基于神經網絡和不同立地質量的森林蓄積量遙感估測
2019-04-08 03:13:04,,,
山東科技大學學報(自然科學版) 2019年2期
, , ,
(1.山東科技大學 測繪科學與工程學院,山東 青島 266590;2.國家海洋信息中心,天津 300171)
森林被譽為“地球之肺”,在全球生態系統的平衡中發揮著重要作用,是人類以及多種物種賴以生存和發展的基礎[1]。森林蓄積量是衡量森林健康與否的重要指標,也是政府掌握國家森林資源狀況和制定計劃采伐、森林經營管理措施的重要依據。傳統的蓄積量測定方法是一、二類森林調查,人力、物力投入巨大,而且調查周期長,難以掌握森林的動態發展狀況。20世紀70年代以來,遙感技術如雨后春筍,迅速應用于各個領域,利用遙感技術進行森林蓄積量的定量估測也取得了一系列的重要進展[2-4]。
基于遙感技術對森林蓄積量進行估算,主要是利用遙感影像數據以及少量實地調查數據,采用數學方法構建森林蓄積量的估算模型,從而使得模型可以直接應用在森林蓄積量估算中[5]。國外很早就有遙感數據定量估算森林蓄積量的應用。早在1988年,Nelson等[6]就利用Laser數據估算了森林的蓄積量和生物量。Gemmell等[7]基于專題制圖儀(thematic mapper, TM)數據,研究了各波段影像以及其他實測數據對估測森林蓄積量的影響度,為TM影像數據在定量估測蓄積量方面提供了理論依據。Fazakas等[8]使用TM影像數據結合最近鄰法估算了森林的蓄積量。國內蓄積量的遙感估算相對國外起步較晚,劉瓊閣等[1]提出了基于偏最小二乘法的森林蓄積量遙感估測模型,程武學等[9]對基于小班的各種蓄積量預測的合理性進行了診斷,證實了其合理性。近年來,得益于神經網絡超強的非線性處理能力,國內外研究人員將其成功地運用到森林蓄積量的估測中,取得了一定的成果。王臣立等[10]運用3層的后向傳輸(back propagation, BP)神經網絡建立了基于植被指數的熱帶森林蓄積量估算模型,同等條件下較回歸分析模型的預測效果更好。許煒敏等[11]構建了結構為10∶3∶1的杉木林蓄積量BP神經網絡模型。吳達勝等[12]建立了涵蓋地形、地貌、氣候氣象、土壤、林分結構特征及光譜特征的森林資源蓄積量預測自變量因子集,并應用改進的BP神經網絡模型對森林資源蓄積量進行了預測,所取得的模型充分利用了多源數據,且具備很強的泛化能力。
