基于DPI 和BP 神經(jīng)網(wǎng)絡的P2P 流量識別研究
2019-05-17 07:42:26萬建偉胡勇
現(xiàn)代計算機 2019年10期
萬建偉,胡勇
(四川大學電子信息學院,成都 610021)
0 引言
在過去的十幾年里,對等網(wǎng)絡P2P(Peer to Peer)技術在各個領域里得到了廣泛的應用。P2P 技術的使用,使得網(wǎng)絡用戶在作為客戶端的同時也成為了服務端,能夠給網(wǎng)絡中的其他節(jié)點提供服務,共享信息。因此,采用P2P 技術的應用軟件因受到用戶的歡迎而快速發(fā)展。研究表明,60%的互聯(lián)網(wǎng)流量都是P2P 流量。P2P 協(xié)議傳輸?shù)臄?shù)據(jù)具有傳輸速度快、容量超大等優(yōu)點,它極大地方便了用戶,但與此同時,由于缺乏有效的監(jiān)管,P2P 應用也給網(wǎng)絡服務管理帶來了一些問題,例如,眾多的網(wǎng)絡用戶同時使用P2P 流量會造成網(wǎng)絡堵塞、占用帶寬,這會加大網(wǎng)絡開銷。并且P2P 流量在傳播的過程中,可能會攜帶木馬病毒、詐騙信息,容易造成網(wǎng)絡安全問題;還有部分P2P 應用軟件為了搶占客戶資源,惡意侵占網(wǎng)絡帶寬,大大降低了網(wǎng)絡空間的整體利用效率,破環(huán)了網(wǎng)絡運營環(huán)境。
隨著P2P 流量的急劇增多,網(wǎng)絡管理員如何更加有效監(jiān)控P2P 流量成為了一個形勢嚴峻的問題。而要處理好這個問題,必須對P2P 流量進行識別研究,只有識別控制該流量,才能最大化地利用網(wǎng)絡資源,提升整個網(wǎng)絡的使用效率,P2P 流量的識別研究是網(wǎng)絡安全研究領域的熱點。
1 P2P流量的檢測方法
P2P 流量識別技術主要包括:基于固定端口的識別、基于深度包檢測技術(Deep Packet Inspection,DPI)、基于流量統(tǒng)計特征和機器學習的識別方法。
基于固定端口的識別方法是最常用、最基本的識別方法,其原理是通過分析報文段的報頭,獲取傳輸層的端口號信息,識別流量類型。該識別方法在使用固定端口號的應用程序上有著很高的識別率,方法簡單、識別速度快。但是這種方法對未知端口和協(xié)議不適用。
基于DPI 技術的流量識別方法不僅分析數(shù)據(jù)包中源、目的地址和源、目的端口,還要分析應用層的數(shù)據(jù)。獲取數(shù)據(jù)包之后,通過DPI 技術識別載荷里面的特征字,識別出對應類型的流量。DPI 主要是一種對應用層載荷特征進行識別的技術,它基于特征字符串以及行為模式。但是,隨著互聯(lián)網(wǎng)技術的發(fā)展,DPI 方法在檢測流量的過程中出現(xiàn)了一些問題,例如,當P2P應用更新時,檢測分析過程中的特征庫沒有及時更新,則無法檢測出該應用。并且,該方法也不適用于檢測使用加密的應用程序。
