據標簽證明進行批量審計.
服務器Prove-DataTag的計算開銷與TPA批量審計Verify的計算開銷均與TPA選取的挑戰塊數量有關,所以我們在同樣的條件下對這兩個計算進行了仿真.實驗中,我們設置了10個用戶和10個服務器,每個用戶擁有10 000個數據塊,每個數據塊4KB,每個分區20B,每個用戶將其10 000個數據塊均勻地存儲到10個服務器上,這樣,每個服務器上存儲著10個用戶的10 000個數據塊.若云服務器的數據塊損毀率為1%,則TPA挑戰其上的300個(460個)數據塊,就能以95%(99%)的概率檢測出該服務器的損毀數據行為[23].因此,在TPA隨機均勻選取10個服務器上的挑戰塊的情況下,我們對總挑戰塊數為3 000~4 600(相應的每個服務器上被挑戰塊數為300~460),以步長為200,進行了實驗,結果如圖5所示.
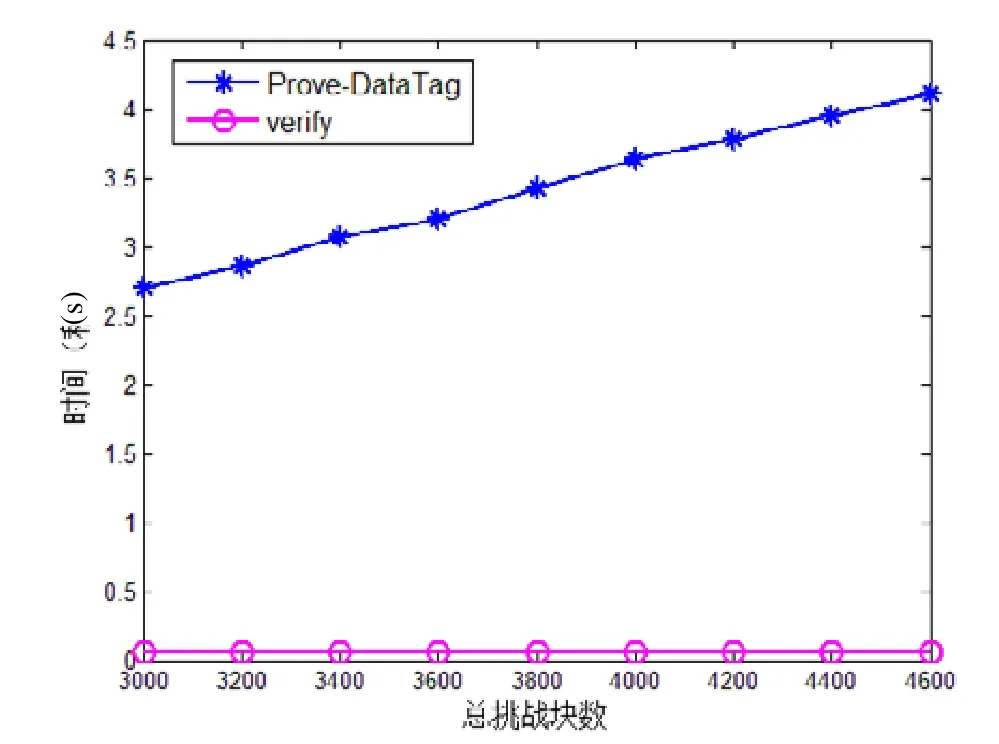
Fig.5 Computational cost of Prove-DataTag by single server &Verify by TPA for increased number of total challenged blocks圖5 總挑戰塊數增加時,單個服務器Prove-DataTag和TPA Verify的計算開銷
從實驗結果可以看出,服務器Prove-DataTag的計算開銷隨著其上被挑戰塊數量的增加而增長.這主要是因為當其上被挑戰塊數增加時,服務器需要為增加的挑戰塊的數據標簽做群上的指數運算.隨著總挑戰塊數的增加,TPA批量校驗數據標簽證明 Verify的計算開銷增長并不明顯.這是因為增加的操作只是一些偽隨機函數和普通加法運算,實驗結果與性能分析結果一致.進一步觀察,當總挑戰塊數為 3 000(4 600)個時,服務器 Prove-DataTag的時間為2.7s(4.1s),TPA Verify的時間僅為53ms(54ms).
被挑戰服務器計算定位標簽證明Prove-PositionTag的計算開銷與該服務器上被挑戰用戶的所有數據塊數有關.我們對其中最壞的情況進行了模擬,即數據存放于該服務器上的所有用戶均有數據塊被TPA挑戰,所以被挑戰服務器需對其上存儲的所有數據塊進行重構MHT的操作.我們令被挑戰服務器存儲的數據塊數為5 000~12 000,步長為1 000,對單個被挑戰服務器計算定位標簽證明Prove-PositionTag(即重構MHT)的計算開銷進行測試,結果如圖6所示.
