一種融合用戶與項目屬性的協同過濾算法的設計與實現
2019-04-01 13:11:46陶志勇崔新新
計算機應用與軟件 2019年2期
陶志勇 崔新新
遼寧工程技術大學電子與信息工程學院 遼寧 沈陽 125105)
0 引 言
隨著網絡的普及,信息量的劇增,推薦系統得到迅速發展。推薦系統的核心是推薦算法,推薦算法的方式可以分為:社交網絡的推薦[1]、基于內容的推薦[2]、基于協同過濾的推薦[3]。其中,協同過濾是推薦系統[4-5]中應用最早并且最成功的算法之一。盡管協同過濾算法應用很廣泛,但仍面臨著數據稀疏、冷啟動、推薦精度低等問題。為解決這些問題,學者們提出了隱馬爾科夫[6]、支持向量機[7]、神經網絡[8-9]等方法,但仍然受數據稀疏的影響嚴重。在傳統的協同過濾算法中,數據稀疏,反饋項目過少勢必會造成項目間相似度計算不準確,進一步導致興趣度的估計值和真實值存在較大的偏差。因此,合理高效地利用已知數據的信息,獲得接近真實相似度的計算方法成為學者們研究的熱點。杜丹琪等[10]利用項目的屬性進行聚類,根據聚類的結果和同一類別的項目屬性值加權的方法進行評分預測。同時,為解決用戶興趣隨時間變化的問題引入TimeRBM模型再次進行評分預測,最后采用線性組合的方法對兩種預測結果進行合理取舍。劉靜等[11]提出了一種基于用戶興趣度和項目屬性的推薦算法,算法在計算相似度過程中加入基于時間的用戶興趣度權重函數,然后再與項目屬性相似度進行融合,最后進行項目預測與推薦。宮志晨等[12]利用多向測量的方法獲得用戶對項目的評分相似性,然后結合項目屬性挖掘用戶對項目屬性的偏好,采用加權的方式獲得最終的用戶間相似度。胡建等[13]采用最大差值評分解決了個別項目造成非常相似用戶丟失的問題,利用用戶的屬性進行量化評分,然后再對其評分進行相似度計算,這樣有利于目標用戶獲得較為相似的近鄰用戶。王三虎等[14]將用戶評分相似度、興趣的傾向相似度、評分相似度的置信度以及用戶屬性相似度進行融合提出了一種融合用戶評分和屬性相似度的協同過濾推薦算法。
以上文獻一定程度上提高了推薦質量的問題,但并沒有做到充分利用已有的數據信息。因此。本文提出了一種充分融合用戶和項目屬性的協同過濾算法。算法的核心思想為:首先利用用戶(項目)屬性修改用戶(項目)相似度計算方法,確定最相似用戶(項目)集;然后將兩種算法組合加權,再進行興趣度估計;最后利用用戶和項目屬性信息挖掘用戶偏好,利用天牛須搜索方法獲得融合用戶偏好的興趣度估計方法。本文在Movie Lens 100k的數據集上進行試驗,實驗表明:本算法緩解了數據稀疏性和冷啟動對推薦系統的影響,提高了推薦精度。
1 基本原理
