基于SA-SVM的中文文本分類研究
2019-04-01 09:28:20郭超磊陳軍華
計算機應用與軟件 2019年3期
郭超磊 陳軍華
(上海師范大學信息與機電工程學院 上海 201400)
0 引 言
文本分類,就是利用計算機相關技術將具有相同特征的文本信息根據文本內容自動劃分到預先設定好的文本類別體系中的過程[1]。眾多學者在研究文本分類的過程中,提供了許多優秀的分類算法,鐘將等[2]提出一種改進的KNN文本分類算法,介紹KNN文本分類算法,并基于LSA降維和樣本密度對KNN進行改進;Shathi等[3]將貝葉斯算法應用于文本分類中;Bahassine等[4]使用決策樹算法對文本進行分類;Goudjil等[5]采用SVM算法對文本分類進行技術研究。經過大量實驗表明,在中文文本分類上,SVM具有較強的泛化能力。基于SVM的文本分類性能與其懲罰因子C和核函數參數σ等密切相關,直接影響文本分類精度[6-7]。
選擇SVM的參數是一個優化問題,近年來,國內外學者提出了很多優化SVM參數的方法。莊嚴等[8]提出了基于蟻群優化算法(ACO)的支持向量機選取參數算法;陳晉音等[9]提出了基于粒子群算法(PSO)的支持向量機的參數優化;王克奇等[10]采用遺傳算法(GA)優化支持向量機參數。ACO算法的收斂速度較慢易陷入局部最優,PSO算法易早熟收斂且局部尋優能力較差,GA算法實現比較復雜,需先對問題進行編碼,然后再對最優解進行解碼,搜索速度較慢。模擬退火算法(SA)也是一種啟發式算法[11],能較強地跳出局部最優,提高全局尋優能力。
本文提出一種基于模擬退火算法優化SVM參數的方法,并應用于中文文本分類中。利用SA良好的尋優性能構建的SVM中文文本分類器,與樸素貝葉斯、KNN算法、決策樹算法、邏輯回歸算法構建的分類器相比,該分類器能達到更好的分類效果,具有更強的魯棒性。
1 相關理論
