基于改進損失函數的YOLOv3網絡①
2019-04-10 05:06:36呂鑠,蔡烜,馮瑞
計算機系統應用 2019年2期
呂 鑠,蔡 烜,馮 瑞
1(復旦大學 計算機科學技術學院,上海 201203)
2(上海視頻技術與系統工程研究中心,上海 201203)
3(復旦大學 智能信息處理實驗室,上海 201203)
4(公安部第三研究所物聯網技術研發中心,上海 201204)
目標檢測具有廣闊的發展前景和巨大的商業價值,已經成為國內外相關從業者的研究熱點,在智能安防、自動駕駛等領域具有廣泛應用.經典的目標檢測方法有Dalal于2005年提出的基于HOG特征的檢測方法[1],Felzenswalb等人于2008年提出的可變行組件模型(Deformable Part Model,DPM)檢測方法[2],該方法先利用梯度算子計算出目標物體的HOG特征并采用滑動窗口+SVM的方法進行分類,在目標檢測問題中表現良好.
與經典方法相比,深度神經網絡提取特征能力強,準確率高,在計算機文本、圖像分析等領域取得令人矚目的成果,受益于深度學習的快速發展,基于卷積神經網絡(CNN)的目標檢測模型層出不窮,檢測效果不斷提升,Girshick R等人于2014年提出R-CNN網絡[3],采用選擇性搜索(selective search)方法代替傳統的滑動窗口,將VOC2012數據集上目標檢測平均準確率(mean Average Precision,mAP)提高了30%;Girshick R和Ren SQ等人相繼提出了Fast R-CNN[4]與Faster R-CNN[5]網絡,Faster R-CNN采用區域推薦網絡(Region Proposal Network,RPN)生成候選框,再對這些候選框進行分類和坐標回歸,檢測精度大幅提升,檢測速度約5 fps,這些方法由于生成候選框和進行預測分成兩個步驟進行,所以稱為為Two-Stage方法,同時進行這兩種操作的網絡稱為One-Stage方法,代表有YOLO[6],SSD[7]等.2016年Redmon J等提出YOLO網絡,其特點是將生成候選框與分類回歸合并成一個步驟,預測時特征圖被分成S×S(S為常數,在YOLOv1中取7)個cell,對每個cell進行預測,這就大大降低了計算復雜度,加快了目標檢測的速度,幀率最高可達45 fps,之后,Redmon J再次提出了YOLOv2[8],與前代相比,在VOC2007測試集上的mAP由67.4%提高到76.8%,然而由于一個cell只負責預測一個物體,面對被遮擋目標的識別表現不夠好.2018年4月,YOLO發布第三個版本YOLOv3[9],在COCO數據集上的mAP-50由YOLOv2的44.0%提高到57.9%,與mAP61.1%的RetinaNet[10]相比,RetinaNet在輸入尺寸500×500的情況下檢測速度約98 ms/幀,而YOLOv3在輸入尺寸416×416時檢測速度可達29 ms/幀,在保證速度的前提下,達到了很高的準確率.
為了實現實時分析的目標,本文針對One-Stage方法的代表YOLOv3網絡模型進行研究和改進,根據坐標預測值和Sigmoid函數的特殊性質,將原版的損失函數進行優化,不僅減少了梯度消失的情況,而且可以使網絡收斂更加快速,同時通過分析數據集中目標的分布情況修正anchor box,使得anchor box更加符合目標尺寸,增強收斂效果,在Pascal VOC[11]數據集上的實驗表明,在不影響檢測速度的情況下準確率提高了1個百分點左右,且收斂速度變快,使目標檢測能力進一步提升.
1 傳統YOLOv3網絡
YOLO網絡將目標檢測問題轉化為回歸問題,合并分類和定位任務到一個步驟,直接預測物體的位置及類別,檢測速度可以滿足實時分析的要求.YOLOv3包含了新的特征提取網絡Darknet-53,以及三種尺度的YOLO層,也就是預測層.通過在三種尺度上進行預測的方法,有效的增強了對不同大小物體及被遮擋物體的檢測效果,并引入躍層連接以強化收斂效果,同時采用隨機多尺度訓練的方式增強了魯棒性.