1.1 基于用戶的協同過濾
傳統的user-based CF算法是使用用戶的歷史信息,獲取用戶間的相似度,然后選擇相似性最高的用戶作為最相似用戶集。興趣度估計常用的相似性度量方式有Jaccard公式、余弦公式。sim(u,v)表示用戶u和用戶v之間的相似度,則以上相似性的度量公式如下:
(1)
(2)
式中:N(u)表示用戶u有過正反饋的項目集合;N(v)表示用戶v有過正反饋的項目集合。由于式(2)過于粗略,John S.breese提出了修正余弦公式如式(3)所示。本文的用戶相似度計算就采用式(3)。
(3)
推薦生成的核心是興趣度估計,即利用目標用戶的類似用戶來估量目標用戶對未瀏覽過項目的興趣度,興趣度估計方法如下所示:
(4)
式中:s(u,k)表示用戶u的k個最近鄰,N(i)代表對項目i有過行為的用戶集合,rvi代表用戶v對項目i的興趣度,因為使用的是單一行為的隱反饋數據,所以rui=1。
user-based CF的時效性較強,適用于用戶個性化不太明顯的領域。存在如下缺點:(1) 當用戶有新行為時,對推薦的結果影響不大。(2) 經常推薦的是搶手項目,推薦長尾里的項目能力不足。(3) 當新的用戶對很少的項目產生行為時,不能進行個性化推薦。
1.2 基于項目的協同過濾
傳統的item-based CF是利用項目之間的相似度進行推薦的,首先計算項目間的相似度,相似度的計算方式和1.1節用戶相似度計算方式類似。項目i和項目j的相似性計算方式如下:
(5)
式中:N(i)為瀏覽過項目i的用戶集合;N(j)為瀏覽過項目j的用戶集合;N(g)為瀏覽過項目i也瀏覽過項目j的用戶集合。其次得到項目間的相似性后,尋找用戶瀏覽過項目的最相似項目集,利用該集合估計用戶對未瀏覽過的項目的偏好。興趣度估量計算方法如下:
(6)
式中:N(u)表示用戶u有過正反饋的項目集,s(i,k)表示項目i的k最近鄰,rui表示用戶u對項目i的興趣度。這里和基于用戶的協同過濾一樣,rui=1。
item-based CF有較強的新穎性,容易挖掘長尾里的項目,利于滿足用戶的個性化需求。用戶有新行為,一定會導致推薦結果的實時變化,但是也存在一定的缺點。由于item-based CF是通過項目間的相似性進行推薦的,很難探索到用戶潛在喜歡的項目,推薦的項目樣式單一。
2 融合用戶和項目屬性的協同過濾算法
融合用戶和項目屬性的協同過濾算法,簡稱UIACF算法,下面詳細介紹UIACF算法的主要內容。
2.1 改進相似度計算方法
