在線醫(yī)療問答文本的命名實體識別①
2019-04-10 05:06:38楊文明褚偉杰
計算機系統(tǒng)應用 2019年2期
楊文明,褚偉杰
(北京大學 軟件與微電子學院,北京 102600)
通訊作者: 褚偉杰,E-mail: chuwj@ss.pku.edu.cn
1 引言
伴隨互聯(lián)網和大數據技術的發(fā)展,很多患者在感到身體不適時,首先會到醫(yī)療問答網站上提問和查詢疾病相關的問題,同時許多醫(yī)生也會到醫(yī)療問答網站去回答患者的疑問,這類網站已經成為聯(lián)系患者和醫(yī)生之間的樞紐.在線醫(yī)療問答社區(qū)的發(fā)展使得我們獲取醫(yī)學知識的渠道多樣化,有助于患者了解自己的健康狀況,同時也有助于健康醫(yī)學知識的普及.國內如39健康網,尋醫(yī)問藥,春雨醫(yī)生等網站,不僅提供基礎的疾病知識和醫(yī)學知識,而且每天還積累了大量的問答數據,這些醫(yī)療文本數據中包含大量有意義的信息,如尋醫(yī)問藥從2004年開始一直到現(xiàn)在,已經積累了大量真實的信息,并且每天都在產生數萬條的問答數據.這些醫(yī)療文本數據將匯聚成非常客觀的大數據,數據中包含有大量的真實案例和醫(yī)生的診療建議.在這些數據中蘊含著比較豐富的醫(yī)療價值.但這些數據是非結構化的狀態(tài),無法進行更深的數據挖掘,實現(xiàn)數據的充分利用.為了更好的利用這類數據,抽取和挖掘更有價值的醫(yī)療信息,需要把非結構化的數據進行結構化,而命名實體識別是結構化文本中的第一步,而且該類文本的命名實體識別可以為醫(yī)療問答的研究和應用打好基礎.本文利用醫(yī)療問答網站積累的數據,進行了命名實體識別的研究.
2 命名實體識別相關研究
實體是文本的基本信息元素,是構成文本的基礎.命名實體識別(Named Entity Recognition,NER)是自然語言處理的一項基本任務,主要是從一段文本中找出實體,并對實體出現(xiàn)的位置和類別進行標記.NER概念的提出是在MUC-6(Message Understanding Conference)會議上[1],最初的提出是作為信息提取的重要任務之一.通用的命名實體識別任務,主要是在一段文本中識別出人名,地名,專業(yè)機構,時間和數字(貨幣,百分數)等.在特定的領域,可以用來識別特殊領域的實體如醫(yī)療領域和金融領域等.命名實體識別技術包括許多不同的方法: 基于詞典和規(guī)則的方法;基于統(tǒng)計學習的方法;還有將二者混合的方法.常見的統(tǒng)計學習的方法有支持向量機(SVM)、最大熵模型、貝葉斯分類等,這些方法把NER任務看成分類問題.此外,還有隱馬爾可夫模型(HMM)和條件隨機場(CRF),這類模型把NER任務當做序列標注問題處理.隨著深度學習的發(fā)展,最近幾年出現(xiàn)了大量的基于神經網絡的模型,并取得了較好的效果,最具代表性的是BiLSTMCRF模型[2],該模型在各個公共數據集上均取得了不錯的效果.在RNN的輸出層連接CRF層,這種結構已經成為命名實體識別模型的常用結構.目前對于醫(yī)療文本命名實體識別的研究主要集中在電子病歷,醫(yī)學文獻,醫(yī)學書籍等,而互聯(lián)網醫(yī)療問答社區(qū)文本的研究并不多,國內最近幾年也有研究者開始關注這方面的研究,比如蘇婭等[3]使用CRF在自建數據集上進行研究,抽取的目標實體共5類,分別包括疾病、癥狀、藥品、治療方法和檢查,通過采用逐一添加特征的方式訓練模型,模型精確率達到81.26%,召回率60.18%.張帆等人[4]設計深度神經網絡應用到在線醫(yī)療文本實體識別上,抽取的目標實體也是5類.深度神經網絡模型同CRF等方法相比減少了很多人工特征,并且提高了精確率和召回率.