1.1 檢測過程
YOLOv3提出了新的提取圖片特征的網絡Darknet53,作為全卷積網絡,darknet53主要由卷積層、Batch Normalization及躍層連接組成,激活函數采用LeakyRelu,其網絡結構如圖1所示.

圖1 YOLOv3的網絡結構
YOLO卷積層負責輸出檢測結果,包括目標的中心位置xy,寬高wh,置信度,以及類別,這種檢測分別在三個尺度上進行,13×13,26×26,52×52,通道數為3,也就是每個box負責對三個anchor box進行回歸,取其中的一個作為最終檢測結果,共對9個anchor box進行回歸,所以對于一張輸入圖像,最后的輸出尺寸為1×(3×(13×13+26×26+52×52))×(5+k)=1×10647×(5+k),k代表類別數,在COCO數據集上為80,VOC數據集上為20,如圖2所示.
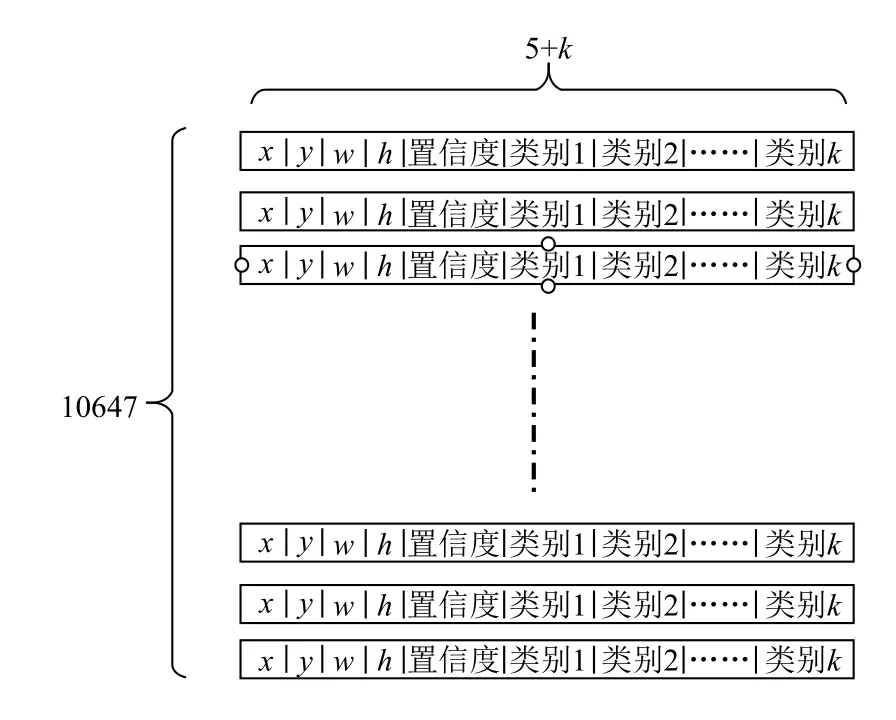
圖2 YOLOv3網絡的輸出格式
在YOLOv1版本中,x,y,w,h是直接預測物體實際值,預測值的微小變化都會被放大到整個圖像的范圍,導致坐標波動較大,預測不準確.YOLOv2對其進行了改進,其公式為:
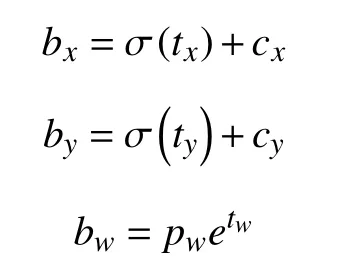
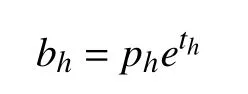
其中,tx,ty為網絡預測值,經過Sigmoid運算將其縮放到0和1之間,tw,th也為網絡預測值,無需Sigmoid;cx,cy為cell坐標,也就是距離左上角的偏移量;pw,ph代表該cell對應anchor box的寬高,計算出bounding box的位置,如圖3所示.通過對confidence這一項設定閾值,過濾掉低分的預測框,然后對剩下的預測框執行非極大值抑制(Non Maximum Suppression,NMS)處理,得到網絡最終的預測結果.