帶有不同屬性的用戶對項目的需求有所不同,比如用戶的年齡屬性,年輕人和老年人的消費觀念差別很大,年輕人更加注重的是購物過程中的享受和愉悅感,而老年人更加注重物美價廉,所以,用戶屬性影響用戶之間的相似度。因此,本文在傳統的用戶相似度計算方法中,引入了用戶屬性權重。根據MovieLens 100k(http://www.grouplens.org/)[15]數據集提供的用戶屬性信息,引入用戶年齡、性別、職業屬性的權重。
年齡為yu的用戶u、年齡為yv的用戶v,他們的年齡權重的計算方式如下所示:
ageweightu,v=e-|yu-yv|
(7)
MovieLens 100k數據集將用戶的職業按行業屬性分為21種。用戶u的性別和職業屬性的集合記為Xu,用戶v的職業屬性和性別屬性的集合記為Xv,則這兩個屬性的權重用式(8)來計算:
(8)
引入用戶屬性的相似度計算方法為:
simim(u,v)= (1-a1-a2)×sim(u,v)+
a1×soweightu,v+a2×ageweightu,v
(9)
式中:ageweightu,v和soweightu,v分別為用戶年齡屬性權重和性別職業屬性權重,a1,a2∈[0,1]為未知參數,實際應用時可以根據用戶類別屬性做回歸分析擬合得出。
同理具有相同屬性的項目的相似性也較高,而傳統的項目相似度計算的過程中卻忽略了這一點,因此引入項目屬性權重作為衡量項目相似度的一部分,在項目相似度計算中引入項目屬性權重。項目i和項目j屬性的集合分別記Ti和Tj,項目屬性權重計算方式如下所示:
(10)
最后改進的電影相似度計算公式為:
simim(i,j)=(1-b1)sim(i,j)+b1×typeweighti,j
(11)
式中:typeweighti,j∈[0,1],為電影類型權重,b1∈[0,1],實際應用時可以根據項目類別屬性做回歸分析擬合得出。
2.2 基于用戶和項目結合的協同過濾算法
2.1節詳細介紹了融合用戶屬性的用戶相似性度量方法和融合項目屬性的項目相似性度量方法,改進用戶相似度的計算方法后的興趣度計算方式如式(12),改進項目相似度后的興趣度計算方式如式(13)。
(12)
(13)
式(12)、式(13)會得到用戶對同一種項目的兩種興趣度估計值,為了得到更加準確的興趣度,采用加權的方式,進行綜合預測。引入控制參數a,最終的興趣度估計方式如下:
PUI(u,i)=(1-a)×pI(u,i)+a×pU(u,i)
(14)
式中:a為控制參數,當用戶數量多于項目數量時,用戶相似度計算占主導地位,參數a權重應該偏小;反之,項目相似度計算占主導地位,這時參數a應該偏大,實際應用時參數a可以根據用戶數量和項目數量統計確定。
兩種算法的結合不僅彌補了基于用戶的協同過濾存在的對用戶新行為反映不及時、推薦長尾項目能力不足的缺點,還解決基于項目的協同過濾存在的推薦項目多樣性性能差的問題。
