基于改進K均值聚類算法的星點聚類研究
2019-05-14 08:10:36夏永泉孫靜茹WUXinwen謝希望
圖學學報 2019年2期
夏永泉,孫靜茹,WU Xin-wen,支 俊,王 兵,謝希望
?
基于改進K均值聚類算法的星點聚類研究
夏永泉1,孫靜茹1,WU Xin-wen2,支 俊1,王 兵1,謝希望1
(1. 鄭州輕工業學院計算機與通信工程學院,河南 鄭州 450000; 2.格里菲斯大學工程信息技術學院,昆士蘭 布里斯班 4000)
針對高分辨率天文圖像中的星點聚類研究中存在的2個問題:①天文圖像的分辨率較高,且圖像處理速度較慢;②選取何種聚類算法對天文圖像中的星點進行聚類分析效果較好。在研究中,問題1采用圖像分塊的方法提高圖像的處理速度;問題2提出了一種改進的K均值聚類算法,以解決傳統的K均值聚類算法的聚類結果易受到值和初始聚類中心隨機選擇影響的問題。該算法首先在用K均值聚類算法對數據初步聚類的基礎上確定合適的值,其次用層次聚類對數據聚類確定初始聚類中心,最后在此基礎上再采用K均值聚類算法進行聚類。通過MATLAB仿真實驗的結果表明,該算法的聚類結果與效率優于其他聚類算法。
k值;初始聚類中心;K均值聚類算法;層次聚類
對于天文圖像中星點的提取識別,國內外眾多專家學者都進行了研究,其中,王龍等[1]提出一種星敏感器星點聚類提取方法;全偉和房建成[2]提出一種基于蟻群聚類算法的快速星圖識別方法;王春歆等[3]提出一種基于層次聚類的弱小目標檢測算法。雖然這些文獻通過聚類算法提取識別星點,但是很少對星點進行聚類分析的研究。
本文主要對天文圖像中星點作聚類分析。星點聚類分析可采用的算法有很多,其中K均值聚類算法是最著名和最常用的方法之一。但是,由于傳統的K均值聚類算法必須在聚類前設定值和隨機選取聚類中心,最后得到的聚類結果會受到值和聚類中心的影響。若選取的值和聚類中心不合適,不僅會增加迭代的次數還會導致聚類結果不理想。張素潔和趙懷慈[4]提出一種算法,基于SSE (sum of the squared error)選取聚類個數,基于聚類中心點所在的周圍區域相對比較密集、聚類中心點之間距離相對較遠的選取原則來選取初始聚類中心;GUPTA等[5]提出一種混合PSO和K均值聚類的算法,用PSO算法優化K均值聚類的結果。