基于流量統(tǒng)計特征的識別方法在文獻[1]中有提及,該方法在分析P2P 協(xié)議工作原理的基礎上,提出了區(qū)分P2P 流量的幾個統(tǒng)計特征,如節(jié)點的鏈接不穩(wěn)定性、節(jié)點發(fā)現(xiàn)模式、遠端IP 分布廣度。基于流量統(tǒng)計特征的識別方法識別度好且效率高效,這是由于該方法選取了良好的流量特征,成功克服了基于效載荷方法成本高、無法識別加密流量的局限性,但是它不能辨別出具體的P2P 流量。
而后出現(xiàn)了大量的基于機器學習的識別方法,主要包括支持向量機、決策樹以及基于神經(jīng)網(wǎng)絡的識別方法。該類方法不再依賴于單個應用程序的特征,而是對基于流的傳輸層特性進行分析,進而識別P2P 應用,該方法可以解決深度包檢測技術不能識別應用層加密流量和應用更新的問題。文獻[2]提出了基于支持向量機(SVM)的識別方法,其改進模型有:基于SVM的遺傳算法[3],基于SVM 的粒子群優(yōu)化算法[4]和基于SVM 的人工蜂群算法[5]等。該方法是一種有堅實理論基礎的新穎的小樣本學習方法,它不僅算法簡單,而且十分穩(wěn)定,但SVM 算法及其改進方法對大規(guī)模訓練樣本難以實施,且在解決多分類問題時存在困難。文獻[6]提出了基于BP 神經(jīng)網(wǎng)絡的識別方法,其改進模型有:基于自適應BP 神經(jīng)網(wǎng)絡的識別方法[7]和基于BP-LVQ 神經(jīng)網(wǎng)絡的識別方法[8]。BP 神經(jīng)網(wǎng)絡具有自學習能力,但是該方法存在選擇網(wǎng)絡結構不唯一的缺點。文獻[9]提出了基于決策樹(Decision Tree)的識別方法,該方法易于理解和實現(xiàn),效率高,但是在處理特征關聯(lián)性比較強的數(shù)據(jù)時誤差比較大。因此,當需要識別流量的數(shù)量足夠大時,以上方法不能很好地識別出P2P 流量。
文獻[10]提出了基于卷積神經(jīng)網(wǎng)絡(CNN)的識別方法,該方法是一種前饋神經(jīng)網(wǎng)絡方法,特別適合圖像處理。CNN 在處理高維數(shù)據(jù)時表現(xiàn)良好,并且無需手動選取特征,訓練好權重,特征分類效果好,但是該方法需要調(diào)參,需要大量樣本,實現(xiàn)起來比較復雜,并且訓練所需時間比較久,在進行P2P 流量識別時,該方法不能實時識別出流量類型。