3 算法模型設計
本文以BiLSTM-CRF作為基準模型,設計了兩種不同的命名實體識別模型,并且在自構建的數據集上進行驗證,均取得了不錯的效果.
3.1 BiLSTM-CRF模型
雙向循環(huán)神經網絡(BiLSTM)由兩個單向的循環(huán)神經網絡構成,兩個網絡中一個隨時間正向,另一個隨時間逆向,逆向網絡的實現(xiàn)本質上把輸入序列進行逆轉,然后輸入到正向網絡中.BiLSTM的優(yōu)勢是可以在當前節(jié)點獲取正反兩個方向的特征信息,即能捕捉到未來信息的特征,也能捕捉到過去信息的特征.但是,兩個方向的循環(huán)神經網絡并不會共享一個隱狀態(tài),正向LSTM的隱狀態(tài)傳給正向的LSTM,逆向LSTM的隱狀態(tài)傳給逆向的LSTM,兩個方向的循環(huán)神經網絡之間沒有連接,兩個輸出會共同連接到輸出節(jié)點合成最終輸出.方向不同的兩個循環(huán)神經網絡,都可以展開成為普通的前饋網絡,使用反向傳播算法(BPTT)進行訓練.雙向循環(huán)神經網絡被用在許多序列標注任務上.
條件隨機場(CRF)模型是一種概率無向圖模型,可以解決序列標注任務,命名實體識別可以看做是序列標注任務,即給定觀察序列X={x1,x2,…,xn}的條件下,求Y的概率.隨機變量Y={y1,y2,…,yn},Y是隱狀態(tài)序列.數學表達式為P(Y|X).在命名實體識別上使用的CRF主要是CRF線性鏈,CRF建模的數學公式如式(1)和(2).

上式中fk是特征函數,wk是特征函數的權重,Z(x)是歸一化因子.條件隨機場可以看成是定義在序列上的對數線性模型,能夠使用極大似然估計方法求參數.目前已經有了一些優(yōu)化算法進行該問題的求解,比如梯度下降法,改進的迭代尺度法和擬牛頓法等.模型在進行解碼時可以利用維特比算法,這是一種動態(tài)規(guī)劃算法,在給定觀察序列的條件下,求出最大的標記序列的概率.BiLSTM與CRF的結合,本質上是把BiLSTM的輸出作為CRF的輸入,BiLSTM層輸出的是每一個標簽的預測分值,這些分值會輸入到CRF層.其過程可描述為利用BiLSTM解決提取序列特征,再使用CRF利用句子級別的標記信息進行訓練,單獨使用BiLSTM也可以完成命名實體識別,可以從BiLSTM的輸出中挑選最大值對應的標簽,作為該單元的標簽,但是這不能保證每次預測的標簽都是合法的,比如對于{B,I,O}體系的標注,標簽序列是“IOrganization I-Person”和“B-Organization I-Person”,很顯然這是錯誤的.如果在BiLSTM的輸出層接入CRF層后,相當于對最后的預測標簽加入了約束,保證輸出的標簽是合法的,這些約束會在訓練的過程學習到,對于BiLSTM-CRF模型的學習方法同樣可以使用極大似然估計方法.
可以把雙向循環(huán)神經網絡的輸出看成打分矩陣,稱為P矩陣.對于輸入語句X=(x1,x2,x3,…,xn),P是一個n×k的矩陣,k是輸出標注y的個數,Pi,j表示句子中第i個詞被標記為第j個標簽的概率.句子的預測標注序列可以表示為:y=(y1,y2,y3,…,yn).定義y矩陣的打分函數的計算式(3).

Ai,j是看成轉移打分矩陣,代表從標注i轉移到標注j的得分.y0和yn分別代表句子開始和結束的標簽,標注矩陣A是一個k+2階的方陣.通過式(4)計算y在給定x下的條件概率p(y|x),其中YX代表對于給定的句子X所有可能的標簽序列,損失函數可以定義為式(5),并在訓練的過程中極大化正確標簽序列概率的對數值.
