基于卷積神經網絡的藏文手寫數字識別
2019-03-12 08:13:24夏吾吉色差甲扎西吉貢保才讓華卻才讓
現代電子技術 2019年5期
關鍵詞:自動識別
夏吾吉 色差甲 扎西吉 貢保才讓 華卻才讓


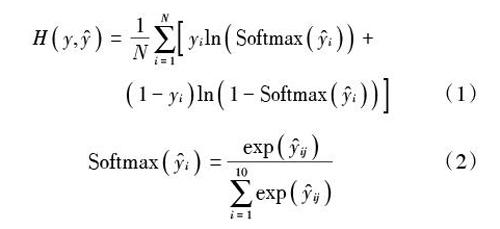
關鍵詞: 藏文手寫數字; 數字識別; CNN; 數據預處理; 樣本訓練; 自動識別
中圖分類號: TN711?34 ? ? ? ? ? ? ? ? ? ? ? 文獻標識碼: A ? ? ? ? ? ? ? ? ? ? ? ? ? ?文章編號: 1004?373X(2019)05?0079?04
Tibetan handwritten numeral recognition based on convolutional neural network
XIA Wuji1, 2, SE Chajia1, ZHAXI Ji1, GONGBAO Cairang1, HUAQUE Cairang1
(1. Key Laboratory of Tibetan Information Processing of Ministry of Education, Qinghai Normal University, Xining 810008, China;
2. Normal College for Nationalities, Qinghai Normal University, Xining 810008, China)
Abstract: The Tibetan information processing technology is potentially needed for Tibetan processing and Tibetan numeral automatic recognition increasingly, and has become one of the important research topics in Tibet. Tibetan handwritten numeral data is collected and constructed, which is 15 000 samples in total, in which 13 000 samples are taken as the training data, and 2 000 samples are taken as the test data and preprocessed. The convolutional neural network (CNN) model is used to train the Tibetan handwritten numeral samples. The experimental results show that the recognition correct rate of test set can reach up to 97.85%.
Keywords: Tibetan handwritten numeral; numeral recognition; convolutional neural network; data preprocessing; sample training; automatic recognition
0 ?引 ?言
藏文作為我國藏族地區、不丹、尼泊爾和其他藏傳佛教傳播地區廣泛使用的語言文字,屬于世界上公認的復雜拼音文字之一[1]。經過1 400多年的演變和發展,藏文形成了嚴格而完整的拼寫規則體系,是由4個元音字母和30個輔音字母從上到下、從左到右疊加而形成的二維結構。
