基于學習者求助行為的論壇回答者推薦研究
2019-03-13 05:14:32葉俊民趙麗嫻羅達雄王志鋒
小型微型計算機系統 2019年3期
關鍵詞:模型
葉俊民,趙麗嫻,羅達雄,王志鋒, 陳 曙
1(華中師范大學 計算機學院,武漢 430079) 2(華中師范大學 教育信息技術學院,武漢 430079)
1 引 言
以MOOC為代表的在線學習社區應用的普及,為在線學習者提供了越來越多的學習資源和學習機會,同時他們在學習過程中也會產生各種各樣的問題,這時如何有效地為這些學習者及時解決這些問題,就是一個值得研究的課題.依據在線學習者的行為來推薦問題回答者則是解決該問題的一種有效途徑.為此,本文提出了基于學習者行為的論壇問題回答者推薦算法.
國內外相關研究現狀如下:Bhat 等人[1]揭示了Stack overflow學習社區中問題得以解決的時長現象,即大部分問題在一小時內得到解答,但有30%左右的問題回答要在一天之后才能完成,還有許多問題的回答時間超過一天;Greer 等人[2-4]研究了典型問答社區中成功為少數學習者及時推薦問題解答的回答者特征,這些人員通常在多個不同領域有著豐富的知識及興趣;Tian[5]使用主題模型方法來預測最合適的問題回答者;Xia等人[6-8]從靜態特征挖掘角度,分析了開發者和主題之間關聯,以實現為特定主題推薦開發者;Mao[9]通過GitHub上開發者對特定技術術語的使用頻度,分析了問答社區上標簽和技術術語之間的關聯關系,為Stack Overflow實現了問答專家推薦.Tian[10]分析了Stack Overflow上開發者的歷史數據,通過LDA主題模型分析,發現了開發者潛在興趣,并基于這些興趣和協作投票機制來推薦問題回答專家;Shola O M[11]等人基于個性化標簽預測高質量的問題解決者;Elalfy D[12]等人使用問題的內容和內容特征訓練機器學習模型直接得到推薦的問題答案.由上述研究現狀,本文認為學習者在論壇提問行為屬于求助行為,而發現問題的解決速度會影響學習者對論壇的使用頻度,同時依據學習者的求助行為進行論壇回答者推薦有待進一步研究.
本研究研究意義表現在:
1)心理學研究者認為[13],好的求助體驗將給學習者帶來信心和鼓舞,而不良的求助體驗將最終使得學習者放棄在線學習,同時快速并恰當的為學習者推薦具有合適在線學習求助行為的回答者,幫助其解決論壇問題,可提高學習者的求助體驗;
2)可促進對學習者在線學習行為認知研究,以更好地設計出滿足學習者要求的各種個性化服務;
3)本研究有助于在線學習環境設計者改進設計并使得在線學習環境產生更大的社會價值.
2 研究框架
本研究由兩步組成:第一步,識別學習者求助行為類別,以獲得學習者的求助行為類別;第二步,訓練論壇回答者推薦模型,將具有合適學習者求助行為類別的并與論壇問題匹配度高的論壇回答者推薦給需要幫助的學習者.
2.1 自動識別學習者求助行為類別
所謂基于學習者求助行為的論壇問題回答者推薦,是根據給定的在線學習環境中的學習者在線學習行為數據(問題輸入),獲得該學習者的求助行為類別,并根據其類別為其推薦合適的論壇問題回答者(問題輸出).
為了自動識別學習者求助行為類別,本文采用了聚類和分類相結合的方法,以識別出學習者求助行為類別,并依據學習者的求助行為類別為其推薦合適的論壇回答者.為此,首先采用Bik-Means算法對在線學習環境中的在線學習求助行為數據進行聚類分析,獲得學習者求助行為類別標簽;然后,使用部分學習者求助行為數據及其類別標簽訓練樸素貝葉斯分類器,并利用剩余的學習者求助行為數據來驗證該分類器的準確率,通過使用該分類器達到自動識別學習者求助行為類別的目的.
2.2 論壇回答者推薦的研究框架
所謂在線學習環境下論壇回答者推薦,是根據給定的在線學習環境中的學習者在論壇中發布的問題(問題輸入),對該在線學習環境中的學習者輸出最善于回答該問題的回答者(問題輸出).