魏建東等[6]提出基于DBI度量的層次初始的聚類個數自適應的聚類算法;陶瑩等[7]通過全局化思想對K均值算法的改進,避免選取出初始聚類中心;CHAKRABARTY[8]提出一種質心初始化技術,用于K均值聚類算法;AKTHAR等[9]提出2種選取K均值聚類的初始聚類中心的方法,一種是從高密度區域選擇最遠距離的點作為初始聚類中心,另一種是從高密度區域選擇最近距離的點作為初始聚類中心;CHOUHAN和PUROHIT[10]提出了基于PSO和K均值算法的文檔聚類方法,通過在K均值聚類之前使用PSO方法進行尋找最優點并作為K均值聚類的初始聚類中心;丁明月和莊曉東[11]提出了自適應K均值算法,利用灰度直方圖來確定初始聚類中心;于化龍和韓雪峰[12]提出改進K均值聚類算法的銀行分類算法,根據類間最大相似度均值選擇初始聚類中心;張紅云和李萍萍[13]提出基于層次聚類的K均值算法研究,采用層次方法對文檔進行初始聚類,得到的聚類總數作為K均值算法中的值,在此基礎上,通過K均值聚類對聚類結果進行修訂。
上述文獻用到了各種方法來確定值和優化初始聚類中心,但本文提出一種新的方法來確定初始聚類中心,①通過K均值聚類算法的聚類準則函數值來確定合適的值;②使用經過層次聚類算法聚類后的結果計算出對應的聚類中心作為初始聚類中心;③在此基礎上進行K均值聚類。
1 算法描述
由于天文圖像的分辨率一般都比較大,所以直接對天文圖像進行星點聚類效率很低甚至不能實現,因此本文進行聚類算法前先對天文圖像進行分塊,之后再對每一塊子圖像進行特征提取,確定合適的值和初始聚類中心,其次完成每一塊子圖像的星點聚類,最后以每一塊子圖像的聚類中心作為新的數據,采用本文聚類算法進行聚類得到整幅天文圖像的聚類結果。
1.1 圖像分塊
一般圖像分塊是將1幅圖像分為若干個圖像塊,如2×2,4×4,8×8。而本文采用的分塊機制與之不同。本文采用的是按照一定大小的對圖像依行列的方式直接進行分塊,即將1幅高分辨率的天文圖像按照分辨率的大小分成若干塊。假定原始圖像I經過灰度轉換后分辨率大小為,設置子圖像的寬高大小為,取值為2(=1,2,3,4,···),則天文圖像被分成()×()塊。