藏文中的數字通常有兩種表達方式[2]:第一種是阿拉伯數字,比如“0,1,2,…,9”;第二種是藏文數字,比如“?、?…?”。其中,阿拉伯數字是全世界公用的數字,其手寫識別是多年來的研究熱點,并且手寫阿拉伯數字技術在各個行業領域得到了廣泛的應用,包括支票數據處理、自動識別郵政編碼、稅務智能系統和商貿往來等。經過數十年的研究和發展,研究者提出了很多有效的手寫阿拉伯數字識別方法[3?9],并得到了較好的效果。以計算機科學技術為核心的網絡信息化時代,隨著藏區的網絡信息化和藏文信息量的急劇增長,對藏文字處理和藏文數字識別等藏文信息處理技術的潛在需求也越來越高,目前已經成為藏區重要的研究課題之一。同樣藏文手寫數字也廣泛應用于藏文信息化的各個行業領域,比如,藏文郵政編碼系統和藏文支票數據處理等,這些應用場合對藏文手寫數字識別的精確度有很高的要求,并且其識別直接關系到藏區經濟、藏區信息化建設和民族交流等問題。由于不同手寫者和手寫數字的隨意性,會加大識別的難度,導致影響識別效果。因此,藏文手寫數字識別問題是藏文信息處理和藏區信息化建設等領域的關鍵問題。目前,在信息界的相關研究者未對藏文手寫數字自動識別進行研究和討論。因此,本文將手寫阿拉伯數字識別研究作為參考,采用卷積神經網絡(CNN)模型對藏文手寫數字識別進行研究。
1 ?數據采集與預處理
手寫數據樣本采集和構建是數字識別中最重要的工作之一,為此,隨機選擇了50位懂藏文的人,采集每個人“?”至“?”的藏文手寫數字樣本,每個人將每一個藏文數字均手寫30次,共得到15 000個樣本。由于不同樣本圖像的字體、字號和所在區域是有差別的,所以為了確保數字圖像輸入到卷積神經網絡的形式具有一致性,對所有樣本數據做了如下預處理:
1) 繪制像素為2 480×3 508、行數為15、列數為10的表格,共有150個格子,為便于圖像的切割處理,每個格子的像素固定為200×200。然后用A4紙張打印,每人均手寫兩張(300個樣本),50人共得到15 000個樣本。
2) 將所有樣本用掃描儀進行掃描,得到藏文手寫數字圖像。
3) 將得到的每張藏文手寫數字圖像,通過像素計算切割成像素為200×200的150個小圖片。
4) 將得到的藏文數字圖像用最大類間方差法(OTSU)進行二值化,獲得藏文手寫數字二值化圖像,在二值化過程中,把藏文數字圖像各像素點的值由(0,255)灰度圖像處理成二值(0,1)。
5) 為了便于后續識別,將所有的樣本歸一化為相同的像素點陣圖,本文選擇的形式為28×28。
數據處理見圖1。
2 ?模型及框架
2.1 ?模 ?型
卷積神經網絡(Convolutional Neural Network,CNN)通過局部感受野、下采樣和權值共享三個特性來實現位移識別、縮放和扭曲等不變性[10]。設計一個CNN時,單層CNN由卷積層(Convolutional)、下采樣層(Pooling)、Relu(Rectified Linear Units)層、全連接層等四個層構成。其中,卷積是圖像識別中一種常用算法,通過卷積運算可以使樣本信息的特征增強,并降低噪聲數據[11]。同一個特征圖片中的所有神經元都用一個卷積核來共享,其卷積核被認為是訓練參數或者權重。用卷積核計算得出的值可以代表一個特征,從圖片中局部感受野能夠發現一些局部特征。一般卷積核的大小、數目以及滑動步長等設置不同將會影響局部的特征學習效果。下采樣也稱之為二次采樣(Subsampling),使用圖片局部信息的相關性對圖片進行子抽樣,其目的就是降低數據的計算量,同時存留特征明顯的信息。在CNN中這種操作稱為池化(Pooling)操作,常見的有最大池化(Max Pooling)和平均池化(Mean Pooling)。池化層具有將特征進行聚合和防止模型過擬合等作用。Relu是一個常見的激活函數,其具有卷積層提取特征進行非線性轉換的作用。目前其他常見的激活函數還有Sigmoid,Softmax,tanh等。Relu在訓練梯度下降時可獲得更快的收斂速度[12],這也是CNN中使用Relu的原因之一。全連接層使用卷積層和池化層等多層學習后將結果映射到一個固定大小的向量,為了處理后續待解決的任務(比如分類任務等),一般在全連接層中也會使用激活函數,針對解決問題的不同,使用的激活函數也不同,比如多類分類時使用Softmax函數,而二類分類時一般使用Sigmoid函數。