識別學習者求助行為類別的研究是基于Linda Corrin相關工作[14]開展.本文抽取了學習者行為數據的部分屬性表達學習者的求助行為.通過對該學習者求助行為數據采用聚類算法處理,可得到該學習者求助行為類別標簽,用此學習者求助行為數據和求助行為類別標簽作為訓練數據來訓練樸素貝葉斯模型,從而可自動識別出新學習者求助行為的類別.在此基礎上,本文可為學習者推薦合適的論壇問題回答者,具體處理流程參見圖1.
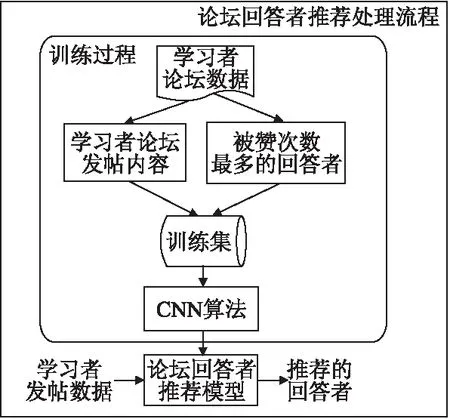
圖1 論壇回答者推薦處理流程Fig.1 Forum respondents recommend process
圖1的相關思路如下[15]:
1)對收集到的論壇文本數據進行Embedding處理,轉換為CNN模型能夠處理的數據集;
2)使用卷積神經網絡算法(CNN)訓練論壇回答者推薦模型,在這個過程中,數據集被分為互不相交的兩個集合,一個用作訓練集,一個用作驗證集,以驗證本模型的推薦有效性;
3)得到論壇回答者推薦模型之后,可根據新學習者未被解答的論壇數據,提取該數據的特征,基于該特征使用本模型為學習者推薦合適的回答者.
3 基于學習者求助行為的論壇回答者推薦
3.1 自動識別學習者求助行為類別
識別學習者求助行為類別算法的流程可以描述如下:
1)根據學習者的論壇行為數據獲取學習者的求助行為特征向量,并使用Bik-Means聚類算法處理求助行為特征向量;
2)根據學習者所屬的類別獲取其類別標簽,與求助行為特征向量一同作為貝葉斯分類算法的訓練集;
3)根據訓練數據集,計算每個求助行為類別出現的概率P(rj);
4)對學習者求助行為特征向量的每個特征屬性計算所有劃分的條件概率;
5)根據待分類項X的特征屬性,對每個求助行為類別計算P(X|rj)P(rj);
6)以具有最大P(X|rj)P(rj)值的類別作為待分類項X所屬類別.1)-2)階段執行聚類算法,3)-6)階段執行分類算法.
自動識別學習者求助行為類別的算法首先對學習者求助行為數據進行聚類分析,獲得K個聚類中心,即得到K個類別.而后依據類別標簽,訓練樸素貝葉斯模型,對待分類學習者進行分類處理.該算法的時間復雜度為O(NK+NV+KV),其中N是學習者求助行為數據集的規模,K是學習者求助行為類別數,V是學習者求助行為數據的特征屬性數.
3.2 推薦論壇回答者
在經過識別學習者求助行為類別之后,根據我們得到的類別結論,對學習者進行論壇回答者推薦,為其推薦具有合適求助行為類別的論壇回答者.
3.2.1 卷積神經網絡的基本結構
論壇回答者推薦的目的根據學習者的發帖內容,為其推薦合適的回答者.我們使用了卷積神經網絡模型達到推薦論壇回答者的目的.一般的卷積神經網絡由以下五個結構[17]組成.
1)輸入層.輸入層是作為全部卷積神經網絡的輸入.在本文中輸入層是學習者論壇文本數據經過Embedding處理之后所得的數據.
2)卷積層.卷積層是用于做特征提取的.在一個卷積層,上一層輸出的特征值被一個可學習的卷積核進行卷積,然后經由一個激勵函數,該卷積層的輸出特征就可以被獲得.卷積層試圖對神經網絡進行更深入的剖析,從而獲得抽象水平更高的數據特征.
3)池化層.降低矩陣的規模依靠池化層實現.對輸入的特征矩陣進行壓縮,一方面使特征矩陣變小,簡化網絡計算復雜度;一方面進行特征壓縮,提取主要特征.