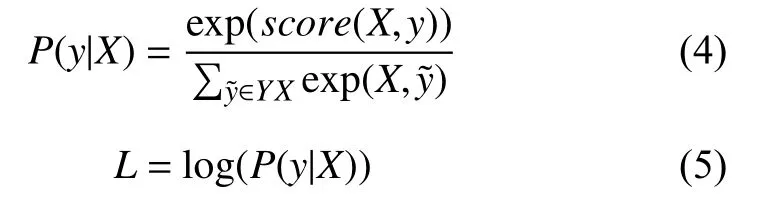
在模型訓練完成后可以通過式(6)進行模型預測,其中y*是集合中使得得分函數score取最大值的序列.
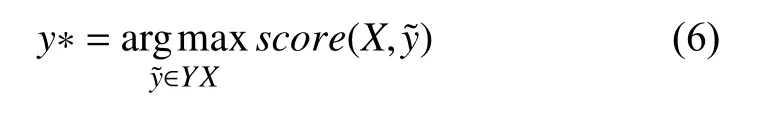
以上是BiLSTM-CRF的基本原理,本文在設計的BiLSTM-CRF模型結構圖如圖1.首先將輸入語句經過一個embedding層,之后連接到BiLSTM層,在BiLSTM層后連接映射層,并進行邏輯回歸,該層的輸出會輸入到下一層CRF層.為了提高模型的泛化能力,在embedding層和BiLSTM層之間加入了droupout層.
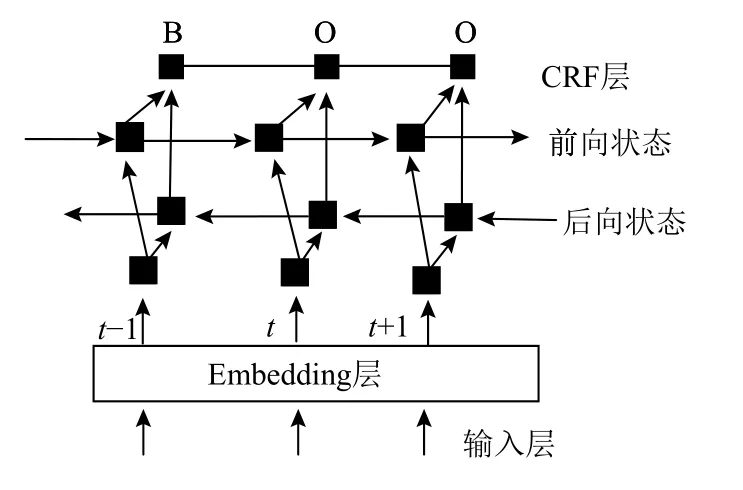
圖1 BiLSTM-CRF模型結構圖
3.2 IndRNN-CRF模型
獨立循環(huán)神經網絡(Independently Recurrent Neural Network,IndRNN)[5]由Li S等人提出,同傳統(tǒng)的RNN不同的是IndRNN的神經元之間是獨立的.傳統(tǒng)的RNN的隱藏層數學公式如式(7),其中W是N×M的矩陣,U是N×N的矩陣,N是RNN中的神經元節(jié)點數.

在傳統(tǒng)的RNN中每個神經元都和上一時刻的全部神經元發(fā)生聯(lián)系(U的行向量與ht-1向量的乘積,ht-1是t-1時刻的隱狀態(tài)),也就是神經元之間是不獨立的.而IndRNN結構神經元之間的連接僅發(fā)生在層與層之間,IndRNN的數學表達式可以在上面式(7)進行改造后得到如式(8).其中U和ht-1是點積,此時的U不是矩陣,而是一個N維的向量,t時刻的每個神經元只和t-1時刻自身相聯(lián)系,與其他的神經元無關.這也是獨立循環(huán)神經網絡名稱的由來.為了在神經元之間發(fā)生聯(lián)系,至少需要進行兩層的堆疊.