森林地位級表是森林管理中的常用數表之一。早在上世紀90年代,林昌庚等[13]就提出了適合于中國森林調查數據的地位級表編制方法,周春國等[14-15]對其進行了完善,提出了最佳導線曲線的測定方法。研究表明,區分立地質量等級進行預測建模可以顯著提高森林蓄積量的估算精度。王艷婷等[16]運用嶺估計法,分不同地類分別建立森林蓄積量估測方程,結果表明,當影響蓄積量估測的自變量間存在復共線性時,分地位級建立模型的精度明顯優于統一建模的精度。劉俊等[5,17]建立了基于不同立地質量的杉木和松樹的森林蓄積量遙感估測模型,采用了更為準確的地位級劃分方法,但在建模時只利用了遙感影像主成分分析的第一主成分進行線性回歸建模,并沒有充分利用遙感影像和遙感輔助數據,由于森林蓄積量受到多方面因素的影響,單一變量難以準確估算蓄積量,因此估算精度不高。
本研究以2009年TM影像數據和涼水自然保護區森林二類小班數據為數據源,采用地位級法劃分林分的立地質量等級,結合回歸分析與神經網絡分析算法,對紅松樹種以不區分立地質量和區分不同立地質量等級分別建立森林蓄積量的遙感估測模型,旨在為森林蓄積量的遙感監測提供一種新的思路。
1 研究基礎
1.1 研究區概況
涼水自然保護區位于黑龍江省伊春市帶嶺區,小興安嶺山脈的東南段。地理坐標為東經128°47′8″—128°57′19″,北緯47°6′49″—47°16′10″,東西寬13.0 km,南北長17.0 km,總面積為12 133 km2(圖1)。該地區深受海洋性氣候的影響,具有明顯的溫帶大陸性季風氣候特征,總的特點是冬長夏短,冬季嚴寒干燥,夏季濕涼多雨。年平均氣溫-0.3 ℃,年平均最高氣溫7.5 ℃,年平均最低氣溫-6.6 ℃;年平均降水量676 mm,年平均相對濕度78%,年平均蒸發量805 mm。土壤類型主要有暗棕壤、沼澤土、草甸土、泥炭土4類。該地區森林資源豐富,其中紅松是這里的優勢樹種。
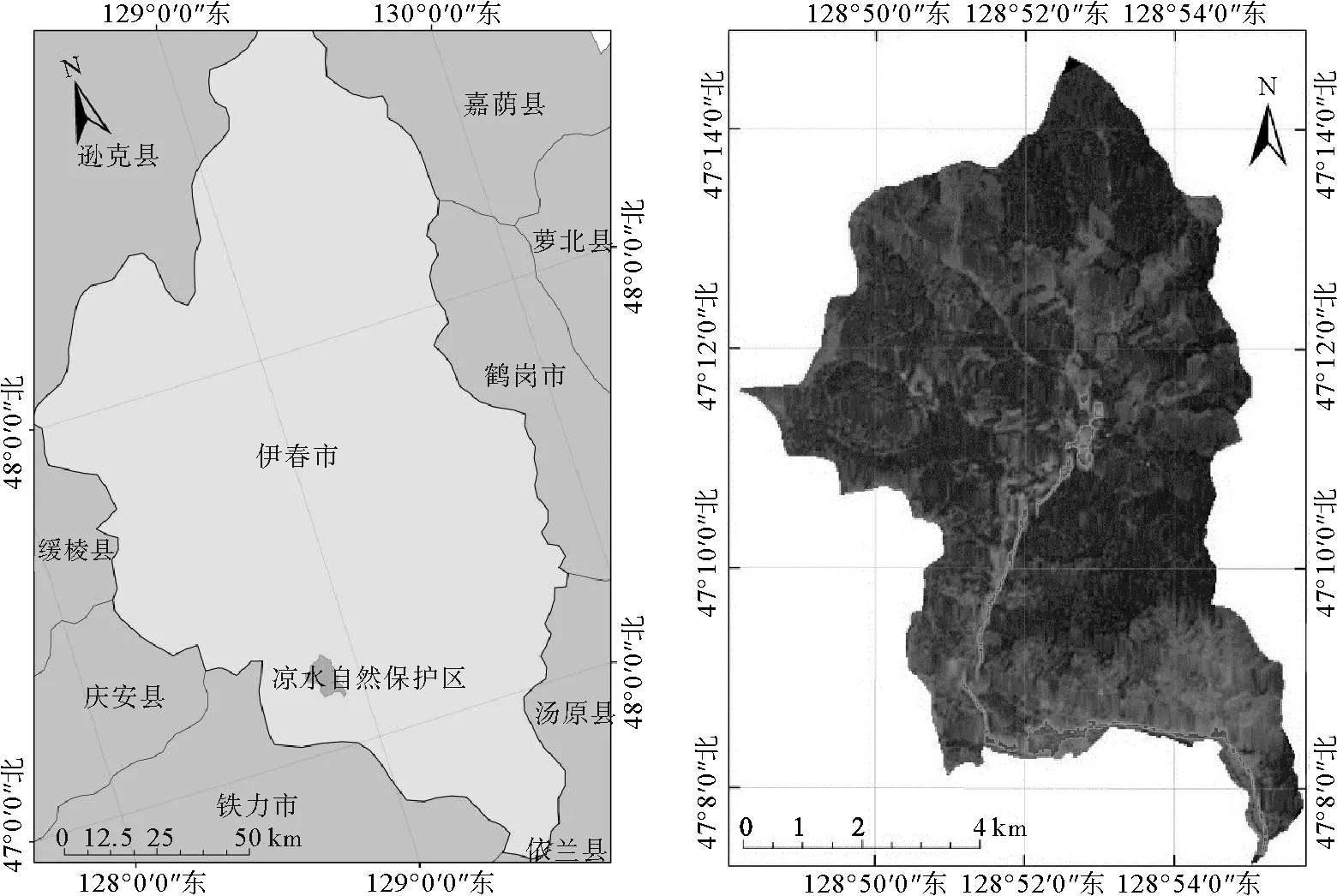
圖1 研究區地理位置與TM影像數據圖Fig.1 Geographical location and TM image data of the study area
1.2 數據獲取
1.2.1 遙感影像數據
實驗使用Landsat TM遙感影像,數據在美國地質勘探局(United States Geological Survey,USGS)官網(https://earthexplorer.usgs.gov)上獲取,綜合考慮時相和云量等因素,選取成像時間為2009年5月29日覆蓋涼水自然保護區的TM遙感影像。利用ENVI5.3對影像進行輻射定標、大氣校正、裁剪與鑲嵌等預處理。
1.2.2 高程數據