1.1 模擬退火算法
模擬退火算法[12]來源于材料統計力學的研究成果,它引入固體退火過程的自然機理并適當引入隨機因素,在整個解鄰域范圍內隨機性地取值,提高全局尋優能力,有效地解決眾多組合優化問題。
引入Metropolis準則到優化過程,以最大化目標函數為例,對于某一溫度Ti和優化問題的一個解x(k),可以生成x′。接受x′作為下一個新解x(k+1)的概率為:
(1)
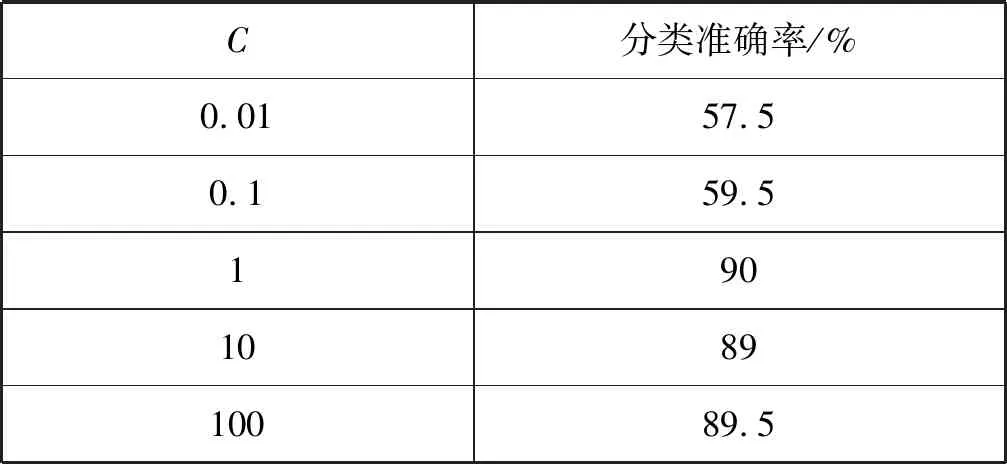
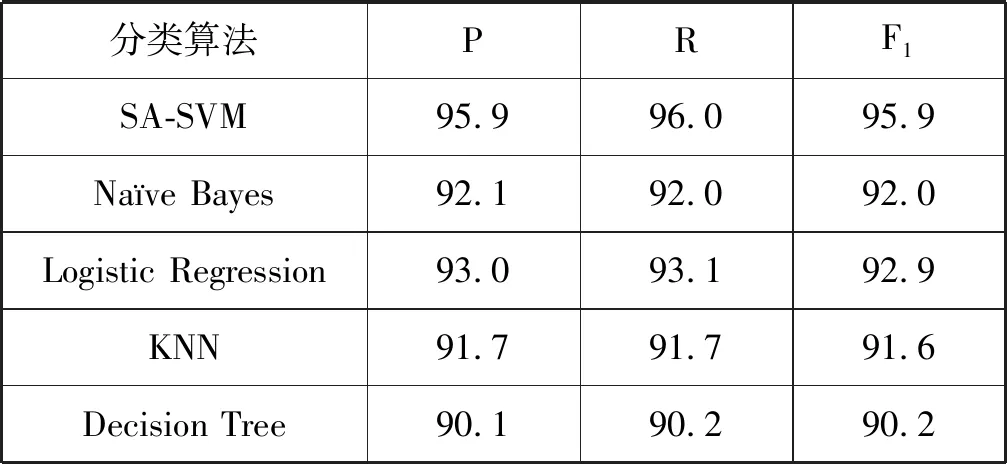
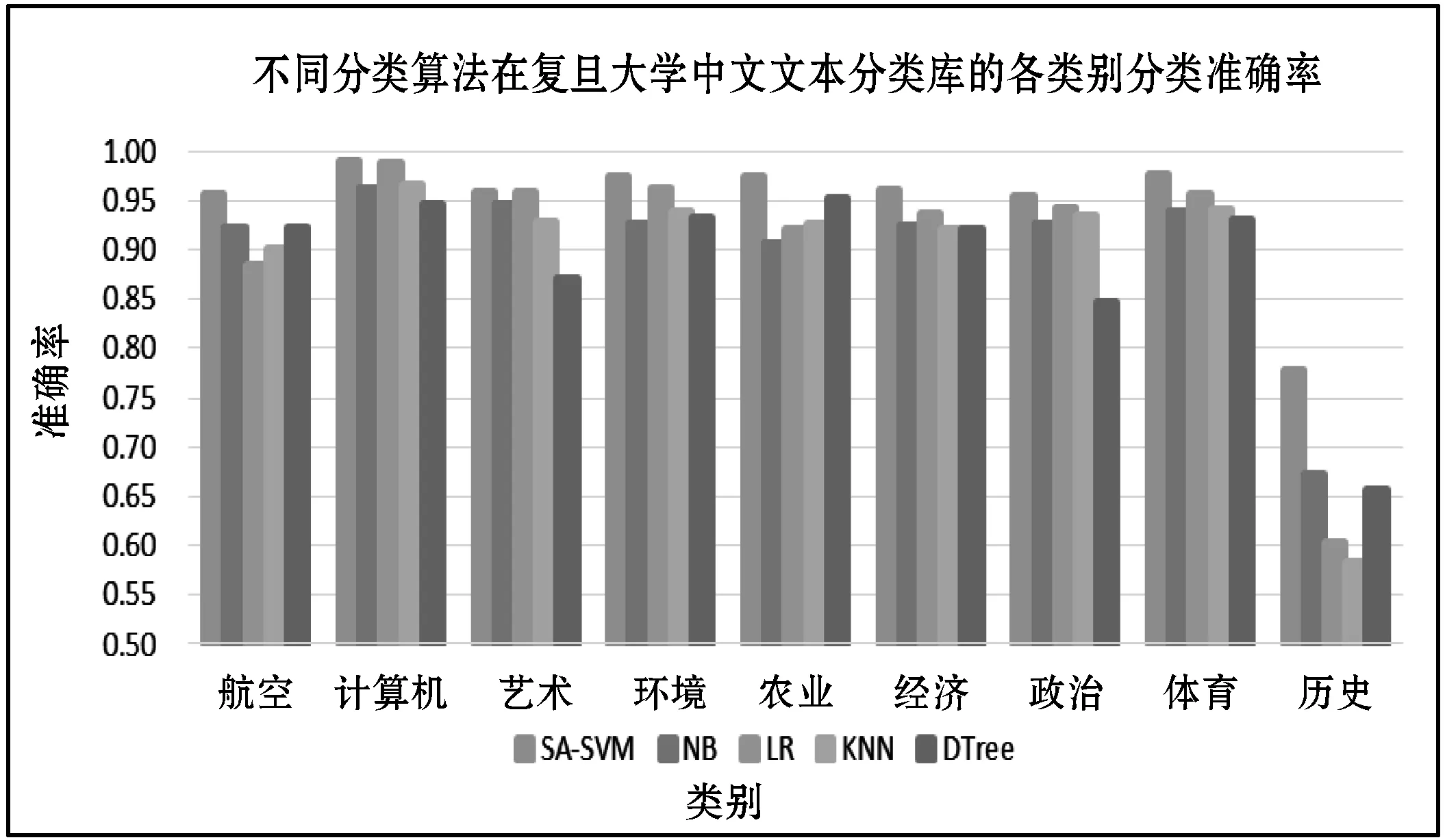
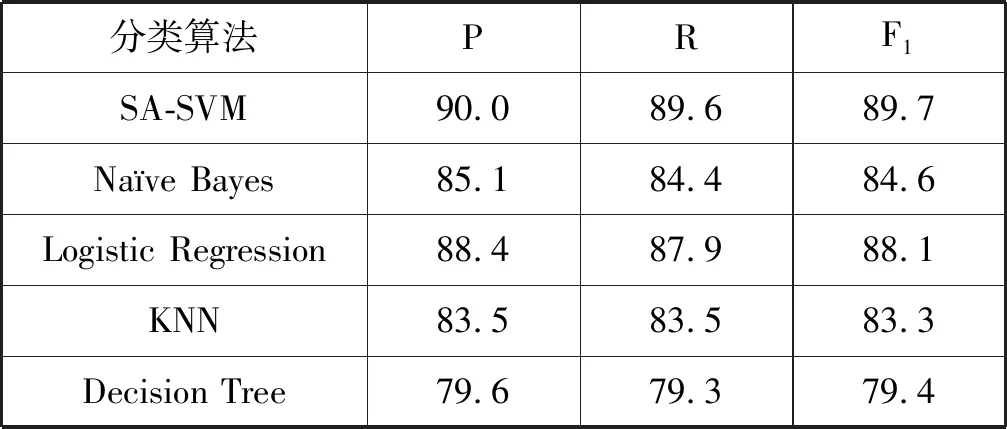
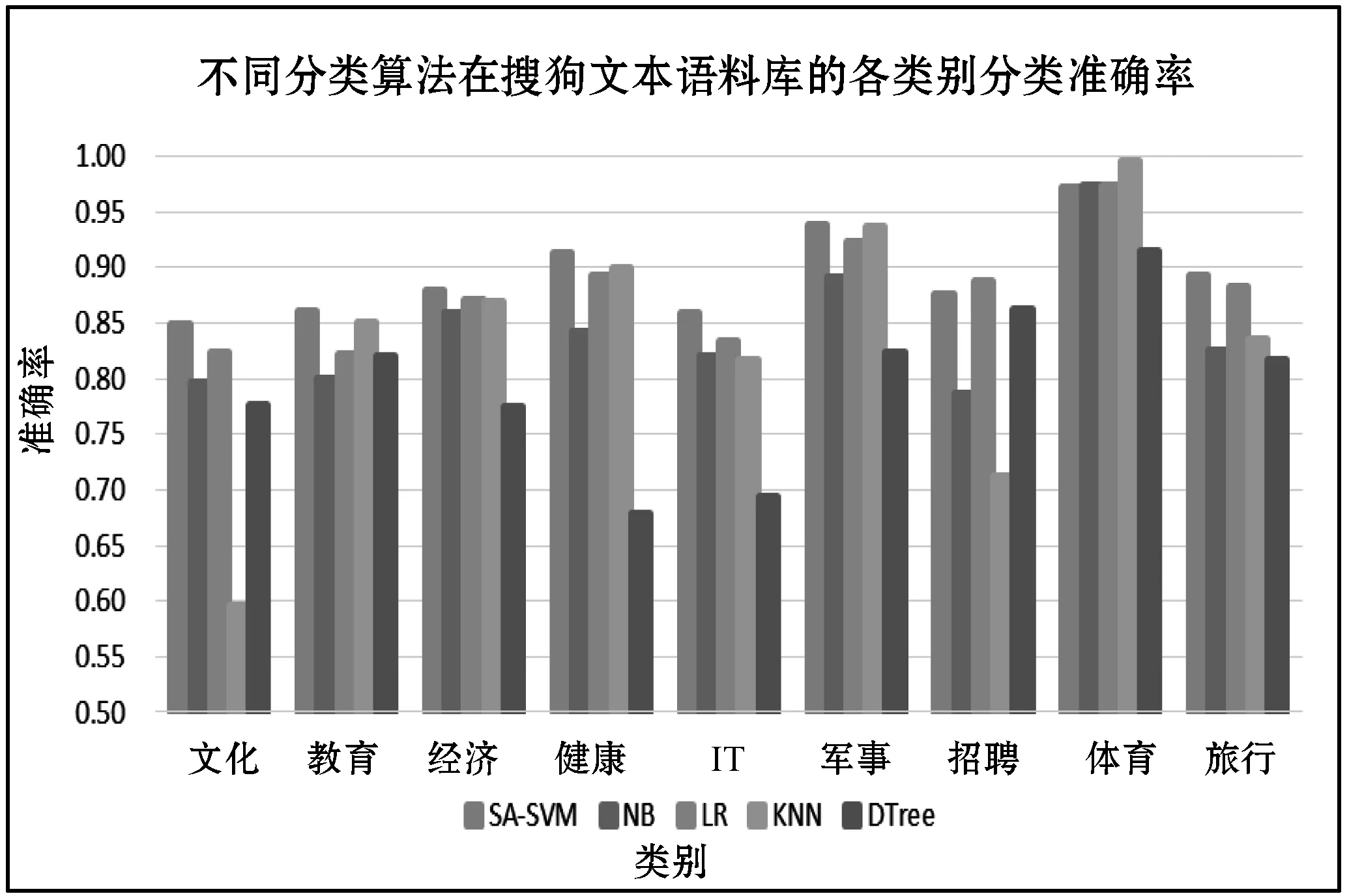
在溫度Ti下,經過很多次的轉移之后,降低溫度Ti,得到Ti+1 對于數據集D={(x1,y1),(x2,y2),…,(xn,yn)},其中xi∈Rn,并表示輸入,yi表示對應輸出,n為輸入樣本的維數。SVM分類目標是找到一個超平面,這個超平面能將所有樣本分開,并使樣本之間的距離盡可能最大。即有: y=ωTΦ(x)+b (2) 式中:Φ(x)為標準正態分布函數,ω表示權值向量,b表示偏移向量。 求解最優超平面,就是針對所給定的數據集樣本,找到權值向量ω和偏移向量b的最優值,使得權值代價函數最小化,且正例和反例之間的間隔最大。對于式(2)而言,難以對超平面參數ω和b直接求解,因此利用增加非負的松弛因子將式(2)轉變成二次優化問題: (3) s.t.yi(ωΦ(xi)+b)≥1-ξiξ≥0,i=1,2,…,n 式中:C為懲罰因子,C>0;ξi表示松弛因子。將最少錯分樣本和最大分類間隔折衷考慮,就能得到廣義上的最優分類面。 