2.3 興趣度估計
2016年中國旅游領域用戶行為畫像及偏好分析認為旅游行業各領域中男性偏愛航空服務,女性偏愛旅游攻略,同時也反映了用戶的某些屬性對帶有某些屬性項目的興趣度存在影響。因此本節首先進行了用戶屬性偏好的挖掘,然后利用用戶偏好對興趣度計算方式進行改進。
(1) 用戶年齡和項目類型 根據數據的用戶年齡屬性將用戶的年齡進行分段。年齡階段為x的用戶的集合記為Ux,觀看過t類型項目的用戶的集合記為Iut,x階段的所有用戶觀看過的t類型項目總和記為sum(u∈Ux,i∈Iut)。x階段的用戶對t類型項目評分的平均值為他們對t類型項目的偏好值,計算方式如下所示:
(15)
(2) 用戶職業和項目類型 統計不同類型項目的瀏覽用戶以及各個類型中的不同職業的用戶對該類型打分的平均值,把這個平均值定義為不同職業對項目類型的偏好值。Uo表示職業為o用戶的集合,Iut表示用戶u瀏覽過的項目中類型為t的電影集合。sum(u∈Uo,i∈Iut)表示職業為o的所有用戶瀏覽過的項目類型為t的個數總和。職業為o的用戶對t類型項目偏好值的計算方式如下:
(16)
(3) 用戶性別和項目類型 統計不同類型的項目的瀏覽用戶以及各個類型中的不同性別的用戶對該類型打分的平均值,把這個平均值定義為用戶性別對項目類型的偏好值。性別為g的用戶的集合記為Ug,用戶u瀏覽過的項目中類型為t的項目集合記為Iut,性別為g的所有用戶瀏覽過的項目類型為t的個數總和記為,則性別為g的用戶對t類型的項目偏好值計算公式如下:
(17)
(4) 用戶和項目類型 不同用戶具有不同的偏好,前幾部分是針對用戶的不同屬性對項目類型的偏好。統計用戶對不同類型電影打分的平均值,用這個平均值反映用戶的對不同項目類型的偏好值。Iut表示用戶u瀏覽過的項目中類型為t的項目集合。表示用戶瀏覽過項目類型為t的個數。則用戶u對電影類型t的偏好值計算方式如下:
(18)
通過上述對用戶歷史信息的處理,利用用戶屬性對應項目類型的偏好值,調節用戶對項目的興趣度的估計值。引入用戶年齡與項目類型的權重因子ωa、用戶職業與電影類型的權重因子ωo、用戶性別與項目類型的權重因子ωg、用戶個體和項目類型的權重因子ωu,最終的調節方式如下:
PUIA(u,i)= (1-ωa-ωg-ωo-ωu)×PUI(u,i)+
ωa×aweight(x,t)+ωg×gweight(g,t)+
ωo×oweight(o,t)+ωu×uweight(u,t)
(19)