以便于OA學術資源的發現、獲取、利用為出發點,依托目前部分院校圖書館數字資源加工室,對資源進行科學高效、規范統一的組織管理是提高OA學術資源利用效率的有效措施。考慮到軍隊網絡安全的特殊性和軍隊院校圖書館OA學術資源管理實際,筆者從軍網和互聯網兩方面就軍隊院校圖書館OA學術資源的組織展開論述。
4)全連接層.分類任務主要由全連接層完成.在經過卷積層、池化層和激勵函數的作用之后,原始數據已經被映射到隱層特征空間.全連接層就起到將隱層特征空間中的數據表示映射到樣本標記空間的作用.全連接的核心操作就是矩陣向量乘積,本質就是由一個特征空間線性變換到另一個特征空間.在CNN中,全連接(full-connected)通常出現在最后幾層.
5)Softmax層.Softmax函數主要處理多分類問題.經過Softmax層后,可得到樣本屬于不同類別的概率.模型的預測值ypred代表的是概率最大的類,具體如公式(1)及公式(2)所示.P(Y=i|x,W,b)表示在權重矩陣為W偏置向量為b的情況下,輸入向量x是第i類的概率.
ypred=argmaxiP(Y=i|x,W,b)
(1)

(2)
3.2.2 論壇回答者推薦模型
依據文獻[17],本文首先將論壇文本經過Embedding處理,將提問者的問題q轉化成詞向量q={w1,w2,…,wn}.卷積神經網絡的輸入層就是該向量組成的矩陣,例如論壇發帖最大長度為n,每個文字對應的詞向量長度為m,則輸入矩陣的規模為n*m.池化層采用Max-Pooling的方法,之后重復上述卷積和池化的過程,搭建多層網絡.經過特征學習,提取出論壇數據的特征,利用這些特征進行論壇回答者推薦.在經過卷積和池化處理之后,池化層輸出通過全連接的方式連接到一個Softmax分類層并且本文使用Adam optimizer優化器來加速神經網絡.除此之外,為了防止訓練過程中過擬合現象的發生看,本文使用了Dropout策略.依此設計的論壇回答者推薦方法所用的訓練模型如圖2所示.
本模型使用 ReLU( Rectified Linear Units)函數作為神經元的激勵函數,使用該激勵函數可以加快訓練速度,有效的減少計算開銷.在訓練結束之后,采用了saver函數來保存最優損失參數,從而根據學習者的發帖內容為其推薦合適的回答者,達到一次訓練多次使用的目的.本文根據回答者歷來回答過的問題數據,對回答者進行向量表示,即將其表示為形如
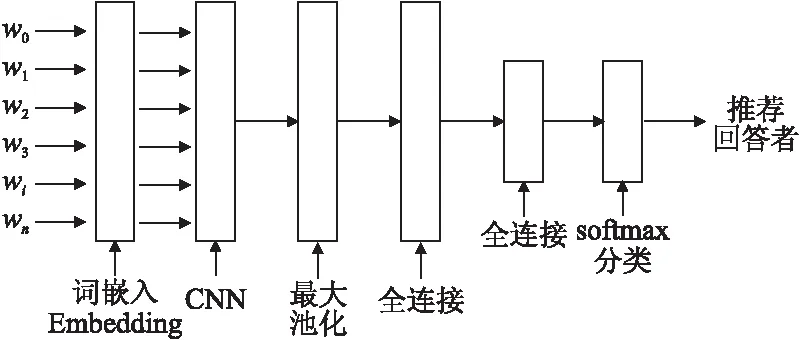
圖2 論壇回答者推薦CNN訓練模型Fig.2 CNN training model for forum respondents recommend
算法1.論壇回答者推薦算法
輸入:學習者論壇文本數據X;待解決論壇發帖d;學習者類別數據C.
輸出:被推薦的回答者u.
1.V←buildvocab(X) /*構建詞匯表,將文本數據X中的詞匯提取出來*/
2.C←readrecommendation () /*將以往回答者用向量表示*/
3.W←readvocab(V) /*讀取上述得到的詞匯表,將詞匯用向量表示*/
4.X,Y←professfile(C,W) /*將每一條文本數據都轉換成固定長度的向量*/
5.Repeat/*運行CNN算法*/
6. loss,acc←run(cnnmodel.loss,cnnmodel.acc)
7. run(adam optimizer)
8. until acc==1||大于指定迭代次數
9. saver(cnnmodel) /*保存最優CNN模型*/
10. data←word_to_id(d) /*將待解決論壇發帖內容d轉換為向量表示*/
11. u← run(self.cnnmodel,data) /*運行最優CNN模型,得到最優推薦回答者*/
12. if u not in c[0]/*若最優推薦回答者求助行為類別不適合,在具有合適求助行為的學習者中獲取匹配度最高的回答者*/
13. u0← run(self.cnnmodel based on c[0],data)
14. return u and u0/*返回被推薦的回答者*/
15. End
圖3 論壇回答者推薦算法
Fig.3 Forum replier recommendation algorithm
4 實證分析
4.1 自動識別學習者求助行為類別實證分析
4.1.1 實驗對象與設計
學習者求助行為的主要表現場景為:
1)學習者遇到問題時,可以在論壇中搜索相關問題或者發布帖子,以此獲取問題答案;
2)在學習者遇到感興趣的帖子時,還可以在論壇中回帖,并通過討論來解決問題;
3)學習者還可以通過多次參加測驗,由測驗的反饋來獲得問題的解答等.