通過引入拉格朗日乘子將式(3)轉化為對偶問題,以便于更好地求解,公式如下: (4) 式中:αi為拉格朗日乘子。 對式(4)進行求解得到αi值,那么ω為: ω=∑αiyiΦ(xi)·Φ(x) (5) 最終,SVM相應的分類決策函數為: f(x)=sgn(αiyiΦ(xi)·Φ(x)+b) (6) RBF函數具有收斂域寬、參數少、通用性好等優點,是一個很理想的分類依據函數,因此采用RBF函數建立SVM,公式如下: (7) 式中:σ為RBF核函數參數。 SVM進行分類的基本流程可歸納為:首先將輸入的SVM向量映射到一個特征空間,緊接著在這個特征空間中尋找優化的線性分界線,于是就構建出了一個可分離類別的超平面,使不同的類別正確分開。SVM的訓練過程實質上就是尋找全局最優解。 為了驗證懲罰因子C和核函數參數σ對SVM分類性能的影響,隨機選擇四類3 306個文本作為訓練集。建立分類SVM模型,并選取適當數目的文本作為測試集,分析不同C和σ對SVM分類精度的影響,具體結果如表1、表2所示。 表1 C=1時的分類結果 表2 σ=1時的分類結果 從表1和表2的結果可知,在相同的訓練集、測試集下,懲罰因子和核函數參數不同,SVM分類準確率不同,這表明C和σ的取值影響基于SVM的文本分類結果,要獲得最優的SVM文本分類模型,找到最優的C和σ值是關鍵。 SA優化SVM的懲罰因子C和核函數參數σ的主要判定是取得更高的文本分類準確率,在最優參數[C,σ]處能取得最高的分類準確率,故最大化目標函數為F=Vprecision(C,σ)。 相關設置如下: (1) 設置溫度T的初始值:SA算法的全局搜索性能受溫度初始值的影響,若初始值高,則全局搜索能力強,但需大量時間進行計算;反之,雖可減少時間,但會影響全局搜索性能。在具體操作時,T的初始值可根據實驗結果進行靈活調整。 (2) 設置退火速度(內循環每個溫度的迭代次數):SA算法的全局搜索性能同時也受退火速度的影響,若在某個溫度下充分搜索,需要時間代價,在具體執行時,要根據實際問題設置合理的退火速度。 (3) 設置溫度管理:權衡計算復雜度,通常的降溫方式為T(k+1)=αT(k),k為降溫次數,α一般取較接近1的正常數。 (4) 設置初始解和解的搜索范圍:SA算法具有優良的健壯性,求得的最優解不受初始解的影響,可在解空間內隨機設置初始解。不同的數據集的最優參數[C,σ]范圍不同,實際應用中可根據實驗結果進行靈活調整。 (5) 設置記憶存儲器:在搜索過程中,SA算法由于執行概率接受環節,有可能遺漏當前取得的最優解,增加記憶存儲器,存儲搜索過程的中間最優解,并及時更新。 (6) 設置終止條件: ① 內循環終止條件:當前狀態下連續若干個新解都未被接受或達到迭代次數。 ② 外循環終止條件:連續若干次降溫所獲得的最優解均不變或T SA優化SVM參數的過程具體操作描述如下: (1) 初始化溫度T,設置終止溫度Tmin,設置降溫系數α。 (2) 產生隨機初始解[C0,σ0](是算法迭代起點),并以此作為當前最優解[Cbest,σbest]=[C0,σ0],計算目標函數值F(Cbest,σbest)。 (3) 設置每個T值的迭代次數L;對l=1,2,…,L做第4至第6步。 (4) 在可行解空間內,對當前最優解作一次隨機擾動,利用狀態產生函數生成一個新解[Cnew,σnew],并計算其目標函數值F(Cnew,σnew)以及目標函數值增量Δf=F(Cnew,σnew)-F(Cbest,σbest),其中F(C,σ)為優化目標。 (5) 采用狀態接受函數,判斷是否接受新解:若Δf>0,則接受[Cnew,σnew]作為新的當前解;否則按式(1)中Metropolis準則判決,以概率p接受[Cnew,σnew]為當前最優解。