式中:ωa、ωg、ωo、ωu為控制參數,用于調節4種屬性偏好在最終的興趣度中所占的比重,使得興趣度更加接近真實情況。控制參數的確定是通過天牛須搜索獲得。天牛須搜索BAS(Beetle Antennae Search)[16-17]是2017年提出的一種高效的智能優化算法,類似于遺傳算法、粒子群算法等智能算法。與傳統的智能算法相比,該算法具有不需要函數的具體形式、不需要梯度信息就可以高效尋優的優點。其生物原理為:天牛的身體長有兩只觸角,在覓食時根據兩只觸角來判斷食物氣味的強弱。哪邊接收到的氣味強度大,天牛就會往哪邊飛。數學建模如下:
(1) 創建天牛須朝向的隨機向量且做歸一化處理。
(20)
式中:rands()為隨機函數;k表示空間維度。
(2) 創建天牛左右須空間坐標。
(21)
式中:xrn和xln分別表示天牛右須、天牛左須在第n次迭代時的位置坐標;xn表示天牛在第t次迭代時的質心坐標;d0表示兩須之間的距離。
(3) 創建適應度函數f(x),并計算f(xl)和f(xr)。
(4) 迭代更新天牛的位置。
xn+1=xn-δn×b×sign(f(xrn)-f(xln))
(22)
式中:δn表示第n次迭代時的步長因子;sign()表示符號函數。
本文協同過濾的適應度函數為:
(23)
式中:x=[ωa,ωg,ωo,ωu];Nx(i)表示x取值的情況下,對目標用戶ui推薦商品列表。目標用戶ui在測試集上有過歷史行為的電影的集合,記為T(i)。
2.4 興趣度估計UIACF推薦算法描述
目前推薦系統的推薦方式可以分為評分預測和top-N,評分預測估算的是用戶對項目發生行為后對項目的滿意程度,而top-N估算的是用戶對項目發生行為的可能性。在實際應用中,top-N比評分預測更有應用價值。這是因為即使用戶對一個項目發生行為后的評分非常高,但是時間、場合等因素一直對該項目沒有發生過行為。這時,評分預測沒有意義。本文的興趣度預測采用的top-N推薦,具體的算法步驟如下:
輸入:目標用戶u,用戶-項目的評分矩陣H,最相似用戶集合U*的大小k1,最相似項目集I*的大小k2,推薦個數N。
輸出:對目標用戶的N個推薦結果。
步驟1根據式(9)、式(11)分別計算目標用戶(項目)和其他用戶(項目)的相似度,確定最相似用戶集合U*和最相似項目集合I*。
步驟2根據式(12)、式(13)分別計算目標用戶對未瀏覽項目的興趣度的估計值,然后進行user-based CF和item-based CF的估計值的組合,跟據式(14)計算興趣度。
步驟3根據式(15)-式(18)統計不同用戶的屬性對應的項目類型的偏好值。