1.2 星點聚類特征的選取
本文選取顏色及紋理2類特征。其原因是從直觀上觀察每個星點的大小、明暗度、顏色以及光芒如何發散的不同,而顏色特征可以反映星點的明暗度和顏色,紋理特征可以反映星點的大小和光芒如何發散的。
1.2.1 顏色特征
大部分的彩色圖像是基于RGB顏色3基色模型,但是RGB顏色空間體制并不適應人的視覺特點。所以本文采用更加符合人眼視覺特征的HIS顏色空間。HSI顏色空間模型是色調(ue)、飽和度(Saturation)和強度(Identity)首字母的簡稱。H表示顏色的種類,S表示顏色的純度,I表示亮度信息。HSI顏色空間是由RGB顏色空間轉換得來的,轉換關系如下
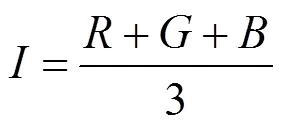
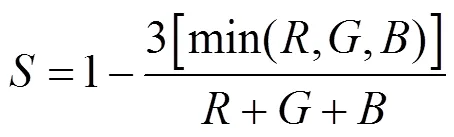
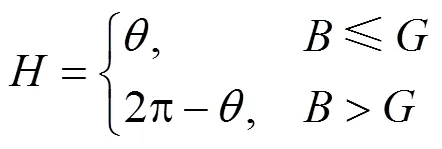
其中
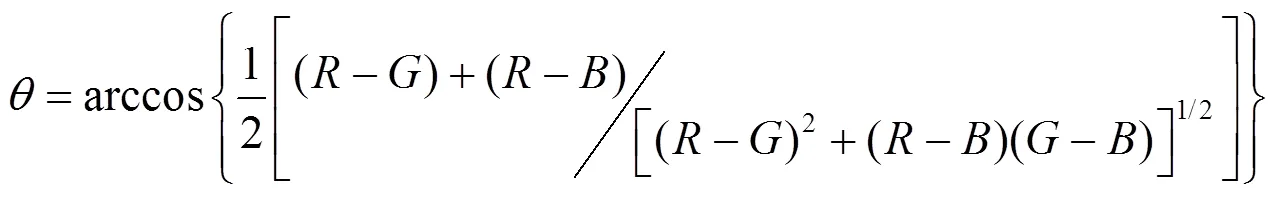
1.2.2 紋理特征
紋理特征提取有多種方法,如灰度差分統計、自相關函數、灰度共生矩陣等。本文使用灰度共生矩陣描述紋理。1幅圖像的灰度共生矩陣能反映圖像灰度方向,相鄰間隔和變化幅的綜合信息。為了能夠更加直觀地以共生矩陣描述紋理狀況,選取以下5個標量來表征灰度共生矩陣的特征。
(1) 能量。是灰度共生矩陣元素值的平方和,反映了圖像灰度分布均勻程度和紋理粗細度。
(2) 對比度。反映了圖像的清晰度和紋理溝紋深淺的程度。返回整幅圖像中像素和其相鄰像素之間的亮度反差。
(3) 相關性。是度量灰度共生矩陣元素在行列方向上的相似程度,因此,相關性的值反映了圖像中局部灰度相關性。返回整幅圖像中像素與其相鄰像素是如何相關的度量值。
(4) 熵。是圖像所具有的信息量的度量。表示圖像中紋理的非均勻程度或復雜程度。