若接受,設置當前狀態為[Cnew,σnew],存入記憶存儲器;反之,當前狀態為[Cbest,σbest]。 (6) 判斷是否滿足內循環終止條件,若是,輸出當前解為最優解并結束此次迭代,轉入(7);否則轉入(4)。 (7) 降溫。根據設置的降溫系數α進行降溫,取新的溫度T=αT(其中T為上一步迭代的溫度)。 (8) 判斷滿足外循環終止條件,退火過程終止,轉入(9);否則轉入(3); (9) 輸出當前最優解與記憶存儲器的中間最優解比較,找到最優解[Cfinal,σfinal],算法結束。 基于SA-SVM的中文文本分類過程如圖1所示。 圖1 基于SA-SVM的中文文本分類過程 采用Python的第三方庫jieba分詞對數據集進行分詞處理,然后去除停用詞。 利用TFIDF進行權重計算,TF指的是特征詞在文本中出現的絕對頻率,而IDF指的是特征詞在文本中的文本內頻率。常用的TFIDF公式如下: (8) 利用DF進行特征選擇,文檔頻率計算訓練集中包含特征項t的文本數目。設|D|為訓練集中的文本總數,di為其中的一個訓練文本,于是有: (9) 若t∈di,則p(t,di)=1;若t?di,則p(t,di)=0。 DF值低于某個設定閾值的特征詞屬于低頻詞,它們可能不含或者含有很少的文本分類信息,可以在原始特征空間剔除這樣的特征項,既能降低特征空間的維度,還有可能提高文本分類的準確率。 采用分類常用的評價指標:準確率P、召回率R和F1度量,具體表示如下: (10) (11) (12) 為驗證SA-SVM中文文本分類的有效性和可行性,采用SA-SVM對中文文本進行分類實驗。實驗的硬件平臺:操作系統為Windows 10專業版,處理器為Inter(R) Core(TM) i5-3210M CPU @2.50 GHz,內存為10 GB,硬盤為256 GB;軟件平臺:Python 2.7。