步驟4根據天牛須搜索算法式(20)-式(23)獲得最佳的權重參數。然后利用式(19)計算校正后的興趣度,進行排序,推薦興趣度最高的前N個電影。需要注意的是當一個用戶是新用戶時,他沒有任何歷史信息,在熱門的項目中通過用戶屬性與電影類型的關系進行用戶對項目的興趣度估計。假設,一個新的用戶屬性信息分別為xu、ou、gu。則他對電影i的興趣度計算公式如下:
p(u,i)=ageweight(xu,ti)×occupationweight(ou,ti)×
genderweight(gu,ti)
(24)
3 實 驗
為了驗證算法的性能,在Windows server 2008 64位操作系,16 GB內存,Intel?Xeon?CPU E5-2630 v3 @2.40 GHz,python2.7的環境下對算法進行仿真分析。利用MovieLens 100k數據集將該算法分別與user-based CF和item-based CF、PCEDS算法[18]以及Pearson算法做比較,并且對得到的結果進行分析。
3.1 評價標準
本實驗采用的衡量指標為準確率、召回率。用戶的集合為U,對目標用戶ui推薦N個商品,記為N(i)。目標用戶ui在測試集上有過歷史行為的電影的集合,記為T(i)。計算方式如下:
(25)
(26)
3.2 實驗結果及分析
本文設計了6組實驗,分別是user-based CF、item-based CF、基于用戶和項目組合的協同過濾算法、用戶相似度改進后的組合協同過濾算法、相似度改進后組合的協同過濾算法、融合用戶和項目屬性的協同過濾算法。6組實驗驗證了算法組合、相似度改進以及興趣度矯正的有效性。為了方便描述實驗結果,本文采用表2中的縮寫來表示對應的算法,采用k1表示最相似用戶的個數,采用k2表示最相似項目的個數。

表1 本文算法和擬比較算法
(1) 算法結合的有效性 該實驗主要是驗證兩種算法的組合對推薦質量的影響。本文實驗的推薦個數定為10。首先,利用召回率和準確率作為評判標準來測試使UCF結果達到最佳的參數k1的值,用11個k1值來測試UCF算法的推薦質量。得到的實驗結果如圖1所示。由圖1中可以看出,取值在30附近時,該算法的召回率和準確率最高。為了便于對比,UIACF算法實驗的最相似用戶集的大小定為30。
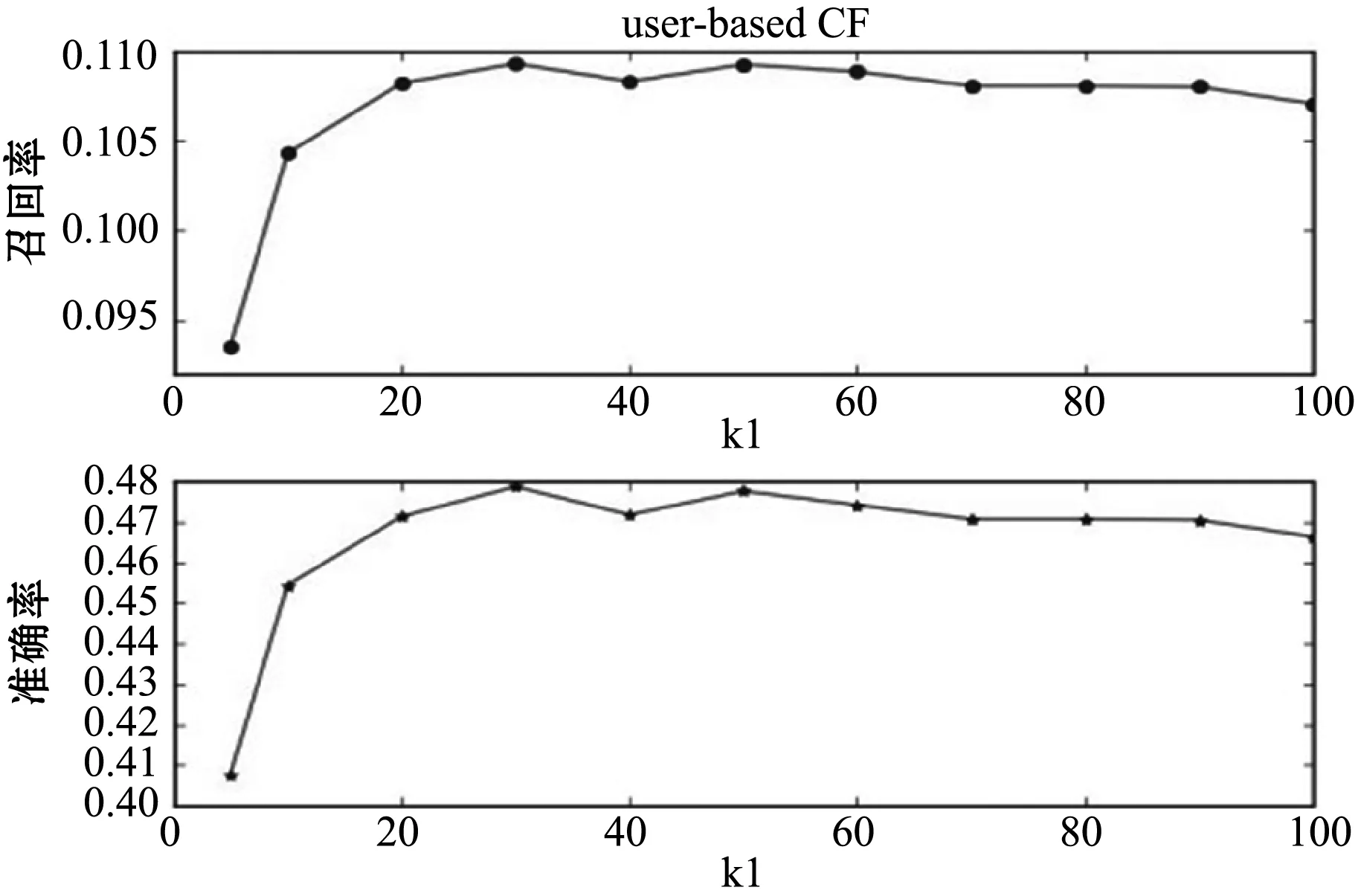
圖1 基于用戶的協同過濾
用9個k2值來測試ICF算法,實驗結果如圖2所示。由圖2可以看出k2取值在500~900范圍內時,召回率穩定在0.104~0.105之間,準確率也穩定在0.450~0.455不再有大的波動,召回率和準確率變化趨勢相同。同樣,為了方便比較,在UIACF算法中最相似項目集的大小值取為500。
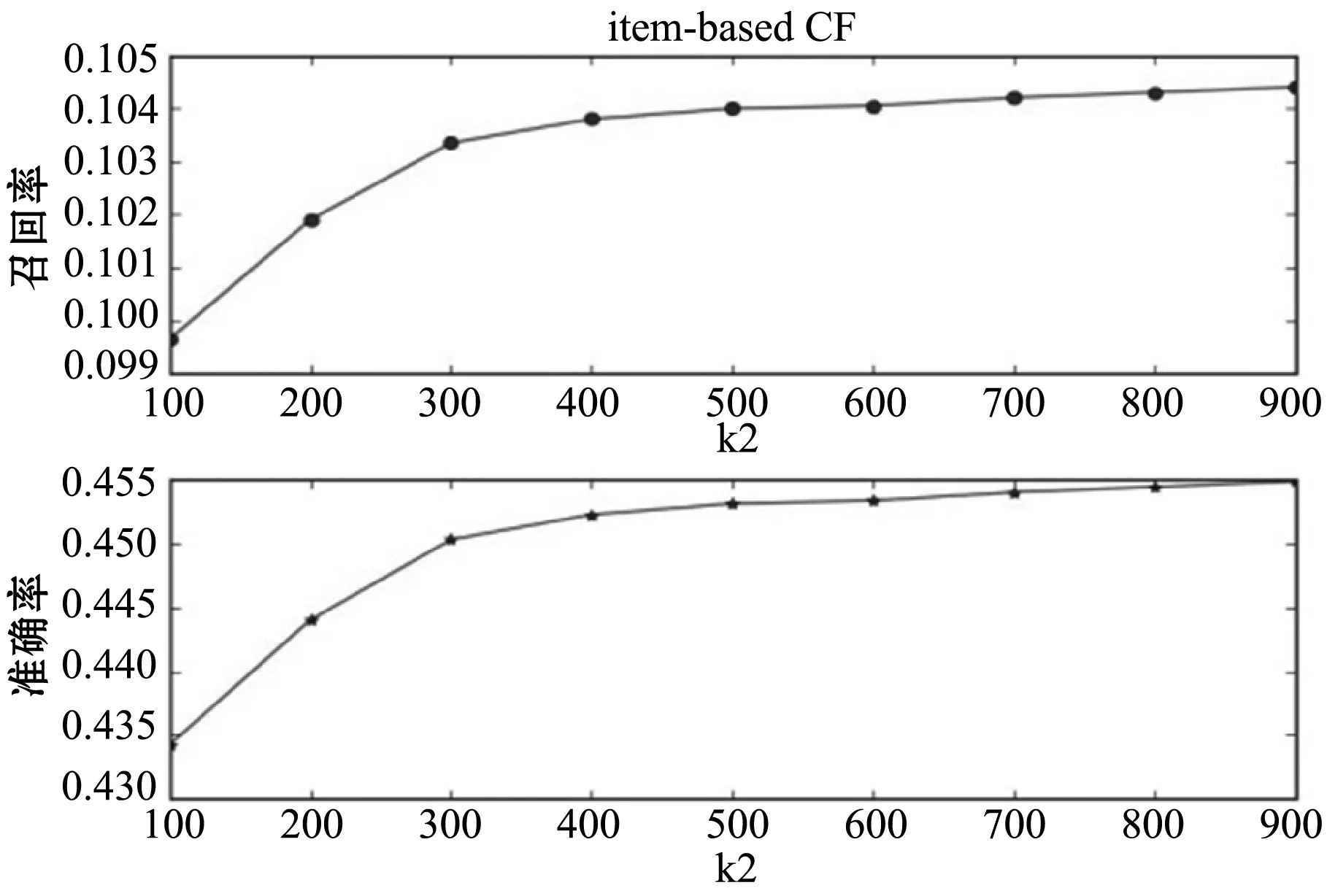