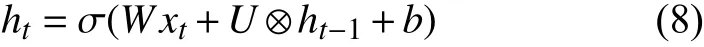
模型中的第n個神經元的隱藏狀態(tài)hn,t,可由式(9)計算得出,其中wn和un分別是輸入權重和t-1到t時刻的連接權重的第n行,每個神經元只接受前一步它自己的隱藏狀態(tài)和輸入傳來的信息.這與傳統(tǒng)的RNN是不同的,這種結構提供了一種循環(huán)神經網絡的新視角,隨著時間的推移(通過u),獨立的聚集空間模式(通過w),不同神經元的相關性可以通過多層堆疊來實現(xiàn),下一層的神經元處理上一層所有神經元的輸出.模型同樣采用梯度后向傳播算法進行優(yōu)化,IndRNN進一步緩解了隨時間累積的梯度爆炸或消失的問題,梯度可以在不同的時間步上有效的傳播,可以使得網絡疊加更深.在本文中,將BiLSTM-CRF模型中的BiLSTM換成多層的IndRNN,提出了一種新的模型Multi-IndRNN-CRF,本文中IndRNN有4層,之后拼接CRF,模型示意圖如圖2,在Embedding層后輸出的數據,會進行dropout,每層IndRNN輸出后都會進行BatchNormalization防止數據發(fā)生嚴重偏移,同時防止梯度爆炸.IndRNN-CRF的損失函數和LSTM-CRF模型一樣,參數的學習方法依然是極大似然估計.
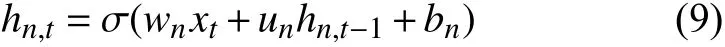
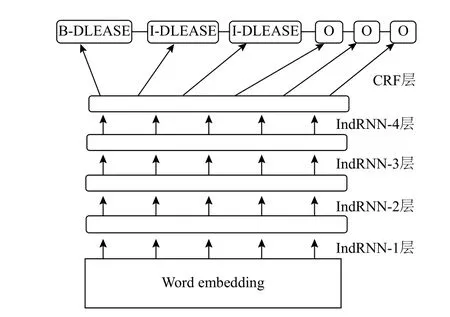
圖2 4-IndRNN-CRF結構圖
3.3 IDCNN-BiLSTM-CRF模型
膨脹卷積(Dilated Convolution,簡稱DCNN)是Yu F,Koltun V在2015年提出的[6],經典卷積的filter,作用在矩陣的一片連續(xù)區(qū)域上做滑動,而膨脹卷積是在filter中增加了膨脹寬度,在輸入矩陣上做滑動時會跳過膨脹寬度中間的數據.filer矩陣大小不變,filter最終獲取到了更廣的輸入矩陣的數據.DCNN的示意圖如圖3.
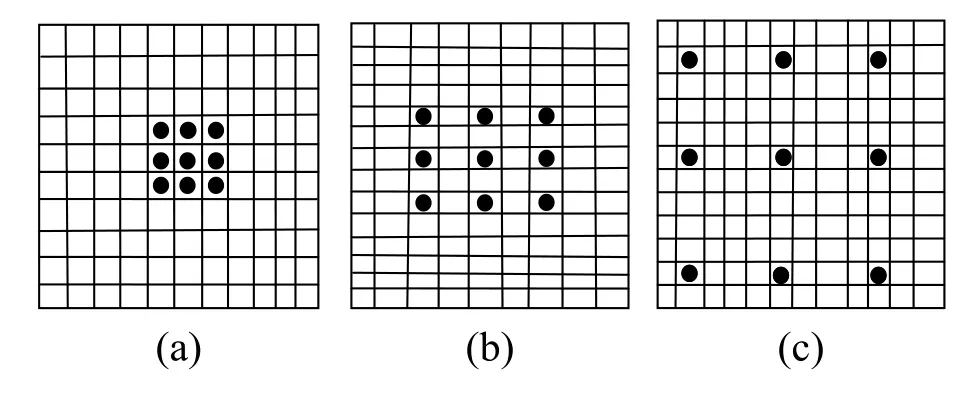
圖3 DCNN示意圖
圖3中的(a)圖對應3×3的1-dilated convolution,同經典的卷積操作一樣;(b)圖對應3×3的2-dilated convolution,卷積核的大小仍然是3×3,空洞大小是1,可以理解成卷積核的大小是7×7,receptive filed是7×7;(c)圖是4-dilated convolution操作,receptive filed是15×15的感受野.