為保證實驗具有全面性和代表性,使用復旦大學中文文本分類庫和搜狗文本語料庫進行對比實驗。 復旦大學中文文本分類庫共有9 804篇訓練文本,9 833篇測試文本,分為20個類別,每一個文本只屬于一個類別。去除重復和損壞的文本以及文本數小于100篇的稀有類別,共有9個類別,其中訓練文本9 318篇,測試文本9 331篇。經過SA優化的SVM參數[Cfinal,σfinal]=[100,0.05],將其代入分類模型重新訓練學習,與常用的文本算法比較,實驗結果如表3和圖2所示。 表3 不同分類算法在復旦大學中文文本 分類庫的分類結果 % 圖2 不同分類算法在復旦大學中文文本分類庫 各類別分類精度 搜狗文本語料庫共有9個類別,每個類別1 990篇文本,隨機將每個類別的1 400篇文本分為訓練文本,590篇文本分為測試文本。經過SA優化的SVM參數[Cfinal,σfinal]=[10,0.5],將其代入分類模型重新訓練學習,與常用的文本算法比較,實驗結果如表4和圖3所示。 表4 不同分類算法在搜狗文本語料庫的分類結果 % 圖3 不同分類算法在搜狗文本語料庫的各類別分類準確率 實驗表明,不同數據集的最優參數[Cfinal,σfinal]不同,兩組數據集通過SA全局尋優能力搜索到最優的SVM參數。經過SA優化參數的SVM分類模型,相比其他中文文本分類算法,在準確率、召回率和F1度量各個方面有明顯的優勢,具有較強的泛化能力,展現了較為顯著的分類性能。 基于SVM的文本分類模型的泛化能力與其參數選擇緊密相關,為解決優化SVM參數難題,本文提出了一個基于SA優化SVM參數的方法,以最大化文本分類準確率為目標全局搜索SVM的最優參數[Cfinal,σfinal]。在設計算法流程時,合理靈活地設置模擬退火的關鍵參數,并引入記憶存儲器以防止因執行概率接受環節遺漏中間最優解,使得模擬退火算法更為智能。在設置內外循環終止條件時充分考慮實際情況,在保證最優性的基礎上盡可能減少不必要的計算量。