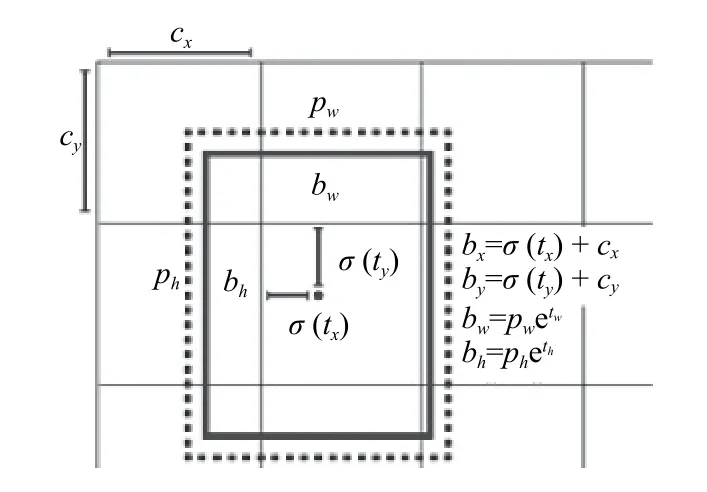
圖3 YOLOv3的bounding box坐標轉換公式
1.2 損失函數
對于YOLOv3的損失函數,Redmon J在論文中并沒有進行講解,本文作者根據對Darknet,也就是Redmon J實現YOLOv3網絡的平臺的源代碼進行解讀,總結出YOLOv3網絡的損失函數為:

其主要分為三大部分,坐標損失,置信度損失及分類損失,λobj在該cell存在物體時為1,其他cell為0,且均采用SSE計算,最終Loss采用和的形式而不是平均Loss,主要原因為預測的特殊機制,造成正負樣本比巨大,尤其是置信度損失部分,以一片包含一個目標為例,置信度部分的正負樣本比可以高達1:10646,如果采用平均損失,會使損失趨近于0,網絡預測變為全零,失去預測能力.并且,根據作者描述,Lin TY等提出的,用于解決正負樣本不均衡,使得網絡專注于困難樣本計算的Focal Loss無法解決這個問題,會導致mAP下降.
2 模型訓練與改進
2.1 Anchor參數設定
PASCAL VOC數據集是目標分類、檢測等常用的數據集,通過模型在VOC2007 test部分的表現衡量目標檢測模型的性能已經成為常用的驗證方法,在實際訓練過程中,一般使用VOC2012的全部樣本及VOC2007的train及val部分樣本作為訓練集,VOC2007 test部分作為測試集,本文也是如此.訓練集部分包含圖片16 551張,物體40 058個,測試集包含圖片4952張,物體12 032個.根據標簽數據,對訓練集的物體寬高進行分析,其分布情況如圖4所示,可以發現VOC數據集中較小目標占比較大.
作為聚類算法的一種,K-means具備簡潔快速,易于實現的優點,應用非常廣泛,其基本思想是以空間中K個點作為形心,將最靠近他們的點進行歸類,然后迭代更新這K個點的值,直到K個值不再變化或達到最大迭代次數.本文使用K-means算法對VOC數據集進行分析,結果如圖5,縱坐標表示平均畸變程度,越小說明類內距離越小,根據肘部法則選擇K值為9,并確定相應的anchor box.
