基于高光譜成像技術的工夫紅茶數字化拼配
2019-03-11 08:44:36寧井銘李姝寰王玉潔張正竹陸國富
食品科學 2019年4期
關鍵詞:模型
寧井銘,李姝寰,王玉潔,張正竹,宋 彥,徐 乾,陸國富
(1.安徽農業大學 茶樹生物學與資源利用國家重點實驗室,安徽 合肥 230036;2.祥源茶業有限公司,安徽 祁門 245600)
工夫紅茶是中國傳統出口茶類之一[1]。拼配是工夫紅茶生產和經營中重要的工序,是保持產品質量穩定的重要手段。茶葉拼配是根據成品茶的質量標準(一般以實物樣為標準),將多種不同的篩號茶(原料),按一定的比例混合,組成某一確定花色等級的成品茶[2-4]。對于同一款產品,如采用高等級原料拼配而成,企業的經濟利益就會受到損失;如用低等級原料拼配,又會達不到產品質量要求,因而拼配對于茶葉企業而言至關重要。準確掌握拼配質量是調劑茶葉品質,穩定產品質量,充分發揮茶葉經濟價值,提高經濟效益的關鍵環節。目前,茶葉拼配通常采用的方法是由拼配人員先對各茶葉樣品進行外觀和內質審評,再根據經驗和審評結果,試拼小樣,然后進行適當調整,最終確定拼配方案[5],因而不同批次拼配結果具有偶然性,無法進行量化、標準化生產。另外,拼配專家的培養過程較為漫長,不利于拼配技術的推廣。
高光譜圖像技術融合了光譜信息和圖像信息,既能利用光譜信息分析樣品的內部品質信息,也能基于圖像信息表征樣品的外部品質特征[6-8]。近年來,高光譜圖像技術在農業生產得到了廣泛應用[9-13]。高光譜圖像技術在茶葉上的研究主要集中在茶類識別、等級劃分、茶園管理以及茶葉品質檢測等方面。蔡健榮等[14]結合紋理特征值和支持向量機的模式識別方法進行了碧螺春茶葉的真偽鑒別;艾施榮等[15]也通過紋理特征值結合BP神經網路方法對不同產地的廬山云霧進行了鑒別。于英杰等[16]結合20 個光譜特征參數和支持向量機分類模型對不同等級的鐵觀音茶葉進行等級分類識別;茶園管理主要體現在葉綠素含量及分布在線無損檢測以及茶樹缺素診斷[17]和病蟲害檢測[18]等方面。熊俊飛[19]利用高光譜圖像技術結合表面增強拉曼技術快速檢測茶葉中的農藥殘留。李浬[20]結合紋理特征值快速檢測出龍井茶的含水率,并建立了含水率預測模型。高光譜圖像技術應用到預測茶葉拼配配比的研究,鮮見相關報道。對茶葉拼配質量的定量化、智能化評估,實現拼配過程的自動化,是未來拼配技術的發展趨勢。