實驗結果比較表明,基于SA-SVM中文文本分類模型具有良好的使用價值,展現出了非常顯著的分類性能,為今后的文本分類建模提供了一種可行的思路。由于在綜合考慮分類性能時未能做到充分的特征降維,使得分類過程時間較長,因此下一步的工作將在文本分類的特征降維方法上進行改進,進一步提高模型的計算效率。1.2 支持向量機
2 SA-SVM文本分類方法
2.1 參數對SVM分類性能的影響

2.2 基于SA的SVM參數選擇設計方案
3 基于SA-SVM的中文文本分類
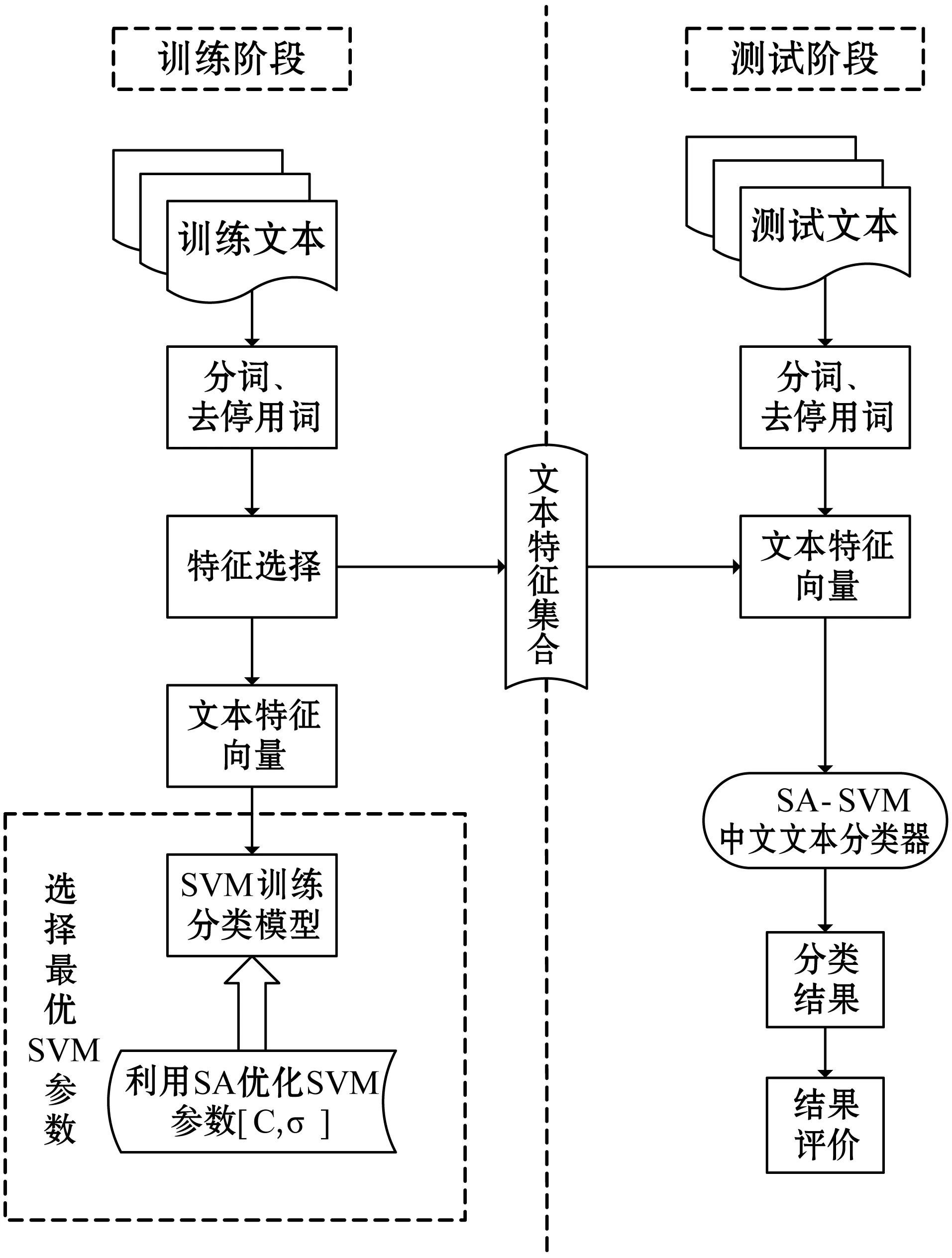
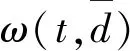


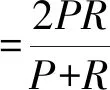
4 實驗例證
5 結 語
猜你喜歡
少先隊活動(2021年4期)2021-07-23 01:46:22數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56制造技術與機床(2019年10期)2019-10-26 02:48:08中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32電子制作(2018年18期)2018-11-14 01:48:06中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06初中生世界·七年級(2017年9期)2017-10-13 22:27:46小學教學參考(2015年20期)2016-01-15 08:44:38沈陽醫學院學報(2015年1期)2015-12-27 13:44:40醫學教育管理(2015年3期)2015-12-01 06:43:16
