融合前景先驗和背景先驗的顯著性目標檢測
2019-03-12 12:27:58楊慧婷
現代計算機 2019年5期
楊慧婷
(四川大學計算機學院,成都 610065)
0 引言
顯著性檢測是識別一幅場景中最重要和最有價值的部分。它可以被應用到許多計算機視覺應用當中,例如圖像檢索、圖像壓縮、內容感知的圖像編輯以及目標檢測。顯著性檢測模型大體上被劃分為自下而上的模型和自上而下的兩種模型。自下而上的模型是基于數據驅動的,不需要對其進行訓練,而自上而下的模型則是任務驅動的,且要使用帶有注釋的數據進行訓練。顯著性模型隨著時間的推進劃分為了視覺注意預測模型和顯著性目標檢測模型。不同于視覺注意預測模型在自然圖像上識別出少量的人類視覺注意點的目的,顯著性目標檢測主要是要凸現出具有明確邊界的目標區域,這對于后續高層次的視覺任務是大有脾益的。本文主要依據自下而上的顯著性目標檢測模型。
近年來,基于前景先驗的顯著性目標檢測已經取得了比較好的檢測效果。在衡量顯著性前景因素時,對比度是最為重要的一個因素。還有一些研究是通過提取圖像中的一些稀有特征來進行顯著性檢測。由格式塔心理圖形-背景分配原則可知,情景線索在視覺注意點預測有比較優良的表現,但僅僅依賴于此卻很難凸顯出整個顯著目標。顯著性目標檢測的另外一種有效的方式是利用圖像中的背景先驗信息,從而有效地突出顯著性目標。假定圖形的邊界為背景,以此有效地提取背景先驗信息,從而利用背景先驗信息來計算顯著圖,這種算法也存在缺陷,因為圖像邊界并不總是背景信息,當顯著性目標主體碰觸到圖像邊界時會出現算法失效的情況。綜上,本文提出了融合前景先驗和背景先驗的框架,本框架可以有效使用前景信息和背景信息來進行顯著性檢測。本文提出了一種全新的自下而上的顯著性目標檢測模型。首先利用情景線索挖掘前景先驗信息,使用此前景信息對前景種子定位并進行顯著性運算,再從圖像邊界地區提取背景先驗種子點,并進行顯著性運算;然后融合基于前景先驗生成的顯著圖和基于背景先驗生成的顯著圖;最后使用測地線距離對融合的顯著圖進行平滑,減少噪聲,均勻地突出整個顯著區域,從而得到最終顯著圖。
本文有如下幾點創新:①使用情景線索對前景先驗信息進行提取;②建立了一種更加穩定的種子選取方案,此方案對于顯著圖生成的準確性有著有效的效果;③提出了融合前景先驗和背景先驗的顯著性目標檢測框架。
1 本文算法
本文框架主要分為兩個并行的子過程:前景顯著性計算和背景顯著性計算。然后根據提取得到的前景種子點和背景種子點,生成兩幅顯著圖,在將兩幅顯著圖進行融合,然后使用測地線距離對顯著圖進行平滑,生成最終顯著圖。本文算法框架如圖1所示。

圖1 本文算法框架
1.1 基于前景先驗的顯著圖
本節主要介紹如何找到可靠的前景種子點,并依此計算顯著圖。
(1)前景種子點估計
使用情景線索有效提取前景種子點。采用基于二值分割的BMS方法,充分利用圖圖像中的周圍環境因素,從而指導前景種子的局部化。將BMS生成的圖像稱為被包圍狀態圖SB,其中像素值表示為起被包圍度。為了更好地利用結構信息和抽象小噪聲,采用SLIC算法將圖像分解為一組超像素。本文其他的操作也是在超像素上面進行的。每個超像素的被包圍值,是取超像素中的像素值的SB的平均值來定義的,表示為N 是超像素的個數。
與之前的文獻將某些區域設定為確定的種子點的選取方式不同,本文提供了一個更加靈活的種子選取方案。定義了兩種不同的種子:強種子和弱種子。強種子歸屬前景/背景的可能性較大,弱種子歸屬前景/背景的可能性較小。對于前景種子,這兩種種子是通過以下兩個公式來選取的:

C+表示強種子的集合,C-表示弱種子的集合,i表示第i個超像素,mean(?)表示平均函數。從公式(1)(2)可以看出,環境包圍度較高的超像素更加可能被選為前景種子,這跟人類直覺是一致的。
(2)基于前景先驗的顯著圖
利用數據固有流形結構進行圖像標注的排序方法對上述計算出的前景種子點進行顯著值計算。排序方法是對每個超像素和給定種子集之間的相關性進行序。我們構造了一個能表示整個圖像的圖,其中每個節點都是由SLIC計算的超像素塊。
排序過程如下所示:定義一個圖模型G=(V ,E ),V表示圖的結點,E表示邊,其權值由關聯矩陣定義。度矩陣定義為 D=diag{d11,…,d,nn}。
其中dii=∑jwij,排序函數則是如下公式定義:

g*結果向量存儲每個超像素的節點最終的排序結果。y=[ ]y1,y2,…,ynT是種子查詢向量。本文中,兩個節點之間的權值由下列公式定義:

其中,ci和cj表示CIE LAB顏色空間中兩個節點對應的超像素的均值,σ是一個常數,用來控制權值的大小。與之前的研究定義如果i表示種子點強查詢,則yi=1,否則yi=0不同,本文把yi定義為額外查詢強度,也即是說,若是i表示種子點強查詢,則yi=1,i表示種子點弱查詢,則yi=0.5,否則yi=0。基于前景種子的排序,在(1)(2)給定種子集的情況下,所有的超像素都按照公式(4)進行排序。前景先驗的顯著圖如圖2所示。

圖2 基于前景先驗的顯著圖
1.2 基于背景先驗的顯著圖
背景先驗作為前景先驗的補充,主要目的對特征分布中與背景不同的區域進行提取。首先提取背景種子點,然后根據每個圖像元素與這些種子的相關性來計算它們的顯著性。本節主要介紹如何找到可靠的背景種子點,并依此計算顯著圖。
(1)背景種子點估計
與以往不同僅僅把圖像邊界上的元素當成種子點的方式不同,本文把圖像邊界元素劃分為了兩類,強種子點和弱種子點,正如前文前景種子點劃分一樣。將所有邊界元素平均值表示為cˉ。每個特征向量和平均特征向量之間的歐氏距離是由dc=dist(c,cˉ)這個公式計算的,dc的平均值表示為-dc。背景種子點通過下列兩個公式進行評估:
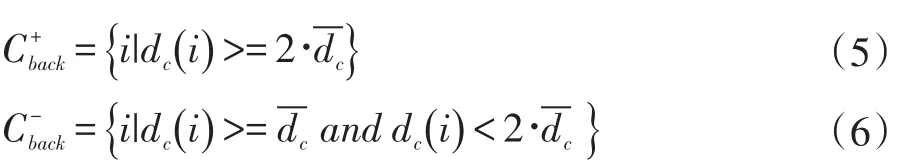
Cb+ack表示背景強種子點,Cback表示背景弱種子點。
(2)背景種子點估計基于背景先驗的顯著圖
與前景先驗計算顯著圖的相同,若是i表示種子點強查詢,則yi=1,i表示種子點弱查詢,則yi=0.5,否則yi=0。利用公式(3)計算各元素和背景種子點的相關性。生成的向量g*中的元素表明節點和背景種子點的相關性,其補集就是顯著性衡量的方式。顯著圖是通過下列公式計算:
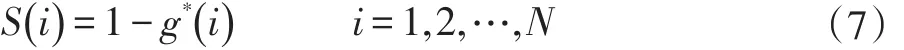
計算基于背景先驗的顯著圖的過程如圖3所示。