由于生產中茶葉拼配涉及的原料太多,比較復雜,因此,本研究采用4 種原料進行拼配,依次逐步判別。以不同等級不同嘜號的祁門紅毛茶為原料[21],按照一定比例進行拼配,采集拼配樣本的高光譜圖像,利用連續投影算法篩選特征光譜變量,并基于灰度共生矩陣提取圖像的紋理值,融合光譜和紋理特征值建立茶葉拼配比例的定量預測模型,構建拼配比例求解與優化算法。本研究將為茶葉拼配工藝提供一種品質定量評估的新方法,研究結果有利于提高拼配工藝的自動化、智能化水平,推進茶葉生產標準化。
1 材料與方法
1.1 材料
實驗材料來自祥源茶葉股份有限公司,原料A:祁門工夫紅毛茶5 級6 孔正子口;原料B:祁門工夫紅毛茶6 級8 孔正子口;原料C:祁門工夫紅毛茶6 級6 孔正子口;原料D:祁門工夫紅毛茶5 級8 孔正子口。
1.2 儀器與設備
高光譜圖像系統(HSI-NIR-XEVA,五鈴光學股份有限公司),系統主要由高光譜圖像攝像儀(Imspector V17E, Spectral Imaging Ltd., Oulu, Finland)、2 個150 W的光纖鹵素燈(3900型,Illumination Technologies Inc., New York, USA)、移動平臺、暗箱以及包括圖像采集和分析軟件(Spectral Image Software, Isuzu Optics Corp., Taiwan, China)的電腦等組成。
1.3 方法
1.3.1 樣本處理
由于在生產中用于拼配的原料太多、太復雜,本研究采用逐步判別的方法,首先采用2 種原料進行拼配、判別,再采用4 種原料進行拼配、判別,依次類推。實驗采用原料A和B按照比例0%~100%,以10%的變化為梯度且每個梯度拼配10 個樣本,共拼出110 個樣本,原料C和D按照同樣的比例拼出110 個樣本。分別從2 次拼出的茶樣中任挑一個比例的拼配樣本,本實驗挑取的是由原料A與原料B以5∶5的配比拼出的茶樣P1,以及由原料C與原料D以5∶5配比拼出的茶樣P2。然后由P1和P2再次按照比例0%~100%,以10%的變化為梯度拼出110 個樣本。利用高光譜圖像系統采集茶樣的高光譜信息。全部樣品按照2∶1的比例將樣品隨機分成校正集(73 個)和預測集(37 個),利用校正集的樣品建立判別模型,預測集的樣品測試模型的性能。
1.3.2 高光譜圖像采集和處理
為防止信息的過度飽和成像失真,需對高光譜成像系統的參數進行設置。經過反復調節,最終曝光時間設置為2 ms,物鏡的高度設為26 cm。拼配樣品(10±0.5)g均勻平鋪在規格為7.5 cm×1 cm的培養皿中,置于移動平臺上以7.2 mm/s的速率采集高光譜圖像。系統的光譜分辨率5 nm,光譜范圍為908~1 735 nm,共508 個波段。樣本在圖像采集的過程中,由于受高光譜成像儀硬件的影響,獲取的樣本數據在采集開始和結束時受噪聲的影響較大,因此在后續的數據處理過程中,選取957~1 670 nm波段范圍內,共438 個波段的高光譜圖像進行分析。
