局部稀疏表示的魯棒PCA人臉識別
2019-04-26 08:55:46游春芝崔建丁伯倫
微型電腦應用 2019年4期
游春芝,崔建,丁伯倫
(1. 山西醫科大學汾陽學院 基礎醫學部, 呂梁 032200; 2. 安徽信息工程學院, 蕪湖 241000)
0 引言
隨著科技的發展,人臉識別在計算機視覺、圖形識別等領域成為研究的熱門。在我們的實際生活當中也被廣泛應用,如公共安全,信息檢索等。盡管人臉識別技術近年來取得巨大的進步,很多相關算法被提出,如矩陣分解[1],線性判別分析[2]等,但是這些算法對光照、遮擋、姿態變化等問題性能嚴重下降。為此基于稀疏表示下的人臉識別算法被廣泛應用,其中最為代表性的為稀疏表示分類方法(Sparse Representation based Classification,SRC)[3],線性回歸方法(Linear Regression based Classification,LRC)[4],這些算法對連續遮擋中并不魯棒。而且對訓練樣本有一定的依賴性。近年來一種對遮擋魯棒的RPCA[5,6]算法被提出,實驗表明RPCA在圖像恢復、聚類等方面也效果顯著。在文獻[6]中Luan等提出通過RPCA將測試樣本分解成低秩和誤差人臉,最后分析誤差人臉,構建平滑因子和稀疏因子用于人臉的識別。然而當字典較大時,低秩分解會變得更復雜。針對此問題我們提出一種局部稀疏表示的魯棒PCA人臉識別算法。受稀疏表示的影響,本文提出用稀疏系數來選取臨近樣本組成新的字典,即選取前K個稀疏系數絕對值和最大的臨近樣本組成新的字典,通過魯棒PCA在新的字典上進行人臉圖像的分類識別。在Yale 、ORL人臉數據的實驗表明通過稀疏系數來選取臨近樣本的可行性。
1 相關工作
1.1 稀疏表示
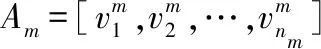
subject toAx=y
(1)
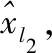
(2)
基于最小二乘問題的系數解可表示為式(3)。
(3)
1.2 基于RPCA人臉識別算法
魯棒主成分分析(RPCA)是將目標矩陣分解為低秩矩陣和誤差矩陣兩部分。設目標矩陣D∈Rn×m,當誤差矩陣E足夠稀疏時(相對于低秩矩陣L),低秩RPCA分解就可以表示為式(4)。
s.t.D=L+E
(4)
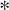
Dsparsity(E)=Num(|E|≤ε)
(5)
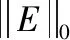
(6)
平滑性:設Ex,Ey分別表示矩陣E的水平和垂直方向的偏導數,Dsmoothness(E)表示矩陣E的平滑性,值越小平滑性越好。
通過稀疏性、平滑性構建基于比值的判別準則為式(7)。
S(E)=Dsparsity(E)/Dsmothness(E)
(7)
則 identityy=argmaxS(E)。
2 局部魯棒主成分分析(LRPCA)
在RPCA人臉識別算法是通過將每個用戶的訓練樣本依次與待測試人臉進行低秩誤差分解。然后通過誤差圖像的稀疏性和平滑性進行人臉識別。該算法一方面導致現存的低秩分解算法很難在有限時間內找到優質解,另一方面隨著字典樣本數的增大,算法準確識別率也會降低,這在很大程度上限制了該算法在數據識別方面的發展。使用部分訓練樣本不僅會加快測試樣本的稀疏分解過程,同時可以提高算法的分類準確性。文獻[9-11]中提出稀疏系數可以反映樣本之間的相關性,即對測試樣本的貢獻程度。與l1范數下求解稀疏系數相比l2范數逼近求解速度更快,實驗發現稀疏系數更能反應樣本的相關性。本文我們取稀疏系數的絕對值和來衡量樣本之間的相關性,以此來選取鄰近的訓練樣本。從ORL人臉數據庫中進行測試的一個例子,如圖1所示。