涼水自然保護區位于小興安嶺地區,地形復雜多樣,海拔290~550 m,以山地、丘陵地形為主。實驗運用全球數字高程模型(global digital elevation model,GDEM)數據,對應的分辨率精度為30 m。
1.2.3 森林資源二類調查數據
獲取涼水自然保護區2009年森林資源二類調查小班矢量數據,屬性表中包括小班林種、起源、地類、公頃株數、郁閉度、高度、自然度、林分高、優勢樹高、優勢徑階、枯倒樹種、下木名稱、地權使用權、地被總蓋度、地被名稱、地貌、部位、坡向、坡度、樹種組成、林分類型、樹種年齡、樹種直徑、樹高、林層結構、齡級、齡組、小班每公頃蓄積量、小班總蓄積量等。
1.3 研究技術路線
運用2009年涼水自然保護區二類森林資源調查數據和同年度該區TM影像作為數據源,首先,對數據進行預處理后,根據前人研究經驗和方法,尋找最合適的立地指數導向曲線來劃分森林各小班數據的立地質量等級。其次,篩選出共線性低且與森林蓄積量相關性高的遙感因子變量作為模型的自變量,對自變量和蓄積量之間分別進行基于回歸分析和基于神經網絡分析的模擬,并進行精度檢驗,篩選出最合適的森林蓄積量估測模型。研究技術路線如圖2所示。
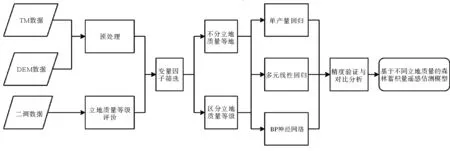
圖2 技術路線圖Fig.2 Technology roadmap
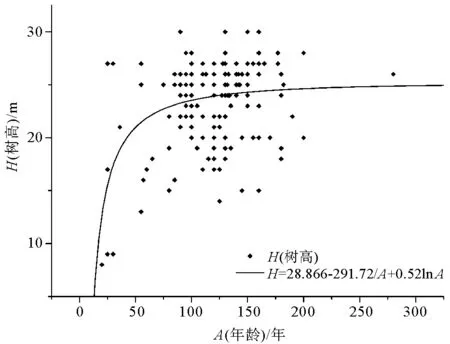
圖3 最佳地位級導向曲線Fig.3 The best sue level guide curve
2 地位級劃分與因子選取
2.1 立地質量等級評價
采用地位級法進行立地質量的評價。地位級表以林分平均高與平均年齡的關系為依據, 是對同齡純林分地區分樹種編制、反映林地生產力高低的數表, 是森林經營及森林調查中主要的常用數表之一[10]。按相同年齡時,林分高度的變動程度劃分為若干個等級,通常為5~7級,以羅馬數字Ⅰ、Ⅱ、Ⅲ…等符號依次表示,將每一等級所對應的各個樹齡時的平均高度列成表,即為地位級表[10]。編制地位級表的關鍵就是導向曲線的選定,前人[10-12]提出了多種計算導向曲線的函數模型與方法,但各種導向曲線模型的選擇因數據而異。基于涼水自然保護區森林資源二類小班調查數據,對優勢樹種為紅松且郁閉度0.4以上的小班,依據平均樹高和平均年齡建立一條代表中等立地等級條件下的地位級導向曲線[11](圖3)。通過不同數學模型比較選出對數與逆函數結合的曲線作為紅松地位級導向曲線的最優模型,最終所得方程為:
H=28.866-291.720/A-0.524lnA。
(1)
其中,H代表小班的平均高,A代表小班的平均年齡。