Strubell E等人[7]提出了IDCNN(Iterated Dilated Convolution,IDCNN)模型,用在實體識別任務上取得了不錯的效果.膨脹的寬度隨著層數的增加呈現(xiàn)為指數增加,但參數的數量是線性增加的,這樣接受域很快就覆蓋到了全部的輸入數據.模型是4個大小相同的膨脹卷積塊疊加在一起,每個膨脹卷積塊里的膨脹寬度分別為1,1,2的三層膨脹卷積.把句子輸入到IDCNN模型中,經過卷積層,提取特征,其基本框架同BiLSTM-CER一樣,由IDCNN模型的輸出經過映射層連接到CRF層.
盡管IDCNN模型可以使得接受域擴大,但不會像雙向循環(huán)神經網絡,可以從序列的整體提取正向和反向特征,但循環(huán)神經網絡不能很好的兼顧到局部特征,本文提出模型IDCNN-BiLSTM-CRF既能兼顧全局特征(通過BiLSTM),又能兼顧局部特征(通過IDCNN).
模型的基本結構描述如下: 首先輸入語句經過embedding層,輸出字向量,字向量并行輸入到IDCNN模型和BiLSTM模型,經過兩個模型后,將輸出的向量進行拼接后形成向量特征,然后經過映射層后輸入到CRF層.IDCNN在提取局部特征的同時能夠兼顧到部分全局特征,但不會像BiLSTM能夠很好的提取全局特征,因此將IDCNN輸出的向量特征作為對局部特征的彌補,拼接在BiLSTM的向量特征上,模型示意圖如圖4.其中Dilated CNN block中有三個卷積層,沒有池化層,第一層為1-dilated convolution,第二層為1-dilated convolution,第三層為2-dilated convolution.將4個block(對應圖中的DCNN-i)堆疊,當有數據輸入后.先經過embedding層,然后輸入到DCNN-1,從DCNN-1的輸出有兩個去向,一是與其他DCNN的輸出拼接后形成最終的特征向量,另一個輸出變成DCNN-2的輸入,依次類推.IDCNN模型的輸出和BiLSTM模型的輸出進行拼接后,經過一個映射層,再將值輸入到CRF中,模型圖見圖4.模型的訓練以及參數的學習方法同BiLSTM-CRF.
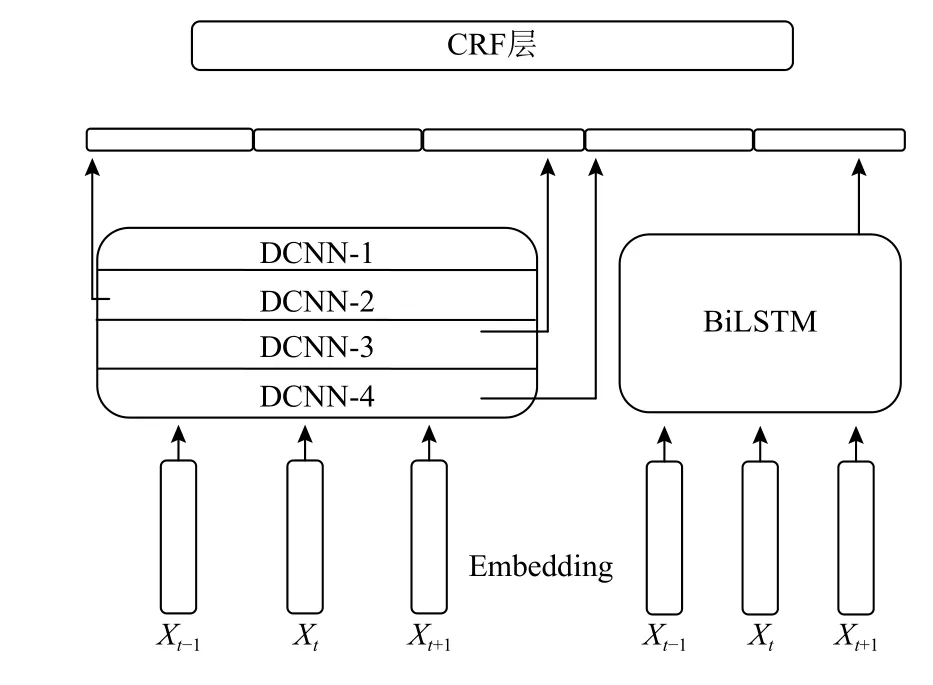
圖4 IDCNN-BiLSTM-CRF模型結構圖
4 數據處理和標注
使用Scrapy框架編寫爬蟲,從醫(yī)療問答網站爬取數據.爬取的網站分別是“尋醫(yī)問藥”,“39健康網”,“快速問醫(yī)生”等網站.在各個網站的問答板塊收集咨詢者的問題,總計收集數據約1200萬條,大約2.27 GB.從收集的數據中挑選8027條數據作為訓練集,1972條作為測試集.采用{B,I,O}標注體系,對醫(yī)療文本進行人工標注,具體格式為B-X,I-X和O.B代表實體開始,I代表實體中間或結束部分,O代表非實體.