b 訓練集
圖1中a是測試樣本,圖1b是部分訓練樣本。圖1a經訓練樣本圖1b稀疏表示后對應的各樣本系數絕對值和如圖2所示。
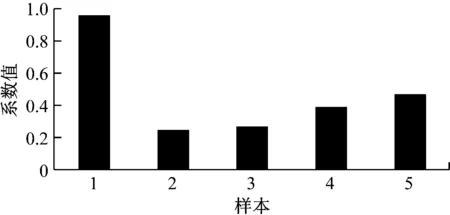
圖2 稀疏系數樣本的相關性
測試樣本圖1a在訓練樣本1上系數最大0.96,說明通過稀疏系數的相關性來選擇鄰近樣本具有一定的可行性。
改進的RPCA人臉識別算法流程如下:
(1) 輸入:訓練樣本矩陣A∈Rm×n,測試樣本ym×1,K等參數;
(2) 分別對訓練樣本和測試樣本進行歸一化處理;
(5) 通過RPCA分解,得誤差矩陣Ei;
(6) 用式(7)計算(S(Ei));
(7) 輸出:測試圖像的類別。identity=arg maxS(Ei)。
3 實驗驗證與分析
本節通過在ORL,Extended Yale B人臉數據庫的實驗來驗證算法的有效性,對比方法主要有LRC、SRC、CRC等。參數說明:所選用的機器是Acer 筆記本電Matlab2014a,CPU 為Intel Core i5- 3210M雙核處器,4GD DR3內存,Windows 10系統進行仿真實驗。通過與SRC、LRC、CRC、RPCA和本文新算法(NEW)對比驗證算法的性能,實驗中參數K=R/5;
實驗一:ORL人臉數據庫由40個人組成,每個人10幅不同表情姿態圖片。總計400張。實驗中首先將所有圖像縮放為大小為64×64的人臉圖像,隨機選擇每個人的8幅圖像組成訓練樣本,其余為待測試樣本。部分樣本如圖(3)所示。

圖3 ORL人臉庫中的部分訓練樣本
在實驗中取10次中最高的識別率作為最終的結果。在ORL人臉數據庫實驗結果如表1所示。

表1 ORL人臉數據庫上的正確識別 (%)
由表1可看出,本文算法最高識別率相比SRC、LRC、CRC算法顯著提升,與RPCA相當。
實驗二:Extended Yale B人臉庫是根據光照程度依次分為5個子集,38類人,2 414幅人臉圖像。實驗中選取子集1、2、3、4、5中每個人臉的前兩幅圖像組成訓練樣本,其余作為測試樣本。Extended Yale B人臉庫部分訓練樣本,如圖4所示。

圖4 Extended Yale B人臉庫部分訓練樣本
不同算法在5個子集下的識別率,如表2所示。
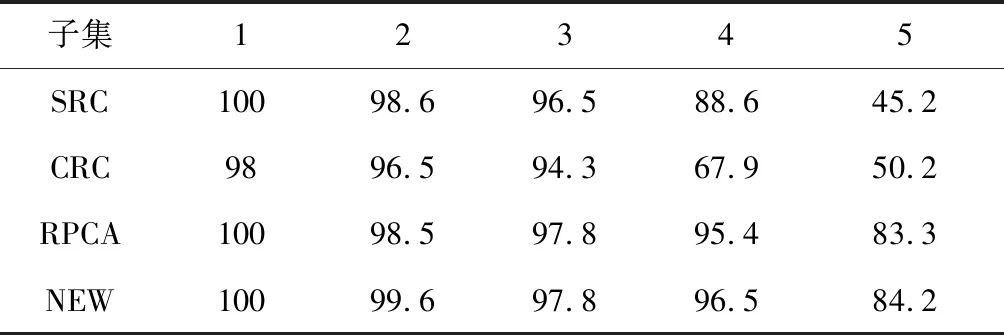
表2 Extended Yale B上的正確識別率(%)
從表2中可以看出在前四個子集中RPCA、NEW這兩種方法的最高都達到百分之百的高識別率;在子集4和子集5作為測試集,即光照對人臉影響較大時,RPCA、NEW算法都能達到80%~90%,相比其他算法有更好的識別性能。
實驗三:為了驗證改進的算法在遮擋的人臉的效果,我們采用Extended Yale B人臉庫中的子集1和子集2、3分別作為訓練樣本和測試樣本.將測試樣本分別進行隨機塊遮擋和偽裝實驗,部分遮擋如圖5所示。其中(a)表示一個遮擋了40%的測試樣本,圖5(b)是進行測試的5類訓練樣本,圖5(c)是分解后對應的低秩圖像,圖5(d)是對應的誤差部分。
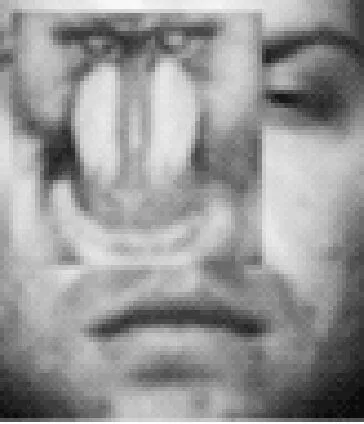
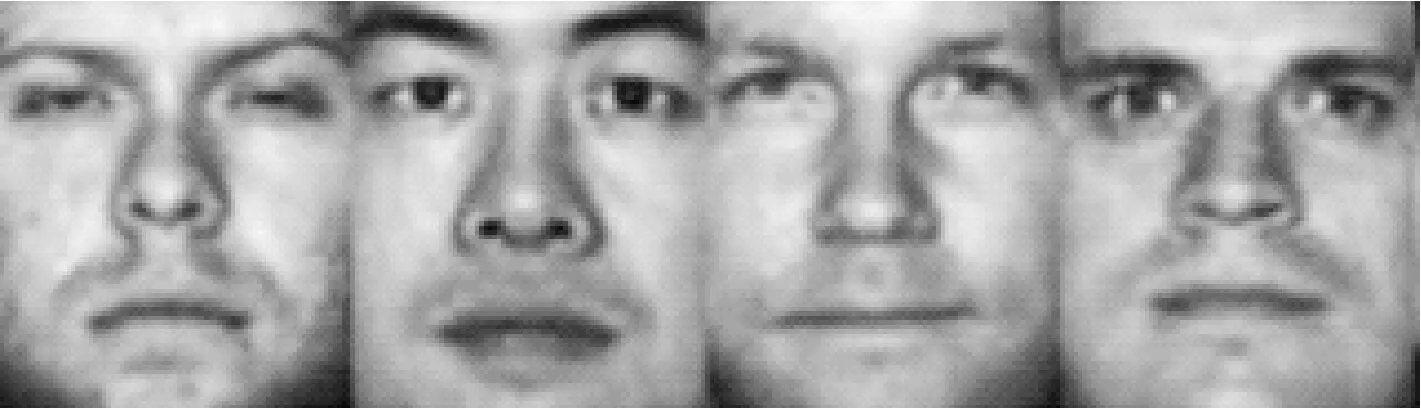