在高光譜成像系統中,光源強度分布不均勻。因此在對高光譜圖像處理前,先要按照式(1)對圖像進行黑白校正。

式中:Rc為校正后的圖像;R為原始的圖像;B為黑板校正的圖像;W為白板校正的圖像。
1.4 數據分析
1.4.1 主成分分析法
高光譜數據量龐大,因此,要對高光譜數據進行降維,去除冗余信息,優選特征波長。主成分分析[22](principal component analysis,PCA)法主要是通過協方差最大的方向將高維數據空間向低維數據空間投影,將原始數據轉化到新的坐標系統中[23],得到幾個彼此相互獨立的綜合變量,且都是原始數據的線性組合,本研究根據方差貢獻率提取主成分圖像,并通過比較主成分圖像下各波長的權重系數的絕對值大小優選特征波長。
1.4.2 光譜特征值的選取
連續投影算法(successive projections algorithm,SPA)[24]利用向量的投影分析,在光譜信息中充分尋找含有最低限度的冗余信息的變量組,將變量間共線性的影響降到最低,從而減少信息的重疊,同時篩選出的幾個變量就能代表原始數據的大部分信息,提高了建模的速度和效率。
1.4.3 紋理特征提取
基于灰度共生矩陣提取特征波長圖像下的紋理值。灰度共生矩陣[25]是關于圖像亮度變化的二階特征統計[26],是計算特定像素間距離和角度的函數。本實驗中,距離設置為1,對0°、45°、90°和135°四個角度的對比度、相關性、能量和同質性提取紋理變量。其中對比度反映目標圖像的紋理溝槽的深淺程度以及清晰度;相關性是對目標圖像灰度矩陣所有元素在圖像的行、列方向相似度的體現;能量反映了目標圖像在灰度方面的紋理粗細與均勻度;同質性則體現目標圖像的局部平滑[27]。
1.4.4 建模方法的篩選
偏最小二乘(partial least squares,PLS)法[28]結合了PCA和多元線性回歸的化學計量學方法,通過優選因子數達到最佳的模型效果。最小二乘支持向量機(least squares-support vector machine,LS-SVM)是Suykens等[29]為減少計算復雜程度、降低訓練時間以及提高泛化能力提出的一種在經典SVM上改進后的新型統計學習方法。其優勢是在于采用了等式約束,使用求解線性方程組的方法得出最優化結果,占用內存小,求解速度高。