圖2 基于項目的協同過濾
將上述兩種算法結合后,得到結果如圖3所示。圖3中,由本文的算法結合方式可知,當a=0時,對應點縱坐標的值為ICF算法的推薦精度;當a=1時,對應點的縱坐標的值為UCF算法的推薦精度。而a=0.3時,對應的推薦精度高于這兩種情況的任何一種。說明兩種算法的結合提高了推薦質量。由圖1、圖2、圖3可以看出準確率和召回率的趨勢相同,在后面的實驗選擇了召回率作為算法的衡量指標。
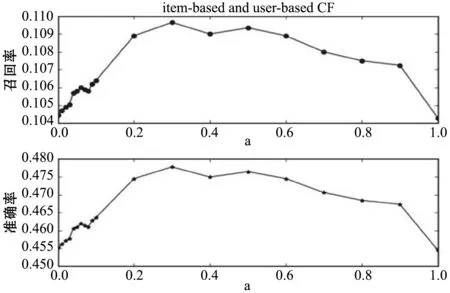
圖3 用戶和項目組合的協同過濾
(2) 相似度改進的有效性 本實驗主要是驗證相似度改進的有效性,IUICF的實驗結果如圖4所示。由圖4可知:b1取值為0.05時推薦的質量最高,b1的取值為0時,相當于項目相似度未改進前單純的兩種算法結合的推薦質量。項目相似度改進后將召回率從0.109 6提高到0.110 7。
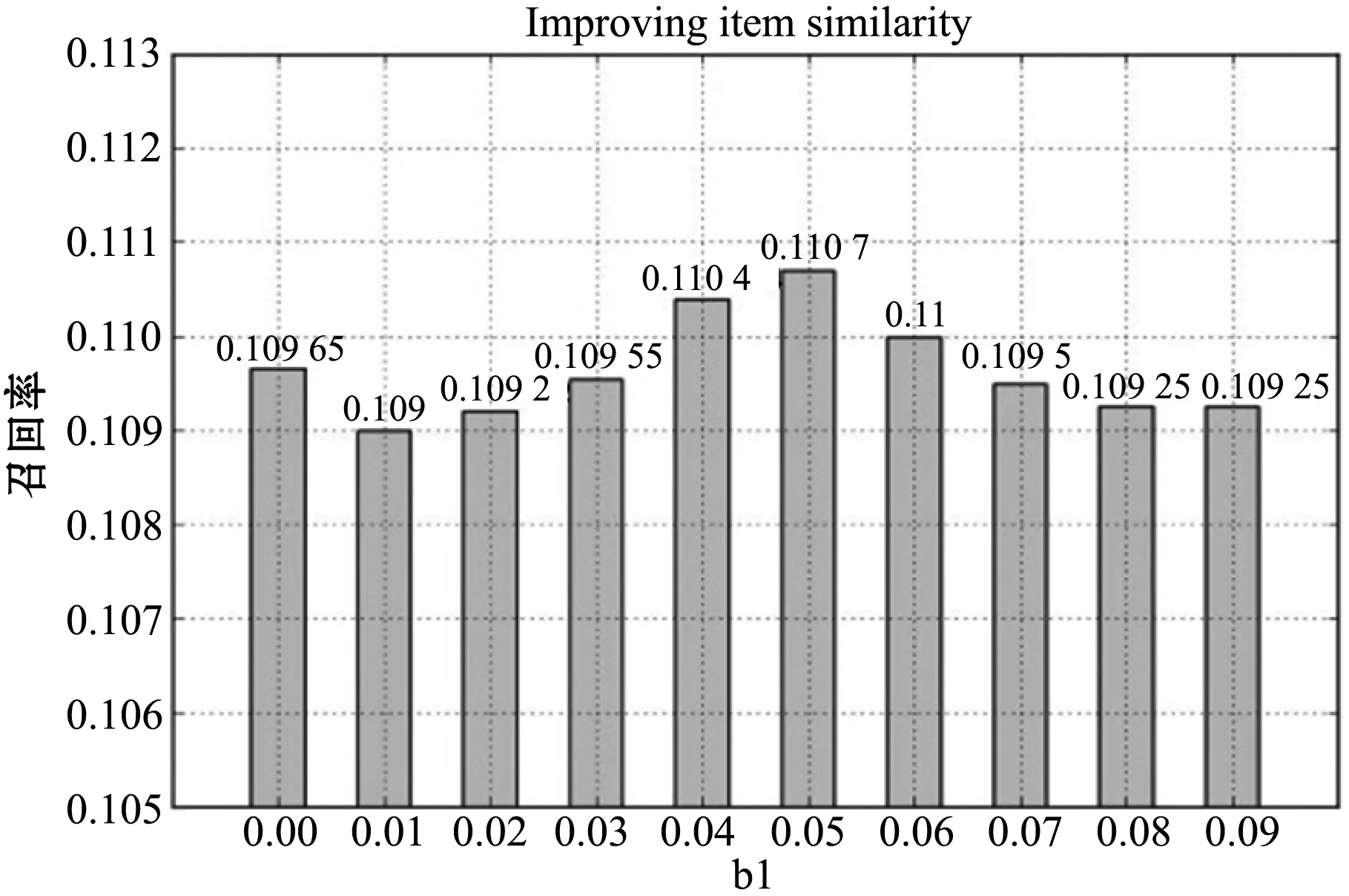
圖4 項目相似度參數測試圖
UIUICF的實驗結果如圖5所示。由圖5可以得到該算法在a1=0.04,a2=0.01時的結果最佳。當a1=a2=0時,相當于IUICF的推薦精度。實驗表明,用戶相似度改進后,召回率從0.110 7提高到0.112 2。說明用戶的性別,年齡和職業對用戶的相似度有影響,性別決定總體相似度的1%,年齡和職業決定總體相似度4%。

圖5 用戶相似度參數測試圖
通過上述實驗,可以確定提出的用戶和項目相似性計算方式的改進均可以降低數據稀疏對協同過濾算法的影響,提高推薦質量。
(3) 興趣度矯正的有效性 本實驗主要是驗證用戶偏好矯正興趣度的有效性。利用2.3節提出的數據處理方式,得到用戶屬性對應項目類型偏好值。由于評分的范圍是1~5,所以偏好值的范圍也為1~5。偏好值為0時,代表該屬性的用戶對應類型的項目沒有發生過行為。
利用式(15)計算用戶年齡對應電影類型的偏好值。圖6為各年齡段的電影類型偏好分布圖,由圖6可知:各年齡段的用戶存在電影類型的偏好,且各有不同。在圖中的十種電影類型中,青少年更傾向于科幻片,青年更中意犯罪片,中年人喜歡看美劇,老年人更偏愛推理電影。
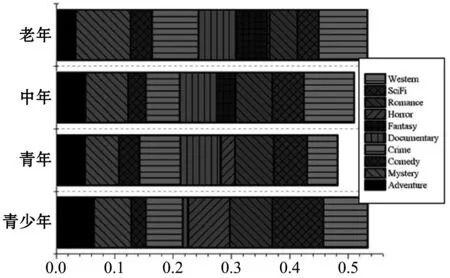
圖6 各年齡段的電影類型偏好分布圖
利用式(17)計算用戶性別對應電影類型的偏好值。圖7為不同性別對6種電影類型偏好程度圖。圖7表明:男女性別對電影類型的偏好存在差異。在圖中的6種電影類型中,男性比較偏好科幻片,而女性比較偏好愛情片。同理,根據式(16)和式(18)挖掘到用戶的職業以及用戶個體對應的電影類型偏好均存在差異。