從實驗結果可以看出,服務器重構MHT的計算開銷隨著該服務器上存儲的數據塊數增加而增長,且增長趨勢基本呈線性,與性能分析結果一致.由于Prove-PositionTag的計算是重構MHT樹,所做的都是Hash操作,因此即使是在最壞情況下,重構MHT的時間也是較快的.當服務器上存有5 000(12 000)個數據塊,且所有其上用戶都有數據塊被挑戰時,服務器Prove-PositionTag的時間為0.42s(1.34s).
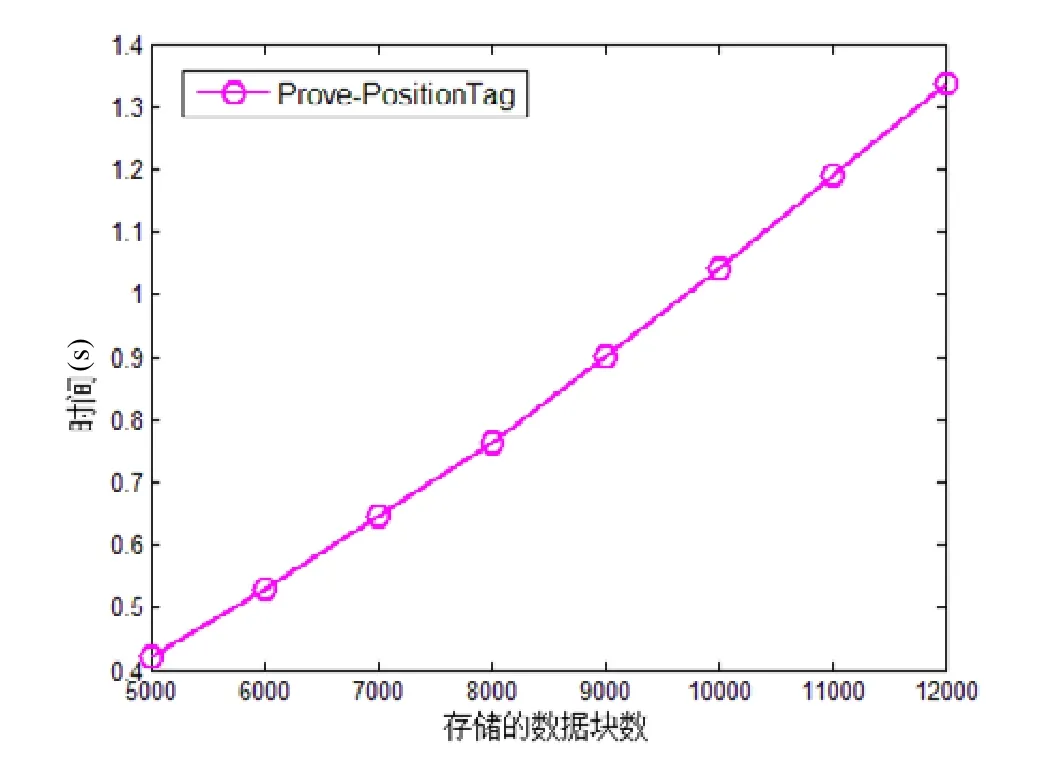
Fig.6 Computational cost of Prove-PositionTag by single server for its increased number of stored blocks圖6 存儲的數據塊數增加時,單個服務器Prove-PositionTag的計算開銷
3.TPA定位錯誤時間比較
在本節中,我們對兩種定位錯誤方式的定位效率進行對比:逐一校驗方式和利用定位標簽輔助定位的方式.為了使對比結果更合理,我們同樣是在 Zhou等人方案[17]的基礎上實現逐一校驗定位錯誤,并設置相同的環境參數.但需要說明的是,逐一校驗方式使得Zhou等人的方案只能定位錯誤數據所在服務器.
在實驗中,我們設置10個用戶和100個服務器,每個用戶擁有100 000個數據塊,每個數據塊4KB,每個分區20B,每個用戶將其 100 000個數據塊均勻存儲到 100個服務器上,這樣,每個服務器上就存儲著 10個用戶的10 000個數據塊.在TPA隨機均勻選取每個被挑戰服務器上10個用戶的300個挑戰塊的情況下,令被挑戰服務器個數為10~100,模擬兩種定位錯誤方法的計算開銷,實驗結果如圖7所示.