采用徑向基核函數(radial basis function,RBF)兩個重要參數為回歸誤差權重γ和RBF核函數的核參數δ2。這兩個參數字在很大程度上決定了算法的學習和泛化能力,采用二次網絡搜索和留一交叉驗證的方法對γ和δ2進行了全局尋優。初始值分別設置為100和0.1。反向傳播人工神經網絡(back propagation-artificial neural networks,BPANN)是一種反向傳遞并修正誤差的多層映射神經網絡,具有很強的非線性建模能力,適合解決復雜的映射問題。
1.4.5 數據分析軟件
ENVI 4.7(ITT Visual Information Solutions, Boulder, USA),Matlab 2014a(The Mathworks Inc., Massachusetts, USA)。
2 結果與分析
2.1 不同樣品的光譜差異
本實驗采集908~1 735 nm波長范圍的近紅外光譜數據,選擇圖像中間100×100像素范圍為感興趣區域(region of interest,ROI),提取ROI所有像素的光譜值,并計算出其平均值,作為這個樣本的光譜值[30]。化學含量以及物理特征的不同,樣本對特定的波長有著不同的反射率,通過分析光譜信號的差異實現樣本品質信息的定性或者定量檢測。原料C和原料D光譜值差異比較明顯,從圖1可以看出,3 條光譜曲線的趨勢相似,在1 112 nm和1 307 nm波長處出現明顯的特征峰,且峰的高低有明顯差異。
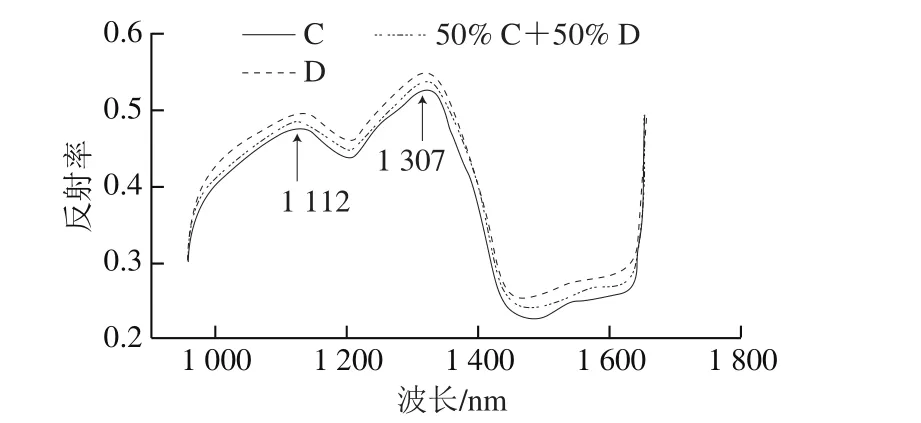
圖1 茶樣C、D與拼配茶樣的平均光譜圖Fig. 1 Average reflectance spectra of samples C and D and their blend
2.1.1 光譜預處理方法篩選
為減少實驗中外界環境的噪聲對信息帶來的影響,本實驗比較了一階導數、平滑、極小/極大歸一化和標準正態變量變換4 種光譜預處理方法對原始光譜進行處理,4 種方法預處理后的光譜圖見圖2,并且采用PLS分別建立定量模型,分析光譜預處理方法對建模結果的影響,結果如表1所示。
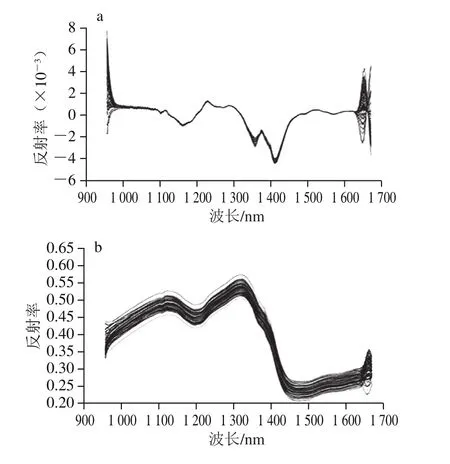
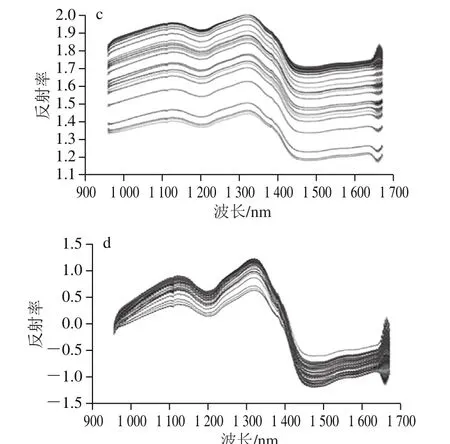