為了驗證識別學習者求助行為類別方法的有效性,本文選用了《馬克思主義基本原理》在線課程中的數據進行實驗,在某次課程教學活動中,學習者人數為342.我們從學習者在線學習行為數據中抽取了6個特征表征學習者的求助行為,包括學習者的發帖數量、學習者的回帖數量、學習者發帖被瀏覽次數、學習者發帖被回復次數、作業提交次數以及學習者成績.
4.1.2 實驗結果
1)聚類高維原始學習者求助行為數據 根據識別到的6維學習者求助行為數據,對其進行BiK-Means聚類處理,得到了四種類別標簽.分析這四種類別里面的學習者求助行為數據,本文將這四類類別定義為很少參與課程活動、主動參與課程活動、被動參與課程活動、專注于課程測驗.
2)自動識別學習者求助行為類別 經過第一步處理,我們得到了學習者求助行為類別標簽.我們將學習者求助行為數據及其類別標簽分為互不相交的兩個集合:訓練集和驗證集.訓練集中數據用于訓練樸素貝葉斯分類模型,而后使用驗證集中數據測試該分類模型的準確率.測試結果用五元組

表1 部分測試結果Table 1 Part of the test results
4.2 論壇回答者推薦實證分析
經過識別學習者求助行為類別,我們得到學習者的四種求助類別,研究發現這四種類別的主要區別在于論壇發帖量的不同,并且論壇發帖量和學習者績效有正相關性,即越主動參與論壇活動的學習者越容易獲得更好的學習績效.因此,為了提高學習者解決問題的效率,使其對求助結果更為滿意,從而促進其更加主動的參與課程活動,需進行論壇回答者推薦.
4.2.1 實驗對象與設計
針對該在線課程中的論壇數據,首先獲取學習者的發帖內容;其次,獲取該貼中被贊次數最多的回答者信息.實際中我們共獲取了850 條實驗數據.本文的論文數據分為最佳回答者和回答者歷來回答過的問題兩個部分.
由4.1節的研究可知,主動參與課程活動的學習者參與論壇發帖,回帖的可能性更大,并且普遍具有更高的學習績效.因此,為了保證學習者求助的有效性和求助結果的可靠性,若得到的被推薦回答者不屬于主動參與課程活動的學習者,可在主動參與課程活動的學習者中為其匹配到最適合回答該問題的回答者,而后將以上得到的兩位被推薦的回答者推薦給該需要幫助的學習者.
4.2.2 實驗操作
本部分所做研究主要是基于Tensorflow庫[19],該庫中包含了基本的深度學習算法,包括卷積神經網絡CNN和循環神經網絡RNN等.此外,還需要用到數組處理numpy庫、機器學習算法庫sklearn以及用于繪制圖像的Matplotlib庫等內容.
首先將論壇文本數據進行一次劃分,將其分為訓練集、驗證集和測試集,根據訓練集可得到論壇回答者推薦模型:具體而言,本文中得到的詞向量維度為64,最大序列長度為600,調用Tensorflow庫中的CNN算法,設置CNN模型中的dropout參數為0.5,學習率為0.001.在訓練集的準確率達到100%、驗證集正確率長期不提升或者迭代次數超過1000次的情況下結束訓練,而后保存最佳推薦模型,繪制出誤差和準確率的變化情況.在進行模型有效性測試時,直接讀取該最佳推薦模型數據,避免重復計算.通過檢驗測試集的準確率、召回率、F1-score以及混淆矩陣來驗證該推薦模型的有效性.最后,我們使用上述最佳論壇回答者推薦模型,為學習者推薦論壇問題回答者.準確率P、召回率R和F1-score三個指標[20]相關的計算如公式(3)-公式(5)所示.