(5) 平穩度。反映圖像紋理的同質性,度量圖像紋理局部變化的多少。返回度量灰度共生矩陣中元素的分布到對角線緊密程度。
綜合以上2種特征,可以定義一個樣本有8個特征值,則可以看作是一個8維的特征向量,即
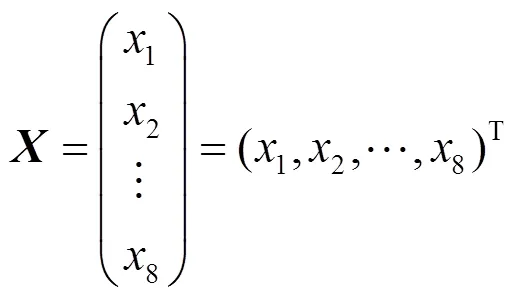
其中,1為對比度;2為相關性;3為熵;4為均勻度;5為能量;6為,7為,8為。
1.3 k值(聚類個數)的確定
傳統的K均值聚類算法中的值必須是用戶人為最先確定,即分成多少類。但是合適的值,用戶是不可知的。因此本文通過對星點進行不同值下的K均值聚類算法,選取合適的值。選取適當的值的一個普遍方法是通過遍歷得到某一范圍聚類數的誤差平方和。誤差平方和準則是一種簡單而又廣泛應用的聚類準則,以評價聚類的優劣。
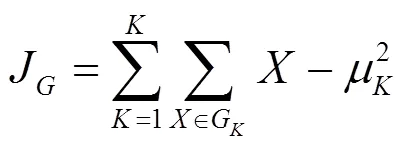
1.4 初始聚類中心的確定
傳統的K均值聚類算法在聚類前隨機選取聚類中心,并根據初始聚類中心進行循環迭代,直到聚類中心不在變化停止。因此,初始聚類中心的不同可能導致聚類結果的不穩定,會產生多個局部最優值。
本文算法通過以層次聚類作為前期處理,得到初步聚類結果,根據聚類結果選擇相應的聚類中心的方法優化初始聚類中心。以此聚類中心作為K均值聚類的算法的初始聚類中心,進行K均值聚類算法。
前期處理中層次聚類是首先定義樣本之間和類與類之間的距離,在各自成類的樣本中,將距離最近的2類合并,重新計算新類與其他類間的距離,并按最小距離歸類。重復此過程,每次減少一類,直到所有的樣本稱為一類為止。
根據式(4)定義包含個數據的特征值矩陣可用一個行8列的矩陣表示。那么第個樣品和第個樣品的特征值向量見式(7),2個樣品的距離可根據歐式距離式(8)求得d,即
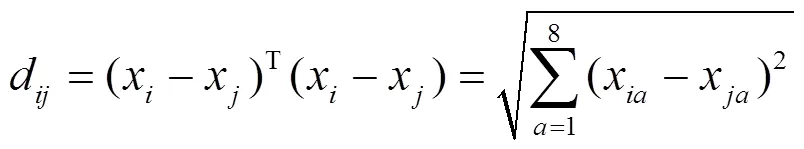
類與類之間的距離選取的是ward距離,用D表示第個類G到第個類G的距離。先計算1,2,···中各樣本與類重心(即均值)的歐氏距離,然后將之取平方求和,得出結果稱為離差平方和。若通過計算,把距離最近的2個類(G和G)合并,使之成一個新的類(G),那么這2個類(G和G)和合并后的新類G的離差平方和分別為[14]式(9)~(11),即