本文結合機器學習利用傳輸層數(shù)據(jù)的檢測方法和DPI 方法,提出了一種新的識別模型:基于DPI 和BP神經(jīng)網(wǎng)絡的P2P 流量識別模型。該模型很好地彌補了DPI 檢測法不能及時識別出更新后的P2P 應用和加密應用的缺點,極大地提升了識別P2P 流量的能力。
2 P2P流量檢測新模型
該模型結合DPI 技術和BP 神經(jīng)網(wǎng)絡來識別P2P流量。該模型的檢測流程圖如圖1 所示。
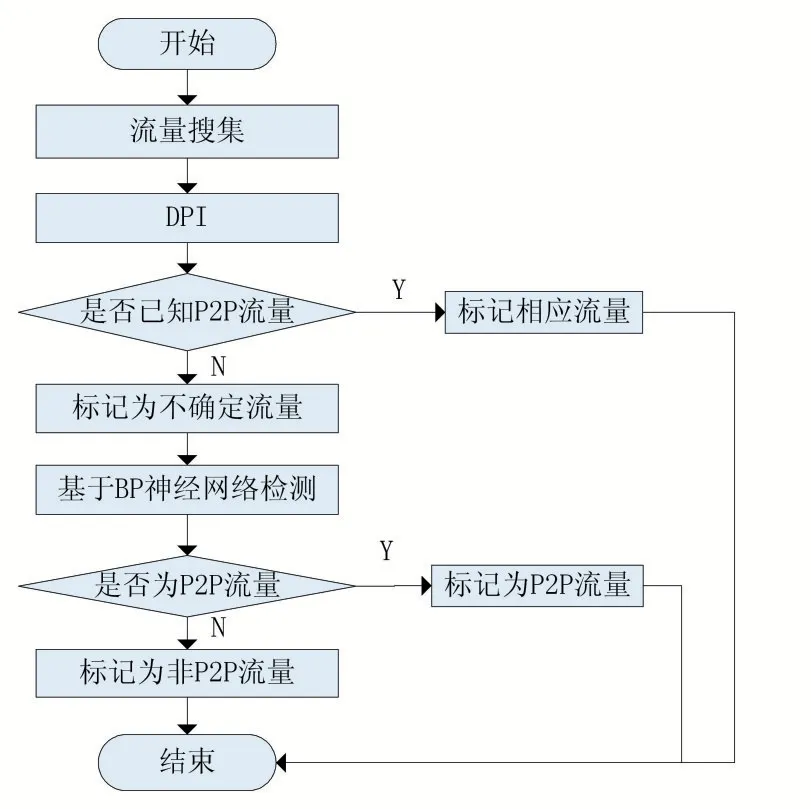
圖1 混合檢測模型
流量收集模塊的功能是捕獲流經(jīng)網(wǎng)絡中的流量,當被捕獲的流量傳到DPI 模塊后,該模塊提取這些流量的應用層特征,再結合特征庫中的特征數(shù)據(jù),對提取的特征進行匹配,判斷該流量是否為P2P 流量。若是,則標記該流量為已知流量;若不是,則進行下一步操作,將該流量送入基于BP 神經(jīng)網(wǎng)絡模塊,做進一步識別。圖1 是對此模塊的詳細說明。
2.1 DDPPII檢測模型
深度包檢測技術(DPI)通常利用模式匹配算法對數(shù)據(jù)包有效載荷中協(xié)議的關鍵字進行匹配,從而判斷是否屬于對應的協(xié)議。DPI 技術主要包含兩個方面,一方面是匹配算法的選取,另一方面是協(xié)議中關鍵字的提取。協(xié)議關鍵字的提取:有些協(xié)議具有唯一標識該數(shù)據(jù)包對應業(yè)務類型的特征串,可以通過搜索數(shù)據(jù)包中應用層有效載荷的特征串,識別數(shù)據(jù)包中的協(xié)議。部分協(xié)議的負載特性如表1 所示。
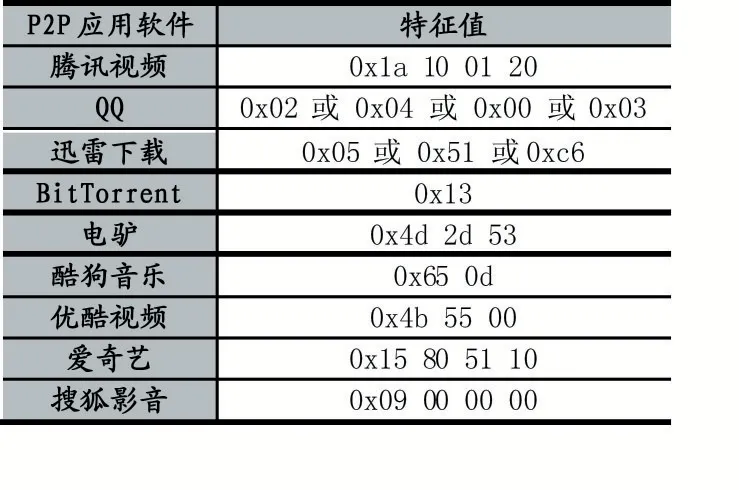
表1 常見的P2P 應用軟件特征值
在協(xié)議識別過程中,提取特征串的準確度越高,識別的結果越準確。
匹配算法利用特征庫中的協(xié)議特征字匹配數(shù)據(jù)包應用層中有效載荷的內(nèi)容,如果匹配成功,則將該數(shù)據(jù)包的協(xié)議類型對應到協(xié)議特征字的應用類型。如使用表 1 中的 BitTorrent 的特征串“0x13Bittorrent Protocol”匹配數(shù)據(jù)包中有效載荷的內(nèi)容,如果匹配成功,則認為這個數(shù)據(jù)包屬于BitTorrent 數(shù)據(jù)包。匹配算法[11]可以分為多模匹配和單模匹配兩種,常見的算法有KMP、AC、KR 和BM。特征串的長度與模式匹配算法的時間復雜度有關,當特征串較長時,模式匹配算法的計算速度較慢,這將導致DPI 吞吐量降低。
綜上所述,在使用DPI 技術識別有特征字的協(xié)議時,可以準確、可靠地識別相應協(xié)議流量,但是特征庫需要隨著協(xié)議的更新而不斷更新。