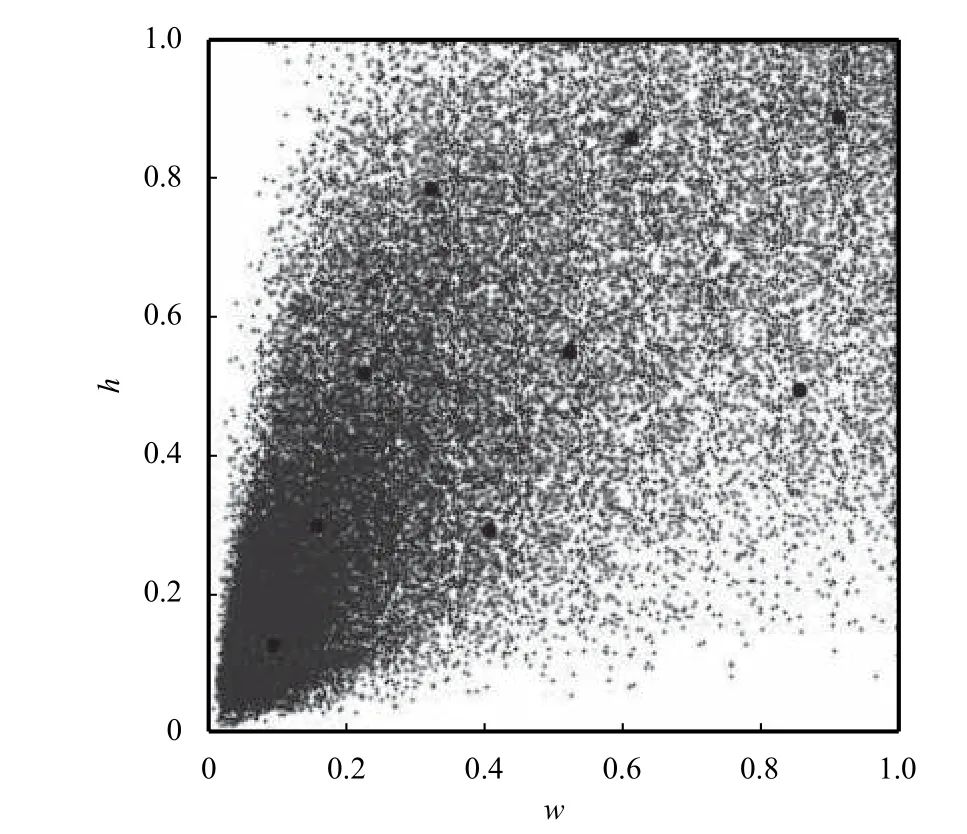
圖4 VOC物體寬高分布情況,大點為聚類結果
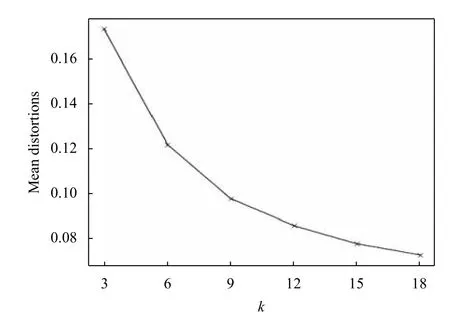
圖5 K-means聚類分析結果
2.2 損失函數分析
作為深度神經網絡對誤檢測樣本進行懲罰的根據,損失函數可以在很大程度上影響模型收斂的效果,如何設計更合適的損失函數以獲得更好地預測效果也成為模型優化的重要方向,學界對此也進行了很多研究[12,13].在YOLOv3網絡的最終輸出中,x,y,物體置信度以及類別置信度部分均經過Sigmoid函數激活,然后采用SSE計算最終損失,從Sigmoid函數的導數圖像(圖6)可以看到,當神經網絡的輸出較大時,(x)會變得非常小,此時使用平方誤差得到的誤差值很小,導致網絡收斂很慢,出現誤差越大收斂越慢,也就是梯度消失的情況,為了解決這個問題,當真實值只能取0或1時,一個常用的方法是采用交叉熵(cross-entropy)損失函數,其形式為:
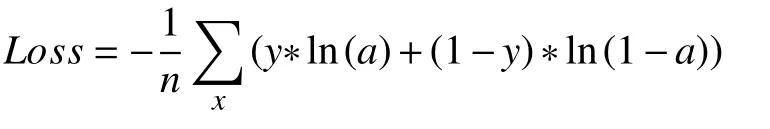
a代表神經網絡經過Sigmoid以后的輸出值,也就是a=σ(ωx+b),令z=ωx+b,可以計算出交叉熵函數的導數.