圖3 基于背景先驗的顯著圖
1.3 利用測地線距離細化顯著圖
基于前景先驗和基于背景先驗的顯著圖的融合過程如下:大于兩個顯著圖顯著性元素平均值的元素值被重新標定為顯著性元素,然后把這些新的顯著元素集成為一個集合。再把這些新的顯著元素當作種子點,計算圖像節點與新的種子點之間的相關性,生成融合顯著圖Smap。
本文方法的最后一步時是測地線距離對融合之后的顯著圖進行細化。為何采用測地線距離是基于觀察得來,即把一個像素的顯著值確定為周圍像素顯著值的加權和,其中權值與歐幾里得分布相對應,在均勻突出顯著目標方面有著比較好的性能。從最近的研究來看,權值可能對測地線距離比較敏感,這就為均與地增強突出顯著區域的目的帶來很大的可能性。
對于第 j個超像素,把它的后驗概率表示為Scom(j)。利用測地線距離重新細化第q個超像素的顯著值的公式如下:

其中N表示圖像中超像素的總數,δqj是基于第q個和第 j個超像素由測地線距離衡量的權值。根據本文1.1(2)構造的圖模型可知,兩個超像素之間的測地線距離dg(p,i)可以定義為兩個超像素在圖上沿其最短路徑累積的邊緣權值:
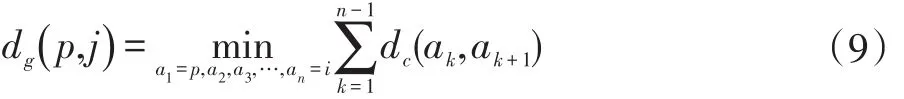
以此,可以得到圖像中任意兩個超像素之間的測地線距離。然后權值δpi被定義為其中σc表示所有dc值的偏差。在此步驟后顯著物體被均勻顯示出來,具體結果可在實驗部分中看到。
2 實驗
本節主要對本文提出的模型進行實驗和評估。
數據集。在ASD數據集和OUT-OMRON數據集上對本文模型進行測試。ASD數據集提供了1000個帶有注解的基于對象輪廓的顯著性期望預測結果集,OUT-OMRON數據集提供了提供更為負責的5168個帶有像素級注解的顯著性期望預期結果集。
評價指標。為了精確評估,采用了四個評價指標:PR 曲線、F-measure、平均絕對誤差(MAE)、AUC 分數。圖5為PR曲線,自適應閾值的精度、召回率和F測度值,自適應閾值定義為圖像平均顯著性的兩倍。表1和表2顯示了兩個數據集上的MAE和AUC得分。
對比。將本文提出模型與最先進的11的模型相比較,這些模型分別是 CAS、wCtr、FT、DFRI、GBVS、IT?TI、MILPS、MR、PCA、SBD、BMS。如圖 4 可見,結果表明,本方法能更均勻地突出顯著區域,特別在PR曲線和MAE分數這兩個評價指標上取得了較好的效果。大體來說,此方法還是要優于其他方法。

圖4 本文顯著性模型和其他顯著性模型的比較
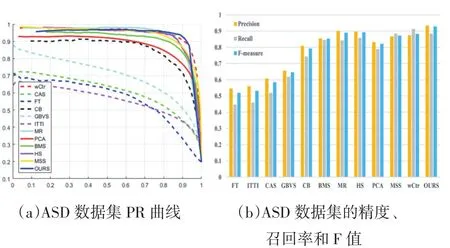

圖5

表1 ASD數據集上MAE和AUC的比較

表2 DUT-OMRON數據集上MAE和AUC的比較
3 結語
本文提出了一種基于前景先驗和背景先驗互補的顯著性目標檢測框架,主要創新有下列兩點,首先是利用環境線索對前景先驗信息進行了挖掘,并且結合背景先驗信息,證明了方法的有效性;其次是提出了一種更加穩定的種子選擇方案。在與其他方法的對比上也顯示了,本文提出方法的有效性。
猜你喜歡
汽車工程師(2021年12期)2022-01-17 02:29:54
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
建材發展導向(2021年6期)2021-06-09 05:57:08
現代國際關系(2021年2期)2021-04-13 01:59:16
當代陜西(2020年14期)2021-01-08 09:30:42
中國外匯(2019年11期)2019-08-27 02:06:32
貴州師范學院學報(2016年4期)2016-12-01 03:54:07
太空探索(2016年10期)2016-07-10 12:07:01