圖2 一階導數(a)、平滑(b)、歸一化(c)和標準正態 變量變換(d)預處理后的光譜圖Fig. 2 Preprocessed spectra with first derivative (a), smoothing (b),maximum-minimum normalization (c) and standard normal variate (d)
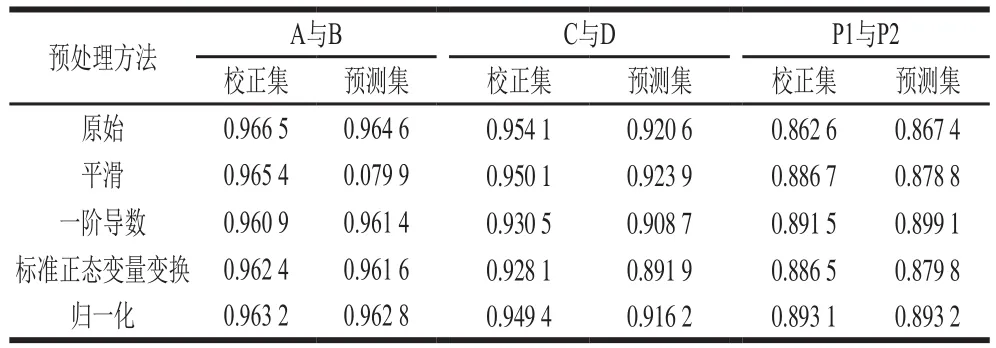
表1 不同預處理方法拼配樣PLS模型的結果比較Table 1 Comparison of the results of PLS with different preprocessing methods for calibration and prediction sets
表1通過對比校正集相關系數(Rc)和預測集相關系數(Rv)確定各預處理方法的效果。其中原料A與原料B的拼配樣,由于進行光譜預處理后建立模型的效果并沒有明顯優于原始數據,從建立模型簡單易行的角度考慮,認為原始光譜數據最優,所以后面的數據處理全部是基于原始光譜數據。原料C與原料D的拼配樣,通過比較校正集與預測集的相關系數,平滑為最佳預處理方法。P1與P2的拼配樣,歸一化為最佳預處理方法。
2.1.2 光譜特征值的選取
全光譜的波段較多,數據量大,且數據間冗余性強,本實驗通過SPA提取特征光譜值。圖3表示的是原料A和原料B拼配樣本通過SPA優選特征光譜變量的過程,當輸入模型的變量個數為10時,RMSE最小,為0.048,所以最終優選出10 個特征波長;這10 個特征波長的位置依次為966、1 019、1 113、1 267、1 338、1 386、1 627、1 647、1 660、1 670 nm。
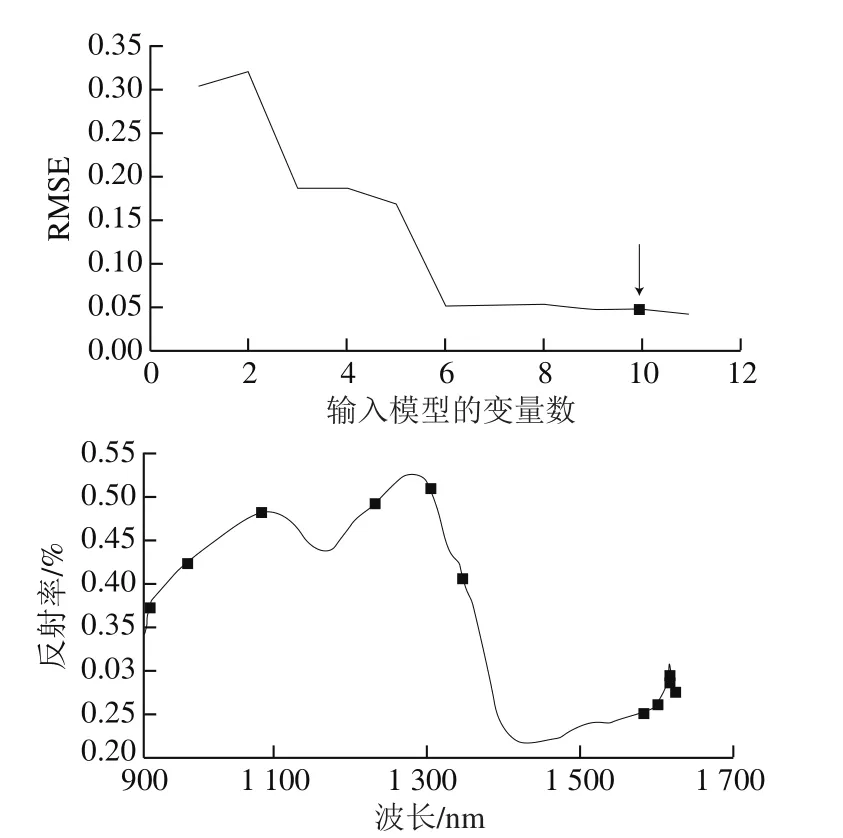
圖3 SPA篩選特征光譜變量過程圖Fig. 3 Selection of characteristic spectral variables by SPA
2.1.3 PCA結果

圖4 拼配茶樣的權重系數圖Fig. 4 Weighted coefficient plots for tea blends
依次對3 次拼出的茶樣高光譜圖像進行PCA,得到前3 個主成分圖像,其中A與B、C與D、P1與P2拼配樣的PC1的方差貢獻率分別為98.85%、98.51%和97.20%,PC2的方差貢獻率分別為0.79%、1.20%和2.08%,前2 個主成分的累計方差貢獻率均達到了99%以上,幾乎可以代表全部信息,因此,可以利用前2 個主成分來進行特征波長的提取。如圖4所示,根據前2 個主成分圖像下各波長的權重系數的絕對值的大小優選5 個特征波長。