(3)
(4)
(5)
4.2.3 實驗結果
1)訓練并驗證論壇回答者推薦模型表2表示論壇回答者推薦模型的訓練及驗證情況,由表2可以看出,本次訓練經過300次迭代終止,此時訓練集的準確率達到100%,訓練集誤差為0.044,誤差很小.驗證集準確率達到了90%,驗證集誤差為0.32.訓練過程中訓練集的準確率以及誤差變化分別如圖4和圖5所示.

表2 訓練并驗證論壇回答者推薦模型準確率情況Table 2 Training and verifying the accuracy of forum respondents′ recommendation models


圖4 訓練集的準確率變化Fig.4 Accuracy variation in Training set圖5 訓練集的誤差變化Fig.5 Error variation in training set
2)測試論壇回答者推薦模型在測試論壇回答者推薦模型時,抽取了250條數據,其中合適的問題回答者共有5人.在訓練回答者推薦模型之后,采用了saver函數保存最優損失參數,在測試回答者推薦模型時,可不必再次訓練回答者推薦模型.測試回答者推薦模型的有效性如表3所示.根據表3,可知論壇回答者推薦模型的平均準確率達到了90%,準確率最低的D同學也達到了77%.召回率均在75%以上,F1-score均值達到了90%,其中F1-score最低的E同學也達到了81%.因此本回答者推薦模型具有較好的推薦效果,并由圖6所示的混淆矩陣(Confusion Matrix)也可以看出每位回答者的推薦準確性普遍較高,這是因為混淆矩陣中的主對角線上的數字越大,推薦的準確性就越高.例如,矩陣中第一行數據代表A同學,在其50條測試數據中,48條數據被正確分析.因此,本方法用于推薦論壇問題回答者是有效的.
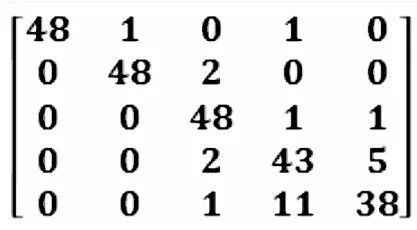
圖6 混淆矩陣Fig.6 Confusion Matrix
3)推薦論壇問題回答者在得到準確率較高的論壇回答者推薦模型之后,使用該模型針對學習者新發布的帖子,推薦合適的回答者.例如,本實驗中使用了一個學習者新發布的論壇問題:“絕對真理和相對真理的關系”.使用論壇回答者推薦模型之后,所得到的推薦回答者如圖7所示.

圖7 問題的推薦回答者實例Fig.7 An example of recommending responder
分析E同學的求助行為類別,我們發現其屬于被動參與課程活動者,不屬于主動參與者.因此推薦模型同時推薦了C同學,該同學在具有較高匹配度的同時,具有主動參與課程活動的特征.分析C、E這兩位回答者歷來回答的論壇發帖情況,我們得出該推薦確實有效的結論.同時這也證明了使用卷積神經網絡(CNN)算法推薦論壇回答者的有效性.
5 相關工作對比
與文獻[19]開展的研究相比,本文與該工作相同之處是:
1)在推薦研究問題中使用了深度學習;
2)采用了卷積神經網絡CNN算法構建推薦模型.
與該文工作不同之處是:
1)本文做了識別學習者求助行為類別的研究.本文在推薦論壇回答者的同時,除了推薦與問題具有最高匹配度的回答者,還會在主動參與課程活動的學習者中推薦一位具有最高問題匹配度的回答者;
2)優化算法不同.該文獻采用了SGD(Stochastic Gradient Descent,隨機梯度下降)[21]算法加速神經網絡,調節其學習速度.在本文中采用了Adam Optimizer優化器,該優化器在一般情況下能夠使神經網絡更快速地完成學習.
6 結束語
通過分析在線學習課程中的學習者在線學習行為數據,發現了學習者求助行為的幾種不同的類別;研究了能夠為學習者推薦合適的論壇問題回答者的方法,在推薦過程中,本文不僅考慮到了問題匹配度問題,還考慮到了被推薦回答者的求助行為類別情況,以使得學習者獲得幫助更加便捷,求助結果更為有效.進一步的研究是根據學習者求助行為類別,結合學習者行為模型和領域知識模型等構建更有針對性的推薦模型,從而能夠更有效的使用教學資源,最終共同達到提高學習者學習績效的目的.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