目前的研究中,通常以導線曲線為基礎,采用比例法確定地位等級的上下界線,以導向曲線的1.35倍為上界線,0.55倍為下界線[10]。用f(A)表示導向曲線方程,則上下界模型分別為1.35f(A)和0.55f(A)。把杉木分為5個地位級數,各等分高度間隔為0.55f(A)、0.75f(A)、0.9f(A)、1.05f(A)、1.35f(A),按照以上分類辦法,得到地位級表,如表1所示。
結合表1,將地位級為Ⅰ、 Ⅱ的歸為立地質量差,地位級為Ⅲ的歸為立地質量中等,將地位級為Ⅳ、Ⅴ的歸為立地質量優。以此數據作為立地質量劃分的結果分別用來擬合不同立地質量的森林蓄積量的估算模型。
2.2 影響因子定義
根據以往的研究,依據單變量或者多變量的線性組合,可以不同程度地突出某些需要的信息以及抑制無關的信息[13]。本次調查數據共有小班431個,刪除優勢樹種不是紅松和郁閉度低于0.4的小班數據,并利用標準差分析法剔除明顯的異常數據。剔除異常樣本后各級統計數據如表2。
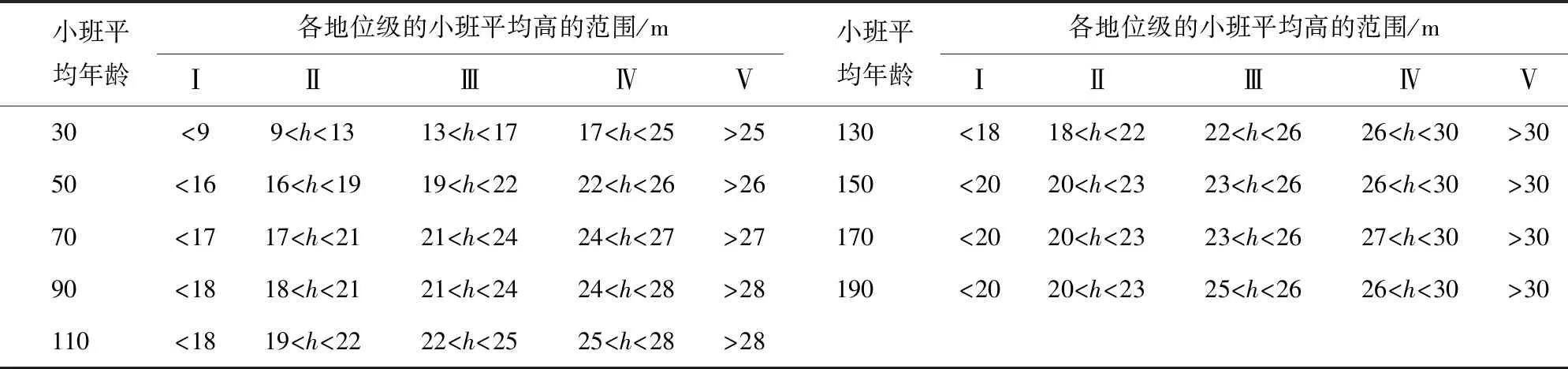
表1 紅松地位級Tab.1 The site lovel of Korean Pine

表2 不同立地質量等級的建模及驗證樣本數Tab.2 Modeling and validation samples of different site qualities
查閱相關文獻后,在前人研究基礎上,從TM影像中選取可能影響蓄積量的遙感信息參數,如TM影像的第一波段(B1)、第二波段(B2)、第三波段(B3)、第四波段(B4)、第五波段(B5)、第七波段(B7);多波段組合(B1/B3、B2/B4、B3/B5、B3×B4/B7、B4×B5/B7、(B1-B7)/B4、(B3+B4+B5)/(B1+B2+B7),下文分別用B13、B24、B35、B347、B457、B174、B345127表示);植被指數如歸一化植被指數(normalized difference vegetation index,NDVI)、比值植被指數(ratio vegetation index,RVI)、增強型植被指數(enhanced vegetation index,EVI)、差值植被指數(difference vegetation index,DVI);主成分分析的第一分量(principal componet analysis,PCA);經過遙感影像數據反演的土壤濕度(soil moisture,SM)、地表溫度(land suface temperature,LST);經過研究區數字高程數據提取的坡向(Aspect)、坡度(Slope)、海拔高度(ASL)等23個變量作為因子,如表3所示。