如圖4所示,A與B拼配樣的特征波長為1 107、1 187、1 307、1 435、1 655 nm;C與D拼配樣的特征波長為1 112、1 193、1 307、1 438、1 655 nm;P1與P2拼配樣的特征波長為1 121、1 195、1 309、1 475、1 662 nm。
2.2 圖像紋理特征值分析結果
基于灰度共生矩陣的方法來計算茶樣圖像的紋理,提取5 個特征波長下的紋理特征為特征變量。即對A和B在1 107、1 187、1 307、1 435、1 655 nm波長處的灰度圖像分別提取0°、45°、90°、135°的對比度、同質性、能量和相關性。對C和D在1 112、1 193、1 307、1 438、1 655 nm波長處的灰度圖像分別提取4 個角度的對比度、同質性、能量和相關性。在茶樣表面溝紋越深、灰度差越大,則對比度越大,反之越小;若茶樣灰度分布均勻、紋理較粗糙,則能量值越大,反之越小;同質性體現目標圖像的局部平滑;茶樣的灰度共生矩陣值均勻相等時,相關性較大,反之較小。如表2所示,相比而言,原料A溝紋較深、灰度差大,紋理較平滑,條索較緊細;原料B溝紋較淺、灰度分布較均勻,紋理較粗糙,條索較松散;原料C溝紋深度次于原料A,灰度差大,紋理平滑,條索緊細;原料D溝紋稍深于B,灰度分布較均勻,紋理粗糙程度稍高于B,條索較松散。
表2 基于灰度共生矩陣的紋理特征均值Table 2 Mean textual features based on gray level co-occurrence matrix
2.3 定量預測模型的建立結果
光譜特征能表征拼配茶葉的內部品質,紋理特征能表現拼配茶葉外形特點。為更好地表示拼配茶葉隨著拼配比例的不同茶葉整體品質發生的變化,本研究將優選的光譜特征值與紋理特征值在特征層[31]進行融合。分別將光譜特征值、紋理特征值以及光譜和紋理特征值融合得到的數據作為PLS、LS-SVM和BP-ANN模型的輸入值,建立拼配茶樣配比定量預測模型,結果如表3所示。以光譜特征值和紋理特征值融合數據作為LS-SVM模型的輸入值時預測結果最好,原料A與原料B拼配樣預測集判別率為91.89%,原料C和原料D拼配樣預測集判別率為86.13%,茶樣P1和茶樣P2拼配樣預測集判別率為94.5%,其中通過預測茶樣P1、P2配比,即可分別得到原料A、B、C、D的配比,可以間接解決4 個原料茶樣拼配預測配比的問題。結果表明本研究能實現對拼配茶樣配比的量化判別。
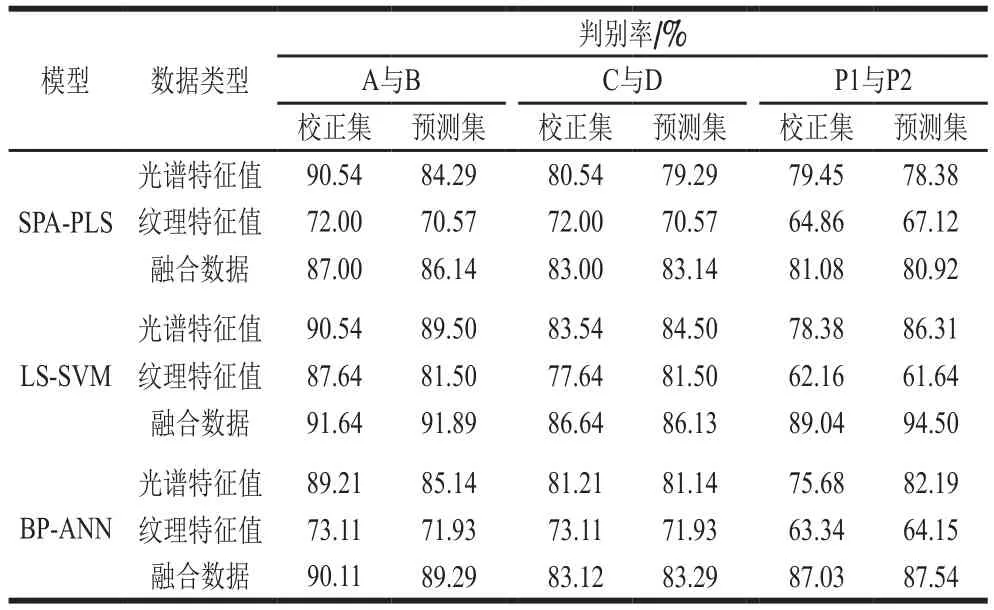