圖5 隨機遮擋人臉圖像RPCA分解
表3是所有算法在不同遮擋程度下SRC、LRC、RPCA與本文的算法NEW的對比。如表3所示。
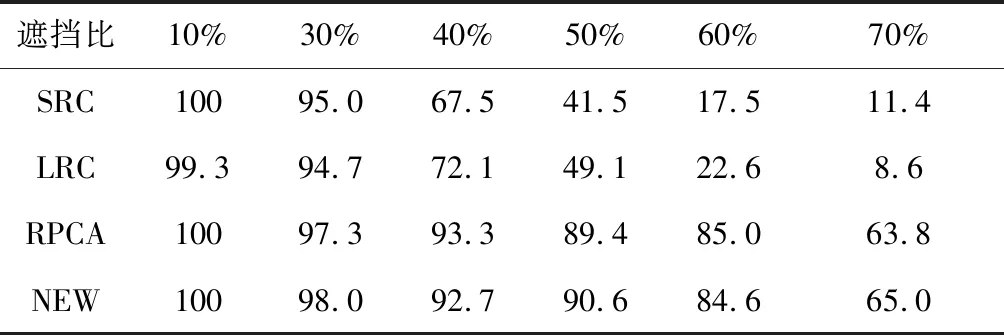
表3 不同遮擋下各算法的正確識別率(%)
不難看出即便是在60%的遮擋下,識別率都能達到88%遠比SRC和LRC,體現了算法對的遮擋具有較高的魯棒性。
實驗四:表4列出了在ORL人臉數據庫上各種算法的識別速度,實驗中我們取當識別率最高時對應的每個測試樣本的平均時間作為標準如表4所示。

表4 不同算法在ORL人臉數據庫測試時間
從實驗可以發現,改進算法總體來說在保證識別率的條件下很大程度上減少了計算成本,改進的新算法計算時間是RPCA的1/5,主要原因在于訓練樣本減少為原來的1/5。
4 總結
本文通過稀疏表示中稀疏系數的相關性對訓練樣本進行篩選,然后在新的字典上進行低秩、誤差分解。在基于表情、光照、遮擋的人臉數據實驗表明新的算法具有很好的魯棒性,而且很大程度上提高計算速度。另一方面也驗證了利用稀疏系數選取臨近樣本的可行性。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
作文中學版(2022年1期)2022-04-14 08:00:34
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
學生天地(2020年31期)2020-06-01 02:32:06
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2017年17期)2017-12-18 06:40:55
電子制作(2017年1期)2017-05-17 03:54:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
計算機工程(2015年8期)2015-07-03 12:19:07