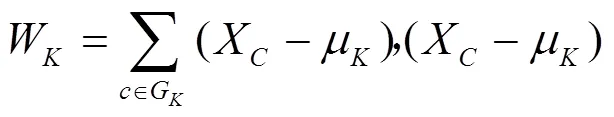
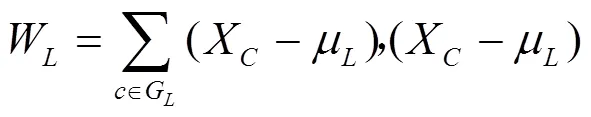
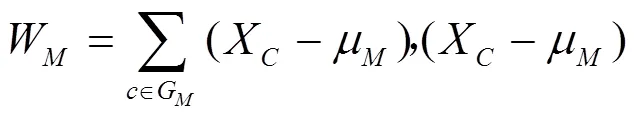
其中,

μ,μ,μ分別為類G,G,G的重心;W,W,W為各自類內樣本分散程度的度量。G和G之間平方距離表示為
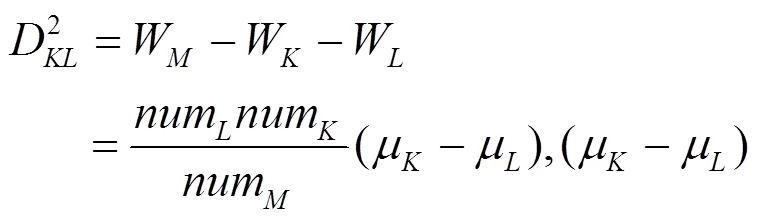
根據歐氏距離和ward距離完成層次聚類,并根據層次聚類的聚類結果計算出相應的聚類中心。聚類中心以某一類中的所有樣本特征的平均值表示,根據式(13)可計算出其特征值,即
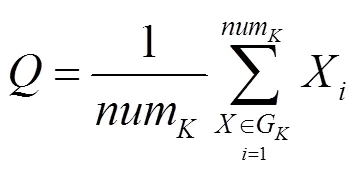
1.5 星點聚類
由于圖像分辨率較大,所以在聚類分析時,需對每塊子圖像進行星點聚類分析,再對子圖像之間進行聚類分析從而得到整幅天文圖像的聚類分析。
1.5.1 子圖像的星點聚類
首先通過腐蝕膨脹提取出每個圖像塊中的星點,并提取其紋理特征和顏色特征。其次對同1幅圖像作3種方法的聚類分析,且分別記錄聚類時間和誤差平方和的值。
(1) 傳統的K均值聚類算法。首先在整個數據集中任意選取個數據作為初始聚類中心,然后根據其他數據對象與個聚類中心的距離大小,將數據對象劃分到距離最近的相似類中。所有數據劃分后,重新計算個聚類中每個聚類的全部數據對象的平均值,該平均值所在的數據點作為新的聚類中心,經過多次迭代,直到連續2次的聚類中心相同,說明此時數據對象類別劃分完畢,即得到個聚類。
(2) 文獻[5]方法。一種混合PSO和K均值聚類的算法,用PSO算法優化K均值聚類的結果。先進行一次傳統的K均值聚類算法,再對得到的聚類結果運用PSO算法優化。
(3) 本文方法也稱改進的K均值聚類算法。通過算法確定值和初始聚類中心。將傳統的K均值聚類算法改進成了一種自適應選取值的并優化了初始聚類中心的K均值聚類算法。
1.5.2 整幅圖像的星點聚類