表3 拼配茶樣配比預測結果Table 3 Comparative evaluation of three prediction models based on different input values
2.4 模型的驗證結果
為驗證模型的穩定性,重新拼出30 個樣本進行模型的外部驗證。其中P3茶樣是原料A與原料B配比為3∶7的拼配樣,P4茶樣是原料C與原料D配比為6∶4的拼配樣。通過PLS篩選出90 個變量,導出預測集模型和系數,然后代入計算預測出樣本的配比。由表4建模結果可知,總判別率達到86.7%,發生誤判的樣本分別為第7、26、29、30個茶樣。此結果達到了具有統計學意義的判別率不低于85%的要求。
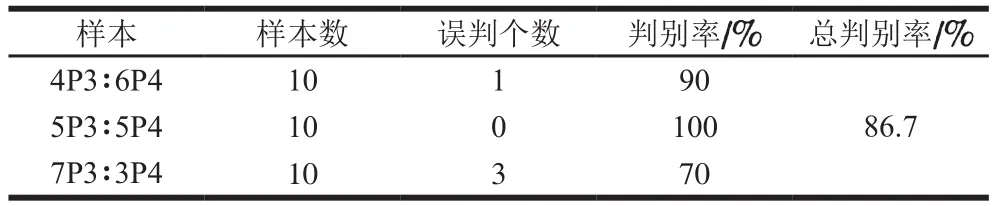
表4 驗證模型判別結果Table 4 Validation of the LS-SVM prediction model
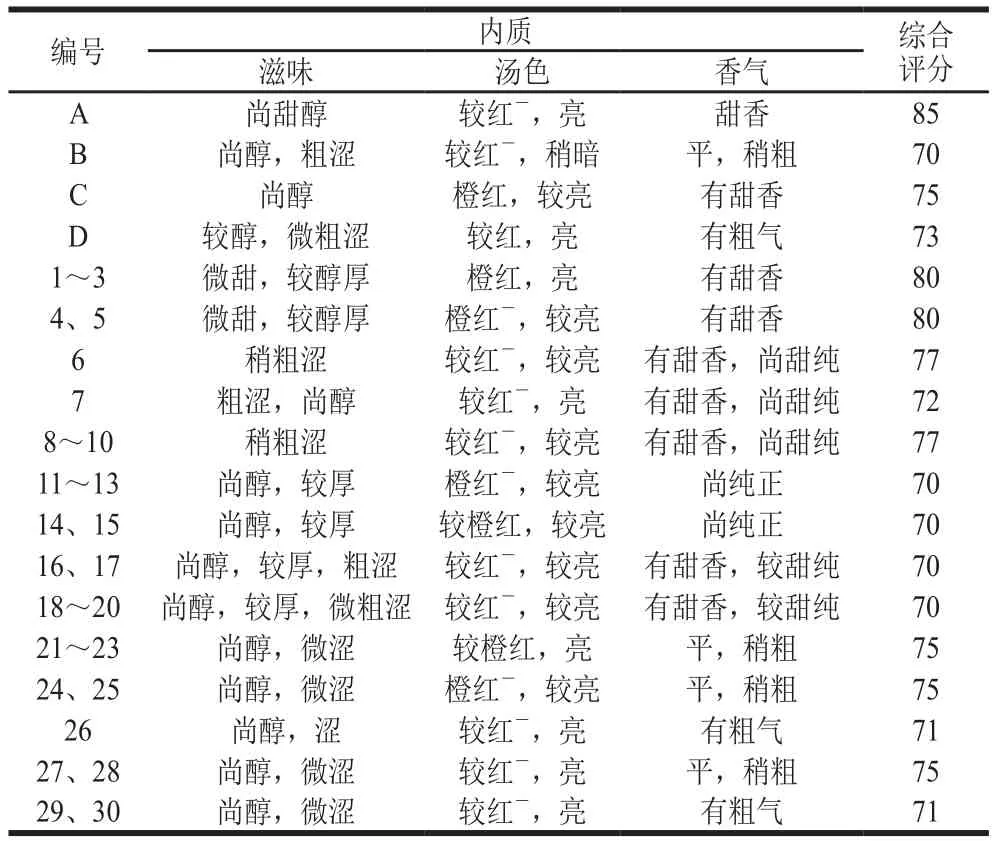
表5 拼配茶樣審評結果Table 5 The result of tea tasting of tea blends
本實驗對以上30 個拼配樣本審評,并將原料茶樣A、B、C和D作為標準樣。由于光譜信息是對內質的反映,所以更偏重于對滋味的評審,并依據GB/T 13738.2—2017《紅茶 第2部分:工夫紅茶》感官品質要求進行評分,結果如表5所示,從審評結果可以看出,編號分別為7、26、29、30的樣本所得分數與組內其他樣本分數相差相對較大,與模型驗證的結果一致。
3 討 論
本研究利用高光譜圖像技術獲取經4 種茶原料按照一定比例拼配出的茶樣的光譜圖像,通過PCA法提取出5 個特征波長,然后進行光譜數據與圖像紋理數據的提取,本實驗嘗試基于光譜信息和圖像信息融合技術結合模式識別,預測拼配茶葉的配比。結果顯示,融合光譜和紋理特征值結合LS-SVM模型算法,建立拼配茶葉配比預測模型,判別率最高,達到94.5%,預測結果較好。用模型以外的隨機30 個樣本進行對模型進行驗證,結果其中有4 個樣本發生誤判,總判別率為86.7%,因采用的原料在品質上接近,對結果有一定的影響。
目前,拼配茶葉的配比通過高光譜圖像技術結合數學模型可以相對準確地預測出,但是,實際生產中,茶葉拼配原料需要很多種,比較復雜,需要大量的數據對模型進行進一步的訓練和優化,從而求解標準茶樣中各原料的比例。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