2.2 基于BBPP神經(jīng)網(wǎng)絡的檢測模塊
BP 神經(jīng)網(wǎng)絡在模式識別、數(shù)據(jù)壓縮和函數(shù)逼近等領域有著廣泛的應用。圖2 展示了BP 神經(jīng)網(wǎng)絡對已有數(shù)據(jù)進行訓練、建立流量分類器的過程,圖2 對未知流量分類進行了解釋。
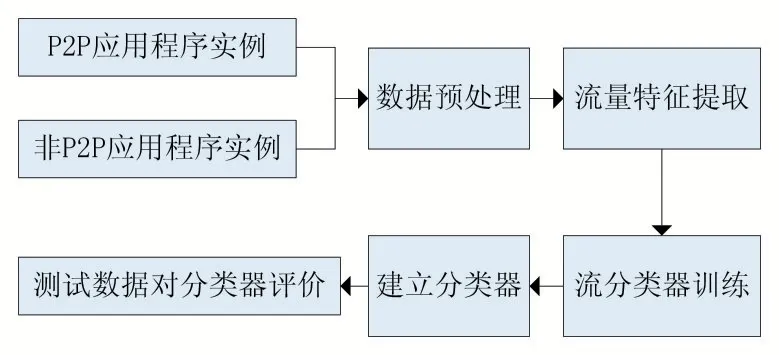
圖2 流量分類器的建立過程
首先,選擇部分常見的P2P 應用(例如BitTorrent、騰訊視頻、酷狗音樂等)和部分非P2P 應用(例如FTP、網(wǎng)頁瀏覽、DNS)的數(shù)據(jù)作為訓練數(shù)據(jù)和測試數(shù)據(jù)集。實驗中,為提高對一些非常見流量的識別度,將選擇等量的應用程序?qū)嵗?/p>
其次將這些應用程序進行預處理,提出數(shù)據(jù)流的特征屬性,如流持續(xù)的時間、流中發(fā)送/接收數(shù)據(jù)包的個數(shù)、流中發(fā)送與接收數(shù)據(jù)包個數(shù)的比值等。接著選擇流量特征。
特征選擇也叫特征子集選擇,是指從眾多特征中選出可以使系統(tǒng)獲得最優(yōu)化特征子集,去除冗余特征的過程。通過這種方法可以提高數(shù)據(jù)質(zhì)量。本文通過使用WireShark 工具對采集的P2P 流量數(shù)據(jù)樣本進行分析,同時結合Moore 數(shù)據(jù)集(該數(shù)據(jù)是由英國劍橋大學的Moore 等在一天的10 個不同時間段采集經(jīng)過網(wǎng)絡出口的所有雙向流量數(shù)據(jù)所得到的,該數(shù)據(jù)集包含了377526 個流量樣本,由十個集合構成,其中每一條的數(shù)據(jù)流樣本又包含248 個屬性特征。)中的大量屬性特征進行比較,最終將用作P2P 流量識別依據(jù)的流特征向量定義為:
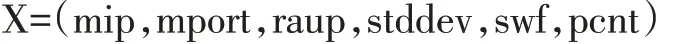
其中,各分量分別對應一個流量特征:多連接性特征(mip)、多端口性特征(mport)、遠端地址端口統(tǒng)一性特征(raup)、數(shù)據(jù)包凈荷長度標準差(stddev)、大小數(shù)據(jù)包交替出現(xiàn)次數(shù)(swf)和凈荷長度大于零的數(shù)據(jù)包個數(shù)(pcnt),這些特征分別從不同的視角闡述了P2P 流量與非P2P 網(wǎng)絡流量的差異,雖然單個特征不足以用來準確識別P2P 流量,但是多個特征的組合則產(chǎn)生累加效應,從而提高識別準確率。