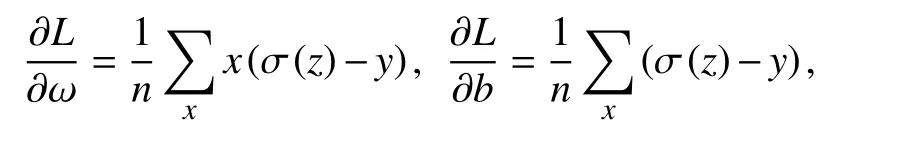
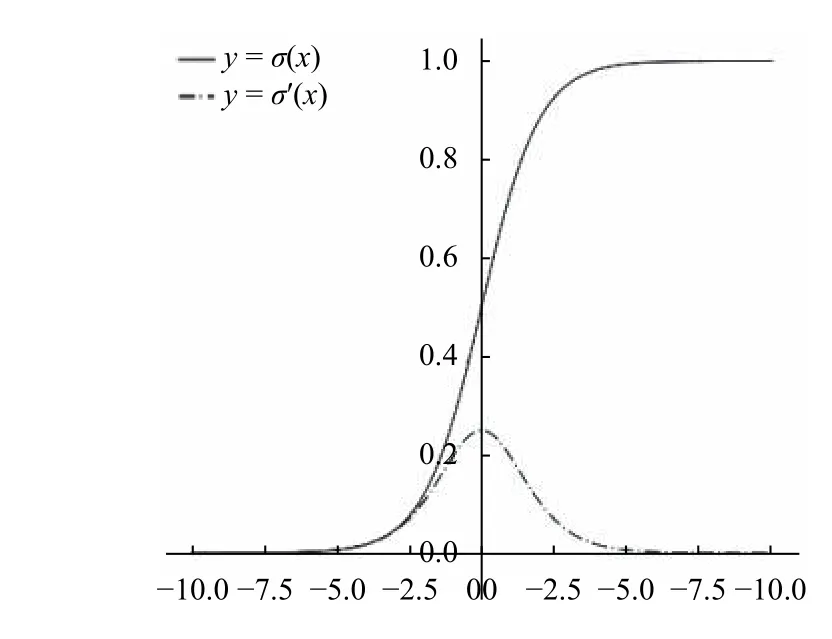
圖6 Sigmoid函數及其導數
特別的,對于predx和predy的輸出,它們的真實值并不是0或1,而是0和1之間的某個值,也就是說predx,predy并不是離散變量,以truthx=predx=0.7為例,交叉熵損失為 -0.7 ln(0.7)-0.3 ln(0.3)≈0.61,不為0,所以不能采用交叉熵損失函數.
通過以上分析可知,損失函數的導數形式f(x)需要具備以下性質: ①f(x)的定義域為x2(-1,1),值域f(x)2(-1,1);②f(x)為 單調遞增函數,且f(0)=0;③f(x)的 圖像需要關于坐標原點對稱;④(x)≠0.因此,本文設計了一種新的損失函數,稱為tan方損失(Tan-Squared Error,TSE),導數形式為LossGrad=tan(t-σ(z))/tan(1),在YOLOv3中,t-σ(z)2(-1,1),由于t也是不定項,此差值與σ(z)本 身的取值無關,令x=t-σ(z),作出 函數圖像如圖7.