若對整幅圖像直接進行聚類分析,時間過長甚至得不到結果,所以需要通過對子圖像之間的聚類分析得到整幅圖像的值,即可將整幅圖像中的星點分成若干類。本文算法如下:
(1) 對每塊子圖像進行聚類分析。根據式(4),式(5)和式(11)得到每塊圖像的值和每一類的聚類中心的特征值。通過循環得到所有的子圖像的聚類中心的特征值矩陣;
(2) 對聚類中心的特征值矩陣采用本文算法進行聚類分析,得到的聚類結果中的值就是整幅圖像的值。
2 實驗結果與分析
2.1 實驗平臺
實驗平臺選取matlabR2013b,4核CPU i5-3470,內存4 GB,操作系統Windows 8。
2.2 實驗結果與分析
聚類實驗中將分辨率為40000×30131的天文圖像按照2048×2048大小的分塊分辨率分成圖像塊,對每一個圖像塊中的星點進行3種方法的聚類分析,得到3種算法的聚類準則函數值和聚類時間,并根據所有的圖像塊的聚類中心的聚類結果得到天文圖像的值。
(1)值的確定。根據不同的值,對同一幅圖像進行多次傳統的均值聚類,分別得到聚類準則函數值。以一張圖像為例,值與聚類準則函數值的關系變化如圖1所示。
從圖1可看出,隨著值的增加,聚類準則函數值越小。其中在=3之后,聚類準則函數值的減少速度越來越平緩,而=3之前,聚類準則函數值的急劇減少,即星點分成3類比較合適。
(2) 分析3種算法聚類結果的優劣。選取多幅圖像實驗,證明改進后的算法得到的結果的優越性。由于傳統的K均值聚類的結果具有不穩定性,所以選用多次結果的平均值作為最終結果。圖像的分辨率較大所以分成的塊數較多,因此任意選取其中的16組進行實驗結果顯示(表1)。選取的原則是對角線選取。實驗結果見。
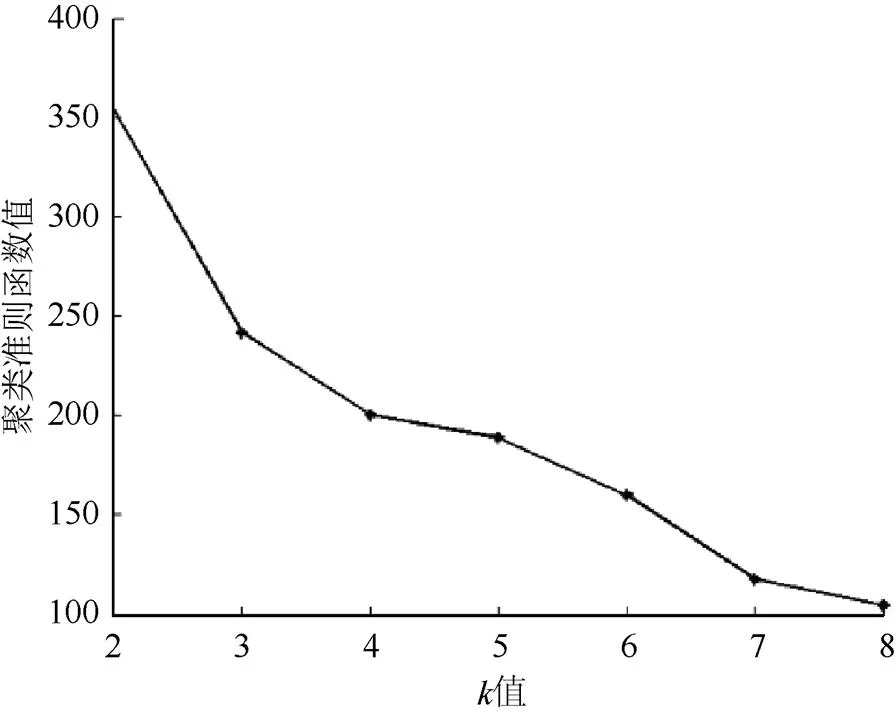
圖1 k值與聚類準則函數值的關系變化圖
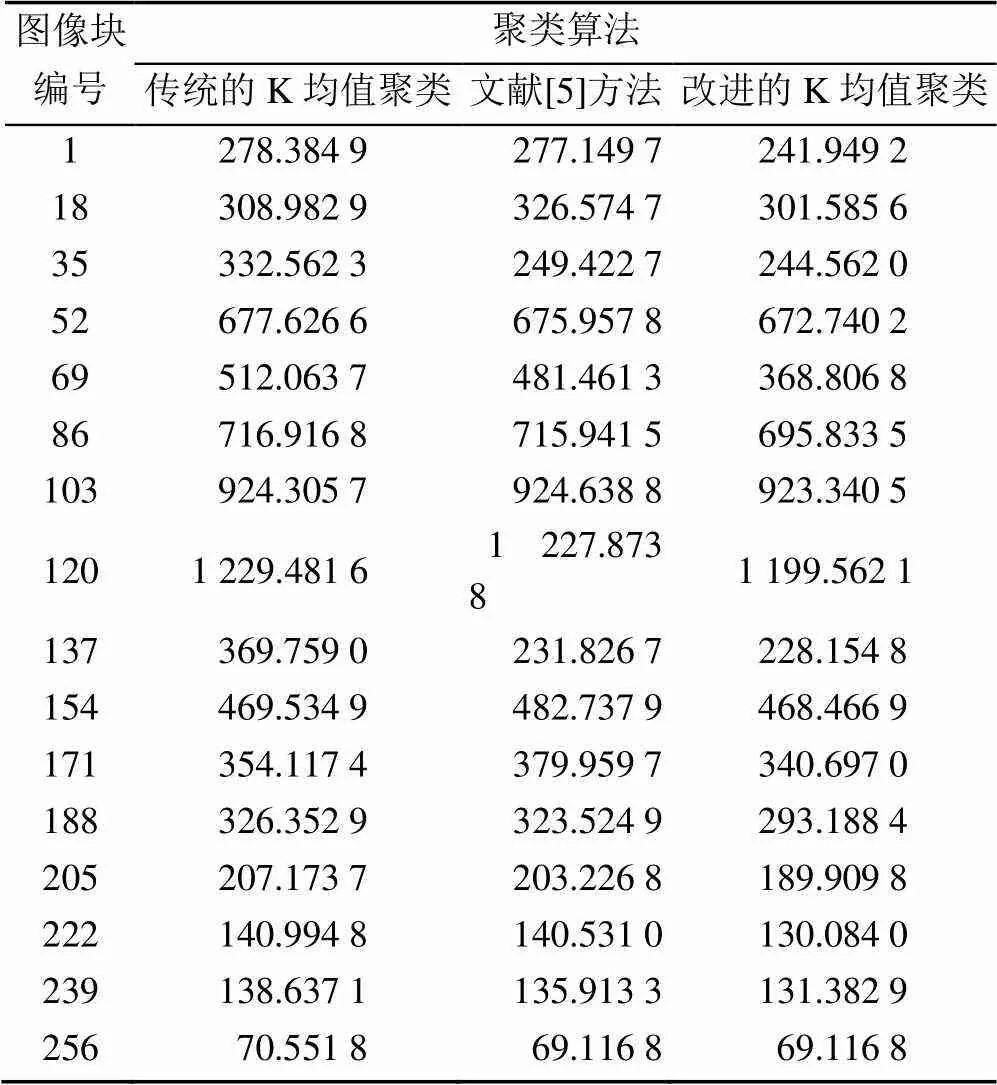
表1 聚類準則函數值表
聚類結果折線圖如圖2所示。
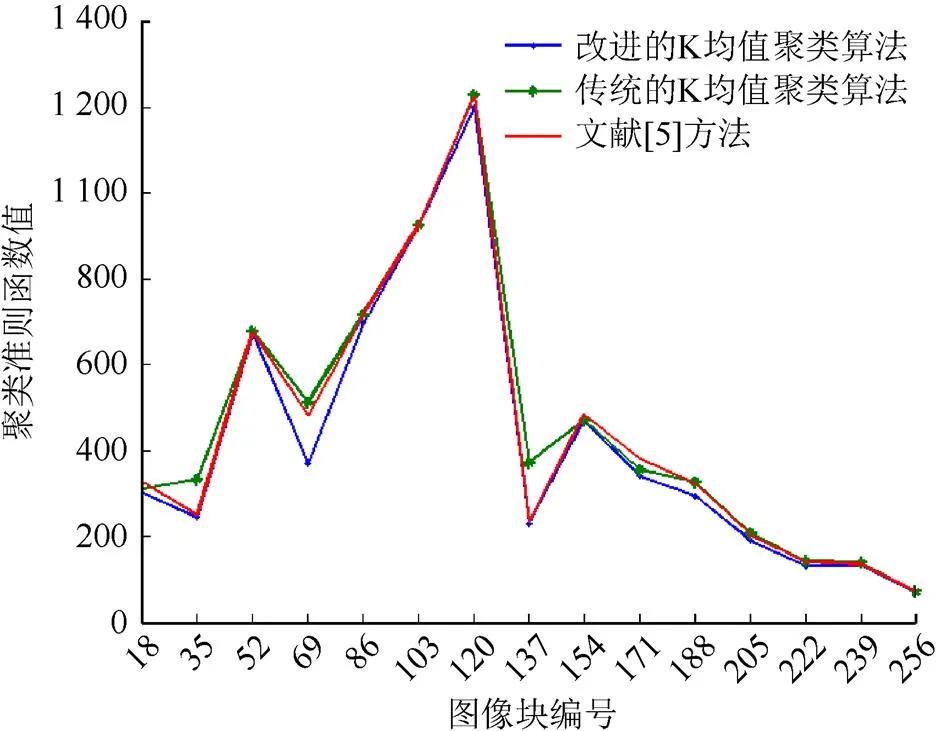
圖2 聚類結果圖