圖2中每個卷積操作和池化操作過程中使用的[Wi(i=1,2,3)]和[Mj(j=1,2,4)]都是固定的權重以及固定的窗口,其窗口大小與輸入的大小和窗口移動步長等有關。同時,在模型訓練過程中,必須確定一個目標函數和參數更新方法。其中,常見的目標函數有交叉熵、互信息和對比估計噪聲法(Noise?Contrastive Estimation,NCE)[13]等,本實驗中目標函數將使用交叉熵(Cross Entropy With Softmax)。由于藏文數字識別是多類問題,所以目標函數中應用Softmax函數。其公式如下:
[Hy,y=1Ni=1NyilnSoftmaxyi+1-yiln1-Softmaxyi] (1)
[Softmaxyi=expyiji=110expyij] (2)
式中:[Hy,y]為目標函數,即用交叉熵計算損失函數;[yi]是第[i]個數據的真實標簽;[yi]是第[i]個數據模型得出的標簽;[N]是訓練樣本個數;[yij]是第[i]個樣本向量的第[j]個位置上的值。參數更新法主要用于梯度下降法,而常見的梯度下降法有隨機梯度下降法(Stochastic Gradient Descent,SGD)、批量梯度下降法(Batch Gradient Descent,BGD)和自適應矩估計法(Adaptive Moment Estimation,Adam)等。本文使用Adam法,其主要優點有動態調整學習率,對偏值進行校對后,每次迭代時學習率控制在一定的范圍內,使得參數比較平穩。
2.2 ?基本框架
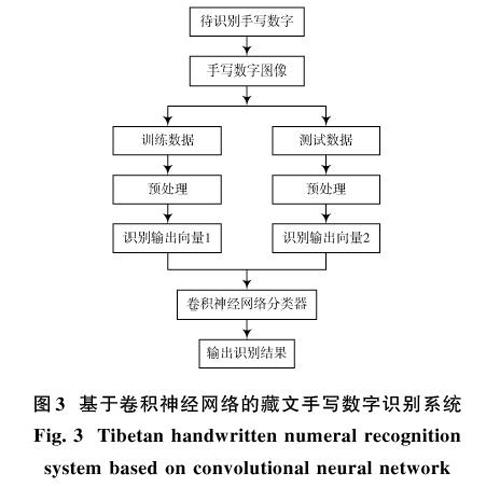
基于卷積神經網絡的藏文手寫數字識別系統主要利用三層卷積層、三層池化層以及一層全連接層的卷積神經網絡,在手寫數字識別領域有良好的識別性能。整個識別系統包括從采集手寫圖像到得出識別結果的過程。具體框架如圖3所示。
3 ?實 ?驗
實驗采用藏文手寫數字共15 000個樣本,訓練集規模為13 000個樣本,測試集規模為2 000個樣本。為了客觀評價本文所提基于卷積神經網絡模型藏文手寫數字識別方法的有效性,通過正確率指標對藏文手寫數字識別的結果進行評價。經測試,十種藏文手寫數字的平均自動識別準確率達到97.85%,“?”至“?”每一種藏文手寫數字具體識別結果如表1所示。
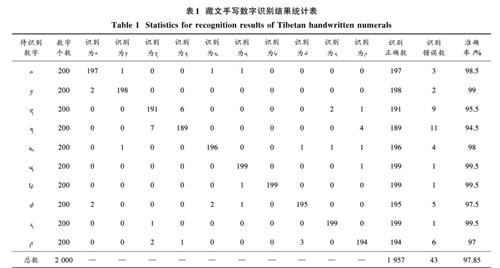
通過實驗結果得出,由于50個人的書寫方式不同,寫出的藏文數字也各不相同。因此,本文對每一個數字進行了分析,分析數字的范圍是“?” 到“?”這十類數據,每類提取200個,每個數字與其他數字進行對比分析后得出數字“?”,“ ?”和“ ?”的識別率最高均為99.5%,錯誤數僅為1;數字“?”和“?”的識別率相對較低,分別為95.5%和94.5%。由表1可知,“?”和“?”相互出錯率最高,原因是在藏文數字中“?”和“?”的字形相近,且手寫時由于手寫者和手寫數字隨意性的不同,導致“?”和“?”容易混淆,加大了識別難度。其余數字因手寫時超出規定表格,切分時將數字圖像的一些細節信息丟失,從而導致少數識別錯誤。
4 ?結 ?語
隨著深度學習理論和技術在各個研究領域中獲得突破性成績,在圖像識別和理解領域,深度學習同樣取得了不錯的效果,其識別正確率甚至超過了人工的識別結果,然而藏文手寫識別的研究工作相對空缺。為此,本文初步完成了基于神經網絡的藏文手寫數字識別工作,在構建的數據樣本集上取得了97.85%的平均正確率。
由于藏文手寫數字樣本數據較為匱乏,加之采集到的數據中手寫字體的格式(粗細、大小)、手寫方式等存在差異,導致實驗結果相對于阿拉伯手寫數字的識別準確率較低。在后續的工作中,將繼續擴大手寫數據規模,提高準確率,并在此基礎上嘗試藏文手寫字符的識別工作。
注:本文通訊作者為華卻才讓。
參考文獻
[1] 華卻才讓.基于樹到串藏語機器翻譯若干關鍵技術研究[D].西安:陜西師范大學,2014.
HUAQUE Cairang. Research on some key techniques of Tibet machine translation based on tree to string [D]. Xian: Shaanxi Normal University, 2014.