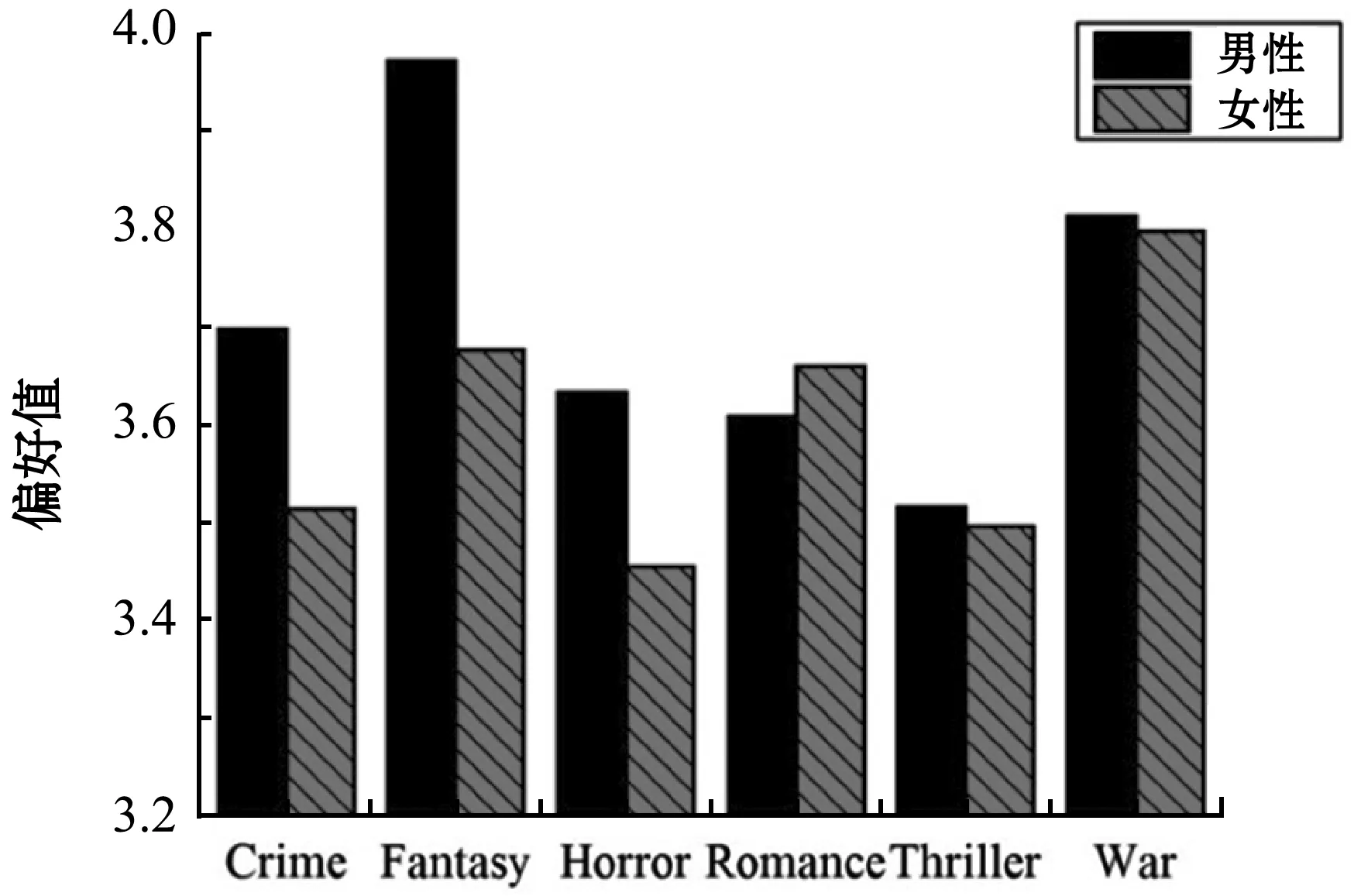
圖7 用戶性別的電影類型偏好
利用上述獲取得的用戶屬性對應電影類型的偏好值,分別用式(19)進行準確度矯正。利用天牛須搜索算法尋找最優的參數,總迭代的次數為500,迭代大約200次時,實驗結果收斂。最終的實驗結果如圖8所示。當權重因子ωa、ωo、ωg、ωu分別取值為0.01、0.01、0.003 061、0.001時,用戶的屬性矯正的興趣度最接近真實興趣度。本次實驗的結果驗證了實驗最初的假設,表2為實驗結果對照表。
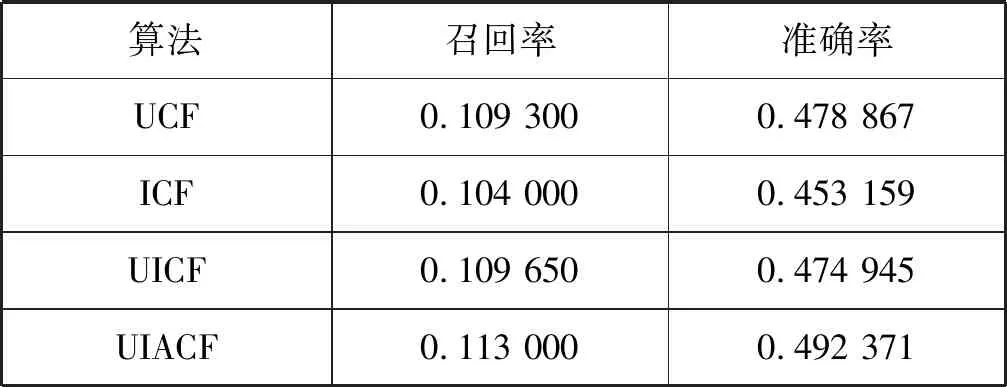
表2 實驗結果對照表
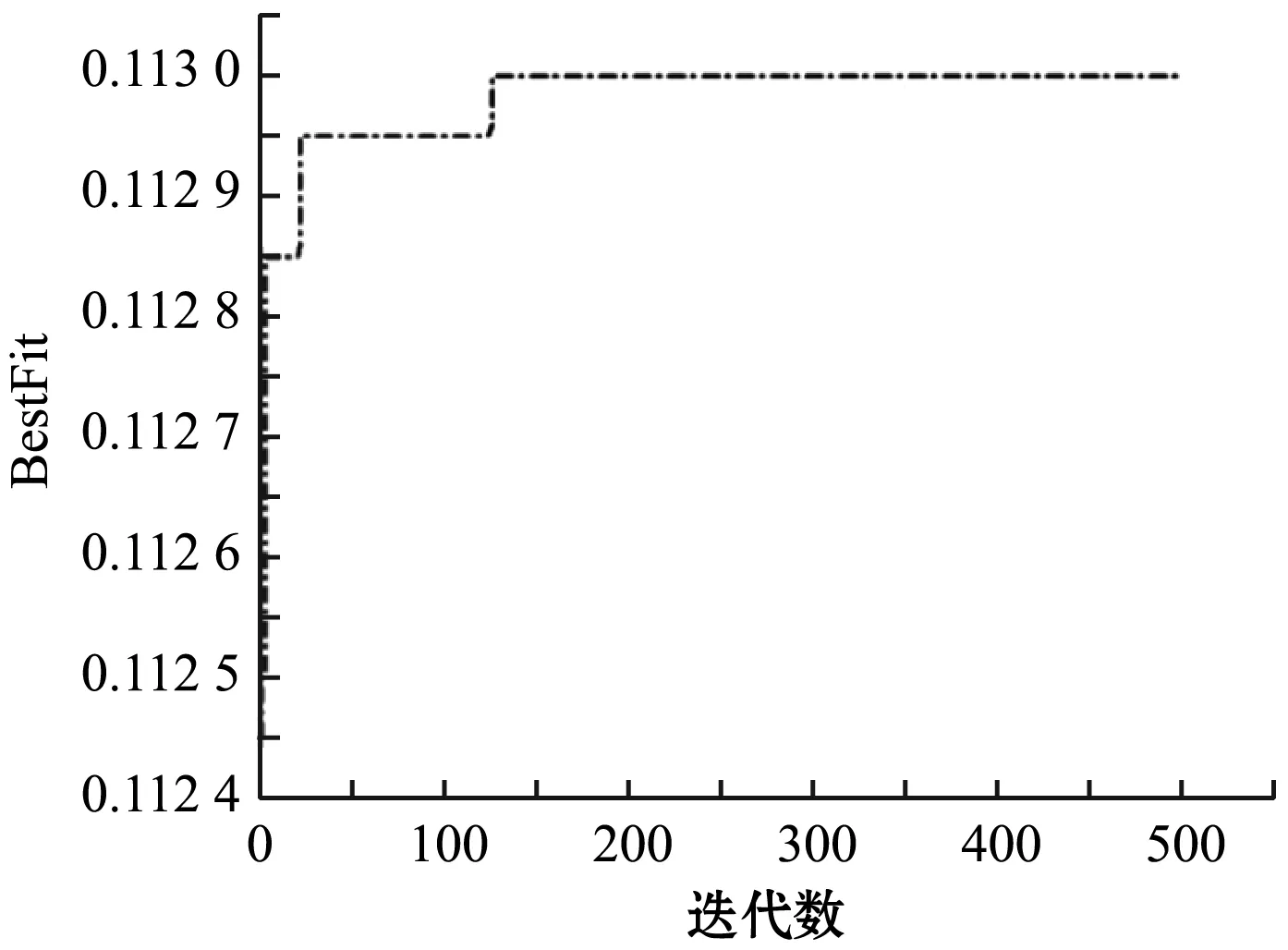
圖8 協同過濾適應度曲線
(4) 不同算法之間的對比 近鄰數分別取15、20、25、30、35、40、45,對文獻[20]中的PCEDS算法、Pearson算法、UCF算法、ICF算法以及UIACF算法進行比較,實驗結果如圖9所示。實驗結果表明:UIACF算法的性能不僅優于UCF和ICF,還優于PCEDS算法。同時也說明了合理地利用用戶和項目的屬性信息對推薦系統推薦質量的提高有很大的價值。
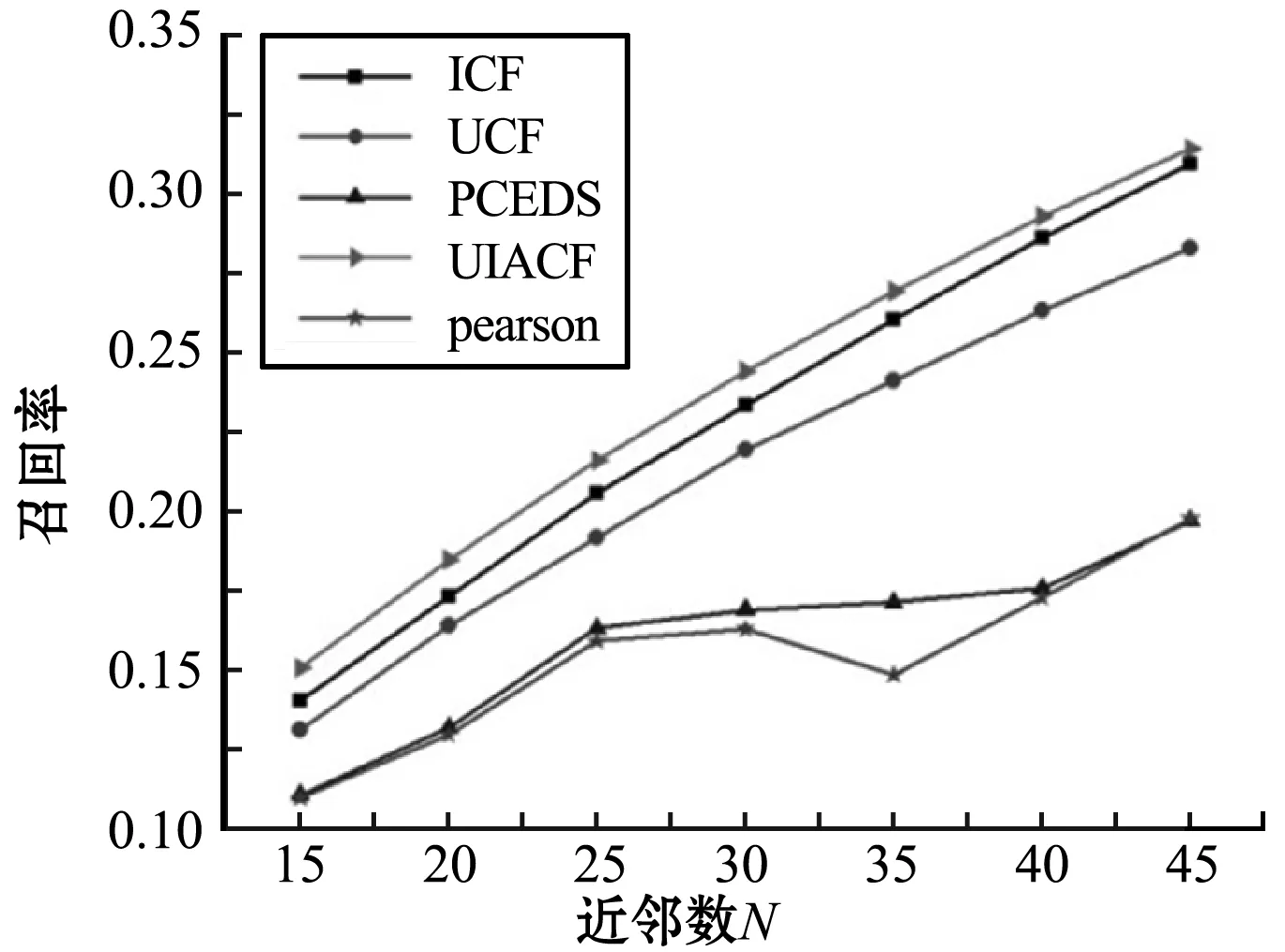
圖9 算法對比圖
4 結 語
傳統的user-based CF和item-based CF以及目前存在的一些算法缺少對用戶的屬性和項目屬性的充分考慮,從而導致冷啟動、數據稀疏性、推薦精度低等問題。本文在傳統的協同過濾基礎上,提出一種融合用戶和項目屬性的協同過濾算法。利用兩種算法的結合、用戶屬性對應的偏好以及天牛須搜索算法來調整興趣度的預測,從而使預測的興趣度更接近真實的興趣度。此外,傳統相似度的度量忽略了用戶屬性和項目屬性對相似度的影響,本文引入用戶的年齡、職業權重以及項目的類型權重因素。實驗結果表明,本文提出的算法在召回率上與用戶協同過濾相比提高了3.39%,較傳統項目協同過濾算法提高8.65%。本算法存在的不足是需要數據集帶有用戶和項目的屬性信息,受屬性細度劃分的影響嚴重。下一步的工作是在本算法的基礎上研究如何進行屬性細度劃分,進一步提高推薦系統的推薦質量。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
商用汽車(2016年11期)2016-12-19 01:20:16
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