標注的實體類別參考楊錦峰等人[8]在論文中提出的方案,分為四類實體: 疾病、癥狀、檢查和治療.X代表命名實體的類別,分別為DISEASE、SYMPTOM、TREATMENT、CHECK四個不同的標識,代表疾病、癥狀、治療和檢查.該任務的標記一共有9(=4×2+1)類標簽,在標注時把藥物歸結到治療實體.表1給出了標注的示例.

表1 命名實體類別
實際標注的格式如下: 對于語句“我有點發(fā)燒,渾身無力,是感冒了嗎?”,標注為{O,O,O,B-SYMPTOM,I-SYMPTOM,O,B-SYMPTOM,I-SYMPTOM,ISYMPTOM,I-SYMPTOM,O,O,B-DISEASE,IDISEASE,O,O,O},其中語句中包含的標點符號作為非實體,標注為“O”.
5 實驗結果和分析
5.1 實驗條件
本文實驗是在Linux平臺下使用Python 3.5語言在tensorflow框架進行開發(fā),硬件環(huán)境如下: Intel i7的cpu,16 GB內存以及NVIDIA GTX-1070顯卡.
使用預訓練的字向量對embedding層進行初始化,預訓練字向量的過程如下: 首先將下載的1200萬條問句,按照字級別進行字向量的訓練.訓練的模型使用的是開源工具Word2vec,該工具是Toms Mikolov在2013年開發(fā)的工具包,Word2vec使用CBOW模型[9-11](連續(xù)詞袋模型).對于word2vec參數的設定如下: 字向量的維度設置為200,窗口大小為5,訓練次數為20,其余參數默認.
5.2 模型參數設置
對于BiLSTM-CRF模型參數的設定: BiLSTM的隱層節(jié)點為300,模型中的droupout層參數設置為0.5,采用Adam優(yōu)化算法,學習率設置為0.001,batch size的大小為64,epoch的大小為100.
對于IndRNN-CRF模型參數的設定: IndRNN的隱層節(jié)點為300,共有4層IndRNN,模型中的droupout層參數設置為0.5,采用Adam優(yōu)化算法,學習率設置為0.001,batch size的大小為64,epoch的大小為100.
對于IDCNN-BiLSTM-CRF模型參數的設定:BiLSTM的隱層節(jié)點為300,IDCNN的filter個數為100,模型中的droupout層參數設置為0.5,采用Adam優(yōu)化算法,學習率設置為0.001,batch size的大小為64,epoch的大小為80.
5.3 實驗結果和分析
實驗結果的評價指標有3個,分別為精確率,召回率和F值.計算公式如式(10),(11),(12).

不同模型的實驗結果分別見表2,3和4.