[2] 孫萌,華卻才讓,劉凱,等.藏文數詞識別與翻譯[J].北京大學學報(自然科學版),2013,49(1):75?80.
SUN Meng, HUAQUE Cairang, LIU Kai, et al. Tibetan number identification and translation [J]. Journal of Peking University (natural science edition), 2013, 49(1): 75?80.
[3] 李文趨.SVM在手寫數字識別中的應用[J].泉州師范學院學報(自然科學),2010,28(4):18?21.
LI Wenqu. Application of SVM in handwritten numeral recognition [J]. Journal of Quanzhou Normal University (natural science), 2010, 28(4): 18?21.
[4] 張黎,劉爭鳴,唐軍.基于BP神經網絡的手寫數字識別方法的實現[J].自動化與儀器儀表,2015(6):169?170.
ZHANG Li, LIU Zhengming, TANG Jun. Realization of handwritten numeral recognition based on BP neural network [J]. Automation and instrumentation, 2015(6): 169?170.
[5] 焦微微,巴力登,閆斌.手寫數字識別方法研究[J].軟件導刊,2012,11(12):172?174.
JIAO Weiwei, BA Lideng, YAN Bin. Handwritten digital re?cognition method [J]. Software guide, 2012, 11(12): 172?174.
[6] 杜梅,趙懷慈.手寫數字識別的研究[J].計算機工程與設計,2010,31(15):3464?3467.
DU Mei, ZHAO Huaici. Research on handwritten digit character recognition [J]. Computer engineering and design, 2010, 31(15): 3464?3467.
[7] 付慶玲,韓力群.基于人工神經網絡的手寫數字識別[J].北京工商大學學報(自然科學版),2004,22(3):43?45.
FU Qingling, HAN Liqun. Recognition for handwritten numbers based on Artificial neuron network [J]. Journal of Beijing Technology and Business University (natural science edition), 2004, 22(3): 43?45.
[8] 劉東澤,蔡建立.基于神經網絡的手寫數字識別[J].福建電腦,2009(11):83?84.
LIU Dongze, CAI Jianli. Handwritten numeral recognition based on neural network [J]. Fujian computer, 2009(11): 83?84.
[9] 王璇,薛瑞.基于BP神經網絡的手寫數字識別的算法[J].自動化技術與應用,2014,33(5):5?10.
WANG Xuan, XUE Rui. The algorithm of handwritten digit recognition based on BP neural network [J]. Automation technology and applications, 2014, 33(5): 5?10.
[10] 高學,王有旺.基于CNN和隨機彈性形變的相似手寫漢字識別[J].華南理工大學學報(自然科學版),2012,32(5):538?544.
GAO Xue, WANG Youwang. Recognition of similar handwritten Chinese characters based on CNN and random elastic deformation [J]. Journal of South China University of Technology (natural science edition), 2012, 32(5): 538?544.
[11] 匡青.基于卷積神經網絡的商品圖像分類研究[J].軟件導刊,2017,16(2):178?182.
KUANG Qing. Commodity image classification based on convolutional neural network [J]. Software guide, 2017, 16(2): 178?182.
[12] NAIR V, HINTON G E. Rectified linear units improve restricted boltzmann machines [C]// Proceedings of the 27th International Conference on Machine Learning. Haifa: ACM, 2010: 807?814.
[13] MNIH A, KAVUKCUOGLU K. Learning word embeddings efficiently with noise?contrastive estimation [C]// Proceedings of the 26th International Conference on Neural Information Proces?sing Systems. Lake Tahoe: ACM, 2013: 2265?2273.
猜你喜歡
中國自動識別技術(2023年6期)2024-01-12 08:13:22
艦船科學技術(2022年22期)2022-12-13 03:39:42
艦船科學技術(2022年10期)2022-06-17 06:27:48
空間科學學報(2020年3期)2020-07-24 09:23:02
中國交通信息化(2019年7期)2019-10-08 09:04:40
水上消防(2019年3期)2019-08-20 05:46:08
西南交通大學學報(2018年6期)2018-12-18 02:23:20
特別健康(2018年3期)2018-07-04 00:40:18
發明與創新(2016年26期)2016-08-22 03:23:28
電測與儀表(2016年6期)2016-04-11 12:06:38
