基于分治算法的DNA序列比對成本模型
2019-04-28 05:59:36劉欣睿四川大學軟件學院
數碼世界 2019年3期
劉欣睿 四川大學軟件學院
引言
DNA序列比對是生物信息學中的一項重要任務,在實際應用中,DNA序列比對可用于DNA親代測試,同時有助于了解物種和個體差異之間的變化。本文將提供最佳的DNA序列比對,旨在減少任何給定序列的缺失匹配和缺口的數量。算法實現的第一個挑戰是巨大的搜索空間,因此本文建立了優化數學模型以修剪搜索方法。其次,不能用蠻力來找到比較的最佳方法。綜上本文算法基于這兩個挑戰而引入。
1 分治算法
對于分治算法需要確定何時退出遞歸。例如,對于兩個DNA序列:X(0,m)和Y(0,n),如果要計算opt(i,j),那么遞歸的退出可以分為兩種情況:

但該算法存在兩個缺陷。首先,該算法僅提供最佳成本懲罰,而不是最佳對齊。其次,算法的復雜度非常大并且呈指數增長,在最壞的情況下,該算法的時間復雜度將為O(3 ^ max(m,n))。
2 動態規劃算法
為克服上述分治算法的缺陷,本文引入動態規劃算法。在設計動態規劃算法時,通常可以遵循以下幾個步驟:
1.分析和比較最優解的特征;
2.遞歸定義最優值;
3.通過自上而下的邏輯運算得到最優解,得到函數的最大值或最小值。
這種方法是以時間交換空間。首先,建立一個m乘n的矩陣。然后將opt(i,j)的結果存儲到第i行第j列。例如,設有兩個DNA序列 X(0,10)和 Y(0,8):
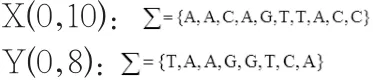
根據遞歸的終止條件,可以得出以下結論:

3 算法實現結果
由上述算法原理可進一步實現動態規劃算法,最終得到已知DNA序列的成本矩陣11*9,如下所示:

i/j 0T 1A 2A 3G 4G 5T 6C 7A 8 -0A 7 8 10 12 13 15 16 18 201A 6 6 8 10 11 13 14 16 182C 6 5 6 8 9 11 12 14 163A 7 5 4 6 7 9 11 12 144G 9 7 5 4 5 7 9 10 125T 8 8 6 4 4 5 7 8 106T 9 8 7 5 3 3 5 6 87A 11 9 7 6 4 2 3 4 68C 13 11 9 7 5 3 1 3 49C 14 12 10 8 6 4 2 1 210- 16 14 12 10 8 6 4 2 0
根據上述矩陣,已知array [0] [0]=7,即可利用tracepath來獲得最佳對齊。
(1)如果(0,1)屬于路徑,則 opt(0,0)= opt(0,1)+ 2 = 6+ 2 = 8> 7,因此這種情況不會退出。
(2)如果(0,1)屬于路徑,則 opt(0,0)= opt(1,0)+ 2 = 8+ 2 = 10> 7,因此這種情況不會退出。(x0與a對齊間隙)
(3)如果(1,1)屬于路徑,則 opt(0,0)= opt(1,1)+ 1 = 6 +1 = 7,因此本情況是最佳對齊。(x0與y0對齊,但是x0與y0不匹配)
4 結論
序列比對是生物信息學中最基本的問題。為了進一步研究DNA序列比對問題,本文建立了一個新模型,稱為成本模型,以確定比對優化的程度。基于這個新模型,使用Divide and Conquer算法來解決這個問題。但本文選擇動態規劃算法來克服時間復雜性的缺陷。最后,創建了后向跟蹤算法,以找到最佳對齊的軌跡。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
河南電力(2021年5期)2021-05-29 02:10:00
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電影(2018年12期)2018-12-23 02:18:48
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
中國衛生(2016年2期)2016-11-12 13:22:16
光學精密工程(2016年6期)2016-11-07 09:07:19
中國工程咨詢(2016年4期)2016-02-14 07:28:28