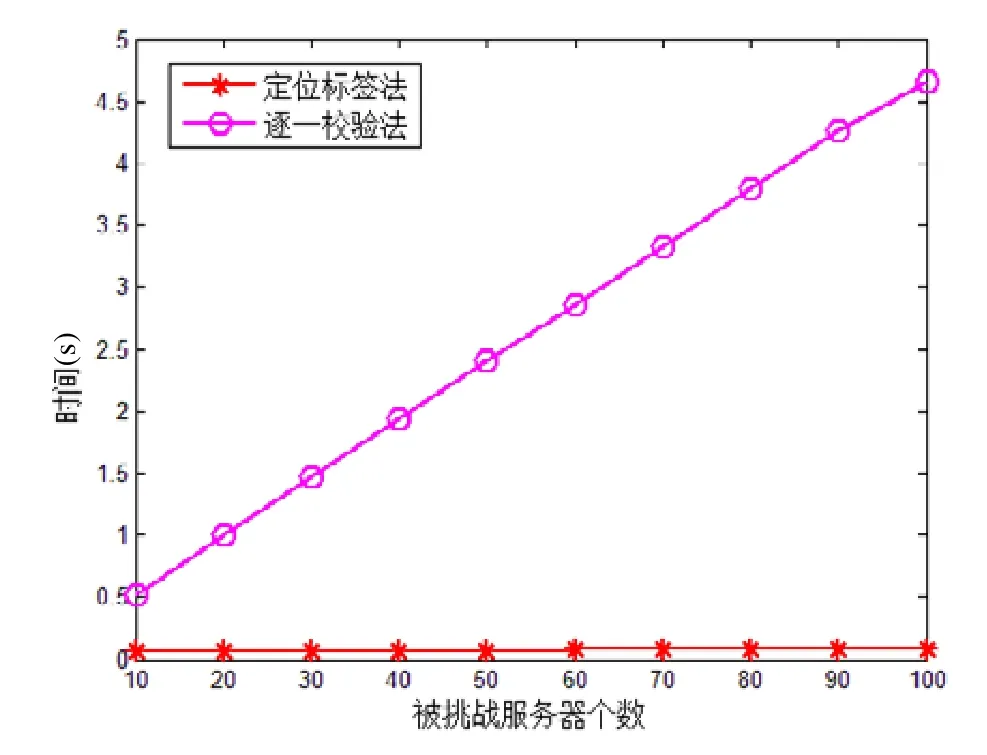
Fig.7 Time comparison of location errors by TPA圖7 TPA定位錯誤時間比較
從實驗結果可以看出,隨著被挑戰服務器數量的增加,逐一校驗方式定位錯誤服務器的時間耗費呈線性增長趨勢,而利用定位標簽定位錯誤數據所屬用戶和所在服務器的計算開銷增長并不明顯.這是因為逐一校驗方式中,TPA針對每個被挑戰服務器返回的證明單獨校驗,每次校驗都需要做多個指數運算和雙線性對運算;而利用定位標簽的方式只涉及比較操作.在被挑戰服務器個數為 10(100)時,定位標簽方式僅需 0.059s(0.087s),而逐一校驗方式則需0.523s(4.652s).顯然,隨著被挑戰服務器個數的增加,使用定位標簽輔助錯誤定位的效率顯著優于逐一校驗的方式.
6 總 結
本文主要研究了批處理 PDP方案在批量審計不通過情況下的錯誤數據定位問題.提出了利用定位標簽輔助第三方審計員快速定位錯誤的方法,并在多用戶多服務器環境下給出了一個具體實現,在批處理校驗不通過的情況下,僅通過比較操作就能同時定位錯誤數據所屬用戶和所在服務器.我們對方案的正確性和安全性進行了證明,并對方案的性能進行了理論分析和仿真實驗.性能分析結果表明,我們的方案在定位錯誤數據的能力和效率方面均高于其他具有單一定位功能的方案.實驗結果也表明,利用定位標簽輔助錯誤定位的效率顯著優于逐一校驗的方式,且實現錯誤定位功能的額外計算開銷是可接受的.
在本文方案中,預先設定的 MHT數量使得本方案不適合進行無限次的錯誤定位.為了緩解次數限制問題,有兩種可行的解決辦法.
(1)不要求每次校驗都返回樹的根值.僅當批處理校驗發生錯誤后,校驗者給服務器再次發送挑戰,要求服務器提供相應樹的根值.
(2)對服務器建立分級制度,校驗者在挑戰時可設立一個狀態標識,若狀態為“1”,則要求返回根值;若為“0”則不要求.對信譽好的服務器,可以適當減少其返回根值的次數.
猜你喜歡
動漫星空(興趣英語)(2019年3期)2019-03-06 01:55:00
商用汽車(2016年11期)2016-12-19 01:20:16
少年博覽·小學低年級(2016年10期)2016-11-24 16:07:01
少年博覽·小學低年級(2016年9期)2016-11-24 16:07:00
商用汽車(2016年6期)2016-06-29 09:18:54
少年博覽·小學低年級(2016年5期)2016-05-14 11:59:03
商用汽車(2016年4期)2016-05-09 01:23:12
就業與保障(2015年9期)2015-04-17 03:41:47
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