表3 變量因子表Tab.3 Variable factor table
自變量的選擇是建立模型的首要任務。分別計算表3選取的因子在不同立地質量下與獲取的蓄積量之間的相關系數R和他們的方差擴大因子(variance inflation factor,VIF),所得結果如表4所示。
如表4可見,除去地形和地表溫度、濕度之外,森林的蓄積量與以上各個因子的相關系數均較高,達到了0.01的顯著性水平。無論是否劃分立地質量等級,NDVI與蓄積量的相關性均較高,其次是TM影像的第3波段、遙感圖像主成分分析的第一主成分等變量,說明NDVI以及遙感影像的紅色波段是監測森林蓄積量的敏感波段。然而,紅色波段(B3)、NDVI變量的方差擴大因子(VIF)很高,說明其自變量觀察值之間存在嚴重的共線性。各個變量之間的相關性也比較高,會造成模型的冗余[17]。因此在建模之前必須進行因子的篩選,確定進入模型的自變量。
2.3 因子篩選方法
2.3.1 所有子集回歸法
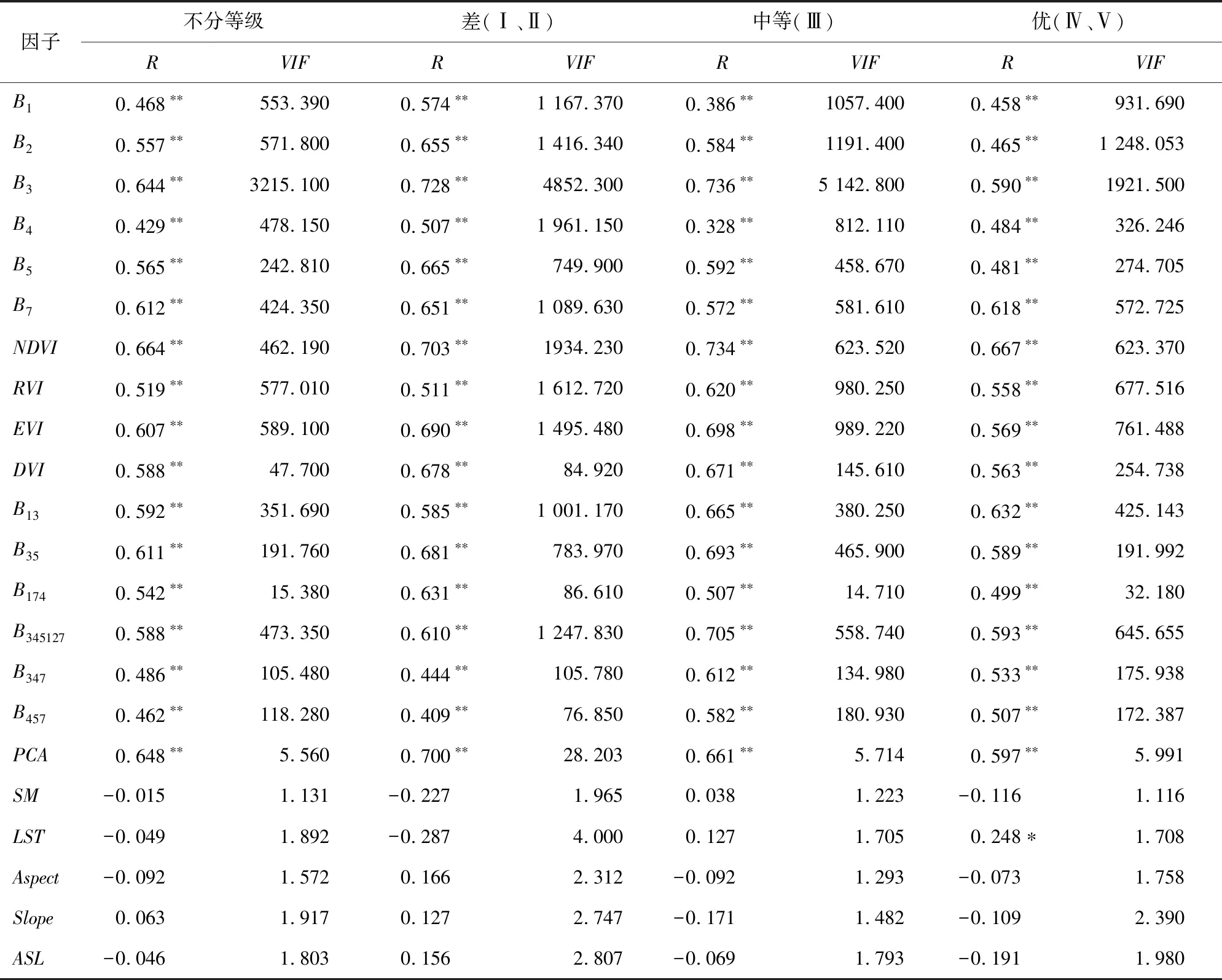
表4 不同立地質量等級的變量因子相關信息Tab.4 Information about the selected variable factors of different site qualities
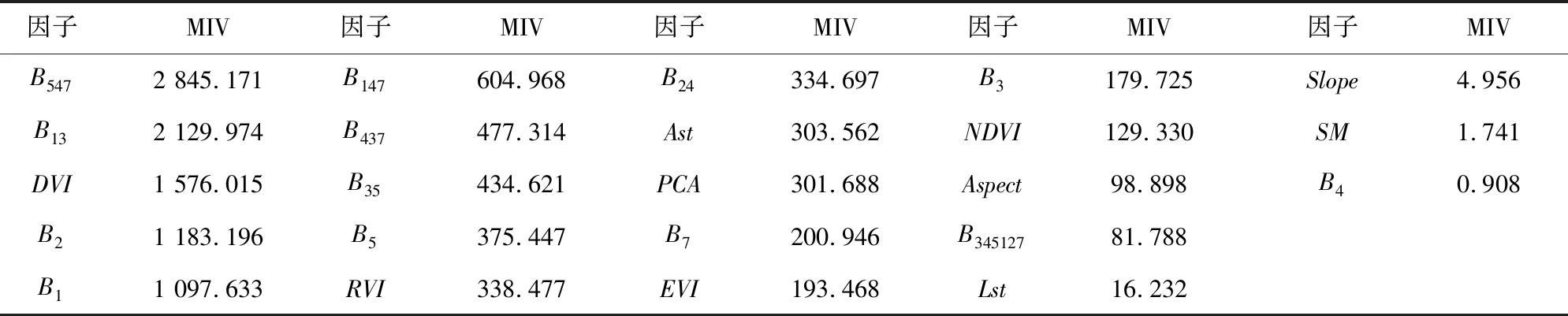
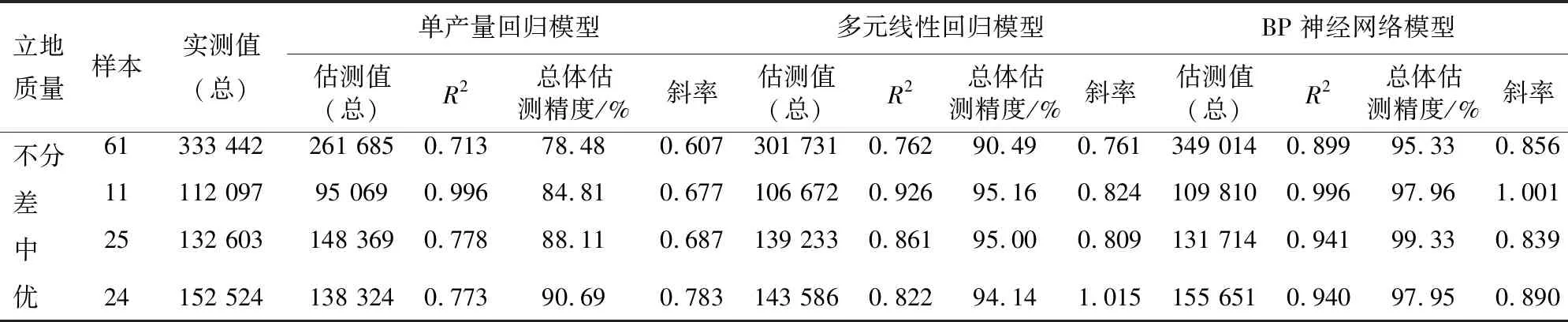
注:1.**表示其達到了0.01的顯著性水平,*表示其達到了0.05的顯著性水平。2.VIF值表示自變量觀察值之間復共線性程度,VIF越大代表共線性越顯著。一般來說:當0 應用回歸分析處理實際問題時,逐步回歸是一種最常用的選擇回歸變量的方法。但由于這種方法不計算所有可能性,因此得到的變量子集只是局部“最優”,可能會遺漏全局最優的變量子集。因此,本研究選用所有子集回歸法,即若有m個可供選擇的變量,那么所有可能的回歸方程就有2m個,然后利用選元準則挑出最優的方程。常見的選元準則有Cp統計量、自由度調整復決定系數和赤池信息量等。本研究的目的是建立預測模型,故運用使預測值的均方根誤差盡量小的Cp統計量[18-19]。馬洛斯(Mallows)[20]從預測的角度提出了用Cp統計量來選擇自變量。