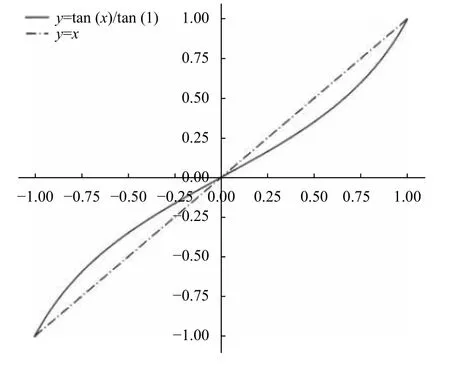
圖7 TSE與SSE導數圖像
在本網絡的訓練過程中,由于極其巨大的正負樣本比,訓練開始時會難以避免地出現網絡輸出全零的情況,此時負樣本部分,也就是真實值為0的部分,其誤差逼近于0,而真實值為1的部分,誤差則非常的大,對于predx和predy來說,差值更是為(-1,1),而不是常見的(0,1),作者采用平方損失進行計算,并且是定義了梯度值的計算方法,也就是直接使用公式grad=tx-predx進行梯度計算,這也正是平方損失函數的導數形式,遵循同樣的思路,本文定義了TSE導數形式的計算公式,通過TSE與SSE的圖像(圖7)可以直觀地看出,TSE與SSE導數的值域均為(-1,1),并且TSE導數的絕對值要小于SSE,也就是說對于較大的誤差,可以將它進行適當地縮小,這樣當梯度傳播到Sigmoid函數時,可以使小幅度地增大,加快初始時的收斂速度,減小梯度消失的影響;同樣的,對于誤差已經逼近0的情況,由于TSE要略微小于SSE,可以使輸出層權重的調整幅度更小,使模型得到更好收斂.這種調整也應該控制在一個較小的幅度,防止對輸出層的權重作出過大的調整,導致模型不收斂或者發散的情形.對兩函數求導,得到他們的導數圖像如圖8.
可以看到,TSE導數的值域約為(-2.2,2.2),即使誤差極大導數也在有限范圍內,并且最小值約為0.64,不會出現梯度為0從而導致梯度消失.不同于SSE的常數梯度值,TSE的梯度會隨著誤差的變化而變化,具有誤差大時梯度大,誤差小時梯度小的性質,既能在誤差較大時加大權重的調整,也在誤差減小以后,以更小的變化率調整權重,使網絡模型可以收斂得更好,這是對 于連續變量predx和predyTSE所具有的優勢.

圖8 TSE與SSE導數的梯度變化
2.3 調整幅度驗證
對預測損失值的大小進行控制可以增強反向傳播時卷積層權重調整的效果,TSE控制梯度變化的幅度是否合適也需要驗證.將TSE與梯度調整幅度更大的損失函數進行對比,其導數形式為:
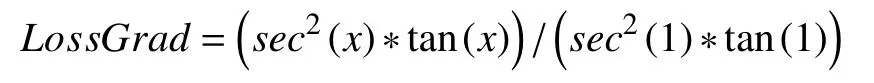
從它與TSE的對比圖像如圖9.
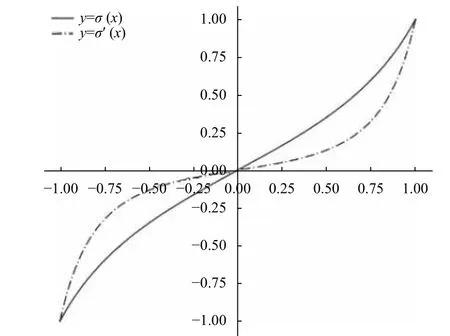
圖9 TSE與另一函數對比
從圖9可以看出: 該函數在訓練的初期可以對損失進行更大幅度的調整,理論上來講可以更大程度地減少梯度消失的情況,使得預測層梯度保持在一個較大的數值.在實際的實驗過程中,訓練的初始階段Loss下降得非常快,正樣本的置信度上升速度也加快了很多,但是由于誤差靠近0時梯度的過度減小,負樣本的置信度未能得到有效下降,訓練后期梯度消失的現象也導致正負樣本沒有被很好地區分開,模型收斂效果變差,最終的mAP很低;而且由于采用較大的學習率,訓練中也出現了預測值變為Nan的情況,說明過大的調整幅度也可能導致梯度發散.