接著將訓練數(shù)據(jù)輸入BP 神經(jīng)網(wǎng)絡檢測模塊,建立分類器。在整個訓練過程中,選取包含P2P 應用和非P2P 應用的46500 條數(shù)據(jù)流量,驗證方法采用十折交叉法,用于提高準確度。
BP(Back Propagation)神經(jīng)網(wǎng)絡的學習過程包含前向傳播和反向傳播兩個部分,它是目前應用最為廣泛的神經(jīng)網(wǎng)絡之一。前向傳播將輸入神經(jīng)元的閾值整合進隱層權值向量中,逐層傳播。當輸出層的實際輸出和期望輸出不符時,進入誤差反向傳播,將誤差分攤給輸出層和隱含層的所有處理單元,逐層修正權值和閾值,反復迭代。通過這種方法,可以大大降低誤差。圖3 中是一個三層BP 神經(jīng)網(wǎng)絡的結構圖。

圖3 三層BP神經(jīng)網(wǎng)絡
本文使用三層神經(jīng)網(wǎng)絡進行訓練和測試,選取輸入神經(jīng)元的個數(shù)為6,即樣本數(shù)據(jù)會話流的6 個屬性特征。輸出神經(jīng)元是輸入流量的對應類別,取值為0 或1,結果為1 則判定輸入流量為此類別,反之,則不是。通過多次訓練比較,確定隱含層神經(jīng)元的個數(shù)為11。
最后驗證分類器的精確度,所用的數(shù)據(jù)為測試數(shù)據(jù)集。
數(shù)據(jù)的分類過程如圖4。通過預處理捕獲的46500 條數(shù)據(jù)流量,獲取統(tǒng)計特征,然后篩選出所需特征,再將樣本中的流量數(shù)據(jù)輸入分類器,通過輸出結果判斷流量是否為P2P 類型。
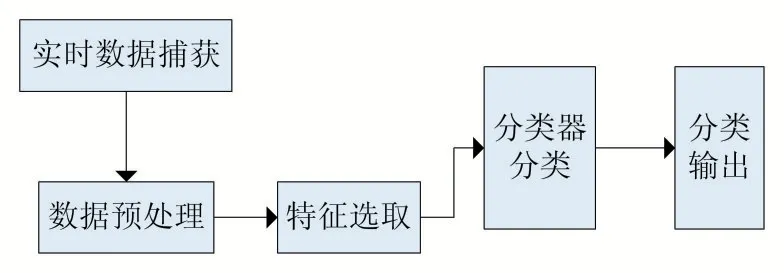
圖4 BP神經(jīng)網(wǎng)絡基于傳輸層檢測法
3 實驗過程
3.1 實驗環(huán)境
實驗拓撲結構如圖5 所示,在實驗室局域網(wǎng)環(huán)境下,使用3 臺均為Win7 系統(tǒng)的客戶端,1 臺服務器的操作系統(tǒng)使用的是Linux 系統(tǒng)。在Linux 服務器內(nèi)運行識別P2P 流量的程序Weka3.7。
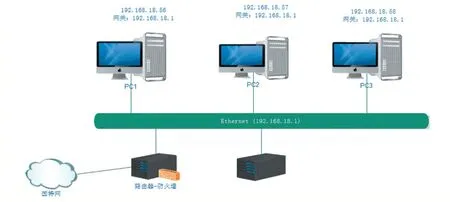
圖5 實驗拓撲圖
3.2 實驗方法
方法1:使用DPI 方法,測試應用選擇BitTorrent、酷狗音樂、騰訊視頻、迅雷、Skype。
方法2:使用BP 神經(jīng)網(wǎng)絡檢測方法。
方法3:結合BP 神經(jīng)網(wǎng)絡和DPI 的檢測方法。