設n為樣本數,SSEp表示p個變量模型的殘差平方和,則 (2) 使用SAS軟件進行最優子集的選擇,取Cp統計量作為準則進行所有子集回歸,得到森林蓄積量預測的最優子集,如表5所示。 表5 各立地質量等級的最優子集Tab.5 Optimal subset of each site quality grades 2.3.2 基于平均貢獻值(MIV)的因子篩選 平均貢獻值(mean impact value,MIV)方法選擇神經網絡輸入變量,用于確定輸入神經元對應變量的影響大小,其符號代表相關的方向,絕對值大小代表影響的相對重要性。具體過程為:首先,在網絡訓練終止后,將訓練樣本P中每一個自變量特征在其原值基礎上分別加、減10%構成新的樣本P1和P2,將P1、P2分別作為仿真樣本利用已經建成的網絡進行仿真,得到仿真結果A1和A2,求出A1和A2的差值,即得出該自變量對于因變量的MIV值;其次,根據MIV絕對值的大小為各自變量排序,得到各自變量對網絡輸出影響相對重要性的位次表;最后,根據位次采用逐步剔除法實現變量的篩選。由于BP神經網絡的權重是隨機得到的,每次訓練生成的MIV值不同,故選取10次計算的均值作為變量的MIV值。使用MATLAB的神經網絡工具,構建一個簡單的神經網絡,并實現各因子的MIV值計算,結果如表6所示。 表6 各因子對網絡的平均貢獻值(MIV)Tab.6 Mean impact value (MIV) of each factor on the network 首先進行單產量的回歸,以小班的計蓄積量為因變量、小班提取的TM影像第一主成分遙感因子為自變量,對紅松區區分立地質量等級和不區分立地質量兩種辦法分別建立蓄積量估算模型。根據散點圖分布,選取線性函數和冪函數兩種模型。各個模型的擬合結果如表7所示。 綜合對比可見,無論是何種建模方法,模型的P值都小于0.01,通過了0.01的顯著性水平檢驗,且均通過了F檢驗,說明森林的蓄積量和TM影像的第一主成分之間存在較好的回歸關系。其中,冪函數模型的決定系數均在0.6以上,最高為0.707,較普通線性模型有著顯著的提高。另外,基于不同立地質量的模型較不區分立地質量的模型效果略有提升,但提升并不顯著。 可見,同等條件下,相較于單產量回歸模型,多元線性模型的R2有明顯的提高。特別是基于不同立地質量等級進行建模時,模型的擬合效果顯著提升,R2分別從0.707、0.620、0.601提升到0.819、0.720、0.712,這一現象表明基于不同立地質量等級分別對森林蓄積量進行建模中的有效性,且遙感因子與森林蓄積量之間存在復雜的關系。為進一步挖掘數據中存在的非線性關系,引進了處理非線性問題表現良好的BP神經網絡技術。 