從表1可以看出,3種聚類算法的準則函數值相差的不大,只有幾個數值相差較大,說明3種聚類算法在一些圖像上進行聚類分析時差異性較大,但大部分圖像的差異性較小。
從圖2可以看出,改進的K均值聚類的每個結點的值都小于傳統的K均值和文獻[5]方法的聚類準則函數值,由于聚類準則函數值越小,代表聚類的效果越好,所以說明改進后的聚類結果優于傳統的聚類結果和文獻[5]的聚類結果。圖3顯示了部分聚類效果圖。

(A1)(B1)(C1) (A2)(B2)(C2)
(3) 分析3種算法的速度。對同一幅圖像分別采用3種算法聚類,分別記錄其聚類時間。表2根據條件(2)中的圖像所運行的聚類時間。
聚類時間折線圖如圖4所示。
從圖4可以看出改進的K均值聚類時間和傳統的K均值聚類時間均小于文獻[5]方法的聚類時間,雖然文獻[5]的聚類結果優于傳統的K均值聚類算法,但是時間要高于傳統的K均值聚類算法,因為文獻[5]方法使用PSO算法優化K均值聚類結果,增加了時間消耗。改進的K均值聚類算法和傳統的K均值聚類算法的聚類時間相差較小,但還是低于傳統的K均值聚類算法,由于初始聚類中心的優化而減少了迭代次數,從而減少了聚類時間。故改進的K均值聚類算法優于其他兩種方法。
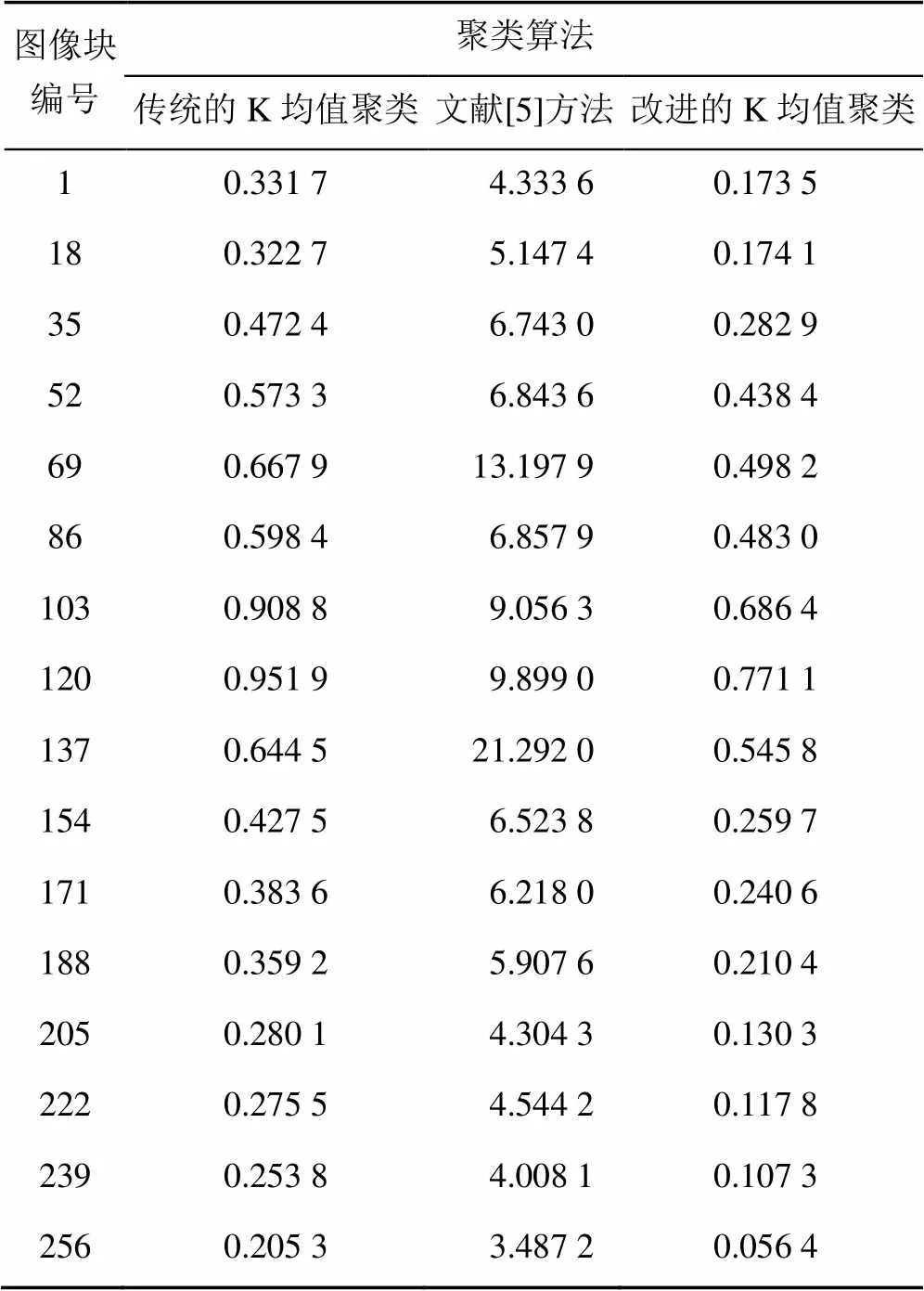
表2 聚類時間表
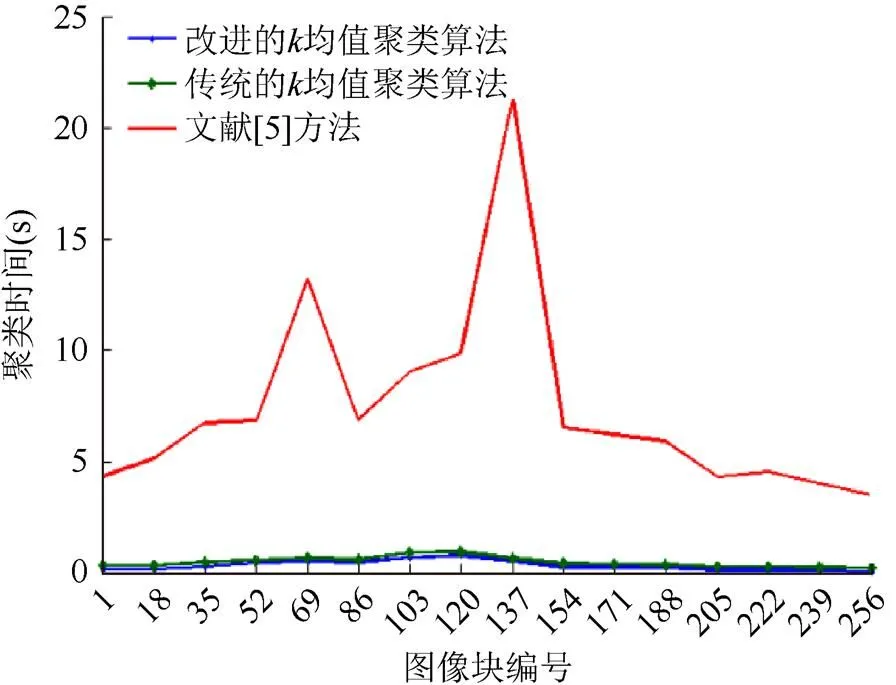
圖4 聚類時間圖
綜上,改進的K均值聚類算法的聚類結果和效率優越于其他聚類算法。
3 結束語
本文針對高分辨率天文圖像中星點聚類問題進行研究,利用改進的K均值聚類算法進行聚類分析。改進的K均值聚類算法通過不同值下的K均值聚類算法找到合適的值,采用層次聚類算法得到初步聚類結果,并計算出聚類中心,以此為K均值算法的初始聚類中心,在得到的值和初始聚類中心時進行K均值聚類算法。通過實驗結果證明改進的K均值聚類算法的聚類結果和效率均比其他聚類算法優越,說明改進的K均值聚類算法更適用于星點聚類。
[1] 王龍, 楊孟飛, 鐘紅軍, 等. 星敏感器星點聚類提取方法[J]. 中國科學: 技術科學, 2015(3): 257-262.