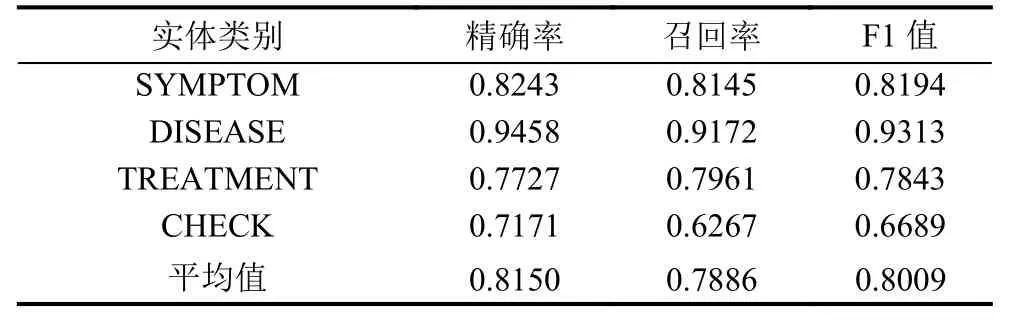
表2 BiLSTM-CRF的實驗結果
對比實驗結果可以看出,IndRNN-CRF模型在精確率上比基準模型BiLSTM-CRF高,召回率的值為0.6848,相比于模型BiLSTM-CRF的召回率比較低.IDCNN-BiLSTM-CRF模型在精確率,召回率和F1值上均超過了基準模型BiLSTM-CRF.圖5,圖6和圖7分別是模型BiLSTM-CRF,IndRNN-CRF和IDCNNBiLSTM-CRF的Loss曲線圖,縱坐標代表Loss值,橫坐標代表的是迭代次數.從圖中可以看出在經過了24 000次的迭代后模型BiLSTM-CRF的Loss值大于2.0,模型IndRNN-CRF和IDCNN-BiLSTM-CRF的loss值小于2.0,其中模型IndRNN-CRF的loss值最低.
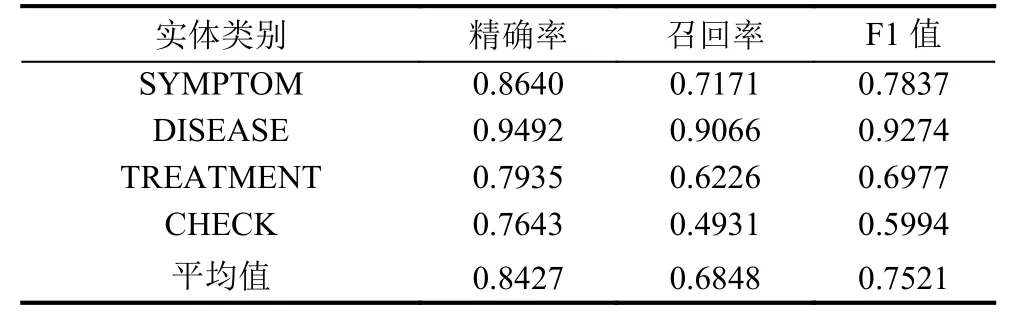
表3 IndRNN-CRF的實驗結果
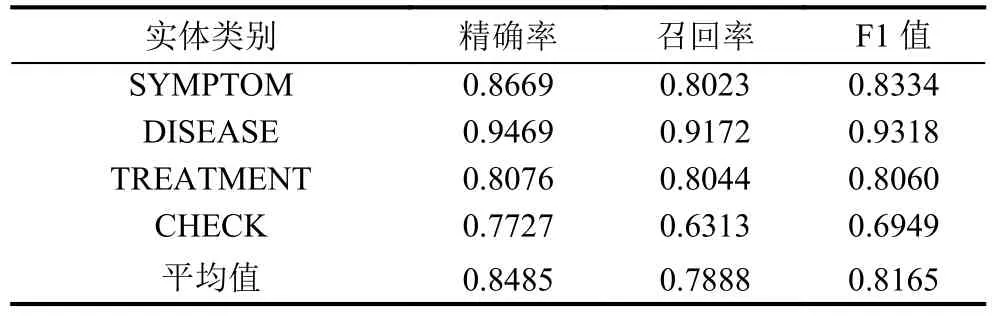
表4 IDCNN-BILSTM-CRF的實驗結果
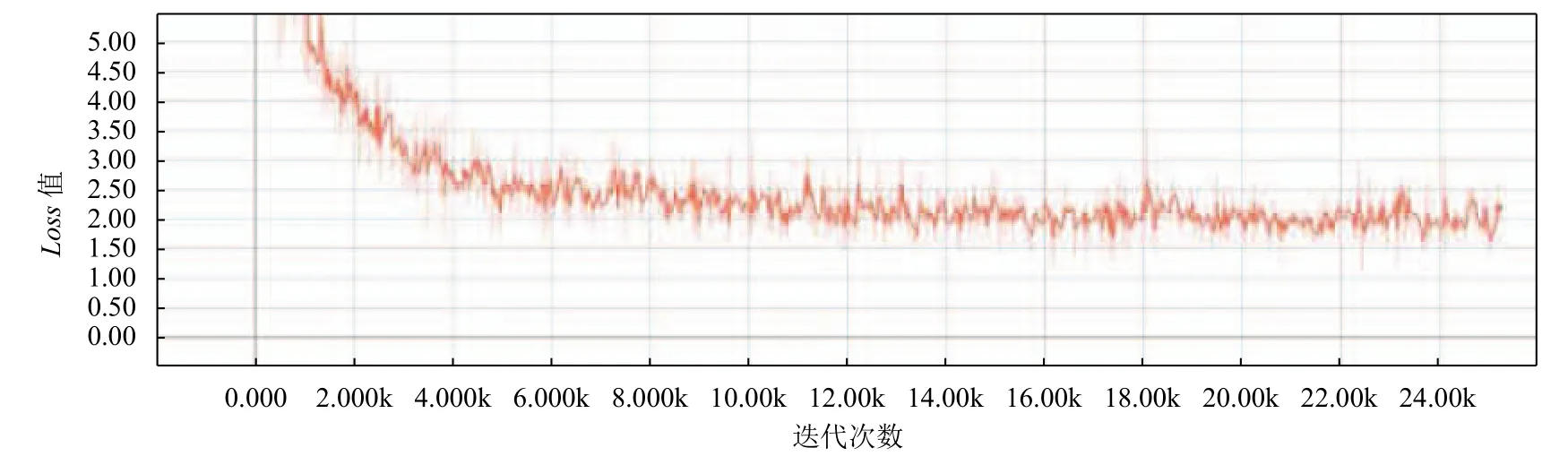
圖5 BiLSTM-CRF的loss-step曲線圖