表7 單產量因子的回歸擬合結果Tab.7 Fitting result of each variable factor 表8 森林蓄積量的多元回歸結果Tab.8 Multiple regression result of forest stock volume BP神經網絡是當前應用最廣泛的神經網絡模型之一,是一種按照誤差逆向傳播算法訓練的多層前饋神經網絡,具有任意復雜的模式分類能力和優良的多維函數映射能力,可以很好地處理非線性問題[21]。 利用神經網絡建模的過程分為數據預處理、網絡訓練、調參、網絡再訓練、模型評價等5個階段。首先,將數據進行歸一化以消除量綱的影響;然后進行網絡結構的設計,網絡共3層,分別是輸入層、隱含層和輸出層;使用控制變量法分別對比不同傳遞函數、不同訓練函數、不同神經元數等各種網絡參數下網絡的表現,經多次訓練、調參,得到各立地質量等級的網絡結構及其在訓練集上的系數。其中,模型的傳遞函數均選擇Purelin函數,立地質量為差的數據因樣本較少,選擇Trainlm為訓練函數,其他類別使用的訓練函數為Trainrp。模型以網絡擬合的均方誤差(mean squared error, MSE)為目標損失函數。各模型的網絡結構均已在表9中說明。模型的迭代次數設置為1 000次,每個實驗重復10次,取10次訓練的MSE的均值及其標準差,如表9所示。 可見,利用神經網絡技術對不同立地質量的數據進行建模時,模型的均方誤差可以收斂于更小的水平,模型的擬合性能得到顯著改善。為全面對比分析模型效果,下面進行模型對比驗證。 表9 不同立地質量的神經網絡模型及訓練參數Tab.9 Neural network model and training parameters of different site qualities 采用隨機預留的驗證數據驗證模型的精度,將驗證集數據應用到模型,得到森林蓄積量的估測值。將估測值與實際蓄積量之間進行線性擬合,得到的R2、斜率及其總體估計精度作為精度評價指標,完成模型的精度檢驗。其中,曲線斜率越接近1代表預測值和實測誤差越小,總體估計精度(P)的計算公式為: (3) 檢驗結果如圖4和表10所示。綜合對比以上驗證結果,可見: 1) 模型預測值與實測值之間的R2均達0.7以上,總體估測精度在78%以上,使用遙感影像可以較好地預測森林蓄積量,其中,多自變量模型的預測效果要遠好于單產量模型; 2) BP神經網絡模型表現要好于單產量回歸和多元線性回歸模型,其預測值和實測值的R2均達到0.9及以上,曲線斜率也更接近于1,總體預測精度也大大提升,達到了95%以上; 3) 基于不同立地質量等級進行建模,無論采用何種建模方式,較不區分立地質量時,預測精度、R2都有顯著的提升。