[2] 全偉, 房建成. 一種基于蟻群聚類算法的快速星圖識別方法[J]. 宇航學報, 2008, 29(6): 1814-1818.
[3] 王春歆, 沈同圣, 張玉葉. 基于層次聚類的弱小目標檢測算法[J]. 計算機工程與應用, 2006, 44(19): 24-27.
[4] 張素潔, 趙懷慈. 最優聚類個數和初始聚類中心點選取算法研究[J]. 計算機應用研究, 2017, 34(6): 1617-1620.
[5] GUPTA A, PATTANAIK V, SINGH M. Enhancing K means by unsupervised learning using PSO algorithm [C]//2017 International Conference on Computing, Communication and Automation. New York: IEEE Press, 2017: 228-233.
[6] 魏建東, 陸建峰, 彭甫镕. 一種層次初始的聚類個數自適應的聚類方法研究[J]. 電子設計工程, 2015(6): 5-8.
[7] 陶瑩, 楊鋒, 劉洋, 等. K均值聚類算法的研究與優化[J]. 計算機技術與發展, 2018, 28(6): 96-98.
[8] CHAKRABARTY A. An empirical seed initialization idea for K-Means algorithm inspired by CLIQUE algorithm [C]//2017 International Conference on Information Technology (ICIT). New York: IEEE Press, 2017: 21-23.
[9] AKTHAR N, AHAMAD M V, AHMAD S. MapReduce model of improved K-means clustering algorithm using Hadoop MapReduce [C]//Second International Conference on Computational Intelligence and Communication Technology. New York: IEEE Press, 2016: 192-198.
[10] CHOUHAN R, PUROHIT A. An approach for document clustering using PSO and K-means algorithm [C]//2018 2nd International Conference on Inventive Systems and Control (ICISC).New York: IEEE Press, 2018: 19-20.
[11] 丁明月, 莊曉東. 基于數據融合的K均值聚類彩色圖像分割方法[J]. 青島大學學報: 工程技術版, 2018, 33(2): 46-50, 62.
[12] 于化龍, 韓雪峰. 基于改進K均值聚類的銀行客戶分類算法[J]. 湘潭大學自然科學學報, 2018, 40(3): 129-132.
[13] 張紅云, 李萍萍. 一種基于層次聚類的K均值算法研究[J]. 微計算機信息, 2010, 26(12): 228-229.
[14] 王學民. 應用多元分析[M]. 上海: 上海財經大學出版社, 2009.
Star Point Clustering Based on Improved K-Means Clustering Algorithm
XIA Yong-quan1, SUN Jing-ru1, WU Xin-wen2, ZHI Jun1, WANG Bing1, XIE Xi-wang1
(1. School of Computer and Communication Engineering, Zhengzhou University of Light Industry, Zhengzhou Henan 450000, China; 2. Faculty of Engineering and Information Technology, Griffith University, Brisbane Queensland 4000, Australia)
Two problems in the study of star point clustering in high resolution astronomical images: ① The resolution of the astronomical image is higher, and the image processing speed is slower. ② Which clustering algorithm is selected to cluster the star points in the astronomical image is better. In the research, problem 1 uses image segmentation method to improve image processing speed. problem 2 proposes an improved K-means clustering algorithm to solve the traditional K-means clustering algorithm clustering results are susceptible to-value and The initial clustering center randomly selects the problem of impact. Firstly, the K-means clustering algorithm is used to determine the appropriate-value based on the preliminary clustering of data. Secondly, the clustering is used to determine the initial clustering center by data clustering. Finally, K-means clustering is used. The algorithm performs clustering. The simulation results of MATLAB show that the clustering results and efficiency of the algorithm are better than other clustering algorithms.
k-value; initial cluster center; K-means clustering algorithm; hierarchical clustering
TP 391.41
10.11996/JG.j.2095-302X.2019020358
A
2095-302X(2019)02-0358-06
2018-10-18;
2019-01-13
國家自然科學基金項目(81501547);河南省科技攻關項目(172102410080)
夏永泉(1972-),男,遼寧綏中人,副教授,博士。主要研究方向為圖像處理、計算機視覺、模式識別與人工智能研究。 E-mail:694473762@qq.com