3 實驗結果
在Pascal VOC數據集上進行實驗,使用兩塊1080TI的顯卡,顯存為2×12 GB,CPU為Intel Xeon E5-2620 V4@2.10 GHz,軟件環境為cuda9.0 + cudnn7,訓練集為VOC07+12,測試集為07 test-dev,由于作者并未公布相關的mAP數據,本文直接使用作者提供的訓練配置文件進行訓練,總計訓練了50 000個batch,除了更換損失函數和修改anchor box外不作其他改動,結果如表1所示.

表1 VOC數據集訓練結果
由于本實驗的主要目的是驗證TSE的有效性,作者并沒有對訓練時的超參數進行仔細調參,不保證該mAP一定為YOLOv3網絡模型在VOC數據集上可以達到的最高值.通過最終的mAP值可以表明,只是改用TSE就可以得到1個百分點左右的提升,TSE可以使網絡獲得更好地收斂效果.
為了驗證TSE相比于SSE在收斂速度方面所獲得的優勢,采取每10 000個batch保存一次模型的方式,收集了5個階段的mAP數據,如圖9所示,可以看出,在訓練10 000個batch時,TSE就可以比SSE取得更高的mAP值,并且在30 000個batch時mAP就達到了SSE訓練40 000個batch的水平,說明使用TSE可以使網絡收斂得更加快速.當訓練40 000個batch以后,學習率被減少為原來的1/10,模型進一步收斂,mAP獲得了比較大的提升,并且受益于TSE的函數性質,模型獲得了1個百分點左右的mAP提升.
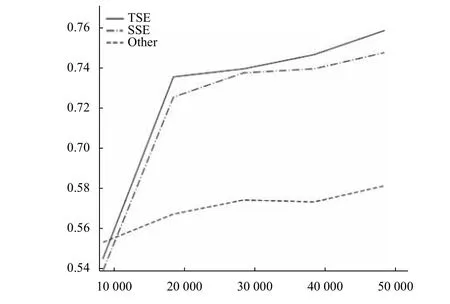
圖10 三種方法訓練的mAP
4 總結與展望
4.1 本文工作總結
本文分析了YOLOv3模型的結構,并且對它實際的訓練應用過程做出了有益嘗試.通過對原版損失函數特點的分析,提出了一種新的損失函數TSE,在VOC數據集上的實驗結果表明: ① 與SSE相比,TSE適用于連續變量的情況,減少了梯度消失的情況,mAP穩步提升;② 模型的收斂速度得到提升,能夠使訓練所需輪數減少,節省訓練所需時間;③ 對比實驗表明TSE進行梯度調整的幅度比較合適,可以在保證正負樣本區分度的基礎上有效增強正樣本的置信度.基于改進損失函數的網絡模型取得1個百分點左右的mAP提升,獲得了更好的檢測效果.
目前,YOLO系列網絡由于其檢測快速的優點,已經在實際生產中獲得了大量應用.如鄭志強等將YOLO網絡應用于遙感圖像的飛機識別[14],王福建等將YOLO網絡應用于車輛信息的快速檢測[15],蔡成濤等基于YOLO網絡實現機場跑道目標的快速檢測[16],都取得了非常好的效果,本文提出的方法適用面廣,通用性強,可以很好地應用于現有的YOLO檢測系統中,獲得更為準確的檢測效果,使系統性能獲得進一步增強.
4.2 未來工作展望
本文從損失函數的角度,提出了現有網絡的改進方法.在下一步的研究工作中,將會在更多其他的網絡模型中,采用更大規模的數據集如MSCOCO[17]等,用以驗證TSE的通用性與魯棒性;同時也對連續變量的梯度控制問題,尋求更好的解決方案;另外,針對于網絡結構本身的改進,如何設計出性能更強的網絡來提取圖像特征,也需要更加細致地研究.

圖11 檢測結果示例
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