特別是BP神經網絡模型的總體預測精度在97%以上,R2達到了0.94以上,達到了很高的預測水平。由此可見基于不同立地質量建立森林蓄積量估算模型的思路是正確的,在同等條件下可以使模型性能得到顯著的提升。 表10 不同立地質量模型的精度評價結果Tab.10 Accuracy evaluation results of different site quality models 本研究以2009年涼水自然保護區二類森林調查數據,結合2009年該地區的TM影像,以各小班面積上遙感因子的信息總量為自變量,各小班的計蓄積量為因變量,對紅松建立不分立地質量和區分立地質量等級的森林蓄積量遙感估算模型。得到以下結論: 1) 采用地位級法對森林的立地質量進行評定,將各個小班數據分別劃分為3種立地質量等級,然后基于不同立地質量等級的數據分別建模,蓄積量預測精度顯著改善; 2) BP神經網絡具有很強的非線性處理能力,基于不同立地質量等級建立的模型經過反復調參之后總體預測精度可達97%以上,模型可以很好地跟蹤實測值,較單產量回歸模型和多元線性回歸模型具有更強的預測能力。 模型適用于黑龍江省伊春市涼水自然保護區紅松林蓄積量預測,對其他優勢樹種的小班是否有效還有待探討,立地質量的劃分和建模方法的選擇可為之提供借鑒。建模所需樣本數目有限,為了提高估測模型穩定性和預測能力,還應考慮增加樣本數。 圖4 各模型預測值與實測值的精度對比與驗證Fig.4 Comparison and verification of the accuracy of predicted and measured values of each model

3 蓄積量估測模型的建立
3.1 基于回歸分析的森林蓄積量估測模型


3.2 基于BP神經網絡的蓄積量預測模型

3.3 預測模型對比與驗證
4 結論與展望
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2019年2期)2019-08-23 08:12:08
產品可靠性報告(2017年7期)2017-09-05 09:49:12
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車觀察(2016年3期)2016-02-28 13:16:26
核科學與工程(2015年4期)2015-09-26 11:59:03