由于IDCNN-BiLSTM-CRF模型的總體性能最好,可以用在互聯(lián)網在線問診醫(yī)療文本的實體識別上,該模型也可用在醫(yī)學文獻,電子病歷等文本的命名實體識別上.模型IndRNN可以用在對精確率要求較高,但對召回率要求不高的任務中.
6 結論與展望
本文針對在線問診醫(yī)療文本,利用深度學習技術設計了兩種不同的神經網絡模型,進行醫(yī)療文本命名實體識別的研究,共識別4類醫(yī)療實體: 疾病,癥狀,治療和檢查.對基于字級別的命名實體識別任務,在模型IDCNN-BiLSTM-CRF中使用卷積神經網絡和循環(huán)神經網絡提取特征向量,并將兩個特征向量拼接,形成既包含全局特征又包含局部特征的向量,該向量經過映射層后輸入到CRF層中,實驗結果表明該模型的整體性能最好.但是由于醫(yī)療領域的特殊性,仍然需要繼續(xù)提高醫(yī)療實體的識別率,獲取更精確的挖掘結果.在接下來的工作中,可以考慮先對醫(yī)療文本分詞,然后加入詞性或者拼音等特征訓練模型,提高識別率.此外,對于醫(yī)療文本還要考慮文本中是否含有修飾性實體,比如表示時間和否定的詞匯等,如“無頭痛”,癥狀“頭痛”前的“無”就是修飾實體.模型最終結果與參數的調試也有較大的關系,設置不同的參數,模型的輸出值可能會不同.

圖6 IndRNN-CRF的loss-step曲線圖

圖7 IDCNN-BILSTM-CRF的loss-step曲線
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