分別在3 臺客戶端的虛擬機(VMware 下的Win7系統(tǒng))上運行P2P 應用軟件,PC1 上運行BT 下載以及Skype 聊天;PC2 上運行騰訊視頻在線播放以及迅雷下載;PC3 上運行酷狗音樂和 Skype 聊天。BitTorrent、騰訊視頻、迅雷、酷狗音樂的應用層特征均為已知,Skype為加密應用軟件。同時,在每臺PC 上運行網(wǎng)頁瀏覽、FTP 上傳等非P2P 流量操作。本實驗中,通過3 臺客戶端來獲取數(shù)據(jù),以便在較短的時間內(nèi)得到足夠多的數(shù)據(jù)量,在VMware 環(huán)境下可以減少Windows 系統(tǒng)自帶的應用軟件在運行過程中對采集的數(shù)據(jù)流量進行干擾。數(shù)據(jù)采集完畢后,運行Linux 系統(tǒng)中的識別程序。
3.3 實驗結果
運行15 分鐘后,從程序中得到的實驗識別結果如圖6 所示。
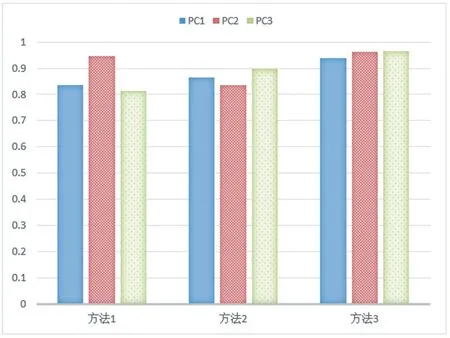
圖6 各方法的識別率
由圖6 可以看出,DPI 技術在識別P2P 流量時,識別率達到了86%以上;BP 神經(jīng)網(wǎng)絡在識別P2P 流量時,識別率也在85%左右;而結合了DPI 和BP 神經(jīng)網(wǎng)絡的方法在識別P2P 流量時,識別率達到了95%。
整理圖表數(shù)據(jù),對各方法的平均識別率進行對比,結果如表2 所示。
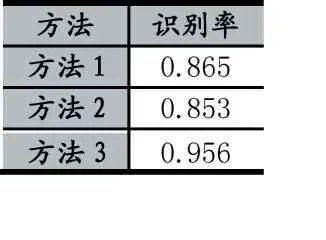
表2 各方法的平均識別率
由表2 可知,在進行P2P 流量識別時,DPI 的識別率為86.5%,BP 神經(jīng)網(wǎng)絡的識別率為85.3%,結合了DPI 和BP 神經(jīng)網(wǎng)絡方法的識別率為95.6%。
3.4 實驗分析
結合圖6 和表2 中的數(shù)據(jù)進行分析可知,基于DPI 的檢測方法在識別BT、騰訊視頻、迅雷、酷狗音樂和Skype 等應用程序時,其效果和基于BP 神經(jīng)網(wǎng)絡的方法相差較小,這是因為基于BP 神經(jīng)網(wǎng)絡的檢測方法在識別BT、騰訊視頻、迅雷和酷狗音樂等已知的P2P應用程序時,其表現(xiàn)不及DPI 方法,但是它在識別加密流量Skype 時,性能比DPI 檢測法要好;而基于DPI 和BP 神經(jīng)網(wǎng)絡的檢測方法結合了兩者的優(yōu)點,在識別已知P2P 應用和加密P2P 應用時都能獲得比較好的性能,因此它的識別率很高。
4 結語
本文結合DPI 和BP 神經(jīng)網(wǎng)絡對P2P 流量進行檢測。實驗證明該方法提升了流量檢測的準確度。但由于傳統(tǒng)BP 神經(jīng)網(wǎng)絡存在易陷入局部極小值的缺陷,在以后的工作中可以對BP 算法做一些優(yōu)化,進一步提升P2P 流量檢測的準確度。
猜你喜歡
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
